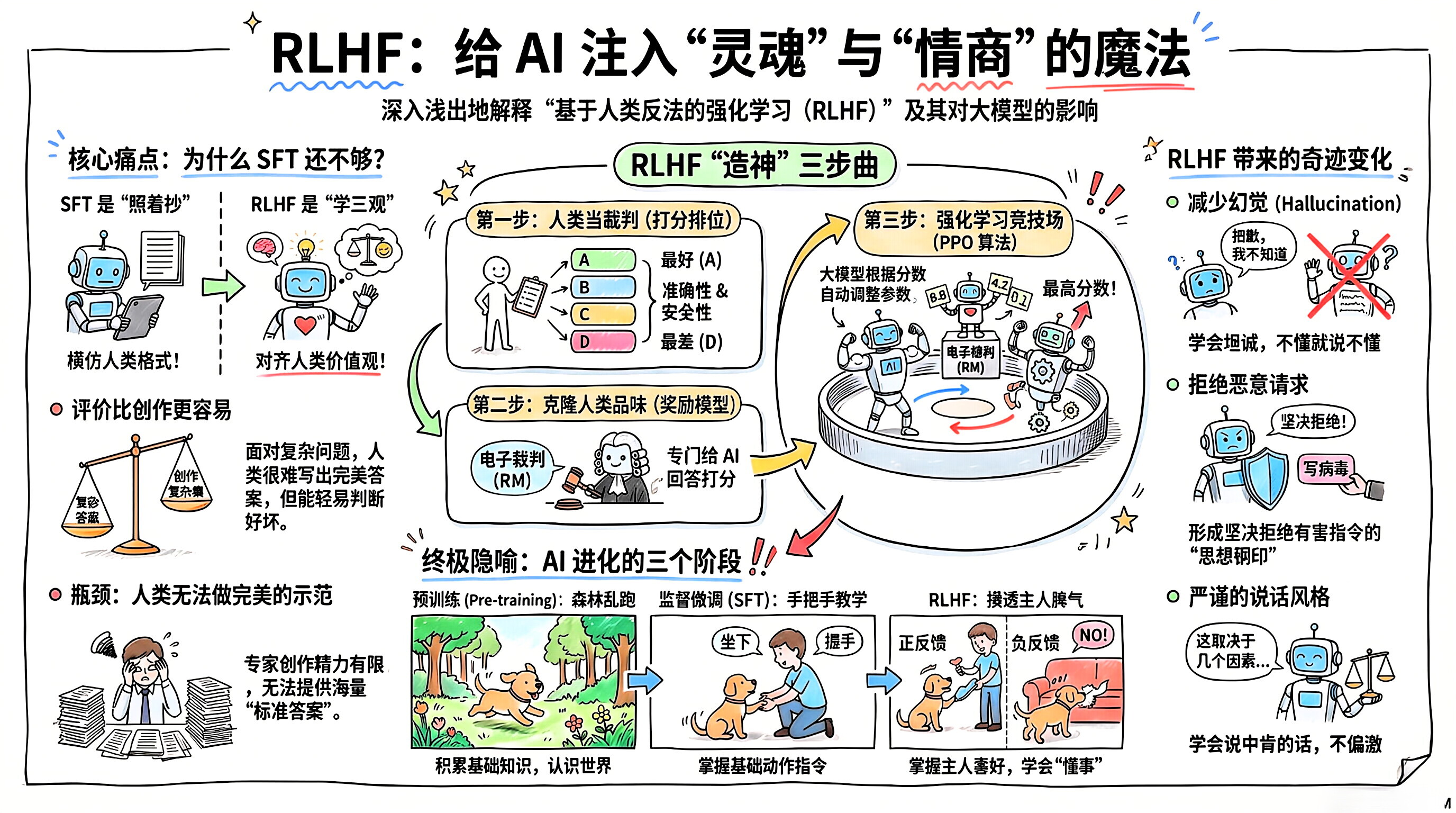
基于人类反馈的 强化学习 ( Reinforcement Learning from Human Feedback , 简称 RLHF ) 是点燃大模型时代的真正魔法,也是 ChatGPT 当年能一鸣惊人、远超其他竞品的"秘密武器"。
如果说 SFT (监督微调) 是手把手教 AI 掌握人类说话的 "格式"; 那么 RLHF 就是在给 AI 培养人类的**"品味、情商和三观"** (即 AI 领域常说的 Alignment / 对齐)。
1.🛑 核心痛点:为什么有了 SFT 还需要 RLHF?
