目录
[3.1 日志级别设计](#3.1 日志级别设计)
[3.2 用户需求说明](#3.2 用户需求说明)
[3.3 本案例的核心思想](#3.3 本案例的核心思想)
[4.1 示例代码](#4.1 示例代码)
[4.2 Powershell 运行结果](#4.2 Powershell 运行结果)
[5.1 先获取用户输入的日志级别](#5.1 先获取用户输入的日志级别)
[5.2 再准备要输出的测试日志](#5.2 再准备要输出的测试日志)
[5.3 日志过滤的核心判断](#5.3 日志过滤的核心判断)
[5.4 为什么这里可以直接比较大小](#5.4 为什么这里可以直接比较大小)
[5.5 switch 在这里起什么作用](#5.5 switch 在这里起什么作用)
[(1)switch 不是"判断和外面传入的 logLevel 比较"](#(1)switch 不是“判断和外面传入的 logLevel 比较”)
[(2)switch 不会影响"后续输出内容"](#(2)switch 不会影响“后续输出内容”)
[六、当前 if 不成立,为什么后续日志还能继续输出](#六、当前 if 不成立,为什么后续日志还能继续输出)
[7.1 本节涉及的核心知识](#7.1 本节涉及的核心知识)
[7.2 这个案例的实战意义](#7.2 这个案例的实战意义)
[7.3 日志流程](#7.3 日志流程)
一、本节学习内容概要图
二、前言
前面我们已经学习了**if / else、switch、enum class、main 函数参数传递**等内容。
如果只是单独看这些语法,很多人会觉得"会写了,但不知道有什么用"。
所以这一节,不再只讲单个语法点,而是通过一个完整的小案例,把这些内容串起来:实现一个最基础的日志模块逻辑。
在实际工程中,日志模块几乎无处不在。程序运行时,经常会输出调试信息、普通信息、错误信息、严重错误信息。
但并不是所有日志都要一直显示出来,通常都会让用户指定一个"最低显示级别",然后程序根据这个级别决定哪些日志该输出,哪些日志不输出。
本节案例代码核心思路:
通过命令行参数控制日志级别,再结合枚举、条件判断和 switch,实现一个最基础的日志过滤功能。
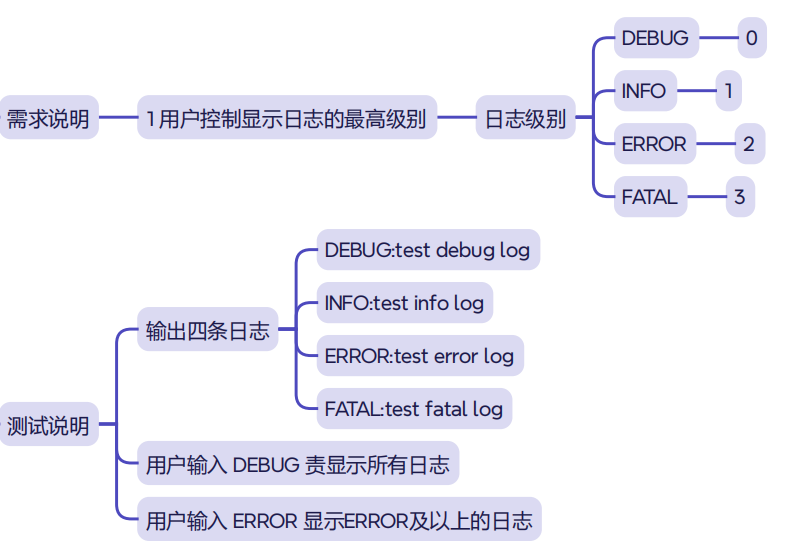
三、案例需求与整体思路
案例的目标:让用户控制程序显示哪一级及以上的日志信息。
3.1 日志级别设计
程序中定义了四种日志级别:
cpp
enum class LogLevel
{
DEBUG,
INFO,
ERROR,
FATAL
};它们默认按顺序对应为:
DEBUG= 0INFO= 1ERROR= 2FATAL= 3
也就是说,日志级别是从低到高逐渐变严重的。
这也是后面能够直接用大小比较来判断日志是否输出的基础。
3.2 用户需求说明
用户运行程序时,可以在命令行(Powershell)中输入一个参数,例如:
bash
.\test_main_log.exe debug
.\test_main_log.exe info
.\test_main_log.exe error
.\test_main_log.exe fatal这个参数表示:用户希望看到的最低日志级别。
例如:
(1)输入
debug
表示显示所有日志。(2)输入
info
表示只显示INFO及以上日志。(3)输入
error
表示只显示ERROR和FATAL日志。(4)输入
fatal
表示只显示最严重的FATAL日志。
3.3 本案例的核心思想
这个案例本质上就是一句话:
当前日志级别如果大于等于用户设置的最低级别,就输出;否则就不输出。
也就是代码中的核心判断:
cpp
if (level >= logLevel)四、完整代码
4.1 示例代码
cpp
#include <iostream>
using namespace std;
enum class LogLevel
{
DEBUG,
INFO,
ERROR,
FATAL
};
int main(int argc,char *argv[])
{
//用户传递日志的最低显示级别
//debug < info < error < fatal
// test_main_log info
auto logLevel = LogLevel::DEBUG;
if (argc > 1)
{
string levelstr = argv[1];
