Elasticsearch 初识篇:核心概念与环境搭建
整理自黑马程序员《SpringCloud微服务开发与实战》Day08-Elasticsearch 课程
核心目标:掌握 ES 基础概念、安装部署、倒排索引原理及 IK 分词器配置。
1. 初识 Elasticsearch
1.1 认识和安装
1.1.1 安装 Elasticsearch
环境准备:
- 系统:Linux (CentOS 7)
- 工具:Docker
- 版本:Elasticsearch 7.12.1 (黑马项目标准版本)
Docker 启动命令:
bash
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network hm-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1关键参数说明:
-e ES_JAVA_OPTS=-Xms512m -Xmx512m:限制 JVM 内存,避免服务器 OOM。-e discovery.type=single-node:设置为单节点模式,适合学习环境。-v:挂载数据卷,保证数据持久化。--network hm-net:加入自定义网络,方便 Kibana 连接。-p 9200:9200:HTTP 端口,用于 REST API 访问。-p 9300:9300:TCP 端口,用于集群通信。
验证安装:
bash
curl http://192.168.150.101:9200/
# 预期返回包含 "name", "cluster_name", "version" 的 JSON 信息1.1.2 安装 Kibana
Kibana 是 ES 的可视化管理工具,支持 DevTools 控制台。
Docker 启动命令:
bash
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=hm-net \
-p 5601:5601 \
kibana:7.12.1验证安装 :
浏览器访问 http://192.168.150.101:5601。
- 首次访问可能需要等待几分钟,待 Kibana 启动完成。
- 进入 Dev Tools 页面,输入
GET /,如果返回集群信息,说明连接成功。
2. 倒排索引 (Inverted Index)
倒排索引是 Elasticsearch 实现极速搜索的核心数据结构。
2.1 正向索引 (Forward Index)
- 定义 :传统数据库使用的索引。通过主键 ID 查找对应的记录内容。
- 原理 :类似书本的目录,先找章节号(ID),再翻到具体页码(内容)。
- 缺点 :执行模糊查询(如
LIKE '%手机%')时,无法利用索引,只能全表扫描,效率极低。
2.2 倒排索引 (Inverted Index)
- 定义:将文档的内容(词条)作为键,包含该内容的文档 ID 列表作为值。
- 原理 :类似书本的索引页。先列出关键词,再指向包含该词的页码。
- 构建步骤 :
- 分词 (Tokenize):将文档内容切分成一个个独立的词条(Token)。
- 标准化 (Normalization):将词条转换为统一格式(如小写、去停用词)。
- 建立索引:记录每个词条出现在哪些文档中。
示例 :
假设有以下两篇文章:
- 文档1:
黑马程序员 SpringCloud - 文档2:
SpringCloud 微服务实战
正向索引(按ID查内容):
| ID | 内容 |
