你是否想过,AI如何从一堆随机噪声中"变"出一张逼真的人脸?或者让马变成斑马、让夏天变成冬天?
这些看似魔法的效果,背后都藏着一种叫**生成对抗网络(GAN, Generative Adversarial Network)**的AI技术。本文将用最通俗的语言,带你揭开GAN的神秘面纱,甚至教你如何用代码实现一个简单的GAN!
一、GAN是什么?一场"造假者"与"警察"的博弈
想象一个场景:
- 你是一名伪钞制造者(生成器),目标是造出以假乱真的钞票。
- 警察(判别器)的任务是识破你的假钞。
游戏规则:
- 你不断改进造假技术,试图骗过警察。
- 警察不断升级鉴别能力,试图识破你的假钞。
- 经过无数轮博弈,最终有两种可能:
- 你成为顶级"造假大师",警察根本分不清真假。
- 警察练就"火眼金睛",你的假钞一眼被识破。
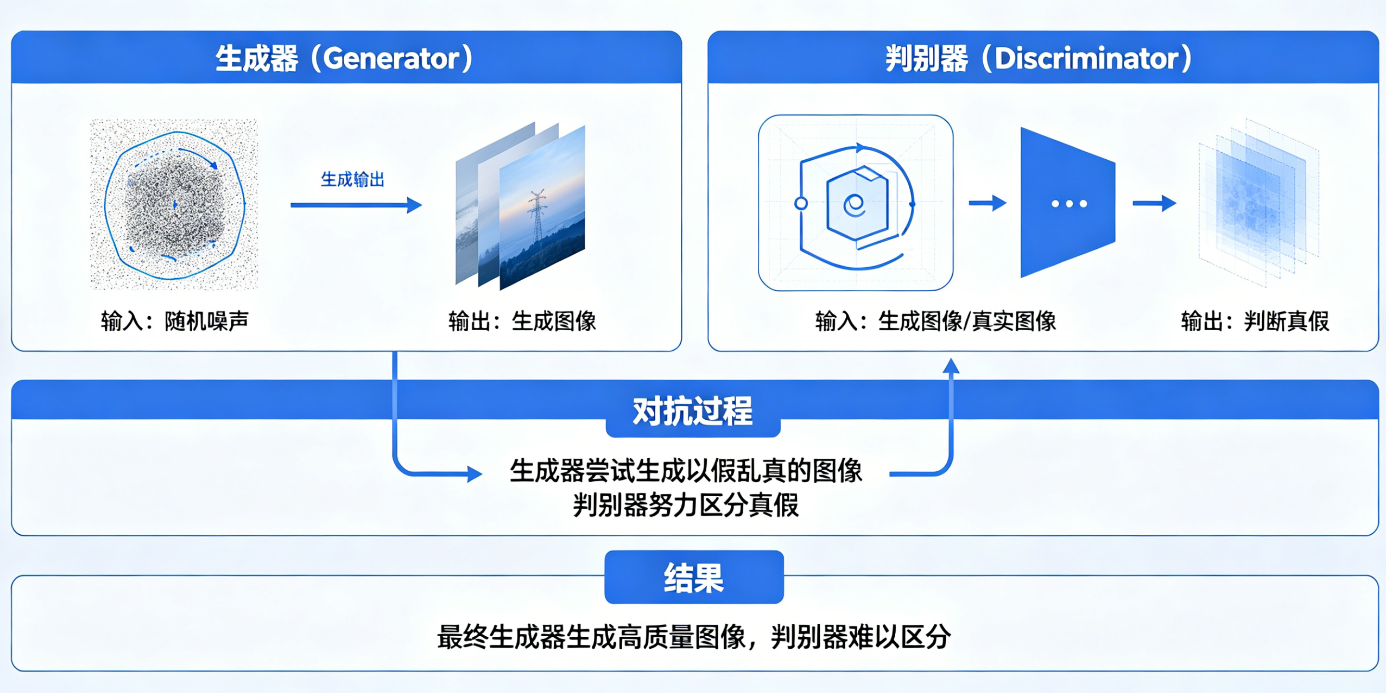
GAN的核心思想正是如此:
- 生成器(Generator):接收随机噪声(比如一堆乱码),生成"假数据"(如图片、文字)。
- 判别器(Discriminator):接收真实数据或生成器输出的假数据,判断它是真的还是假的(输出概率值,0=假,1=真)。
- 对抗训练:生成器努力欺骗判别器,判别器努力识破生成器,两者在博弈中共同进化。
类比 :
GAN就像两个学生在考试中互相较劲:
- 学生A(生成器)拼命作弊(造假),试图让老师(判别器)看不出来。
- 老师(判别器)拼命抓作弊,试图识破学生A的假答案。
- 最终,学生A的作弊技术越来越高明,老师的防作弊能力也越来越强,直到老师再也抓不到作弊(生成的数据和真实数据一模一样)。
二、GAN如何工作?极小极大博弈的数学游戏
GAN的目标是通过优化一个"损失函数"来实现动态平衡。这个函数看起来很复杂,但可以用一个简单的比喻理解:
损失函数公式:
GminDmaxV(D,G)=Ex∼pdata(x)logD(x)+Ez∼pz(z)log(1−D(G(z)))
通俗解释:
- 判别器(D)的目标 :
- 对真实数据(比如真实照片),输出概率接近1("这是真的")。
- 对生成数据(比如AI生成的假照片),输出概率接近0("这是假的")。
- 判别器的损失:真实数据被判为假的 + 假数据被判为真的(越小越好)。
- 生成器(G)的目标 :
- 生成的数据能让判别器误判为真(即判别器输出概率接近1)。
- 生成器的损失:假数据被判为假的(越小越好,即让判别器误判)。
博弈过程:
- 生成器努力让判别器犯错(损失变小)。
- 判别器努力不犯错(损失变大)。
- 最终,生成器生成的样本和真实样本完全一致,判别器无法区分,输出概率恒为0.5(随机猜)。
三、GAN的进化史:从"菜鸟"到"大神"
GAN自2014年提出以来,经历了多次升级,解决了原始版本的许多问题:
1. 原始GAN(2014)
- 问题:训练不稳定,容易"模式崩溃"(比如生成器只生成一种类型的图片,比如全是"7")。
- 类比:就像学生A只会作弊一种答案,老师很快就能识破。
2. DCGAN(深度卷积GAN,2015)
- 改进:用卷积神经网络(CNN)替代全连接层,更适合处理图像。
- 效果:可以生成更清晰的人脸、场景图片。
- 类比:学生A学会了用更高级的方法作弊(比如用隐形墨水),老师更难发现。
3. WGAN(Wasserstein GAN,2017)
- 改进:用"地球移动距离"(Wasserstein距离)替代交叉熵损失,解决梯度消失问题。
- 效果:训练更稳定,生成样本更多样。
- 类比:老师和学生A的较量变得更公平,不再是一方碾压另一方。
4. StyleGAN(风格生成GAN,2018)
- 改进:可以控制生成图像的风格(比如发色、表情、光照)。
- 效果:生成高分辨率、可编辑的人脸图像(如DeepFake的基础技术)。
- 类比:学生A不仅可以作弊,还能控制作弊的"风格"(比如用不同字体写答案)。
四、GAN能做什么?从艺术到医疗的"魔法"
GAN的应用非常广泛,几乎涵盖了所有需要"生成"数据的领域:
1. 图像生成
- 例子:生成逼真的人脸、动物、风景图片。
- 应用:AI绘画(如DALL·E、MidJourney)、游戏角色生成、虚拟试衣。
2. 图像修复
- 例子:修复老照片、去除图片中的水印或遮挡物。