SFT 的逻辑是"人类写标准答案,机器照着抄"。但这遇到了两个巨大的瓶颈:
-
人类写不出完美的答案 :面对极其复杂的问题(比如"如何解决中东冲突"或"写一段极其精妙的 Python 算法"),人类专家也要憋好几天,甚至根本写不出来。如果人类都写不出来,怎么给 AI 做示范?
-
"评价"比"创作"容易得多:这就像我们大多不是米其林大厨(写不出菜谱),但一道菜端上来,我们一口就能尝出好不好吃(能做评价)。
RLHF 的天才构想就是:不再强迫人类去"写标准答案",而是让人类去当"裁判"。
2.⚙️ RLHF 是怎么运作的?("造神"三步曲)
RLHF 把训练过程变成了一场不断试错并追求高分的游戏。它通常分为三个阶段(假设第一阶段的 SFT 已经完成):
第一步:人类当裁判,给 AI 的作答打分排位
-
场景:给出一个 Prompt(比如:"讲个笑话")。
-
AI 盲盒:让经过 SFT 的大模型同时生成 4 个不同的回答(A、B、C、D)。
-
人类排序 :人类标注员坐到电脑前,不写答案,只做选择题。他们根据"是否有害"、"是否好笑"、"是否事实准确"等人类价值观,给这 4 个答案排序,比如:C > A > D > B。
第二步:训练一个"电子裁判" (Reward Model, 奖励模型)
-
让人类天天坐在电脑前打分太贵了,所以我们要克隆人类的"品味"。
-
科学家会用成千上万条人类排好序的数据,单独训练一个相对较小的模型------奖励模型 ( RM )。
-
结果 :这个 RM 不会写文章,但它成了一个极其苛刻的阅卷老师。你扔给它一段话,它就能根据人类的偏好,打出一个具体的分数(比如 8.5 分或 -2.0 分)。
第三步:强化学习 (Reinforcement Learning / PPO 算法)
-
真正的魔法在这里。现在,我们把"大模型"和"电子裁判 (RM)"放在一个封闭的竞技场里。
-
大模型开始疯狂做题。
-
每次写完一个答案,电子裁判就给它打分。
-
大模型 根据分数,利用强化学习算法(通常是 PPO)自动调整自己脑子里的千亿个参数,目标只有一个:尽可能迎合电子裁判的喜好,把分数刷到最高!
3.🛡️ RLHF 带来了什么奇迹?
经过 RLHF 洗礼的模型,发生了脱胎换骨的变化:
-
学会了"说废话/套话":你会发现 ChatGPT 经常说"作为一个人工智能..."、"这取决于几个因素..."。这不仅是因为设定,而是因为在 RLHF 训练中,说这种严谨、两头不得罪的话,能从人类裁判那里拿到最高分。
-
减少了幻觉 (Hallucination):如果它不懂装懂胡说八道,会被人类裁判打极低的分(负反馈)。久而久之,它学会了坦诚地说:"抱歉,我不知道。"
-
拒绝恶意请求:如果你让它写病毒代码,电子裁判会给出毁灭性的低分,从而让它形成"思想钢印",坚决拒绝有害指令。
4.🏟️ 终极隐喻:训狗与寻宝
-
预训练 (Pre-training):让狗在广阔的森林里乱跑,认识所有的花草树木。
-
SFT (监督微调):主人按着狗的头,手把手教它"坐下"、"握手"。
-
RLHF ( 强化学习 ) :主人坐在沙发上,狗如果把拖鞋叼过来,就给一块肉(正反馈);如果狗咬坏了沙发,就大声呵斥(负反馈)。经过成千上万次的互动,狗不仅学会了技能,还完全摸透了主人的脾气和喜好。
总结
RLHF 是 AI 从"冰冷的概率计算器"变成"善解人意的对话伙伴"的关键桥梁。它巧妙地将人类复杂、模糊的价值观和偏好,转化为了数学上可以优化的"奖励信号",从而实现了 AI 与人类社会的超级对齐 (Alignment)。