有试过编译程序吗,主要用哪些工具。
编译程序,将程序员所写的代码转换成计算机能够识别的可执行程序,程序运行:
- 预编译:将头文件编译,进行宏替换,输出.i文件
- 编译:将其转化为汇编语言文件,主要做词法分析,语义分析以及检查错误,检查无误后将代码翻译成编译语言,生成.s文件
- 汇编:汇编器将汇编语言文件翻译成机器语言,生成.o文件(二进制文件)
- 链接:将目标文件和库链接到一起,生成可执行文件
编译工具gcc与g++
GCC(GNU Compiler Collection)是一个强大的编译器套件,支持多种编程语言。
GCC包含多个编译器前端和一个通用的后端。这个通用后端负责将中间表示(由前端生成的,通常是汇编代码)转换成目标机器代码。
gcc(GNU C Compiler)是GCC的一个组成部分,它是GCC编译器集合中用于编译C(以及其他语言)的命令行工具和驱动程序。gcc和g++都属于GCC(也可以叫GNU组织),gdb是GNU的调试器。
实际使用中,我们更习惯用gcc指令编译C语言程序,使用g++指令编译C++代码。但是gcc 指令也可以用来编译 C++ 程序,同样 g++ 指令也可以用于编译 C 语言程序。
(1)后缀为.c的, gcc 把它当作是 c程序,而g++当作是 c++程序;
(2)后缀为.cpp 的,两者都会认为是C++程序,c++的语法规则更加严谨一些,编译阶段对于c++代码, gcc会调用g++,因为gcc命令不能自动和c++程序使用的库联接,通常用g++来完成链接, 为了统一起见,干脆编译/链接统统用g++ 了,这就给人―种错觉,好像cpp程序只能用g++似的;
(3)编译可以用gcc/g++,而链接可以用g++或者gcc -lstdc++;gcc命令不能自动和C++程序使用的库联接.所以通常使用g++来完成联接。但在编译阶段, gcc会自动调用g++,二者等价。
make和makefile
当我们的程序只有一个源文件时,直接就可以用gcc命令编译它。但是,如果我们的程序包含很多个源文件时,就需要用make工具来进行编译。
make工具可以看成一个智能的批处理工具 ,它本身没有编译 和链接的功能,而是类似于批处理的方式-通过调用makefile文件中用户指定的命令来进行编译和链接。
make工具就根据makefile中的命令进行编译和链接,makefile中就包含了调用gcc(也可以是别的编译器)去编译某个源文件的命令。
cmake和cmakelist
cmake可以更加简单生成makefile文件给上面的make用,而且cmake还是一个很好用的跨平台编译工具,就是可以跨平台生成对应平台能用的makefile。
cmake需要根据CMakeLists.txt文件生成makefile文件。
nmake是Microsoft Visual Studio中的附带命令,需要安装VS,实际上可以说相当于linux的make。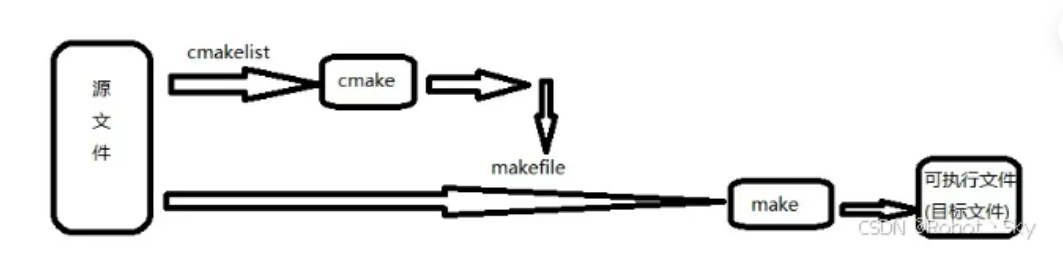
VScode中CPP编译调试环境配置
VScode通过项目文件夹来管理项目,项目的配置文件保存在.vscode文件夹中,其中
- tasks.json (compiler build settings) ,负责编译
- launch.json (debugger settings),负责调试
- c_cpp_properties.json (compiler path and IntelliSense settings),负责更改路径等设置
- setting.json,负责vsode编辑器和插件的相关配置工作
- extensions.json,负责推荐当前项目中使用的插件
详细看:
关于gcc和g++版本,通常在/usr/bin/gcc。。
usr是指Unix System Resource,而不是User。
/usr/bin下面都是系统预装的可执行程序,系统升级有可能会被覆盖。
/usr/local/bin目录是给用户放置自己的可执行程序,不会被系统升级而覆盖同名文件
/bin、/sbin、/usr/bin、/usr/sbin、/usr/local/bin、/user/local/sbin都是存放可执行文件的目录,但各有特定用途。
Linux下开发的调试命令有哪些,常用的命令和一些管理内存、进程的命令
GDB(GNU symbolic debugger),看名称可以知道如上gcc、g++都诞生至于GNU计划,是Unix及Unix-like下常用的程序调试工具。
- 程序启动时可以按照自定义的要求运行程序,例如设置参数和环境变量
- 使程序在指定条件下停止 ,并查看此时程序的运行状态(查看变量或表达式的值)
- 程序执行过程中,可以修改程序中内容
基于Linux系统是免费、开源,Linux也衍生出了不同的发行版本。LInux发行版可以分为两个系列,分为RedHat系列和Dibian
系列,不同的Linux发行版,系统管理包的工具也不同,所有安装的指令也不同。
RedHat系列代表Linux发行版有RedHat、CentOS、Fedora等,使用yum作为包管理器。RedHat系列的Linux发行版通过在命令行 窗口中执行sudo yum -y install gdb 指令,即可完成GDB调试器的安装。
Debian系列代表Linux发行版有Debian、Ubuntu等,使用apt作为包管理器。这系列的Linux发行版通过执行sudo apt -y install gdb 指令,既可完成GDB调试器的安装。
查看GDB调试器是否安装成功,在命令行窗口中执行gdb -v,执行结果如下图所示则表示安装GDB调试器成功。

GDB调试需要程序与GDB调试器一起运行在,则必须指示编译器将调试信息放到程序的代码对象中。
这些调试信息也称为是调试符号或符号信息,它们包含函数和变量的名称以及CPU指令、源文件和行号之间的关系。
对于GNU编译器gcc和大部分编译器来说,进行调试的编译器标志是-g,所以在编译程序的指令后面加上-g才能生成满足调试的可执行文件。
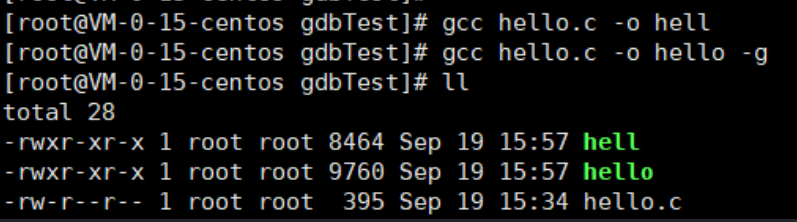
默认优化模式下的编译程序指令:gcc hello.c -o hell,生成可执行文件hell,大小为8464
程序调试模式下的编译程序指令:gcc hello.c -o hello -g,生成可调试的可执行文件hello,大小为9760常用调试命令,run启动目标程序(r),start,break location(b),break...if cond条件断点,watch cond观察断点,catch event捕捉断点,单步调试next(n)count,step(s)count,until(u),查看输出print(p)num,display,删除clear,delete,禁用disable。。。。详细看上面链接深入学习。。还没遇到考这个。。。
Linux常用命令
关于Shell ,Shell 是操作系统与用户之间的桥梁 ,它接收用户输入的命令,并调用系统内核去执行相应的任务。在 Linux 系统中,最常用的 Shell 是 Bash(Bourne Again Shell)。我们平时在终端中输入的命令,实际上都是通过 Shell 来解析和执行的。
Shell命令 :Shell 不仅是一个交互工具,更是一种具备编程能力的"命令解释器"。它允许我们将多个命令写入一个脚本文件中,批量执行,从而实现自动化操作。
Shell 命令是 Linux 系统操作的核心工具,比如我们常用的 ls、cd、cp、echo 等命令,都是在 Shell 中运行的指令。
Shell 脚本: 是一系列 Shell 命令的集合 ,保存在一个文本文件中,按照顺序依次执行。 通俗地讲:你在终端一个个敲的命令,可以提前写进一个**.sh**文件中,将其变成一个"可执行的任务集合",以后只需要运行这个文件,就能一次性执行所有操作,无需手动重复输入。
- Shell 是工具,负责与系统交互
- Shell 命令是操作单位 ,如
ls,rm,echo(常用的liunx命令很多都是shell命令) - Shell 脚本是程序,可以批量执行命令,实现自动化处理
搜索命令
bash
find / -name 'b' 查询根目录下(包括子目录),名以b的目录和文件;
find / -name 'b*' 查询根目录下(包括子目录),名以b开头的目录和文件;
find . -name 'b' 查询当前目录下(包括子目录),名以b的目录和文件;重命名
bash
mv 原先目录 文件的名称 mv tomcat001 tomcat 剪切命令(有目录剪切到制定目录下,没有的话剪切为指定目录)
bash
mv /aaa /bbb 将根目录下的aaa目录,移动到bbb目录下(假如没有bbb目录,则重命名为bbb);
mv bbbb usr/bbb 将当前目录下的bbbb目录,移动到usr目录下,并且修改名称为bbb;
mv bbb usr/aaa 将当前目录下的bbbb目录,移动到usr目录下,并且修改名称为aaa;内存管理命令
-
free :显示系统中物理内存(RAM)和交换空间(swap)使用情况 的工具。查看当前系统未使用和已使用的内存,以及被内核使用的内存缓冲区。默认以kb为单位。
bashfree -m free -h free free -m -s 5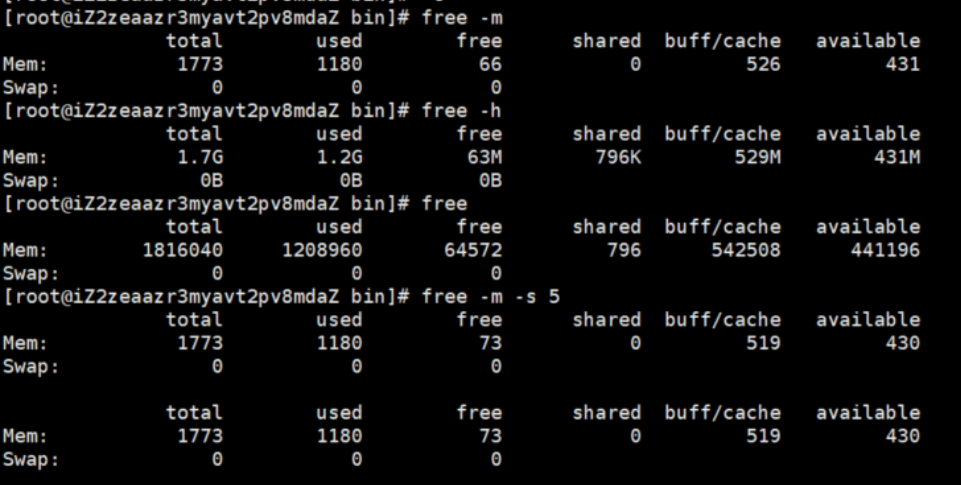
-
df :用于显示文件系统的磁盘空间 使用情况.
