文章目录
- [Linux 系统编程 进程篇 (三)](#Linux 系统编程 进程篇 (三))
-
- [1 进程优先级 是什么,为什么,怎么做](#1 进程优先级 是什么,为什么,怎么做)
- [2 进程切换](#2 进程切换)
-
- [2.1 如何切换](#2.1 如何切换)
- [2.2 Linux 真实的调度算法 O(1)调度算法](#2.2 Linux 真实的调度算法 O(1)调度算法)
Linux 系统编程 进程篇 (三)
1 进程优先级 是什么,为什么,怎么做
先来说这个进程优先级是什么,进程优先级是进程得到CPU资源的先后顺序。
注意,这里要和权限区分一下,权限指的是能否得到资源,而优先级是能得到资源,考虑先后顺序。
为什么要设计优先级呢?CPU只有一个,或许是两个,但是这个进程却有非常多个,不设置一个优先级来分配资源的话很容易就乱套了。
那么,怎么办呢? 优先级和状态一样,是一个整数,这个整数的大小决定优先级的先后。 这个数字依然在task_struct里面。
这个数字的值越低,优先级越高,这个数字的值越大,优先级就越低。
像我们使用这个windows 和linux都是基于时间片的分时操作系统,CPU资源是平均分配的,考虑公平性,所以,优先级可能变化,但是变化幅度不大。
那么我们要怎么 ess, 这个 PRI 和 NI就是之前提到的进程数
PRI是进程的优先级, 默认是 80。 NI 是进程优先级的修改参数, nice值。
进程真实的优先级是 PRI(默认) + NI
最后,这个进程真实的优先级会显示在PRI上。


为什么进程优先级要用两个数的和来表示,而不是直接用一个数来表示,这里先说第一个原因,第二个我们后期讲调度算法的时候说。 我们思考一下,如果直接用一个数表示的话,我们每一次要修改进程优先级为了是不是要先看一眼这个优先级是多少然后再改,但是如果是这样用一个默认值是80,然后nice值来的话,就不需要改之前先查一下了,每次修改只需要修改这个nice值就好了,想改多少改多少(bushi。
或许有敏锐的同学发现了,这个PID前面还有一个UID, UID是什么呢?user id就是用户的身份。还记得之前讲权限,访问文件的时候,操作系统怎么知道现在的用户是拥有者,还是所属组,还是other? 就是看的这个UID

因为在 Linux系统中,访问任何资源都是进程访问,进程就代表用户,这点非常重要。
那么我们如何修改这个nice值呢? 方法就是nice 和renice命令, 如何在写代码的时候获取进程优先级和修改呢?
这个搜搜ai有个印象就好。

nice是启动时以某个nice值启动程序。 renice是运行时修改。
bash
sudo nice -n -10 vim /etc/hosts # 以高优先级(nice=-10)启动文本编辑器(需 root 权限)
bash
renice -n 5 -p 1234还有一个办法是top命令,启动top以后按下r, 输入进程pid,然后输入nice值就好。
然后我们再来谈一下这个进程优先级的范围问题。不卖关子,进程优先级的主要关系着就是nice值,我们的linux里面nice值的范围是-20, 19, 也就是说,优先级的范围是 60, 99一共四十个优先级。
如果把nice值改为小于 -20 或者 大于 19的数,会直接取 -20 或 19。
优先级设置如果不合理的话,会导致优先级低的进程,长时间得不到CPU资源,造成进程饥饿.
