文章目录
- 前言
- 1.纯PyTorch版本
- [2.PyTorch Lighting版本](#2.PyTorch Lighting版本)
- 结语
前言
最近正在准备毕业设计的相关内容,发现其使用的是PyTorch Lightning和之前的PyTorch有一定的差距,因此就主动了解了它们之间的差距。
如果你用过PyTorch,一定会经历过类似的场景:手动编写训练循环、反复切换model.train()和model.eval()模式、手动管理GPU设备、写一堆日志记录逻辑......这些重复的工程代码占用了大量时间,却与核心的模型研究无关。
PyTorch Lightning正是为了解决这些问题而诞生的。它不是替代PyTorch的新框架,而是在PyTorch之上构建的工程化规范和最佳实践集合。
本篇博客以深度学习领域的"hello world"------MNIST 手写数字分类 为例,介绍两者的区别。
1.纯PyTorch版本
1.1数据集加载
MNIST数据集都不陌生,这里不再赘述了,直接通过torchvision库下载即可,预处理阶段常规的归一化处理,详细过程如下:
python
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# 加载MNIST数据集
transform=transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
)
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)1.2定义网络结构
因为此次重点在于介绍PyTorch Lightning,所以网络结构就使用较为简单的全连接网络
python
from torch import nn
class SimpleMLP(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Flatten(),
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(512, 256),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(256, 10)
)
def forward(self, x):
return self.model(x)1.3训练过程
在训练之前需要选择优化器,损失函数,学习率等内容,这里就随便设置了
python
from torch import optim
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = SimpleMLP().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)模型训练过程这里使用tensorboard进行可视化,判断是否过拟合/欠拟合
python
import time
from torch.utils.tensorboard import SummaryWriter
# TensorBoard日志
writer = SummaryWriter('logs')
for epoch in range(10):
# 训练阶段
model.train()
train_loss = 0
correct = 0
total = 0
start_time = time.time()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