bashdf -hT df df -mT df -h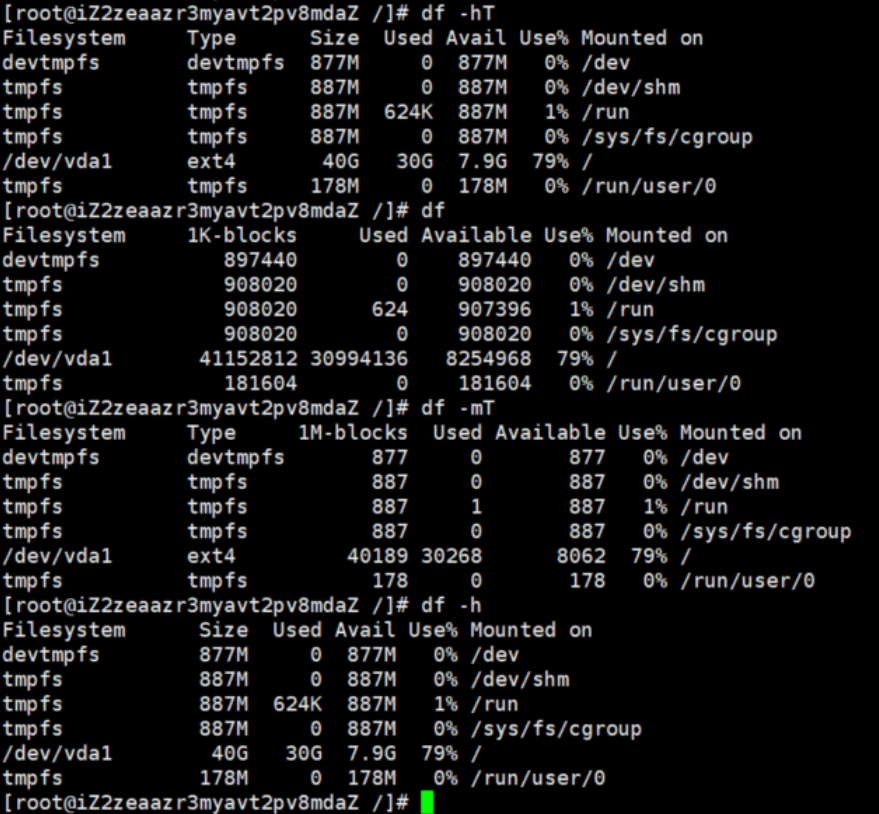
-
du :用于显示文件和目录的磁盘使用情况。它可以递归地显示目录下每个文件和子目录的大小,也可以显示单个文件的大小。
bashdu ./* -hsc du ./* -hs du -sh * ### 建议用这个 -
mount:用于将文件系统(如硬盘分区、USB驱动器、网络文件系统等)挂载到指定的挂载点,使其可以被访问,一般需要root权限
-
dumpsys meminfo:查看进程或包名的内存使用情况
-
cat /proc/meminfo:记录系统内存的使用情况
-
MemTotal:可用的总内存大小
-
MemFree:当前还没有被用到的内存
-
MemAvailable:应用程序可用内存大小,系统中有些内存虽然被使用但是可以回收,MemFree不能代表所有可用内存,要加上可回收的部分
。。。还有一些其他命令。。
进程相关命令
-
ps :显示当前进程的状态(Process Status)
bash// 显示所有进程的详细信息 ps -aux // 列出所有的进程,相比 ps -aux 信息要少一些 ps -ef 使用 ps -ef | grep "可执行文件名" 查找进程 -
top:实时显示进程的信息
bashtop [-] [i] [n数字] i:不显示任何闲置 (idle) 或无用 (zombie) 的进程 n:更新的次数,完成后将会退出top 常用说法 // 不显示任何闲置 (idle) 或无用 (zombie) 的进程 top -i // 更数指定次数后,退出top命令 top -n数字 -
pstree:将所有的进程以树型结构的方式进行展示
-
kill:用于结束进程的命令或者用于显示相关信号
网络相关命令
- ifconfig:显示或设置网络设备
- ip:与ifconfig类似
- ping:检测主机
- route:显示和操作ip路由表
- lsof:查看进程打开的文件的工具
- netstat:查看当前操作系统的网络连接状态
再补充把。。。
define和模板的区别
define是在编译程序的预处理 阶段纯文本替换 ,无类型检查 ,宏出现几次就会被执行替换几次 ;而template类型参数化是在编译阶段 阶段带类型检查 ,的泛型编程 ,根据传入的模板实参,实例化出对应类型的具体函数,代码。参数仅在调用时求值一次。
为什么基类有子类基础的时候基类的析构要写成虚函数
主要是为了确保在删除基类指针指向的派生类对象 时,派生类的析构函数能够正确调用,避免内存泄漏或未释放的资源。
如果基类的析构函数不是虚函数 ,当基类指针指向派生类对象,并通过基类指针删除对象时,**只会调用基类的析构函数,不会调用派生类的析构函数,**导致派生类的资源没有释放,造成内存泄漏。
这不得不谈一下构造析构的调用顺序。
全局变量、静态变量和局部变量
- 全局变量在程序开始时调用构造函数、在程序结束时调用析构函数。
- 静态变量在所在函数第一次被调用时调用构造函数、在程序结束时调用析构函数,只调用一次。
- 局部变量在所在的代码段被执行时调用构造函数,在离开其所在作用域(大括号括起来的区域)时调用析构函数。可以调用任意多次。
每次调用析构函数时总是析构最近被构造的、且没有被析构的对象。也就是:先被构造的对象后被析构,析构顺序恰与构造顺序相反。
- 先调用基类的构造函数
- 再调用子对象类(成员变量)的构造函数
- 最后调用派生类的构造函数
- 调用顺序与派生类构造函数冒号后面给出的初始化列表(Derived(): m1(), m2(), Base1(), Base2())没有任何关系,按照继承的顺序和变量再类里面定义的顺序进行初始化。 先继承Base2,就先构造Base2。先定义m2,就先构造m2。
- 析构函数调用顺序仍然与构造函数构造顺序相反。
这里相反就说明,先从派生类开始析构,再到基类。。所以先从基类指针指向的派生类析构函数调用,如果不是虚函数就无法完全清理掉派生类的资源。!!!
使用父类指针指向子类时,当父类析构函数为非虚函数时,只会调用父类的析构函数 ,子类的析构函数不会被调用 ,从而造成内存泄漏。而把父类的析构函数定为虚函数之后,再使用父类执行指向子类并且删除该对象时,会先调用派生类的析构函数,再调用基类的析构函数
析构函数的作用
释放对象占用的资源,如动态分配的内存、打开的文件、数据库连接等。
析构函数和delete的区别
在所有函数之外创建的对象为全局对象,与全局变量类似,位于内存分区的全局数据区,程序在结束时,会调用这些对象的析构函数。
在函数内部创建的对象是局域对象,它与局部变量类似,位于栈区,函数结束时会调用它们的析构函数;
而new创建的对象位于堆区,在通过delete删除时才会调用析构函数;如果没有delete,则析构函数就不会被调用。!!
