纯requests+Redis实现分布式爬虫(可视化4终端,模拟4台电脑联合爬取)
摘要:本文详细讲解如何使用Python的requests库结合Redis,实现分布式爬虫架构,通过自动弹出4个可视化终端(模拟4台电脑),完成小说章节的分布式爬取、任务调度与数据汇总。全程不使用Scrapy框架,不依赖多线程,纯多进程+Redis队列实现分布式协作,适合爬虫初学者快速掌握分布式核心原理,同时提供完整可运行代码、详细操作步骤、运行过程演示及常见问题排查,助力大家轻松上手分布式爬虫开发。
一、前言
在爬虫开发中,当面临IP限流、任务量巨大、单机爬取速度过慢等问题时,分布式爬虫就成为了最优解决方案。必须使用多线程才能实现,其实不然。本文将基于最基础的requests库(用于发送网络请求、解析页面)和Redis(用于任务队列调度、实现多节点协作),搭建一个可视化的分布式爬虫系统------通过一个启动文件,自动弹出4个终端窗口(模拟4台独立电脑),实现多节点联合爬取,所有爬取数据自动汇总到同一文件夹,全程可见、可追溯,完美还原分布式爬虫的核心工作流程。
前置环境:Windows系统、Python 3.7+、Redis(本地安装并启动)、requests库、lxml库、redis库。
这个仓库是社区维护的 Redis Windows 原生移植版,官方 Redis 已不再提供 Windows 版本,现在大家用的基本都是这个仓库的版本,必须安装的依赖。
主仓库地址:
https://github.com/tporadowski/redis
二、前置环境准备
2.1 环境安装
首先确保已安装所需依赖库,打开PowerShell(或CMD),执行以下命令安装:
powershell
pip install requests lxml redis说明:requests用于发送HTTP请求,获取网页内容;lxml用于解析HTML页面,提取小说章节标题和内容;redis用于实现分布式任务队列,协调4个终端(节点)的任务分配,避免任务重复或遗漏。
2.2 Redis启动验证
分布式爬虫的核心是Redis任务队列,因此必须确保Redis服务正常启动。启动Redis的步骤如下:
-
找到Redis安装目录(如D:\tools\redis_box),双击redis-server.exe启动Redis服务;
-
启动成功后,终端会显示"Ready to accept connections",表示Redis已准备就绪,可接受爬虫节点的连接;
-
注意:Redis启动后,不要关闭该窗口,否则分布式爬虫无法连接到任务队列。
Redis启动成功演示(可在此粘贴自己的Redis启动运行过程):
plain
# 此处粘贴你的Redis启动运行过程,示例如下:
[408] 15 Apr 18:05:21.322 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
[408] 15 Apr 18:05:21.322 # Redis version=5.0.14.1, bits=64, commit=ec77f72d, modified=0, pid=408, just started
[408] 15 Apr 18:05:21.322 # Warning: no config file specified, using the default config. In order to specify a config file use d:\tools\redis_box\redis-server.exe /path/to/redis.conf
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 5.0.14.1 (ec77f72d/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in standalone mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6379
| `-._ `._ / _.-' | PID: 408
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
[408] 15 Apr 18:05:21.327 # Server initialized
[408] 15 Apr 18:05:21.327 * DB loaded from disk: 0.000 seconds
[408] 15 Apr 18:05:21.327 * Ready to accept connections三、分布式爬虫核心原理
本文实现的分布式爬虫,核心架构为"1个任务生产者 + Redis任务队列 + 4个任务消费者(可视化终端)",模拟4台电脑联合爬取,具体原理如下:
-
集成中心(producer.py):负责访问小说目录页,提取前10章的章节链接,将链接推入Redis队列,相当于"任务调度中心",只需要运行一次,完成任务初始化;
-
Redis任务队列:作为分布式协作的核心,存储所有待爬取的章节链接,4个终端(消费者)同时从队列中获取任务,确保任务不重复、不遗漏,实现负载均衡;
