摘要
本文系统介绍了RAG(检索增强生成)技术,阐述其通过结合LLM参数化知识与外部非参数化知识解决大模型幻觉、知识滞后等问题的核心机制,对比了Naive/Advanced/Modular三阶段架构演进,并详细讲解了从数据准备、索引构建到检索优化的完整工程实践,包括文本分块策略、向量数据库选型及FAISS/rerank等关键优化方向。
1. RAG简介
RAG技术一句话总结:RAG 就是让 LLM 学会了"开卷考试",它既能利用自己学到的知识,也能随时查阅外部资料。
从本质上讲,RAG(Retrieval-Augmented Generation)是一种旨在解决大语言模型(LLM)"知其然不知其所以然"问题的技术范式。它的核心是将模型内部学到的"参数化知识"(模型权重中固化的、模糊的"记忆"),与来自外部知识库的"非参数化知识"(精准、可随时更新的外部数据)相结合 。其运作逻辑就是在 LLM 生成文本前,先通过检索机制从外部知识库中动态获取相关信息,并将这些"参考资料"融入生成过程,从而提升输出的准确性和时效性。
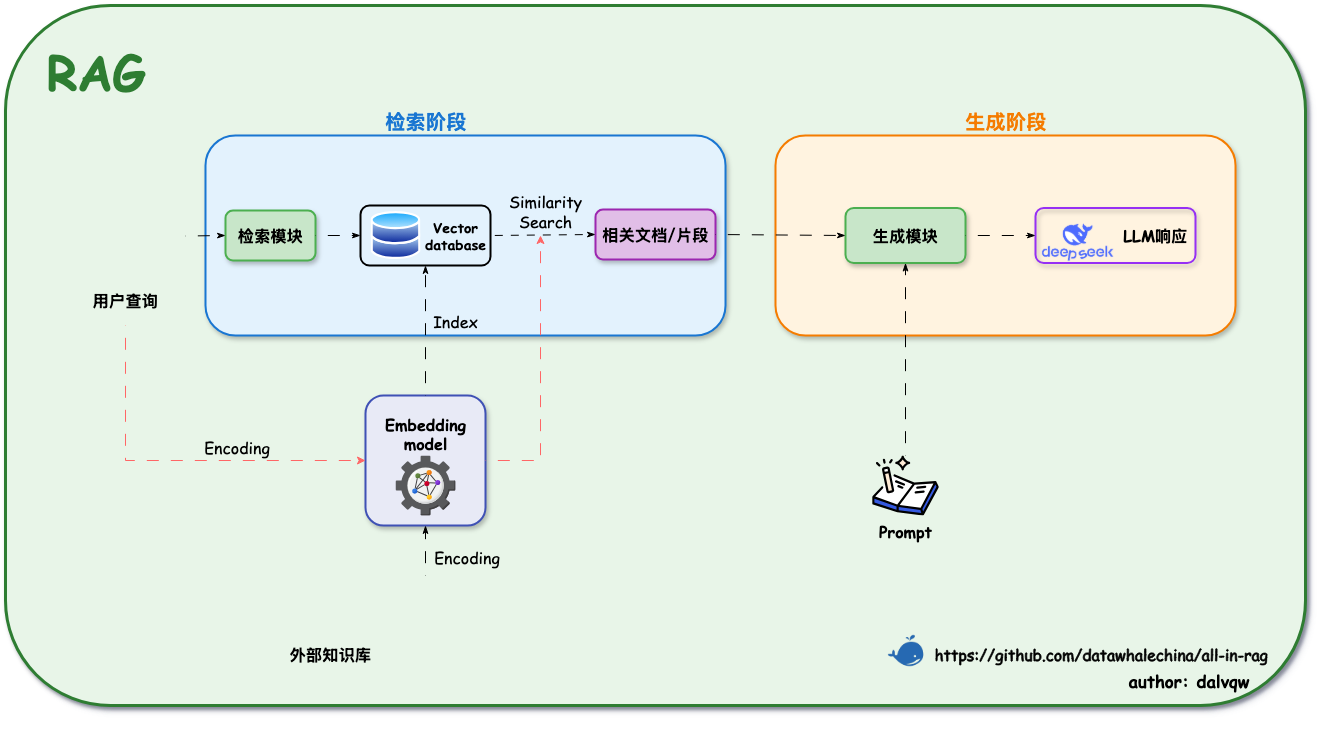
如图所示,其架构主要通过两个阶段来完成这一过程:
- 检索阶段:寻找"非参数化知识"
-
- 知识向量化 :嵌入模型(Embedding Model) 充当了"连接器"的角色。它将外部知识库编码为向量索引(Index),存入向量数据库。
- 语义召回 :当用户发起查询时,检索模块利用同样的嵌入模型将问题向量化,并通过相似度搜索(Similarity Search),从海量数据中精准锁定与问题最相关的文档片段。
- 生成阶段:融合两种知识
-
- 上下文整合 :生成模块接收检索阶段送来的相关文档片段以及用户的原始问题。