栈:由编译器管理分配和回收,存放局部变量和函数参数。
堆:由程序员管理,需要手动 new malloc delete free 进行分配和回收,空间较大,但可能会出现内存泄漏和空闲碎片的情况。
全局/静态存储区:分为初始化和未初始化两个相邻区域,存储初始化和未初始化的全局变量和静态变量。
常量存储区:存储常量,一般不允许修改。
代码区:存放程序的二进制代码。
指针和引用的区别,什么时候分别用什么
引用和指针都是C++中用来间接访问内存中对象的机制,
- 引用 ,是某个变量的别名,在声明时必须被初始化,并且初始化后不能改变引用的目标
- 指针 ,是一个变量,它存储另一个变量的内存地址,指针可以在运行时被重新赋值,并且可以为空nullptr
|---|----------------------------|--------------------------------|
| | 指针* | 引用& |
| | 声明时不用初始化 | 声明时必须进行初始化 |
| | 需要使用解引用运算符*访问指针所指向的对象 | 引用直接使用对象的名字来访问所引用的对象,无需解引用 |
| | 指针有自己的内存地址 | 引用本身没有自己的内存地址 |
| | 指针可以是nullptr | 引用不能指向nullptr或者无效的对象 |
| | 指针通过解引用修改所指对象的值 | 引用可以修改所引用对象的值,引用本质上就是对该对象的直接访问 |
1**.指针是一个实体,而引用是一个别名** ;**在汇编上,引用的底层是以指针的方式实现的,**定义一个引用变量,相当于就是定义了一个指针,然后把引用内存的地址写到这个指针里面,当通过引用变量修改它所引用的内存时,它先访问了指针里面的地址,然后在这个地址的内存里面对值进行修改
2.指针可以不初始化 ,通过赋值可以指向任意同类型的内存;但是引用必须初始化,而且引用一经引用一块内存,再也不能引用其它内存了,即引用不能被改变
3.在进行 sizeof 操作时, sizeof 指针在 32 位系统下永远是 4 个字节,而 sizeof 引用计算的 是它所引用内存的大小
4.引用是内存单元的别名,不是数值的别名。如int &a=10;//error,底层是指向10的地址,引用不能引用不能取地址的数据
5.引用只能使用引用变量所引用的数据,例如b是a的别名,b只能使用a的数据
很多说法。。。。大概意思
来一个手撕。
双向链表
与普通的单向链表不同之处在于,每个节点除了存储数据元素外,还存储着指向前一个节点和后一个节点的指针
cpp
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
//定义双向链表中节点的结构
typedef int LDateType;
typedef struct ListNode {
LDateType date;
struct ListNode* prev;
struct ListNode* next;
}LNode;
//注意,双向链表带有哨兵位,插入数据之前必须要初始化哨兵位
/*void LInit(LNode** plist);*///初始化哨兵位
LNode* LInit();//无需传参初始化哨兵位(函数里面创建哨兵位)
//申请节点
LNode* LBuyNode(LDateType x);
//不需要改变哨兵位,则不需要传二级指针
void LPushBack(LNode* pphead, LDateType x);//尾插
void LPushFront(LNode* phead, LDateType x);//头插(在第一个有效节点之前插入)
//打印双向链表
void LPrint(LNode* phead);
//头删
void LPopFront(LNode* phead);
//尾删
void LPopBack(LNode* phead);
//指定位置之后插入数据
void LInsert(LNode* pos, LDateType x);
//删除pos位置的数据
void LErase(LNode* pos);
//查找
LNode* LFind(LNode* phead, LDateType x);
//链表销毁
void LDestroy(LNode** pphead);//这里是用二级指针销毁
//推荐一级 ------>(保持接口一致性)
cpp
#include "List.h"
//void LInit(LNode** pphead)
//{
// *pphead = (LNode*)malloc(sizeof(LNode));
// if (*pphead == NULL)
// {
// perror("malloc fail!");
// exit(1);
// }
// (*pphead)->date = -1;//该数据无作用
// (*pphead)->next = (*pphead)->prev = *pphead;//或者NULL
//}
LNode* LInit()
{
//创建一个哨兵位
LNode* phead = LBuyNode(-1);
return phead;
}
//申请节点
LNode* LBuyNode(LDateType x) {
LNode* newnode = (LNode*)malloc(sizeof(LNode));
if (newnode == NULL)
{
perror("malloc fail");
exit(1);
}
newnode->date = x;
newnode->next = newnode->prev = newnode;
return newnode;
}
//链表的打印
void LPrint(LNode* phead) {
assert(phead);
LNode* pcur = phead->next;
while (pcur != phead)
{
printf("%d->", pcur->date);
pcur = pcur->next;
}
printf("\n");
}
//尾插和头插
void LPushBack(LNode* phead, LDateType x)
{
assert(phead);//双向链表第一个节点不可能为空,无需assert*phead
LNode* newnode = LBuyNode(x);
//phead phead->prev(ptail) newnode 修改指针连接
newnode->next = phead;
newnode->prev = phead->prev;
(phead->prev)->next = newnode;
phead->prev = newnode;
}
void LPushFront(LNode* phead, LDateType x)
{
assert(phead);
LNode* newnode = LBuyNode(x);
// phead newnode phead->next 修改这三个节点的连接
newnode->next = phead->next;
newnode->prev = phead;
phead->next->prev = newnode;
phead->next = newnode;
}
void LPopBack(LNode* phead) {
assert(phead);
//若哨兵位节点的next指针或prev指针指向的是自己,则链表为空
assert(phead->next != phead);
LNode* del = phead->prev;
LNode* prev = del->prev;
//实现结果一致,无需分情况讨论,
prev->next = phead;
phead->prev = prev;
free(del);
del = NULL;
}
void LPopFront(LNode* phead) {
assert(phead);
assert(phead->next != phead);
LNode* del = phead->next;
LNode* next = del->next;
//改变指针指向,删除指定节点即可
next->prev = phead;
phead->next = next;
free(del);
del = NULL;
}
LNode* LFind(LNode* phead, LDateType x) {
assert(phead);
LNode* pcur = phead->next;
while (pcur != phead)
{
if (pcur->date == x)
{
return pcur;
}
pcur = pcur->next;
}
return NULL;
}
void LInsert(LNode* pos, LDateType x) {
assert(pos);
LNode* newnode = LBuyNode(x);
//pos newnode pos->next
newnode->next = pos->next;
newnode->prev = pos;
pos->next->prev = newnode;
pos->next = newnode;
}
void LErase(LNode* pos) {
assert(pos);
//pos->prev pos pos->next
pos->next->prev = pos->prev;
pos->prev->next = pos->next;
free(pos);
pos = NULL;
}
void LDestroy(LNode** pphead) {
assert(pphead);
//哨兵位不能为空
assert(*pphead);
LNode* pcur = (*pphead)->next;
while (pcur != *pphead)
{
LNode* next = pcur->next;
free(pcur);
pcur = next;
}
//最后链表只剩哨兵位
//销毁哨兵位
free(*pphead);
*pphead = NULL;
}测试
cpp
#include "List.h"
//void ListTest01() {
// LNode* plist = NULL;
// LInit(&plist);
//}
void ListTest02() {
LNode* plist = LInit();//初始化
//尾插
LPushBack(plist, 1);
LPushBack(plist, 3);
LPushBack(plist, 5);
LPrint(plist);
}
void ListTest03() {
LNode* plist = LInit();//初始化
//尾插
LPushFront(plist, 1);
LPushFront(plist, 3);
LPushFront(plist, 5);
LPrint(plist);
LPopBack(plist);
LPrint(plist);
LPopBack(plist);
LPrint(plist);
LPopBack(plist);
LPrint(plist);
}
void ListTest04()
{
LNode* plist = LInit();//初始化
//尾插
LPushFront(plist, 1);
LPushFront(plist, 3);
LPushFront(plist, 5);
LPrint(plist);
LPopFront(plist);
LPrint(plist);
LPopFront(plist);
LPrint(plist);
LPopFront(plist);
LPrint(plist);
}
void ListTest05()
{
LNode* plist = LInit();//初始化
//尾插
LPushFront(plist, 1);
LPushFront(plist, 3);
LPushFront(plist, 5);
LPrint(plist);
LNode* findRet1 = LFind(plist, 2);
if (findRet1 == NULL) printf("未找到!\n");
else printf("找到了!\n");
LNode* findRet2 = LFind(plist, 3);
if (findRet2 == NULL) printf("未找到!\n");
else printf("找到了!\n");
}
void ListTest06()
{
LNode* plist = LInit();//初始化
//尾插
LPushFront(plist, 1);
LPushFront(plist, 3);
LPushFront(plist, 5);
LPrint(plist);
LNode* findRet1 = LFind(plist, 3);
LInsert(findRet1, 666);
LPrint(plist);
LNode* findRet2 = LFind(plist, 666);
LErase(findRet2);
LPrint(plist);
LDestroy(&plist);
}
int main()
{
//ListTest01();//由传址的哨兵位初始化
//ListTest02();//初始化+尾插
//ListTest03();//头插+尾删
//ListTest04();//头删
