一、实验目的
利用正则文法理解单词结构,并将正则文法转换为状态转换图,开展指定高级程序设计语言(如C语言)的词法分析设计及实现;通过将正则文法。能够正确掌握词法分析的技术原理及方法,针对C语言的不同单词,开展单词识别模型设计及词法分析处理。
自主查阅参考资料,结合教材3.4节,利用高级程序设计语言(编码语言不限制,如C/C++/Python等)开展词法分析器设计及编码实践,输出实验结果,解释实验和理论分析结果差异;撰写实验报告。
二、实验环境(仪器设备、软件等)
1、机房电脑 Window10
2、Dev-C++/ Eclipse等
三、实验原理
( 1 )待识别的 C 语言单词类型
在C语言词法分析中,待识别的单词类型可分为基础类型和特殊类型 两大类。
基础类型如下:
1.关键字:如int, float, if, else, while, for, return, break, continue 等
2.标识符:变量/函数名如sum, calculate_score,用户自定义类型:typedef 定义的别名等。
3.常量:整型:42, 0x1A3F(十六进制);浮点型:3.14, 1.23e-5;字符型:'a'、'\n';字符串型:"Hello"
4.运算符:算术:+, -, *, /, %;关系:<, >, ==, !=, <=, >=;逻辑:&&, ||, !;位运算:&, |, ^, ~, <<, >>;复合赋值:+=, -=, *=, /=, %=
5.界符:分隔符:,, ;括号:( ), { },
( 2 )不同类型单词的正则文法,根据正则文法构造状态转换图
正则文法:
S→关键字|标识符|整数常量|浮点数常量|字符常量|字符串常量|运算符|分界符
<关键字>→ "auto" | "break" | "case" | ... | "while"
<标识符> → <letter>(<letter>|<digit>)*
<letter> → a-z A-Z
<digit> → 0-9
<整数常量> → (+|-)<digit>+
<浮点数常量> → <integer>.<digit>+
自主绘制的状态图如下:输出为 Token 二元组(单词符号种别/类型,属性值)的形式