- 指令引导生成 :该模块会遵循预设的 Prompt 指令,将上下文与问题有效整合,并引导 LLM(如 DeepSeek)进行可控的、有理有据的文本生成。
RAG的技术架构经历了从简单到复杂的演进,如图大致可分为三个阶段
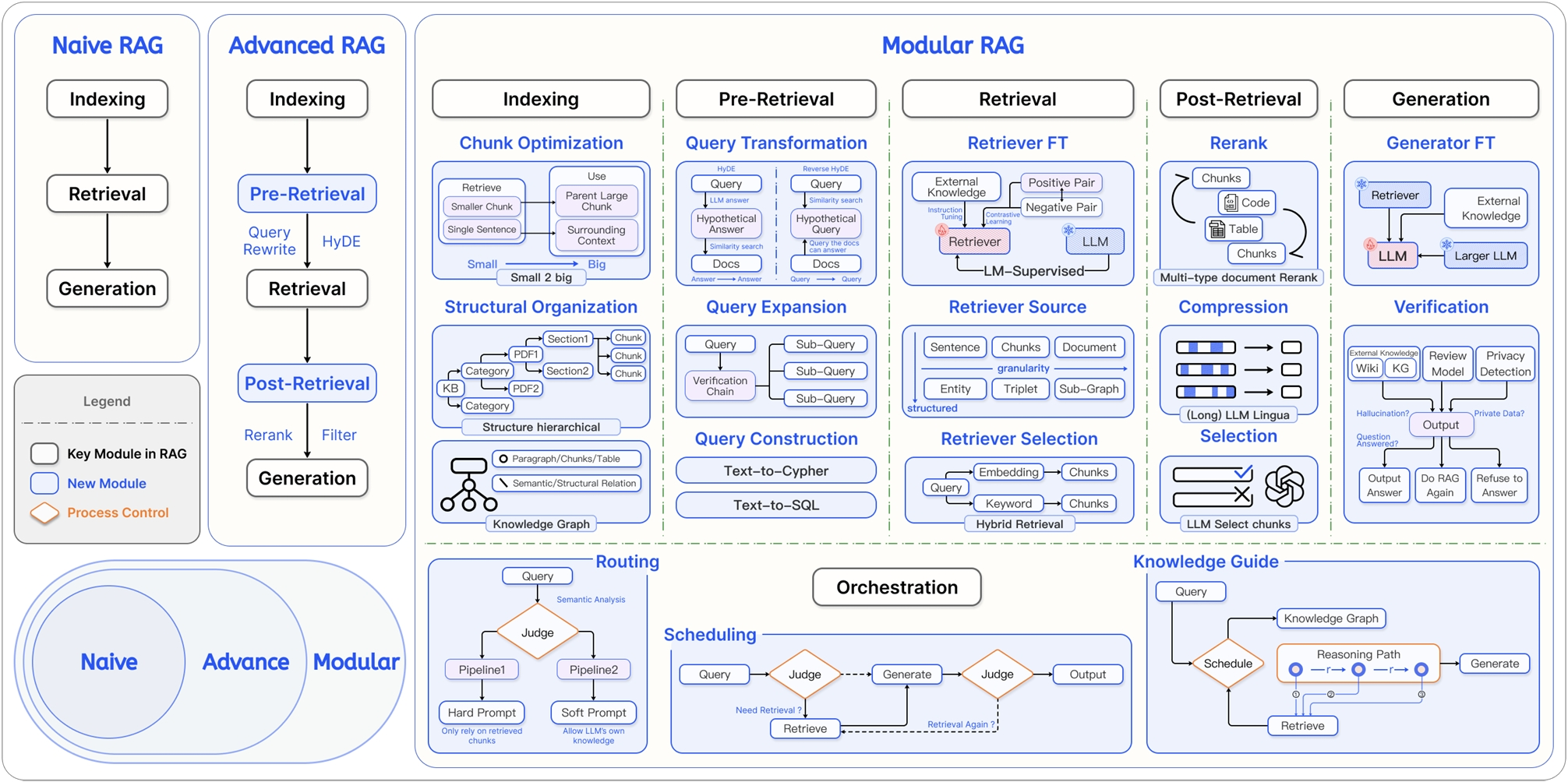
那么,RAG 系统是如何实现"参数化知识"与"非参数化知识"的结合呢?这三个阶段的具体对比如表所示。
|----------|--------------------------------|------------------------------------------|-------------------------------------------------------------------|
| | 初级 RAG(Naive RAG) | 高级 RAG (Advanced RAG) | 模块化 RAG (Modular RAG) |
| 流程 | 离线: 索引 在线: 检索 → 生成 | 离线: 索引 在线: 检索前 →检索后 → | 积木式可编排流程 |
| 特点 | 基础线性流程 | 增加检索前后的优化步骤 | 模块化、可组合、可动态调整 |
| 关键技术 | 基础向量检索 | 查询重写(Query Rewrite) 结果重排(Rerank) | 动态路由(Routing) 查询转换(Query Transformation) 多路融合(Fusion) |
| 局限性 | 效果不稳定,难以优化 | 流程相对固定,优化点有限 | 系统复杂性高 |
"离线"指提前完成的数据预处理工作(如索引构建);"在线"指用户发起请求后的实时处理流程。
2. 为什么要使用RAG?
