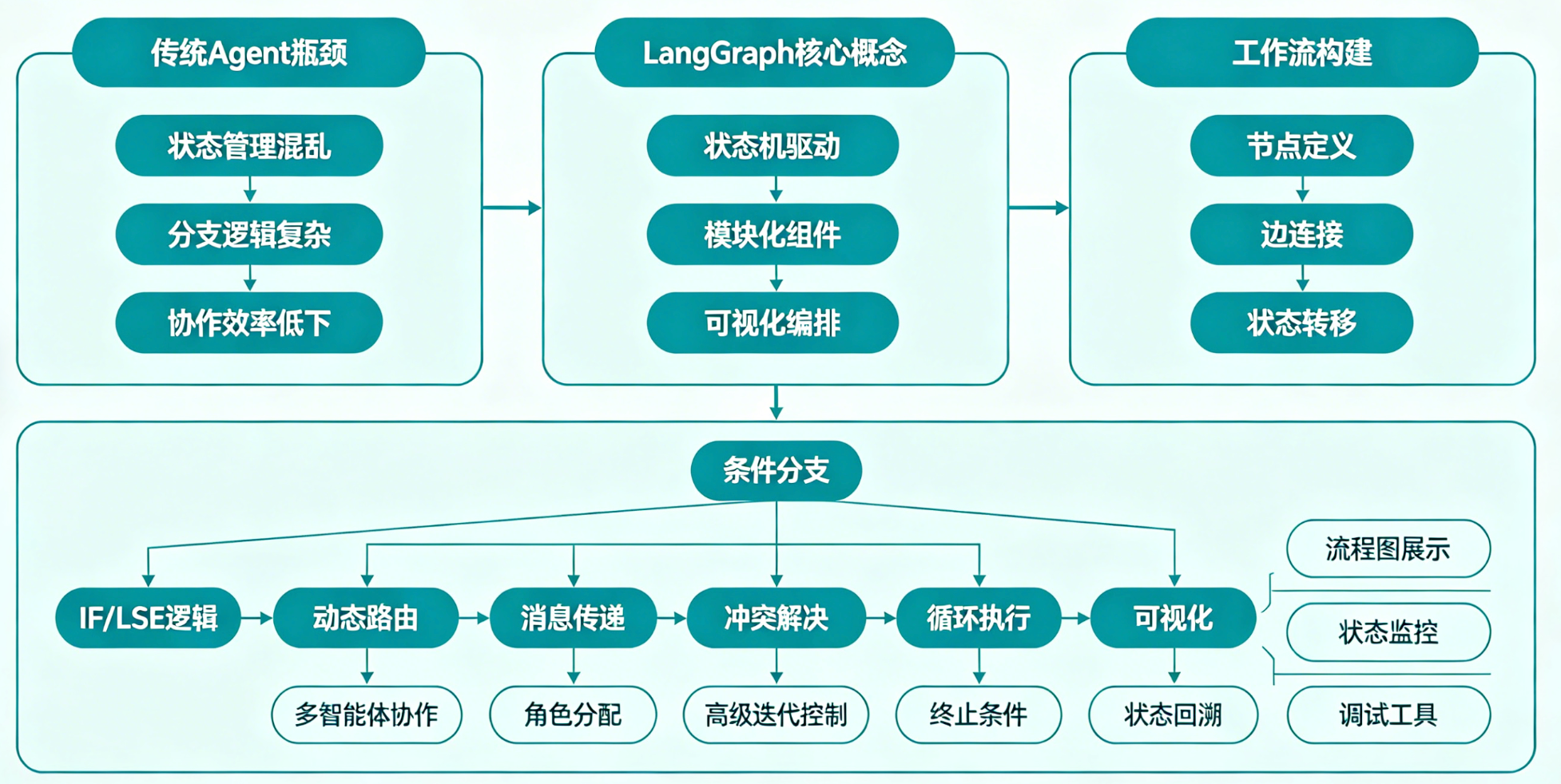
在人工智能应用快速落地的今天,智能体Agent已经成为连接大模型与实际业务的关键桥梁。从简单的问答交互,到复杂的内容创作、数据分析、多步骤任务处理,Agent正在不断拓展大模型的应用边界。早期我们借助LangChain搭建基础Agent时,确实能够快速实现工具调用、简单推理等功能,但在面对真实业务场景中复杂的流程控制、多角色协作、循环迭代等需求时,传统Agent的局限性被无限放大。而LangGraph的出现,正是为了解决这些痛点,它以状态机和有向无环图为核心,让智能体的工作流从不可控的黑箱,变成可定义、可调试、可扩展的结构化系统。本文将从基础Agent的困境出发,深入解析LangGraph的核心概念、构建逻辑与实战应用,帮助开发者真正掌握高级智能体的开发方法。
一、传统Agent的瓶颈:为什么我们需要LangGraph
在LangGraph出现之前,大多数开发者使用的都是LangChain提供的基础Agent,比如Zero-shot ReAct。这类Agent依托大模型的推理能力,能够根据用户问题自主判断是否需要调用工具、调用何种工具,看似灵活高效,却在实际项目中暴露出难以忽视的缺陷。
首先是流程完全不可控。基础Agent的执行逻辑完全由大模型主导,开发者无法预设固定的执行顺序,也不能强制要求"先执行调研,再完成撰写,最后进行校对"。在处理多步骤任务时,经常出现步骤混乱、重复执行、遗漏关键环节的问题,导致任务失败率居高不下。
其次是缺乏统一的状态管理。基础Agent没有专门的中间数据存储容器,调研结果、草稿内容、修改意见等关键信息,只能依赖大模型的上下文窗口传递。一旦上下文过长被截断,或是步骤跳转过多,中间数据就会丢失,后续节点无法复用之前的执行结果,严重影响任务连贯性。
再者是无法实现多智能体协作。传统Agent是单一主体模式,只能由一个智能体完成所有任务,无法拆分出调研、写作、校对等独立角色,更不能实现分工协作。面对复杂任务时,单一智能体容易出现决策混乱、专业度不足的问题。
最后是分支与循环能力薄弱。实际业务中经常需要"校对不通过则返回修改""执行失败则重试"等逻辑,但基础Agent难以实现精准的条件分支,更无法控制循环次数,要么陷入死循环,要么提前终止流程,无法满足复杂业务需求。
正是这些痛点,催生了LangGraph的诞生。作为LangChain生态中专门用于构建高级Agent的核心库,LangGraph基于状态机和有向无环图思想,彻底解决了传统Agent的四大缺陷,让智能体工作流实现精准管控、状态共享、多体协作与灵活迭代,成为复杂智能体开发的首选工具。
二、LangGraph核心基石:状态与节点的协同逻辑
LangGraph的本质是状态机驱动的图结构工作流,而状态(State)和节点(Node)是构成这一系统的两大核心要素,二者相互配合,实现数据流转与逻辑执行的完美统一。
(一)状态:工作流的统一数据中心
状态可以理解为整个智能体工作流的数据容器,所有中间结果、执行参数、判断标识都存储在状态中,是各个节点之间数据传递的唯一桥梁。它打破了传统Agent数据传递依赖上下文的局限,实现了数据的共享与持久化。
LangGraph提供两种定义状态的方式,分别适用于不同场景。第一种是Pydantic定义法,通过BaseModel构建结构化状态,自带数据校验功能,适合对数据格式有严格要求的项目,代码示例如下:
python
from pydantic import BaseModel, Field
class WritingState(BaseModel):
topic: str = Field(description="写作主题")
research_data: str = Field(default="", description="调研资料")
draft: str = Field(default="", description="文章草稿")
review_comment: str = Field(default="", description="校对意见")
is_approved: bool = Field(default=False, description="是否通过校对")第二种是TypedDict定义法,无需数据校验,格式更加灵活,适合快速开发简单工作流,代码示例如下:
python
from typing import TypedDict
class WritingState(TypedDict):
topic: str
research_data: str
draft: str
review_comment: str
is_approved: bool无论采用哪种方式,状态都具备可修改、可共享的特性,每个节点都能读取状态中的数据,也能对状态进行更新,确保数据在整个工作流中无缝传递。
(二)节点:工作流的最小执行单元
节点是LangGraph中执行具体逻辑的模块,对应工作流中的一个步骤,比如调研、撰写、校对都可以独立成为一个节点。每个节点接收当前状态作为输入,执行完业务逻辑后,返回修改后的状态,完成数据更新。
