论文名称:A synergistic CNN-transformer network with pooling attention fusion for hyperspectral image classification
论文原文 (Paper) :https://www.sciencedirect.com/science/article/abs/pii/S1051200425000922
目录
-
-
- [1. 核心思想](#1. 核心思想)
- [2. 背景与动机](#2. 背景与动机)
-
- [2.1 文本背景与痛点](#2.1 文本背景与痛点)
- [2.2 动机与解决方案分析](#2.2 动机与解决方案分析)
- [3. 主要创新点](#3. 主要创新点)
- [4. 方法细节、](#4. 方法细节、)
-
- [4.1 整体网络架构](#4.1 整体网络架构)
- [4.2 核心创新模块详解](#4.2 核心创新模块详解)
- [4.3 理念与机制总结](#4.3 理念与机制总结)
- [5. 即插即用模块的作用](#5. 即插即用模块的作用)
- [6. 实验分析](#6. 实验分析)
- [7. 获取即插即用更多内容关注 【AI即插即用】](#7. 获取即插即用更多内容关注 【AI即插即用】)
-
1. 核心思想
本文提出了一种协同 CNN-Transformer 网络(SCTNet),旨在解决高光谱图像(HSI)分类中空间-光谱信息利用不足以及深层网络信息丢失的问题。核心思想是采用**双分支特征提取(TBFE)模块并行利用 2D 和 3D 卷积来捕获局部空间-光谱特征,并设计了一个 混合池化注意力(HPA)模块,通过多尺度池化和跨维度交互来增强特征表示。此外,引入了跨层特征融合(CFF)**机制,将 Transformer 编码器的多层输出进行聚合,有效保留了浅层关键信息,最终在五个基准数据集上超越了包括 SS-Mamba 在内的 SOTA 方法。
2. 背景与动机
2.1 文本背景与痛点
高光谱图像分类的核心难点在于如何充分挖掘数百个光谱波段中的精细信息以及复杂的空间上下文。
- CNN的局限:擅长提取局部特征,但难以捕捉长距离的光谱依赖关系。