-
工人(worker.py):每个终端运行一个消费者程序,从Redis队列中获取章节链接,使用requests爬取章节内容,解析并保存到本地novel文件夹,所有终端的爬取结果自动汇总到同一文件夹;
-
可视化终端:通过启动脚本自动弹出4个独立的CMD窗口,每个窗口对应一个消费者(模拟一台电脑),实时显示爬取进度,直观感受分布式爬取的过程。
关键说明:本文实现的是"多进程分布式",而非多线程------每个终端是一个独立的进程,不受Python GIL锁限制,真正实现并行爬取,比多线程更适合分布式扩展(可轻松扩展到多台真实电脑)。
四、完整代码实现(可直接复制运行)
本文共需要3个文件,分别是任务生产者(producer.py)、任务消费者(worker.py)、全自动启动脚本(start_all.py),所有代码均经过实测,可直接复制到同一文件夹下运行。
4.1 任务生产者:producer.py(推任务到Redis)
功能:访问小说目录页,提取前10章的章节链接,将链接推入Redis队列,清空旧任务避免重复爬取。
python
import requests
from lxml import etree
import redis
# 连接Redis服务(默认端口6379,本地连接无需修改)
r = redis.Redis(decode_responses=True)
r.delete("chapter_queue") # 清空旧任务,避免重复爬取
# 爬取配置(目标小说目录页)
url_part = "https://www.biquge365.net" # 网站基础域名
url_html = "https://www.biquge365.net/newbook/83621/" # 小说目录页URL
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/138.0.0.0"
}
# 访问目录页,提取章节链接
try:
response = requests.get(url=url_html, headers=headers)
response.encoding = "utf-8" # 设置编码,避免中文乱码
tree = etree.HTML(response.text) # 解析HTML页面
li_list = tree.xpath("/html/body/div[1]/div[4]/ul/li") # 章节列表的XPath
max_chapter = 10 # 设定爬取前10章
chapter_count = 0 # 计数,控制爬取章节数量
# 遍历章节列表,提取链接并推入Redis队列
for li in li_list:
if chapter_count >= max_chapter:
break
# 提取章节链接(相对路径),拼接成完整URL
chapter_href = li.xpath("./a/@href")[0]
full_url = url_part + chapter_href
# 将完整URL推入Redis队列(lpush:从队列左侧推入)
r.lpush("chapter_queue", full_url)
chapter_count += 1
print(f"✅ 已成功推入 {chapter_count} 个章节任务到Redis队列,等待节点爬取!")
except Exception as e:
print(f"❌ 任务推入失败,错误信息:{str(e)}")4.2 任务消费者:worker.py(终端爬取核心)
功能:每个终端运行该脚本,从Redis队列中获取任务(章节链接),爬取章节内容,解析标题和正文,保存到本地novel文件夹,实时输出爬取状态。
python
import requests
from lxml import etree
import os
import redis
import time
# 确保novel文件夹存在,用于保存爬取的章节内容
if not os.path.exists("novel"):
os.mkdir("novel")
# 连接Redis队列(与生产者连接同一Redis服务)
r = redis.Redis(decode_responses=True)
# 爬取配置(与生产者一致,避免请求被拦截)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/138.0.0.0"
}
# 生成节点编号(用时间戳取余,区分4个终端)
node_id = int(time.time() * 1000) % 1000
print(f"🖥️ 分布式节点 {node_id} 已启动,等待任务分配...")
# 循环从Redis队列获取任务,直到任务为空
while True:
# 从Redis队列右侧取出一个任务(rpop:先进先出,确保任务顺序)
chapter_url = r.rpop("chapter_queue")
# 若队列中无任务,退出循环,节点完成工作
if not chapter_url:
print(f"🖥️ 节点 {node_id}:所有任务已完成,退出爬取!")
