引言:为什么肺部分割如此重要?
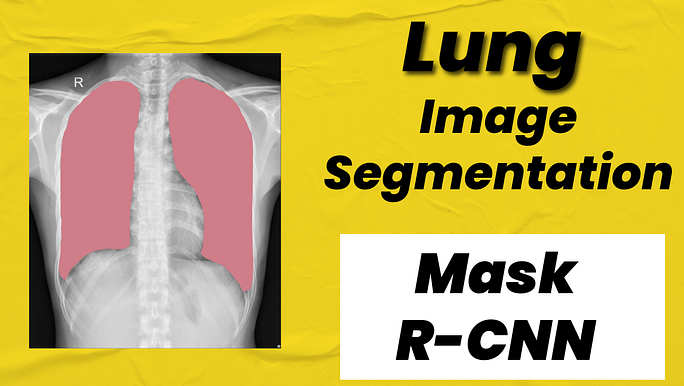
在医学影像分析中,肺部分割是一项基础而关键的任务。无论是胸部X光片还是CT扫描,准确的肺部分割都能:
- 提高后续疾病诊断的准确性
- 减少背景噪声对分析的干扰
- 为下游模型提供更干净的输入数据
传统的肺部分割依赖人工标注,耗时且主观。而Mask R-CNN的出现,彻底改变了这一局面。作为一款强大的实例分割模型,它不仅能检测肺部区域,还能生成精确的像素级分割掩码。
今天,我将带你从零开始,构建一个完整的Mask R-CNN肺部分割训练 pipeline,从环境搭建到模型推理,每一步都有详细的代码和说明。
Mask R-CNN:医学影像分割的利器
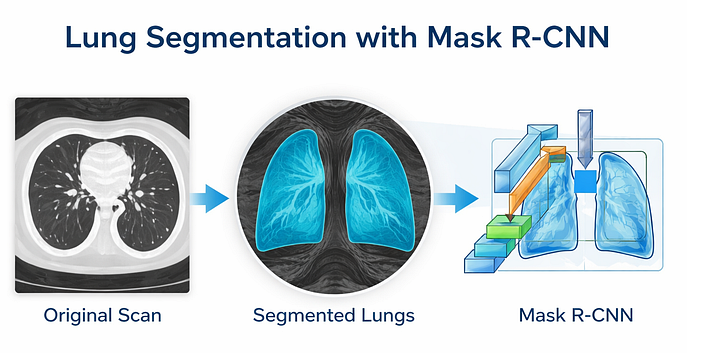
什么是Mask R-CNN?
Mask R-CNN是在Faster R-CNN基础上发展而来的实例分割模型,它的核心优势是:
- 两阶段检测:先定位目标,再生成分割掩码
- 端到端训练:检测和分割在同一个网络中完成
- 高精度:能捕捉到细微的边界和结构
为什么选择Mask R-CNN进行肺部分割?
与传统的U-Net等分割模型相比,Mask R-CNN的优势在于:
- 同时输出边界框和分割掩码,信息更丰富
- 利用区域提议机制,对小目标和复杂边界更敏感
- 支持迁移学习,训练更高效
环境搭建:为训练做好准备
步骤1:创建隔离的conda环境
bash
# 创建环境
conda create --name Pytorch251 python=3.12
# 激活环境
conda activate Pytorch251
# 检查CUDA版本
nvcc --version步骤2:安装核心依赖
bash
# 安装PyTorch(带CUDA支持)
conda install pytorch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 pytorch-cuda=12.4 -c pytorch -c nvidia
# 安装OpenCV
pip install opencv-python==4.10.0.84数据准备:将医学影像转换为训练格式
Mask R-CNN需要特定的训练数据格式,包括图像、边界框和分割掩码。下面是数据准备的核心代码:
python
def prepare_dataset(csv_path, base_dir, output_path, resize=(512, 512)):
# 加载CSV文件
df = pd.read_csv(csv_path)
dataset = []
for _, row in tqdm(df.iterrows(), total=len(df)):
# 加载图像和掩码
image = Image.open(os.path.join(base_dir, row['images'])).convert("RGB").resize(resize)
mask = Image.open(os.path.join(base_dir, row['masks'])).convert("L").resize(resize, resample=Image.NEAREST)
# 转换为张量
image_tensor = TF.to_tensor(image)
mask_tensor = torch.from_numpy(np.array(mask))
# 提取目标实例
obj_ids = torch.unique(mask_tensor)
obj_ids = obj_ids[obj_ids != 0] # 跳过背景
if len(obj_ids) == 0:
continue # 跳过空掩码
# 创建实例掩码
masks = mask_tensor.unsqueeze(0) == obj_ids[:, None, None]
# 计算边界框
boxes = []
for m in masks:
pos = (m.nonzero(as_tuple=True))
xmin, xmax = pos[1].min().item(), pos[1].max().item()
ymin, ymax = pos[0].min().item(), pos[0].max().item()
boxes.append([xmin, ymin, xmax, ymax])
# 构建目标字典
target = {
'boxes': torch.tensor(boxes, dtype=torch.float32),
'labels': torch.ones((len(boxes),), dtype=torch.int64),
'masks': masks.type(torch.uint8),
'image_id': torch.tensor([len(dataset)]),
'area': (masks.sum(dim=(1, 2))).float(),
'iscrowd': torch.zeros((len(boxes),), dtype=torch.int64),
}
dataset.append((image_tensor, target))
# 保存处理后的数据
torch.save(dataset, output_path)
print(f"Saved dataset to: {output_path}")数据准备要点:
- 图像大小:统一调整为512x512,确保训练稳定性
- 掩码处理:使用最近邻插值,保持标签的清晰度
- 边界框:从掩码自动计算,无需手动标注
- 数据格式:严格按照TorchVision的要求构建目标字典
模型构建:定制化Mask R-CNN
加载预训练模型并修改头部
python
def get_model(num_classes):
# 加载预训练权重
weights = MaskRCNN_ResNet50_FPN_Weights.DEFAULT
model = maskrcnn_resnet50_fpn(weights=weights)
# 替换分类头
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
# 替换掩码头
in_features_mask = model.roi_heads.mask_predictor.conv5_mask.in_channels
hidden_layer = 256
model.roi_heads.mask_predictor = MaskRCNNPredictor(in_features_mask, hidden_layer, num_classes)
return model
# 构建模型(背景+肺部,共2类)
model = get_model(num_classes=2)
model.to(device)模型构建要点:
- 迁移学习:使用预训练的ResNet-50 FPN backbone,加速收敛
- 类别设置:num_classes=2(背景+肺部)
- 设备选择:优先使用GPU加速训练
模型训练:带早停和 checkpoint 的训练循环
python
# 训练设置
num_epochs = 50
patience = 10
best_loss = float("inf")
epochs_without_improvement = 0
# 训练循环
for epoch in range(num_epochs):
print(f"\n📘 Epoch {epoch + 1}/{num_epochs}")
model.train()
epoch_loss = 0.0
progress_bar = tqdm(train_loader, desc="Training", leave=False)
for images, targets in progress_bar:
# 数据移至设备
images = [img.to(device) for img in images]
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
# 前向传播
loss_dict = model(images, targets)
total_loss = sum(loss for loss in loss_dict.values())
# 反向传播
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
# 累计损失
epoch_loss += total_loss.item()
progress_bar.set_postfix(loss=total_loss.item())
# 计算平均损失
avg_loss = epoch_loss / len(train_loader)
print(f"🔹 Epoch {epoch+1:02d} | Avg Loss: {avg_loss:.4f}")
# 保存最佳模型
if avg_loss < best_loss:
best_loss = avg_loss
epochs_without_improvement = 0
torch.save(model.state_dict(), "maskrcnn_best.pth")
print("✅ Best model saved.")
else:
epochs_without_improvement += 1
print(f"⚠️ No improvement for {epochs_without_improvement} epoch(s).")
# 保存最后模型
torch.save(model.state_dict(), "maskrcnn_last.pth")
# 早停检查
if epochs_without_improvement >= patience:
print(f"\n⏹ Early stopping triggered after {epoch+1} epochs.")
break训练要点:
- 批量大小:设置为2,平衡GPU内存使用
- 早停机制:避免过拟合和浪费计算资源
- 模型保存:同时保存最佳模型和最后模型,确保训练结果的可靠性
模型推理:测试分割效果
python
# 加载模型
model = get_model(num_classes=2)
model.load_state_dict(torch.load("maskrcnn_best.pth", map_location=device))
model.to(device)
model.eval()
# 推理过程
for rel_path in random_images:
# 加载图像
img_path = os.path.join(base_dir, rel_path)
image_bgr = cv2.imread(img_path)
image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB)
image_tensor = TF.to_tensor(image_rgb).to(device)
# 执行推理
with torch.no_grad():
output = model([image_tensor])[0]
# 绘制掩码
masked_image = image_rgb.copy()
for i in range(len(output["masks"])):
if output["scores"][i] > 0.5:
mask = output["masks"][i, 0].mul(255).byte().cpu().numpy()
color = np.random.randint(0, 255, (1, 3), dtype=np.uint8).tolist()[0]
masked_image[mask > 128] = color
# 保存结果
cv2.imwrite(output_path, cv2.cvtColor(masked_image, cv2.COLOR_RGB2BGR))推理要点:
- 置信度阈值:设置为0.5,过滤低置信度的预测
- 可视化:使用随机颜色绘制分割掩码,便于观察
- 结果保存:同时保存原始图像和带掩码的图像,方便对比
常见问题解答
Q:为什么Mask R-CNN需要边界框?我只想要分割掩码。
A:TorchVision的Mask R-CNN实现需要边界框作为训练输入,这有助于模型学习目标的位置信息,从而生成更准确的掩码。
Q:为什么num_classes设置为2?
A:Mask R-CNN将背景视为一个类别,肺部作为另一个类别,所以总共有2个类别。
Q:图像大小为什么要设置为512x512?
A:固定的图像大小使批处理更稳定,避免因图像尺寸不一致导致的张量堆叠错误。
Q:如何选择合适的置信度阈值?
A:默认0.5是一个合理的起点。如果假阳性太多,可以提高阈值;如果漏检太多,可以降低阈值。
Q:训练损失变成NaN怎么办?
A:常见原因包括边界框格式错误、空掩码、数据类型不匹配或设备放置错误。检查一个批次的数据通常能快速发现问题。
总结
通过本教程,你已经掌握了使用Mask R-CNN进行肺部分割的完整流程:
- 环境搭建:创建隔离的conda环境,安装必要的依赖
- 数据准备:将医学影像转换为Mask R-CNN所需的训练格式
- 模型构建:基于预训练模型,定制化适合肺部分割的网络
- 模型训练:使用早停和checkpoint机制,高效训练模型
- 模型推理:测试分割效果,生成可视化结果
Mask R-CNN不仅适用于肺部分割,还可以扩展到其他医学影像分割任务,如肝脏分割、肿瘤分割等。通过迁移学习和适当的参数调整,你可以快速适应不同的医学影像分割需求。
好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!