文章目录
项目说明
通过分析新闻标题、文章摘要等短文本的语义,将其自动分类到10个内容频道(如体育、游戏、政治等)
流程梳理
- 输入:文本内容(最好是文章摘要或新闻标题这种短文本,长文本会采用简单的截断方式,比如前300个字符)
- 输出:多分类标签(如体育、财经、游戏、科技等)
- 模型:BERT系列全参数微调
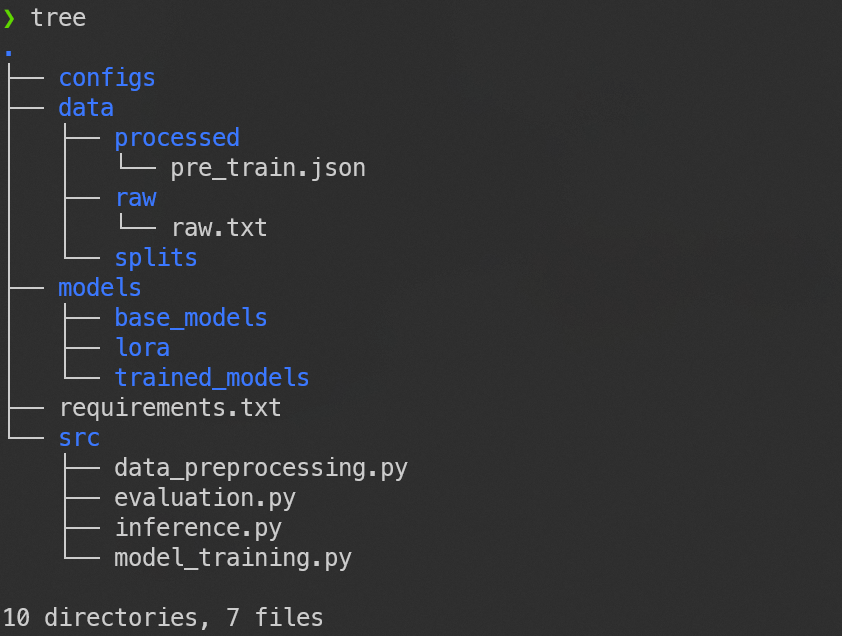
项目结构预览:
project/
├── data/ # 数据目录
│ ├── raw/ # 原始数据
│ ├── processed/ # 处理后的数据
│ └── splits/ # 训练/验证/测试集
├── models/ # 模型目录
│ ├── base_models/ # 基础模型
│ └── trained_models/ # 完整模型
├── src/ # 源代码
│ ├── data_preprocessing.py
│ ├── model_training.py
│ ├── inference.py
│ └── evaluation.py
├── configs/ # 配置文件
│ ├── model_config.yaml
│ ├── training_config.yaml
│ └── lora_config.yaml
├── notebooks/ # Jupyter notebooks
├── scripts/ # 脚本
├── requirements.txt
└── README.md我的目录结构:
-
我采用本地vscode+wsl的环境编写代码,简单测试;然后上传至云服务器进行训练、微调、部署等操作
-
这里给出一套适合
vllm0.19.0版本的环境(requirements.txt):
bash
# 使用 python3.11
# 执行:pip install -r requirements.txt
vllm==0.19.0
transformers==4.57.6
tokenizers==0.22.2
torch==2.10.0
torchaudio==2.10.0
torchvision
fastapi
uvicorn[standard]
sentence-transformers
peft
numpy
pandas
scikit-learn数据获取以及预处理
-
从huggingface社区获取
- 搜索数据集关键词:THUCNews
-
标签分布情况查看(做分类任务要确保标签均衡,不然准确率会大打折扣)
python# 参考代码 import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 加载数据 df = pd.read_csv('data.csv') # 1. 基础统计 print("=== 标签分布统计 ===") label_counts = df['label'].value_counts() print(label_counts) print(f"\n总样本数: {len(df)}") print(f"类别数: {len(label_counts)}") print(f"样本最多的类别: {label_counts.idxmax()} ({label_counts.max()}条)") print(f"样本最少的类别: {label_counts.idxmin()} ({label_counts.min()}条)") # 2. 百分比 print("\n=== 百分比分布 ===") label_percent = df['label'].value_counts(normalize=True) * 100 print(label_percent.round(2)) # 3. 可视化 plt.figure(figsize=(12, 6)) # 条形图 plt.subplot(1, 2, 1) label_counts.plot(kind='bar') plt.title('标签分布(数量)') plt.xlabel('标签') plt.ylabel('数量') plt.xticks(rotation=45) # 饼图 plt.subplot(1, 2, 2) label_counts.plot(kind='pie', autopct='%1.1f%%') plt.title('标签分布(百分比)') plt.ylabel('') plt.tight_layout() plt.show() -
数据格式转换
-
原始数据是一个tsv文件(即csv文件采用制表符 '\t'作为分隔符)
-
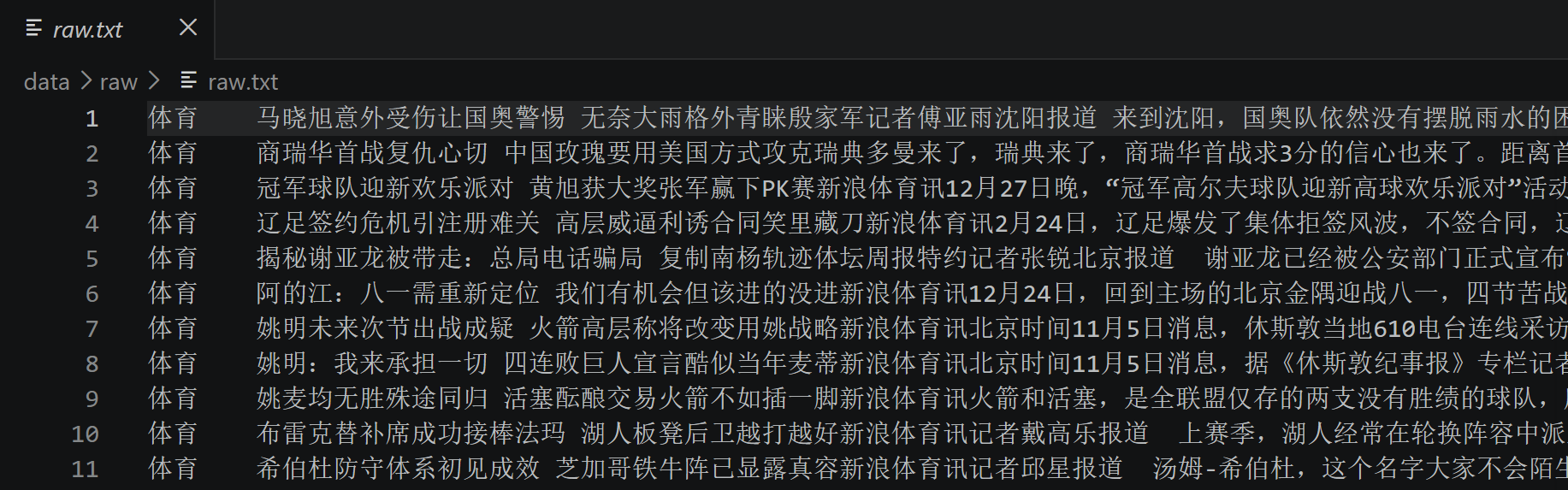
-
预处理:
- 截断长文本(太长的文本消耗token,而且本质是做短文本的语义分析)
- 转为jsonl文件(即每行都是一个json对象,格式:
{"label":"xx", "text":"xxxxxxxxx"})
-
相关代码:
pythonimport pandas as pd import json file_name = "../data/raw/raw.txt" to_path = "../data/processed/pre_train.jsonl" df = pd.read_csv(file_name, header=None, sep="\t", names=["label", "text"]) # 截断过长的text df["text"] = df["text"].str[:240] # 转为json格式:{"label": label, "text": text} # 创建并写入 with open(to_path, "w", encoding="utf-8") as f: for label, text in zip(df["label"], df["text"]): f.write(json.dumps({"label": label, "text": text}, ensure_ascii=False) + "\n") -
转化后的jsonl文件:
-

-
-
数据增强:
- 目的:丰富数据集,增加多样性
- 可用同义词替换,回译增强等方式
这里我选的数据集本身质量就高,而且10分类,每个都有5000条,就不做增强处理了。
基座模型选择
优先选择BERT系列模型,因为只是做一个多分类任务,没必要选择大语言类的模型
注:当任务多的时候可以选择Qwen、ChatCLM类的大语言模型,因为可以做LoRA微调,模型效果好且能够重复利用
BERT系列模型对比
| 模型 | 参数量 | 特点 | 推荐度 |
|---|---|---|---|
| bert-base-chinese | 110M | 标准中文BERT,兼容性好 | ★★★★★ |
| chinese-roberta-wwm-ext | 110M | 全词掩码,效果更好 | ★★★★★ |
| chinese-macbert-base | 110M | MLM纠正,最新技术 | ★★★★★ |
这里我选择经典的chinese-roberta-wwm-ext模型,实际生产情况可以都跑一下做对比测试
云服务器实战
云服务器推荐
个人推荐AutoDL或者腾讯云的cloudstudio.net
- AutoDL:提供学术加速,性价比高
- cloudstudio:轻松复刻项目,文件可视化操作,类似Vscode界面
我选择使用AutoDL,租西北地区(训练稳定且速度快)3080以上、vGPU或者其他系列
远程连接
可以选择传统的x-shell或者wsl2来连接
我选wsl2:
-
复制SSH登录指令:SSH***,粘贴到终端,回车,随后cv密码,回车:
-
登录成功的页面:
环境搭建
环境初始化(建议使用conda,将数据下载到数据盘):
bash
# 无脑执行就可以
# 创建conda下载
mkdir -p /root/autodl-tmp/conda/envs
mkdir -p /root/autodl-tmp/conda/pkgs
mkdir -p /root/autodl-tmp/pip/cache
# 配置conda
conda config --add envs_dirs /root/autodl-tmp/conda/envs
conda config --add pkgs_dirs /root/autodl-tmp/conda/pkgs
pip config set global.cache-dir /root/autodl-tmp/pip/cache
conda init bash
source .bashrc
# 学术加速 加速对github和huggingface的资源获取
source /etc/network_turbo-

-
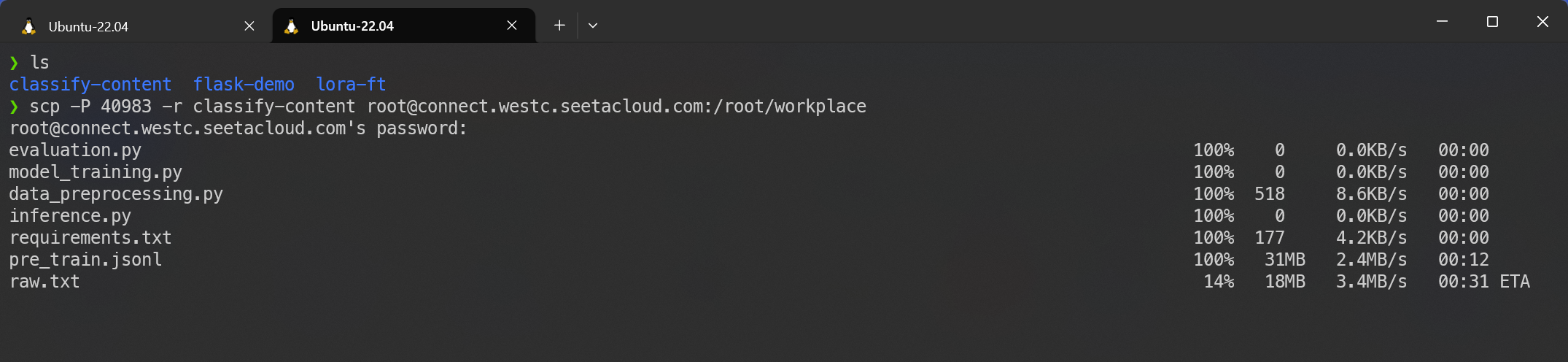
然后上传本地文件到云服务器:
scp -P 40983 -r classify-content root@connect.westc.seetacloud.com:/root/workplace
-
切换到虚拟环境,执行
pip install -r requirements.txt,大概181个依赖,有学术加速,很快就能下完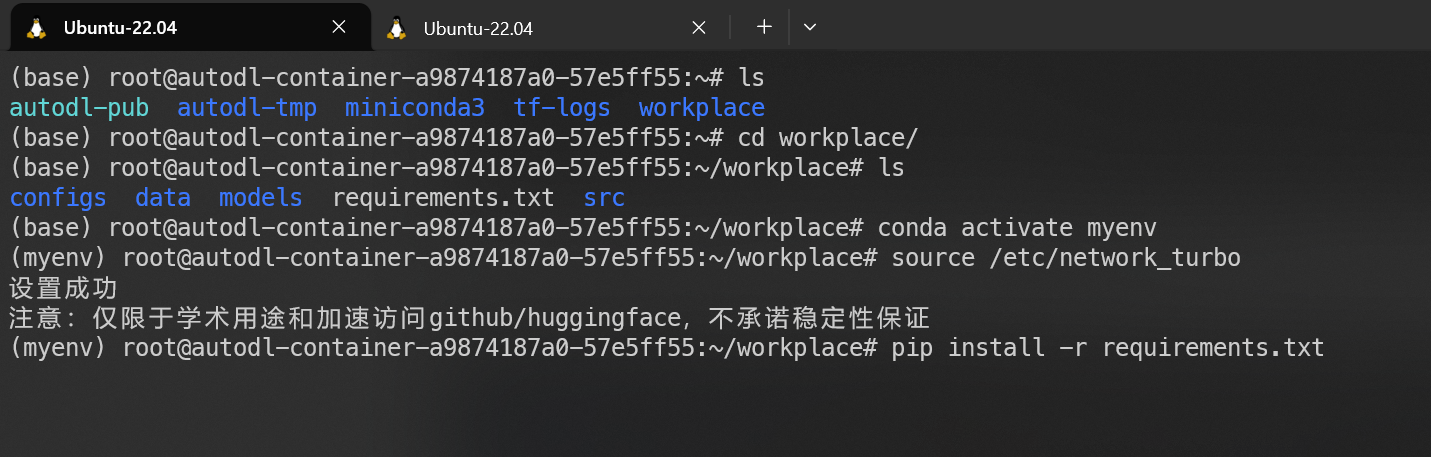
全参数微调
直接在workplace目录执行该代码块
python
cat > train_final_fixed.py << 'EOF'
import json
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import Dataset
from sklearn.metrics import accuracy_score, f1_score
import numpy as np
print("📊 加载数据...")
texts, labels = [], []