- 应用:照片修复软件、医疗影像去噪。
3. 风格迁移
- 例子:把马变成斑马、把夏天变成冬天、把照片变成梵高画风。
- 应用:AI滤镜、艺术创作、电影特效。
4. 数据增强
- 例子:生成更多的训练数据(比如医学影像、自动驾驶场景)。
- 应用:解决数据稀缺问题,提升模型鲁棒性。
5. 文本生成
- 例子:生成假新闻、写诗、写代码。
- 应用:聊天机器人、内容创作、自动化编程。
五、GAN的挑战:它并不是完美的"魔法"
尽管GAN很强大,但它也有一些"脾气":
1. 训练不稳定
- 问题:生成器和判别器的训练进度不一致,可能导致一方"碾压"另一方。
- 类比:老师和学生A的较量中,如果老师太强或学生太弱,游戏就无法继续。
2. 模式崩溃
- 问题:生成器只生成一种类型的样本(比如全是"7"或全是"猫")。
- 类比:学生A只会作弊一种答案,老师很快就能识破。
3. 评估困难
- 问题:无法直接计算生成样本与真实数据的"相似度"。
- 类比:老师无法量化学生A的作弊技术有多高明,只能靠感觉判断。
4. 伦理问题
- 问题:GAN可能被用于生成假新闻、DeepFake伪造视频,造成社会危害。
- 类比:学生A用作弊技术伪造考试答案,可能被学校开除甚至法律追责。
六、如何入门GAN?从代码到实践
现在让我们实现一个生成对抗网络(GAN)的核心框架,包含生成器(Generator)和判别器(Discriminator)两个核心模块。
生成器接收100维的随机噪声向量,通过三层全连接网络(含ReLU激活)将其扩展为784维的向量,最后通过Tanh激活限制输出范围在-1,1并重塑为28x28的灰度图片(1通道)。判别器则接收28x28的扁平化图片数据(784维),通过三层全连接网络(含ReLU激活)压缩为1维概率值,通过Sigmoid函数判断图片为真实的概率(0表示生成,1表示真实)。
训练过程采用对抗学习策略:在每个epoch中,判别器先通过真实图片(标签1)和生成器生成的假图片(标签0)计算损失(二分类交叉熵),优化自身区分能力;随后生成器利用判别器对假图片的判断结果(希望被误判为真实,即标签1)计算损失,反向传播优化自身生成能力。两个优化器(Adam,学习率0.0002)交替更新参数,形成"生成-判别"的对抗训练循环,最终目标是让生成器生成以假乱真的图片。
如果你想亲自体验GAN的"魔法",可以尝试以下步骤:
1. 安装环境
- 工具:Python + PyTorch(或TensorFlow)。
- 库 :
torch,torchvision,numpy,matplotlib。
2. 下载数据集
- 推荐:MNIST手写数字(60,000张28x28灰度图)。
3. 写代码
1import torch
2import torch.nn as nn
3import torch.optim as optim
4from torchvision import datasets, transforms
5
6# 定义生成器(输入噪声,输出假图片)
7class Generator(nn.Module):
8 def __init__(self):
9 super().__init__()
10 self.model = nn.Sequential(
11 nn.Linear(100, 256), nn.ReLU(),
12 nn.Linear(256, 512), nn.ReLU(),
13 nn.Linear(512, 784), nn.Tanh() # 输出范围[-1, 1]
14 )
15 def forward(self, z):
16 img = self.model(z)
17 return img.view(-1, 1, 28, 28) # 调整为(N, C, H, W)
18
19# 定义判别器(输入图片,输出真假概率)
20class Discriminator(nn.Module):
21 def __init__(self):
22 super().__init__()
23 self.model = nn.Sequential(
24 nn.Linear(784, 512), nn.ReLU(),
25 nn.Linear(512, 256), nn.ReLU(),