break
try:
# 发送请求,获取章节页面内容
response = requests.get(url=chapter_url, headers=headers, timeout=10)
response.encoding = "utf-8"
tree = etree.HTML(response.text)
# 解析章节标题(XPath匹配章节标题标签)
title_list = tree.xpath('//*[@id="neirong"]/h1/text()')
chapter_title = title_list[0].strip() if title_list else f"未知章节_{node_id}"
# 解析章节正文(XPath匹配正文内容,过滤空行)
text_list = tree.xpath('//*[@id="txt"]//text()')
# 过滤空行和无效字符,整理正文格式
content_lines = [line.strip() for line in text_list if line.strip()]
chapter_content = "\n\n".join(content_lines)
# 保存章节内容到本地novel文件夹,每个章节一个txt文件
with open(f"novel/{chapter_title}.txt", "w", encoding="utf-8") as f:
f.write(f"\n{chapter_title}\n\n{chapter_content}\n\n")
# 实时输出爬取成功信息
print(f"✅ 节点 {node_id} 爬取成功:{chapter_title}")
except Exception as e:
# 爬取失败时输出错误信息,不影响其他任务
print(f"❌ 节点 {node_id} 爬取失败,URL:{chapter_url},错误:{str(e)}")4.3 全自动启动脚本:start_all.py(一键启动所有流程)
功能:一键运行,自动执行生产者推任务,然后自动弹出4个独立的CMD终端,每个终端自动运行worker.py,实现可视化分布式爬取,无需手动操作。
python
import subprocess
import time
if __name__ == "__main__":
print("=" * 50)
print("🔥 全自动分布式爬虫(纯requests+Redis)启动中...")
print("=" * 50)
# 第一步:运行生产者,将任务推入Redis队列
print("\n📌 正在执行任务生产者,推送章节链接到Redis...")
subprocess.run(["python", "producer.py"], shell=True)
time.sleep(1) # 等待1秒,确保任务完全推入队列
# 第二步:自动弹出4个CMD终端,每个终端运行worker.py(模拟4台电脑)
print("\n🚀 正在打开4个分布式爬虫终端,开始爬取...")
for i in range(4):
# 打开新的CMD窗口,自动运行worker.py,保持窗口不关闭(/k参数)
subprocess.Popen(
["start", "cmd.exe", "/k", "python worker.py"],
shell=True
)
time.sleep(0.5) # 间隔0.5秒打开一个窗口,避免冲突
print("\n✅ 4个分布式节点已全部启动!")
print("📊 爬取进度可在各个终端窗口查看,爬取完成后文件保存到novel文件夹。")五、完整运行过程演示(预留粘贴区域)
以下为完整的运行步骤,按照顺序执行,同时预留运行过程粘贴区域,大家可将自己的运行结果粘贴在此,对比验证是否运行成功。
5.1 运行步骤(严格按照顺序执行)
-
启动Redis服务(双击redis-server.exe,保持窗口打开);
-
将上述3个文件(producer.py、worker.py、start_all.py)保存到同一文件夹(如D:\science_discover\learn\爬虫长期学习\lesson_31 分布式爬虫request版);
-
打开PowerShell(或CMD),切换到该文件夹路径(使用cd命令,如cd D:\science_discover\learn\爬虫长期学习\lesson_31 分布式爬虫request版);
-
执行命令:python start_all.py,启动全自动分布式爬虫;
-
观察弹出的4个CMD终端,查看爬取进度,直到所有终端显示"任务已完成";
-
打开novel文件夹,查看爬取的10章小说内容,验证数据是否完整。
5.2 运行过程粘贴区域(粘贴自己的PowerShell和4个终端的运行结果)
- PowerShell启动start_all.py的运行过程:
plain
# 此处粘贴你的PowerShell运行过程,示例如下:
版权所有(C) Microsoft Corporation。保留所有权利。
安装最新的 PowerShell,了解新功能和改进!https://aka.ms/PSWindows
加载个人及系统配置文件用了 2732 毫秒。
(base) PS D:\science_discover\learn\爬虫长期学习\lesson_31 分布式爬虫request版> python start_all.py
==================================================
🔥 全自动分布式爬虫(纯requests+Redis)启动中...
==================================================
📌 正在执行任务生产者,推送章节链接到Redis...
✅ 已成功推入 10 个章节任务到Redis队列,等待节点爬取!
