文章目录
-
- 介绍
- [一、TREE 核心原理(一句话看懂)](#一、TREE 核心原理(一句话看懂))
-
- [1. 输入:多组学 + 双网络结构编码](#1. 输入:多组学 + 双网络结构编码)
- [2. 核心:共注意力 Co-Attention(最关键创新)](#2. 核心:共注意力 Co-Attention(最关键创新))
- [3. 训练:子图采样 + 多通道聚合 + 加权损失](#3. 训练:子图采样 + 多通道聚合 + 加权损失)
- [二、TREE 为什么能精准预测癌基因?(生物学 + 算法双逻辑)](#二、TREE 为什么能精准预测癌基因?(生物学 + 算法双逻辑))
-
- [1. 生物学依据(模型为什么 "懂" 癌基因)](#1. 生物学依据(模型为什么 “懂” 癌基因))
- [2. 算法优势(为什么比 GCN/EMOGI/GAT 更强)](#2. 算法优势(为什么比 GCN/EMOGI/GAT 更强))
- [三、TREE 怎么解决黑箱:三层可解释(原生可解释,不是事后归因)](#三、TREE 怎么解决黑箱:三层可解释(原生可解释,不是事后归因))
-
- [1. 组学层面:哪类信号最关键?](#1. 组学层面:哪类信号最关键?)
- [2. 路径层面:哪条调控路径最关键?](#2. 路径层面:哪条调控路径最关键?)
- [3. 图模式层面:模型到底在看什么结构?](#3. 图模式层面:模型到底在看什么结构?)
- 代码
- [TREE 模型:输入 / 输出 / 标签(精准完整版)](#TREE 模型:输入 / 输出 / 标签(精准完整版))
-
- 一、输入数据(Input)
-
- [1. 节点属性(多组学特征)→ 核心输入](#1. 节点属性(多组学特征)→ 核心输入)
- [2. 生物网络结构(图结构)](#2. 生物网络结构(图结构))
- [3. 结构编码(模型内部计算,不算人工输入)](#3. 结构编码(模型内部计算,不算人工输入))
- 二、输出数据(Output)
- [三、标签数据(Label / Ground Truth)](#三、标签数据(Label / Ground Truth))
- 参考
介绍
图表示学习已被用于从生物网络中识别癌症基因。然而,其适用性受到解释性和泛化性不足的限制,尤其是在整合网络分析的情况下。
在此,我们报告了一种可解释且可泛化的基于转换器的模型的开发,该模型通过利用图表示学习以及将多组学数据与同质和异质生物相互作用网络的拓扑结构相结合,能够准确预测癌症基因。该模型能够解释多组学和更高阶结构特征的各自重要性,其在跨生物网络(包括 miRNA 与蛋白质之间的网络、转录因子与蛋白质的网络以及转录因子与 miRNA 的网络)的泛癌和癌症特异性场景中预测癌症基因方面达到了最先进的性能,在 8 个泛癌数据集中从 4729 个未标记基因中预测出了 57 个癌症基因候选物(其中包括三个其他模型尚未识别的基因)。该模型的可解释性和泛化能力可能有助于增进对基因相关调控机制的理解,并有助于发现新的癌症相关基因。