//ListTest05();//查找
ListTest06();//在指定位置之后插入数据,删除数据,销毁链表
return 0;
}后序遍历
递归
cpp
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector res;
void traversal(TreeNode* root) {
if (root == nullptr) return ;
traversal(root->left);
traversal(root->right);
res.push_back(root->val);
}
vector postorderTraversal(TreeNode* root) {
traversal(root);
return res;
}
};迭代
cpp
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector postorderTraversal(TreeNode* root) {
vector res;
stack st;
if (root != nullptr) st.push(root);
while (!st.empty()) {
TreeNode* node = st.top();
st.pop();
res.push_back(node->val);
if (node->left != nullptr) st.push(node->left);
if (node->right != nullptr) st.push(node->right);
//栈先进后出
}
reverse(res.begin(), res.end());
return res;
}
};层序遍历
cpp
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector> levelOrder(TreeNode* root) {
vector> res;
queue que;
if (root != nullptr) que.push(root);
while (!que.empty()) {
vector vec;
int size = que.size();
for (int i = 0; i < size; i++) {
TreeNode* node = que.front();
que.pop();
vec.push_back(node->val);
if (node->left != nullptr) que.push(node->left);
if (node->right != nullptr) que.push(node->right);
}
res.push_back(vec);
}
return res;
}
};C++11中,swap、move和拷贝构造的区别和使用场景
- swap:交换 两对象的资源或内容,适用于快速交换大对象或容器
- move:转移对象资源到新对象,原对象置空,适用于返回值、临时对象优化
- 拷贝构造:创建新对象并拷贝原对象内容,适用于需要保留原对象时
**swap是互换,move是转移,拷贝构造是复制。**选择策略可显著影响性能。
什么是RVO(返回值优化)?结合C++11的move构造说明高效返回对象的方法。
RVO:避免函数返回对象时产生临时拷贝,直接调用栈上构造返回值。
C++11:结合move构造,当RVO不适用时,可将返回值资源迁移,减少深拷贝。
浅拷贝和深拷贝:
浅拷贝只复制指向某个对象的指针 ,而不复制对象本身,新旧对象共享同一块内存。
深拷贝会另外创造一个一模一样的对象,新对象跟原对象不共享内存,修改新对象不影响旧对象。而浅拷贝会。
static和全局变量的区别
静态全局变量static和全局变量,都是静态存储
全局变量的作用域是整个源程序,当一个源程序由多个源文件组成时,全局变量在各个源文件中都有效。在一个文件内定义全局变量,另一个文件中,通过extern全局变量名的声明,就可以使用全局变量。
static修饰的静态全局变量则限制了其作用域,只在定义该变量的源文件内有效,在同一源程序的其他源文件不能使用它
这里还有一个静态局部变量 ,局部变量只在函数体内有效,静态局部变量在一个文件内有效
.C文件到可执行文件的过程
.C文件即C源程序->编译预处理->编译->汇编程序->链接程序->可执行程序
第一个问题也有编译程序的过程
- 预编译:将头文件编译,进行宏替换,输出.i文件
- 编译:将其转化为汇编语言文件,主要做词法分析,语义分析以及检查错误,检查无误后将代码翻译成编译语言,生成.s文件
- 汇编:汇编器将汇编语言文件翻译成机器语言,生成.o文件(二进制文件)
- 链接:将目标文件和库链接到一起,生成可执行文件
匿名函数如何获取成员对象
匿名函数绝大多数情况下,就是lambda。lambda就是匿名函数一种,lambda是专门快速写匿名函数的语法糖。
lambda:
捕获列表(参数列表)mutable->返回值类型{
函数体
}
默认情况下,Lambda函数总是一个const函数,mutable可以取消其常量性。可变规范允许lambda表达式的主体修改由值捕获的变量。在使用该关键字时,参数列表不可省略(即使参数为空)。
捕捉列表能够访问或获取上下文中的变量供lambda函数使用。
- 通过引用访问:具有&前缀的变量\&b
- 通过值访问:无&前缀的变量a
空捕获 [ ]:
不从周围捕获变量
在 lambda 表达式中捕获外界变量的默认捕获模式:
- 可以为全部变量默认指定捕获方式,然后为特定变量显式指定模式
- \&:引用捕获外部所有变量
[=]:捕获外部所有变量
静态成员不需要捕获
捕获当前对象指针this
cpp
//lambda主体通过引用访问外部变量total,通过值访问外部变量factor
//顺序不同 等效
[&total, factor]
[factor, &total]
//默认引用捕获 显式指定factor为值捕获
[&, factor]
//默认值捕获 显式指定total为引用捕获
[=, &total]引用捕获和值捕获模式的区别:
- 引用捕获可修改外部变量原始数据,值捕获只能修改副本,不能修改原始数据。
- 引用捕获反映外部变量的更新,值捕获不反映。
- 引用捕获引入了生存期依赖关系,值捕获没有生存期依赖关系。如果在异步lambda中通过引用捕获本地,在lambda运行时,本地数据消失会导致运行时访问冲突。
这里还是有些不清不楚。。。需要回顾更新。
链表是否有环,环的入口
做一个高性能模块,需要用链表,会优先考虑std的list吗,还是有其他考量
做高性能模块,绝大多数情景下,不优先用std::list,甚至尽量别用。std::list性能很差,基本是C++标准库里"性能垫底"的容器之一。
不适合高性能
- 每个节点独立堆分配。每插入一个节点就一次new,缓存不友好,大量小对象极慢
- 内存不连续。CPU缓存命中率低,遍历比vector慢几倍到几十倍
- 双向链表overhead大。每个节点存两个指针prev/next,内存占用高
- 无法随机访问i。找第几个元素必须从头遍历
只有一种情况适合
频繁在中间插入、删除,且迭代器不能失效的情况下,但性能也远不及优化过的vector。
所以高性能首选std::vector,当作连续内存链表用
- 内存连续,缓存友好,性能碾压std的list
- 插入删除如果不是巨大量,速度反而更快
- 支持随机访问,能和算法、SIMD配合
如何避免内存泄漏
作为C/C++开发人员,内存泄漏是最容易遇到的问题之一。这是由于C/C++语言的特性,C/C++需要开发者去申请释放内存,要开发者去管理内存,内存使用不当,容易造成段错误segment fault或者内存泄漏memory leak。
性能下降、程序终止、系统崩溃、无法提供服务。
**内存泄漏,指程序中已动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,**导致一系列后果。。很严重。。
我们在程序中对原始指针(raw pointer)使用new操作符或者free函数的时候,实际上是在堆上为其分配内存,这个内存指的是RAM,而不是硬盘等永久存储。持续申请而不释放(或者少量释放)内存的应用程序,最终因内存耗尽导致OOM(out of memory)。
当程序申请了内存,而不进行归还,久而久之,可用内存越来越少,OS就会进行自我保护,杀掉该进程,这就是我们常说的OOM(out of memory)。
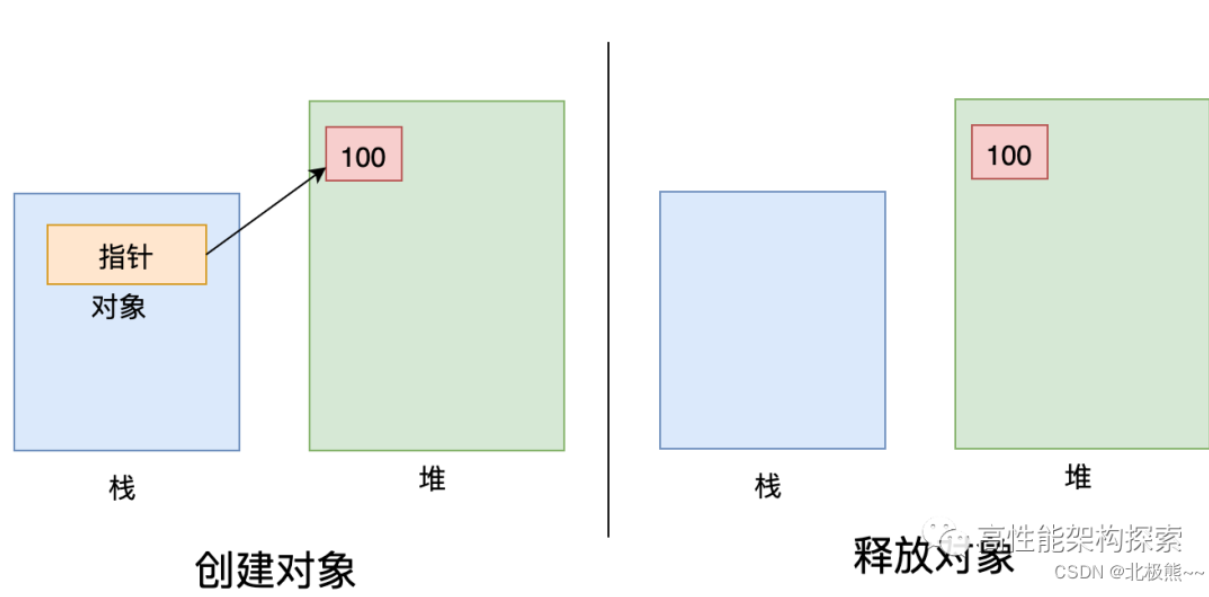
内存泄漏分为以下两类:
- 堆内存泄漏 :我们经常说的内存泄漏就是堆内存泄漏,在堆上申请了资源,在结束使用的时候,没有释放归还给OS,从而导致该块内存永远不会被再次使用
- 资源泄漏 :通常指的是系统资源 ,比如socket,文件描述符等,因为这些在系统中都是有限制的,如果创建了而不归还,久而久之,就会耗尽资源,导致其他程序不可用
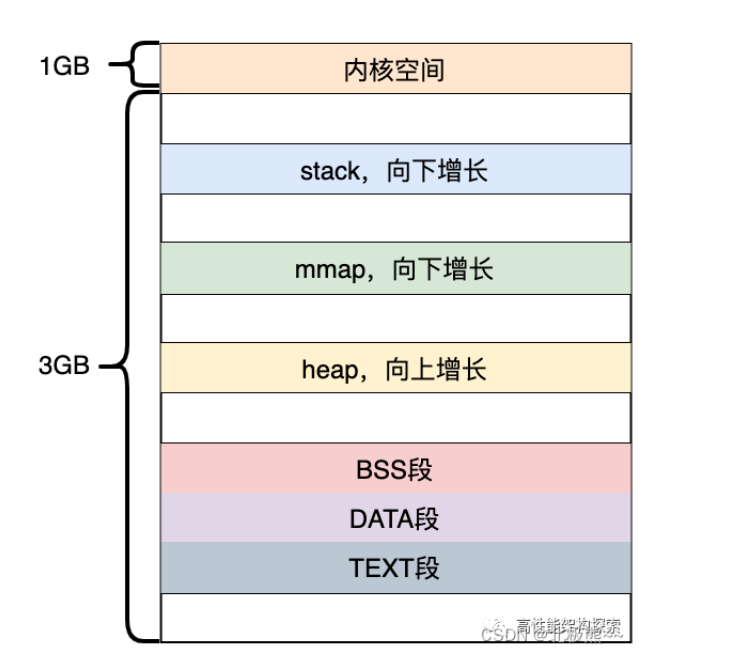
本文主要分析堆内存泄漏,所以后面的内存泄漏均指的是堆内存泄漏。
- 内核空间:供内核使用,存放的是内核代码和数据
- stack:这就是我们经常所说的栈,用来存储自动变量(automatic variable)
- mmap:也成为内存映射,用来在进程虚拟内存地址空间中分配地址空间,创建和物理内存的映射关系
- heap:就是我们常说的堆,动态内存的分配都是在堆上
- bss:包含所有未初始化的全局和静态变量,此段中的所有变量都由0或者空指针初始化,程序加载器在加载程序时为BSS段分配内存
- ds:初始化的数据块
包含显式初始化的全局变量和静态变量
此段的大小由程序源代码中值的大小决定,在运行时不会更改
它具有读写权限,因此可以在运行时更改此段的变量值
该段可进一步分为初始化只读区和初始化读写区- text:也称为文本段
该段包含已编译程序的二进制文件。
该段是一个只读段,用于防止程序被意外修改
该段是可共享的,因此对于文本编辑器等频繁执行的程序,内存中只需要一个副本
避免内存泄漏:
-
避免在堆上分配。在栈上。
众所周知,大部分的内存泄漏都是因为在堆上分配引起的,如果我们不在堆上进行分配,就不会存在内存泄漏了(这不废话嘛),我们可以根据具体的使用场景,如果对象可以在栈上进行分配,就在栈上进行分配,一方面栈的效率远高于堆,另一方面,还能避免内存泄漏,我们何乐而不为呢。 -
手动释放
对于malloc函数分配的内存,在结束使用的时候,使用free函数进行释放
对于new操作符创建的对象,切记使用delete来进行释放
对于new \[\]创建的对象,使用delete\[\]来进行释放(使用free或者delete均会造成内存泄漏) -
避免使用裸指针
cppint fun(int *ptr) {//fun是一个接口或lib函数 //函数体 return 0; } int main() {} int a = 1000; int *ptr = &a; // ... fun(ptr); return 0; }使用STL中或者自己实现对象。
在C++中,提供了相对完善且可靠的STL供我们使用,所以能用STL的尽可能的避免使用C中的编程方式,比如:
。使用std::string 替代char *, string类自己会进行内存管理,而且优化的相当不错
。使用std::vector或者std::array来替代传统的数组
。其它适合使用场景的对象
-
智能指针
自C++11开始,STL中引入了智能指针(smart pointer)来动态管理资源。
unique_ptr是限制最严格的一种智能指针,用来替代之前的auto_ptr,独享被管理对象指针所有权。
unique_ptr是独占管理权,而shared_ptr则是共享管理权
weak_ptr的出现,主要是为了解决shared_ptr的循环引用
-
RAll
RAII是Resource Acquisition is Initialization(资源获取即初始化)的缩写,是C++语言的一种管理资源,避免泄漏的用法。
利用的就是C++构造的对象最终会被销毁的原则 。利用C++对象生命周期的概念来控制程序的资源 ,比如内存,文件句柄,网络连接等。RAII的做法是使用一个对象,在其构造时获取对应的资源,在对象生命周期内控制对资源的访问,使之始终保持有效,最后在对象析构的时候,释放构造时获取的资源。
简单地说,就是把资源的使用限制在对象的生命周期之中,自动释放。
举个简单的例子,通常在多线程编程的时候,都会用到std::mutex,
cpp
std::mutex mutex_;
void fun() {
mutex_.lock();
if (...) {
mutex_.unlock();
return;
}
mutex_.unlock()
}如果if分支多的话,每个if分支里面都要释放锁,如果一不小心忘记释放,那么就会造成故障,为了解决这个问题,我们使用RAII技术
cpp
std::mutex mutex_;
void fun() {
std::lock_guard<std::mutex> guard(mutex_);
if (...) {
return;
}
}在guard出了fun作用域的时候,会自动调用mutex_.lock()进行释放,避免了很多不必要的问题
这一篇也不错。。!
