arXiv:2205.08608v1 physics.optics 2022年5月17日
作者
Jasvith Raj Basani1,2^{1,2}1,2、Mikkel Heuck3,4^{3,4}3,4、Dirk R. Englund3^{3}3、Stefan Krastanov3^{3}3
1^11印度特伦甘纳邦海得拉巴校区,皮拉尼博拉理工学院,电气与电子工程系,500078
2^22美国马里兰大学帕克分校,电气与计算机工程系、电子与应用物理研究所、联合量子研究所,马里兰州20742
3^33美国马萨诸塞州剑桥市,麻省理工学院,电气工程与计算机科学系,马萨诸塞大道77号,02139
4^44丹麦技术大学,电气与光子工程系,343号楼,2800灵比
(日期:2022年5月19日)
摘要
光学与光子学作为加速线性矩阵处理的平台,近年来备受关注,而线性矩阵处理被认为是传统数字电子架构中的性能瓶颈。本文提出一种全光子人工神经网络处理器 ,该处理器将信息编码在充当神经元的频率模式振幅中,层间连接权重则编码在充当泵浦光的受控频率模式振幅中。通过非线性光学过程 实现模式间的信息处理交互,矩阵乘法与逐元素激活函数均通过相干过程完成,无需探测器或数字电子器件即可直接表示负数与复数。数值模拟表明,该设计在图像分类基准测试中,性能与当前主流计算网络相当。该架构的独特之处在于提供完全幺正、可逆的计算模式。此外,只要光路可承受更高光功率,计算速度可随泵浦光功率提升至任意高速。
一、引言
过去十年,机器学习领域取得显著进展,应用覆盖自然语言处理1^{1}1、结构生物学2^{2}2乃至博弈决策3^{3}3。随着大数据集与强算力的普及,机器学习模型复杂度持续提升,以应对各类问题。网络性能需求推动硬件加速器研发,尤其针对深度神经网络训练。近年来,专用数字电子架构(如图形处理器GPU4^{4}4、谷歌张量处理单元TPU5^{5}5、IBM TrueNorth6^{6}6、英特尔Nervana7^{7}7)相继问世,用于加速机器学习模型的训练与推理。但这类器件仍需消耗大量能源,处理高计算复杂度问题时成本高昂。
随着硅光子学技术进步8,9^{8,9}8,9,光计算成为大规模计算方案的理想平台。光的相干性、叠加性,结合大量CMOS兼容光学器件,使光子学成为高效实现计算方案的重要方向。
自由空间与光子集成电路中均已提出并实现光子神经网络,在脉冲神经网络10^{10}10与光子储备池计算11^{11}11领域取得突破。光子平台凭借光的多自由度(波长、偏振、相位等)提供的大规模并行性,受到科研与工程界广泛关注。
即使是最优电子架构,也面临数据移动能耗远高于逻辑运算 的问题12,13^{12,13}12,13。而光子方案通过无源光学相互作用完成线性(及部分非线性)变换,大幅降低数据传输与计算能耗。此外,线性矩阵变换速率已突破100 GHz14^{14}14,纳米光子学进步使体光学非线性易于实现且延迟极低。
神经网络的构建仅包含两个核心模块:层间线性矩阵乘法 、非线性(Sigmoid)激活函数 。本文基于非线性光学互调 ,提出一种全新的全光人工神经网络架构。与现有方案15--19^{15--19}15--19不同,本文将信息编码在多模腔中充当神经元的频率态复振幅中,神经元模式的线性变换信息则编码在受控泵浦模式振幅中。
通过**四波混频(FWM)**过程20^{20}20实现通用矩阵--向量与矩阵--矩阵乘法,该过程已广泛用于多频率模式间的互调21^{21}21。该方法可表示负数(甚至复数)激活值,解决了其他光学方案的固有难题。
与其他光学22--25^{22--25}22--25和光电混合26--30^{26--30}26--30方案不同,本文提出通过非线性光学过程相干实现逐元素Sigmoid激活函数,无需经过探测器与电子数字计算机,即可处理负数与复数激活值。
该设计具备快速可编程 特性,可基于微环谐振器实现,依托成熟光刻技术易于制备。此外,该硬件执行的全部计算原则上可逆且幺正,为低功耗(甚至可逆)计算与训练开辟新路径。最后,矩阵乘法运算速率与泵浦光功率成正比,只要光路耐受高功率控制脉冲,即可实现超高速运算。
本文结构如下:第二部分介绍两种矩阵乘法方案,即多模光腔中"神经元"脉冲的被动耦合 与主动耦合 方法,讨论光腔的哈密顿量与矩阵变换,建立神经元模式的时间动力学,分析运算局限性及解决方法,并在鸢尾花线性可分数据集31^{31}31上完成基准测试。第三部分阐述非线性激活函数的实现。第四部分在MNIST数据集32^{32}32上训练神经网络加速器,模拟验证不同参数下硬件设计的性能。最后总结结果、应用前景与实验实现方向。
二、基于四波混频的可编程变换
深度神经网络(DNN)本质上由多层神经元堆叠而成,每层依次执行矩阵乘法 (x⃗↦Wx⃗\vec{x}\mapsto W\vec{x}x ↦Wx )与逐元素非线性激活函数 (xi↦σ(xi)x_i\mapsto\sigma(x_i)xi↦σ(xi))。对于任意深度的DNN,第k+1k+1k+1层输入与第kkk层输入的关系为:
xi(k+1)=σ(∑jWi,j(k)xj(k))x_i^{(k+1)}=\sigma\left(\sum_j W_{i,j}^{(k)}x_j^{(k)}\right)xi(k+1)=σ(j∑Wi,j(k)xj(k))
本文提出在多模光腔 中实现W(k)W^{(k)}W(k)矩阵乘法。例如,采用支持通信波段(约1550 nm)光频梳的微环谐振器作为光腔,将其支持的频率态选为泵浦模式 或神经元模式,通过四波混频(FWM)实现模式间相互作用。
设计将待处理信息编码在神经元模式的复振幅 中,矩阵乘法运算通过与受控泵浦模式的相互作用实现。由于FWM是三阶非线性光学过程,微环谐振器需采用具备大三阶非线性极化率χ(3)\chi^{(3)}χ(3)的材料制备。在传统全连接神经网络中,层间连接权重编码在泵浦光强度中。
A. 被动耦合方法
第一种全连接神经网络层实现方案,采用传播的神经元脉冲穿过微环谐振器(如图1所示),脉冲混合由谐振器中控制泵浦光的FWM相互作用驱动。
以仅包含4个模式的谐振器为例:两个低频模式为驱动系统的泵浦模式,用算符(p^1,p^2)(\hat{p}_1,\hat{p}_2)(p^1,p^2)表示;两个高频模式为神经元模式,用算符(a^1,a^2)(\hat{a}_1,\hat{a}_2)(a^1,a^2)表示。四波相互作用的哈密顿量为:
H^=ℏχ(p^1p^2†a^1a^2†)+H.c.(2)\hat{H}=\hbar\chi\left(\hat{p}_1\hat{p}_2^\dagger\hat{a}_1\hat{a}_2^\dagger\right)+H.c. \tag{2}H^=ℏχ(p^1p^2†a^1a^2†)+H.c.(2)
耦合系数χ\chiχ决定相互作用强度,包含腔材料非线性极化率、相位匹配、模式体积等参数影响。假设泵浦为强经典光模式,算符可替换为经典复振幅p^i↦pi=<n^i>eiθ\hat{p}i\mapsto p_i=\sqrt{<\hat{n}i>}e^{i\theta}p^i↦pi=<n^i> eiθ,其中nin_ini为泵浦模式平均光子数,θ\thetaθ为相位。泵浦光远强于其他模式,因此非耗尽 。假设模式共振满足FWM能量匹配条件:ωp2−ωp1=ωa2−ωa1\omega{p_2}-\omega{p_1}=\omega_{a_2}-\omega_{a_1}ωp2−ωp1=ωa2−ωa1。
神经元与泵浦模式以固定耦合速率γ\gammaγ从波导耦合进微环谐振器,总损耗率Γ=γ+γH\Gamma=\gamma+\gamma_HΓ=γ+γH,γH\gamma_HγH为腔内固有损耗率。采用耦合模理论 求解模式时间动力学,系统耦合振幅方程33,34^{33,34}33,34为:
P˙i=0=−Γ2Pi−γSin,Pi(3)\dot{P}i=0=-\frac{\Gamma}{2}P_i-\sqrt{\gamma}S{in,P_i} \tag{3}P˙i=0=−2ΓPi−γ Sin,Pi(3)
dA1dt=(−Γ2+iχ∣P1∣2+iχ∣P2∣2)A1+(χP1P2∗)A2−γSin,1(4)\begin{aligned}\frac{dA_1}{dt}=&\left(-\frac{\Gamma}{2}+i\chi\left|P_1\right|^2+i\chi\left|P_2\right|^2\right)A_1\\&+\left(\chi P_1P_2^*\right)A_2-\sqrt{\gamma}S_{in,1} \tag{4}\end{aligned}dtdA1=(−2Γ+iχ∣P1∣2+iχ∣P2∣2)A1+(χP1P2∗)A2−γ Sin,1(4)
dA2dt=(−Γ2+iχ∣P1∣2+iχ∣P2∣2)A2−(χP1∗P2)A1−γSin,2(5)\begin{aligned}\frac{dA_2}{dt}=&\left(-\frac{\Gamma}{2}+i\chi\left|P_1\right|^2+i\chi\left|P_2\right|^2\right)A_2\\&-\left(\chi P_1^*P_2\right)A_1-\sqrt{\gamma}S_{in,2} \tag{5}\end{aligned}dtdA2=(−2Γ+iχ∣P1∣2+iχ∣P2∣2)A2−(χP1∗P2)A1−γ Sin,2(5)
Sout,i=Sin,i+γAi(6)S_{out,i}=S_{in,i}+\sqrt{\gamma}A_i \tag{6}Sout,i=Sin,i+γ Ai(6)
其中AiA_iAi与PiP_iPi分别为谐振器内第iii个神经元模式与泵浦模式的振幅。泵浦振幅远高于神经元激活幅度,可忽略神经元间直接相互作用。编码数据通过输入波导模式Sin,iS_{in,i}Sin,i(神经元激活值)注入系统,环内相互作用后的输出神经元模式为Sout,iS_{out,i}Sout,i。
泵浦模式间纯非线性相互作用需对PiP_iPi值修正,但这是简单矩阵求逆问题,不影响下文动力学分析。
将该形式推广至包含NNN个神经元的单层网络,第nnn近邻泵浦(频率差为n×ΩFSRn\times\Omega_{FSR}n×ΩFSR,ΩFSR\Omega_{FSR}ΩFSR为环自由光谱范围)会耦合所有对应频率差的神经元模式,产生交叉耦合项。第iii个神经元模式的修正耦合振幅方程为:
dAidt=(−Γ2+iχ∑m=1N∣Pm∣2)Ai−χ∑j\>iN∑k=1j−1(PkPk+j−i∗)Aj−∑j\
不失一般性,假设第一个泵浦P1P_1P1远强于其他泵浦,简化实验标定并忽略交叉耦合项,得:
dAidt=(−Γ2+iχ∣P1∣2)Ai−χ∑j\>iN(P1Pj∗)Aj−∑j\
结合式(6),可将耦合模方程组改写为矩阵形式:
S⃗out=S⃗in+γP−1(A⃗+γS⃗in)(9)\vec{S}{out}=\vec{S}{in}+\sqrt{\gamma}\leftP\^{-1}\\left(\\vec{A}+\\sqrt{\\gamma}\\vec{S}_{in}\\right)\\right \tag{9}S out=S in+γ P−1(A +γ S in)(9)
其中矩阵PPP为常对角矩阵(Toeplitz矩阵) ,第nnn个非对角线元素值为P1PnP_1P_nP1Pn。该模型表明,输出模式振幅取决于矩阵PPP的逆,即编码线性运算的泵浦振幅。
深度神经网络通常包含多层,本文通过级联多个微环谐振器实现。为重复执行该变换,需保证脉冲经FWM变换时时域包络无显著变化 。假设SinS_{in}Sin脉冲为高斯时域包络,若脉冲宽度远大于1/γ1/\gamma1/γ,则输出脉冲SoutS_{out}Sout可保持高斯形状。
当脉冲宽度足够大时,可采用绝热近似 A⃗˙=0\dot{\vec{A}}=0A ˙=0,进入稳态工作区。图2对比稳态模型与全动力学模型的解,输入脉冲越长,稳态模型与全动力学模型越接近。该近似将式(9)简化为:
S⃗out=(IN+γP−1)S⃗in=TS⃗in\vec{S}{out}=(\mathbb{I}N+\gamma P^{-1})\vec{S}{in}=T\vec{S}{in}S out=(IN+γP−1)S in=TS in
