本文介绍了OpenClaw数据采集工具的使用方法和核心功能。首先概述了OpenClaw的设计理念------轻量化与高可扩展性,适合处理各类网页数据采集需求。然后详细讲解了从环境配置、依赖安装到编写首个爬虫脚本的全过程,包括参数配置、数据清洗和导出等关键步骤。文章还提供了定时任务配置、常见问题排查以及反爬机制应对等实用技巧,帮助用户实现稳定高效的自动化数据采集。通过多页面遍历与深度抓取等高级功能,OpenClaw能够满足复杂场景下的数据采集需求,是数据分析师和开发者的理想工具选择。
目录
- [一、AI 产品试用](#一、AI 产品试用)
- [二、OpenClaw 数据采集工具新手入门指南](#二、OpenClaw 数据采集工具新手入门指南)
-
- [① OpenClaw 核心功能与应用场景解析](#① OpenClaw 核心功能与应用场景解析)
- [② 运行环境准备与依赖库安装步骤](#② 运行环境准备与依赖库安装步骤)
- [③ 配置文件参数详解与快速初始化](#③ 配置文件参数详解与快速初始化)
- [④ 编写首个爬虫脚本抓取目标数据](#④ 编写首个爬虫脚本抓取目标数据)
- [⑤ 数据清洗规则设置与格式导出](#⑤ 数据清洗规则设置与格式导出)
- [⑥ 定时任务配置实现自动化采集](#⑥ 定时任务配置实现自动化采集)
- [⑦ 常见连接超时与解析失败排查](#⑦ 常见连接超时与解析失败排查)
- [⑧ 反爬机制应对策略与请求频率控制](#⑧ 反爬机制应对策略与请求频率控制)
- [⑨ 多页面遍历与深度抓取技巧](#⑨ 多页面遍历与深度抓取技巧)
- [⑩ 采集性能优化与资源占用管理](#⑩ 采集性能优化与资源占用管理)
一、AI 产品试用
这里,我们选择的产品是:OpenClaw
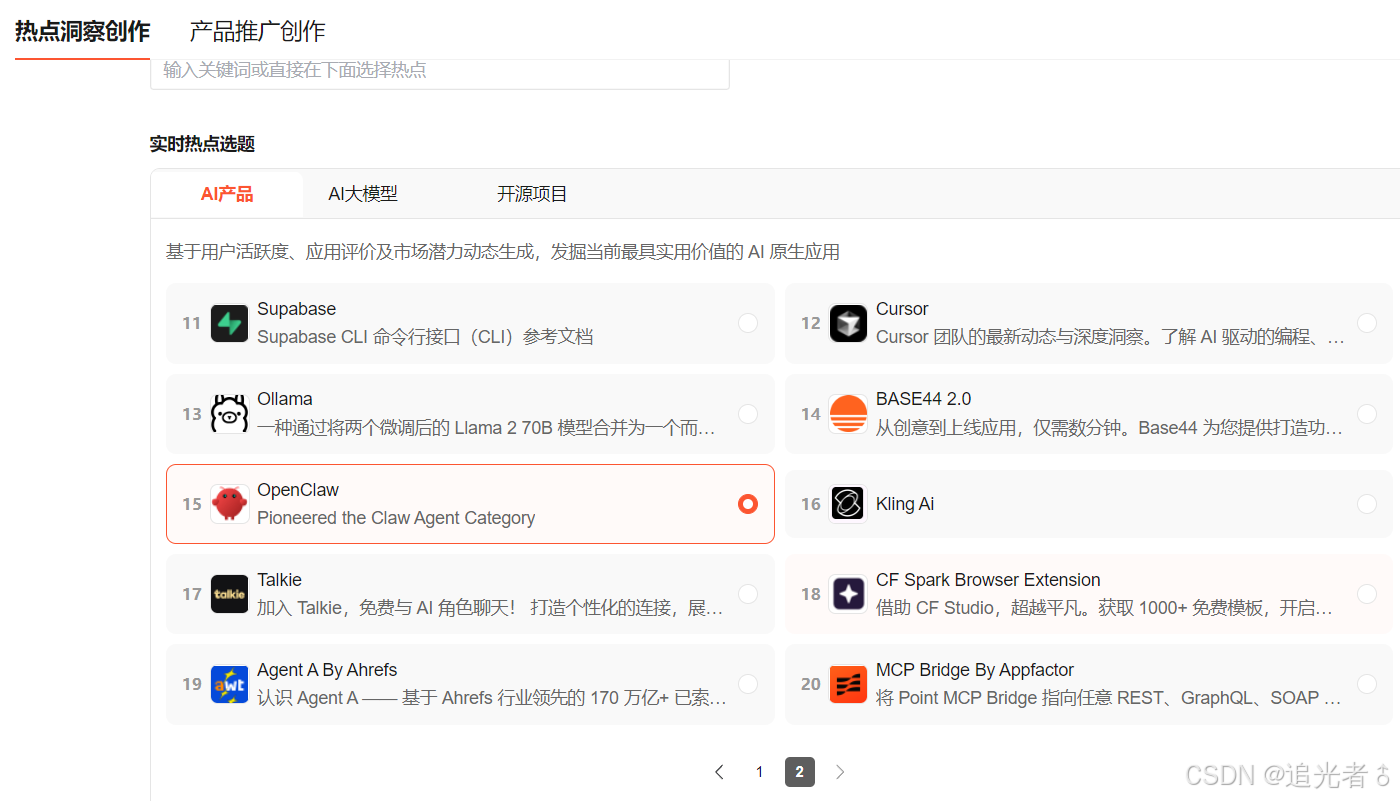
下一步,选择"基础教程类":
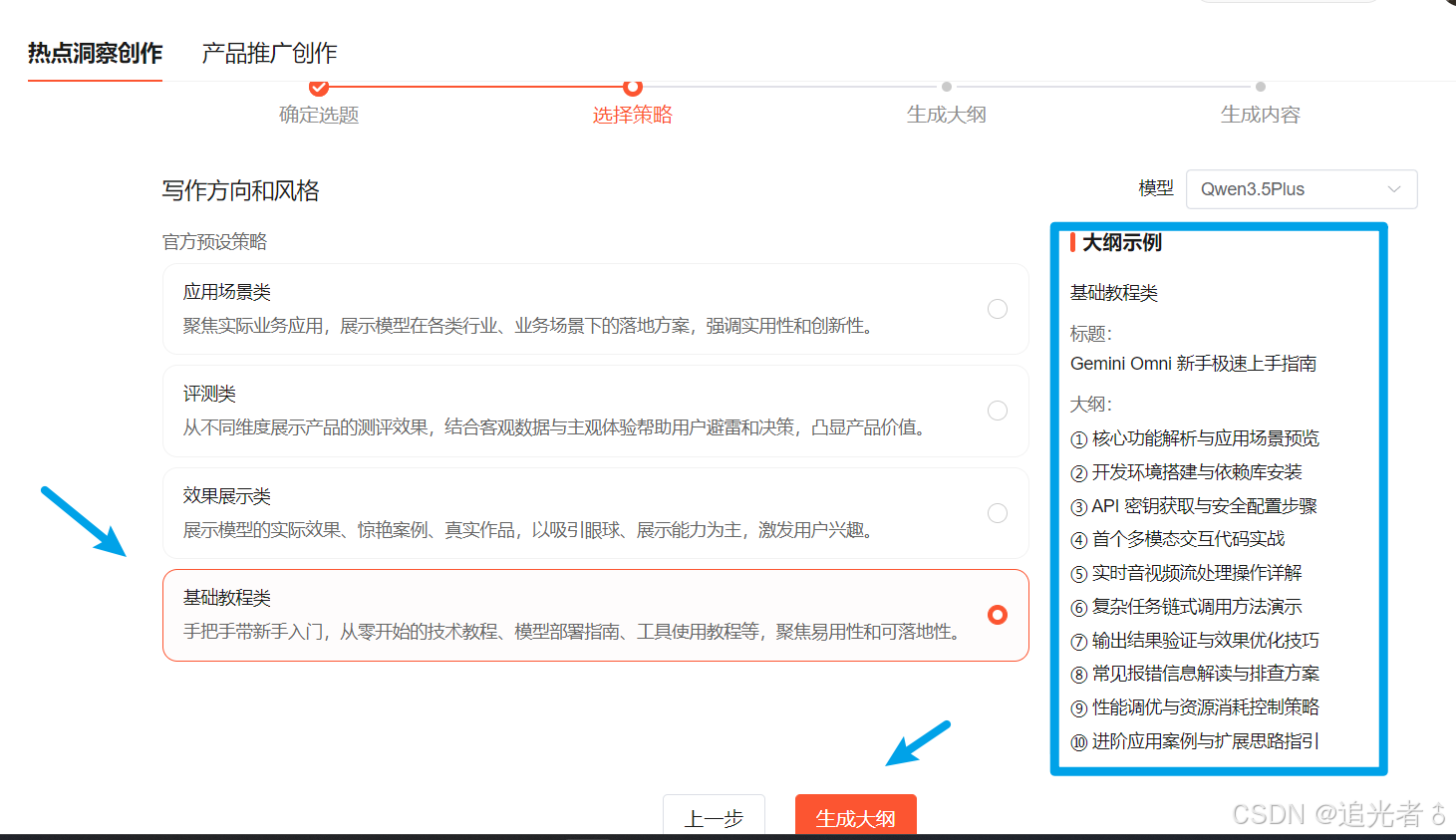
生成大纲:
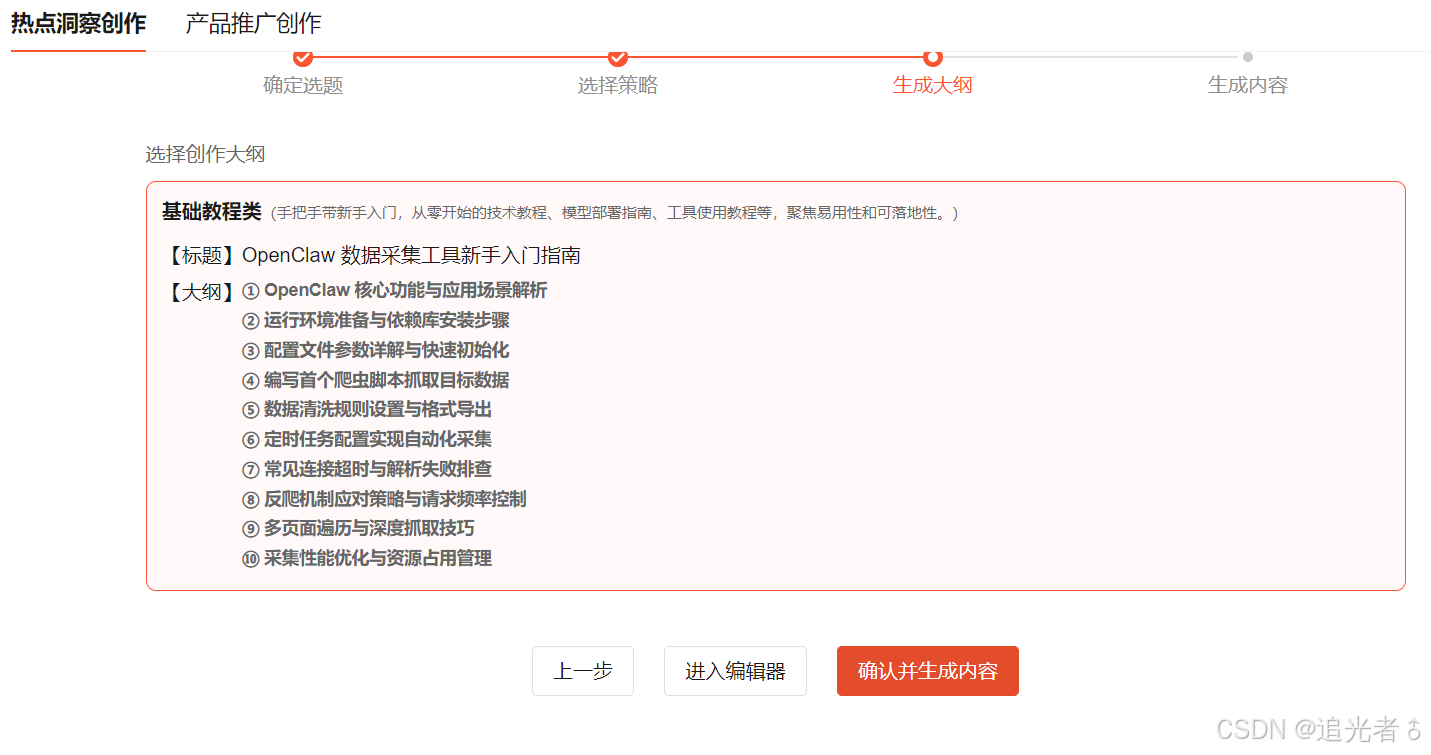
确认并生成内容,如目录二所示:
二、OpenClaw 数据采集工具新手入门指南