train_loss += loss.item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
total += target.size(0)
train_loss /= len(train_loader)
train_acc = 100. * correct / total
# 验证阶段
model.eval()
val_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
val_loss += criterion(output, target).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
val_loss /= len(test_loader)
val_acc = 100. * correct / len(test_loader.dataset)
# 学习率调度
scheduler.step()
# 日志记录
writer.add_scalar('Loss/train', train_loss, epoch)
writer.add_scalar('Loss/val', val_loss, epoch)
writer.add_scalar('Accuracy/train', train_acc, epoch)
writer.add_scalar('Accuracy/val', val_acc, epoch)
writer.add_scalar('Learning Rate', scheduler.get_last_lr()[0], epoch)
elapsed = time.time() - start_time
print(f'Epoch {epoch+1:2d} | Time: {elapsed:.2f}s | '
f'Train Loss: {train_loss:.4f} Acc: {train_acc:.2f}% | '
f'Val Loss: {val_loss:.4f} Acc: {val_acc:.2f}%')
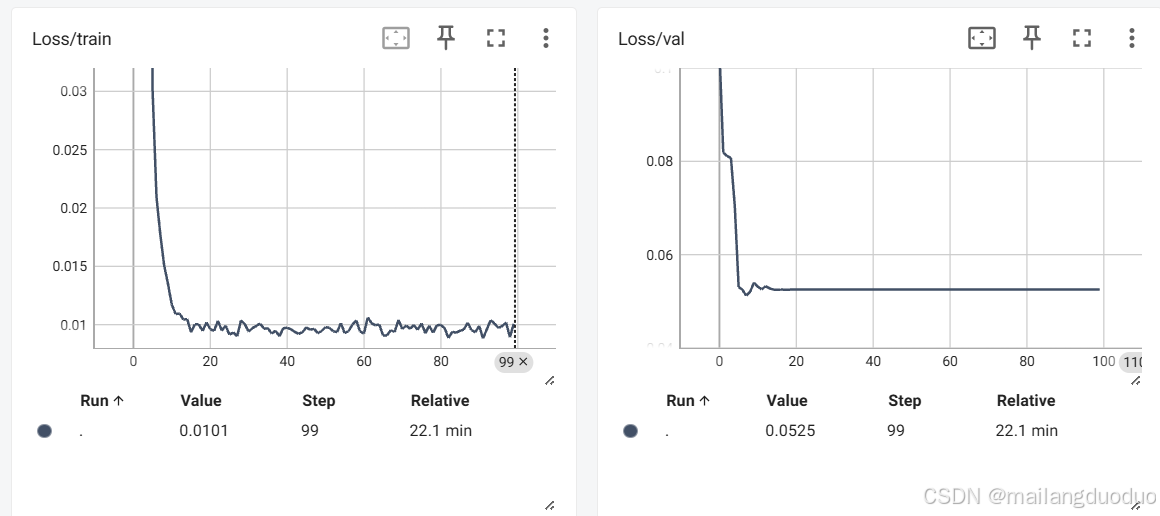
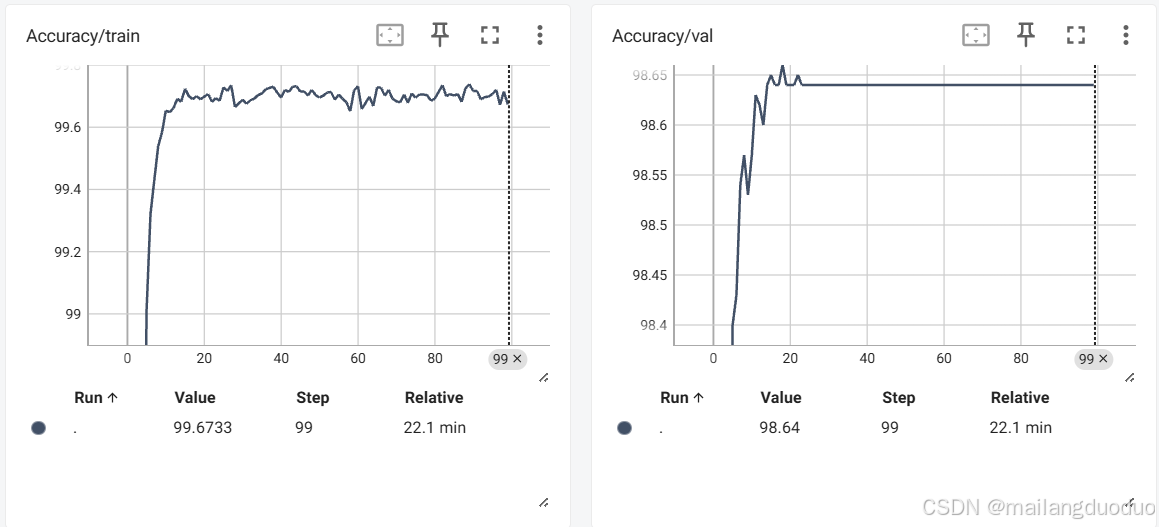
writer.close()通过tensorboard进行可视化,大概收敛在25轮的样子
python
# 模型保存
torch.save(model.state_dict(), 'simple_mlp.pth')
# 模型加载权重
model.load_state_dict(torch.load('simple_mlp.pth'))从上述代码实现逻辑上,可以看出使用PyTorch设备管理(to(device))、梯度清零、反向传播、训练 / 验证循环等逻辑重复编写,同时日志记录、模型保存、学习率调度等功能需要额外实现。
2.PyTorch Lighting版本
2.1 定义数据类
这里使用一个类来定义数据集,PyTorch中的自定义类,一般是如下格式,主要需要定义单个样本如何获取__getitem__和数据集长度__len__
python
class MyDataset(torch.utils.data.DataSet):
def __init__(self, stage ...):
pass
def __len__(self):
pass
def __getitem__(self,idx):
pass
train_data = MyDataset(stage = 'train', ...)