( 3 )词法分析的实验内容及原理:
①词法分析器的核心功能
②词法分析器的输出形式(Token序列)
③正则文法描述C语言不同类型单词的单词结构,根据词法分析工作原理及不同单词结构差异,开展词法分析器设计及编码实践。
四、实验步骤
(1)开展实验所设计的种别码表为:(见文末链接)
|---|
| |
| |
(2)实验采用的C语言不同单词的正则文法及状态图为;
正则文法:
S→关键字|标识符|整数常量|浮点数常量|字符常量|字符串常量|运算符|分界符
<关键字>→ "auto" | "break" | "case" | ... | "while"
<标识符> → <letter>(<letter>|<digit>)*
<letter> → a-z A-Z
<digit> → 0-9
<整数常量> → (+|-)<digit>+
<浮点数常量> → <integer>.<digit>+
<字符常量> → '<character>'
<character> → 可打印ASCII字符 | <escape_sequence>
<escape_sequence> → \\nrt'"\\\\
<字符串常量> → "(<character>|<escape_sequence>)*"
<运算符> → "+" | "-" | "*" | "/" | "%" | "++" | "--" | ... | "?:"
<分界符> → "," | ";" | ":" | "." | "(" | ")" | "" \| "" | "{" | "}" | "#" | "\\"
自主绘制的状态图如下:输出为 Token 二元组(单词符号种别/类型,属性值)的形式(下一页)
(见文末链接)
(3)词法分析器主要函数、变量说明及算法流程图
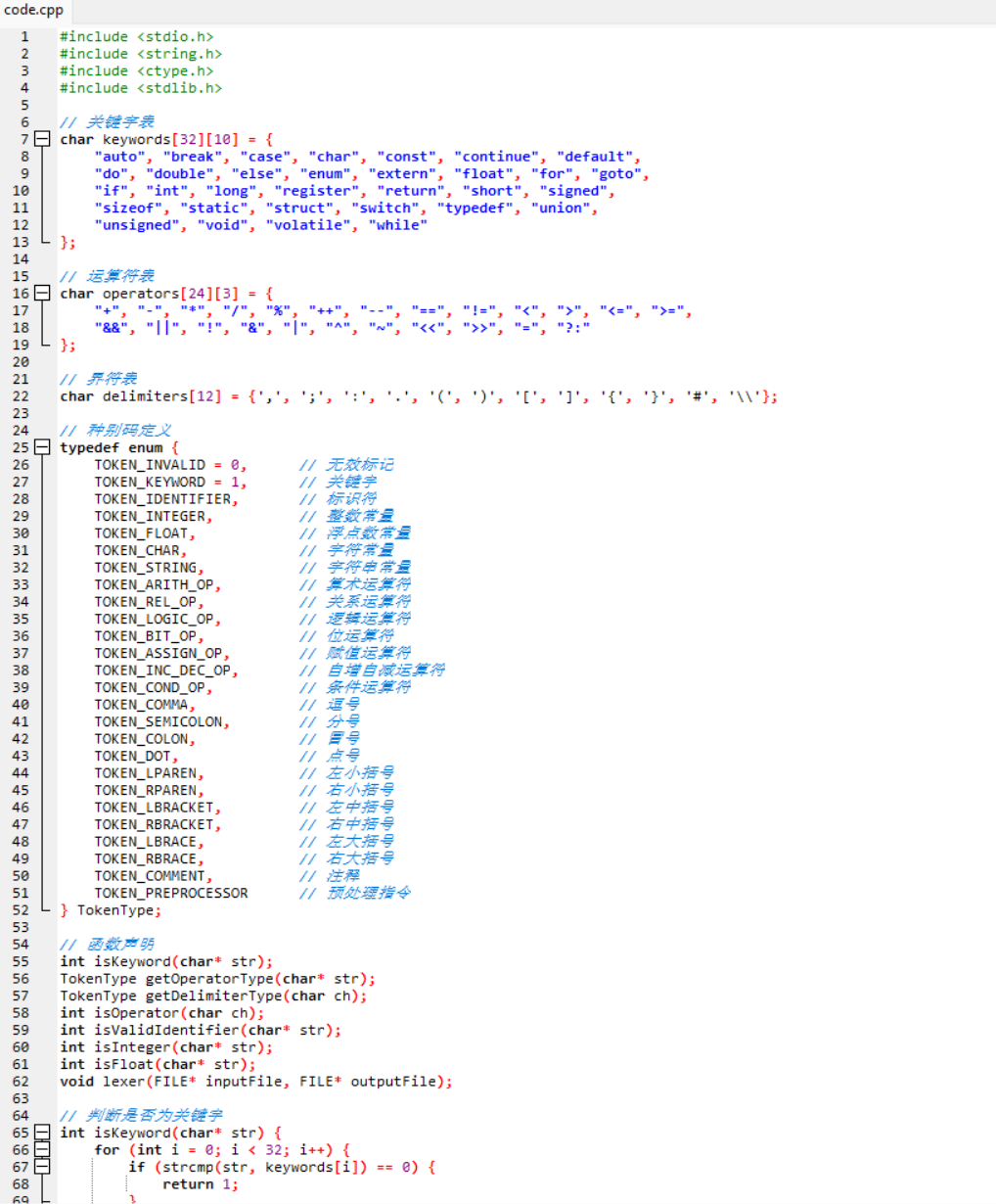
1.主要函数:
isKeyword(char*) 判断字符串是否为关键字(查keywords表)
isOperator(char) 判断字符是否为运算符起始字符(查operators表)
...
主分析函数:void lexer(FILE* input, FILE* output)
初始化缓冲区buffer和行号计数器line
2.变量说明