节点具有高度独立性,可单独开发、测试与复用,既可以是普通函数,也可以是LangChain的Chain、Agent,甚至是另一个LangGraph工作流,扩展性极强。以写作工作流为例,三个基础节点的定义代码如下:
python
from langchain.chat_models import ChatOpenAI
from dotenv import load_dotenv
import os
load_dotenv()
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.3)
# 调研节点
def research_node(state: WritingState) -> WritingState:
prompt = f"围绕主题{state['topic']}收集3条核心调研资料,简洁准确"
research_data = llm.invoke(prompt).content
return {**state, "research_data": research_data}
# 撰写节点
def write_node(state: WritingState) -> WritingState:
prompt = f"根据调研资料{state['research_data']}撰写300字左右文章"
draft = llm.invoke(prompt).content
return {**state, "draft": draft}
# 校对节点
def review_node(state: WritingState) -> WritingState:
prompt = f"校对草稿{state['draft']},检查语法与逻辑,无误则返回通过"
comment = llm.invoke(prompt).content
is_approved = "通过" in comment
return {**state, "review_comment": comment, "is_approved": is_approved}状态与节点的关系清晰明了,节点是逻辑的执行者,状态是数据的承载者,节点通过修改状态实现数据传递,状态为节点提供执行所需的全部信息,二者共同构成了LangGraph的基础运行框架。
三、构建基础工作流:有向无环图的实战应用
LangGraph的工作流基于有向无环图(DAG)构建,节点作为图的顶点,节点间的执行顺序作为图的边,无循环、方向固定,确保工作流按照预设顺序稳定执行。构建基础DAG工作流只需三步,定义状态、定义节点、搭建图结构,下面以"调研→撰写→校对"线性工作流为例,完成完整实战。
(一)环境准备与依赖安装
首先需要安装LangGraph及相关依赖,命令如下:
shell
pip install langgraph langchain openai python-dotenv(二)线性工作流完整代码实现
python
from langgraph.graph import Graph, END
from typing import TypedDict
from langchain.chat_models import ChatOpenAI
from dotenv import load_dotenv
import os
load_dotenv()
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.3)
# 定义状态
class WritingState(TypedDict):
topic: str
research_data: str
draft: str
review_comment: str
is_approved: bool
# 定义节点
def research_node(state: WritingState) -> WritingState:
prompt = f"围绕{state['topic']}收集3条核心调研资料"
research_data = llm.invoke(prompt).content
return {**state, "research_data": research_data}
def write_node(state: WritingState) -> WritingState:
prompt = f"根据资料{state['research_data']}撰写300字文章"
draft = llm.invoke(prompt).content
return {**state, "draft": draft}
def review_node(state: WritingState) -> WritingState:
prompt = f"校对{state['draft']},无误返回通过"
comment = llm.invoke(prompt).content
is_approved = "通过" in comment
return {**state, "review_comment": comment, "is_approved": is_approved}