with open('data/processed/pre_train.jsonl', 'r', encoding='utf-8') as f:
for line in f:
data = json.loads(line.strip())
texts.append(data['text'])
labels.append(data['label'])
print(f"总样本: {len(texts)}")
print(f"类别数: {len(set(labels))}")
# 标签映射
label_list = sorted(set(labels))
label2id = {l: i for i, l in enumerate(label_list)}
id2label = {i: l for i, l in enumerate(label_list)}
# 创建完整数据集
full_dataset = Dataset.from_dict({
'text': texts,
'label': [label2id[l] for l in labels]
})
# 划分训练集(80%)和验证集(20%)
dataset = full_dataset.train_test_split(test_size=0.2, seed=42)
train_dataset = dataset['train']
val_dataset = dataset['test']
print(f"训练集: {len(train_dataset)}条")
print(f"验证集: {len(val_dataset)}条")
# 加载模型
print("🤖 加载模型...")
model = AutoModelForSequenceClassification.from_pretrained(
'./models/base_models/chinese-roberta-wwm-ext/',
num_labels=len(label_list),
id2label=id2label,
label2id=label2id
)
# tokenizer
tokenizer = AutoTokenizer.from_pretrained('./models/base_models/chinese-roberta-wwm-ext/')
# 预处理
def preprocess(examples):
return tokenizer(
examples['text'],
truncation=True,
padding='max_length',
max_length=128
)
train_dataset = train_dataset.map(preprocess, batched=True)
val_dataset = val_dataset.map(preprocess, batched=True)
# 评估函数
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return {
'accuracy': accuracy_score(labels, predictions),
'f1_macro': f1_score(labels, predictions, average='macro')
}
# 训练参数
training_args = TrainingArguments(
output_dir='./models/trained_models',
num_train_epochs=3,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
learning_rate=5e-5,
warmup_steps=100,
weight_decay=0.01,
logging_steps=50,
eval_strategy='epoch',
save_strategy='no',
load_best_model_at_end=False,
fp16=True,
report_to='none',
)
# 训练器
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=compute_metrics,
)
print("🚀 开始训练...")
print("-" * 50)
# 训练
train_history = trainer.train()
print("-" * 50)
print("✅ 训练完成!")
# 最终评估
print("📈 最终评估...")
eval_results = trainer.evaluate()
print(f"验证集准确率: {eval_results['eval_accuracy']:.2%}")
print(f"验证集F1分数: {eval_results['eval_f1_macro']:.2%}")
# 保存模型
print("💾 保存模型...")