2 进程切换
在讲进程切换之前,我们首先补充四个概念。
竞争性,独立性,并行,并发。
竞争性:因为CPU资源占少量,而进程数量众多,所以,进程之间是具有竞争属性的。 为了高效完成任务, 更合理竞争相关资源,便有了优先级。
独立性:多进程运行,需要独享各种资源,多进程运行期间互不干扰。 task_struct + 代码和数据
并行:多个进程在多个CPU下同时运行,这个叫并行。
并发:多个进程在一个CPU下采用进程切换的方式同时运行,在一段时间内,使得多个都得以推进。
还记得我们之前提到过的基于时间片的分时操作系统吗?着就是并发的,大家的电脑的CPU基本上都只有一个,所以,进程都是并发执行的。 这样来回更换进程,不会卡卡的吗? 评价是CPU运行速度超快,不要用人的眼光来看CPU运行的速度,
有了这个理解之后,为什么死循环的程序不会卡死CPU? 就是因为有这个时间片。
CPU跑程序不会直接跑完整个程序,而是跑一定的时间,就是这个时间片的时间。然后这个程序就会从CPU里面拿下来,然后然换下一个,等着继续轮到它,所以,进程不会一直占有CPU。
我们再来聊聊CPU里面的寄存器。
CPU里面有很多寄存器,相信大家之前多少都听说过一些。CPU里面内置了很多寄存器,比如说pc/EIP(程序计数器),ebp,esp 栈底栈顶指针。 eax,ebx,ecx,edx等等通用寄存器。还有什么块寄存器cs/ds/es/fg/gs
还有程序状态字,叫eflags,还有什么cr0~cr4 等等,后续我们会陆续谈到。
寄存器里面存放的一般是正在运行的进程产生的临时数据,以这个pc指针为例,简单说一下,这个就是用来记录到程序现在进行到哪一行了。之前不是提到过基于时间片的分时操作系统嘛,为什么进程切换出去再切换回来还能继续执行,就是因为他跑的那一些的数据储存在寄存器里面。
这里要特别提一个容器搞混的点,寄存器是CPU里面的临时空间,寄存器是只有一份的,但是寄存器里面的数据是变化的,多分的。寄存器不等于寄存器里面存储的数据。
2.1 如何切换
那么进程如何切换呢?我们举一个当兵的例子。比如说,现在大学生小王刚刚大三,想要去当兵,他能直接就是什么也不干,拍拍屁股直接走人吗?肯定不行,真这么干了早就因为缺勤被开除了。
所以,小王去当兵之前,一定要和这个导员说一声,导员上报学校,然后把小王的学籍先留下来,档案交给小王保管。然后小王开开心心当一年兵,变成退伍老兵后,小王回来继续上学,小王就把档案交给导员,然后小王继续上学。
这个例子里面呢,学校就是CPU,进程是小王,导员是调度器,学籍就是小王的运行数据(也叫上下文数据),保留学籍就是把小王的运行数据,也就是寄存器里面的内容保存起来,回复学籍就是把保存的内容加载回寄存器里面。
去当兵就是进程从CPU剥离下来。
这个例子一举是不是就清晰一些了,我们再来看看具体的:
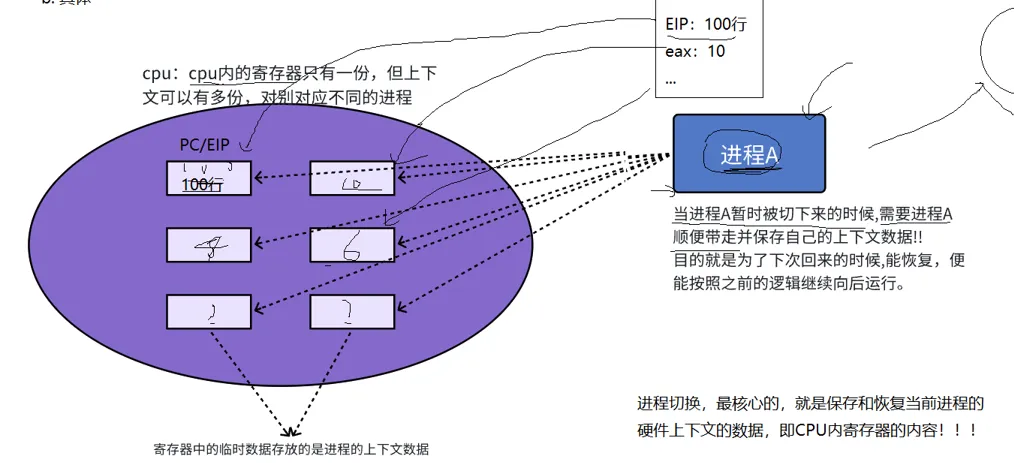
进程A在CPU中运行,A中的寄存器里面存着A进程的上下文数据,例如这个PC指针,假设代表着A运行到了一百行的地方。
等到时间到了,进程A就被剥离下来,A临走的时候,要顺便带走A自己的上下文信息,目的就是为了下次再回来继续运行。
那么A带走的这个上下文数据去了那里?我们暂且不表,先弄明白这个过程。