# 构建DAG图
graph = Graph(state_schema=WritingState)
# 添加节点
graph.add_node("research", research_node)
graph.add_node("write", write_node)
graph.add_node("review", review_node)
# 定义执行顺序
graph.add_edge("research", "write")
graph.add_edge("write", "review")
graph.add_edge("review", END)
# 设置起始节点
graph.set_entry_point("research")
# 编译工作流
app = graph.compile()
# 执行工作流
initial_state = {
"topic": "LangGraph核心用法解析",
"research_data": "",
"draft": "",
"review_comment": "",
"is_approved": False
}
final_state = app.invoke(initial_state)这种线性DAG工作流流程固定、无分支无循环,适合简单的顺序执行任务,能够保证步骤有序执行,解决了传统Agent流程混乱的问题。
四、条件分支:让工作流具备决策能力
线性工作流只能处理固定流程,而实际业务往往需要根据执行结果选择不同路径,比如校对通过则结束任务,不通过则返回修改。LangGraph通过条件边(Conditional Edges) 实现分支决策,让工作流具备智能判断能力。
(一)条件边的核心逻辑
条件边通过add_conditional_edges方法定义,核心是编写条件判断函数,根据状态中的关键字段,返回下一个执行节点或结束标识END,实现分支跳转。对于简单的布尔值判断,还可以通过mapping参数简化代码,无需编写复杂的判断函数。
(二)带分支的工作流实战
python
from langgraph.graph import Graph, END
from typing import TypedDict
from langchain.chat_models import ChatOpenAI
from dotenv import load_dotenv
import os
load_dotenv()
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0.3)
class WritingState(TypedDict):
topic: str
research_data: str
draft: str
review_comment: str
is_approved: bool
# 节点定义与之前一致
def research_node(state: WritingState) -> WritingState:
prompt = f"围绕{state['topic']}收集3条核心调研资料"
research_data = llm.invoke(prompt).content
return {**state, "research_data": research_data}
def write_node(state: WritingState) -> WritingState:
prompt = f"根据资料{state['research_data']}和意见{state['review_comment']}修改文章"
draft = llm.invoke(prompt).content
return {**state, "draft": draft}
def review_node(state: WritingState) -> WritingState:
prompt = f"校对{state['draft']},无误返回通过"
comment = llm.invoke(prompt).content
is_approved = "通过" in comment
return {**state, "review_comment": comment, "is_approved": is_approved}
# 构建带条件分支的图
graph = Graph(state_schema=WritingState)
graph.add_node("research", research_node)
graph.add_node("write", write_node)
graph.add_node("review", review_node)
graph.add_edge("research", "write")
graph.add_edge("write", "review")
# 添加条件边,简化写法
graph.add_conditional_edges(
start_node="review",
condition=lambda state: state["is_approved"],
mapping={True: END, False: "write"}
)