关键字表:char keywords3210 = { "auto", "break", ... };
存储C语言的32个关键字
运算符表char operators243 = { "+", "-", ... };
存储12个单字符界符
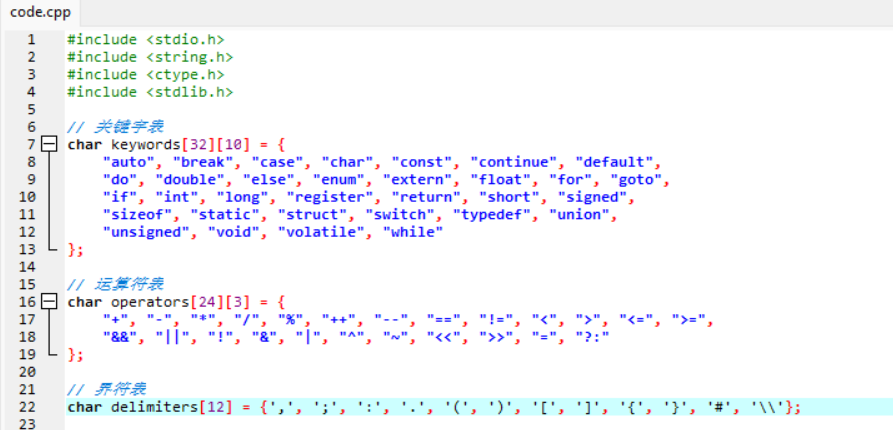
种别码枚举

代码的算法流程图如下所示:(见文末链接)
(4)词法分析器完整代码实现:(见文末链接)
代码从输入文件中逐个读取字符,根据字符类型进入不同的处理逻辑。对于空白字符直接跳过并记录行号;遇到注释则跳过整个注释内容;识别字符串和字符常量时处理转义字符;数字常量区分整数和浮点数;标识符需验证格式并区分是否为关键字;运算符需要处理多字符情况;界符直接匹配预定义表。所有识别出的词素都会附加上对应的种别码,按照"(种别码,词素内容)"的格式输出到结果文件。
五、记录与处理
用例1:
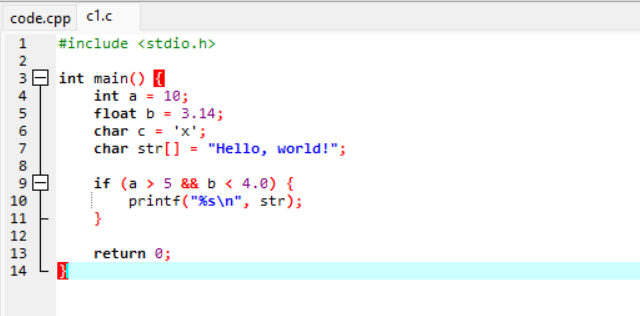
运行过程:
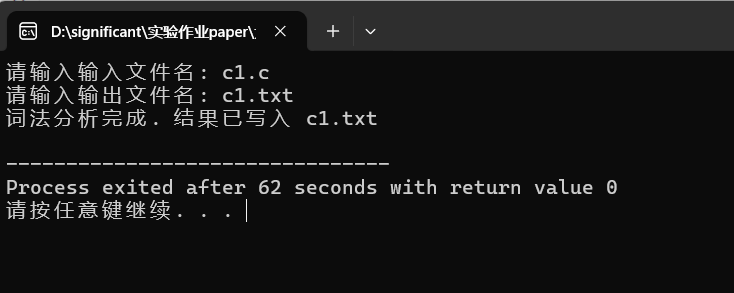
最终输出的txt文本结果:(见文末链接)
用例2:
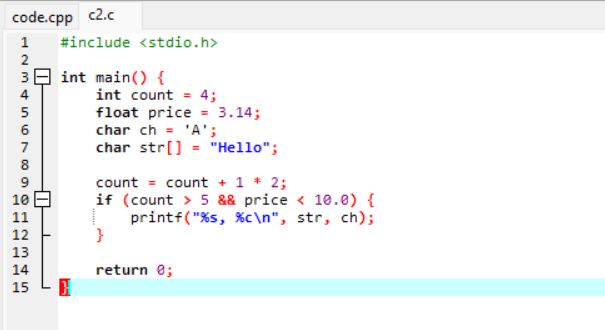
运行过程:
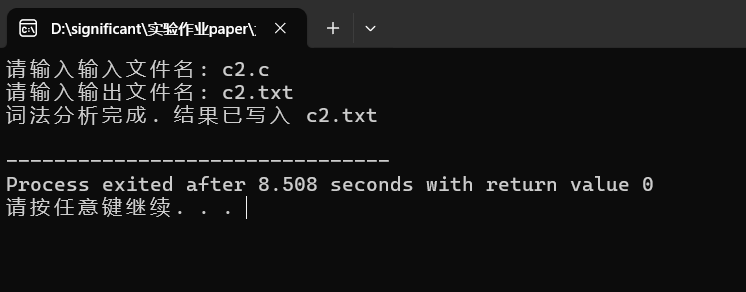
最终输出的txt文本结果:(见文末链接)
用例3:
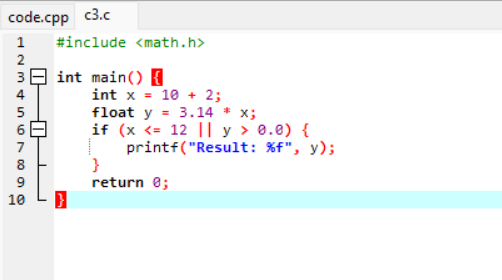
运行过程:
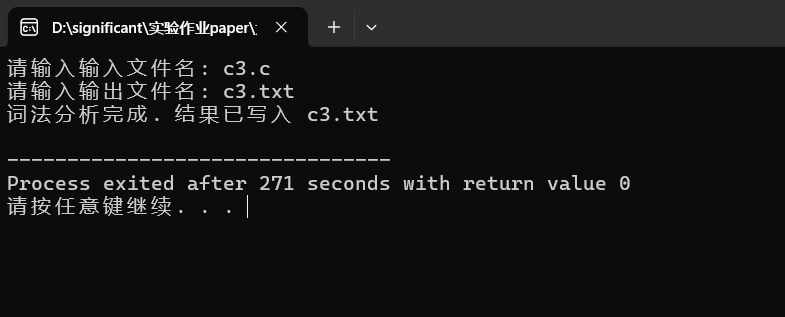
最终输出的结果:(见文末链接)
实际输出都与预期结果一致。
六、思考与总结
这次实验加深了我对词法分析部分的理解,掌握了利用正则文法进行单词结构描述及词法分析器设计的方法和步骤。我深刻体会到了正则文法在词法分析中的重要性,正则文法不仅能够帮助我们清晰地定义单词结构,还能够为词法分析提供系统的处理方法。
七、成果文件提取链接
通过网盘分享的文件:
链接: https://pan.baidu.com/s/1grJ6ohwR_svNbvH2pk5igg?pwd=mj2u 提取码: mj2u