RAll思想
如上。
RAII 是Resource Acquisition is Initialization(资源获取即初始化)。是一种C++中常见的编程范式,主要用于管理资源(如动态内存、文件句柄、网络链接等)。核心思想是++将资源的生命周期绑定到对象的生命周期,通过对象的构造函数来获取资源,通过对象的析构函数来释放资源++。这种方式避免了显式的资源管理,减少了资源泄漏的可能性。
- 资源获取即初始化:资源的分配与对象的初始化绑定在一起,资源的释放与对象的销毁绑定在一起。
- 自动释放资源:当对象超出作用域scope时,系统自动调用其析构函数,从而释放所占用的资源。这可以避免忘记释放资源或者手动释放资源时出现错误。
RAll典型应用。
- 内存管理 :通过智能指针(如 std::unique_ptr 和 std::shared_ptr)自动管理堆内存。
- 文件管理 :通过 std::fstream自动管理文件的打开和关闭。
- 互斥锁管理 :通过std::lock_guard 或 std::unique_lock自动管理锁的获取和释放。
所以前面说过,智能指针就是一个类,借助的就是RAll思想,资源管理
RAll管理文件
cpp
#include <iostream>
#include <fstream>
void readFile(const std::string& fileName) {
// 文件在构造时打开,在析构时关闭
std::ifstream file(fileName);
if (!file.is_open()) {
std::cerr << "Failed to open the file." << std::endl;
return;
}
std::string line;
while (std::getline(file, line)) {
std::cout << line << std::endl;
} // 文件在作用域结束时自动关闭
}
int main() {
readFile("example.txt");
return 0;
}RAII 管理互斥锁
cpp
#include <iostream>
#include <thread>
#include <mutex>
std::mutex mtx;
void printThreadID(int id) {
// 使用 std::lock_guard 自动管理互斥锁
std::lock_guard<std::mutex> lock(mtx);
std::cout << "Thread " << id << " is running." << std::endl;
}
int main() {
std::thread t1(printThreadID, 1);
std::thread t2(printThreadID, 2);
t1.join();
t2.join();
return 0;
}new和delete的规范使用
C语言中动态开辟内存的方法是malloc/calloc/realloc;释放动态开辟内存是free
C++中是new和delete
-
malloc和free是函数,new和delete是操作符;
-
malloc申请的空间不会初始化,new可以初始化;
-
malloc申请空间时,需要手动计算空间大小并传递,new只需在其后跟上空间的类型即可, 如果是多个对象,\[\]中指定对象个数即可;
-
申请自定义类型的空间时,new会调用构造函数,delete会调用析构函数,而malloc与free不会
-
malloc的返回值为void*, 在使用时必须强转,new不需要,因为new后跟的是空间的类型;
-
malloc申请空间失败时,返回的是NULL,因此使用时必须判空,new不需要,但是new需要捕获异常
-
申请自定义类型对象时,malloc/free只会开辟空间,不会调用构造函数与析构函数,而new 在申请空间后会调用构造函数完成对象的初始化,delete在释放空间前会调用析构函数完成空间中资源的清理。
-
。。。。。区别还有一些
new底层其实就是malloc实现开辟空间,new先调用operator new函数底层malloc,再调用自定义类型的构造函数
- new不用担心动态开辟空间失败,因为失败时会抛出异常;malloc开辟空间失败后返回空指针
delete先调用自定义析构函数,再调用operator delete函数,operator delete底层是free
这里需要再细化。。。。
手搓智能指针(文件管理),(内存释放)
野指针。
指针变量没有被初始化,或者指向的内存已被释放。
内存泄漏。
分配的内存没有被释放,且失去了对这块内存的引用。
悬空指针。
类似于野指针,特指指向已经被释放的内存的指针。
C++的RAII(资源获取即初始化)思想就是答案。 其核心是:利用对象的生命周期来管理资源。构造函数中获取资源,析构函数中释放资源。
cpp
#include <iostream>
template <typename T>
class SmartPtr {
private:
T* m_ptr; // 底层原始指针
public:
// 构造函数,获取资源
explicit SmartPtr(T* ptr = nullptr) : m_ptr(ptr) {}
// 析构函数,释放资源
~SmartPtr() {
delete m_ptr; // 安全地对nullptr执行delete
std::cout << "Resource freed by SmartPtr." << std::endl;
}
// 禁止拷贝构造和赋值,防止多个SmartPtr管理同一份资源
SmartPtr(const SmartPtr&) = delete;
SmartPtr& operator=(const SmartPtr&) = delete;
// 允许移动构造(进阶功能,体现现代C++思想)
SmartPtr(SmartPtr&& other) noexcept : m_ptr(other.m_ptr) {
other.m_ptr = nullptr;
}
// 允许移动赋值(进阶功能)
SmartPtr& operator=(SmartPtr&& other) noexcept {
if (this != &other) {
delete m_ptr;
m_ptr = other.m_ptr;
other.m_ptr = nullptr;
}
return *this;
}
// 重载操作符,让它用起来像指针
T& operator*() const { return *m_ptr; }
T* operator->() const { return m_ptr; }
explicit operator bool() const { return m_ptr != nullptr; }
};
// 使用示例
int main() {
{
// 在作用域内创建我们的"智能指针"
SmartPtr<int> sp(new int(42));
// 像普通指针一样使用
std::cout << "Value: " << *sp << std::endl;
*sp = 100;
std::cout << "New Value: " << *sp << std::endl;
// 离开这个作用域时,sp的析构函数会自动调用,delete内部指针
// 你不需要手动调用free/delete!
}
std::cout << "Now sp is out of scope." << std::endl;
return 0;
}是封装一个指针,初始化,单例模式?
看这个把
cpp
template<typename T>
class SharedPtr{
public:
SharedPtr(){
count = new int(0);
ptr = new T(0);
}
SharedPtr(T* p){
count = new int(1);
ptr = p;
}
Sharedptr(T& p) {
ptr = new string(p);
count = new int(1);
}
SharedPtr(SharedPtr<T>& other){
count = other.count;
add_count();
ptr = other.ptr;
}
T* operator->(){
return ptr;
}
T& operator*(){
return *ptr;
}
void add_count(){
(*count)++;//测试下区别,去掉括号
}
void sub_count(){
(*count)--;
}
SharedPtr<T>& operator = (SharedPtr<T>& other){
if(this == &other){
return *this;
}
other.add_count();
sub_count();
if(ptr && *count == 0){
delete count;
delete ptr;
cout<<"delete ptr = "<<endl;
}
ptr = other.ptr;
count = other.count;
return *this;
}
~SharedPtr(){
sub_count();
if(ptr && *count == 0){
delete count;
delete ptr;
cout<<"delete ptr ~ "<<endl;
}
}
int getRef(){
return *count;
}
private:
int* count;
T* ptr;
};还是这样。。。没细看
cpp
namespace bit
{
template<class T>
class auto_ptr
{
public:
auto_ptr(T* ptr)
:_ptr(ptr)
{}
auto_ptr(auto_ptr<T>& sp)
:_ptr(sp._ptr)
{
// 管理权转移
sp._ptr = nullptr;
}
auto_ptr<T>& operator=(auto_ptr<T>& ap)
{
// 检测是否为⾃⼰给⾃⼰赋值
if (this != &ap)
{
// 释放当前对象中资源
if (_ptr)
delete _ptr;
// 转移ap中资源到当前对象中
_ptr = ap._ptr;
ap._ptr = NULL;
}
return *this;
}
~auto_ptr()
{
if (_ptr)
{
cout << "delete:" << _ptr << endl;
delete _ptr;
}
}
// 像指针⼀样使⽤
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
private:
T* _ptr;
};
template<class T>
class unique_ptr
{
public:
explicit unique_ptr(T* ptr)
:_ptr(ptr)
{}
~unique_ptr()
{
if (_ptr)
{
cout << "delete:" << _ptr << endl;
delete _ptr;
}
}
// 像指针⼀样使⽤
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
unique_ptr(const unique_ptr<T>&sp) = delete;
unique_ptr<T>& operator=(const unique_ptr<T>&sp) = delete;
unique_ptr(unique_ptr<T> && sp)
:_ptr(sp._ptr)
{
sp._ptr = nullptr;
}
unique_ptr<T>& operator=(unique_ptr<T> && sp)
{
delete _ptr;
_ptr = sp._ptr;
sp._ptr = nullptr;
}
private:
T* _ptr;
};
template<class T>
class shared_ptr
{
public:
explicit shared_ptr(T* ptr = nullptr)
: _ptr(ptr)
, _pcount(new int(1))
{}
template<class D>
shared_ptr(T * ptr, D del)
: _ptr(ptr)
, _pcount(new int(1))
, _del(del)
{}
shared_ptr(const shared_ptr<T>& sp)
:_ptr(sp._ptr)
, _pcount(sp._pcount)
, _del(sp._del)
{
++(*_pcount);
}
void release()
{
if (--(*_pcount) == 0)
{
// 最后⼀个管理的对象,释放资源
_del(_ptr);
delete _pcount;
_ptr = nullptr;
_pcount = nullptr;
}
}
shared_ptr<T>& operator=(const shared_ptr<T>& sp)
{
if (_ptr != sp._ptr)
{
release();
_ptr = sp._ptr;
_pcount = sp._pcount;
++(*_pcount);
_del = sp._del;
}
return *this;
}
~shared_ptr()
{
release();
}
T* get() const
{
return _ptr;
}
int use_count() const
{
return *_pcount;
}
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
private:
T* _ptr;
int* _pcount;
//atomic<int>* _pcount;
function<void(T*)> _del = [](T* ptr) {delete ptr; };
};
// 需要注意的是我们这⾥实现的shared_ptr和weak_ptr都是以最简洁的⽅式实现的,
// 只能满⾜基本的功能,这⾥的weak_ptr lock等功能是⽆法实现的,想要实现就要
// 把shared_ptr和weak_ptr⼀起改了,把引⽤计数拿出来放到⼀个单独类型,shared_ptr
// 和weak_ptr都要存储指向这个类的对象才能实现,有兴趣可以去翻翻源代码
template<class T>
class weak_ptr
{
public:
weak_ptr()
{}
weak_ptr(const shared_ptr<T>& sp)
:_ptr(sp.get())
{}
weak_ptr<T>& operator=(const shared_ptr<T>& sp)
{
_ptr = sp.get();
return *this;
}
private:
T* _ptr = nullptr;
};
}
int main()
{
bit::auto_ptr<Date> ap1(new Date);
// 拷⻉时,管理权限转移,被拷⻉对象ap1悬空
bit::auto_ptr<Date> ap2(ap1);
// 空指针访问,ap1对象已经悬空
//ap1->_year++;
bit::unique_ptr<Date> up1(new Date);
// 不⽀持拷⻉
//unique_ptr<Date> up2(up1);
// ⽀持移动,但是移动后up1也悬空,所以使⽤移动要谨慎
bit::unique_ptr<Date> up3(move(up1));
bit::shared_ptr<Date> sp1(new Date);
// ⽀持拷⻉
bit::shared_ptr<Date> sp2(sp1);
bit::shared_ptr<Date> sp3(sp2);
cout << sp1.use_count() << endl;
sp1->_year++;
cout << sp1->_year << endl;
cout << sp2->_year << endl;
cout << sp3->_year << endl;
return 0;
}推荐这个。。后面细看,还不会手搓。。。。。
虚函数是什么,如何实现虚函数?