在选择具体的技术路径时,一个重要的考量是成本与效益的平衡 。通常,我们应优先选择对模型改动最小、成本最低的方案,所以技术选型路径往往遵循的顺序是提示词工程(Prompt Engineering) -> 检索增强生成 -> 微调(Fine-tuning)。
我们可以从两个维度来理解这些技术的区别。如图 1-3 所示,横轴代表"LLM 优化" ,即对模型本身进行多大程度的修改。从左到右,优化的程度越来越深,其中提示工程和 RAG 完全不改变模型权重,而微调则直接修改模型参数。纵轴代表"上下文优化",是对输入给模型的信息进行多大程度的增强。从下到上,增强的程度越来越高,其中提示工程只是优化提问方式,而 RAG 则通过引入外部知识库,极大地丰富了上下文信息。
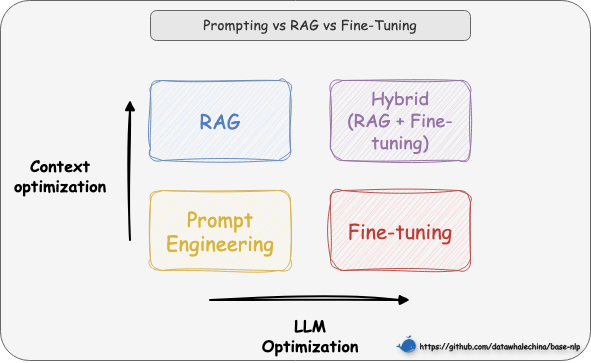
基于此,我们的选择路径就清晰了:
- 先尝试提示工程:通过精心设计提示词来引导模型,适用于任务简单、模型已有相关知识的场景。
- 再选择 RAG:如果模型缺乏特定或实时知识而无法回答,则使用 RAG,通过外挂知识库为其提供上下文信息。
- 最后考虑微调:当目标是改变模型"如何做"(行为/风格/格式)而不是"知道什么"(知识)时,微调是最终且最合适的选择。例如,让模型学会严格遵循某种独特的输出格式、模仿特定人物的对话风格,或者将极其复杂的指令"蒸馏"进模型权重中。
RAG 的出现填补了通用模型与专业领域之间的鸿沟,它在解决如表 1-2 所示 LLM 局限时尤其有效:
|-----------------------|-------------------|
| 问题 | RAG的解决方案 |
| 静态知识局限 | 实时检索外部知识库,支持动态更新 |
| 幻觉(Hallucination) | 基于检索内容生成,错误率降低 |
| 领域专业性不足 | 引入领域特定知识库(如医疗/法律) |
| 数据隐私风险 | 本地化部署知识库,避免敏感数据泄露 |
3. RAG技术关键优势
- 准确性与可信度的双重提升: RAG 最核心的价值在于突破了模型预训练知识的限制 。它不仅能补充专业领域的知识盲区 ,还能通过提供具体的参考材料,有效抑制"一本正经胡说八道"的幻觉现象 。论文研究还表明,RAG 生成的内容在具体性 和多样性 上也显著优于纯 LLM。更重要的是,RAG 具备可溯源性------每一条回答都能找到对应的原始文档出处,这种"有据可查"的特性极大提高了内容在法律、医疗等严肃场景下的可信度。
- 时效性保障: 在知识更新方面,RAG 解决了LLM 固有的知识时滞问题(即模型不知道训练截止日期之后发生的事) 。RAG允许知识库独立于模型进行动态更新 ------新政策或新数据一旦入库,立刻就能被检索到。这种能力在论文中被称为**"索引热拔插"(Index Hot-swapping)**------就像给机器人换一张存储卡一样,瞬间切换其世界知识库,而无需重新训练模型,实现了知识的实时在线。
- 显著的综合成本效益: 从经济角度看,RAG 是一种高性价比的方案。首先,它避免了高频微调带来的巨额算力成本 ;其次,由于有了外部知识的强力辅助,**我们在处理特定领域问题时,往往可以使用参数量更小的基础模型来达到类似的效果,从而直接降低了推理成本。**这种架构也减少了试图将海量知识强行"塞入"模型权重中所需的计算资源消耗。
- 灵活的模块化可扩展性: RAG 的架构具备极强的包容性,支持多源集成,无论是 PDF、Word 还是网页数据,都能统一构建进知识库中 。同时,其模块化设计实现了检索与生成的解耦,这意味着我们可以独立优化检索组件(比如更换更好的 Embedding 模型),而不会影响到生成组件的稳定性,便于系统的长期迭代。
4. RAG技术适用场景风险分级
表展示了 RAG 技术在不同风险等级场景中的适用性。
|----------|-----------|------------|
| 风险等级 | 案例 | RAG适用性 |
| 低风险 | 翻译/语法检查 | 高可靠性 |
| 中风险 | 合同起草/法律咨询 | 需结合人工审核 |
| 高风险 | 证据分析/签证决策 | 需严格质量控制机制 |
5. 如何构建专业领域RAG
5.1. 基础工具链选择