其中TTT见式(10),IN\mathbb{I}_NIN为NNN维单位矩阵。
T=IN+γP−1=IN+γ(−Γ/2+iχ∣P1∣2P1P2∗χP1P2∗χP1P3∗χ...P1PN∗χ−P1∗P2χ−Γ/2+iχ∣P1∣2P1P2∗χ...P1PN−1∗χ−P1∗P3χ−P1∗P2χ−Γ/2+iχ∣P1∣2⋱...P1PN−2∗χ⋮⋱⋱⋱⋮⋮⋱⋱⋮−P1∗PN−1χ...−P1∗P2χ−Γ/2+iχ∣P1∣2P1P2∗χ−P1∗PNχ...−P1∗P3χ−P1∗P2χ−Γ/2+iχ∣P1∣2)(10)\begin{aligned}T=&\mathbb{I}N+\gamma P^{-1}\\=&\mathbb{I}N+\gamma\begin{pmatrix}-\Gamma/2+i\chi\left|P_1\right|^2&P_1P_2^*\chi&P_1P_2^*\chi&P_1P_3^*\chi&\dots&P_1P_N^*\chi\\-P_1^*P_2\chi&-\Gamma/2+i\chi\left|P_1\right|^2&P_1P_2^*\chi&\dots&P_1P{N-1}^*\chi\\-P_1^*P_3\chi&-P_1^*P_2\chi&-\Gamma/2+i\chi\left|P_1\right|^2&\ddots&\dots&P_1P{N-2}^*\chi\\\vdots&\ddots&\ddots&\ddots&\vdots\\\vdots&&\ddots&\ddots&&\vdots\\-P_1^*P_{N-1}\chi&\dots&&-P_1^*P_2\chi&-\Gamma/2+i\chi\left|P_1\right|^2&P_1P_2^*\chi\\-P_1^*P_N\chi&\dots&&-P_1^*P_3\chi&-P_1^*P_2\chi&-\Gamma/2+i\chi\left|P_1\right|^2\end{pmatrix}\end{aligned} \tag{10}T==IN+γP−1IN+γ −Γ/2+iχ∣P1∣2−P1∗P2χ−P1∗P3χ⋮⋮−P1∗PN−1χ−P1∗PNχP1P2∗χ−Γ/2+iχ∣P1∣2−P1∗P2χ⋱......P1P2∗χP1P2∗χ−Γ/2+iχ∣P1∣2⋱⋱P1P3∗χ...⋱⋱⋱−P1∗P2χ−P1∗P3χ...P1PN−1∗χ...⋮−Γ/2+iχ∣P1∣2−P1∗P2χP1PN∗χP1PN−2∗χ⋮P1P2∗χ−Γ/2+iχ∣P1∣2 (10)
N×NN\times NN×N矩阵PPP的Toeplitz特性仅提供NNN个自由度,远低于全连接深度神经网络权重的N2N^2N2个自由度。这意味着单层TTT型变换仅能覆盖全幺正变换群的部分空间。
为量化该变换可覆盖的运算群,引入**表达能力(expressivity)**概念:表达能力为参数化矩阵TTT表示任意幺正运算UUU的平均保真度。数值上,通过采样MMM个哈尔随机幺正矩阵{Ui}1≤i≤M\{U_i\}{1\le i\le M}{Ui}1≤i≤M,对每个矩阵用梯度下降寻找最接近的TiT_iTi,表达能力定义为:
F=1−1M∑i=1Mtr(Ti−Ui)(Ti−Ui)†(11)\mathbb{F}=1-\frac{1}{M}\sum{i=1}^M\sqrt{tr\left\\left(T_i-U_i\\right)\\left(T_i-U_i\\right)\^\\dagger\\right} \tag{11}F=1−M1i=1∑Mtr(Ti−Ui)(Ti−Ui)† (11)
该指标同时考虑损耗(偏离幺正性)与自由度不足导致的缺陷。
单层(单TTT矩阵)变换的表达能力不足以执行任意幺正变换。因此引入子层 概念:单层由多个非对易级联TTT矩阵 组成,实现复合变换。物理上需多个级联微环谐振器,每个子层对应一个环。通过在单层内引入多个子层(级联多个TTT矩阵),可覆盖更大运算群。
图3为不同参数下被动耦合方案TTT变换的表达能力量化结果。每个图展示给定矩阵维度(纵轴)下,表达能力随子层数(横轴)的变化。左侧无腔内损耗(Γ/γ=1\Gamma/\gamma=1Γ/γ=1)时,子层数足够多则表达能力趋近于1;右侧高损耗(Γ/γ=5\Gamma/\gamma=5Γ/γ=5)时,表达能力始终偏低。
腔内损耗γH\gamma_HγH会降低表达能力。此前分析忽略固有损耗(γH=0\gamma_H=0γH=0),即Γ/γ=1\Gamma/\gamma=1Γ/γ=1。由式(10)可知,PPP矩阵对角线包含神经元模式总损耗率。图3右侧展示γH>0\gamma_H>0γH>0时的表达能力,即使子层数增多,表达能力仍无法达到1,损耗导致复合变换无法覆盖完整幺正运算群。
图4展示子层数与损耗比Γ/γ\Gamma/\gammaΓ/γ对鸢尾花数据集线性分类任务的整体影响。该数据集仅含4个特征、3个输出类别,其中一类与另外两类线性可分。神经网络架构为输入特征与预测类别间的单复合层,无逐元素Sigmoid激活。
结果表明:所有Γ/γ\Gamma/\gammaΓ/γ下,子层数越多(表达能力越强),分类精度越高;相同子层数下,损耗越高,网络性能越差。
TTT型变换也可通过三波混频 35^{35}35实现,仅需单个泵浦模式。求解变换矩阵TTT可得与上文相似结果(三波混频不产生不同神经元模式间的交叉耦合)。三波相互作用的哈密顿量为H^=χ(p^a^b^†)+H.c.\hat{H}=\chi(\hat{p}\hat{a}\hat{b}^\dagger)+H.c.H^=χ(p^a^b^†)+H.c.,其中p^\hat{p}p^为单泵浦模式,模式满足能量匹配条件ωp=ωb−ωa\omega_p=\omega_b-\omega_aωp=ωb−ωa。
该系统的实验实现面临微环谐振器设计难题:能量匹配条件要求泵浦模式频率等于神经元模式频率差,导致泵浦模式频率远低于神经元模式(即微环自由光谱范围FSR的整数倍)。该谐振器需支持跨多个倍频程的模式,不同频率模式的折射率与Q值存在差异,难以维持高效波混频所需的共振条件与相位匹配。
跨倍频程的泵浦与神经元模式也可通过电光频梳实现36^{36}36,但受限于跨大频带模式耦合的电子器件速度。
本节方案可构建可编程矩阵乘法运算,但要求脉冲为长宽度高斯包络,且单层需级联多个环以保证完整表达能力。脉冲在环内发生FWM后,依次穿过多个微环谐振器。
为克服这些限制,可将系列微环替换为单个环 ,主动捕获神经元并长时间存储以执行FWM运算。该架构可通过提升泵浦强度任意提高处理速度,即下文主动耦合方案,也是本文后续重点讨论的方案。
B. 主动耦合方法
本节提出电路尺寸更小 的架构:采用单个微环谐振器 ,替代上文线性增长的级联谐振器序列。神经元激活值仍编码在神经元频率态复振幅中,线性变换编码在泵浦模式振幅中。但神经元模式在整个FWM过程中被捕获并存储在谐振器内,而非穿过谐振器。
该主动耦合需谐振器与波导间具备可控耦合系数γ(t)\gamma(t)γ(t)。工作受限于谐振器Q值,存在神经元模式操作的最长时间(下文给出解决方法)。
本设计中泵浦模式随时间变化 ,以实现神经元模式的完整表达能力(即执行任意幺正运算)。数值实验中,将泵浦振幅简化为分段恒定 ,步长为Δt\Delta tΔt。
可控耦合γ(t)\gamma(t)γ(t)实现神经元模式主动耦合(如图8):捕获/释放时增大γ(t)\gamma(t)γ(t)以传输神经元模式;FWM过程中γ(t)\gamma(t)γ(t)设为最小值以避免信息丢失,此时Γ=γ+γH=γH\Gamma=\gamma+\gamma_H=\gamma_HΓ=γ+γH=γH。
相位匹配模式下,FWM过程的系统哈密顿量同式(2)。NNN个神经元模式的耦合振幅方程为:
P˙i(t)=0=−Γ2Pi(t)−γSin,P(t)(12)\dot{P}i(t)=0=-\frac{\Gamma}{2}P_i(t)-\sqrt{\gamma}S{in,P}(t) \tag{12}P˙i(t)=0=−2ΓPi(t)−γ Sin,P(t)(12)
dAidt=(−Γ2+iχ∣P1∣2)Ai−χ∑j\>iN(P1Pj∗)Aj−∑j\
用矩阵--向量运算表示,式(13)可写为A⃗˙=PA⃗\dot{\vec{A}}=P\vec{A}A ˙=PA ,其中PPP为式(10)的Toeplitz矩阵。PPP恒定的Δt\Delta tΔt周期内,系统解为:
A⃗(t=Δt)=eΔtPA⃗(t=0)\vec{A}(t=\Delta t)=e^{\Delta t P}\vec{A}(t=0)A (t=Δt)=eΔtPA (t=0)
本文示例假设PPP分段恒定,自由演化的PPP同样易于处理。
与上文一致,单步解仅提供NNN个自由度,远低于全可训练权重矩阵的O(N2)O(N^2)O(N2)自由度。但本方案中泵浦随时间变化 ,可通过Δt\Delta tΔt步长内改变泵浦值执行多个"子层",无需退出并重新进入谐振器。
经过NΔtN\Delta tNΔt时间后,总变换可获得N2N^2N2个自由度,提升表达能力。图5为不同Γ\GammaΓ下表达能力的数值评估结果。
理想情况(ΓΔt=γHΔt=0\Gamma\Delta t=\gamma_H\Delta t=0ΓΔt=γHΔt=0)下,表达能力随子层级联增长并趋近于1;悲观情况(12ΓΔt=1\frac{1}{2}\Gamma\Delta t=121ΓΔt=1)下,系统对损耗高度敏感。子层数较少时平均保真度上升,超过一定层数后,脉冲进入衰减区,表达能力开始下降。此时即使级联足够层数获得N2N^2N2自由度,最终表达能力仍无法达到1。
图6展示损耗增加对鸢尾花数据集分类的影响。采用与上文相似的单层架构,脉冲宽度从Δt\Delta tΔt(单步)到4Δt4\Delta t4Δt(四段恒定步长)。ΓΔt\Gamma\Delta tΓΔt较小时,网络线性分类性能优异,精度超99%;ΓΔt\Gamma\Delta tΓΔt增大时,分类精度先因表达能力提升而上升(见图5),子层数超过3层后损耗过大,表达能力下降,网络性能随之降低。
C. 计算速度
上文表明,波混频相互作用速率与χP′P′′\chi P'P''χP′P′′成正比,P′P'P′、P′′P''P′′分别为主泵浦与任意次级泵浦的振幅。因此泵浦功率越高,计算执行速度越快,仅受限于加载与散热约束。
下文推导硬件的χ\chiχ值,给出计算速度的实际工程约束。由文献38^{38}38,哈密顿量的非线性分量为:
H^=∫χ(3)D^44ε03η8dr(14)\hat{H}=\int\frac{\chi^{(3)}\hat{D}^4}{4\varepsilon_0^3\eta^8}dr \tag{14}H^=∫4ε03η8χ(3)D^4dr(14)
其中χ(3)\chi^{(3)}χ(3)为材料FWM非线性极化率,ε0\varepsilon_0ε0与η\etaη为真空介电常数与材料折射率,D^\hat{D}D^为电位移场算符。场算符D^m\hat{D}_mD^m为泵浦或神经元模式m^\hat{m}m^之和,可表示为38^{38}38:
D^m(r)=ℏωm2m^dm(r)+H.c.(15)\hat{D}_m(r)=\sqrt{\frac{\hbar\omega_m}{2}}\hat{m}d_m(r)+H.c. \tag{15}D^m(r)=2ℏωm m^dm(r)+H.c.(15)
其中m^\hat{m}m^为模式产生算符,满足归一化条件∫∣d(r)∣2dr=ε0η2\int|d(r)|^2dr=\varepsilon_0\eta^2∫∣d(r)∣2dr=ε0η2。
考虑两个神经元模式a^1\hat{a}1a^1、a^2\hat{a}2a^2与两个泵浦模式p^1\hat{p}1p^1、p^2\hat{p}2p^2的能量匹配条件,结合式(2)得:
ℏχ=32χ(3)ε0η4VFWMℏ4ωa1ωa2ωp1ωp2(16)\hbar\chi=\frac{3}{2}\frac{\chi^{(3)}}{\varepsilon_0\eta^4V{FWM}}\sqrt{\hbar^4\omega{a_1}\omega{a_2}\omega{p_1}\omega_{p_2}} \tag{16}ℏχ=23ε0η4VFWMχ(3)ℏ4ωa1ωa2ωp1ωp2 (16)