|---|---|
| 1 | 黑马程序员 SpringCloud |
| 2 | SpringCloud 微服务实战 |
倒排索引(按词条查ID):
| Term (词条) | Document IDs (文档ID列表) |
|---|---|
| 黑马程序员 | 1 |
| springcloud | 1, 2 |
| 微服务 | 2 |
| 实战 | 2 |
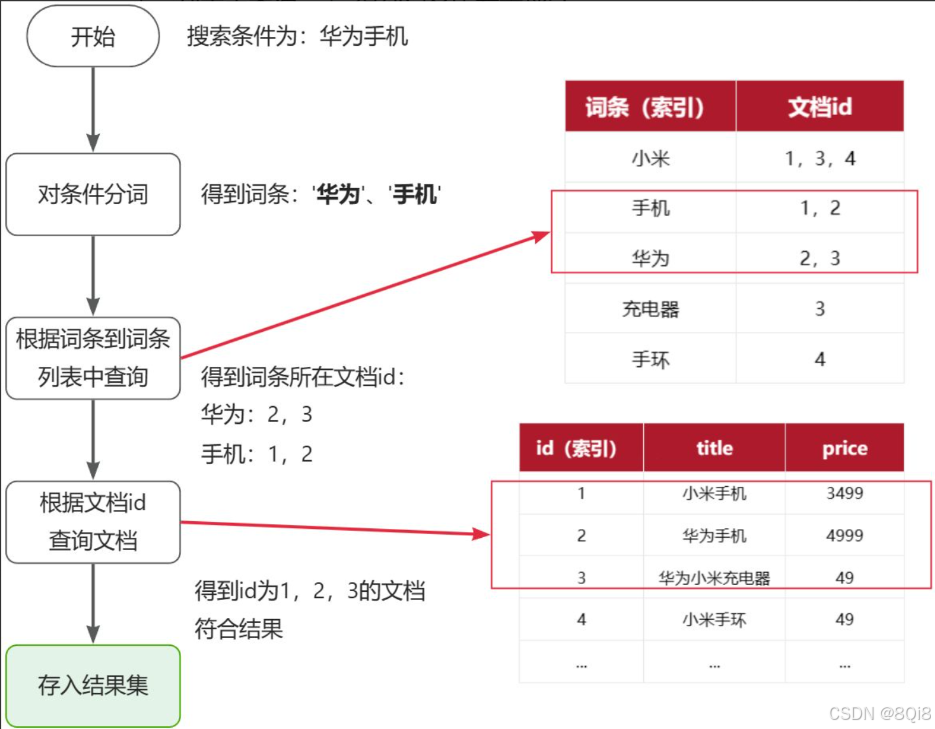
2.3 正向和倒排对比
| 特性 | 正向索引 | 倒排索引 |
|---|---|---|
| 查询方式 | 按 ID 查内容 | 按内容查 ID |
| 模糊查询效率 | 低(全表扫描) | 高(直接定位) |
| 适用场景 | 精确查询、事务处理 | 全文搜索、关键字匹配 |
3. 基础概念
3.1 文档和字段 (Document & Field)
-
Document (文档):
-
ES 中最基本的数据单元 ,通常用 JSON 格式表示。
-
类比于关系型数据库中的 一行记录 (Row)。
-
示例:
json{ "id": 1, "title": "黑马程序员Java教程", "price": 99.9, "brand": "黑马" }
-
-
Field (字段):
- 文档中的一个属性,类似数据库中的一列 (Column)。
- 每个字段都有数据类型和索引规则。
3.2 索引和映射 (Index & Mapping)
-
Index (索引):
- 一组结构相似文档的集合。
- 类比于关系型数据库中的一张表 (Table)。
- 例如:创建一个
product索引,专门存放商品信息。
-
Mapping (映射):
- 类似于数据库的表结构 (Schema),用于定义索引的字段名称、数据类型、是否分词等。
- 关键点 :
- type (类型):字段的数据类型(如 text, keyword, long)。
- index (是否索引):该字段是否参与搜索(默认为 true)。
- analyzer (分词器):指定该字段使用的分词器。
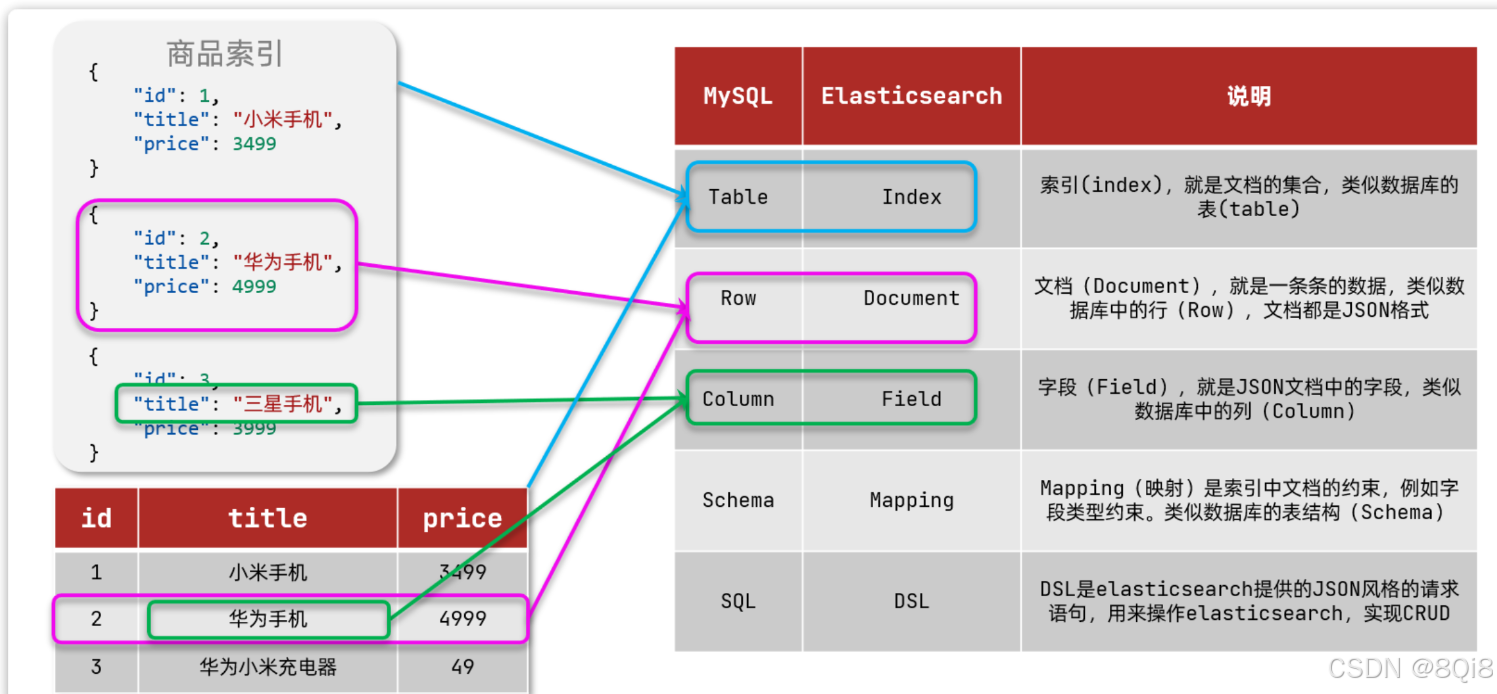
3.3 MySQL 与 Elasticsearch 对比
| Elasticsearch | 关系型数据库 (MySQL) |
|---|---|
| Index | Database (数据库) |
| Type (已废弃) | Table (表) |
| Document | Row (行) |
| Field | Column (列) |
| Mapping | Schema (表结构) |
| DSL | SQL (查询语句) |
4. IK 分词器
4.1 什么是 IK 分词器
- 作用:Elasticsearch 自带的分词器对中文支持不好,会将中文按字拆分(如"黑马"拆成"黑"、"马"),无法满足业务需求。
- IK 分词器 :一款基于 Lucene 开发的中文分词插件,支持中文词语的智能切分。
4.2 安装 IK 分词器
方式一:在线安装(速度慢,不推荐)
bash
docker exec -it es /bin/bash
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
exit
docker restart es方式二:离线安装()
-
将下载好的