构建 RAG 系统通常涉及几个关键环节的选型。在开发模式上,我们可以利用 LangChain 或 LlamaIndex 等成熟框架快速集成,也可以选择不依赖框架的原生开发,以获得对系统流程更精细的控制力(在 AI 编程辅助下这并非难事)。而在记忆载体(向量数据库)方面,既有 Milvus、Pinecone 等适合大规模数据的方案,也有 FAISS、Chroma 等轻量级或本地化的选择,需根据具体业务规模灵活决定。后期为了量化效果,还可以引入 RAGAS 或 TruLens 等自动化评估工具。
5.2. 四步构建最小可行系统(MVP)
- 数据准备与清洗:这是系统的地基。我们需要将 PDF、Word 等多源异构数据标准化,并采用合理的分块策略(如按语义段落切分而非固定字符数),避免信息在切割中支离破碎。
- 索引构建:将切分好的文本通过嵌入模型转化为向量,并存入数据库。可以在此阶段关联元数据(如来源、页码),这对后续的精确引用很有帮助。
- 检索策略优化:不要依赖单一的向量搜索。可以采用混合检索(向量+关键词)等方式来提升召回率,并引入重排序模型对检索结果进行二次精选,确保 LLM 看到的都是精华。
- 生成与提示工程:最后,设计一套清晰的 Prompt 模板,引导 LLM 基于检索到的上下文回答用户问题,并明确要求模型"不知道就说不知道",防止幻觉。
5.3. 新手友好方案
如果希望快速验证想法而非深耕代码,可以尝试 FastGPT 或 Dify 这样的可视化知识库平台,它们封装了复杂的RAG流程,仅需上传文档即可使用。对于开发者,利用 LangChain4j Easy RAG 或 GitHub 上的 TinyRAG等开源模板,也是高效的起手方式。
5.4. RAG 评价与优化
当基础的 RAG 系统搭建完成后,下一步的进阶之路便聚焦于如何评估、诊断并突破其固有的瓶颈。
- 评估维度与挑战:一套 RAG 系统的好坏,并不能仅凭感觉。业界通常会从几个维度进行量化评估,首先是检索相关性(找到的内容是否包含答案),其次是生成质量,这又可以细分为语义准确性(回答的意思是否正确)和词汇匹配度(专业术语是否使用得当)。
- 这些评估维度也直接对应了 RAG 当前面临的主要挑战。比如,检索依赖性问题------如果检索系统召回了错误信息,再强的 LLM 也会"一本正经地胡说八道"。此外,对于需要跨多个文档进行综合分析的多跳推理问题,常见的 RAG 架构也普遍感到吃力。
- 优化方向与架构演进:针对上述挑战,社区探索出了多种优化路径。在性能层面,可以通过索引分层(对高频数据启用缓存)和多模态扩展(支持图像/表格检索)来提升效率和能力边界。而在架构层面,简单的线性流程正在被更复杂的设计模式所取代。例如,系统可以通过分支模式并行处理多路检索,或通过循环模式进行自我修正,这些灵活的架构是通往更智能 RAG 的必由之路。
6. 构建RAG实战
6.1. 下载中文Embeddings模型
import os
import shutil
from modelscope import snapshot_download
from huggingface_hub import snapshot_download
MODEL_NAME = "BAAI/bge-small-zh-v1.5"
LOCAL_DIR = ".././models/BAAI/bge-small-zh-v1.5"
def download_from_modelscope():
"""从 ModelScope 下载(国内推荐)"""
print("🚀 使用 ModelScope 下载模型...")
try:
model_dir = snapshot_download(
model_id="AI-ModelScope/bge-small-zh-v1.5",
cache_dir="./modelscope_cache",
revision="master"
)
print(f"✅ ModelScope 下载成功: {model_dir}")
return model_dir
except Exception as e:
print(f"❌ ModelScope 下载失败: {e}")
return None
def download_from_hf_mirror():
"""从 HuggingFace 镜像下载(备用)"""
print("🌐 使用 HuggingFace 镜像下载...")