定义FWM模式体积VFWMV_{FWM}VFWM为:
1VFWM=∫nlda1ida2j∗dp1kdp2l∗dr∫∣da1∣2dr∫∣da2∣2dr∫∣dp1∣2dr∫∣dp2∣2dr\frac{1}{V_{FWM}}=\frac{\int_{nl}d_{a_1}^id_{a_2}^{j*}d_{p_1}^kd_{p_2}^{l*}dr}{\sqrt{\int|d_{a_1}|^2dr\int|d_{a_2}|^2dr\int|d_{p_1}|^2dr\int|d_{p_2}|^2dr}}VFWM1=∫∣da1∣2dr∫∣da2∣2dr∫∣dp1∣2dr∫∣dp2∣2dr ∫nlda1ida2j∗dp1kdp2l∗dr
其中∫nl\int_{nl}∫nl为非线性材料体积积分,i,j,k,li,j,k,li,j,k,l为非线性相互作用场的空间分量。
采用氮化硅谐振器 (η=2.02\eta=2.02η=2.02,χ(3)=43η2n2ε0c≈3.5×10−21m2V2\chi^{(3)}=\frac{4}{3}\eta^2n_2\varepsilon_0c\approx3.5\times10^{-21}\frac{m^2}{V^2}χ(3)=34η2n2ε0c≈3.5×10−21V2m239^{39}39),相位匹配良好,FWM模式体积VFWMV_{FWM}VFWM与几何体积相当(半径150μm、宽2.5μm、高0.73μm,约1300 μm31300\ \mathrm{\mu m^3}1300 μm340^{40}40),计算得χ≈4.2 s−1\chi\approx4.2\ \mathrm{s^{-1}}χ≈4.2 s−1。
由式(2)推导的耦合模方程,可计算两个神经元模式间完全能量交换周期:
Δt=2πχ<P1><P2>\Delta t=\frac{2\pi}{\chi<P_1><P_2>}Δt=χ<P1><P2>2π
其中最大振幅<P∗>2<P_*>^2<P∗>2为平均光子数的平方根,作为设计能量需求的最坏情况估计。
由图5、图6可知,ΔtΓ\Delta t\GammaΔtΓ超过1时,损耗导致硬件性能显著下降,因此要求:
<P1><P2>>2πΓχ<P_1><P_2>>\frac{2\pi\Gamma}{\chi}<P1><P2>>χ2πΓ
现代氮化硅谐振器Q值约10610^6106,Γ=γH=ωQ≈1 ns−1\Gamma=\gamma_H=\frac{\omega}{Q}\approx1\ \mathrm{ns^{-1}}Γ=γH=Qω≈1 ns−1,因此2πΓχ≈109\frac{2\pi\Gamma}{\chi}\approx10^9χ2πΓ≈109。这意味着主泵浦模式需约10亿光子 ,主泵浦热损耗约Γℏω<P>2≈100 mW\Gamma\hbar\omega<P>^2\approx100\ \mathrm{mW}Γℏω<P>2≈100 mW。
综上,泵浦功率<P>2<P>^2<P>2提升会线性提高计算速率 (χ<P>2\chi<P>^2χ<P>2)与线性增加计算功耗 (Γℏω<P>2\Gamma\hbar\omega<P>^2Γℏω<P>2)。当前典型微环谐振器37^{37}37可实现1 GHz计算速率(每秒10亿次子层矩阵乘法),主泵浦损耗100 mW。
如图7所示,采用已验证技术(富硅氮化硅、AlGaAs等材料提升χ(3)\chi^{(3)}χ(3),提高Q值),可在短期内大幅提升两项指标。有趣的是,该器件存在计算速度下限 :必须提供足够泵浦功率,使计算速度快于神经元模式衰减速率。另一方面,Q值极高的微环谐振器因与环境解耦,脉冲捕获效率受限。主动耦合引入的**可控耦合系数γ(t)\gamma(t)γ(t)**可解决该问题,允许调谐谐振器与波导间瞬时耦合,但需更复杂的控制与制备工艺。
此外,单子层执行速度恒定,与神经元数量无关。本文各类神经网络示例表明,子层数与神经元数量的缩放关系不劣于线性(通常更优),体现该架构的额外优势。
下文简要讨论损耗补偿技术 ,重点聚焦可直接在微环硬件中实现的方法。光信号放大技术种类丰富,尤其通过泵浦模式非线性相互作用的相位敏感放大。该技术与本文利用的动力学完全一致,可将"放大"加入训练优化目标函数,确保典型神经元激活模式被放大。
但乍看之下,本文推导的动力学方程不允许放大,实现的运算至多为幺正(能量守恒),这源于强非耗尽泵浦的关键假设------该假设是获得神经网络线性运算闭式解的前提。放弃该假设会增加训练难度,需通过刚性微分方程数值解反向传播,但可显著放大典型神经激活模式以补偿损耗。
第三部分讨论层间逐元素非线性激活函数时,将提供无训练缺陷的额外损耗补偿方法。
三、非线性激活
非线性激活函数是神经网络工作的核心。现有非线性激活函数实现方案依赖热光效应16,41^{16,41}16,41、光电混合方案42,43^{42,43}42,43、半导体激光器44,45^{44,45}44,45与饱和吸收46,47^{46,47}46,47。本文提出的非线性依赖χ(2)\chi^{(2)}χ(2)介质的非线性相互作用,结合可控捕获进入微环谐振器。但下文表明,上文介绍的线性变换对非线性强度存在约束。
本文非线性基于二阶非线性相互作用 (如铌酸锂波导,具备χ(2)\chi^{(2)}χ(2)极化率)。将完成矩阵乘法的谐振器中神经元模式释放至波导,通过与外部泵浦脉冲(称为次谐波模式)的非线性相互作用,扭曲神经元模式的时域包络。
该次谐波模式频率为神经元模式的1/2 。扭曲后,将神经元模式选择性捕获 48,49^{48,49}48,49至构成神经网络下一层的微环谐振器。扭曲脉冲被选择性吸收进环,吸收效率取决于扭曲程度。高振幅脉冲的非线性扭曲更强,产生有效逐元素非线性。图8为装置示意图。
为避免不同神经模式相互作用(保持激活函数逐元素),可采用色散波导使模式在时间上偏移。
首先研究神经脉冲与次谐波泵浦脉冲在波导中的包络扭曲动力学。将两个包络参数化为En(z,t)E_n(z,t)En(z,t)与Esub(z,t)E_{sub}(z,t)Esub(z,t),zzz为波导长度方向空间坐标。如补充材料所述,包络满足50^{50}50:
∂En∂z+ηc∂En∂t=−κEsub2−αEn(17)\frac{\partial E_n}{\partial z}+\frac{\eta}{c}\frac{\partial E_n}{\partial t}=-\kappa E_{sub}^2-\alpha E_n \tag{17}∂z∂En+cη∂t∂En=−κEsub2−αEn(17)
∂Esub∂z+ηc∂Esub∂t=κEnEsub∗−αEsub(18)\frac{\partial E_{sub}}{\partial z}+\frac{\eta}{c}\frac{\partial E_{sub}}{\partial t}=\kappa E_n E_{sub}^*-\alpha E_{sub} \tag{18}∂z∂Esub+cη∂t∂Esub=κEnEsub∗−αEsub(18)
κ=ωcχ(2)s(19)\kappa=\frac{\omega}{c}\chi^{(2)}s \tag{19}κ=cωχ(2)s(19)
其中sss为神经模式与次谐波模式的模式重叠无量纲量,ω\omegaω为神经模式频率,α\alphaα为波导损耗。
具体而言,输入神经模式(从执行矩阵乘法的环中释放)为高斯波包:
En=ϵne−z24w2e−iφ0E_n=\epsilon_ne^{-\frac{z^2}{4w^2}}e^{-i\varphi_0}En=ϵne−4w2z2e−iφ0
其中www为波包空间长度,φ0\varphi_0φ0为神经元激活相位,ϵn\epsilon_nϵn为场振幅尺度。次谐波泵浦设为Esub=ϵse−z24w2E_{sub}=\epsilon_se^{-\frac{z^2}{4w^2}}Esub=ϵse−4w2z2,也可采用连续波Esub=ϵsE_{sub}=\epsilon_sEsub=ϵs。
数值求解En(z,t)E_n(z,t)En(z,t)演化过程,主要控制动力学的无量纲参数为非线性相互作用有效强度κϵsz0\kappa\epsilon_sz_0κϵsz0与** 神经模式相对固定次谐波模式强度ϵn/ϵs\epsilon_n/\epsilon_sϵn/ϵs** ,χ(2)\chi^{(2)}χ(2)波导长度为z0z_0z0。模拟与代数运算详见交互式补充材料。
扭曲后的神经元包络通过**可控环--波导耦合γ(t)\gamma(t)γ(t)**主动捕获至下一环。无泵浦模式相互作用时,捕获动力学满足34,48,51,52^{34,48,51,52}34,48,51,52:
dAdt=−(γ(t)+γH)2A+γ(t)Sin(20)\frac{dA}{dt}=-\frac{\left(\gamma(t)+\gamma_H\right)}{2}A+\sqrt{\gamma(t)}S_{in} \tag{20}dtdA=−2(γ(t)+γH)A+γ(t) Sin(20)
Sout=Sin+γ(t)A(21)S_{out}=S_{in}+\sqrt{\gamma(t)}A \tag{21}Sout=Sin+γ(t) A(21)
其中Sin(t)=En(0,t)S_{in}(t)=E_n(0,t)Sin(t)=En(0,t)为入射神经模式包络,SoutS_{out}Sout为出射(未捕获)信号,AAA为谐振器捕获的神经元模式振幅。
固定Sout=0S_{out}=0Sout=0,可求解完全捕获给定包络SinS_{in}Sin的γ(t)\gamma(t)γ(t)。高斯波包的解析解见补充材料。高神经激活会导致强包络扭曲,进而使模式无法完全捕获,等效为神经网络中的逐元素非线性激活函数。
重要的是,该实现天然支持负激活值,区别于绝大多数光学方案;也支持任意复数值,如图9所示。
数值实验表明,κϵsz0≈0.2\kappa\epsilon_sz_0\approx0.2κϵsz0≈0.2可实现饱和型激活函数 。采用长度z0=1 cmz_0=1\ \mathrm{cm}z0=1 cm、模式重叠s≈1s\approx1s≈1的铌酸锂波导(χ(2)=31 pm/V\chi^{(2)}=31\ \mathrm{pm/V}χ(2)=31 pm/V),计算得ϵs=160 kV/m\epsilon_s=160\ \mathrm{kV/m}ϵs=160 kV/m。该场强振幅对应截面a=0.2 μm2a=0.2\ \mathrm{\mu m^2}a=0.2 μm2波导的峰值功率约:
ε0ηcϵs2a=20 μW\varepsilon_0\sqrt{\eta}c\epsilon_s^2a=20\ \mathrm{\mu W}ε0η cϵs2a=20 μW
该泵浦功率易于实现,对器件制备无压力。根据平台需求,可选用其他高χ(2)\chi^{(2)}χ(2)材料(如砷化镓53^{53}53、铝镓砷54^{54}54、碳化硅55^{55}55)。同时具备高χ(2)\chi^{(2)}χ(2)与χ(3)\chi^{(3)}χ(3)系数的材料,可将整个器件集成在单一材料平台 56,57^{56,57}56,57。
非线性激活函数也可用于补偿微环谐振器损耗 :将非线性相互作用设计为斜率大于1的激活函数,替代类Sigmoid函数,示例见补充材料。
四、案例研究:图像分类
在模拟神经网络中对所提硬件设计的性能进行基准测试,完成手写数字MNIST数据集分类。训练集包含50000张28×28像素图像。
光神经网络在MNIST图像的低频傅里叶特征 上训练:对图像预处理,截取二维傅里叶变换的中心N×NN\times NN×N窗口,重塑为N2N^2N2维向量,编码为模拟微环谐振器模式的初始复振幅(即神经网络输入层)。选择N=8N=8N=8,低频分量包含图像大部分关键信息。
训练采用小批量梯度下降 ,共200个epoch,Adam优化器58^{58}58,每批2000张训练图像,学习率指数衰减(从0.01降至0.0002)。
线性变换通过主动耦合方法实现。模拟中测试不同损耗 regimes 下网络性能,改变子层数(泵浦分段恒定步数)。前文已观察到:表达能力随子层数先增后减,过长操作导致损耗恶化。图10验证该结论,展示模型分类精度随硬件参数的变化:需达到最小子层数以获得足够精度,继续增加子层数会因损耗导致精度下降。
