一句话总结
VQKV 用向量量化把 KV cache 从"每个 token 存一长串浮点数"改成"存几个共享码本的索引编号",在压掉 82.8% 的缓存后仍保留 98.6% 的原始性能
- 论文标题:VQKV: High-Fidelity and High-Ratio Cache Compression via Vector-Quantization
- 论文地址 :https://arxiv.org/pdf/2603.16435
- 作者背景:上海交通大学、上海人工智能实验室、剑桥大学、新加坡国立大学
- 代码地址 :https://github.com/LUMIA-Group/VQKV
- 模型地址 :https://huggingface.co/LuckyOrz/vqkv_llama3.1-8B
一、动机
大模型在推理时会缓存每一步的 key 和 value 向量,这就是 KV cache。上下文越长,KV cache 越大,显存很快成为部署瓶颈。
现有的 KV cache 压缩方案大致分三类,但各有硬伤:
| 方向 | 代表方法 | 优势 | 痛点 |
|---|---|---|---|
| Token Eviction(丢弃 token) | SnapKV, H2O | 压缩率高 | 信息不可逆丢失 |
| Feature Dimension Reduction(降维) | Palu, ASVD, MLA | 保留信息较多 | 高压缩率时保真难,或需要额外训练 |
| Scalar Quantization(标量量化) | KIVI, KVQuant | 简单直接 | 逐元素独立量化,忽略向量内部结构 |