- Transformer的局限:虽然擅长全局建模,但对局部细节和浅层特征的提取能力较弱,且容易忽略空间信息。
- 融合的难点:现有的混合模型(如 SSFTT)通常只是简单的串联,缺乏深度的特征交互;同时,随着网络层数加深,浅层的关键纹理和光谱信息容易在传播过程中丢失。
本文动机:能否设计一个架构,既能像 CNN 一样精细地提取局部光谱-空间纹理,又能像 Transformer 一样理解全局语义,并且在深层网络中还能"记住"浅层的特征?
2.2 动机与解决方案分析
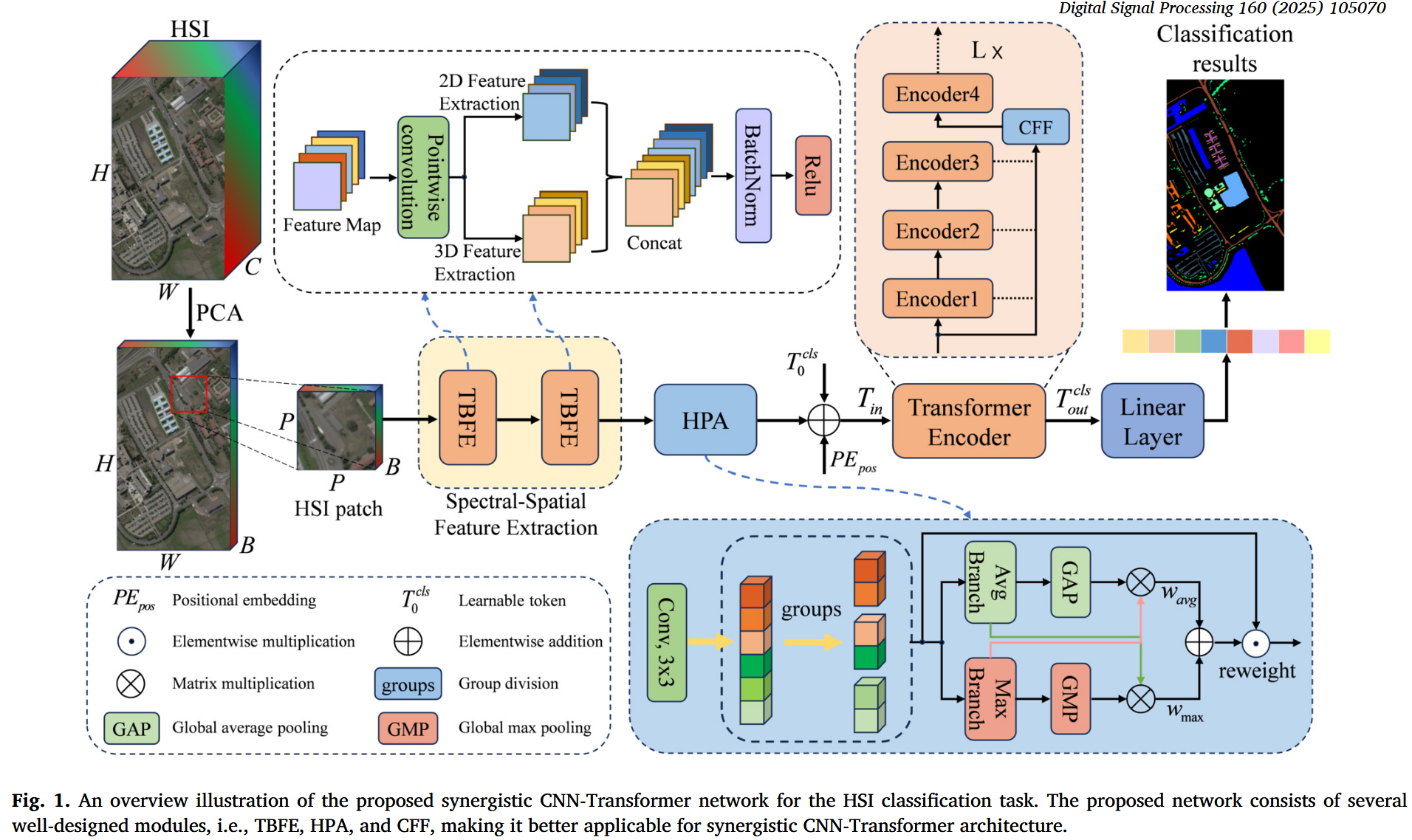
看图说话(架构分析):
- 左侧 (Spectral-Spatial Feature Extraction) :针对 CNN 擅长局部的特点,作者没有使用单一卷积,而是设计了 TBFE(黄色区域)。它并行使用了 3D 卷积(擅长光谱)和 2D 卷积(擅长空间),解决了单一卷积核无法兼顾的问题。
- 中间 (HPA) :在送入 Transformer 之前,插入了 HPA 模块(蓝色区域)。这不仅是为了降维,更是为了通过混合池化(Max+Avg)来"提纯"特征,让 Transformer 聚焦于更有判别力的区域。
- 右侧 (Transformer + CFF) :针对深层信息丢失问题,右侧的 Encoder 堆叠部分引入了 CFF(蓝色小框)。可以看到箭头从 Encoder1, 2, 3 直接连到了 CFF,这意味着最终的分类决策是基于"全层级"特征的,而不仅仅是最后一层。
3. 主要创新点
- 双分支特征提取 (TBFE):创新性地结合了 3D 和 2D 卷积的双流架构,同时提取光谱间的相关性和空间上的纹理信息。
- 混合池化注意力 (HPA):提出了一种基于分组的注意力机制,融合了水平/垂直方向的 1D 全局池化(平均+最大)以及 2D 空间池化,实现了跨维度的特征交互。
- 跨层特征融合 (CFF):在 Transformer 编码器部分引入密集连接机制,自适应地融合不同深度的语义特征,显著减少了信息丢失。
4. 方法细节、
4.1 整体网络架构
数据流详解:
- 输入 (Input) :经过 PCA 降维并切片后的 3D HSI Patch ( P × P × B P \times P \times B P×P×B)。