虚函数(Virtual Function)是在面向对象编程中用于实现动态多态性的一种机制 。通过将基类中的成员函数声明为虚函数,可以在派生类中**重写(Override)**这些函数,从而根据对象的实际类型确定调用的函数版本。通过以下的代码块,参考。。
具体实现:
在基类中使用virtual关键字声明虚函数:
cppclass Base { public: virtual void func() { ... } };派生类重写基类的虚函数
cppclass Derived extends Base { public: virtual void func() { ... } };
通过基类的指针或引用调用虚函数,会执行实际所指派生类的实现
cppBase* b = new Derived(); b->func(); // Calls Derived::func()重写基类的虚函数时,可以使用override关键字检查是否正确重写,如果Derived::func()不是正确重写Base::func(),编译器会报错。
cppclass Derived extends Base { public: virtual void func() override { ... } };派生类可以选择不重写基类的虚函数,这时调用基类
cppclass Derived extends Base { }; Base* b = new Derived(); b->func(); // Still calls Base::func()基类可以声明纯虚函数,这要求所有派生类都重写该虚函数, 如果派生类为重写,则也变成抽象类。
cppclass Base { public: virtual void func() = 0; // Pure virtual function };extends 是 Java / C# 的继承关键字,C++ 根本不认识 extends。。。。大概是怎么个意思
下面才对。。。
-
首先定义基类(父类):在基类中生命虚函数,并将其标记为虚函数,使用关键字virtual。
cppclass Base{ public: virtual void func(); }; -
接下来是定义派生类(子类):在派生类中重写基类的虚函数,并保持函数签名(返回类型、参数列表)一致。
cppclass Derived : public Base{ public: void func() override; }; -
虚函数表:编译器会将每个包含虚函数的类生成一个虚函数表,其中存储了指向各个虚函数的函数指针。每个对象都有一个隐藏的指针指向该虚函数表。
-
调用虚函数:当通过基类指针或引用调用虚函数时,会根据对象的实际类型选择正确的虚函数进行调用。通过虚函数表中的函数指针,确定要调用的函数,并在运行时动态绑定到正确的函数。
cpp#include <iostream> class Base { public: virtual void func() { std::cout << "Base::func()" << std::endl; } }; class Derived : public Base { public: void func() override { std::cout << "Derived::func()" << std::endl; } }; int main(){ Base* tr = new Derived(); ptr->fuinc(); delete ptr; return 0; }
如何用栈实现一个队列
用两个栈来实现队列,一个用于输入,一个用于输出
因为栈遵循LIFO原则(先进后出),输入的数据会被反转顺序。所以用两个栈,就可以将数据的顺序反转过来,从而实现队列的FIFO原则(先进先出)
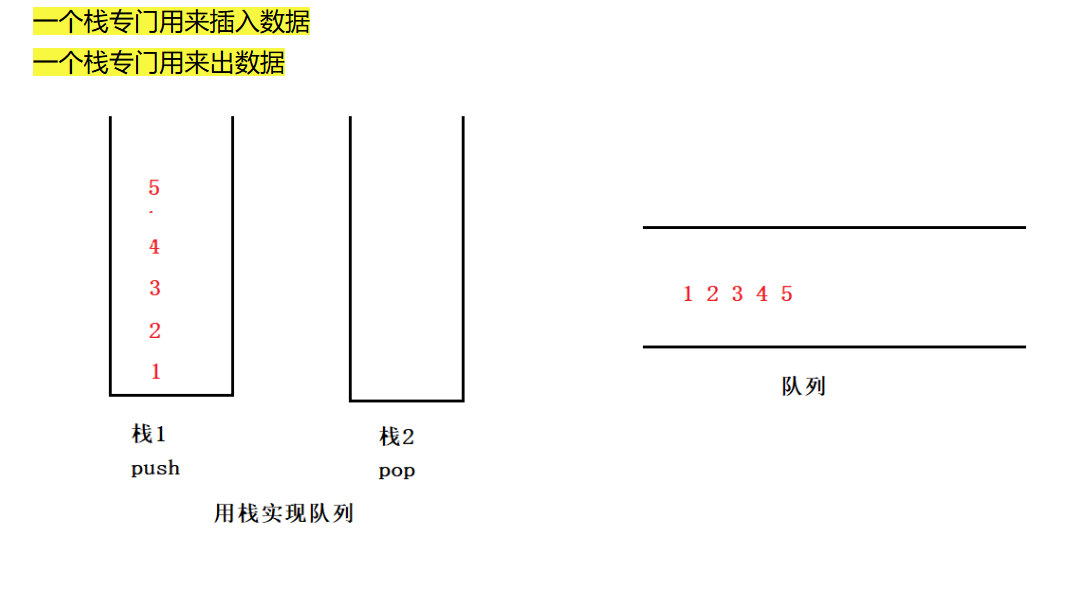
队列,队头Front,队尾Rear
定义栈结构,包含数据的数组,栈顶指针以及栈的容量
cpp
typedef struct Stack {
int* data; // 存储数据的数组
int top; // 栈顶指针
int capacity; // 栈的容量
}Stack; 定义队列结构,包含输入栈和输出栈
cpp
typedef struct {
Stack* in_stack;
Stack* out_stack;
}MyQueue;创建栈并初始化
cpp
Stack* createStack(int capacity) {
struct Stack* stack = (Stack*)malloc(sizeof(Stack));
if (stack == NULL) {
return NULL;
}
stack->data = (int*)malloc(sizeof(int) * capacity);
if (stack->data == NULL) {
free(stack);
return NULL;
}
stack->top = -1;
stack->capacity = capacity;
return stack;
}检查栈是否为空。指向栈的指针为空或者栈的栈顶指针等于-1(初始为-1)时,栈为空
cpp
bool isStackEmpty(Stack* stack) {
return (stack == NULL || stack->top == -1);
} 检查栈是否已满。当栈的栈顶指针指向栈的数据数组的最后一位,说明栈已满
cpp
bool isFullStack(Stack* stack) {
return stack->top == stack->capacity - 1;
}入栈操作。先判断栈是否已满,如果栈已满,就无法再入栈
cpp
bool pushStack(Stack* stack, int val) {
if (isStackFull(stack)) {
return false;
}
stack->data[++stack->top] = val;
return true;
}元素出栈。先判断栈是否为空,为空则无法出栈,反之将元素加入到栈的数据数组中,栈顶指针向前移动一位
cpp
bool popStack(Stack* stack, int* value) {
if (isStackEmpty(stack)) {
return false;
}
*value = stack->data[stack->top];
stack->top--;
return true;
}查看栈顶元素
cpp
// 查看栈顶元素
bool peekstack(Stack* stack, int* value) {
if (isStackEmpty(stack)) {
return false;
}
*value = stack->data[stack->top];
return true;
} 释放栈内存。先释放栈中数组的内存,再释放栈结构的内存
cpp
void clearStack(Stack* stack) {
if (stack == NULL) {