model.save_pretrained('./models/best_models')
tokenizer.save_pretrained('./models/best_models')
print("🎉 所有完成!模型保存在: ./models/best_models/")
EOF
# 执行
python train_final_fixed.py核心逻辑:
-
提取所有的文本和去重标签,存入两个列表:texts和labels
-
标签映射,构造了两个字典
-
label2id:标签:索引
- 解释:模型只能处理数字,将标签表示为其在列表中的索引
- 而文本列表texts也会被tokenizer张量化tensor
-
id2label:索引:标签
-
预测时会用到,模型输出的是一个概率分布,我们取概率最大的下标
通过该字典就能得到对应的标签。
-
-
-
创建并根据82比例划分数据集
-
加载本地模型和tokenizer(网络不好的时候可以在huggingface社区下载到本地,然后通过scp传到云服务器)
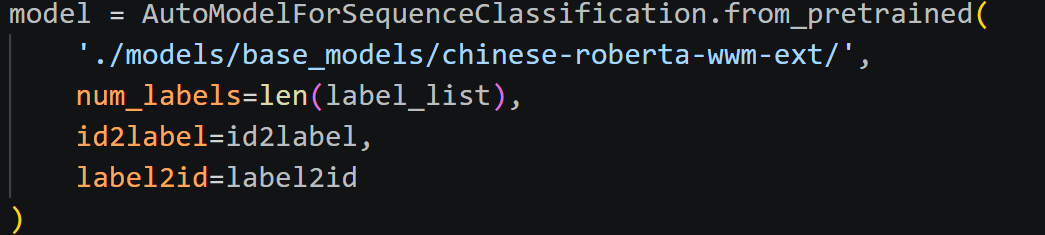
-
数据集预处理
-
要知道模型运算其实就是矩阵运算,所以要进行process
-
按照最大长度128处理:低于128的补0,多于128的截断
-
-
构建评估函数
通过准确率和F1值对每轮训练结果进行一个评估(训练时进行)
-
训练参数
python# 训练参数 training_args = TrainingArguments( output_dir='./models/trained_models', # 设置模型保存的目录路径 num_train_epochs=3, # 设置训练的轮数 per_device_train_batch_size=8, # 设置每个设备上的训练批次大小 per_device_eval_batch_size=8, # 设置每个设备上的评估批次大小 learning_rate=5e-5, # 设置学习率 warmup_steps=100, # 设置预热步数 weight_decay=0.01, # 设置权重衰减系数 logging_steps=50, # 设置每隔多少个步骤进行日志记录 eval_strategy='epoch', # 设置评估的策略为每个epoch进行评估 save_strategy='no', # 设置不保存模型 load_best_model_at_end=False, # 设置不在训练结束时加载最佳模型 fp16=True, # 使用混合精度训练 report_to='none', # 设置不报告训练结果 ) -
最后,封装训练器,开始训练,打印日志
阶段图片展示
-
刚开始训练
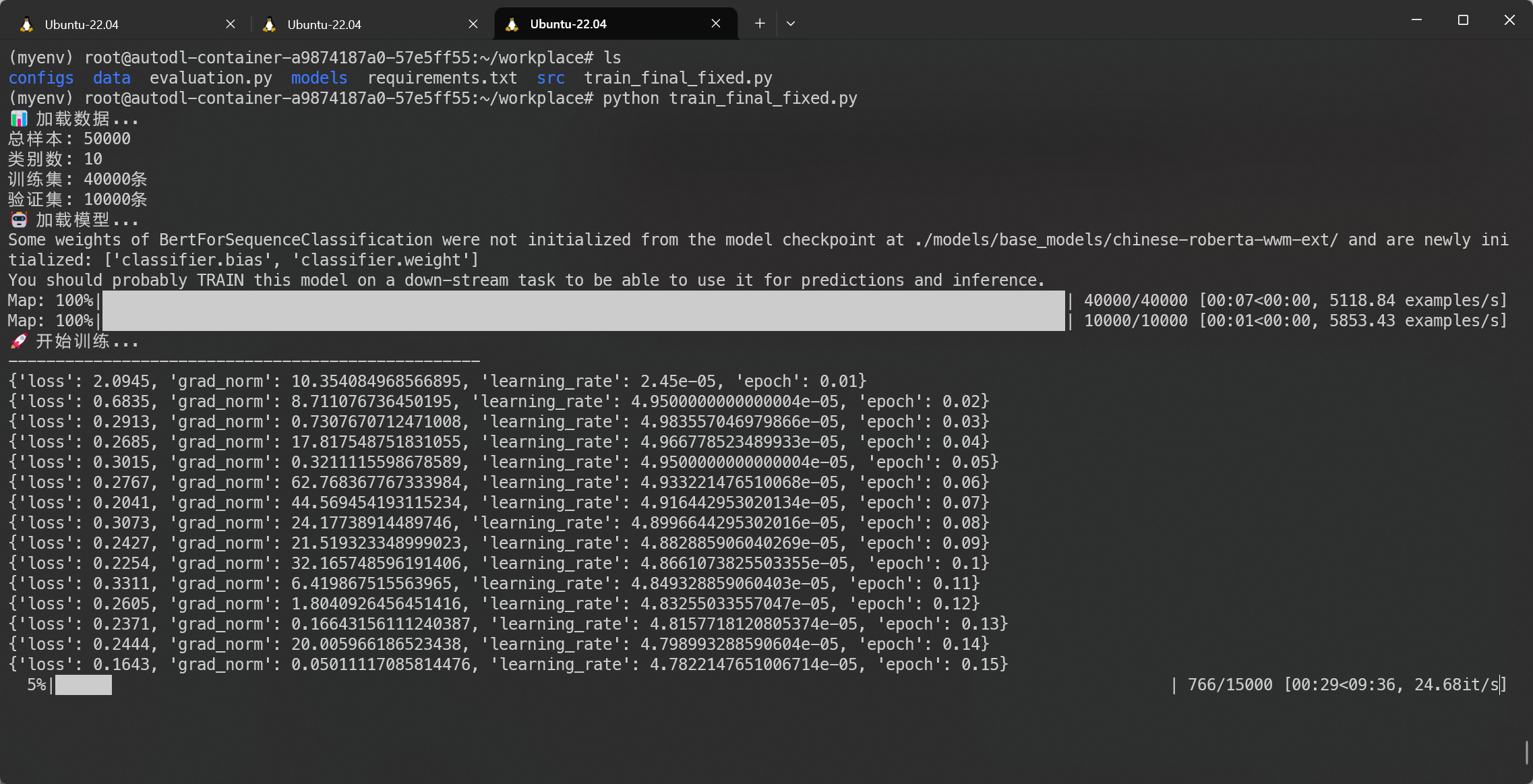
-
训练结束
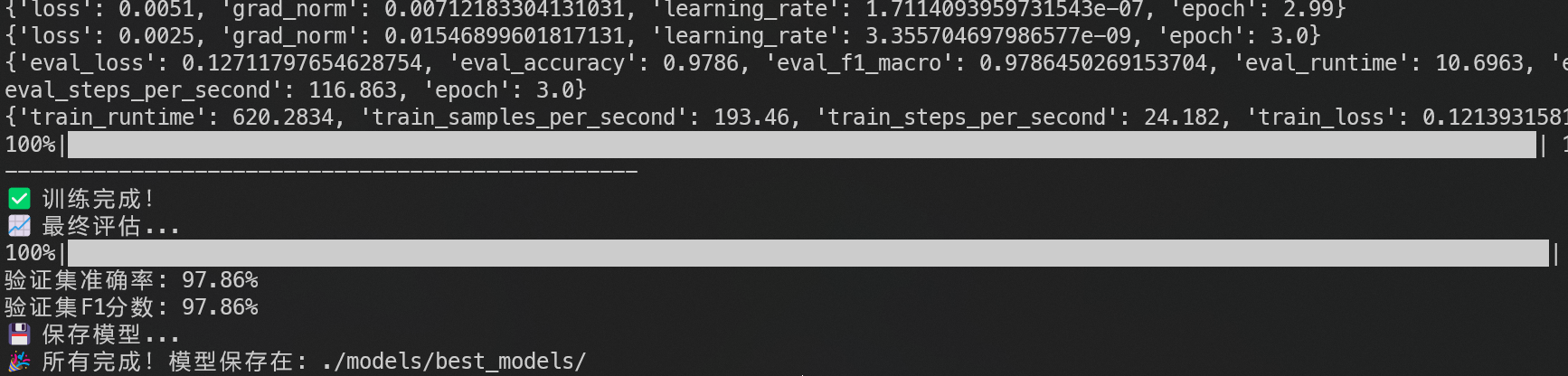
-
测试阶段
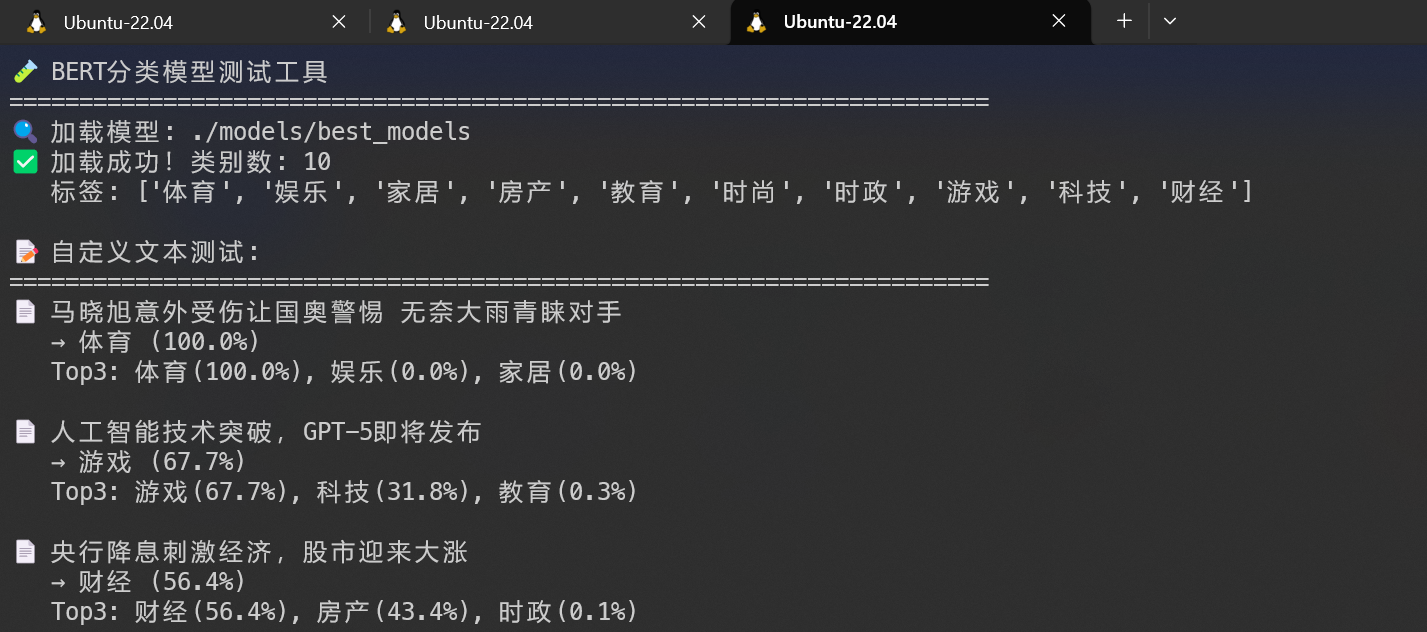

-
模型评估
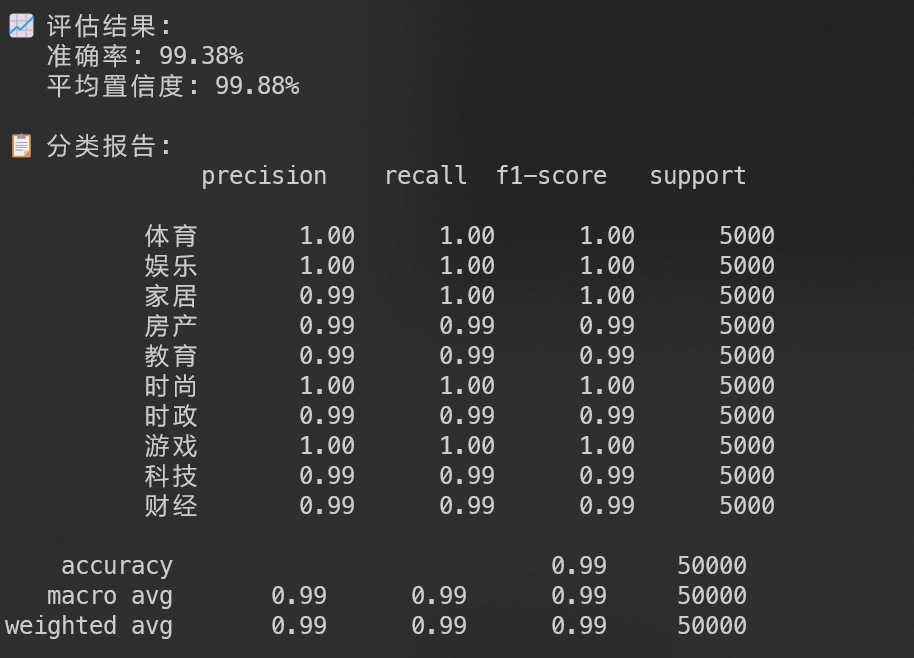
-
性能测试
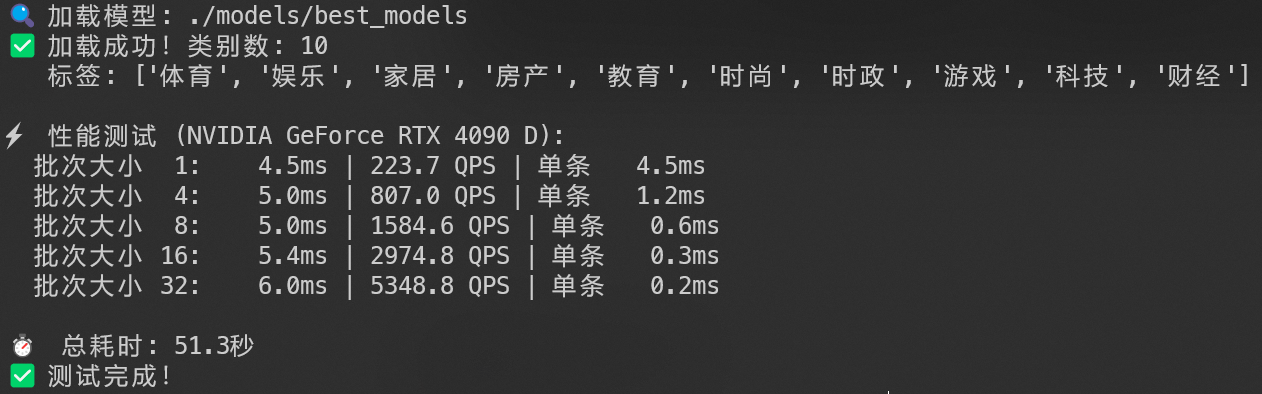
测试代码
python
import torch
import json
from transformers import pipeline, AutoTokenizer, AutoModelForSequenceClassification
import numpy as np
from sklearn.metrics import classification_report, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
def load_model_and_mapping(model_path):
"""加载模型和标签映射"""
print(f"🔍 加载模型: {model_path}")
# 1. 加载模型
model = AutoModelForSequenceClassification.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 2. 加载标签映射
label_mapping_path = f"{model_path}/label_mapping.json"
if os.path.exists(label_mapping_path):
with open(label_mapping_path, 'r', encoding='utf-8') as f:
mapping = json.load(f)
id2label = mapping['id2label']
label2id = mapping['label2id']
elif hasattr(model.config, 'id2label') and model.config.id2label:
id2label = model.config.id2label
label2id = model.config.label2id
else:
print("⚠️ 警告:没有找到标签映射,使用默认数字标签")
id2label = {i: f"类别{i}" for i in range(model.config.num_labels)}
label2id = {v: k for k, v in id2label.items()}