在数据采集的实际工作中,我们常常面临这样的困境:手动复制粘贴效率低下且容易出错,而现有的大型框架又往往过于沉重,配置复杂,对于轻量级的临时抓取任务显得"杀鸡用牛刀"。很多开发者在寻找一种平衡方案------既要有足够的灵活性来处理动态变化的网页结构,又要保持代码的简洁易读,便于快速迭代和维护。OpenClaw 正是为了解决这一痛点而生,它摒弃了繁琐的 boilerplate 代码,让开发者能够专注于数据提取逻辑本身,而非被环境配置和底层协议所困扰。
无论你是需要定期监控竞品价格的市场分析师,还是希望聚合行业资讯的内容创作者,亦或是正在构建数据集的算法工程师,掌握一套高效、稳定的爬虫工具都是必备技能。本文将深入探讨 OpenClaw 的核心机制,从环境搭建到高级反爬策略应对,带你一步步构建属于自己的自动化数据采集流水线。我们将跳过那些晦涩的理论堆砌,直接通过实战案例,展示如何用最少的代码行数实现最稳健的数据获取,让你的采集任务从"能跑"进化到"跑得稳、跑得快"。
① OpenClaw 核心功能与应用场景解析
OpenClaw 的设计哲学在于"轻量化"与"高可扩"。与传统重型爬虫框架不同,它不强制要求用户遵循特定的项目结构,而是提供了一套模块化的工具集。其核心功能主要包括智能请求管理、灵活的 DOM 解析引擎以及内置的数据清洗管道。智能请求模块能够自动处理 HTTP 头部的标准化构造,支持 Cookie 会话保持,这对于需要登录态验证的场景至关重要。DOM 解析引擎则兼容 CSS 选择器与 XPath 语法,能够精准定位嵌套复杂的页面元素,即使面对结构松散的 HTML 也能稳定提取目标数据。
在实际应用场景中,OpenClaw 表现尤为出色。例如,在电商价格监控场景中,它可以定时抓取商品详情页的价格、库存状态及用户评价,并通过内置的差分算法识别价格波动;在新闻聚合领域,它能够遍历多级分类目录,自动提取标题、发布时间及正文内容,并过滤掉广告和无关导航链接。此外,对于需要进行小规模数据标注的机器学习任务,OpenClaw 可以快速将非结构化的网页文本转化为标准的 JSON 或 CSV 格式,极大降低了数据预处理的时间成本。它的灵活性使得开发者可以根据具体需求,像搭积木一样组合功能模块,既避免了资源浪费,又保证了执行效率。
② 运行环境准备与依赖库安装步骤
开始使用 OpenClaw 之前,我们需要构建一个干净且隔离的运行环境。强烈建议使用 Python 的虚拟环境工具(如 venv 或 conda)来管理依赖,以避免不同项目间的库版本冲突。首先,在终端中创建一个名为 oc_env 的虚拟环境并激活它。这一步能确保后续安装的包仅作用于当前项目,不会污染系统全局的 Python 环境。