底部图为输出神经元模式携带能量的直方图:不同子层数(横轴)与损耗率(虚线标注)下,绘制每个神经元模式的能量分布(纵轴直方图)。蓝色直方图对应"错误类别"神经元,红色对应"正确类别"神经元(数量更少)。正确类别神经元能量始终更高,表明分类有效;高表达能力下红色直方图分布更集中;子层数增加时,存在损耗情况下模式功率快速衰减,解释了右上角图中精度的骤降。
采用先进谐振腔(Γ=0.2 ns−1\Gamma=0.2\ \mathrm{ns^{-1}}Γ=0.2 ns−1)、控制脉冲分辨率Δt=1 ns\Delta t=1\ \mathrm{ns}Δt=1 ns,可实现优异分类性能,损耗低于5 dB。更大网络则需前文所述泵浦方案保障可靠运行。
五、讨论与结论
本文提出一种仅依赖非线性光学过程 的全光人工神经网络处理器新架构。该方案将信息编码在频率态复振幅中,通过χ(3)\chi^{(3)}χ(3)介质中的四波混频实现矩阵乘法;非线性激活依赖χ(2)\chi^{(2)}χ(2)与次谐波模式的相互作用,导致神经元模式脉冲扭曲并投影为高斯脉冲形状。该方案可通过微环谐振器轻松片上实验实现。
所提神经网络处理器相比现有光学与电子神经网络具备多项优势:数字矩阵--向量乘法时间复杂度通常为O(N2)O(N^2)O(N2),而本模型仅为O(N)O(N)O(N)------任意FWM过程中所有神经元模式同步调制;片上器件数量极少,所有神经模式共用同一谐振器。
此外,运算速度与泵浦光功率成正比 ,可自由提升计算速度。极端高速下泵浦泄漏导致散热增加,但提高谐振器Q值可补偿该问题。如正文所述,近期光子技术可实现数十亿次/秒矩阵乘法,功耗仅数十毫瓦。
未来研究方向包括:将架构功能扩展至递归神经网络、伊辛机等领域;探索片上原位训练 59^{59}59或自学习机器(替代数值优化泵浦);计算属于幺正群,为超高速可逆计算开辟新路径。
致谢
感谢Ryan Hamerly关于非线性激活函数可行性的讨论。作者感谢MITRE量子登月计划的资金支持。本文模拟在MGHPCC设施的Engaging集群MIT-PSFC分区上完成,由美国能源部资助(DE-FG02-91-ER5410)。感谢Tensorflow与Julia开源社区提供的研究软件,支持优化、机器学习与偏微分方程求解。M. H.感谢Villum基金会资助(QNET-NODES,37417)。
参考文献(原文不动输出)
1 T. Young, D. Hazarika, S. Poria, and E. Cambria, IEEE Computational Intelligence Magazine 13, 55 (2018).
2 A. W. Senior, R. Evans, and J. J. et al., Nature 577, 706 (2020).
3 J. Chrittwieser, I. Antonoglou, and T. S. H. et al., Nature 588, 604 (2020).
4 D. Steinkraus, I. Buck, and P. Y. Simard, in Eighth International Conference on Document Analysis and Recognition (ICDAR'05) (2005) pp. 1115--1120 Vol. 2.
5 A. Graves, G. Wayne, and G. M. R. et al., Nature 538, 471 (2016).
6 S. K. Esser, P. A. Merolla, J. V. Arthur, A. S. Cassidy, R. Appuswamy, A. Andreopoulos, D. J. Berg, J. L. McKinstry, T. Melano, D. S. Barch, C. di Nolfo, P. Datta, A. Amir, B. Taba, and D. S. Flickner, M. D. Modha, in Proceedings of the National Academy of Sciences, Vol. 113 (2016 Oct 11) pp. 11441--1146.
7 Intel nervana neural network processor (2016), (accessed: 12.01.2020).
8 V. Almeida, C. Barrios, and R. e. a. Panepucci, Nature 431, 1081 (2004).
9 J. Leuthold, C. Koos, and W. Freude, Nature photonics , 535 (2010).
10 A. N. Tait, M. A. Nahmias, B. J. Shastri, and P. R. Prucnal, Journal of Lightwave Technology 32, 4029 (2014).
11 K. Vandoorne, W. Dierckx, B. Schrauwen, D. Verstraeten, R. Baets, P. Bienstman, and J. Van Campenhout, Opt. Express 16, 11182 (2008).
12 V. Sze, Y. Chen, T. Yang, and J. S. Emer, Proceedings of the IEEE 105, 2295 (2017).
13 T. Chen, Z. Du, N. Sun, J. Wang, C. Wu, Y. Chen, and O. Temam, ACM SIGARCH Computer Architecture News 42, 269 (2014).
14 L. Vivien, A. Polzer, D. Marris-Morini, J. Osmond, J. M. Hartmann, P. Crozat, E. Cassan, C. Kopp, H. Zimmermann, and J. M. Fédéli, Opt. Express 20, 1096 (2012).
15 X. Lin, Y. Rivenson, N. T. Yardimci, M. Veli, Y. Luo, M. Jarrahi, and A. Ozcan, Science 361, 1004 (2018).
16 Y. Shen, N. C. Harris, S. Skirlo, M. Prabhu, T. BaehrJones, M. Hochberg, X. Sun, S. Zhao, H. Larochelle, and D. Englund, Nature Photon. 11, 441 (2017).
17 A. N. Tait, T. F. Lima, W. A. X., N. M. A., S. B. J., and P. P. R., Sci Rep 7, 7430 (2017).
18 B. Shi, N. Calabretta, D. Bunandar, D. Englund, and R. Stabile, in 2018 Photonics in Switching and Computing (PSC) (2018) pp. 1--3.
19 Y. Zuo, B. Li, Y. Zhao, Y. C. Chen, G. B. Jo, J. Liu, and S. Du, Optica 6, 1132 (2019).
20 M. Borghi, A. Trenti, and L. Pavesi, Scientific reports 9, 1 (2019).
21 R. Kibria and M. Austin, Photonics 2, 200 (2015).
22 G. Mourgias-Alexandris, A. Tsakyridis, N. Passalis, A. Tefas, K. Vyrsokinos, and N. Pleros, Optics express 27, 9620 (2019).
23 M. T. Hill, E. E. Frietman, H. de Waardt, G.-d. Khoe, and H. J. Dorren, IEEE Transactions on Neural Networks 13, 1504 (2002).
24 D. Rosenbluth, K. Kravtsov, M. P. Fok, and P. R. Prucnal, Optics express 17, 22767 (2009).
25 M. Miscuglio, A. Mehrabian, Z. Hu, S. I. Azzam, J. George, A. V. Kildishev, M. Pelton, and V. J. Sorger, Optical Materials Express 8, 3851 (2018).
26 A. N. Tait, T. F. De Lima, M. A. Nahmias, H. B. Miller, H.-T. Peng, B. J. Shastri, and P. R. Prucnal, Physical Review Applied 11, 064043 (2019).
27 R. Amin, J. George, S. Sun, T. Ferreira de Lima, A. N. Tait, J. Khurgin, M. Miscuglio, B. J. Shastri, P. R. Prucnal, T. El-Ghazawi, et al., APL Materials 7, 081112 (2019).
28 J. K. George, A. Mehrabian, R. Amin, J. Meng, T. F. De Lima, A. N. Tait, B. J. Shastri, T. El-Ghazawi, P. R. Prucnal, and V. J. Sorger, Optics express 27, 5181 (2019).
29 M. A. Nahmias, A. N. Tait, L. Tolias, M. P. Chang, T. Ferreira de Lima, B. J. Shastri, and P. R. Prucnal, Applied Physics Letters 108, 151106 (2016).
30 I. A. Williamson, T. W. Hughes, M. Minkov, B. Bartlett, S. Pai, and S. Fan, IEEE Journal of Selected Topics in Quantum Electronics 26, 1 (2019).
31 R. A. Fisher, Annals of eugenics 7, 179 (1936).
32 L. Deng, IEEE Signal Processing Magazine 29, 141 (2012).
33 M. Heuck, J. G. Koefoed, J. B. Christensen, Y. Ding, L. H. Frandsen, K. Rottwitt, and L. K. Oxenløwe, New Journal of Physics 21, 033037 (2019).
34 W. Suh, Z. Wang, and S. Fan, IEEE Journal of Quantum Electronics 40, 1511 (2004).
35 G. Cappellini and S. Trillo, J. Opt. Soc. Am. B 8, 824 (1991).
36 M. Zhang, B. Buscaino, C. Wang, A. Shams-Ansari, C. Reimer, R. Zhu, J. M. Kahn, and M. Lončar, Nature 568, 373 (2019).