- 浅层提取 (TBFE) :
- 数据进入 TBFE 模块 ,首先经过 1 × 1 1 \times 1 1×1 卷积调整通道。
- 然后分流进入 3D 卷积分支 (提取光谱特征)和 2D 卷积分支(提取空间特征)。
- 两个分支的输出在通道维度拼接(Concat),融合局部特征。
- 注意力增强 (HPA) :
- 融合后的特征进入 HPA 模块,通过复杂的池化操作计算注意力权重,对特征图进行重加权(Reweight)。
- 全局建模 (Transformer Encoder) :
- 特征被展平并添加位置编码,输入到堆叠的 Transformer Encoders 中。
- 关键路径 :每个 Encoder 的输出不仅传给下一层,还被 CFF 模块 收集。
- 输出 (Output):CFF 模块将所有层的输出融合后,通过全连接层(Linear Layer)预测中心像素的类别。
4.2 核心创新模块详解
模块 A:双分支特征提取 (TBFE)
- 内部结构 :
- Pointwise Conv :先用 1 × 1 1 \times 1 1×1 卷积降维,减少计算量。
- 3D Conv 分支 :对特征进行维度扩展(Expand),使用 1 × 1 × 3 1 \times 1 \times 3 1×1×3 的 3D 卷积核。目的是专门在光谱维度上进行滑动,捕捉波段间的连续性。
- 2D Conv 分支 :使用 3 × 3 3 \times 3 3×3 的 2D 卷积核。目的是在空间维度上提取纹理和形状信息。
- 融合:将两路输出拼接。
- 设计目的:传统的 3D CNN 计算量大,2D CNN 忽略光谱。TBFE 用轻量级的方式实现了两者的优势互补。
模块 B:混合池化注意力 (HPA)
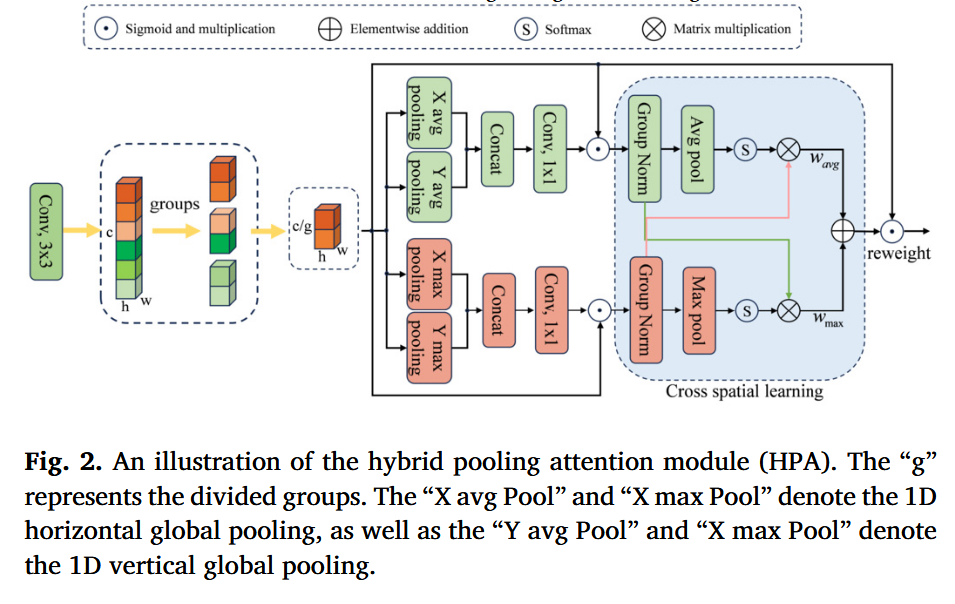
- 内部结构 :
- 分组 (Group):将输入特征沿通道分组,捕捉不同语义。
- 双路 1D 池化 :
- Avg 分支:分别进行 X 轴和 Y 轴的 1D 平均池化,捕捉长距离的空间依赖。
- Max 分支:分别进行 X 轴和 Y 轴的 1D 最大池化,捕捉显著特征(如边缘、极值点)。
