DPO (Direct Preference Optimization , 直接偏好优化) 是大模型对齐(Alignment)领域的一场**"暴力美学"革命** 。
正如我们在上一个话题结尾留下的悬念,如果说传统的 RLHF 是一套极其复杂、昂贵且精密的"造星流水线",那么 DPO 就是直接跳过中间商,用最简单粗暴的方式让 大模型 "长记性"。
在 2023 年由斯坦福大学的研究人员提出后,DPO 迅速风靡了整个 AI 界。现在的开源王者(如 Llama 3、Qwen、DeepSeek)在最后一步对齐时,几乎全都重度依赖 DPO 及其变种。
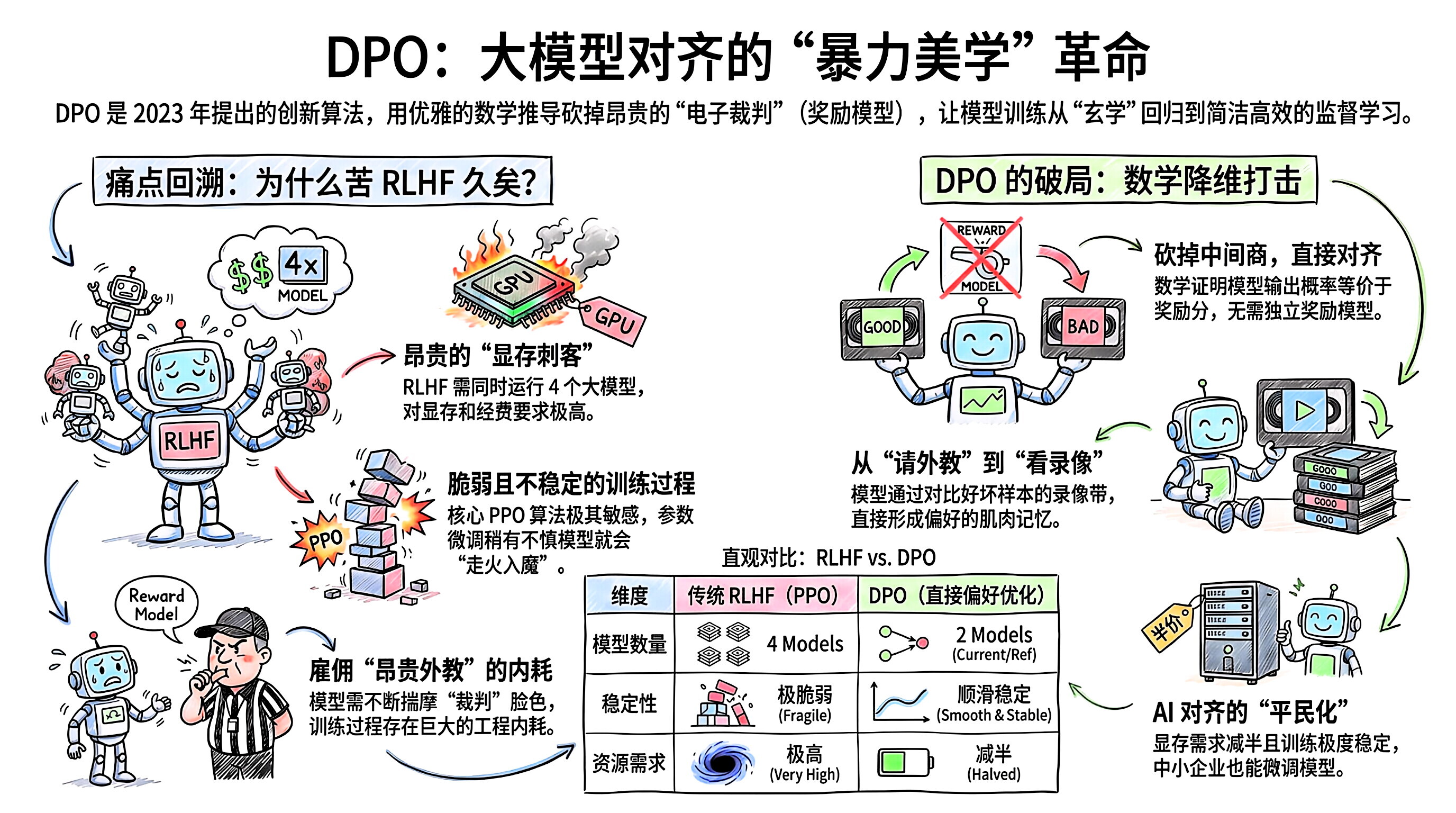
1.🛑 核心痛点:为什么大家苦 RLHF 久矣?