return;
}
free(stack->data);
free(stack);
}创建队列并初始化。包含两个栈,一个用于输入,一个用于输出
cpp
// 创建队列并初始化
MyQueue* CreatemyQueue(int capacity) {
// 分配队列结构内存
MyQueue* queue = (MyQueue*)malloc(sizeof(MyQueue));
if (queue == NULL) {
return NULL;
}
// 创建输入栈(用于入队操作)
queue->in_stack = createStack(capacity);
// 创建输出栈(用于出队操作)
queue->out_stack = createStack(capacity);
return queue;
}判断队列是否为空。判断输出栈为空且输入栈也为空. 如果输出栈为空但输入栈不为空时,可以将输入栈中的元素压入输出栈中
cpp
// 检查队列是否为空
// 输出栈和输入栈都为空
bool isMyQueueEmpty(MyQueue* queue) {
return isStackEmpty(queue->in_stack) && isStackEmpty(queue->out_stack);
}判断队列是否已满。这个要判断的标准是输入栈是已满且输出栈不为空 ,因为如果输入栈已满但输出栈不为空时是不能将输入栈中的元素压入输出栈中的,会打乱数据的顺序,不符合LIFO原则
cpp
// 检查队列是否已满
// 输入栈已满并且输出站不为空 (输入站已满即使输出站又空位也不能插入元素,会打乱元素顺序)
bool isMyQueueFull(MyQueue* queue) {
return isStackFull(queue->in_stack) && !(isStackEmpty(queue->out_stack));
}入队操作
cpp
bool PushmyQueue(MyQueue* queue, int val) {
// 如果输入栈满了,检查是否可以转移元素
if (isStackFull(queue->in_stack)) {
// 只有输出栈为空时才能转移所有元素
// 如果输出栈不为空但是又空位,是不能将输入栈的元素转移到输出栈中的,会带乱数据的顺序,队列遵循FIFO,栈遵循LIFO
if (isStackEmpty(queue->out_stack)) {
// 转移所有输入栈元素到输出栈
while (!isStackEmpty(queue->in_stack)) {
int temp;
if (popStack(queue->in_stack, &temp)) {
pushStack(queue->out_stack, temp);
}
}
// 现在输入栈空了,可以入队
return pushStack(queue->in_stack, val);
} else {
// 输出栈不为空,无法转移,队列满
return false;
}
}
// 输入栈未满,直接入队
return pushStack(queue->in_stack, val);
}出队操作
cpp
bool PopmyQueue(MyQueue* queue) {
// 检查输出栈是否为空
int value;
if (isStackEmpty(queue->out_stack)) {
// 如果输入栈也为空,就直接返回
if (isStackEmpty(queue->in_stack)) {
return false;
} else {
// 输出栈为空,检查输入栈,如果输入栈不为空,将输入栈中的元素全部转移到输出栈
while (!isStackEmpty(queue->in_stack)) {
if (popStack(queue->in_stack, &value)) {
pushStack(queue->out_stack, value);
}
}
}
}
// 输出栈不为空,直接出栈
popStack(queue->out_stack, &value);
return true;
}查看队首元素。先判断队列是否为空 队列不为空,就在判断输出栈是否为空,不为空就直接将输出栈的栈顶元素传给要接受队首元素的指针 如果输出栈为空,就将输入站中的元素全部压入输出栈中,(注意是全部,否则会打乱数据的顺序)
cpp
bool PeekMyQueue(MyQueue* queue, int* value) {
if (isMyQueueEmpty(queue)){
return false;
}
if (isStackEmpty(queue->out_stack)) {
while (!isStackEmpty(queue->in_stack)) {
popStack(queue->in_stack, value);
pushStack(queue->out_stack, *value);
}
}
*value = queue->out_stack->data[queue->out_stack->top];
printf("队首元素是 %d ", * value);
return true;
}最后释放队列内存 先释放队列中两个栈的内存,再释放队列结构的内存
cpp
void FreeMyQueue(MyQueue* queue) {
freeStack(queue->in_stack);
freeStack(queue->out_stack);
free(queue);
}TCP的流量控制,拥塞控制,区别
拥塞控制和流量控制虽然都是TCP原来调节数据传输速率的机制,但他们解决的问题和关注的焦点是不同的。
目的不同。
流量控制主要是为了解决通信双方处理能力不匹配的 问题,防止发送方发送数据太快导致接收方缓冲区溢出;而拥塞控制则为了解决网络拥塞问题,避免过多数据包涌入网络造成网络崩溃。
控制对象不同。
流量控制是端到端的,只关注发送方和接收方 两个端点;而拥塞控制关注整个网络的状态,包括中间的路由器等设备。
实现机制不同。
流量控制主要通过滑动窗口 协议实现,接收方在ACK中告诉对方自己还能接收多少数据;拥塞控制主要通过拥塞窗口、慢启动、拥塞避免、快重传和快恢复等算法实现,主要是发送方根据网络状况自行调整。
触发条件不同。
流量控制由接收方的处理能力 决定,当接收方缓冲区快满时就会减小窗口 ;而拥塞控制主要由**网络状况决定,**当检测到丢包或超时等现象时,判断为网络拥塞,就会相应的调整发送速率。
TCP实际应用使用这两种机制,取两者较小值作为实际发送窗口。如即使接收方有足够缓冲区,但如果网络拥塞,发送方也会降低发送速率;反之网络良好,但接收方处理不来,发送方也会限制发送速度。
多路复用(epoll/IO复用),Reactor/Proactor模型,多线程服务器架构
IO,即操作系统的网络IO操作,一次完整的网络IO分为两个不可拆分的核心阶段:
- 数据准备阶段:内核等待网卡接收网络数据,将数据写入内核缓冲区
- 数据拷贝阶段:内核将缓冲区的数据,拷贝到用户进程的内存空间