try:
# 设置镜像 + 禁用 xet(关键)
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "0"
model_dir = snapshot_download(
repo_id=MODEL_NAME,
local_dir=LOCAL_DIR,
local_dir_use_symlinks=False,
resume_download=True,
max_workers=1
)
print(f"✅ HF 镜像下载成功: {model_dir}")
return model_dir
except Exception as e:
print(f"❌ HF 镜像下载失败: {e}")
return None
def prepare_model_dir(src_dir):
"""整理模型到统一目录"""
print("📦 整理模型目录...")
if not src_dir:
return False
if os.path.exists(LOCAL_DIR):
print("⚠️ 目标目录已存在,跳过移动")
return True
os.makedirs(os.path.dirname(LOCAL_DIR), exist_ok=True)
try:
shutil.copytree(src_dir, LOCAL_DIR)
print(f"✅ 模型已准备好: {LOCAL_DIR}")
return True
except Exception as e:
print(f"❌ 文件整理失败: {e}")
return False
def check_model_exists():
"""检查模型是否已存在"""
return os.path.exists(os.path.join(LOCAL_DIR, "config.json"))
def main():
print("===================================")
print("📥 下载 bge-small-zh-v1.5 模型")
print("===================================")
# 已存在就直接跳过
if check_model_exists():
print(f"✅ 模型已存在: {LOCAL_DIR}")
return
# 1️⃣ 先尝试 ModelScope
src_dir = download_from_modelscope()
# 2️⃣ fallback 到 HF 镜像
if not src_dir:
src_dir = download_from_hf_mirror()
# 3️⃣ 整理目录
if src_dir and prepare_model_dir(src_dir):
print("\n🎉 模型准备完成,可以直接使用!")
else:
print("\n❌ 下载失败,建议手动下载")
print("👉 https://hf-mirror.com/BAAI/bge-small-zh-v1.5")
if __name__ == "__main__":
main()6.2. 验证Embeddings模型可用
from langchain_huggingface import HuggingFaceEmbeddings
# 本地模型目录
LOCAL_DIR = ".././models/BAAI/bge-small-zh-v1.5"
embeddings = HuggingFaceEmbeddings(
model_name=LOCAL_DIR
)
print(embeddings.embed_query("你好"))6.3. 基于LangChain 框架的 RAG 实现
import os
# hugging face镜像设置,如果国内环境无法使用启用该设置
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
os.environ["HF_HUB_ENABLE_HF_TRANSFER"] = "0"
from dotenv import load_dotenv
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# 加载环境变量
load_dotenv()
markdown_path = "../../data/C1/markdown/easy-rl-chapter1.md"
print("步骤1: 加载文档...")
# 加载本地markdown文件
loader = UnstructuredMarkdownLoader(markdown_path)
docs = loader.load()
print(f"文档加载完成,共 {len(docs)} 个文档")
print("步骤2: 文本分块...")
# 文本分块
text_splitter = RecursiveCharacterTextSplitter()
chunks = text_splitter.split_documents(docs)
print(f"分块完成,共 {len(chunks)} 个文本块")
print("步骤3: 加载嵌入模型...")
# 中文嵌入模型 - 使用本地路径
model_local_path = "/Users/hyxf/PycharmProjects/all-in-rag/models/BAAI/bge-small-zh-v1.5"
embeddings = HuggingFaceEmbeddings(
# 使用本地模型数据
model_name=model_local_path,
model_kwargs={'device': 'cpu'},
encode_kwargs={'normalize_embeddings': True}
)
print("嵌入模型加载完成")
print("步骤4: 构建向量存储...")
# 构建向量存储
vectorstore = InMemoryVectorStore(embeddings)
vectorstore.add_documents(chunks)
print("向量存储构建完成")
# 提示词模板
prompt = ChatPromptTemplate.from_template("""请根据下面提供的上下文信息来回答问题。
请确保你的回答完全基于这些上下文。
如果上下文中没有足够的信息来回答问题,请直接告知:"抱歉,我无法根据提供的上下文找到相关信息来回答此问题。"
上下文:
{context}
问题: {question}
回答:"""
)
# 配置大语言模型
print("步骤5: 配置大语言模型...")
# 使用 AIHubmix
llm = ChatOpenAI(
model="glm-4.7-flash-free",
temperature=0.7,
max_tokens=4096,
api_key="***********",
base_url="https://aihubmix.com/v1"
)
# llm = ChatOpenAI(
# model="deepseek-chat",
# temperature=0.7,
# max_tokens=4096,
# api_key=os.getenv("DEEPSEEK_API_KEY"),
# base_url="https://api.deepseek.com"
# )
# 用户查询
question = "全文的重点介绍什么知识? 使用三句话总结一下?"
print("步骤6: 检索相关文档...")