三条路线的共同矛盾是:很难同时做到"不改模型权重"、"高压缩率"和"高保真"。
作者的判断是:问题不在于"要不要压",而在于"怎么压才不把语义骨架压坏"。标量量化把每个数单独处理,就像把一幅画拆成一堆像素各自近似,没抓住整体形状。如果能整段向量一起编码,就更可能保住结构信息。
这引出了向量量化(VQ)的思路。VQ 在文本检索(FAISS)和计算机视觉(VQ-VAE/VQ-GAN)领域早已被验证过高压缩与高保真的能力,但之前很少有人将它用于 LLM 的 KV cache 压缩------主要因为 LLM 对 KV cache 极其敏感,RoPE 还会让不同维度带有不同频率特性,直接套 VQ 并不容易。
二、核心方法
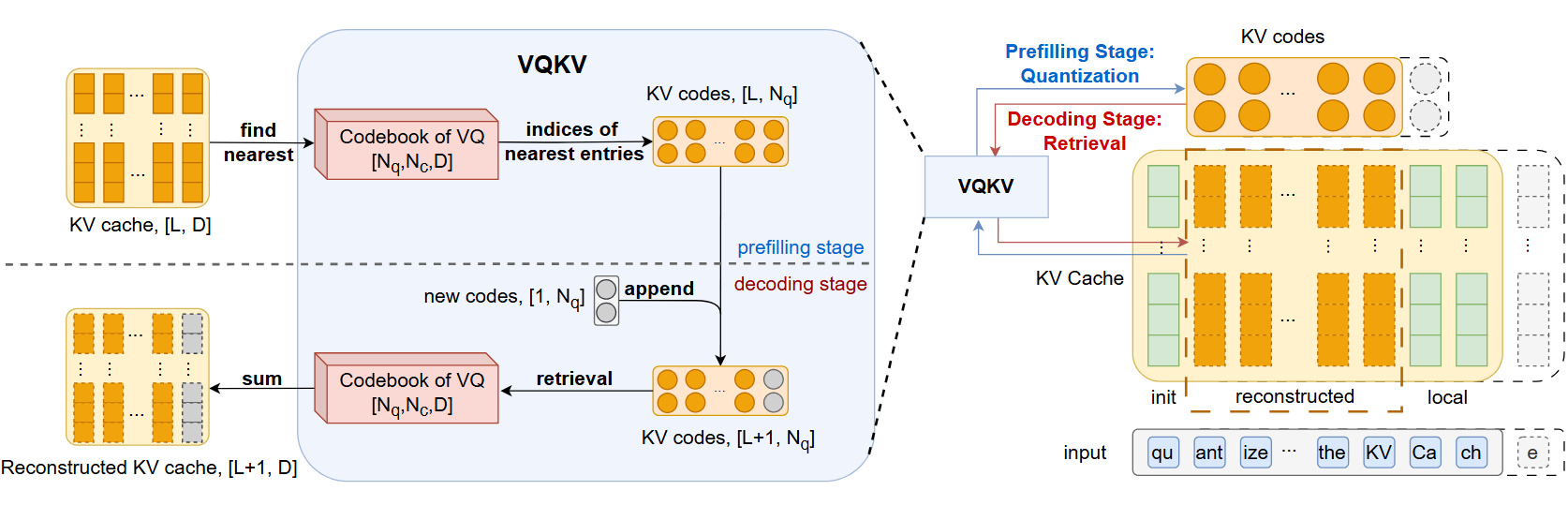
2.1 核心思想:把浮点向量改写成码本索引
VQKV 不"扔掉"信息,也不简单"压扁"维度,而是把每个 KV 向量改写成几个整数索引 。原来需要存一长串浮点数,现在只需存"去第 3 本字典拿第 127 个条目、去第 4 本字典拿第 18 个条目......"这样的编号。真正的大块表示内容放在共享码本(codebook)里,很多 token 共同复用同一套码本。
2.2 残差多级码本:RSimVQ
VQKV 不是只用一个码本,而是用残差式的多级码本(Residual Simple Vector Quantization, RSimVQ)。过程可以类比画画:
- 码本 1 先抓大轮廓:找到最接近原始向量的条目
- 码本 2 修正误差:对第一步的残差再找最近条目
- 码本 3 继续精修:把剩余残差再压一层