print(f"✅ 加载成功!类别数: {len(id2label)}")
print(f" 标签: {list(id2label.values())}")
return model, tokenizer, id2label, label2id
def predict_single(model, tokenizer, id2label, text, device='cuda'):
"""单条文本预测"""
model.eval()
if device == 'cuda' and torch.cuda.is_available():
model.cuda()
with torch.no_grad():
# tokenize
inputs = tokenizer(
text,
truncation=True,
padding='max_length',
max_length=128,
return_tensors='pt'
)
if device == 'cuda' and torch.cuda.is_available():
inputs = {k: v.cuda() for k, v in inputs.items()}
# 预测
outputs = model(**inputs)
logits = outputs.logits
probs = torch.nn.functional.softmax(logits, dim=-1)
# 获取结果
predicted_id = torch.argmax(probs, dim=-1).item()
confidence = probs.max().item()
predicted_label = id2label.get(predicted_id, f"类别{predicted_id}")
# 获取top-3预测
topk_probs, topk_ids = torch.topk(probs, k=min(3, model.config.num_labels))
topk_labels = [id2label.get(idx.item(), f"类别{idx.item()}") for idx in topk_ids[0]]
topk_confidences = topk_probs[0].tolist()
return {
'text': text[:50] + "..." if len(text) > 50 else text,
'predicted': predicted_label,
'confidence': confidence,
'top3': list(zip(topk_labels, topk_confidences))
}
def test_custom_texts(model_path, test_texts=None):
"""测试自定义文本"""
model, tokenizer, id2label, _ = load_model_and_mapping(model_path)
if test_texts is None:
test_texts = [
"马晓旭意外受伤让国奥警惕 无奈大雨青睐对手", # 体育
"人工智能技术突破,GPT-5即将发布", # 科技
"央行降息刺激经济,股市迎来大涨", # 财经
"明星绯闻曝光,粉丝表示震惊", # 娱乐
"新款游戏发布,玩家热情高涨", # 游戏
"房地产政策调整,房价或将波动", # 房产
"教育改革方案公布,家长关注", # 教育
"时装周最新潮流,设计师展示新作", # 时尚
"国际局势紧张,外交部回应", # 时政
"家居装修新趋势,简约风格受欢迎", # 家居
]
print("\n📝 自定义文本测试:")
print("=" * 70)
results = []
for text in test_texts:
result = predict_single(model, tokenizer, id2label, text)
results.append(result)
print(f"📄 {result['text']}")
print(f" → {result['predicted']} ({result['confidence']:.1%})")
if result['top3']:
print(f" Top3: {', '.join([f'{l}({c:.1%})' for l, c in result['top3']])}")
print()
return results
def evaluate_on_test_data(model_path, test_file):
"""在测试集上评估"""
model, tokenizer, id2label, label2id = load_model_and_mapping(model_path)
print(f"\n📊 加载测试数据: {test_file}")
# 加载测试数据
texts, true_labels = [], []
with open(test_file, 'r', encoding='utf-8') as f:
for line in f:
data = json.loads(line.strip())
texts.append(data['text'])
true_labels.append(data['label'])
print(f" 测试样本数: {len(texts)}")