if ("info" == levelstr)
logLevel = LogLevel::INFO;
else if("error" == levelstr)
logLevel = LogLevel::ERROR;
else if ("fatal" == levelstr)
logLevel = LogLevel::FATAL;
}
///测试日志1 debug
{
auto level = LogLevel::DEBUG;
string context = "test log 1";
if (level >= logLevel)
{
string levelstr = "debug";
switch (level)
{
case LogLevel::INFO:
levelstr = "info";break;
case LogLevel::ERROR:
levelstr = "error";break;
case LogLevel::FATAL:
levelstr = "fatal";break;
}
cout << levelstr << ":" << context << endl;
}
}
///测试日志2 INFO
{
auto level = LogLevel::INFO;
string context = "test log 2";
if (level >= logLevel)
{
string levelstr = "debug";
switch (level)
{
case LogLevel::INFO:
levelstr = "info";break;
case LogLevel::ERROR:
levelstr = "error";break;
case LogLevel::FATAL:
levelstr = "fatal";break;
}
cout << levelstr << ":" << context << endl;
}
}
///测试日志3 ERROR
{
auto level = LogLevel::ERROR;
string context = "test log 3";
if (level >= logLevel)
{
string levelstr = "debug";
switch (level)
{
case LogLevel::INFO:
levelstr = "info";break;
case LogLevel::ERROR:
levelstr = "error";break;
case LogLevel::FATAL:
levelstr = "fatal";break;
}
cout << levelstr << ":" << context << endl;
}
}
///测试日志4 FATAL
{
auto level = LogLevel::FATAL;
string context = "test log 4";
if (level >= logLevel)
{
string levelstr = "debug";
switch (level)
{
case LogLevel::INFO:
levelstr = "info";break;
case LogLevel::ERROR:
levelstr = "error";break;
case LogLevel::FATAL:
levelstr = "fatal";break;
}
cout << levelstr << ":" << context << endl;
}
}
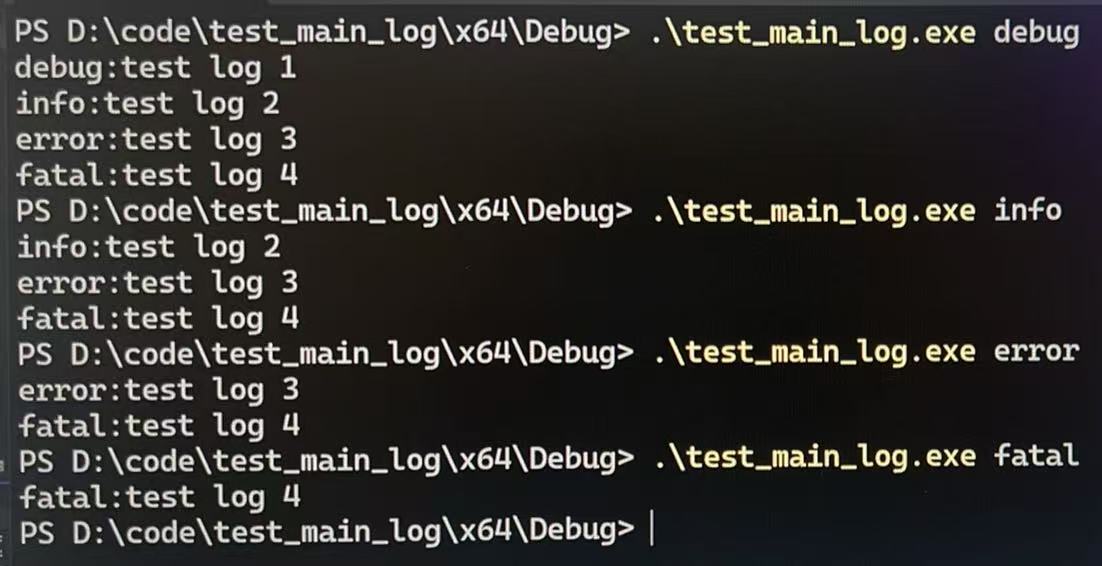
}4.2 Powershell 运行结果
五、代码实现与逻辑分析
5.1 先获取用户输入的日志级别
主函数写法如下:
cpp
int main(int argc, char *argv[])这里:
(1)
argc表示命令行参数个数。
(2)argv表示命令行参数数组。
程序一开始先给出默认值:
cpp
auto logLevel = LogLevel::DEBUG;这表示如果用户没有传参数,那么默认显示所有日志。
接着程序判断用户是否输入了额外参数:
cpp
if (argc > 1)
{
string levelstr = argv[1];
if ("info" == levelstr)
logLevel = LogLevel::INFO;