我们在上一条聊过,RLHF (基于人类反馈的强化学习) 的效果虽然好,但它的工程实现极其反人类。
-
太吃 内存 ( 显存 刺客) :在跑 RLHF 的核心算法 (PPO) 时,你的显卡里实际上要同时塞进 4 个 大模型:
-
正在训练的主模型 (Actor)
-
电子裁判 (Reward Model)
-
价值模型 (Critic)
-
原始参考模型 (Reference Model)
-
这简直是在燃烧显卡和经费。
-
-
太容易崩溃:PPO 算法出了名的脆弱和不稳定,参数稍微没调好,模型就会"走火入魔"(比如学会了前文提到的"作弊刷分")。
2.💡 斯坦福的天才破局:数学上的"降维打击"
DPO 的提出者做了一件极其硬核的事:他们通过一顿复杂的数学推导证明了------我们根本不需要那个单独的"电子裁判 (Reward Model)"!
他们发现,语言模型本身的输出概率(它想说某句话的强烈程度),在数学上完全等价于奖励分数。
用极其简化的逻辑来说:
-
RLHF 的思路:人类数据 -> 训练裁判 RM -> RM 给主模型打分 -> 主模型调整自己。
-
DPO 的思路 :既然主模型的终极目标就是讨好裁判,那我们可以通过一个精妙的数学公式,把"裁判"这个中间变量直接消元(划掉)。
📐 DPO 的核心公式 (展现其优美的数学本质)
在 DPO 中,我们只需要优化下面这个损失函数:
\\mathcal{L}_{\\text{DPO}} = -\\log \\sigma \\left( \\beta \\log \\frac{\\pi_\\theta(y_w \\mid x)}{\\pi_{\\text{ref}}(y_w \\mid x)} - \\beta \\log \\frac{\\pi_\\theta(y_l \\mid x)}{\\pi_{\\text{ref}}(y_l \\mid x)} \\right)
这里 \pi_\theta 是正在训练的模型,\pi_{\text{ref}} 是参考模型,y_w 是好回答,y_l 是坏回答。
公式翻译成大白话就是:
当面对同一个问题时,模型如果提高了"好回答 (y_w)"的生成概率,并且同时压低了"坏回答 (y_l)"的生成概率,它的总损失就会变小(表现变好)。
3.🏟️ 形象比喻:请外教 vs. 看录像带
-
RLHF (请外教打分):
-
球员(大模型)在场上打球。
-
俱乐部花重金请了一个极其严厉的教练(Reward Model)坐在场边打分。
-
球员一边打球,一边还得看教练的脸色,猜教练到底喜欢什么动作,极其内耗。
-
-
DPO (看录像带复盘):
-
教练被开除了(省钱了)。
-
每天训练结束,直接给球员看两段录像带(偏好数据)。
-
录像 A 是好球,录像 B 是烂球。
-
告诉球员:"不用管为什么,以后多打 A 这种球,绝对不要打 B 这种球。"
-
球员直接在大脑里形成了肌肉记忆。
-
4.🚀 DPO 带来的工业界地震
DPO 最大的贡献是实现了 AI 对齐的"平民化"。
-
极其轻量:因为砍掉了 Reward Model 和复杂的强化学习环境,训练 DPO 的显存需求直接减半,很多中小企业和学术界终于也能自己微调模型的三观了。
-
极其稳定:它本质上退化成了一个类似于分类任务的标准监督学习,训练过程像丝一样顺滑,再也不用半夜定闹钟起来看 PPO 算法有没有崩盘。
-
效果拔群:在绝大多数实际测试中,DPO 调出来的模型,说话的语气、遵循指令的能力,不仅不输给 RLHF,甚至在避免"AI 爹味(过度说教)"上表现得更好。
总结
DPO (直接偏好优化) 是目前大模型训练管线中最锋利的一把手术刀。
它用最优雅的数学推导,斩断了 RLHF 臃肿的工程枷锁,让模型能够通过极其简单直接的方式,吸收人类的偏好和价值观。如果说大模型是跑车,SFT 是方向盘,那么 DPO 就是让这辆跑车永远不会偏离车道的顶级 四轮定位 系统。