# 预测所有样本
model.eval()
if torch.cuda.is_available():
model.cuda()
predictions = []
confidences = []
batch_size = 32
for i in range(0, len(texts), batch_size):
batch_texts = texts[i:i+batch_size]
batch_labels = true_labels[i:i+batch_size]
# tokenize批次
inputs = tokenizer(
batch_texts,
truncation=True,
padding='max_length',
max_length=128,
return_tensors='pt'
)
if torch.cuda.is_available():
inputs = {k: v.cuda() for k, v in inputs.items()}
with torch.no_grad():
outputs = model(**inputs)
probs = torch.nn.functional.softmax(outputs.logits, dim=-1)
batch_preds = torch.argmax(probs, dim=-1).cpu().numpy()
batch_confs = probs.max(dim=-1).values.cpu().numpy()
# 转换ID为标签名
batch_pred_labels = [id2label.get(pred, f"类别{pred}") for pred in batch_preds]
predictions.extend(batch_pred_labels)
confidences.extend(batch_confs)
if i % 1000 == 0:
print(f" 已处理: {min(i+batch_size, len(texts))}/{len(texts)}")
# 计算指标
accuracy = np.mean([1 if pred == true else 0 for pred, true in zip(predictions, true_labels)])
print(f"\n📈 评估结果:")
print(f" 准确率: {accuracy:.2%}")
print(f" 平均置信度: {np.mean(confidences):.2%}")
# 分类报告
print("\n📋 分类报告:")
print(classification_report(true_labels, predictions))
# 混淆矩阵(如果类别不多)
if len(set(true_labels)) <= 20:
print("\n🎯 混淆矩阵:")
cm = confusion_matrix(true_labels, predictions, labels=list(id2label.values()))
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=list(id2label.values()),
yticklabels=list(id2label.values()))
plt.title('混淆矩阵')
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.tight_layout()
plt.savefig('confusion_matrix.png', dpi=100)
print(" 已保存到: confusion_matrix.png")
return accuracy, predictions, confidences
def performance_benchmark(model_path):
"""性能测试"""
model, tokenizer, id2label, _ = load_model_and_mapping(model_path)
model.eval()
if torch.cuda.is_available():
model.cuda()
device_name = torch.cuda.get_device_name(0)
else:
device_name = "CPU"
print(f"\n⚡ 性能测试 ({device_name}):")
# 测试文本
test_text = "这是一个测试文本用于性能评估"
# 预热
for _ in range(10):
inputs = tokenizer(test_text, return_tensors='pt')
if torch.cuda.is_available():
inputs = {k: v.cuda() for k, v in inputs.items()}
_ = model(**inputs)
# 批量大小测试
batch_sizes = [1, 4, 8, 16, 32]
results = {}
for bs in batch_sizes:
latencies = []
for _ in range(20):
start = torch.cuda.Event(enable_timing=True) if torch.cuda.is_available() else None