- ......以此类推
最终重建时,把各级码本取回的条目相加:
x ^ = ∑ i = 1 N Q i z i \hat{x} = \sum_{i=1}^{N} Q_iz_i x^=i=1∑NQizi
一口气找一个"万能近似"很难,但分几次逐级修正误差,失真就能被有效压下去。
这里有一个关键优势:残差结构天然适配 RoPE。RoPE 旋转位置编码让 key 的不同维度带有不同频率特性,向量内部结构更复杂。VQKV 的残差设计把 RoPE 引入的变化分摊到多个码本里处理,因此对 RoPE 旋转后的 key 更加稳健。
2.3 码本训练
需要澄清一个容易被误解的点:论文说的 "training-free" 是指对原模型参数 training-free ,推理时不改 LLM 权重、不需微调。但码本本身需要离线预训练:
- 从大约 1000 万 token 的 KV cache 中预取数据
- Key 和 value 分别训练两套独立的码本
- 训练用 OpenWebText 的 0.1% 数据,学习率 0.001,batch size 65536
训练损失包含三项:重建误差、码本更新项、以及 commitment loss,并通过 stop-gradient 保持梯度流通:
L = ∥ x − x ^ ∥ 2 + β ∥ q z − sg ( x ) ∥ 2 + γ ∥ x − sg ( q z ) ∥ \mathcal{L} = \|x - \hat{x}\|^2 + \beta\|q_z - \text{sg}(x)\|^2 + \gamma\|x - \text{sg}(q_z)\| L=∥x−x^∥2+β∥qz−sg(x)∥2+γ∥x−sg(qz)∥