26 nn.Linear(256, 1), nn.Sigmoid() # 输出概率
27 )
28 def forward(self, img):
29 flattened = img.view(-1, 784)
30 return self.model(flattened)
31
32# 初始化模型
33generator = Generator()
34discriminator = Discriminator()
35
36# 优化器
37optimizer_G = optim.Adam(generator.parameters(), lr=0.0002)
38optimizer_D = optim.Adam(discriminator.parameters(), lr=0.0002)
39
40# 训练循环(简化版)
41for epoch in range(100):
42 for real_imgs, _ in dataloader:
43 # 训练判别器
44 optimizer_D.zero_grad()
45 real_labels = torch.ones(real_imgs.size(0), 1)
46 fake_imgs = generator(torch.randn(real_imgs.size(0), 100)).detach()
47 fake_labels = torch.zeros(real_imgs.size(0), 1)
48 d_loss = criterion(discriminator(real_imgs), real_labels) + criterion(discriminator(fake_imgs), fake_labels)
49 d_loss.backward()
50 optimizer_D.step()
51
52 # 训练生成器
53 optimizer_G.zero_grad()
54 fake_imgs = generator(torch.randn(real_imgs.size(0), 100))
55 g_loss = criterion(discriminator(fake_imgs), real_labels) # 欺骗判别器
56 g_loss.backward()
57 optimizer_G.step()生成器(Generator)是一个神经网络,输入是100维的噪声向量,经过三个全连接层,输出784维的向量,然后通过Tanh激活函数限制输出在-1,1范围。最后将输出调整为28x28的图片格式(N, C, H, W),即1通道的28x28图像。
判别器(Discriminator)也是一个神经网络,输入是784维的扁平化图片数据,经过三个全连接层,最后用Sigmoid输出一个概率值,判断输入图片是真实还是生成的。
训练部分使用了两个优化器,分别对应生成器和判别器,学习率都是0.0002。训练循环中,每个epoch遍历数据加载器中的真实图片。首先训练判别器:用真实图片和对应的标签1,以及生成器生成的假图片(detach防止梯度回传到生成器)和标签0,计算判别器的损失,然后反向传播和优化。接着训练生成器:生成新的假图片,计算生成器损失(希望判别器将假图片判断为真实,所以用真实标签1),然后反向传播和优化生成器参数。
4. 运行结果
- 训练100个epoch后,生成器可以输出类似手写数字的图片(如"2""7"等)。
- 判别器对真实/生成数据的判断准确率接近50%(随机猜)。
七、总结:GAN是AI的"造物主"还是"骗子"?
GAN通过"对抗"这一简单却强大的思想,让AI学会了"无中生有"。从生成逼真的人脸到修复老照片,从风格迁移到数据增强,GAN的应用几乎无处不在。然而,它也面临训练不稳定、模式崩溃、伦理问题等挑战。
未来展望 :
随着扩散模型(Diffusion Models)等新技术的崛起,GAN可能不再是生成模型的主流,但它的对抗训练思想将永远激励着研究者探索更智能的AI系统。
动手建议:
- 从MNIST手写数字生成入门,逐步尝试CIFAR-10彩色图像。
- 阅读WGAN论文《Wasserstein GAN》,理解数学推导。
- 关注StyleGAN、CycleGAN等变体,探索风格迁移和图像修复。
GAN的世界充满无限可能,现在,轮到你来创造属于自己的"魔法"了!