# 在向量存储中查询相关文档
retrieved_docs = vectorstore.similarity_search(question, k=3)
docs_content = "\n\n".join(doc.page_content for doc in retrieved_docs)
print("步骤7: 生成回答...")
answer = llm.invoke(prompt.format(question=question, context=docs_content))
print("\n=== 回答 ===")
print(answer)7. RAG技术相关思考
7.1. 中文嵌入模型Embeddings
中文嵌入模型就像一台"语义翻译机",它将我们日常使用的中文文本,转换成计算机能高效处理的数值向量(即数学坐标)。这样,计算机就能"读懂"字里行间的深层含义,并计算句子之间的相似度。它通常位于RAG(检索增强生成)系统的核心,担任着"信息检索员"的关键角色。
7.1.1. Embeddings的定义
想象一下,嵌入模型可以把"北京"和"上海"映射到向量空间中相近的位置,而把"北京"和"苹果"映射到遥远的位置。这种对语义关系的捕捉,是通过以下两个关键步骤实现的:
- 分布式表示:与传统方法(如One-Hot编码)给每个词分配一个独立、稀疏的ID不同,分布式表示将一个词的意义"分布"到一个多维稠密向量的各个维度上。这使得模型可以用几百个数字的组合,来精细刻画一个词的丰富语义。
- 上下文感知 :这是现代嵌入模型的精髓。以BERT、BGE等为代表的现代模型 ,在理解一个词时,会同时考虑它左右的词语。例如,"苹果"这个词在"苹果 很好吃"和"苹果手机很棒"这两个句子中,生成的向量是完全不同的,完美解决了"一词多义"的难题
7.1.2. Embeddings核心作用:它具体能做什么?
将文本转化为富含语义的向量后,计算机就能高效地完成许多实际任务:
- 语义搜索:将你的搜索词也转为向量,在庞大的文档库中寻找语义上最相关的文档。
- RAG(检索增强生成):为大模型提供外部知识,从根本上减少"一本正经地胡说八道"(即大模型幻觉),是构建企业知识库和AI问答系统的核心组件。
- 文本分类与聚类:将向量输入标准分类器(如逻辑回归)即可实现文本分类;或通过向量间的距离,自动将相似的新闻聚合到一起,形成主题。
- 相似度计算:可以精确计算两段文本的语义相似度,广泛用于查重和智能客服的意图识别
7.1.3. 常见中文EmbeddingsModel
目前,中文嵌入模型的选择非常丰富,这里列出了几款代表性模型,你可以根据自己的需求进行选择。
|---------------------------|-------------------------------------------------------|------------------------------|
| 模型名称 | 核心特点 | 适用场景 |
| BGE系列 | 中文场景首选 ,C-MTEB榜单顶尖水平。 如BGE-M3支持多语言、长文本和混合检索,均衡性好。 | RAG、语义搜索、各类NLP任务。 |
| Youtu-Embedding | 大参数(20亿),登顶C-MTEB榜首,性能卓越。 | 对效果要求极高的企业级应用,如智能客服、知识库。 |
| M3E系列 | 专注于中文,轻量高效,易于部署,在中文任务上曾表现优于text2vec。 | 资源有限,需要快速部署的RAG应用场景。 |
| gte-Qwen2-7B-instruct | 超大杯(7B参数),在C-MTEB上得分很高,多语言能力强。 | 追求极致性能,且有充足GPU算力的场景。 |
| text2vec系列 | 入门常用,模型轻量,简单易用,有多个版本。 | 小型项目、原型验证或对效果要求不苛刻的场景。 |
| Jina Embeddings v3 | 多语言支持好,参数规模适中(570M),可处理长文本(8192 token)。 | 多语言检索任务或需要处理长文档的场景。 |
| acge_text_embedding | 曾登顶C-MTEB榜首,技术先进,支持可变维度输出。 | 需要灵活控制向量维度,或在特定任务上追求极致效果。 |
7.1.4. Embeddings与中文分词的区别
要理解这一点,可以看一个简单的流水线对比。分词 是基础预处理,嵌入则是赋予语义的灵魂。
- 分词(Tokenization) :它是预处理的第一步,将连续的文本切分成计算机能识别的最小单元(Tokens)。例如,对于没有空格分隔的中文,分词器需要把"我爱北京天安门"正确地切成"我"、"爱"、"北京"、"天安门"等词或子词(如BPE)。
- 嵌入(Embedding) :它是理解的起点,接收分词器生成的Token序列,将它们转化为蕴含丰富语义信息的数值向量。Tokenizer的输出是整数ID序列,而Embedding模型的输出是浮点数向量
7.2. RAG数据准备
-
加载原始文档 : 先定义Markdown文件的路径,然后使用
TextLoader加载该文件作为知识源。markdown_path = "../../data/C1/markdown/easy-rl-chapter1.md"
loader = TextLoader(markdown_path)
docs = loader.load()Copy to clipboardErrorCopied -