所有IO模型的差异,本质就是这两个阶段的阻塞/非阻塞、调度方式不同
IO多路复用,是一种经典的同步IO模型, 也是高并发网络编程的核心技术。是一种工作机制,
核心用单个线程/进程同时监听成百上千个文件描述符fd、socket、文件句柄。。 他让程序监视多个文件描述符(通常是套接字),等待其中一个或多个文件描述符变为就绪状态。一旦某个fd就绪可读可写异常,就立即通知用户程序执行对应的IO操作。
解决传统阻塞IO模型,一个线程只能处理一个fd,高并发场景下会创建海量线程,导致CPU上下文切换开销爆炸、系统性能急剧下降。
Linux平台下,IO多路复用有三种经典实现:(也是多路转接技术,放快递站?
- select
- poll
- epoll,性能最强、应用最广
select是最古老的IO多路复用API,跨平台支持,监视一组文件描述符。几乎支持所有类型的Unix系统(包括Linux、Mac等)。基本工作原理是用户态进程将一组文件描述符传递给内核,由内核来检查这些文件描述符的状态变化;当调用返回时,会告诉用户哪些文件描述符已经准备好了读写操作。性能随文件描述符增多下降。
poll比select更现代,支持更多文件描述符,效率高于select,跨平台
epoll不跨平台,Linux特有。Linux下最高效的多路复用机制,事件驱动,仅返回就绪描述符
kqueue,类似于epoll,适用于BSD和macOS,高效的事件通知机制
阻塞IO
需要结合多进程/多线程,每个进程/线程处理一路IO
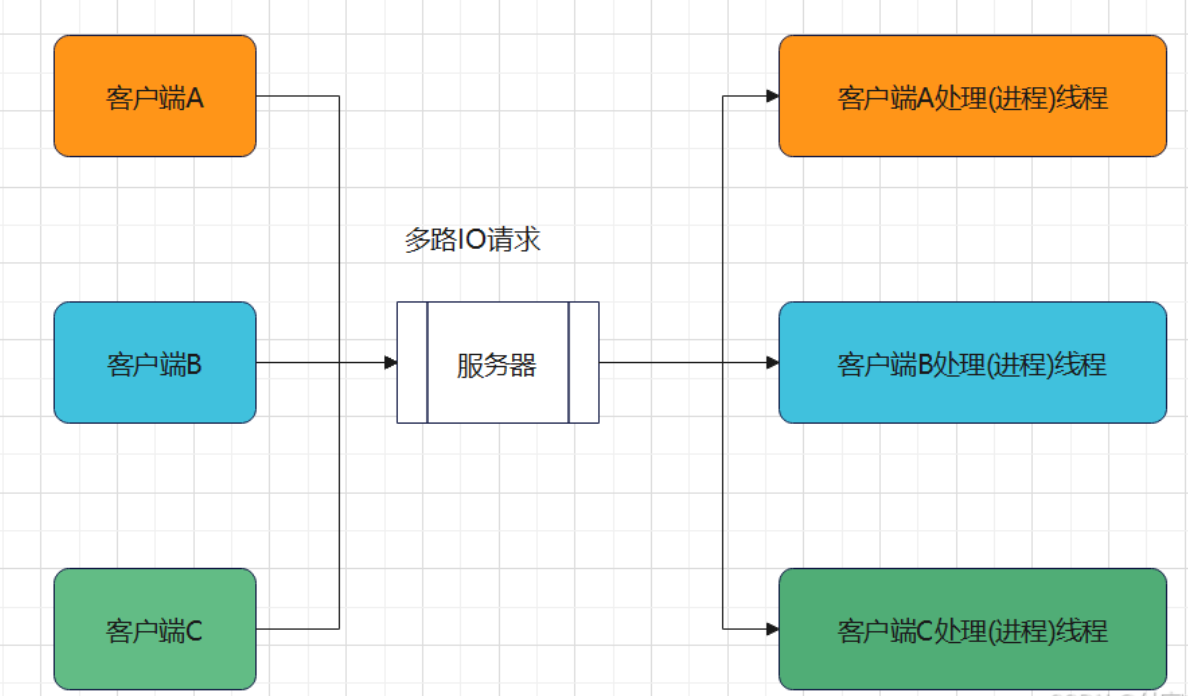
客户端越多,需要创建的进程/线程越多,相对占用内存 资源较多
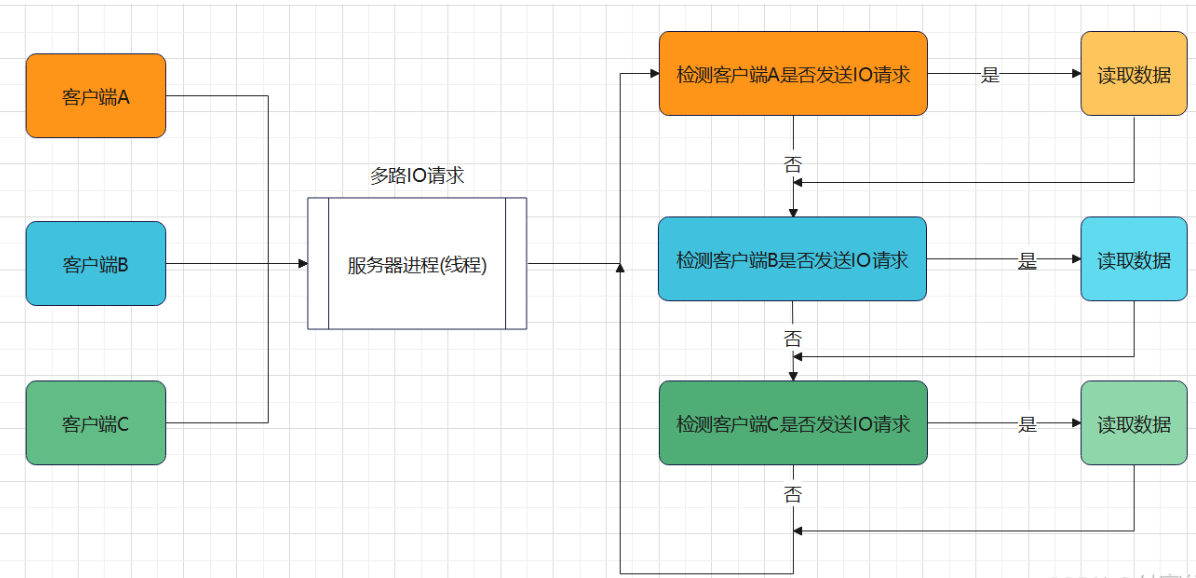
非阻塞IO
单进程可以处理,但是需要不断检测客户端是否发出IO请求,需要不断占用cpu,消耗 cpu 资源
多路复用IO
本质上就是通过复用一个进程来处理多个IO请求
由内核 来监控多个文件描述符是否可以进行I/O操作 ,如果有就绪的文件描述符,将结果告知给用户进程,则用户进程在进行相应的I/O操作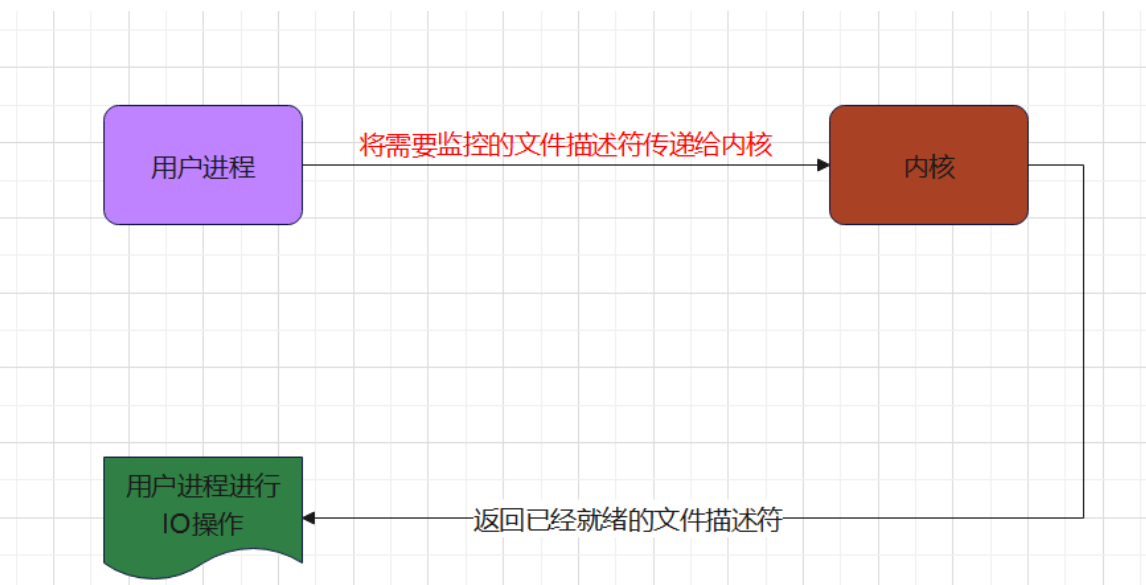
阻塞IO等数据死等
非阻塞IO不等数据,没数据就走,要反复问
多路复用内核帮着盯着一堆IO,哪个好了通知你,不用你挨个问
reactor和proactor模型是高性能网络编程中两大核心事件驱动架构设计模式,目标解决高并发场景下IO处理效率问题。
reactor基于同步IO模型长搭配IO多路复用epoll/select/poll实现;proactor基于操作系统原生异步IO(AIO)模型实现。
同步和异步
同步:调用方发起请求,必须主动等待、主动轮询、主动完成核心操作,最终自己获取结果,整个流程在调用方的控制流里顺序执行
异步:调用方发起请求后,立即返回,无需等待;核心操作完全交给被调用方/系统内核执行,执行完成后,被调用方会通过回调、事件通知等方式,主动把结果推送给调用方
详细的还需补充。。先空着,回来补充。。
线程之间同步和异步
同步和异步是描述两个或多个事件、操作或进程之间的关系。
同步 意味着事件、操作或进程是有序的 ,一个操作必须在另一个操作完成之后开始执行。
异步 则意味着事件、操作或进程是独立的 ,可以在不等待其他操作完成的情况下开始执行。
介绍一下Websocket
Websocket是一种协议,用于Web应用程序和服务器之间建立实时、双向的通信连接。它通过一个单一的TCP连接提供了持久化连接,这使得Web应用程序可以更加实时的传递数据。
WebSocket 是基于 TCP 的一种新的应用层网络协议。 它提供了一个全双工的通道,允许服务器和客户端之间实时双向通信 。因此,在 WebSocket 中,浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输,客户端和服务器之间的数据交换变得更加简单。
为什么需要 WebSocket?
我们已经有了 HTTP 协议,为什么还需要另一个协议?它能带来什么好处? 因为 HTTP 协议有一个缺陷:通信只能由客户端发起,不具备服务器推送能力。 举例来说,我们想了解查询今天的实时数据,只能是客户端向服务器发出请求,服务器返回查询结果。HTTP 协议做不到服务器主动向客户端推送信息。 这种单向请求的特点,注定了如果服务器有连续的状态变化,客户端要获知就非常麻烦。我们只能使用'轮询':每隔一段时候,就发出一个询问,了解服务器有没有新的信息。最典型的场景就是聊天室。轮询的效率低,非常浪费资源(因为必须不停连接,或者 HTTP 连接始终打开)。 在 WebSocket 协议出现以前,创建一个和服务端进双通道通信的 web 应用,需要依赖HTTP协议,进行不停的轮询,这会导致一些问题: 服务端被迫维持来自每个客户端的大量不同的连接 大量的轮询请求会造成高开销,比如会带上多余的header,造成了无用的数据传输。 http协议本身是没有持久通信能力的,但是我们在实际的应用中,是很需要这种能力的,所以,为了解决这些问题,WebSocket协议由此而生,
主要是通过与HTTP对比
连接方式
Http协议是基于请求-响应模式的,每次通信都需要客户端发起一个请求,服务器返回一个响应后断开连接。
而Websocket协议是一种持久连接的协议,客户端和服务器之间建立一次连接后可以持续通信,双方都可以随时发送和接收数据。
数据格式
Http协议传输的数据一般采用明文的ASCII文本格式,通常是HTML、JSON、XML等格式的数据。
而Websocket协议可以传任意格式的数据,包括二进制数据,可以灵活处理各种类型的数据。
通信效率
Http每次通信都需要经过完整的请求-响应过程,包括建立连接、发送请求、服务器处理请求、发送响应等步骤,因此在频繁通信的场景下,Http的开销较大。
而Websocket协议在建立连接后只需要发送少量的头部信息,然后就可以直接进行数据传输,通信效率高。
服务器推送
Http是一种客户端主动发起请求的协议,服务器只能在收到请求后才能返回响应。
而Websocket协议支持服务器主动推送数据给客户端,服务器可以随时向客户端发送数据,实现实时通信。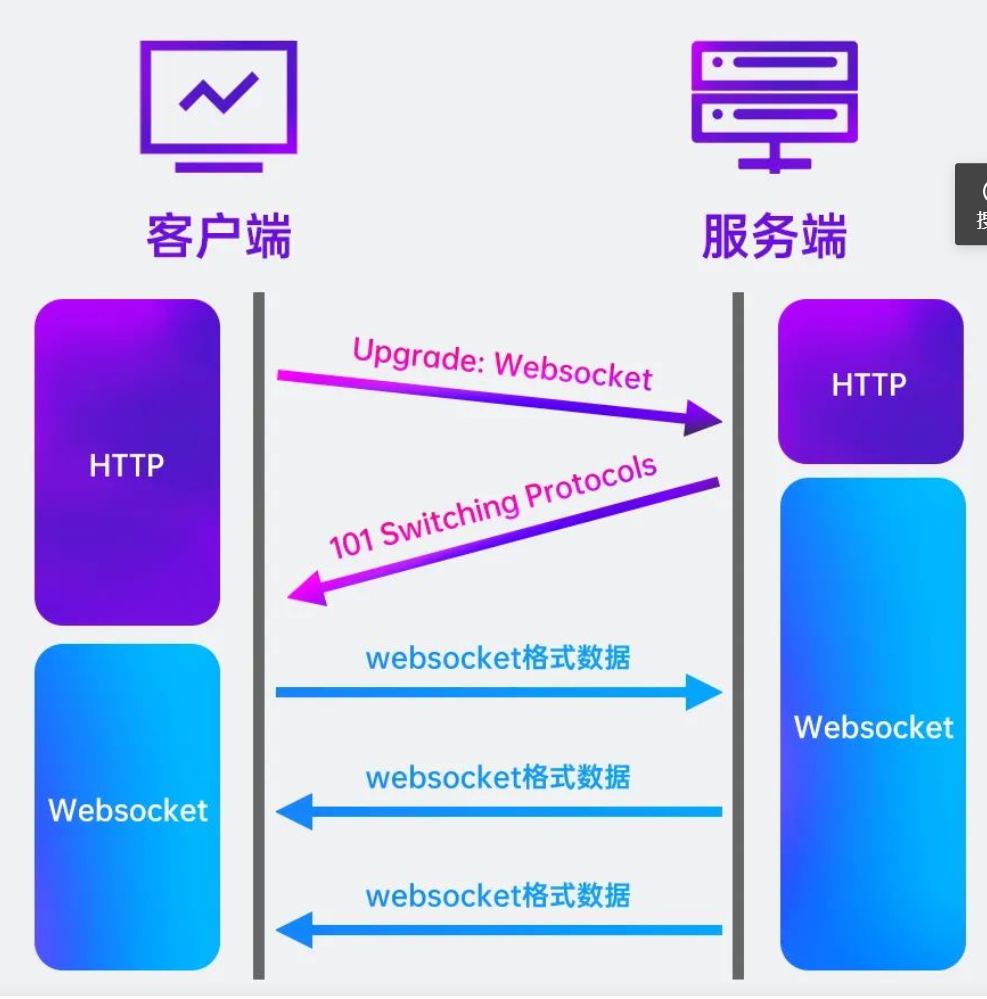
缺点
- 不支持无连接: WebSocket 是一种持久化的协议,这意味着连接不会在一次请求之后立即断开。这是有利的,因为它消除了建立连接的开销,但是也可能导致一些资源泄漏的问题。
- 不支持广泛: WebSocket 是 HTML5 中的一种标准协议,虽然现代浏览器都支持,但是一些旧的浏览器可能不支持 WebSocket。
- 需要特殊的服务器支持: WebSocket 需要服务端支持,只有特定的服务器才能够实现 WebSocket 协议。这可能会增加系统的复杂性和部署的难度。
- 数据流不兼容: WebSocket 的数据流格式与 HTTP 不同,这意味着在不同的网络环境下,WebSocket 的表现可能会有所不同。
tcpudp编程,多线程编程。。如何写出。。