Graph Representation Learning(图表示学习,GRL) 是一套将图结构数据(节点、边、子图)映射为低维稠密向量(Embedding)的机器学习方法,核心是保留图的拓扑结构与节点 / 边的属性信息,以便用传统机器学习 / 深度学习模型处理图数据。它不是单一算法,而是涵盖传统图嵌入、图神经网络(GNN)等的技术体系。
TREE 不是事后解释黑箱,而是把 "可解释" 做进模型架构里 ------ 用图 Transformer + 共注意力 + 多组学 + 网络双编码 ,既精准预测癌基因,又能直接告诉你:哪类组学最重要、哪条调控路径最关键、哪类图模式起决定作用。
一、TREE 核心原理(一句话看懂)
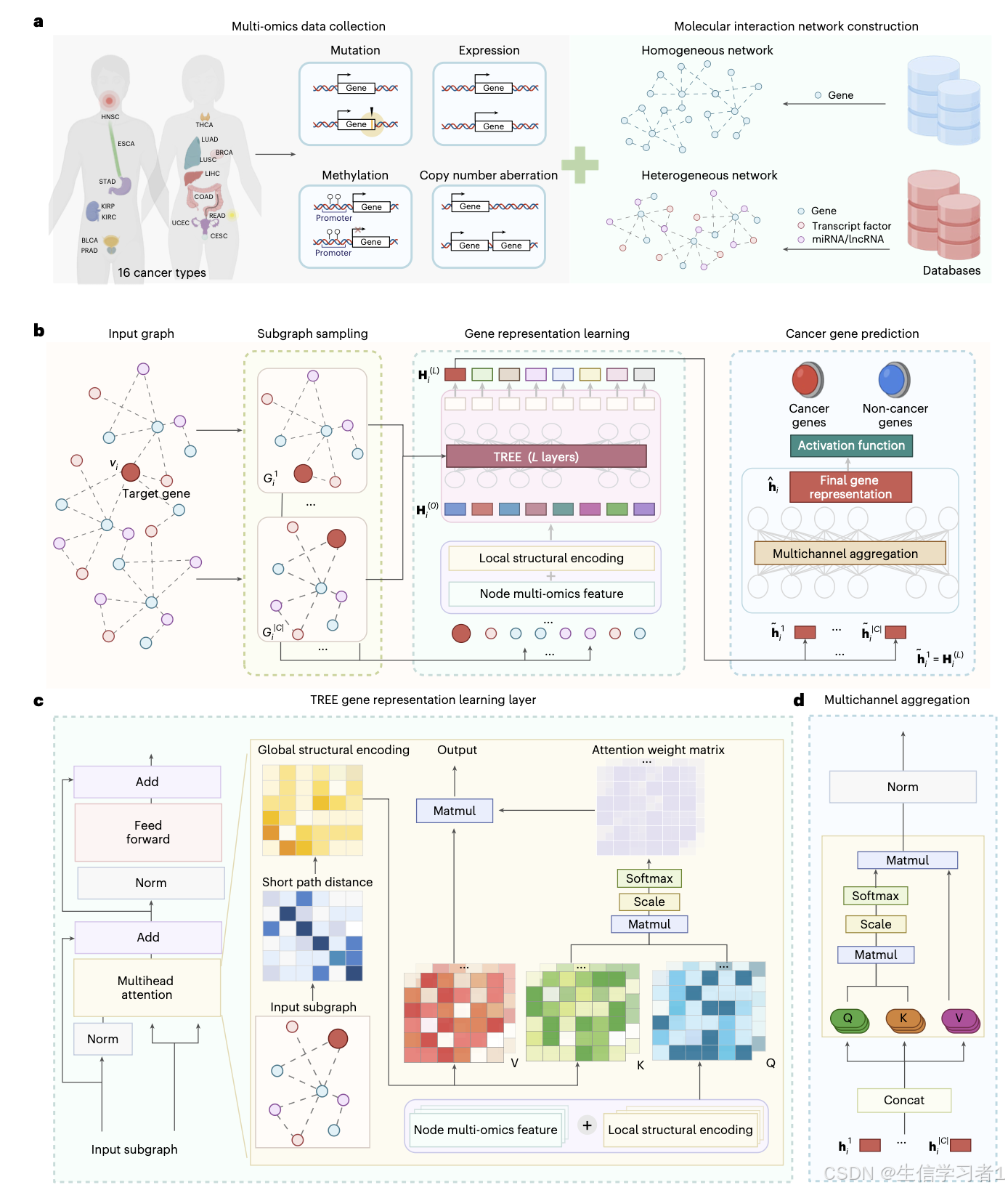
TREE = 适配生物图的 Transformer + 多组学特征 + 全局 / 局部双结构编码 + 共注意力机制 + 多子图聚合
把基因 / TF/miRNA/lncRNA 构成的同质 / 异质生物网络 + 4 类多组学信号一起输入,用 Transformer 注意力学习基因嵌入,最后做二分类判断是否为癌基因。
1. 输入:多组学 + 双网络结构编码
- 节点特征:SNV 突变、表达 GE、甲基化 METH、拷贝数 CNA 4 类多组学
- 局部结构编码:节点度位置嵌入,告诉模型节点在网络里的重要性
- 全局结构编码:最短路径距离,建模长程依赖(解决 GCN 只能看 1-hop 邻居的问题)
- 网络类型:同时支持同质 PPI 网络 + 异质 TMG/LTG 网络(基因 - TF-miRNA/lncRNA)
2. 核心:共注意力 Co-Attention(最关键创新)
标准 Transformer 是自注意力,TREE 改成共注意力:
-
Q 来自多组学 + 局部结构
-
K/V 来自全局最短路径结构编码
→ 让注意力
同时看特征 + 拓扑
,精准抓 "哪些分子、哪条路径、多远距离" 对预测最重要。
3. 训练:子图采样 + 多通道聚合 + 加权损失
- 不训全图,只采局部子图,省算力、适配大生物网络
- 多子图→多通道→自注意力聚合,得到最终基因嵌入
- 加权交叉熵,解决癌基因样本极度不平衡问题。
二、TREE 为什么能精准预测癌基因?(生物学 + 算法双逻辑)
1. 生物学依据(模型为什么 "懂" 癌基因)
- 癌基因不是孤立突变,而是在调控网络里形成驱动模块
- 靠多组学异常 (突变、表达、甲基化、拷贝数)+网络拓扑重要性(度高、路径短、在关键通路)共同决定
- 异质网络能抓到miRNA/TF/lncRNA的间接调控,比只看 PPI 更全面。
2. 算法优势(为什么比 GCN/EMOGI/GAT 更强)
- Transformer 能抓长程依赖,突破 GCN 层数限制与过平滑
- 共注意力比 GAT 单纯注意力更懂 "结构 + 特征" 协同
- 最短路径编码天然适配生物网络 "功能关联往往隔 2-3 跳"
- 子图 + 多通道稳定、泛化强,跨 8 个网络都 SOTA。
三、TREE 怎么解决黑箱:三层可解释(原生可解释,不是事后归因)
TREE 可解释性是模型自带,不用 LRP/GNNExplainer,直接从注意力与梯度读出答案。
1. 组学层面:哪类信号最关键?