三、推理流程
推理分两个阶段:prefill 和 decoding。
3.1 Prefill 阶段
VQKV 不会把所有 KV 都压掉,而是保留两段不压缩的区域:
- 初始段 ( L i n i t = 4 L_{init} = 4 Linit=4):序列最前面的几个 token
- 本地窗口 ( L l o c a l = 1024 L_{local} = 1024 Llocal=1024):最近的一段 token
中间那大段历史 KV 才做向量量化,改存为整数索引。直觉上,这像是把一本书的开头几页和你刚翻到的这几页原样留着,中间的大量内容改存成目录编号。
在 prefill 当下做 forward 时,仍然使用原始 KV 参与 attention(压缩只为后续存储服务)。
3.2 Decoding 阶段
Decoding 阶段的设计更讲究:
- 按需重建:借助 FlashAttention,VQKV 只重建当前这一步 attention 真正需要的 KV 部分,而不是每步都还原整条历史
- 定制 Kernel:实现了专门的 FlashAttention kernel,把"按需重建"和内核计算流程对齐,进一步减少内存占用
- 块级批量量化 :量化动作不是每来一个 token 就做一次,而是每隔 L l o c a l L_{local} Llocal 步做一次批量量化,大幅降低量化频率
3.3 压缩率
压缩率由码本数量和大小共同决定:
r = ( 1 − N k log S k + N v log S v 16 ( D k + D v ) ) × 100 % r = \left(1 - \frac{N^k \log S^k + N^v \log S^v}{16(D^k + D^v)}\right) \times 100\% r=(1−16(Dk+Dv)NklogSk+NvlogSv)×100%
实验中 LLaMA3.1-8B 使用 ( N k , N v ) = ( 56 , 16 ) (N^k, N^v) = (56, 16) (Nk,Nv)=(56,16),码本大小 ( S k , S v ) = ( 1024 , 512 ) (S^k, S^v) = (1024, 512) (Sk,Sv)=(1024,512),对应 82.8% 的压缩率。
四、实验结果
4.1 LongBench
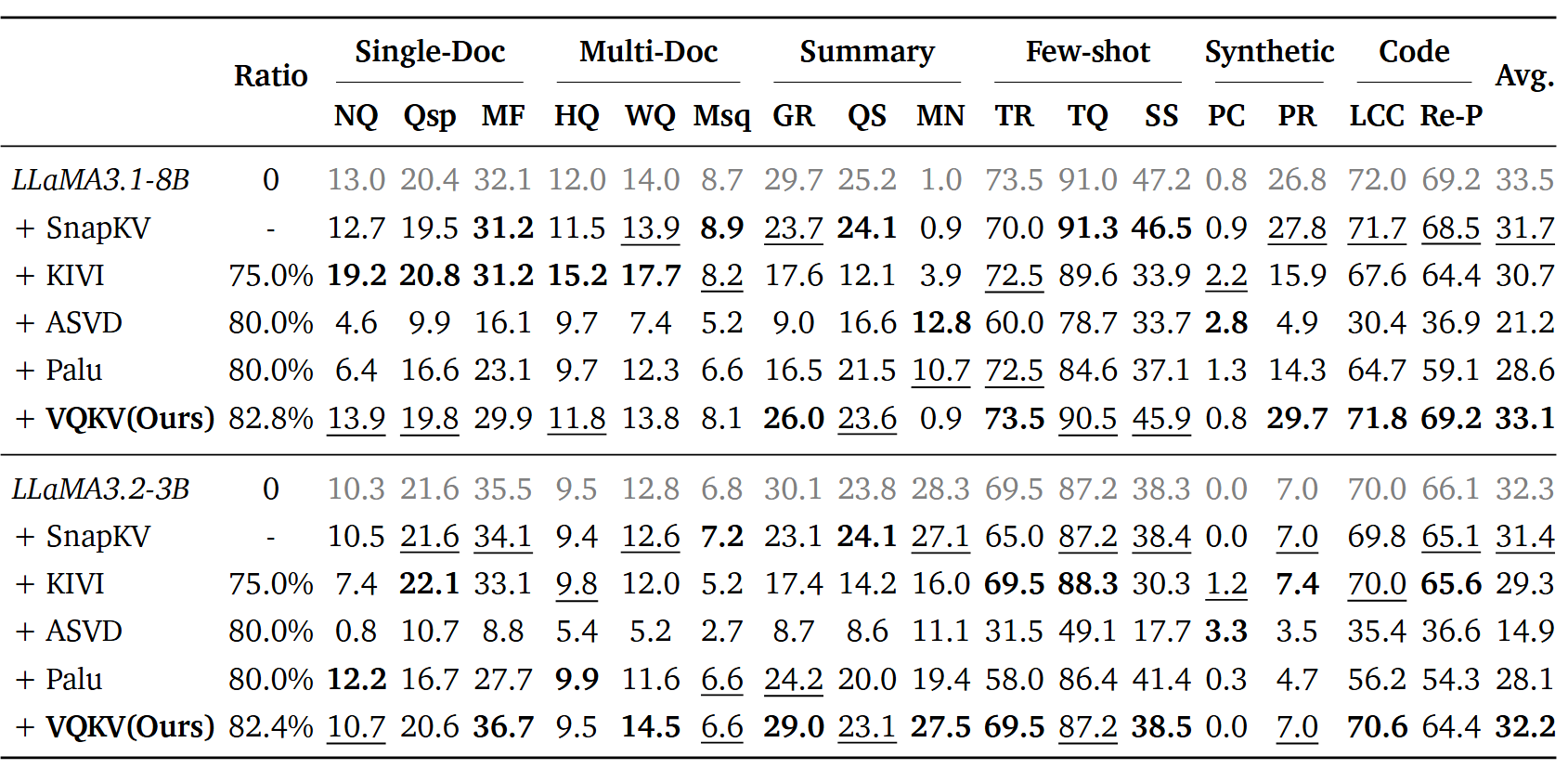
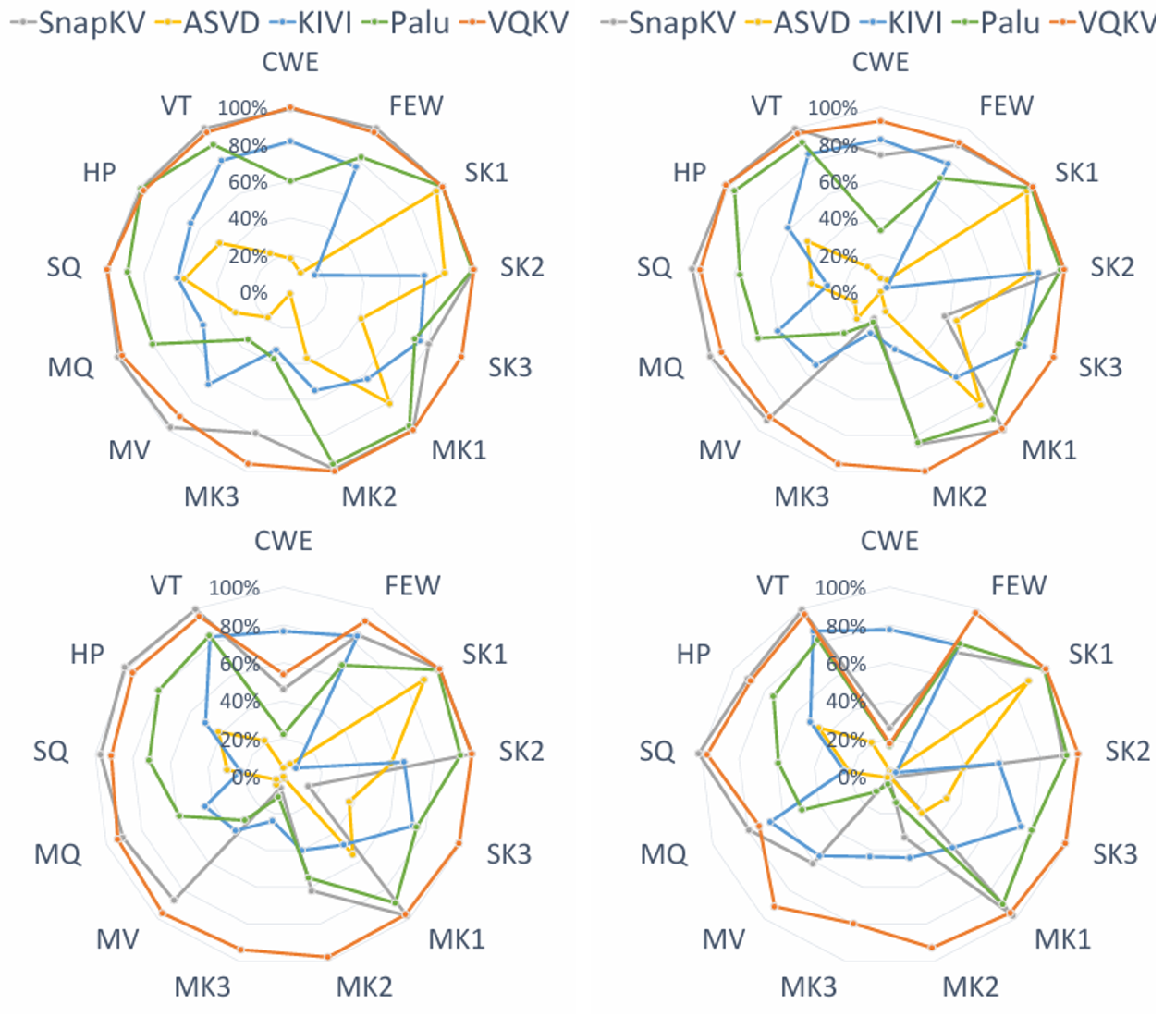
在 LongBench 上,VQKV 在高压缩率下全面领先:
| 方法 | 压缩率 | LLaMA3.1-8B 均分 | LLaMA3.2-3B 均分 |
|---|---|---|---|
| Full Cache | 0% | 33.5 | 32.3 |
| VQKV | 82.8%/82.4% | 33.1 | 32.2 |
| SnapKV | - | 31.7 | 31.4 |
| KIVI | 75.0% | 30.7 | 29.3 |
| Palu | 80.0% | 28.6 | 28.1 |
| ASVD | 80.0% | 21.2 | 14.9 |