val_data = MyDataset(satge = 'val', ...)在Pytorch Lightning中,这些DataLoader实例需要被包含在一个继承自pytorch_lightning.LightningDataModule的类中,主要封装训练/验证/测试所需的所有数据加载逻辑
在这个类里重写各个方法,返回不同的DataLoader实例:
python
class MNISTDataModule(pl.LightningDataModule):
def __init__(self, batch_size=64, data_dir='./data'):
super().__init__()
self.batch_size = batch_size
self.data_dir = data_dir
self.transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
def prepare_data(self):
# 只在主进程中调用,用于下载数据
datasets.MNIST(self.data_dir, train=True, download=True)
datasets.MNIST(self.data_dir, train=False, download=True)
def setup(self, stage=None):
# 在每个进程中调用,用于划分数据
if stage == 'fit' or stage is None:
mnist_full = datasets.MNIST(self.data_dir, train=True, transform=self.transform)
self.mnist_train, self.mnist_val = random_split(mnist_full, [55000, 5000])
if stage == 'test' or stage is None:
self.mnist_test = datasets.MNIST(self.data_dir, train=False, transform=self.transform)
def train_dataloader(self):
return DataLoader(self.mnist_train, batch_size=self.batch_size, shuffle=True)
def val_dataloader(self):
return DataLoader(self.mnist_val, batch_size=self.batch_size)
def test_dataloader(self):
return DataLoader(self.mnist_test, batch_size=self.batch_size)2.2定义网络结构
同样这里的网络类和之前有所不同,nn.model一般只需定义网络层__init__()和前向传播forward(),而pl.lightingmodule需要额外重写单次训练逻辑training_step、单次验证逻辑validation_step(当然如果没有划分验证集,肯定不需要)、单次测试逻辑test_step、优化器和学习率调度器configure_optimizers等方法。
python
class LitMNIST(pl.LightningModule):
def __init__(self, hidden_size=512, learning_rate=1e-3):
super().__init__()
self.save_hyperparameters() # 自动保存超参数
# 模型架构
self.model = nn.Sequential(
nn.Flatten(),
nn.Linear(28 * 28, hidden_size),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(hidden_size, hidden_size // 2),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(hidden_size // 2, 10)
)
# 损失函数
self.criterion = nn.CrossEntropyLoss()
def forward(self, x):
return self.model(x)
def training_step(self, batch, batch_idx):
"""单步训练逻辑"""
x, y = batch
logits = self(x)
loss = self.criterion(logits, y)
# 计算准确率
preds = torch.argmax(logits, dim=1)
acc = (preds == y).float().mean()
# 自动记录到日志
self.log('train_loss', loss, on_step=False, on_epoch=True, prog_bar=True)
self.log('train_acc', acc, on_step=False, on_epoch=True, prog_bar=True)
return loss
def validation_step(self, batch, batch_idx):
"""单步验证逻辑"""
x, y = batch
logits = self(x)
loss = self.criterion(logits, y)