37 K. M. Kaini, H. M. Mbonde, H. C. Frankis, R. Mateman, A. Leinse, A. P. Knights, and J. D. B. Bradley, OSA Continuum 3, 3497 (2020).
38 Q. Nicolás and J. E. Sipe, Opt. Lett. 42, 3443 (2017).
39 R. Paschotta, Encyclopedia of laser physics and technology, Vol. 1 (Wiley-vch, 2008).
40 X. Ji, F. A. Barbosa, S. P. Roberts, A. Dutt, J. Cardenas, Y. Okawachi, A. Bryant, A. L. Gaeta, and M. Lipson, Optica 4, 619 (2017).
41 M. M. Pour Fard, I. A. D. Williamson, M. Edwards, K. Liu, S. Pai, B. Bartlett, M. Minkov, T. W. Hughes, S. Fan, and T. A. Nguyen, Opt. Express 28, 12138 (2020).
42 J. George, R. Amin, A. Mehrabian, J. Khurgin, T. ElGhazawi, P. R. Prucnal, and V. J. Sorger, in Signal Processing in Photonic Communications (Optical Society of America, 2018) pp. SpW4G--3.
43 J. K. George, R. Amin, J. Meng, T. F. de Lima, A. N. Tait, B. J. Shastri, T. El-Ghazawi, P. R. Prucnal, and V. J. Sorger, Opt. Express 28, 12138 (2020).
44 T. S. Rasmussen, Y. Yu, and J. Mork, Optics Letters 45, 3844 (2020).
45 E. Mos, J. Schleipen, and H. De Waardt, Applied optics 36, 6654 (1997).
46 A. Dejonckheere, F. Duport, A. Smerieri, L. Fang, J. L. Oudar, J. Haelterman, and S. Massar, Opt. Express 22, 10868 (2014).
47 Z. Cheng, H. K. Tsang, X. Wang, K. Xu, and J. Xu, IEEE Journal of Selected Topics in Quantum Electronics 20, 43 (2014).
48 J. Upham, Y. Tanaka, Y. Kawamoto, Y. Sato, T. Nakamura, B. S. Song, T. Asano, and S. Noda, Opt. Express 19, 23377 (2011).
49 H. I. Nurdin, M. R. James, and N. Yamamoto, arXiv preprint arXiv:1609.05643 (2016).
50 K. D. Shaw, in Solid State Lasers and Nonlinear Crystals, Vol. 2379 (SPIE, 1995) pp. 365--377.
51 M. Heuck, P. T. Kristensen, Y. Elesin, and J. Mørk, Opt. Lett. 38, 2466 (2003).
52 P. T. Kristensen, J. R. de Lasson, M. Heuck, N. Gregersen, and J. Mørk, Journal of Lightwave Technology 35, 4247 (2017).
53 S. Bergfeld and W. Daum, Physical review letters 90, 036801 (2003).
54 Z. Yan, H. He, H. Liu, M. Iu, O. Ahmed, E. Chen, P. Blakey, Y. Akasaka, T. Ikeuchi, and A. S. Helmy, Optica 9, 56 (2022).
55 H. Sato, M. Abe, I. Shoji, J. Suda, and T. Kondo, JOSA B 26, 1892 (2009).
56 J. Liu, G. Huang, R. N. Wang, J. He, A. S. Raja, T. Liu, N. J. Engelsen, and T. J. Kippenberg, Nature communications 12, 1 (2021).
