一、 知识储备
Transformer 放弃了 RNN 的递归处理,改用"并行计算",其核心可以概括为:注意力是灵魂,位置是坐标,多层堆叠是大脑。
1. 自注意力机制(Self-Attention)
想象你在读一句话:"华为公司昨天发布了新手机,它表现出色。" 当你读到"它"时,你的大脑会自动联系到前面的"华为公司"或"新手机"。
自注意力机制就是给句子里的每个词分配"关注权重"。通过计算词与词之间的相关性,让模型在处理每一个词时,都能"照顾"到全句的上下文。
深度点(Q、K、V):
每个 Token 都会转化为三个向量:
- Query (Q): "我要找什么?"
- Key (K): "我有什么?"
- Value (V):"我具体的内容是什么?"
计算公式为:
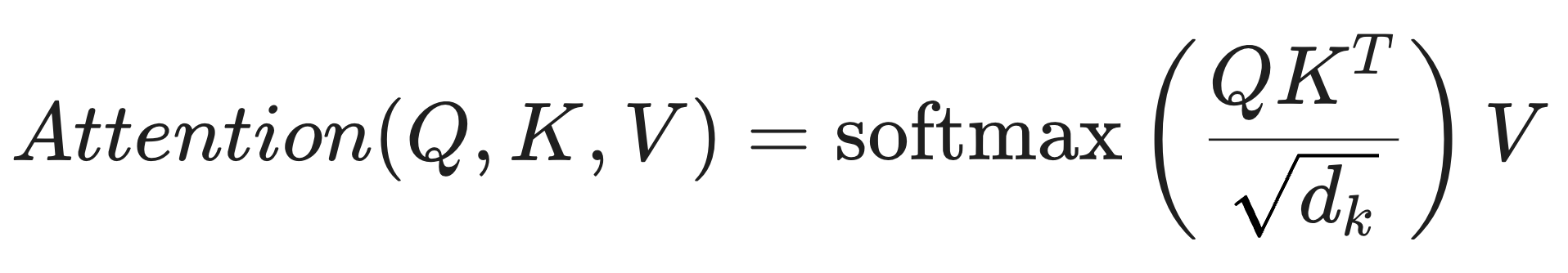
注意: 除以 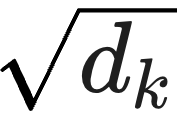 是为了防止梯度消失,这是面试常考的细节。
是为了防止梯度消失,这是面试常考的细节。
2. 多头注意力(Multi-Head Attention)
一个人看问题可能片面,所以我们找"多个人"一起看。有的头关注语法结构,有的头关注语义关联,有的头关注指代关系。最后把大家的意见汇总。
代码逻辑(伪代码):
javascript
// 多头注意力的逻辑简化
function multiHeadAttention(input) {
const heads = [];
for (let i = 0; i < 8; i++) { // 假设 8 个头
heads.push(singleSelfAttention(input));
}
return concatenate(heads).linearProjection();
}3. 位置编码(Positional Encoding)
Transformer 是并行处理的,如果没有位置编码,它会认为"我爱他"和"他爱我"完全一样。位置编码就像给每个词打上"座位号",让模型知道词与词之间的先后顺序。
4. 残差连接(Residual Connection)与 层归一化(LayerNorm)
- **残差连接:**怕模型太深学"糊涂"了,把输入直接拉到输出,防止信息丢失。
- **层归一化:**把每一层的数据分布拉回到合理的范围,让模型训练得更稳、更快。
5. 整体工作流程
**① 输入端:**文本 -> Token -> Embedding + 位置编码。
**② 编码器(Encoder):**负责理解。通过多层自注意力提取特征,输出上下文表示。
**③ 解码器(Decoder):**负责生成。多了一个"交叉注意力(Cross-Attention)",让生成的内容始终盯着 Encoder 的输出。
**④ 输出端:**Linear 层 + Softmax,预测下一个最可能的词。
二、破局之道
在面试中,讲完架构后,一定要补上这一段总结,展现你对技术演进的深刻思考:
Transformer 的伟大之处在于它彻底解决了 RNN 无法并行计算的瓶颈,利用 注意力机制实现了全局感受野。在实际开发中,理解这一点能帮我更好地进行模型选型(比如为何长文本需要优化 Attention 算子)以及处理推理时的 KV Cache 优化。Transformer 不是在"读"序列,而是在"计算"词与词之间的空间关系。