VQKV 在 82.8% 压缩率下保留了基线 98.6% 的性能,且在部分子任务上甚至超过了不压缩的基线。
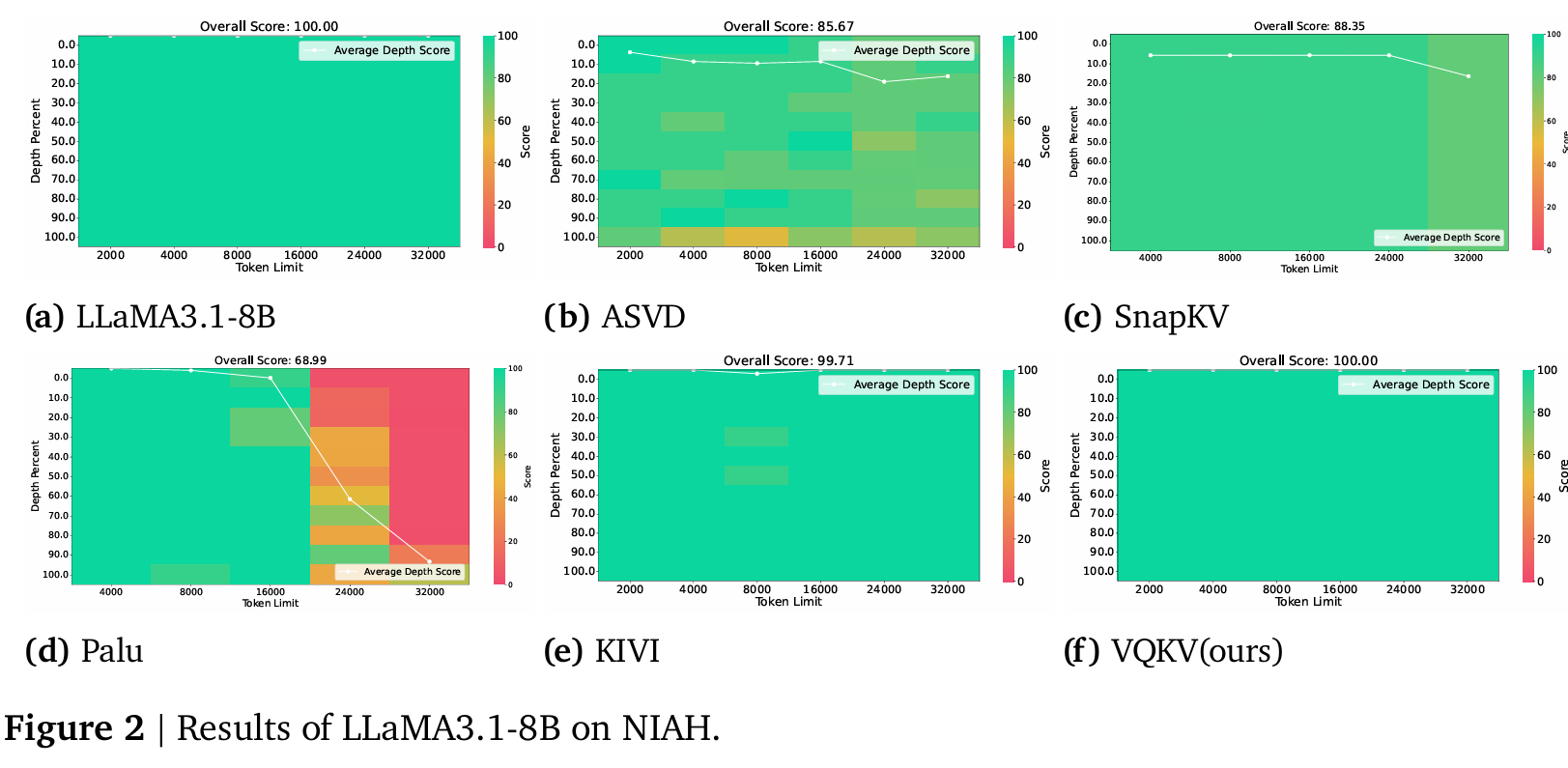
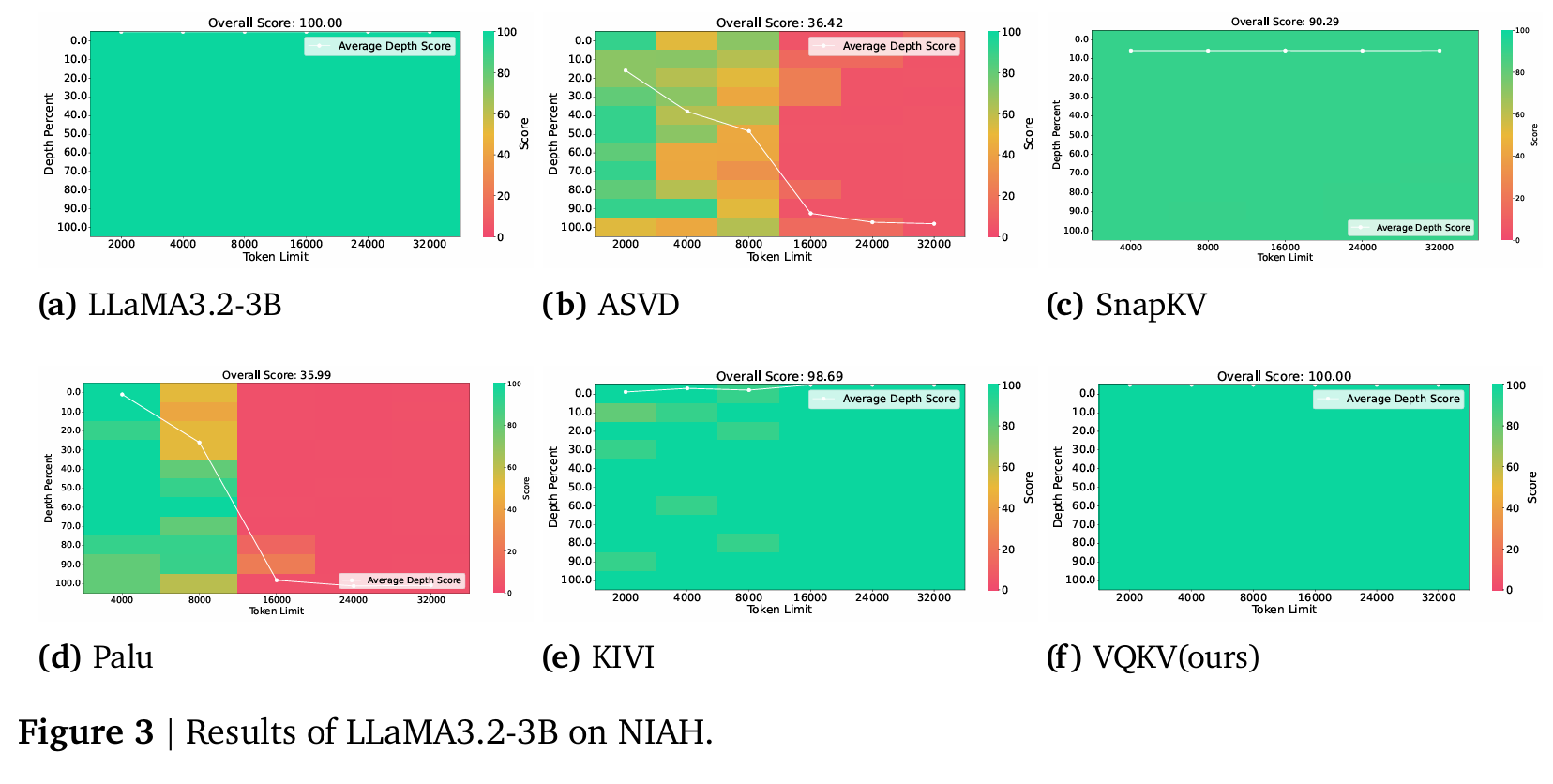
4.2 Needle-In-A-Haystack (NIAH)
NIAH 测试"在长上下文中精准定位特定信息"的能力。VQKV 维持了完美的 100 分,和 full-cache 模型完全一致,而其他所有方法都有明显退化。这说明向量量化在保留精确检索能力上有独特优势。
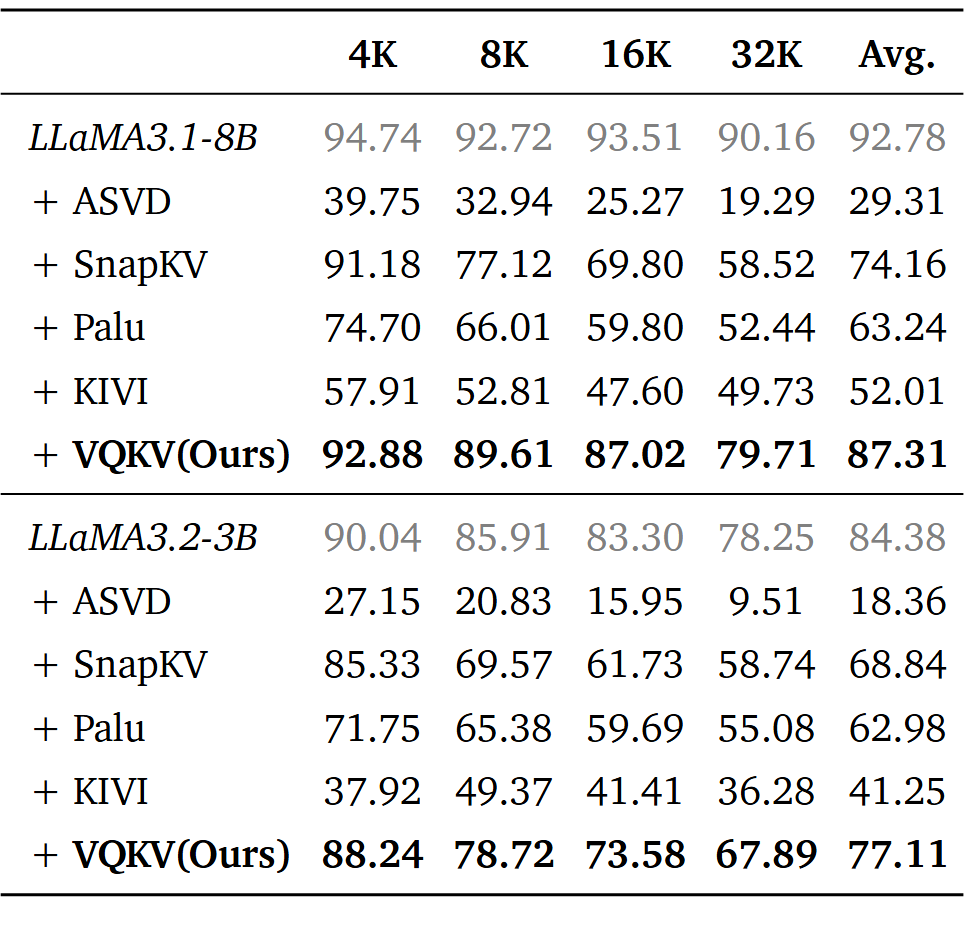
4.3 RULER
在 RULER 长上下文基准上,VQKV 同样大幅领先。随着上下文增长到 32K,其他方法的性能急剧下滑,而 VQKV 仍能保持较高水准:
| 方法 | 4K | 8K | 16K | 32K | 平均 |
|---|---|---|---|---|---|
| Full Cache | 94.74 | 92.72 | 93.51 | 90.16 | 92.78 |
| VQKV | 92.88 | 89.61 | 87.02 | 79.71 | 87.31 |
| SnapKV | 91.18 | 77.12 | 69.80 | 58.52 | 74.16 |
| Palu | 74.70 | 66.01 | 59.80 | 52.44 | 63.24 |
| KIVI | 57.91 | 52.81 | 47.60 | 49.73 | 52.01 |