接下来是核心依赖的安装。OpenClaw 依赖于几个关键的第三方库:requests 用于发送 HTTP 请求,BeautifulSoup4 或 lxml 用于 HTML 解析,以及 pandas 用于后期的数据处理。我们可以通过 pip 命令一次性安装这些基础组件。值得注意的是,某些解析库(如 lxml)可能需要系统级的编译工具支持,如果在 Windows 下遇到安装错误,可以尝试下载预编译的二进制 wheel 文件进行安装,而在 Linux 或 macOS 上则需确保已安装 libxml2 和 libxslt 开发包。安装完成后,运行一个简单的导入测试脚本,确认所有模块均可正常加载,即可进入下一步配置。
③ 配置文件参数详解与快速初始化
为了降低硬编码带来的维护成本,OpenClaw 提倡将关键参数外置到配置文件中进行管理。通常我们可以使用 YAML 或 JSON 格式来定义配置项。配置文件主要包含三大板块:全局设置、请求头模板和重试策略。全局设置中,base_url 定义了目标站点的根域名,delay 参数用于设定请求之间的基础延迟时间,这是礼貌爬虫的基本素养。请求头模板则允许用户预设 User-Agent、Referer 等字段,模拟真实浏览器的行为,减少被服务器识别为脚本的概率。
重试策略是保证采集稳定性的关键。在配置文件中,我们可以定义 max_retries(最大重试次数)和 backoff_factor(退避因子)。当网络波动导致请求失败时,系统会根据退避因子指数级增加等待时间后重新发起请求,而不是立即崩溃或无限循环。初始化过程非常简单,只需在脚本启动时加载该配置文件,并将其实例化为一个配置对象。这样,当目标网站结构调整或反爬策略升级时,我们只需修改配置文件而无需触动核心代码逻辑,极大地提升了项目的可维护性。
④ 编写首个爬虫脚本抓取目标数据
让我们通过一个具体的案例来编写第一个爬虫脚本。假设我们需要抓取某个技术博客列表页的文章标题、作者和发布日期。首先,实例化 OpenClaw 的主控类,并传入之前加载的配置对象。接着,构建目标 URL 列表。对于单页抓取,直接传入完整 URL 即可;若涉及分页,可利用字符串格式化生成 URL 序列。