由此,我们可以看出,进程切换最核心的,就是保存和恢复当前进程的数据和上下文的数据,即CPU内寄存器的内容。
当有一个进程B来了的时候,寄存器里面的上下文就被B进程的给覆盖掉,然后重复这个过程。
还有一点要注意: CPU内寄存器只有一份,但是寄存器里面存的上下文数据可以有很多份,分别对应不同的进程。
再回来,填个小坑,被进程A剥离时带走的上下文数据去了哪里?其实时保存到了A这个进程的task_struct里面,的一个结构体,我们管它叫TSS,意思是任务状态段。

2.2 Linux 真实的调度算法 O(1)调度算法
我们之前提到过 1 个 CPU, 一个调度队列。
那么,这个调度队列里面的结构是什么呢?可不仅仅只是task_struct的队列,
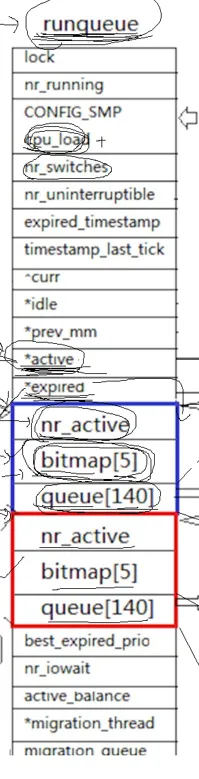
这是这个runqueue的结构,可以看到,这个结构里面包含了很多信息。其中, 这个queue140就是我们之前提到的"调度队列",也就是task_struct的队列。其实,这也不是简单的队列,接着看。
为什么是一百十四个,因为我们优先级有一百四十个。 这里有同学或许就有疑问了,之前不是说优先级只有60,99,只有四十个吗?那一百个怎么来的?
还记得我们提到过的,我们现在用的操作系统,是基于时间片的分时操作系统吗? 还有一种操作系统,就是实时操作系统。
实时操作系统主要运用在应用领域,比如说无人驾驶汽车。这个和分时操作系统有什么区别呢?实时操作系统,新来哪个进程,哪个进程优先级最高。
为什么?比方说,我现在整在无人驾驶汽车,听着歌,前面突然来了个大运,我操肯定要赶紧刹车,刹车或者说拐弯的优先级肯定是要最高的。如果是分时操作系统,基于时间片,突然来个大运,操作系统还在慢悠悠地把这个歌放完,然后再做反应,这肯定是不行的。
这个0,99,也就是前一百个优先级,就是给实时操作系统用的。在分时操作系统里面,也就是我们用的linux,前一百个优先级是禁止使用的,被封掉了,所以,我们就不考虑了。
但是,思考一个问题,这里的数组能用的地方是从 100 开始的 到 139 , 而我们的优先级 是 60 到 99 ,所以这里肯定是要哈希一下,处理哈希冲突这里用的是链地址法,开散列的。
哈希函数就是 x - 60 + (140 - 40) = x + 40;
哈希完了以后,每一个进程的PCB就被链在了哈希表中,哈希表的查找时间复杂度O(1),所以,我们调进程的时间复杂度就差不多是O(1).
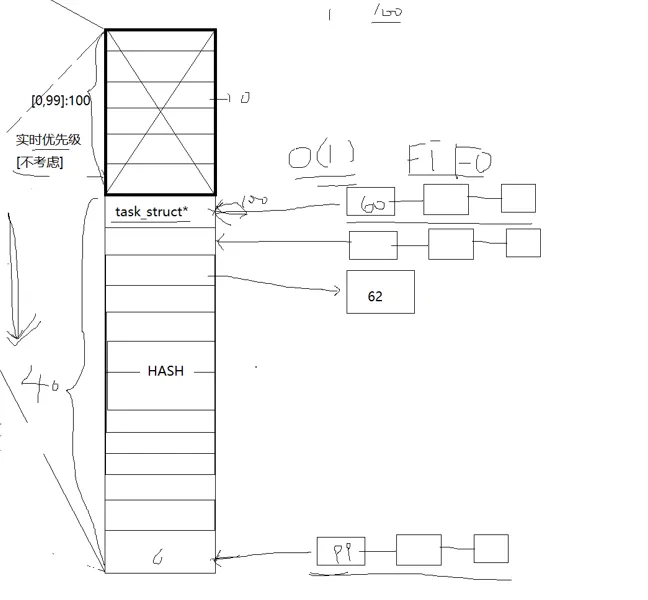
下面的问题是如何挑进程,调度器按照进程的优先级来找进程,每次都要遍历这个表,这个表里面或许有些地方还是空的,那这样是不是有些时间复杂度高了一些,别忘了我们这个调度算法叫O(1)调度算法。

这个时候,就要用到这个bitmap5了,这是个什么呢?这是位图。二进制位是不是有0和1两种状态,那么我就可以利用这个二进制位来表示哈希表对应的下标处有没有进程。 为什么选 5 ,一个整形大小 32 个比特位, 4 个话是 128 少了, 6个是 192 太多了, 一共就一百四十个嘛。 5 就正好之多一点。
这样,每次调进程的时候,先去这个位图里面看看那个位置有,那个没有,直接去第一个有的里面拿进程,这样挑队列的时间复杂度也近似是O(1).
