继续小土堆,并且尝试复现大模型项目。
1. 小土堆10/10h
1.1 完整的模型训练套路
新建文件 train.py。
1.1.1 准备并加载数据集
python
import torchvision
from torch import nn
from torch.utils.data import DataLoader
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root='./dataset', train=True, download=True, transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.CIFAR10(root='./dataset', train=False, download=True, transform=torchvision.transforms.ToTensor())
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为{}",format(train_data_size))
print("测试数据集的长度为{}",format(test_data_size))
# 利用 DataLoader 加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
1.1.2 搭建神经网络
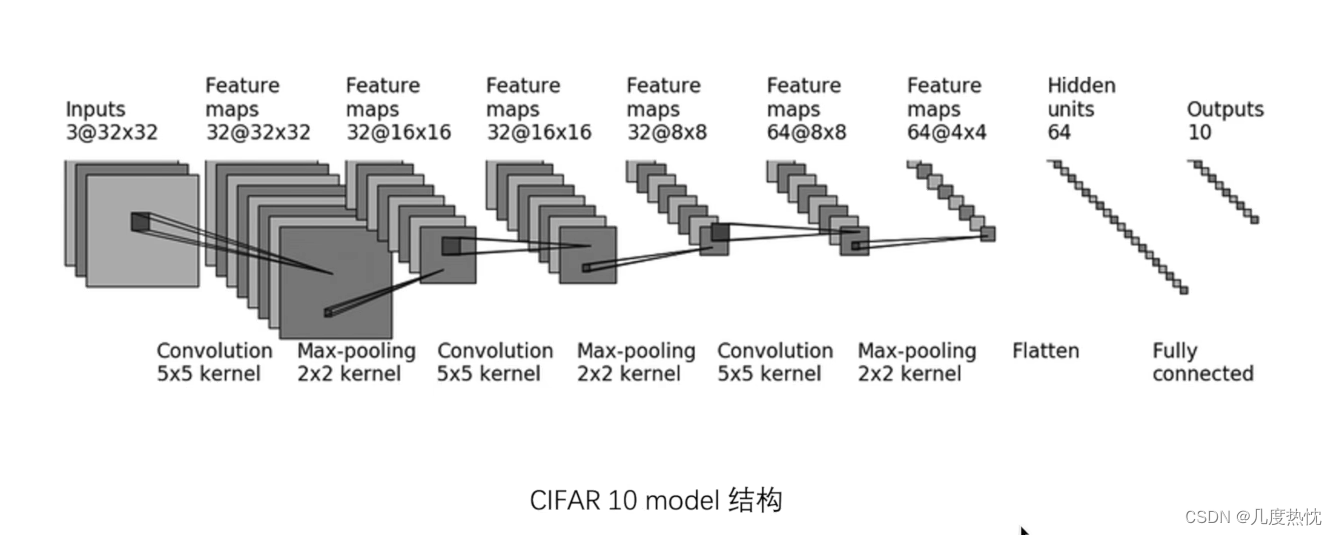
之前已经搭建过,按照这张图去搭建。
一种比较常用的方法是将网络放入单独的python文件里,需要的时候进行引入,所以新建model.py文件。可以直接在这个文件里去测试网络的正确性。
python
import torch
from torch import nn
# 搭建神经网络
class Reina(nn.Module):
def __init__(self):
super(Reina, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(32, 32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(32, 64, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10),
)
def forward(self, x):
x = self.model(x)
return x
if __name__ == '__main__':
reina = Reina()
input = torch.ones(64,3,32,32)
output = reina(input)
print(output.shape)然后引用的其他文件里面在顶部导入,然后直接用。
python
from model import *
# 创建网络模型
reina = Reina()1.1.3 item()函数
新建一个 test.py 文件去进行测试,看一下 loss.item() 和 loss 的区别。
item()函数用于从只包含单个元素的张量中提取Python数值,将张量转换为标量值。
python
import torch
# 创建一个只包含一个元素的张量
tensor = torch.tensor([3.14])
# 使用item()函数获取张量的数值
value = tensor.item()
print("Value extracted using item():", value)
print("Type of extracted value:", type(value))
1.1.4 torch.no_grad()
在推理或评估模型时使用torch.no_grad(),表明当前计算不需要反向传播,使用之后,强制后边的内容不进行计算图的构建
with 语句是 Python 中的一个语法结构,用于包裹代码块的执行,并确保在代码块执行完毕后,能够自动执行一些清理工作。
1.1.5 完整的模型训练与测试套路
python
import torch.optim
import torchvision
from torch import nn
from torch.utils.tensorboard import SummaryWriter
from P8_Tensorboard import writer
from model import *
from torch.utils.data import DataLoader
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root='./dataset', train=True, download=True, transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.CIFAR10(root='./dataset', train=False, download=True, transform=torchvision.transforms.ToTensor())
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为{}".format(train_data_size))
print("测试数据集的长度为{}".format(test_data_size))
# 利用 DataLoader 加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
reina = Reina()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.SGD(reina.parameters(), lr=0.01)
# 设置训练网路的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加 tensorboard
writer = SummaryWriter("logs_train")
for i in range(epoch):
print("-------第{}轮训练开始---------".format(i + 1))
# 训练步骤开始
for data in train_dataloader:
imgs,targets = data
output = reina(imgs)
loss = loss_fn(output, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
print("训练次数:{},Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar('train_loss', loss.item(), total_train_step)
# 测试步骤开始
total_test_loss = 0