elasticse推荐arch-analysis-ik-7.12.1.zip上传到宿主机。 -
复制到容器的 plugins 目录:
bashdocker cp elasticsearch-analysis-ik-7.12.1.zip es:/usr/share/elasticsearch/plugins/ -
进入容器解压并重启:
bashdocker exec -it es /bin/bash cd /usr/share/elasticsearch/plugins/ mkdir ik unzip elasticsearch-analysis-ik-7.12.1.zip -d ik/ exit docker restart es
验证安装 :
在 Kibana DevTools 中执行:
json
POST /_analyze
{
"analyzer": "ik_max_word",
"text": "黑马程序员SpringCloud"
}预期返回包含 黑马程序员、springcloud 等有效分词。
4.3 使用 IK 分词器
IK 分词器提供两种分词模式:
ik_smart:智能切分,粗粒度 。尽可能返回有意义的词语,分次数少。- 示例:
"黑马切程序员"→["黑马", "程序员"]
- 示例:
ik_max_word:最细切分,细粒度 。尽可能多地切分词语,切分次数多。- 示例:
"黑马程序员"→["黑马", "程序员", "黑", "马"]
- 示例:
在 Mapping 中指定分词器:
json
PUT /product
{
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_smart", // 写入时分词
"search_analyzer": "ik_smart" // 搜索时分词
},
"brand": {
"type": "keyword" // 精确匹配,不分词
}
}
}
}4.4 拓展词典
需求:当业务中出现新词(如"白嫖"、"黑丝")时,IK 默认词典中没有,会导致分词错误(如"白嫖"被切成"白"、"嫖")。
配置步骤:
-
进入 IK 插件配置目录:
bashdocker exec -it es /bin/bash cd /usr/share/elasticsearch/plugins/ik/config -
编辑
IKAnalyzer.cfg.xml文件,添加自定义词典路径:xml<properties> <comment>IK Analyzer 扩展配置</comment> <entry key="ext_dict">ext.dic</entry> <entry key="ext_stopwords">stopword.dic</entry> </properties> -
创建
ext.dic文件并添加新词(每行一个):text白嫖 黑丝 艾许 -
重启 ES 容器:
bashexit docker restart es -
再次测试分词,新词将被作为一个整体词条返回。
4.5 总结
- Elasticsearch 是基于 Lucene 的分布式搜索引擎,核心是倒排索引。
- 安装:通过 Docker 部署 ES 和 Kibana,注意内存限制和网络配置。
- 概念:Index (库)、Document (行)、Field (列)、Mapping (表结构)。
- 分词 :中文必须使用 IK 分词器 ,推荐使用
ik_smart模式。 - 扩展:通过自定义词典解决业务新词的识别问题。