核心抓取逻辑封装在一个循环中。在每次迭代里,调用请求模块获取页面响应内容。这里需要加入基本的状态码判断,只有当返回状态为 200 时才进行后续解析,否则记录错误日志并跳过。解析阶段,使用 CSS 选择器定位文章列表容器,然后遍历每个文章节点,分别提取标题、作者和日期的文本内容。为了提高代码的健壮性,提取操作应包裹在异常处理块中,防止因某个字段缺失导致整个程序中断。最后,将提取到的字典数据追加到一个结果列表中。这个过程清晰直观,即使是初学者也能快速理解数据从"网页"到"内存变量"的流转过程。
⑤ 数据清洗规则设置与格式导出
原始抓取的数据往往包含多余的空白字符、换行符甚至是 HTML 实体编码,直接使用会影响后续分析。OpenClaw 内置了一个轻量级的数据清洗管道,允许用户定义一系列转换规则。常见的清洗操作包括:去除首尾空格、替换连续空白为单个空格、统一日期格式以及将相对路径转换为绝对路径。例如,对于提取到的日期字符串"2023 年 10 月 01 日",我们可以编写一个正则替换规则,将其标准化为"YYYY-MM-DD"格式,便于数据库存储和时间序列分析。
清洗完成后的数据需要持久化保存。OpenClaw 支持多种导出格式,最常用的是 CSV 和 JSON。导出为 CSV 适合用于 Excel 查看或导入关系型数据库,需注意处理字段中包含逗号的情况,自动添加引号包裹;导出为 JSON 则更适合保留层级结构或用于 NoSQL 数据库。在导出时,建议开启"追加模式"而非"覆盖模式",这样即使在长周期任务中程序意外中断,已采集的数据也不会丢失。此外,还可以配置导出前的去重逻辑,基于唯一标识符(如文章 ID 或 URL)过滤重复记录,确保数据集的纯净度。
⑥ 定时任务配置实现自动化采集
数据采集的价值往往体现在持续性上。为了让爬虫每天自动运行,我们需要将其集成到操作系统的定时任务调度器中。在 Linux 环境下,cron 是最常用的工具。我们可以编辑 crontab 文件,添加一条规则,指定每天凌晨 2 点执行爬虫脚本。此时需要注意环境变量问题,因为在 cron 环境中可能无法识别虚拟环境的路径,因此在命令中必须使用 Python 解释器和脚本的绝对路径,并显式激活虚拟环境或直接调用虚拟环境中的 python 二进制文件。
对于 Windows 用户,可以使用"任务计划程序"来实现类似功能。创建一个基本任务,触发器设置为每日特定时间,操作设置为启动程序,指向虚拟环境中的 python.exe,并在参数栏填入脚本路径。为了实现更复杂的调度逻辑,如避开业务高峰期或在特定日期停止采集,也可以在脚本内部引入调度库(如 APScheduler),在代码层面控制执行频率。无论采用哪种方式,都务必配置好日志输出,将运行结果和潜在错误写入文件,以便日后排查问题。