else if ("error" == levelstr)
logLevel = LogLevel::ERROR;
else if ("fatal" == levelstr)
logLevel = LogLevel::FATAL;
}这里的含义是:
- 如果输入的是
info,最低显示级别改成INFO - 如果输入的是
error,最低显示级别改成ERROR - 如果输入的是
fatal,最低显示级别改成FATAL
至于 debug,代码里没有单独写判断,是因为默认值本来就是 DEBUG,所以即使不写也成立。
5.2 再准备要输出的测试日志
程序里一共模拟了四条日志,分别是:
cpp
DEBUG : test log 1
INFO : test log 2
ERROR : test log 3
FATAL : test log 4例如第一条日志的写法是:
cpp
{
auto level = LogLevel::DEBUG;
string context = "test log 1";
...
}这里:
level表示这条日志本身的级别context表示日志内容
后面的三条日志也完全类似,只是级别和内容不同。
这样设计的好处是很直观,便于我们观察不同级别在不同输入条件下的输出效果。
5.3 日志过滤的核心判断
每一条日志在输出之前,都会先判断:
cpp
if (level >= logLevel)这里一定要分清两个量:
(1)
level
表示当前这一条日志自己的级别。(2)
logLevel
表示用户要求的最低显示级别。
例如用户输入:
cpp
.\test_main_log.exe error那么:
cpp
logLevel = LogLevel::ERROR;这时程序依次判断:
DEBUG >= ERROR不成立,不输出INFO >= ERROR不成立,不输出ERROR >= ERROR成立,输出FATAL >= ERROR成立,输出
所以最后只能看到:
bash
error:test log 3
fatal:test log 4这正好符合日志模块的设计目标。
5.4 为什么这里可以直接比较大小
很多初学者看到这里会有一个疑问:
枚举类型为什么能直接写 >= 比较?
原因就在于这里的枚举值本身是有顺序的。
虽然代码里没有手动写具体数字,但默认就是从 0 开始递增:
cpp
DEBUG = 0
INFO = 1
ERROR = 2
FATAL = 3所以:
cpp
LogLevel::ERROR >= LogLevel::INFO本质上就相当于:
cpp
2 >= 1结果当然为真。
也就是说,这个案例并不是随便定义一个枚举就能这样比较,而是因为 日志级别本身就天然具备"从低到高"的顺序关系,所以非常适合用枚举来表达。
5.5 switch 在这里起什么作用
(1)switch 不是"判断和外面传入的 logLevel 比较"
switch(level) 判断的对象是当前日志自己的级别 level,不是外面的 logLevel。
也就是说:
cpp
switch (level)这里是在看:
当前这条日志到底是 DEBUG、INFO、ERROR 还是 FATAL。
它的作用不是决定"能不能输出",而是决定:
输出时前面的字符串写成什么。
(2)switch 不会影响"后续输出内容"
如果 level 和某个 case 匹配,就把当前这一小段代码里的 levelstr 改成对应字符串,供这一条日志输出使用。
它只是改了当前这一条日志输出前缀,不会影响后面的其他日志块。
比如这一段里:
cpp
string levelstr = "debug";先默认写成 "debug"。
然后:
cpp
switch (level)
{
case LogLevel::INFO:
levelstr = "info";break;
case LogLevel::ERROR:
levelstr = "error";break;
case LogLevel::FATAL:
levelstr = "fatal";break;
}如果 level 是:
INFO,就把levelstr改成"info"ERROR,就改成"error"FATAL,就改成"fatal"
但如果 level 是 DEBUG,由于这里没有写 case LogLevel::DEBUG,就不会进入任何 case,于是:
cpp