graph.set_entry_point("research")
app = graph.compile(max_steps=5)代码中通过max_steps参数限制最大循环次数,避免因校对不通过陷入无限循环,让分支与循环逻辑更加安全可控。此时工作流会根据校对结果,自动选择结束或重新撰写,完美适配复杂业务的决策需求。
五、多智能体协作:分工协同完成复杂任务
LangGraph最核心的优势之一,是原生支持多Agent协作,我们可以将不同功能的智能体作为独立节点,通过状态共享数据,实现分工明确、高效协同的工作模式。多Agent协作主要有流水线架构和决策-执行架构两种形式。
(一)流水线架构
流水线架构适合流程固定的任务,多个智能体按顺序执行,各自负责单一环节,比如调研Agent负责收集资料,写作Agent负责生成内容,校对Agent负责审核修改,形成完整的生产流水线。
(二)决策-执行架构
决策-执行架构适合流程多变的复杂任务,设置一个核心决策Agent,负责分配任务、判断流程走向,其他执行Agent负责具体操作,执行完成后反馈给决策Agent,由决策Agent决定下一步动作,灵活性更高。
(三)带工具的多Agent实战
实际应用中,智能体需要调用工具增强能力,比如调研Agent调用搜索引擎获取实时资料。以下是集成DuckDuckGo搜索工具的多Agent协作代码:
python
from langchain.tools import DuckDuckGoSearchRun
search_tool = DuckDuckGoSearchRun()
def research_agent_with_tool(state: WritingState) -> WritingState:
from langchain.agents import initialize_agent, AgentType
agent = initialize_agent(
tools=[search_tool],
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION
)
data = agent.run(f"围绕{state['topic']}收集3条最新资料")
return {**state, "research_data": data}将该节点替换原有调研节点,即可让调研Agent具备实时搜索能力,多Agent协作的专业性与实用性大幅提升。同时,多Agent架构具备极强的可扩展性,随时可以添加排版、发布等新智能体,无需改动原有流程。
六、高级迭代控制:Plan-and-Execute架构解析
对于高度复杂、模糊的任务,简单的循环分支无法满足需求,LangGraph支持Plan-and-Execute(规划-执行)高级迭代架构,让智能体先自主规划任务步骤,再逐步执行,最后反思优化,实现自主迭代。
该架构包含三个核心节点,规划节点生成任务步骤,执行节点按步骤完成任务,反思节点检查结果并判断是否需要重新规划。通过条件边实现"规划→执行→反思→重新规划"的循环,直到任务完成。这种模式让智能体具备自主决策与优化能力,适合内容创作、项目管理、数据分析等复杂场景。
七、工作流可视化:调试与优化的关键手段
LangGraph工作流节点与边数量较多时,直观查看结构与执行路径至关重要。LangGraph提供两种可视化方式,一是LangSmith平台可视化 ,配置环境变量后,可实时追踪图结构、执行顺序与状态变化,适合开发调试;二是内置函数导出图片,通过graphviz将工作流导出为PNG图片,快速查看结构,代码如下:
python
from langgraph.graph import draw_graph
draw_graph(graph, format="png", filename="writing_workflow")可视化功能极大提升了工作流的调试效率,能够快速定位流程错误、节点故障,同时方便团队协作沟通,统一对工作流的理解。
八、实战总结:LangGraph重构智能体开发思维
通过全文的解析与实战可以发现,LangGraph不仅仅是一个工具库,更是一种全新的智能体开发思维。它摒弃了传统Agent依赖大模型盲目推理的模式,以状态机为核心,用结构化图结构定义工作流,让智能体从不可控的黑箱,变成可设计、可调试、可扩展的标准化系统。
在实际项目中,LangGraph的应用场景极为广泛,内容创作领域可实现调研、撰写、校对、发布的全流程自动化,数据分析领域可完成数据采集、清洗、分析、可视化的协同作业,企业服务中可搭建多角色智能客服,处理复杂客户咨询。无论是简单的线性任务,还是复杂的多体协作、迭代优化,LangGraph都能提供稳定高效的解决方案。
对于开发者而言,掌握LangGraph,就意味着掌握了高级智能体开发的核心能力。从状态与节点的基础设计,到条件分支、多Agent协作、Plan-and-Execute架构的进阶应用,再到可视化调试优化,每一个环节都在提升智能体的实用性与可靠性。随着大模型技术的不断发展,智能体将成为AI应用的主流形态,而LangGraph作为构建复杂智能体的核心工具,必将在AI开发领域占据越来越重要的地位。