⑦ 常见连接超时与解析失败排查
在网络采集过程中,连接超时和解析失败是最常见的两类异常。连接超时通常由网络波动、目标服务器响应缓慢或本地防火墙限制引起。排查时,首先检查本地网络连接是否正常,然后尝试增加请求超时时间的阈值。如果问题依旧,可以启用代理池机制(需确保合规使用),轮换不同的出口 IP 进行测试。此外,检查目标网站是否开启了 CDN 防护,某些 CDN 节点可能在特定区域访问较慢,调整 DNS 解析策略有时也能缓解这一问题。
解析失败则多源于网页结构的变更。当目标网站更新了前端框架或调整了 DOM 树结构时,原有的 CSS 选择器可能无法匹配到任何元素,导致返回空值。解决此类问题的关键在于建立监控机制。可以在代码中加入断言,当提取到的关键字段为空时,立即抛出警告并截图保存当前页面源码,以便人工介入分析。同时,编写选择器时应尽量利用具有稳定特征的属性(如 data-id),避免过度依赖容易变动的层级路径。定期回顾和更新解析规则,是维持爬虫长期稳定运行的必要工作。
⑧ 反爬机制应对策略与请求频率控制
随着网络安全意识的提升,越来越多的网站部署了反爬机制。常见的策略包括 User-Agent 检测、IP 频率限制以及验证码挑战。应对 User-Agent 检测,最简单有效的方法是维护一个庞大的真实浏览器 UA 列表,并在每次请求时随机选取一个进行伪装,使流量特征更接近普通用户。对于 IP 频率限制,核心策略是"慢即是快"。通过在配置文件中合理设置请求间隔(如 1-3 秒的随机延迟),可以有效避免触发服务器的熔断机制。
更高级的反爬可能涉及动态令牌或加密参数。这种情况下,单纯依靠模拟请求可能不够,需要借助浏览器自动化测试工具(如 Selenium 或 Playwright)来渲染 JavaScript 并获取最终生成的页面内容。但需注意,这类工具资源消耗较大,应仅在必要时使用。此外,尊重网站的 robots.txt 协议是技术伦理的底线,我们在设计采集策略时,应主动规避禁止抓取的目录,控制并发量,确保不会对目标服务器造成过载压力,实现和谐共存。
⑨ 多页面遍历与深度抓取技巧