4.4 高压缩率下的优势
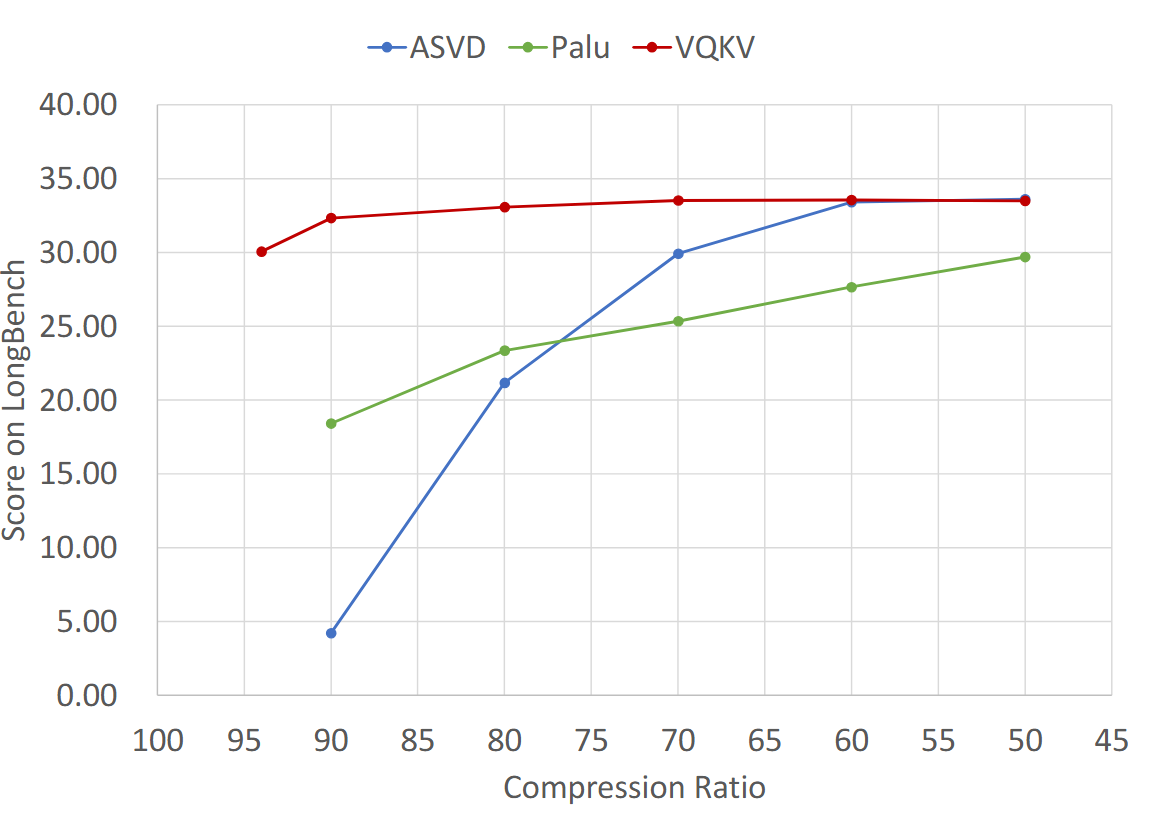
压得越狠,VQKV 的优势越明显。在 LongBench 的不同压缩率对比中:
| 压缩率 | VQKV | ASVD | Palu |
|---|---|---|---|
| 50% | 33.5 | 33.6 | 29.7 |
| 70% | 33.5 | 29.9 | 25.3 |
| 80% | 33.1 | 21.2 | 28.6 |
| 90% | 32.3 | 4.2 | 18.4 |
到 90% 压缩率,ASVD 几乎崩溃(4.2),Palu 也只剩 18.4,而 VQKV 仍维持 32.3。这说明 VQKV 的核心卖点不只是"轻微压缩时不掉点",而是"高压缩比下仍能保住语义骨架"。
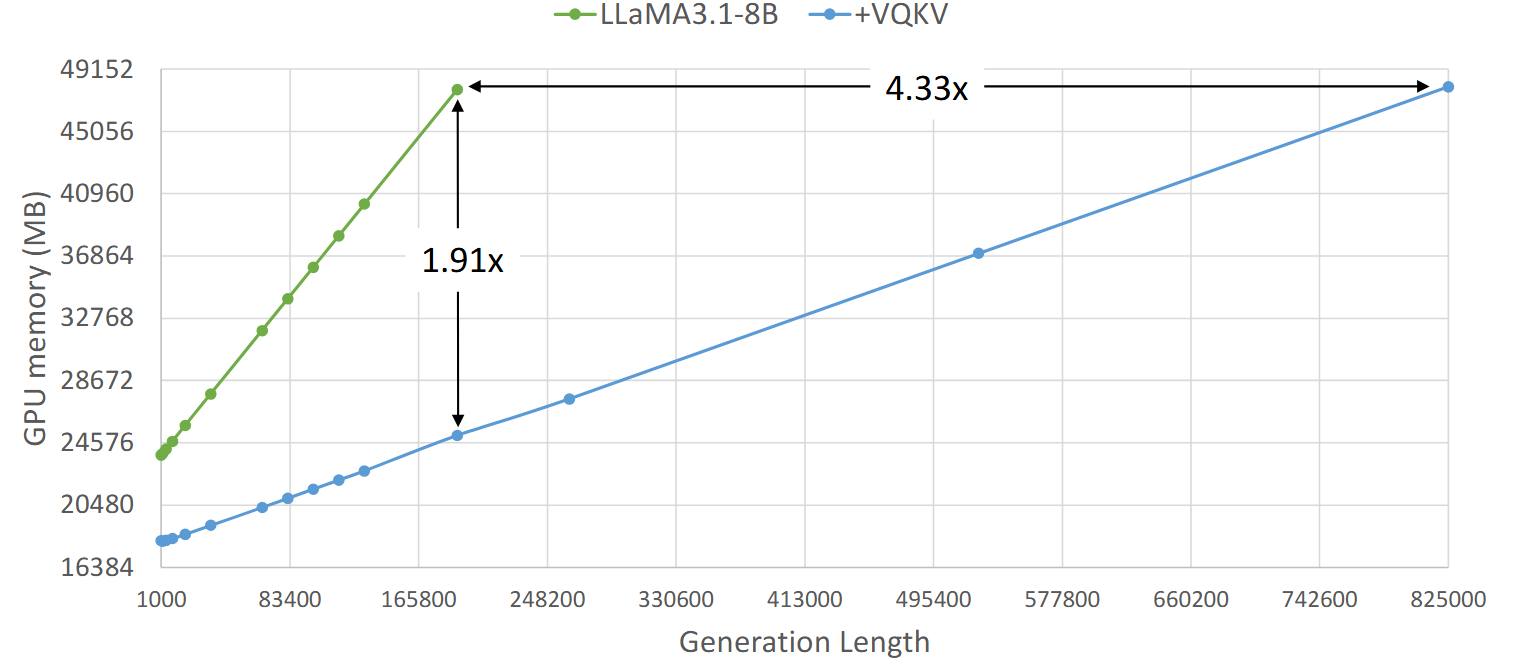
4.5 显存效率
在 RTX 4090 48GB 上的实测:full-cache LLaMA3.1-8B 大约在 190K token 左右 OOM,而 VQKV 能支撑到 824K+ token ,即 4.3 倍以上的可用生成长度。在基线到顶时,VQKV 的显存占用接近只需对方的一半。
五、消融实验
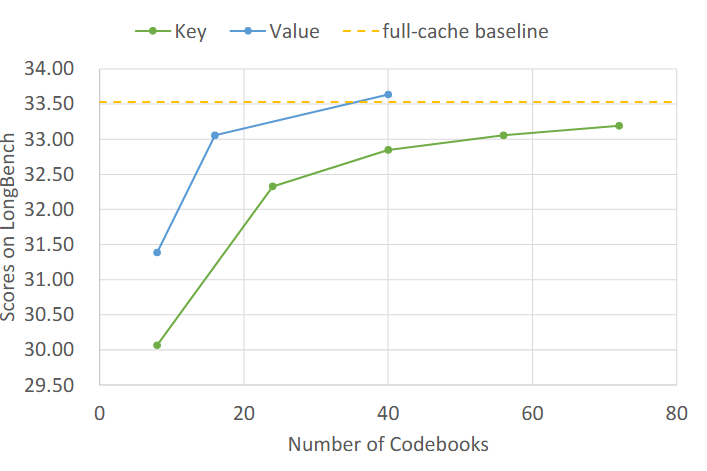
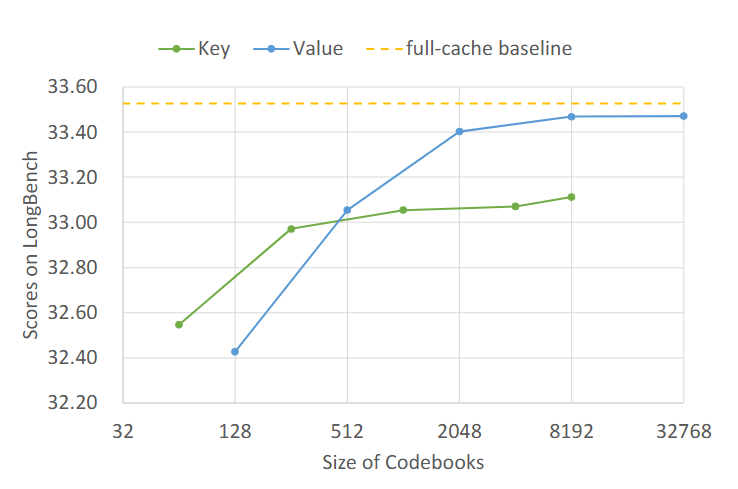
码本配置的消融揭示了两个有趣的规律:
码本数量:增加码本数量能持续提升性能,但收益递减。Key 码本的性能随数量增加平滑上升后趋于饱和,而 value 码本在少量阶段就迅速提升然后快速平台化。