end = torch.cuda.Event(enable_timing=True) if torch.cuda.is_available() else None
if torch.cuda.is_available():
start.record()
else:
start_time = time.time()
# 生成测试批次
batch_texts = [test_text] * bs
inputs = tokenizer(batch_texts, padding=True, truncation=True, max_length=128, return_tensors='pt')
if torch.cuda.is_available():
inputs = {k: v.cuda() for k, v in inputs.items()}
with torch.no_grad():
_ = model(**inputs)
if torch.cuda.is_available():
end.record()
torch.cuda.synchronize()
latency = start.elapsed_time(end)
else:
latency = (time.time() - start_time) * 1000
latencies.append(latency)
avg_latency = np.mean(latencies)
qps = bs * 1000 / avg_latency if avg_latency > 0 else 0
results[bs] = {
'latency_ms': avg_latency,
'qps': qps,
'latency_per_item': avg_latency / bs
}
print(f" 批次大小 {bs:2d}: {avg_latency:6.1f}ms | {qps:5.1f} QPS | 单条 {avg_latency/bs:5.1f}ms")
return results
def main():
import argparse
import time
import os
parser = argparse.ArgumentParser(description='测试BERT分类模型')
parser.add_argument('--model_path', default='./models/best_models', help='模型路径')
parser.add_argument('--test_file', default='data/processed/pre_train.jsonl', help='测试文件')
parser.add_argument('--mode', choices=['custom', 'eval', 'benchmark', 'all'], default='all')
args = parser.parse_args()
print("=" * 70)
print("🧪 BERT分类模型测试工具")
print("=" * 70)
# 检查模型是否存在
if not os.path.exists(args.model_path):
print(f"❌ 模型不存在: {args.model_path}")
print("请先训练模型或指定正确的路径")
return
start_time = time.time()
if args.mode in ['custom', 'all']:
test_custom_texts(args.model_path)
if args.mode in ['eval', 'all'] and os.path.exists(args.test_file):
evaluate_on_test_data(args.model_path, args.test_file)
if args.mode in ['benchmark', 'all']:
performance_benchmark(args.model_path)
elapsed = time.time() - start_time
print(f"\n⏱️ 总耗时: {elapsed:.1f}秒")
print("✅ 测试完成!")
if __name__ == "__main__":
main()模型部署
FastAPI
创建脚本:
python
cat > app_fastapi.py << 'EOF'
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from typing import List, Optional
import uvicorn
import json
app = FastAPI(title="BERT分类API", version="1.0")
# 请求模型
class PredictRequest(BaseModel):
text: str
top_k: Optional[int] = 3
# 响应模型
class PredictResponse(BaseModel):
text: str
predicted_label: str
confidence: float
top_predictions: List[dict]
# 加载模型
@app.on_event("startup")
async def load_model():
global model, tokenizer, device
print("🚀 正在加载模型...")