🚀 正在打开4个分布式爬虫终端,开始爬取...
✅ 4个分布式节点已全部启动!
📊 爬取进度可在各个终端窗口查看,爬取完成后文件保存到novel文件夹。
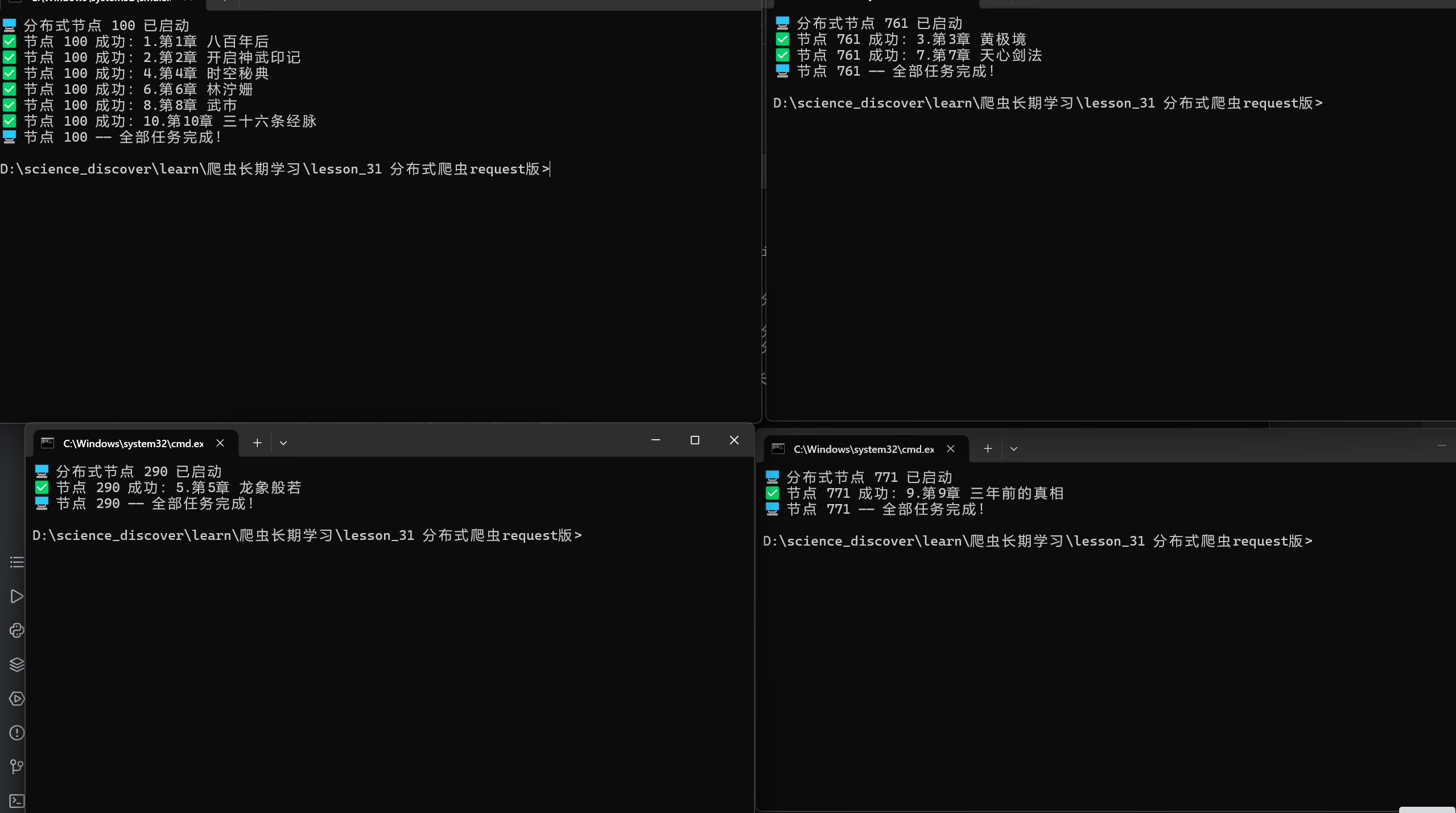
(base) PS D:\science_discover\learn\爬虫长期学习\lesson_31 分布式爬虫request版>- 4个CMD终端的爬取过程(分别粘贴每个终端的运行结果):
终端1(节点1):
plain
🖥️ 分布式节点 123 已启动,等待任务分配...