- 用SHAP + 梯度算每类组学贡献
- 结论:泛癌中突变 SNV 最重要;特定癌里表达 / 拷贝数占优
- 输出单基因组学贡献热图:比如 TP53 靠什么信号被判定为癌基因。
2. 路径层面:哪条调控路径最关键?
- 定义元路径 metapath:GG/GTG/GMG/GTMTG 等
- 用不同元路径子网训练,看 AUPRC
- 结论:基因--TF--基因、基因--miRNA--TF--基因是最有效模式
- 直接可视化高注意力路径,比如 TET2、TP53 的调控链。
3. 图模式层面:模型到底在看什么结构?
- 逐层统计注意力权重--最短路径距离分布
- 同质网络:看重长程依赖(3--6 跳)
- 异质网络:看重近邻局部结构(1--3 跳)
- 自适应感受野:模型自己选 "该看远还是看近",不用人工预设子图大小。
代码
https://github.com/Blair1213/TREE
TREE 模型:输入 / 输出 / 标签(精准完整版)
一、输入数据(Input)
TREE 的输入由三部分组成:
1. 节点属性(多组学特征)→ 核心输入
每个节点(基因 / TF/miRNA/lncRNA)都有一个64 维多组学向量
基因 & 转录因子 TF:4 类组学 × 16 种癌症 = 64 维
- SNV(突变)
- GE(表达)
- METH(甲基 ation)
- CNA(拷贝数变异)
miRNA /lncRNA:只有表达,其余补 0 → 仍对齐到 64 维
2. 生物网络结构(图结构)
两种网络都支持:
同质网络(PPI)
节点 = 基因
边 = 蛋白--蛋白相互作用
如:CPDB、STRING、PCNet、Multinet、IRefIndex
异质网络
TMG:Gene--TF--miRNA 网络
LTG:Gene--TF--lncRNA 网络
节点类型:基因、TF、miRNA、lncRNA
边类型:基因--基因、TF--基因、miRNA--基因、TF--miRNA 等
3. 结构编码(模型内部计算,不算人工输入)
局部结构编码:节点度嵌入(degree embedding)
全局结构编码:最短路径距离(shortest path)
→ 这两个是模型
根据网络自动计算
的,不是你手动输入的。
二、输出数据(Output)
模型最终输出一个标量概率:
ŷ ∈ 0,1
表示 这个基因是癌基因的置信度
你可以理解为:
- 越接近 1 → 越可能是癌基因
- 越接近 0 → 越可能是非癌基因
输出的两种用途
分类
- ŷ ≥ 0.5 → 预测为癌基因
- ŷ < 0.5 → 预测为非癌基因
排序
按得分从高到低排,选出
候选癌基因
(文章中取 ≥0.9 的 57 个新基因)
三、标签数据(Label / Ground Truth)
标签是二分类标记 ,只给基因节点,TF/miRNA/lncRNA 无标签。
标签格式
y ∈ {0, 1}
- y=1(正样本):已知癌基因
- y=0(负样本):已知非癌基因
标签来源(文章真实数据)
正样本(癌基因)来自 3 个权威库:
- NCG(Network of Cancer Genes)
- COSMIC CGC(癌症基因普查库)
- DigSee 文献挖掘结果
负样本(非癌基因)直接使用 EMOGI 提供的负集
参考
- Interpretable identification of cancer genes across biological networks via transformer-powered graph representation learning