preds = torch.argmax(logits, dim=1)
acc = (preds == y).float().mean()
self.log('val_loss', loss, on_step=False, on_epoch=True, prog_bar=True)
self.log('val_acc', acc, on_step=False, on_epoch=True, prog_bar=True)
def test_step(self, batch, batch_idx):
"""单步测试逻辑"""
x, y = batch
logits = self(x)
loss = self.criterion(logits, y)
preds = torch.argmax(logits, dim=1)
acc = (preds == y).float().mean()
self.log('test_loss', loss, on_step=False, on_epoch=True)
self.log('test_acc', acc, on_step=False, on_epoch=True)
def configure_optimizers(self):
"""优化器配置"""
optimizer = torch.optim.Adam(self.parameters(), lr=self.hparams.learning_rate)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
return [optimizer], [scheduler]2.3其他配置
在训练过程中,经常需要设计检查点checkpoint,如果使用pytorch版本的话,需要自行设计逻辑,而如果使用PyTorch Lighting的话,就可以直接调用ModelCheckpoint
python
checkpoint_callback = ModelCheckpoint(
monitor='val_acc',
dirpath='checkpoints/',
filename='mnist-{epoch:02d}-{val_acc:.2f}',
save_top_k=3,
mode='max'
)监控val_acc的值保存最大的mode='max'三个save_top_k=3模型权重等信息,保存至 dirpath目录下,文件格式为filename
同理,这里也可以配置早停策略:
python
early_stop_callback = EarlyStopping(
monitor='val_loss',
patience=3,
mode='min'
)监控val_loss,当它连续patience=3个epoch, val_loss不发生变化(min_delta默认值是0.0),则自动停止训练
这里为了可视化训练操作,同样配置训练日志
python
logger = TensorBoardLogger('lightning_logs', name='mnist')2.4模型训练
相比之前PyTorch就很简化了,如下:
python
trainer = pl.Trainer(
max_epochs=50,
accelerator='gpu' if torch.cuda.is_available() else 'cpu',
devices=1 if torch.cuda.is_available() else None,
logger=logger,
callbacks=[checkpoint_callback, early_stop_callback],
log_every_n_steps=10
)
# 开始训练
trainer.fit(model, dm)
# 测试
trainer.test(model, dm)除此之外,Pytorch Lighting更方便之处在于多卡训练,这里博主只有单卡可以供展示,就不再额外添加了,可自行探索。
训练结果,由于设置了早停策略,连续三个epoch,验证集损失没有下降就早停
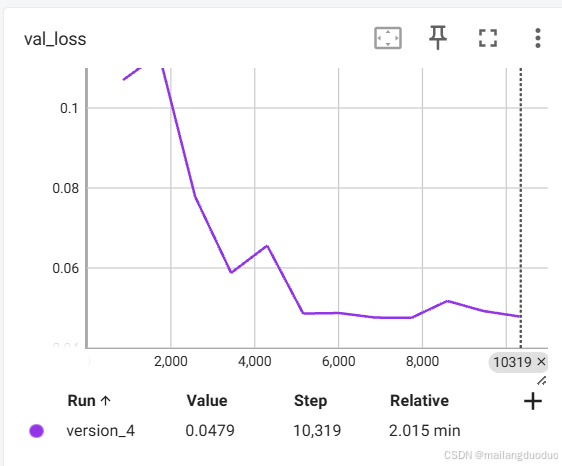
此时发生了早停,训练集的损失下降如图所示:
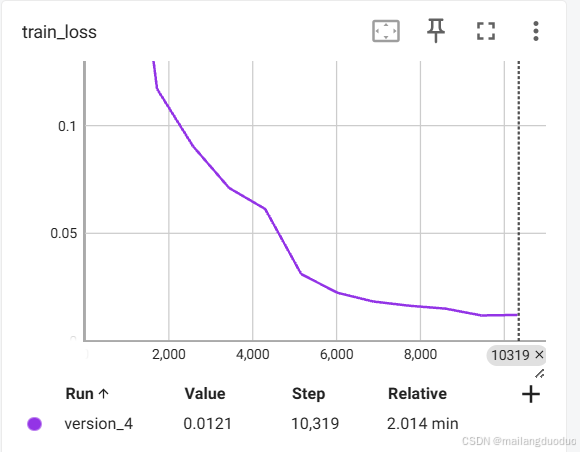
从图可以判断,已经基本收敛。
因为设置了回调函数,模型自动保存val_acc中数值最大的三个模型,此时可以查看,PyTorch和PyTorch Lighting差距还是挺大的,它保存的不只是模型权重,可以简单打印一下:
python
import torch
checkpoint=torch.load('checkpoints/mnist-epoch=10-val_acc=0.99.ckpt')
print(checkpoint.keys())运行结果:
dict_keys('epoch', 'global_step', 'pytorch-lightning_version', 'state_dict', 'loops', 'callbacks', 'optimizer_states', 'lr_schedulers', 'hparams_name', 'hyper_parameters')
如果先保存成PyTorch格式的权重文件,只需要把state_dict键值保存即可
结语
经过上述的小案例可以发现,PyTorch Lighting可以帮助我们简化很多繁琐重复的代码,包括checkpoint模式,这样就不用手动编写继续训练的逻辑了。
至此本篇博客的对比到此结束,如果你用过Keras,你会发现PyTorch Lighting很相似