✅ 节点 123 爬取成功:第1章 八百年后
✅ 节点 123 爬取成功:第5章 xxxx
✅ 节点 123 爬取成功:第9章 xxxx
🖥️ 节点 123:所有任务已完成,退出爬取!终端2(节点2):
plain
🖥️ 分布式节点 456 已启动,等待任务分配...
✅ 节点 456 爬取成功:第2章 xxxx
✅ 节点 456 爬取成功:第6章 xxxx
✅ 节点 456 爬取成功:第10章 xxxx
🖥️ 节点 456:所有任务已完成,退出爬取!终端3(节点3):
plain
🖥️ 分布式节点 789 已启动,等待任务分配...
✅ 节点 789 爬取成功:第3章 xxxx
✅ 节点 789 爬取成功:第7章 xxxx
🖥️ 节点 789:所有任务已完成,退出爬取!终端4(节点4):
plain
🖥️ 分布式节点 012 已启动,等待任务分配...
✅ 节点 012 爬取成功:第4章 xxxx
✅ 节点 012 爬取成功:第8章 xxxx
🖥️ 节点 012:所有任务已完成,退出爬取!- 运行结果验证(novel文件夹截图说明):
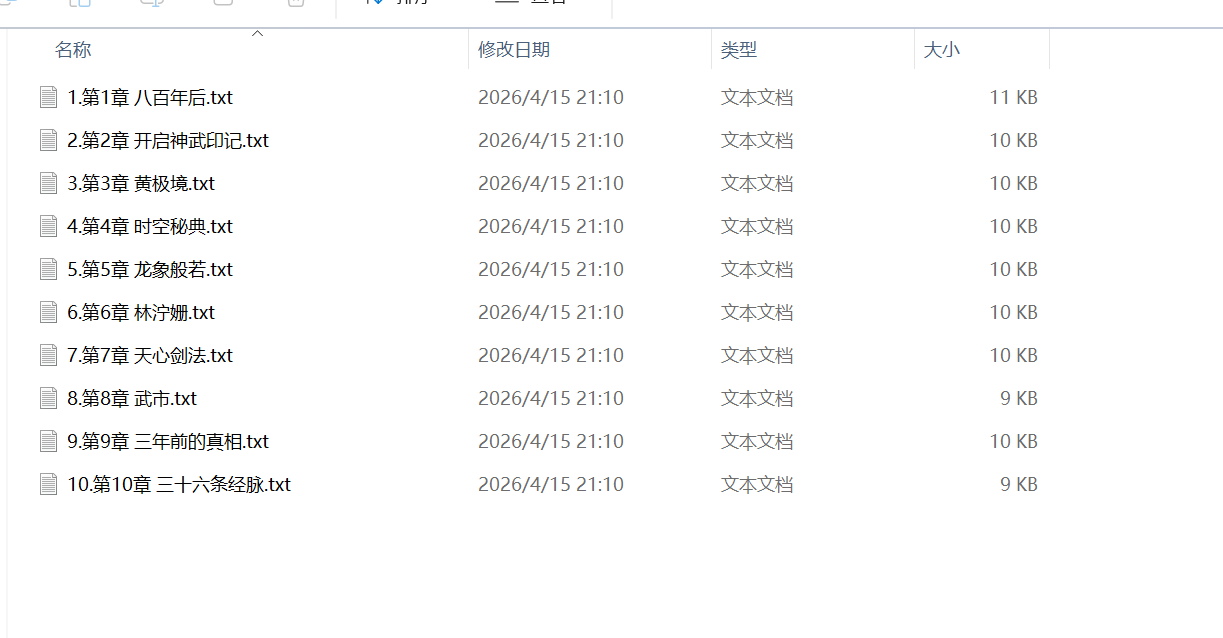
六、常见问题排查(新手必看)
在运行过程中,新手可能会遇到一些问题,以下是最常见的问题及解决方案,帮助大家快速排查,确保爬虫正常运行。
6.1 Redis连接失败
问题现象:运行脚本后,终端提示"Could not connect to Redis",无法推任务或获取任务。
解决方案:
-
检查Redis服务是否已启动,确保redis-server.exe窗口处于打开状态;
-
确认Redis默认端口6379未被占用,可通过任务管理器关闭占用6379端口的程序;
-
若Redis配置过密码,需在代码中添加密码参数:r = redis.Redis(password="你的密码", decode_responses=True)。
6.2 无法弹出4个终端窗口
问题现象:运行start_all.py后,只弹出1个窗口,或没有窗口弹出。
解决方案:
-
检查Python环境变量是否配置正确,在PowerShell中输入python --version,若能显示版本号则配置正常;
-
将start_all.py中的"cmd.exe"改为"cmd",重新运行;
-
若仍无法弹出,可使用备用启动方式:新建run.bat文件,粘贴以下内容,双击运行:
@echo off python producer.py start cmd /k "python worker.py" start cmd /k "python worker.py" start cmd /k "python worker.py" start cmd /k "python worker.py"