文本分块 (Chunking) : 为了便于后续的嵌入和检索,长文档被分割成较小的、可管理的文本块(chunks)。这里采用了递归字符分割策略,使用其默认参数进行分块。当不指定参数初始化
RecursiveCharacterTextSplitter()时,其默认行为旨在最大程度保留文本的语义结构:
-
-
默认分隔符与语义保留 : 按顺序尝试使用一系列预设的分隔符
["\n\n" (段落), "\n" (行), " " (空格), "" (字符)]来递归分割文本。这种策略的目的是尽可能保持段落、句子和单词的完整性,因为它们通常是语义上最相关的文本单元,直到文本块达到目标大小。 -
保留分隔符 : 默认情况下 (
keep_separator=True),分隔符本身会被保留在分割后的文本块中。 -
默认块大小与重叠 : 使用其基类
TextSplitter中定义的默认参数chunk_size=4000(块大小)和chunk_overlap=200(块重叠)。这些参数确保文本块符合预定的大小限制,并通过重叠来减少上下文信息的丢失。text_splitter = RecursiveCharacterTextSplitter()
texts = text_splitter.split_documents(docs)
-
7.3. RAG索引构建
数据准备完成后,接下来构建向量索引:
-
初始化中文嵌入模型 : 使用
HuggingFaceEmbeddings加载之前在初始化设置中下载的中文嵌入模型。配置模型在CPU上运行,并启用嵌入归一化 (normalize_embeddings: True)。embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-zh-v1.5",
model_kwargs={'device': 'cpu'},
encode_kwargs={'normalize_embeddings': True}
)Copy to clipboardErrorCopied -
构建向量存储 : 将分割后的文本块 (
texts) 通过初始化好的嵌入模型转换为向量表示,然后使用InMemoryVectorStore将这些向量及其对应的原始文本内容添加进去,从而在内存中构建出一个向量索引。vectorstore = InMemoryVectorStore(embeddings)
vectorstore.add_documents(texts)Copy to clipboardErrorCopied
这个过程完成后,便构建了一个可供查询的知识索引。
向量存储 = 把文本变成"坐标点",然后用"距离"来找最相似的内容
原始文档 → 分块 → 向量化 → 存储 → 相似度检索7.3.1. 文本分块(chunk)
chunks = text_splitter.split_documents(docs)为什么要分块?
-
大模型有上下文限制(比如 4k / 8k token)
-
embedding 对短文本效果更好。
chunk1: 强化学习是什么...
chunk2: Q-learning 是一种...
chunk3: 举例说明...
7.3.2. 嵌入(Embedding)
embeddings = HuggingFaceEmbeddings(...)每个 chunk 会变成一个向量:
chunk1 → [0.12, -0.33, 0.91, ...]
chunk2 → [0.15, -0.30, 0.89, ...]本质:模型把"语义"编码进向量空间
7.3.3. 存入向量库(Vector Store)
vectorstore.add_documents(chunks)实际做的事情是:
[
(向量1, 文本1),
(向量2, 文本2),
(向量3, 文本3)
]可以理解为:
文本 → 向量 → 存起来7.3.4. 查询(最关键)
vectorstore.similarity_search(question)流程:
-
Step1:问题转向量
问题:文中举了哪些例子?
→ 向量Q
-
Step2:计算相似度
Q vs chunk1 → 相似度 0.2
Q vs chunk2 → 相似度 0.3
Q vs chunk3 → 相似度 0.95 ✅
相似度计算方式(核心):
1️⃣ 余弦相似度(最常用)
cos(θ) = A · B / (|A| |B|)含义:
- 越接近 1 → 越相似
- 越接近 0 → 不相关
7.3.5. 返回最相似的文本
TopK = 3
→ 返回最相关的3个 chunk7.4. 文本切分参数参数chunk_size和chunk_overlap
Langchain代码中RecursiveCharacterTextSplitter()的参数chunk_size和chunk_overlap,观察输出结果有什么变化。
7.4.1. ✅ chunk_size
每个文本块的最大长度(按字符数)
RecursiveCharacterTextSplitter(chunk_size=500)含义:一段文本最多切成 500个字符一块
7.4.2. ✅ 2. chunk_overlap
相邻两个块之间"重复"的部分
RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100
)含义:每个块和下一个块有 100个字符是重复的
7.4.3. 为什么需要这两个参数?