57 L. Chang, A. Boes, P. Pintus, J. D. Peters, M. Kennedy, W. Jin, X.-W. Guo, S.-P. Yu, S. B. Papp, and J. E. Bowers, in CLEO: Science and Innovations (Optical Society of America, 2019) pp. SF2I--2.
58 D. P. Kingma and J. Ba, arXiv preprint arXiv.1412.6980 (2014).
59 X. Guo, T. D. Barrett, Z. M. Wang, and A. Lvovsky, Photonics Research 9, B71 (2021).
六、附录
A. 实现变换的表达能力
2A与2B节研究了所提硬件实现的线性变换表达能力。通过随机采样MMM个幺正矩阵UiU_iUi,尝试在硬件中实现,平均保真度(表达能力)由式(11)定义。本文对M=1000M=1000M=1000个矩阵样本给出更详细统计,展示单样本保真度直方图,替代图3、图5仅展示平均值的形式。
图11:被动耦合变换的优化保真度分布,随所用子层数变化。
被动耦合变换为ΠT\Pi TΠT型矩阵(式(10))。图11展示4×4小矩阵(便于展示)的优化保真度分布,子层数增加,平均保真度逐步提升。主动耦合方法实现的ΠeΔtP\Pi e^{\Delta tP}ΠeΔtP型变换结果相似,见图12。
图12:主动耦合变换的优化保真度分布,随所用子层数变化。
B. 脉冲到谐振器的确定性主动捕获
入射脉冲SinS_{in}Sin捕获到谐振器模式AAA的动力学由式(21)、(22)描述,SoutS_{out}Sout为出射脉冲包络。为确保脉冲完全捕获,重排方程得:
Sout=0⇒γ(t)=SinA(22)S_{out}=0\Rightarrow\sqrt{\gamma(t)}=\frac{S_{in}}{A} \tag{22}Sout=0⇒γ(t) =ASin(22)
dAdt=−γH2A+Sin22A(23)\frac{dA}{dt}=-\frac{\gamma_H}{2}A+\frac{S_{in}^2}{2A} \tag{23}dtdA=−2γHA+2ASin2(23)
可对任意入射包络求解该微分方程。高斯包络入射脉冲Sin=S0e−(t−t0)22w2S_{in}=S_0e^{-\frac{(t-t_0)^2}{2w^2}}Sin=S0e−2w2(t−t0)2的解析解为γ(t)=S0e−(t−t0)22w2A\sqrt{\gamma(t)}=\frac{S_0e^{-\frac{(t-t_0)^2}{2w^2}}}{A}γ(t) =AS0e−2w2(t−t0)2,其中:
A(t)=(πS0weγH2(γHw22+2t0−2t)×(1+erf(−γHw22−t0+t))2)12(24)\begin{aligned}A(t)=&\left(\sqrt{\pi}S_0we^{\frac{\gamma_H}{2}\left(\frac{\gamma_Hw^2}{2}+2t_0-2t\right)}\right.\\&\left.\times\frac{\left(1+erf\left(-\frac{\gamma_Hw^2}{2}-t_0+t\right)\right)}{2}\right)^{\frac{1}{2}}\end{aligned} \tag{24}A(t)=(π S0we2γH(2γHw2+2t0−2t)×2(1+erf(−2γHw2−t0+t)) 21(24)
其他包络可通过微分方程数值解或最小化SoutS_{out}Sout的优化问题求解。图13展示式(25)γ(t)\gamma(t)γ(t)解析解与通用数值优化解的一致性。
图13 :高斯包络入射脉冲的可控耦合系数γ(t)\gamma(t)γ(t)(灰色虚线,右纵轴)。
C. 用于放大的二次谐波泵浦非线性激活函数
正文提出的非线性激活函数采用与神经元模式相互作用的次谐波模式,频率为神经元模式的1/2。但材料透明度、所需频率高效光源等约束可能带来实验困难。因此讨论替代非线性激活函数 :允许神经元模式与二次谐波泵浦 相互作用。与正文一致,相互作用可由同一偏微分方程组建模,仅置换神经元与泵浦模式:
∂Esec∂z+ηc∂Esec∂t=−κEn2−αEsec(25)\frac{\partial E_{sec}}{\partial z}+\frac{\eta}{c}\frac{\partial E_{sec}}{\partial t}=-\kappa E_n^2-\alpha E_{sec} \tag{25}∂z∂Esec+cη∂t∂Esec=−κEn2−αEsec(25)
∂En∂z+ηc∂En∂t=κEsecEn∗−αEn(26)\frac{\partial E_n}{\partial z}+\frac{\eta}{c}\frac{\partial E_n}{\partial t}=\kappa E_{sec}E_n^*-\alpha E_n \tag{26}∂z∂En+cη∂t∂En=κEsecEn∗−αEn(26)
其中EnE_nEn为神经元模式,EsecE_{sec}Esec为二次谐波泵浦模式。该非线性激活函数可用于放大神经元模式、补偿损耗。
D. 三波混频波导中的运动方程
本文明确推导正文中使用的运动方程。考虑"神经元"与"次谐波"场:
En=fnp(x,y)En(z,t)ei(ωt−kz)+c.c.(27)E_n=f_n^p(x,y)E_n(z,t)e^{i(\omega t-kz)}+c.c. \tag{27}En=fnp(x,y)En(z,t)ei(ωt−kz)+c.c.(27)