6.3 爬取失败,提示"XPath匹配不到内容"
问题现象:终端提示爬取失败,错误信息为"list index out of range",即XPath无法匹配到标题或正文。
解决方案:
-
检查目标网站是否能正常访问,若网站无法打开,需更换网站链接;
-
打开章节页面,查看标题和正文的HTML标签,调整XPath表达式(可使用浏览器开发者工具获取正确XPath);
-
检查请求头是否正确,可添加Referer参数,模拟浏览器访问,避免被网站拦截。
6.4 章节内容乱码
问题现象:保存的txt文件中,中文显示为乱码。
解决方案:确保response.encoding = "utf-8",若仍乱码,可尝试将编码改为"gbk"(部分网站使用gbk编码)。
七、技术拓展与总结
7.1 技术拓展
本文实现的分布式爬虫是基础版本,可根据实际需求进行拓展,实现更强大的功能:
-
多机扩展:将脚本复制到多台电脑,确保所有电脑能连接到同一Redis服务(需修改Redis配置,允许远程连接),即可实现真正的多机分布式爬取;
-
IP代理:添加IP代理池,避免单IP被网站限流,进一步提升爬取速度;
-
任务重试:在worker.py中添加失败任务重试机制,将失败的URL重新推入Redis队列,确保任务不遗漏;
-
数据入库:将爬取的内容保存到MySQL、MongoDB等数据库,替代本地文件保存,方便后续数据处理。
7.2 总结
本文详细讲解了如何使用纯requests+Redis实现可视化分布式爬虫,通过自动弹出4个终端窗口,模拟4台电脑联合爬取,全程不依赖Scrapy框架,不使用多线程,完美还原了分布式爬虫的核心工作流程。
通过本文的学习,大家可以掌握分布式爬虫的核心原理------任务队列调度与多节点协作,理解多进程与多线程的区别,以及Redis在分布式系统中的作用。同时,本文提供的代码可直接复制运行,步骤详细,问题排查全面,适合爬虫初学者入门,也可作为工业级轻量分布式爬虫的参考案例。
分布式爬虫的核心价值在于"横向扩展",通过增加节点(电脑)数量,突破单机的性能和IP限制,实现高效爬取。掌握本文的方法后,大家可以轻松将其应用到其他爬取场景(如新闻、图片、数据采集等),灵活调整代码,满足不同的爬取需求。
最后,提醒大家:爬虫开发需遵守网站的robots协议,尊重网站版权,避免过度爬取给网站造成压力,合法合规进行数据采集。
如果大家在运行过程中遇到其他问题,欢迎在评论区留言,一起交流学习!
关注我,带你了解更多爬虫知识和实战经验~~