码本大小:放大码本也能带来增益,但同样收益递减。Value 码本在小尺寸时获益更多,key 码本则更平缓。
核心结论:value 码本对配置更敏感,key 码本更稳健。这暗示未来可以做 key/value 非对称的码本设计,给 value 分配更精细的表示预算。
六、局限与展望
论文坦率承认:解码效率仍有改进空间。虽然定制了 Triton kernel 优化时间效率,但 VQ 引入的额外计算开销还没完全解决。
基于论文结果,我认为有几条自然的延伸方向:
- VQ + Token Eviction 分层缓存:中间历史用 VQ 压缩,极久远部分再做 token 筛选
- 动态码本:从全局固定升级为按层/按头/按任务自适应分配码本预算
- Kernel 深度融合:继续做系统层面的优化,否则高压缩虽省显存,解码变慢太多在真实部署中未必划算
七、启发
VQKV 最大的启发是:KV cache 压缩不一定非得在"扔 token"和"降 bit 数"之间二选一。还可以换个角度,把连续向量改写成离散索引,让"共享码本"承担大部分表示能力。真正有价值的,也许不是每个 token 都带着完整拷贝,而是很多 token 共同引用一套高质量"模板库"。
第二个启发是:高压缩不是纯数学问题,而是算法和系统的协同问题。VQKV 之所以成立,不只是因为残差量化本身好用,还因为它同时考虑了 prefill/decoding 分工、局部窗口保留、FlashAttention 按需重建、块级批量量化这些工程细节。很多论文只给"压缩公式",这篇更像是在认真回答"怎么把它跑起来"。