model = AutoModelForSequenceClassification.from_pretrained('./models/best_models')
tokenizer = AutoTokenizer.from_pretrained('./models/best_models')
model.eval()
if torch.cuda.is_available():
model.cuda()
device = "cuda"
else:
device = "cpu"
print(f"✅ 模型加载完成,使用设备: {device}")
@app.get("/health")
async def health():
return {"status": "healthy"}
@app.post("/predict", response_model=PredictResponse)
async def predict(request: PredictRequest):
try:
text = request.text
top_k = request.top_k
# 预处理
inputs = tokenizer(
text,
truncation=True,
padding='max_length',
max_length=128,
return_tensors='pt'
)
if device == "cuda":
inputs = {k: v.cuda() for k, v in inputs.items()}
# 预测
with torch.no_grad():
outputs = model(**inputs)
probs = torch.nn.functional.softmax(outputs.logits, dim=-1)
# 获取top-k预测
topk = min(top_k, model.config.num_labels)
topk_probs, topk_ids = torch.topk(probs, k=topk)
predictions = []
for i in range(topk):
label_id = topk_ids[0][i].item()
label_name = model.config.id2label.get(label_id, f"类别{label_id}")
prob = topk_probs[0][i].item()
predictions.append({
"label": label_name,
"confidence": round(prob, 4)
})
# 返回结果
return PredictResponse(
text=text[:100] + "..." if len(text) > 100 else text,
predicted_label=predictions[0]["label"],
confidence=predictions[0]["confidence"],
top_predictions=predictions
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=6006, log_level="info")
EOF运行:
bash
python app_fastapi.py
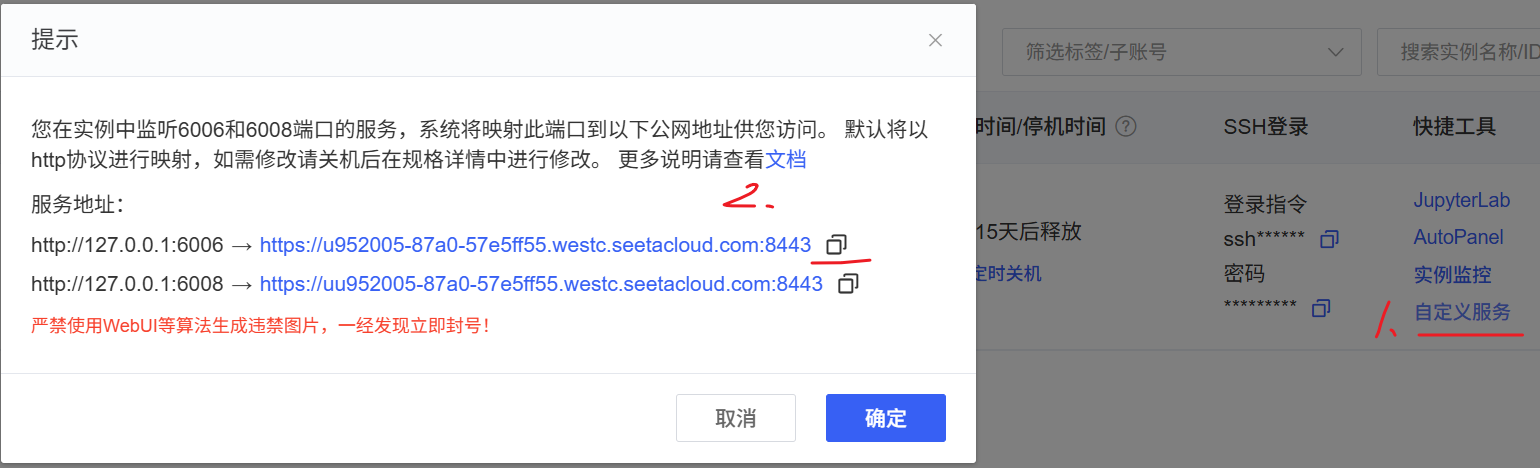
# 访问:https://u952005-87a0-57e5ff55.westc.seetacloud.com:8443/docs (自动API文档)注意:访问地址从这里获取:
测试结果:
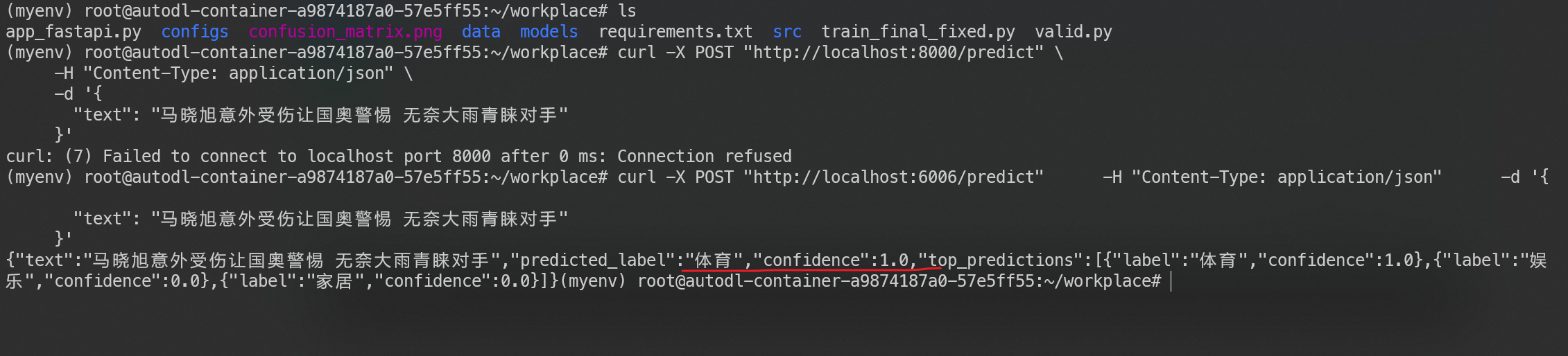
vLLM部署
事实证明,BERT系列模型并不适合使用vLLM部署
简单分析:
1. 任务类型不同
vLLM 设计目标:
- 生成任务(如GPT):输入 → 生成多个token
- 工作方式:自回归(预测下一个token)
- 输出:token序列(如:"这是...一篇...新闻...")
BERT 分类任务:
- 分类任务:输入 → 单一类别
- 工作方式:编码整个文本,用CLS向量分类
- 输出:单个标签(如:"体育")
2. 模型架构不匹配
python
# vLLM 支持的模型类型:
supported = [
"LlamaForCausalLM", # 因果语言模型
"GPT2LMHeadModel", # 生成模型
"BloomForCausalLM", # 生成模型
]
# vLLM 不支持的:
unsupported = [
"BertForSequenceClassification", # BERT分类 ❌
"RobertaForSequenceClassification", # RoBERTa分类 ❌
"T5ForConditionalGeneration", # T5翻译 ❌
]3. 推理模式不同
python
# BERT 推理(简单):
输入 → [CLS]编码 → 分类头 → 类别ID
# GPT 推理(复杂):
输入 → 生成第1个token → 第2个token → ... → 结束符
需要:KV缓存、连续批处理、beam search