- 跨空间学习 (Cross Spatial Learning) :
- 除了上述的通道注意力,还引入了 2D 的全局平均池化和最大池化。
- 通过矩阵乘法(Matrix Multiplication)计算空间注意力图。
- 重加权:将生成的权重作用回原始特征。
- 设计目的:单一的平均池化会模糊细节,最大池化会丢失背景。HPA 结合两者,并显式编码了水平和垂直的位置信息,增强了特征的判别性。
模块 C:跨层特征融合 (CFF)
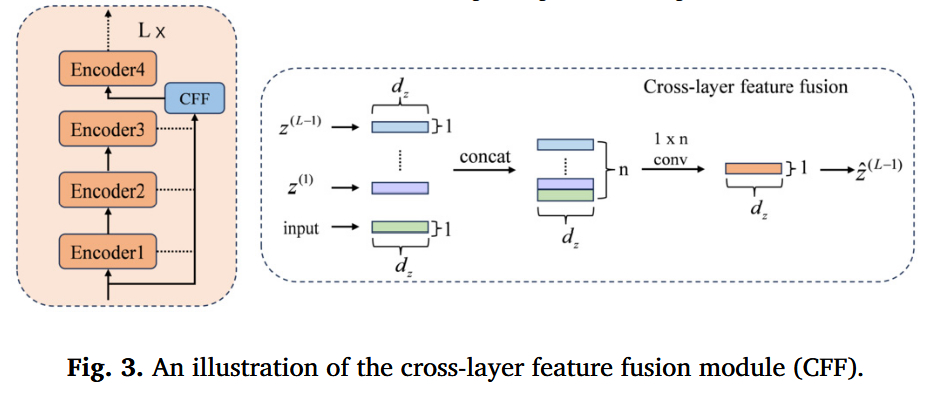
- 工作机制 :
- 输入:Transformer 中第 1 到 L − 1 L-1 L−1 层的所有输出 z ( 1 ) , . . . , z ( L − 1 ) z^{(1)}, ..., z^{(L-1)} z(1),...,z(L−1) 以及原始输入。
- 操作:将这些特征向量进行拼接(Concat)。
- 变换 :通过一个 1 × 1 1 \times 1 1×1 卷积层融合这些多层特征,生成最终的分类 Token。
- 设计理念:深层特征语义强但分辨率低(或丢失细节),浅层特征细节丰富但语义弱。CFF 类似于 DenseNet 的思想,确保分类器能看到"全貌"。
4.3 理念与机制总结
SCTNet 的设计哲学是**"分工明确,全面融合"**:
-
TBFE 负责底层的物理特征提取(光谱+空间)。
-
HPA 负责中层的特征筛选与强化(关注哪里重要)。
-
Transformer 负责高层的语义建模(全局相关性)。
-
CFF 负责纵向的信息流动(防止遗忘)。
这种从局部到全局、从浅层到深层的全方位设计,解决了 HSI 分类中特征表达不充分的问题。
5. 即插即用模块的作用
- HPA (Hybrid Pooling Attention) :
- 适用场景:任何 CNN 或 Transformer 的 Attention 阶段。
- 应用 :可以替代 SE-Block 或 CBAM。由于它同时利用了 Max 和 Avg 池化以及空间位置编码,对于细粒度分类 或小目标检测任务特别有效。
- CFF (Cross-layer Feature Fusion) :