这个调度算法看起来是不是已经很完美了?但是,记不记得,时间片的进程调度是要把进程剥离的,剥离后的进程去哪里呢?
我们再看这个蓝色框里面的,还有一个元素是nr_active,这个就是代表这个这个queue140里面还有多少个进程。
其实,上述讲的哈希表,位图,还有这个nr_active,是放在一个结构体里面的。
c
strcut rqueue_elem
{
int nr_active;
bitmap[5];
queue[140];
}而这个runqueue的调度队列里面,有一个这个结构体的数组,两个元素
c
struct rqueue_elem prio_array[2];这两个元素一个代表活跃进程队列,一个代表过期进程队列,从上图中也能看出来,一个是蓝框,一个红框,一模一样
c
struct rqueue_elem *active = & prio_array[0];
struct rqueue_elem *expired = & prio_array[1];敏锐的同学应该知道要干什么了。
当这个活跃的进程队列里面有进程剥离下来,就把它放到这个过期队列里面。等到这个活跃队列里面nr_active为0了以后,
c
swap(&active, &expired);交换一下指针的指向。这样,既不会乱优先级,还完美解决问题。
这就是linux的O(1),调度算法,一个谷歌的工程师设计的好像。
然后,我们再补充几个知识,顺便填填坑。
比如说,一个新进程来了以后,是去这个活跃队列里面,还是过期队列。按照先到先得的话,肯定是去过期队列里面是更合理的。
我们之前提到过,分时操作系统是可以支持这个优先级修改的,也就是支持内核优先级抢占。我们是通过修改nice值的方式来修改进程优先级的。为什么不直接修改呢?如果直接修改,假设现在有一个进程在活跃队列里面,我直接修改它的优先级,那它放到哪里,直接放到对应优先级的位置?显然是不合理的。就直接跳过CPU放到过期队列,其实也是不合理的。
所以,我们通过修改这个进程nice值,等到这个进程要放到过期队列的时候,然后加上修改的nice值,这样就可以合理修改进程优先级而不去,而不用去修改我们的算法。 这是这个使用 nice值的第二个好处。
我们可以再来看看这个runqueue里面的其它信息,首先就是 lock锁,这个和进程安全有关,后期提到。
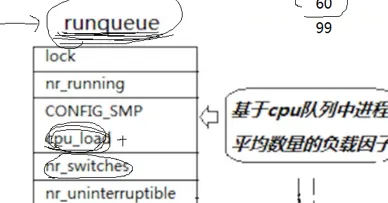
然继续看这个CPU负载因子,这是干嘛用的呢?如果我们有两个CPU的话,如果第一个CPU的调度队列里面有100个进程,第二个CPU调度队列里面只有 20 个,这样利用率过于不平衡是不是也不好,所以,有这个CPU负载因子来调整两个CPU的调度的进程。
如果查看CPU信息呢? 之前提到过/proc里面是内存中的文件,里面有个文件夹是 cpuinfo 列一下就好
bash
ls /proc/cpuinfog-2U2GZ8M1-1776238786724)]
然继续看这个CPU负载因子,这是干嘛用的呢?如果我们有两个CPU的话,如果第一个CPU的调度队列里面有100个进程,第二个CPU调度队列里面只有 20 个,这样利用率过于不平衡是不是也不好,所以,有这个CPU负载因子来调整两个CPU的调度的进程。
如果查看CPU信息呢? 之前提到过/proc里面是内存中的文件,里面有个文件夹是 cpuinfo 列一下就好
bash
ls /proc/cpuinfo