许多有价值的数据分散在多层级的页面结构中,例如从列表页进入详情页,再从详情页跳转到评论页。实现多页面遍历的关键在于维护一个待访问 URL 队列。OpenClaw 支持广度优先(BFS)和深度优先(DFS)两种遍历策略。广度优先适合采集同一层级的所有数据,如抓取某分类下的所有文章;深度优先则适合沿着特定链路深入,如抓取某篇文章及其所有回复。
在实现深度抓取时,需要特别注意"去重"和"边界控制"。使用集合(Set)数据结构存储已访问过的 URL,可以有效防止死循环和重复采集。同时,必须设置最大深度限制(Max Depth),防止爬虫陷入无限嵌套的链接陷阱中。例如,可以设定最大抓取深度为 3 层,超过该层级的链接将被忽略。此外,针对分页列表,可以通过识别"下一页"按钮的特征或使用页码参数递增的方式自动生成后续页面 URL,结合异步 IO 技术,可以在等待响应的间隙处理其他任务,显著提升多页面抓取的吞吐量。
⑩ 采集性能优化与资源占用管理
当采集规模扩大到数万甚至数百万级别时,性能优化变得尤为重要。首先是并发控制,虽然多线程或多进程能大幅提升速度,但过高的并发会耗尽本地资源并触发目标服务器的防御。建议使用信号量(Semaphore)机制限制最大并发数,根据本地 CPU 核心数和网络带宽动态调整。其次是内存管理,避免将所有抓取数据一次性加载到内存中。应采用流式处理方式,每抓取一批数据就立即清洗并写入磁盘,释放内存空间,确保持长时间运行的稳定性。
日志系统的优化也不容忽视。在高并发场景下,频繁的磁盘 I/O 写日志可能成为瓶颈。可以引入异步日志 handler,或将日志先缓存到内存队列中,定期批量写入文件。此外,合理复用 TCP 连接(Keep-Alive)能减少握手开销,显著提升请求效率。通过监控程序的 CPU 使用率、内存占用及网络吞吐量,我们可以及时发现性能瓶颈并进行针对性调优,确保采集任务在资源可控的前提下高效完成。
以上即为OpenClaw相关介绍,你觉得怎么样?
欢迎交流!
🍒 热门专栏推荐:
- 🥇Python&AI专栏:【Python从入门到人工智能】
- 🥈前端专栏:【前端之梦~代码之美(H5+CSS3+JS.】
- 🥉文献精读&项目专栏:【小小的项目 (实战+案例)】
- 🍎C语言/C++专栏:【C语言、C++ 百宝书】(实例+解析)
- 🍏Java系列(Java基础/进阶/Spring系列/Java软件设计模式等)
- 🌞问题解决专栏:【工具、技巧、解决办法】
- 📝 加入Community 一起追光:追光者♂社区
持续创作优质好文ing...✍✍✍
记得一键三连哦!!!
求关注!求点赞!求个收藏啦!