Es=fsp(x,y)Es(z,t)ei12(ωt−kz)+c.c.(28)E_s=f_s^p(x,y)E_s(z,t)e^{i\frac{1}{2}(\omega t-kz)}+c.c. \tag{28}Es=fsp(x,y)Es(z,t)ei21(ωt−kz)+c.c.(28)
其中f∗p(x,y)f_*^p(x,y)f∗p(x,y)描述波导模式轮廓,E∗(z,t)E_*(z,t)E∗(z,t)描述波包形状。因存在非线性过程,需跟踪复共轭部分。
物质中的麦克斯韦方程与非线性极化率典型参数化,给出非线性波动方程:
(∇2−n2c2)E=1ε0c2∂t2PNL=1c2χ(2)EE(29)\left(\nabla^2-\frac{n^2}{c^2}\right)E=\frac{1}{\varepsilon_0c^2}\partial_t^2P_{NL}=\frac{1}{c^2}\chi^{(2)}EE \tag{29}(∇2−c2n2)E=ε0c21∂t2PNL=c21χ(2)EE(29)
其中E=En+EsE=E_n+E_sE=En+Es,近似∇⋅E=0\nabla\cdot E=0∇⋅E=0。
上述方程的线性形式提供定义波导模式轮廓的本征值问题:
(∂x2+∂y2)fnp(x,y)=(−(ik)2+(iω)2n2c2)fnp(x,y)(30)\left(\partial_x^2+\partial_y^2\right)f_n^p(x,y)=\left(-(ik)^2+(i\omega)^2\frac{n^2}{c^2}\right)f_n^p(x,y) \tag{30}(∂x2+∂y2)fnp(x,y)=(−(ik)2+(iω)2c2n2)fnp(x,y)(30)
(∂x2+∂y2)fsp(x,y)=(−(ik2)2+(iω2)2n2c2)fsp(x,y)(31)\left(\partial_x^2+\partial_y^2\right)f_s^p(x,y)=\left(-\left(i\frac{k}{2}\right)^2+\left(i\frac{\omega}{2}\right)^2\frac{n^2}{c^2}\right)f_s^p(x,y) \tag{31}(∂x2+∂y2)fsp(x,y)=(−(i2k)2+(i2ω)2c2n2)fsp(x,y)(31)
非线性微扰导致波包包络的运动方程。推导中考虑包络慢变 ,满足∂z≪k\partial_z\ll k∂z≪k、∂t≪ω\partial_t\ll\omega∂t≪ω:
(∂z+nc∂t)En(z,t)=−κEs2(z,t)(32)\left(\partial_z+\frac{n}{c}\partial_t\right)E_n(z,t)=-\kappa E_s^2(z,t) \tag{32}(∂z+cn∂t)En(z,t)=−κEs2(z,t)(32)
(∂z+nc∂t)Es(z,t)=κEn(z,t)Es∗(z,t)(33)\left(\partial_z+\frac{n}{c}\partial_t\right)E_s(z,t)=\kappa E_n(z,t)E_s^*(z,t) \tag{33}(∂z+cn∂t)Es(z,t)=κEn(z,t)Es∗(z,t)(33)
其中κ\kappaκ满足:
κcω=∫χ(2)fnp∗fspfspdxdy∫fnp∗fnpdxdy=−∫χ(2)fsp∗fnfsp∗dxdy∫fsp∗fspdxdy(34)\kappa\frac{c}{\omega}=\frac{\int\chi^{(2)}f_n^{p*}f_s^pf_s^pdxdy}{\int f_n^{p*}f_n^pdxdy}=-\frac{\int\chi^{(2)}f_s^{p*}f_nf_s^{p*}dxdy}{\int f_s^{p*}f_s^pdxdy} \tag{34}κωc=∫fnp∗fnpdxdy∫χ(2)fnp∗fspfspdxdy=−∫fsp∗fspdxdy∫χ(2)fsp∗fnfsp∗dxdy(34)
为保证方程能量守恒,两个κ\kappaκ表达式必须相等。模式重叠约为1时,κcω≈χ(2)\kappa\frac{c}{\omega}\approx\chi^{(2)}κωc≈χ(2)。
图片说明翻译(按文中出现顺序)
图1 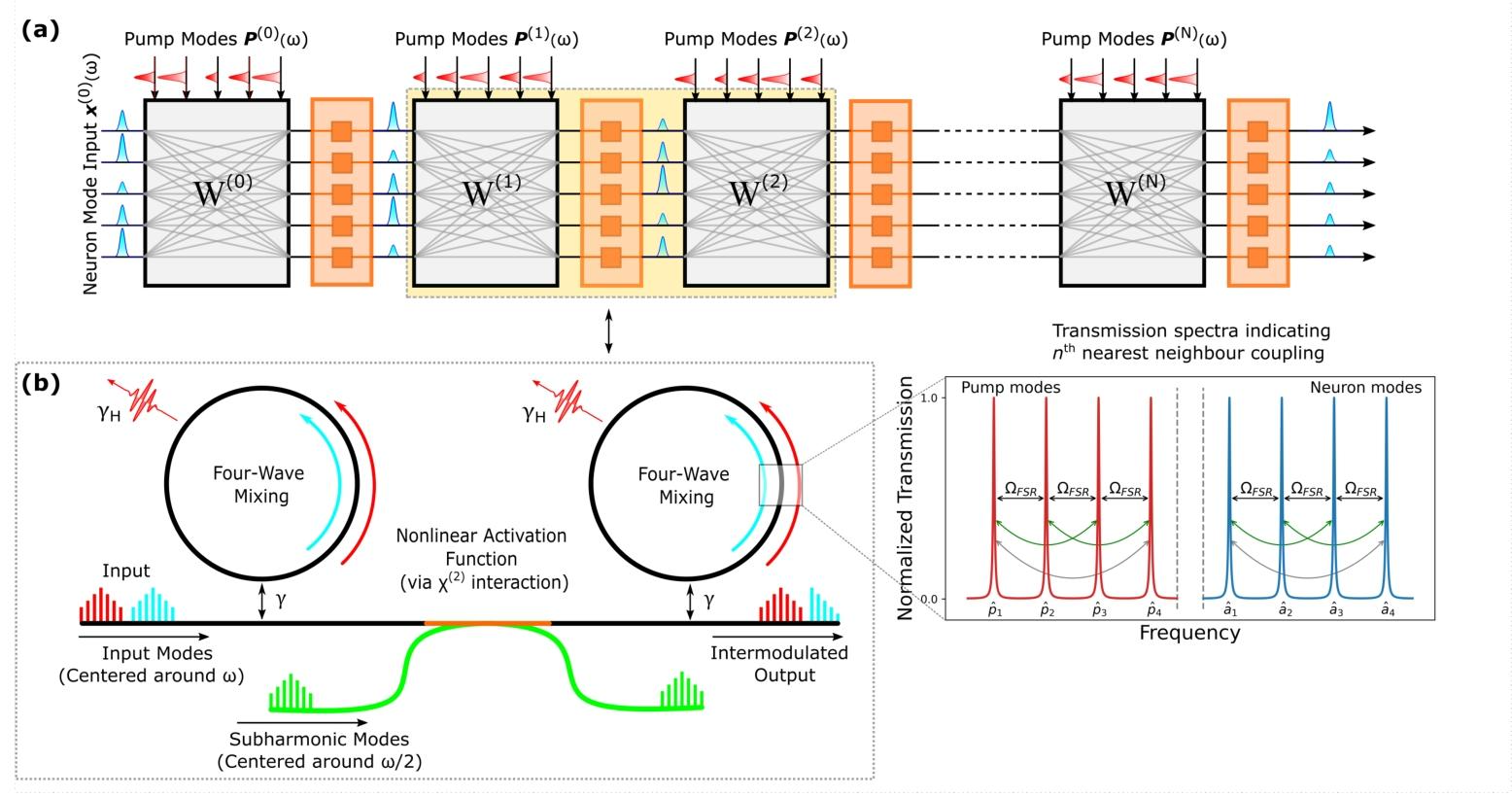
(a) 神经网络示意图,表示为NNN层序列。待处理信息编码在神经元频率态振幅(蓝色)中,线性变换W(i)W^{(i)}W(i)通过强经典泵浦模式(红色)实现。层间传播过程中,神经元模式与外部次谐波泵浦模式(绿色)的非线性光学相互作用,实现非线性激活函数(橙色模块)。
(b) 内嵌图展示包含非线性的两个连续层,由波导连接的微环谐振器构成。旁附微环谐振器透射谱,第nnn近邻泵浦与神经元模式耦合(绿色与灰色箭头)。每个谐振器以耦合系数γ\gammaγ与波导耦合,存在固有损耗γH\gamma_HγH。
图2
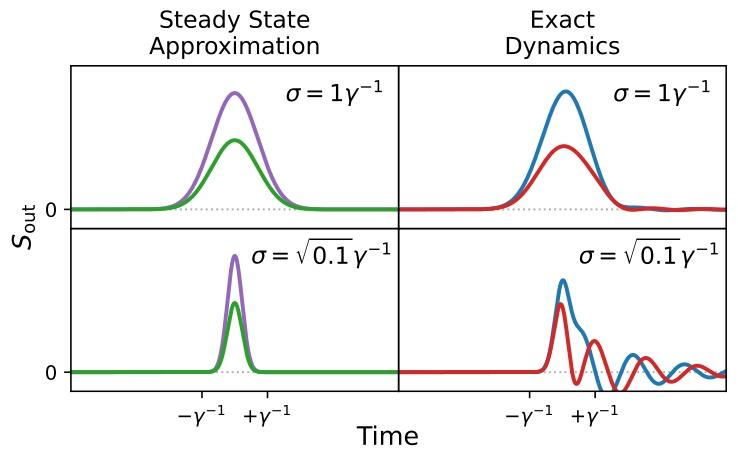
不同宽度高斯包络脉冲的稳态模型与全模型对比。第一列展示SoutS_{out}Sout的真实轮廓,第二列为稳态模型预测轮廓。脉冲宽度远小于1/γ1/\gamma1/γ时,稳态模型失效。
图3 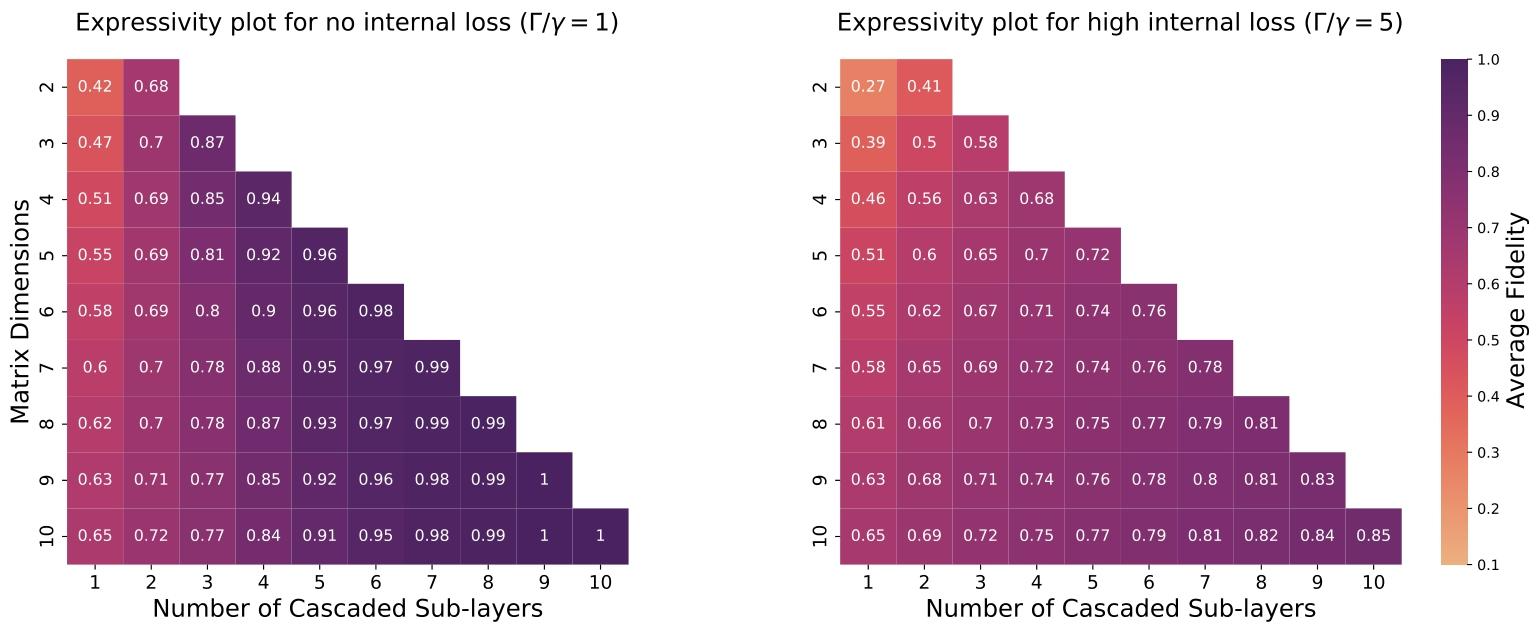