因为你在解决两个核心问题:
1. 文本太长 → LLM吃不下(需要切)
2. 切了以后 → 语义断裂(需要重叠)7.4.4. 示例
原始文本:
强化学习是一种机器学习方法。它通过与环境交互来学习策略。举个例子,智能体可以通过奖励机制优化行为。❌ 情况1:没有 overlap
chunk_size=30
chunk_overlap=0切出来:
chunk1: 强化学习是一种机器学习方法。它通过
chunk2: 与环境交互来学习策略。举个例子,智
chunk3: 能体可以通过奖励机制优化行为。问题:
- "举个例子"被拆开 ❌
- 语义断裂 ❌
✅ 情况2:有 overlap
chunk_size=30
chunk_overlap=10切出来:
chunk1: 强化学习是一种机器学习方法。它通过
chunk2: 法。它通过与环境交互来学习策略。举
chunk3: 学习策略。举个例子,智能体可以通过好处:
- 关键语义不会丢 ✅
- 上下文连续 ✅
7.5. 对你RAG的实际影响(非常关键)
7.5.1. chunk_size 太大
优点:上下文完整
缺点:embedding不精确 / 噪声多表现:
- 检索不准 ❌
- LLM回答跑偏 ❌
7.5.2. chunk_size 太小
优点:embedding更精准
缺点:信息不完整表现:
- 找到的内容不完整 ❌
- 回答缺上下文 ❌
7.5.3. chunk_overlap 太小
表现:
语义断裂 ❌7.5.4. chunk_overlap 太大
表现:
重复太多 → 浪费token / 影响排序 ❌|--------------|--------|
| 参数变化 | 结果变化 |
| chunk_size ↑ | 每块更长 |
| chunk_size ↓ | 每块更碎 |
| overlap ↑ | 重复内容更多 |
| overlap ↓ | 更容易断句 |
8. 向量索引优化的方向
8.1. FAISS(代替 InMemory) ------解决"性能 + 可扩展"
8.1.1. 本质解决什么问题?
你现在用的是:
InMemoryVectorStore本质是:
O(n) 暴力遍历数据一多就废了(几万条就开始慢)
8.1.2. FAISS 做了什么?
用"向量索引结构"加速:
O(n) → O(log n)8.1.3. 🚀 你代码怎么改?
1️⃣ 安装
pip install faiss-cpu2️⃣ 替换代码
from langchain_community.vectorstores import FAISS
# 构建向量库
vectorstore = FAISS.from_documents(chunks, embeddings)3️⃣ 查询不变
retrieved_docs = vectorstore.similarity_search(question, k=3)8.1.4. 🎯 什么时候必须用 FAISS?
|-----------|-------------|
| 数据量 | 建议 |
| < 1k | InMemory OK |
| 1k ~ 10w | ✅ FAISS |
| > 10w | Milvus / ES |
8.2. rerank(提升准确率) ------解决"找的不准"
8.2.1. 问题本质:embedding 只是"粗筛":
有时候会这样:
Top1:相关度 0.82(其实不太对)
Top2:相关度 0.80(更准确)8.2.2. rerank 是干嘛?
用一个更强模型重新排序:
embedding → 召回 Top10
rerank → 选 Top3(更准)8.2.3. 🚀 推荐模型(中文)
BAAI/bge-reranker-basebge-reranker-large
8.2.4. 🚀 简单接入(示例)
from sentence_transformers import CrossEncoder
reranker = CrossEncoder("BAAI/bge-reranker-base")
pairs = [[question, doc.page_content] for doc in retrieved_docs]
scores = reranker.predict(pairs)
# 排序
reranked = sorted(zip(scores, retrieved_docs), reverse=True)
top_docs = [doc for _, doc in reranked[:3]]8.2.5. 🎯 效果
命中率提升:
+20% ~ +40%8.3. chunk size 优化(很关键) ------解决"语义断裂 / 上下文丢失"
8.3.1. 问题本质
你现在:
RecursiveCharacterTextSplitter()默认:
chunk_size=1000
chunk_overlap=200但不一定适合你的数据!
8.3.2. ❗ 错误示例
chunk1: 强化学习是...
chunk2: 举例说明:..."举例"被切断 → LLM看不懂
8.3.3. ✅ 正确优化策略
推荐参数(中文)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100
)8.3.4. 🎯 原则
|------------|--------|
| 参数 | 作用 |
| chunk_size | 单块大小 |
| overlap | 防止语义断裂 |
8.3.5. 🚀 进阶(更牛)
👉 按"语义分块":
- 按标题切
- 按段落切
- Markdown结构切
8.4. embedding 批处理(性能)------解决"性能慢"
8.4.1. 问题本质
你现在是:
一条一条 embedding很慢 ❌
8.4.2. ✅ 批处理做了什么?
一次处理 N 条👉 GPU / CPU 利用率提升
8.4.3. 🚀 怎么做?
LangChain 默认支持 batch,但你可以优化:
embeddings = HuggingFaceEmbeddings(
model_name=model_local_path,
model_kwargs={'device': 'cpu'},
encode_kwargs={
'normalize_embeddings': True,
'batch_size': 32 # 👈 关键
}
)8.4.4. 🎯 性能提升
10x ~ 50x(数据量大时非常明显)