levelstr仍然保持最开始的 "debug"。
(3)代码真实逻辑:
1)先判断能不能输出
cpp
if (level >= logLevel)2)如果能输出,再决定输出前缀是什么
cpp
switch (level)3)最后输出
cpp
cout << levelstr << ":" << context << endl;六、当前 if 不成立,为什么后续日志还能继续输出
这里有一个非常容易混淆的地方,需要特别说明。
当程序执行到某一条日志时,会先判断:
cpp
if (level >= logLevel)这个判断 只负责控制当前这一条日志是否输出,并不会让整个程序后面的代码都停止执行。
例如,第一条日志是:
cpp
auto level = LogLevel::DEBUG;如果用户输入的是:
cpp
.\test_main_log.exe info那么此时用户设置的最低显示级别就是:
cpp
logLevel = LogLevel::INFO;因此第一条日志对应的判断就是:
cpp
if (LogLevel::DEBUG >= LogLevel::INFO)这个条件不成立,于是结果只是:
(1)当前这一条
DEBUG日志不输出;
(2)当前这个if大括号内部的switch和cout都不会执行;
(3)程序继续往下运行,去判断下一条日志。
也就是说,程序并不会因为第一条日志没有通过判断,就把后面所有代码都跳过。
它只是跳过了"当前这一条日志对应的输出代码块",然后继续执行下面的 INFO、ERROR、FATAL 日志判断。
可以把它理解成下面这样:
- 第一条日志判断一次
- 第二条日志再判断一次
- 第三条日志再判断一次
- 第四条日志再判断一次
它们彼此是独立的。
所以当用户输入 info 时,程序的执行效果实际上是:
bash
DEBUG >= INFO // 不成立,第一条不输出
INFO >= INFO // 成立,第二条输出
ERROR >= INFO // 成立,第三条输出
FATAL >= INFO // 成立,第四条输出最终结果就是:
bash
info:test log 2
error:test log 3
fatal:test log 4因此,这里一定要明确:
if 语句只决定"当前这一条日志要不要输出",不会阻止程序继续判断后面的日志。
七、小结
这个日志模块虽然不大,但已经把前面学过的多个知识点串联了起来,包括:
7.1 本节涉及的核心知识
(1)使用
enum class表示一组固定状态;
(2)使用argc和argv获取用户输入;
(3)使用if / else if解析命令行参数;
(4)使用关系运算完成日志级别过滤;
(5)使用switch把枚举值转换成可输出字符串。
7.2 这个案例的实战意义
在真正的工程开发中,日志模块是非常常见的功能。
虽然这里写的还是一个简化版,但它已经具备了日志系统最核心的思想:不是所有日志都无条件输出,而是根据设定的级别进行筛选。
7.3 日志流程
- 程序启动后,先将默认最低日志级别设为
LogLevel::DEBUG,这意味如果用户没有额外传参,程序会显示全部日志。- 随后,程序通过
argc和argv读取命令行参数;如果用户输入了info、error或fatal,就把内部的logLevel修改为对应级别。- 接着,程序并不是一次性统一处理所有日志,而是按顺序分别处理四条测试日志:
DEBUG、INFO、ERROR、FATAL。- 每处理一条日志,都会先取出这条日志自己的级别
level,再与用户设置的最低显示级别logLevel进行比较,即判断if (level >= logLevel)是否成立。- 如果成立,说明这条日志应该显示,于是进入
if内部,再通过switch(level)把枚举级别转换成对应的字符串,例如"debug"、"info"、"error"、"fatal",最后与日志内容context一起输出;- 如果条件不成立,则说明这条日志级别不够,不会输出,但程序不会停止,而是继续往下执行,判断下一条日志。
- 正因为每条日志都是独立判断的,所以当用户输入
info时,第一条DEBUG日志会被过滤掉,但后面的INFO、ERROR、FATAL仍然会继续判断并正常输出。
整个模块的核心思想就是:用命令行参数确定最低显示级别,用条件判断决定当前日志是否输出,用 switch 负责把日志级别转换成最终显示给用户的文本。