被动耦合方案不同参数下TTT变换的表达能力量化。每个图展示给定矩阵维度(纵轴)下,平均表达能力随子层数(横轴)的变化。左侧无腔内损耗(Γ/γ=1\Gamma/\gamma=1Γ/γ=1)时,子层数足够多则表达能力趋近于1;右侧高损耗(Γ/γ=5\Gamma/\gamma=5Γ/γ=5)时,表达能力始终偏低。
图4 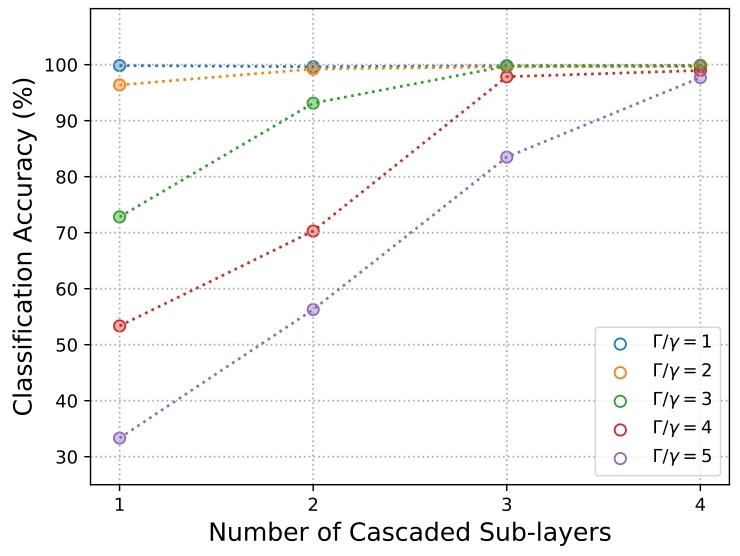
鸢尾花数据集分类精度随级联子层数、不同Γ/γ\Gamma/\gammaΓ/γ损耗比的变化(被动耦合方案)。子层数越多,分类精度越高;Γ/γ\Gamma/\gammaΓ/γ越大,网络性能越差。
图5 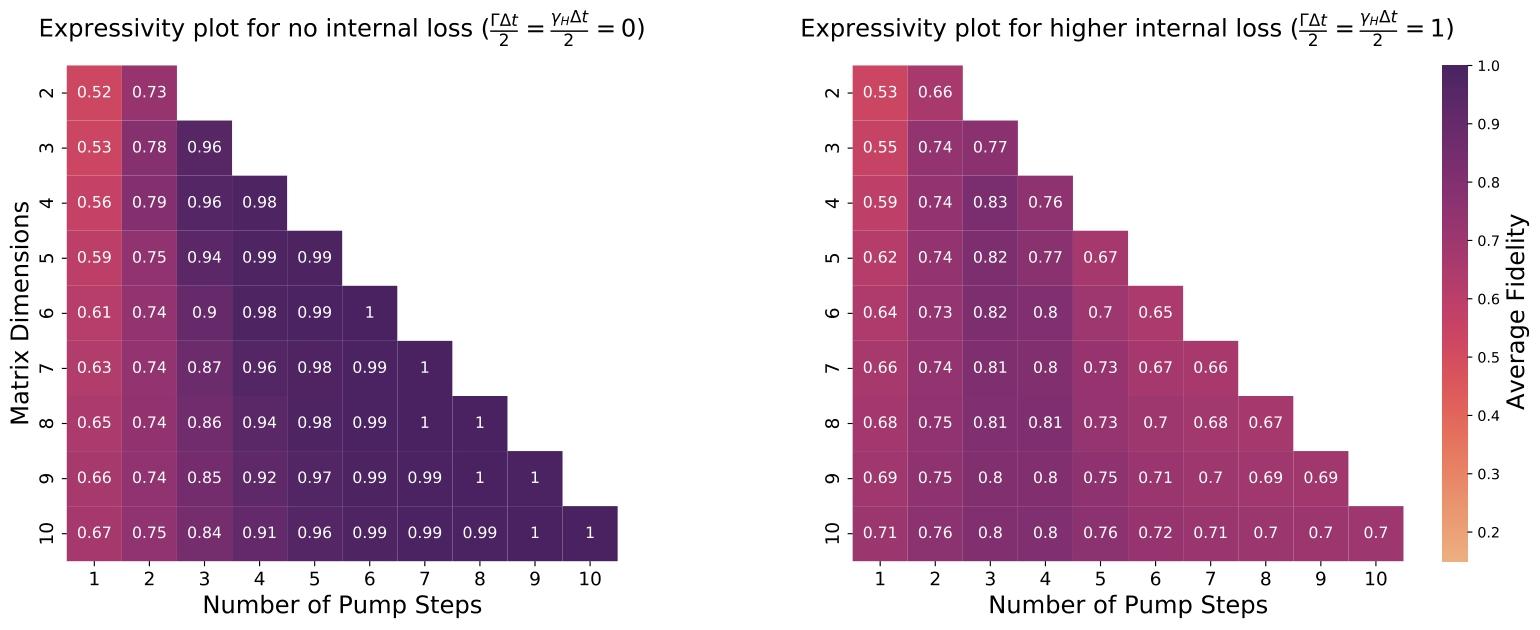
主动耦合ΠeΔtP\Pi e^{\Delta tP}ΠeΔtP型变换在不同参数下的表达能力。每个图展示给定矩阵维度(纵轴)下,平均保真度随子层数(泵浦步长数,横轴)的变化。左侧理想无腔内损耗(Γ=γH=0\Gamma=\gamma_H=0Γ=γH=0)时,子层数/步长足够多则表达能力趋近于1;右侧高损耗(ΓΔt2=γHΔt2=1\frac{\Gamma\Delta t}{2}=\frac{\gamma_H\Delta t}{2}=12ΓΔt=2γHΔt=1)时,表达能力无法接近1。值得注意的是,表达能力随层数先升后降,损耗随层数指数增长。本文定义的表达能力同时包含自由度不足与腔泄漏导致的振幅衰减。
图6 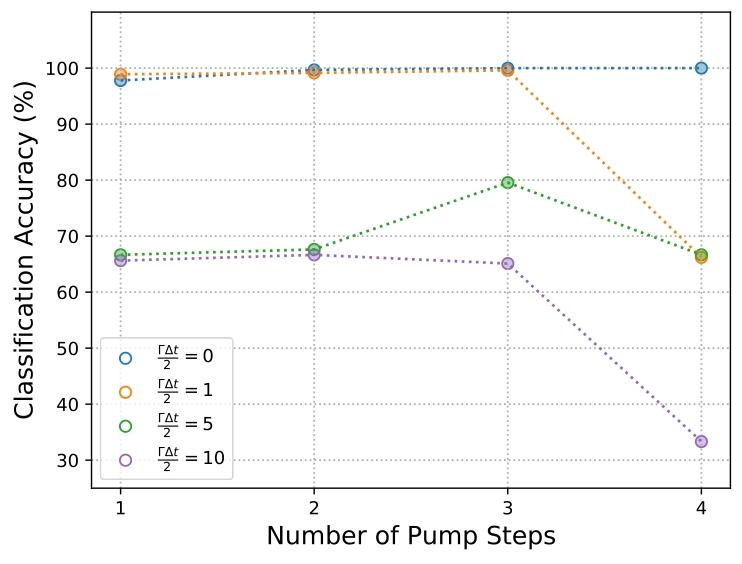
鸢尾花数据集分类精度随级联子层数(脉冲宽度)、内腔损耗率的变化(主动耦合方案)。泵浦步数增加,网络性能先升后降,与图5表达能力变化趋势一致。
图7 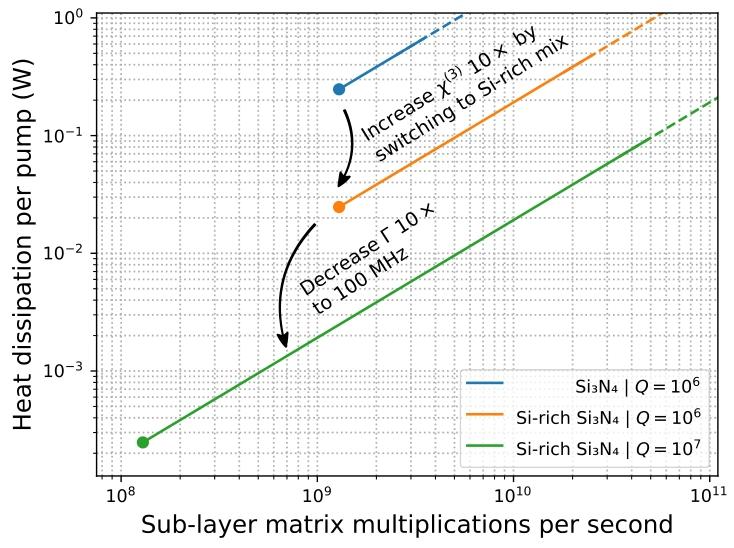
设计的计算性能预估。横轴为子层乘法执行速率(矩阵--向量乘法速率,矩阵为受限幺正矩阵);纵轴为编码矩阵参数的泵浦泄漏导致的单环散热预估。顶部蓝线为典型氮化硅环(Γ=1 ns−1\Gamma=1\ \mathrm{ns^{-1}}Γ=1 ns−1,VFWM=1300 μmV_{FWM}=1300\ \mathrm{\mu m}VFWM=1300 μm)37^{37}37;橙色线为富硅材料(显著提升χ(3)\chi^{(3)}χ(3));绿色线为高Q谐振器。减小环模式体积可获得相似性能提升。曲线左侧截断受限于图5、图6约束:计算速率需快于衰减速率。
图8 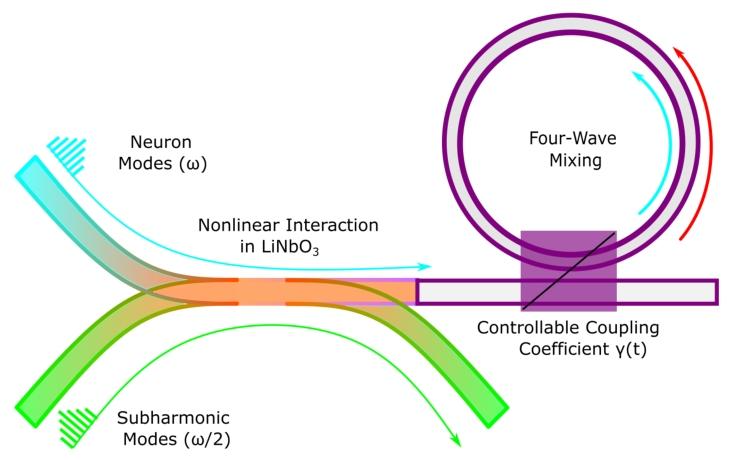
传播"神经"脉冲执行激活函数的示意图。输入脉冲(青色)在χ(2)\chi^{(2)}χ(2)波导中经二阶非线性相互作用扭曲,随后捕获至环谐振器。可控耦合系数γ(t)\gamma(t)γ(t)实现选择性吸收,效率取决于脉冲扭曲程度。
图9 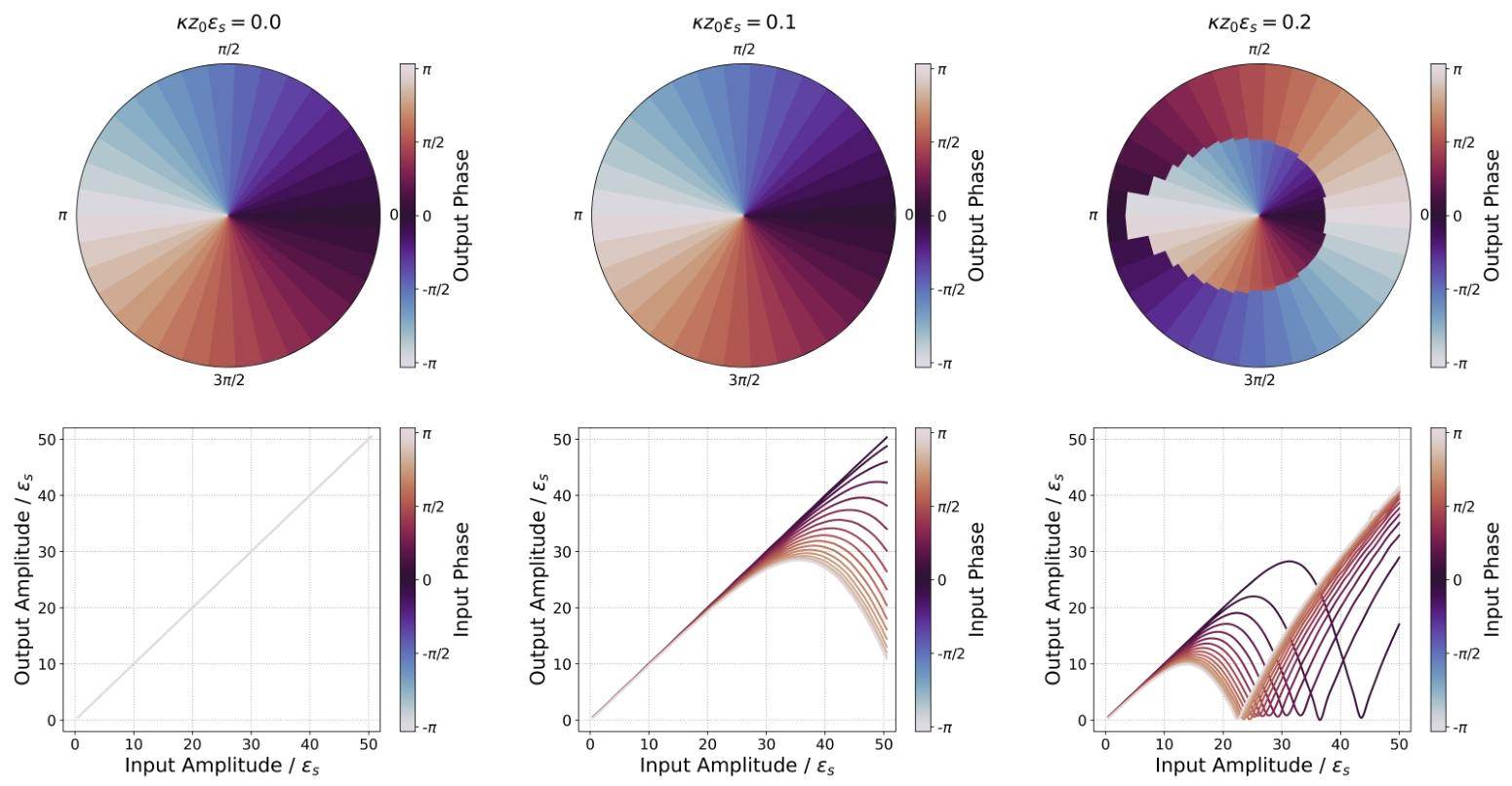
本设计实现的"神经"激活函数。上行极坐标图展示激活后神经模式相位(颜色)随输入模式相位(极坐标)与振幅(径向坐标)的变化,绘制三个无量纲参数κz0ϵs∈{0.0,0.1,0.2}\kappa z_0\epsilon_s\in\{0.0,0.1,0.2\}κz0ϵs∈{0.0,0.1,0.2}下的非线性。下行展示输出振幅(纵轴)随输入振幅(横轴)的变化,归一化至泵浦脉冲固定振幅ϵs\epsilon_sϵs。无非线性相互作用(κz0ϵs=0.0\kappa z_0\epsilon_s=0.0κz0ϵs=0.0)时为线性激活函数;光学非线性相互作用速率提升,激活函数非线性更显著。
图10 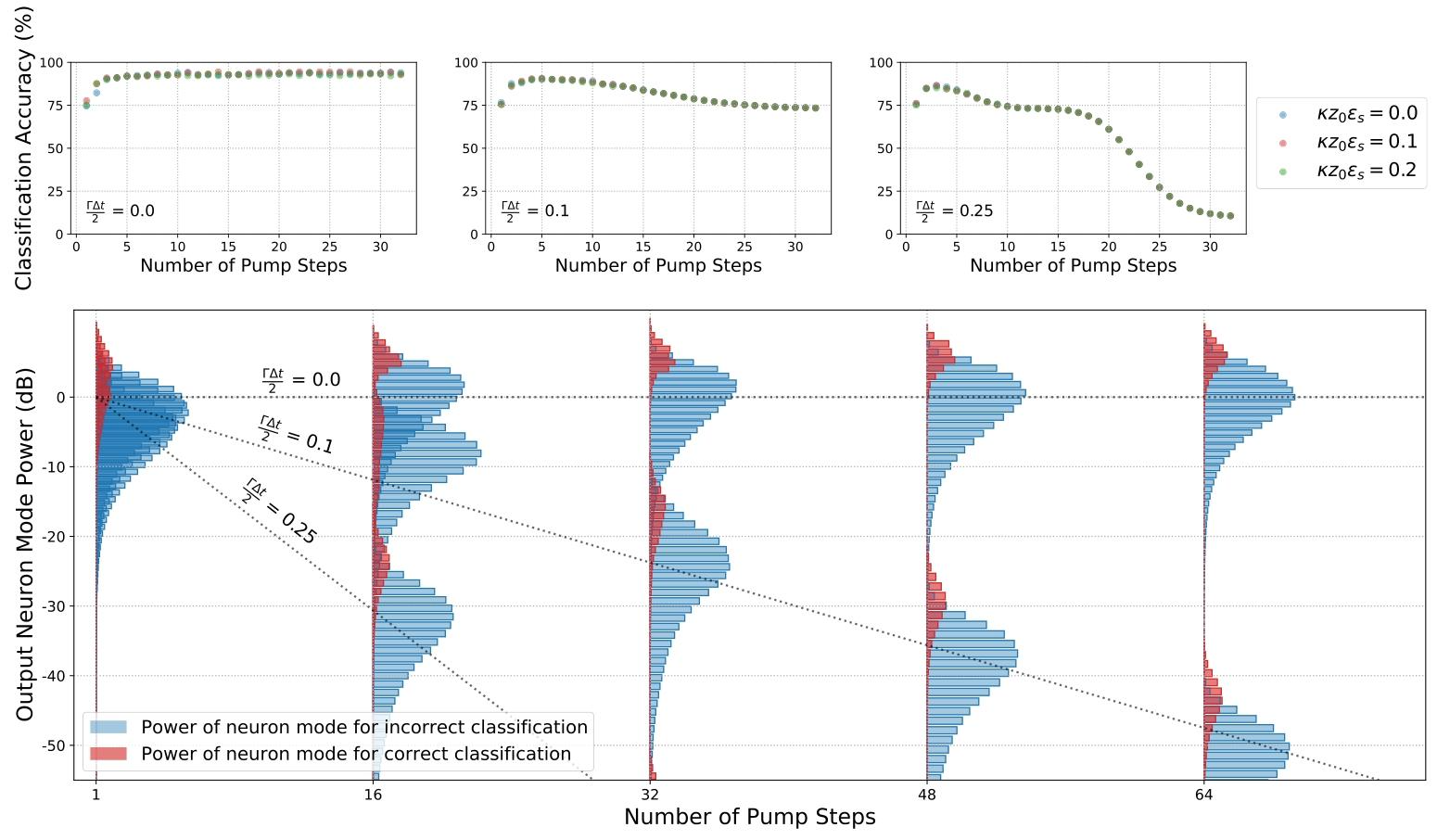
全光神经网络在MNIST数据集上的分类性能,随光学损耗、波导有效非线性、网络尺寸变化。采用不同数量64神经元子层(横轴),后接10个10神经元层。上行展示分类精度(纵轴)随子层数(控制泵浦分段恒定步数,横轴)的变化,三个分图对应不同衰减率Γ\GammaΓ(如ΓΔt2=0.25\frac{\Gamma\Delta t}{2}=0.252ΓΔt=0.25对应步长Δt=1 ns\Delta t=1\ \mathrm{ns}Δt=1 ns、Γ=0.5 ns−1\Gamma=0.5\ \mathrm{ns^{-1}}Γ=0.5 ns−1)。环谐振器间波导非线性强度由标记颜色表示。子层数增加初期,表达能力提升使性能改善;继续增加则导致非幺正行为与表达能力下降,性能恶化。第三分图可观察到损耗增加、散粒噪声主导测量结果时,性能骤降。底部图为输出神经元模式功率直方图。不同子层数(横轴)与损耗率(虚线标注)下,绘制每个神经元模式能量分布(纵轴直方图)。蓝色直方图对应"错误类别"神经元,红色对应"正确类别"神经元(数量更少)。正确类别神经元能量始终更高,表明分类有效;高表达能力下红色直方图分布更集中;子层数增加时,存在损耗情况下模式功率快速衰减,解释了上行右图精度骤降。
图11 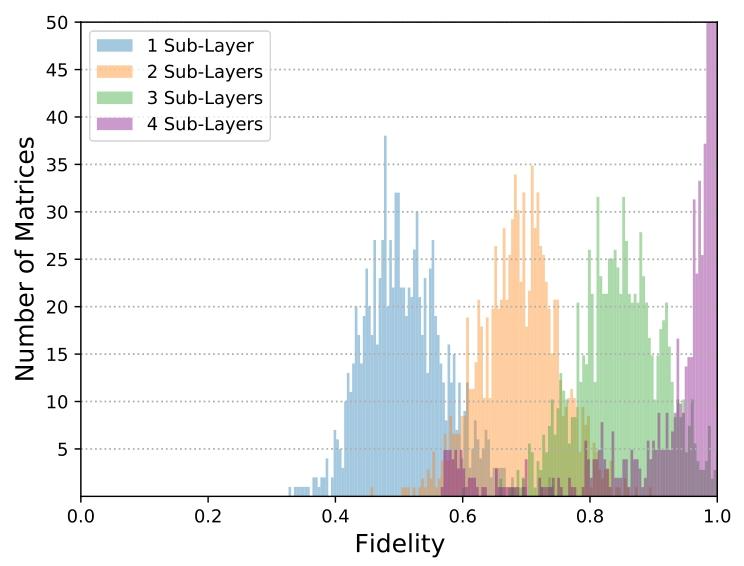
被动耦合变换的优化保真度分布,随所用子层数变化。
图12 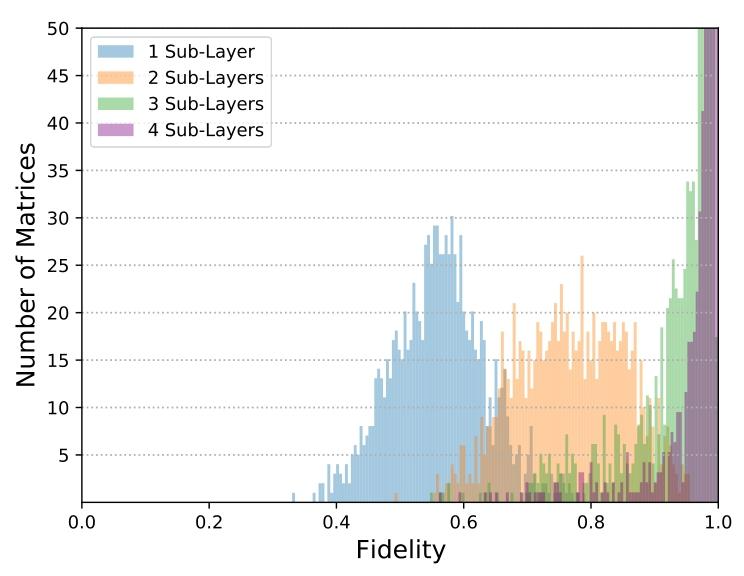
主动耦合变换的优化保真度分布,随所用子层数变化。
图13 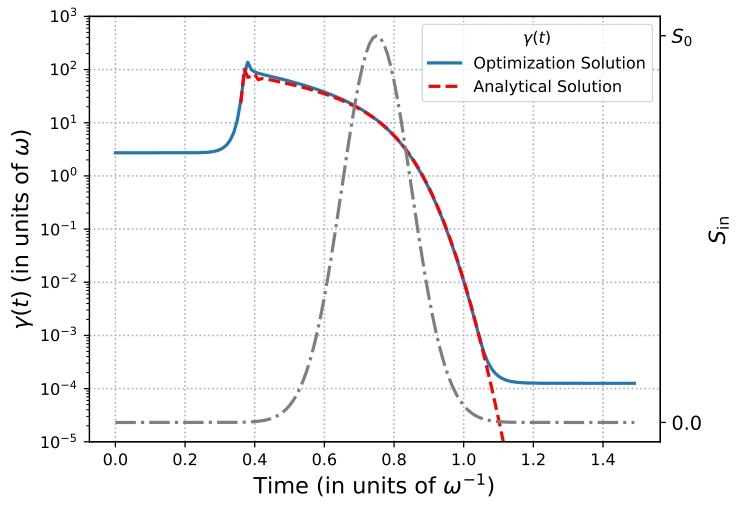
高斯包络入射脉冲的可控耦合系数γ(t)\gamma(t)γ(t)(灰色虚线,右纵轴)。