- 适用场景:基于 Transformer 的分类或回归骨干网络。
- 应用 :在 ViT 的最后分类头之前加入 CFF,可以提升模型在特征混淆严重数据集上的鲁棒性,因为它利用了浅层的判别信息。
6. 实验分析
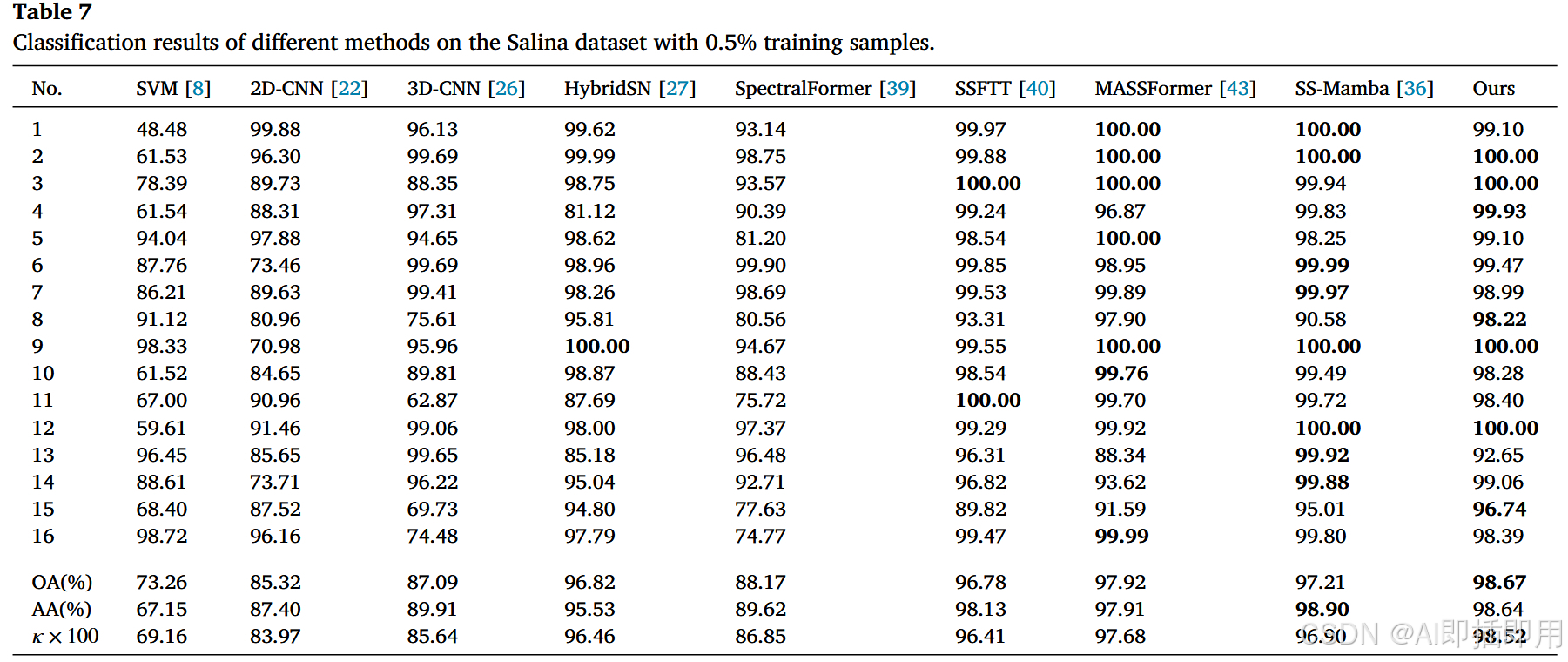
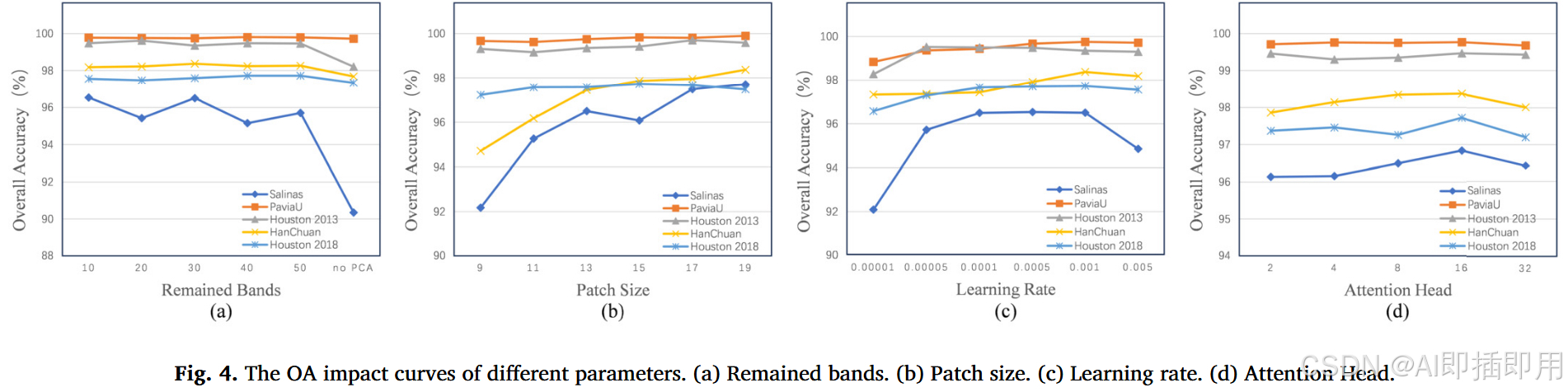
- 数据集 :在 Salinas , Pavia University , Houston2013 , WHU-Hi-HanChuan , Houston2018 五个经典数据集上进行了测试。
- SOTA 对比 :
- 对比对象 :SVM, 2D/3D-CNN, HybridSN, SpectralFormer, SSFTT, MASSFormer, SS-Mamba (2024年最新)。
- 结果 :
- 在 Salinas 数据集上,OA 达到 98.67%,高于 SS-Mamba (97.21%)。
- 在 Houston2013 数据集上,OA 达到 99.65%,显著优于 SSFTT (99.41%) 和 SS-Mamba (94.93%)。
- 在 Pavia University 上,OA 达到 99.92%,几乎完美分类。
- 消融实验 (Table 12) :
- 移除 HPA 或 CFF 都会导致性能下降。例如,去掉 HPA 和 CFF 后(Case 2),OA 从 98.67% 降至 97.35%,证明了这些模块的有效性。
- 效率分析 (Table 13) :
- 虽然引入了 Transformer,但参数量(167k)远小于 3D-CNN (462k) 和 HybridSN (797k),推理时间也保持在极具竞争力的水平(8.02s),仅略慢于纯 CNN 方法,但快于 MASSFormer。
总结:SCTNet 是一篇非常扎实的架构创新论文。它没有盲目追求纯 Transformer 或 Mamba 的热度,而是冷静地分析了 HSI 数据的特性,通过精心设计的 TBFE 和 CFF 模块,成功将 CNN 的稳健性与 Transformer 的先进性结合,是高光谱图像分类领域的一个强力 Baseline。