with torch.no_grad():
for data in test_dataloader:
imgs,targets = data
output = reina(imgs)
loss = loss_fn(output, targets)
total_test_loss += loss.item()
print("整体测试集上的Loss:{}".format(total_test_loss))
writer.add_scalar('test_loss', total_test_loss, total_test_step)
total_test_step += 1
torch.save(reina.state_dict(), './reina_{}.pth'.format(i))
print("模型已保存")
writer.close()
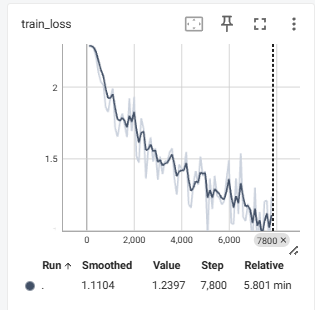
1.1.6 分类问题计算正确率的方法

argmax 是一个数学和编程中常用的术语,它表示找到一个函数或数组中最大值的索引或位置。在 PyTorch 中,torch.argmax 是一个函数,用于返回输入张量(Tensor)中最大值的索引。
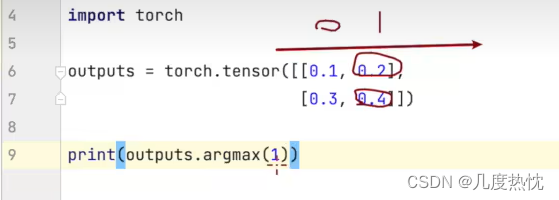

python
import torch
outputs = torch.tensor([[0.1, 0.2],
[0.3, 0.4]])
print(outputs.argmax(1))
preds = outputs.argmax(1)
targets = torch.tensor([0,1])
print(preds == targets)
print((preds == targets).sum())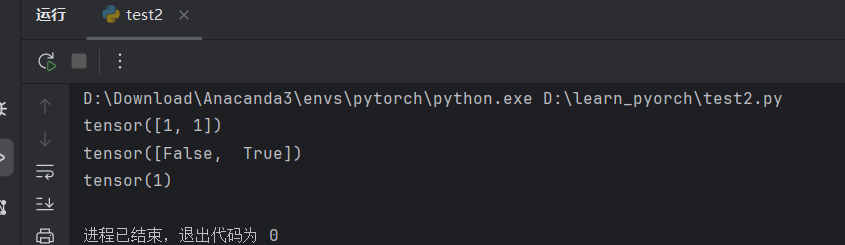
1.1.7 补充正确率代码
python
import torch.optim
import torchvision
from torch import nn
from torch.utils.tensorboard import SummaryWriter
from P8_Tensorboard import writer
from model import *
from torch.utils.data import DataLoader
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root='./dataset', train=True, download=True, transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.CIFAR10(root='./dataset', train=False, download=True, transform=torchvision.transforms.ToTensor())
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为{}".format(train_data_size))
print("测试数据集的长度为{}".format(test_data_size))
# 利用 DataLoader 加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
reina = Reina()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.SGD(reina.parameters(), lr=0.01)
# 设置训练网路的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加 tensorboard
writer = SummaryWriter("logs_train")
for i in range(epoch):
print("-------第{}轮训练开始---------".format(i + 1))
# 训练步骤开始
reina.train()
for data in train_dataloader:
imgs,targets = data
output = reina(imgs)
loss = loss_fn(output, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
print("训练次数:{},Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar('train_loss', loss.item(), total_train_step)
# 测试步骤开始
reina.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs,targets = data
output = reina(imgs)
loss = loss_fn(output, targets)
total_test_loss += loss.item()
accuracy = (output.argmax(dim=1) == targets).sum()
total_accuracy += accuracy.item()
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/train_data_size))
writer.add_scalar('test_loss', total_test_loss, total_test_step)
writer.add_scalar('test_accuracy', total_accuracy/train_data_size, total_test_step)
total_test_step += 1
torch.save(reina.state_dict(), './reina_{}.pth'.format(i))
print("模型已保存")
writer.close()1.1.8 细节补充:model.train()和model.eval()
**model.train()**开启训练模式,模型会跟踪所有层的梯度,以便在优化器(如 torch.optim.SGD 或 torch.optim.Adam)进行梯度下降时更新模型的权重。此外,train() 方法还会将模型中的某些层(如 BatchNorm 和 Dropout)设置为训练行为。
BatchNorm 层:对于包含 BatchNorm(批量归一化)层的模型,model.train() 确保在训练过程中使用每一批数据来计算层的运行均值和方差。这些运行统计量用于归一化网络的激活值,有助于提高训练的稳定性和性能。
Dropout 层:对于包含 Dropout 层的模型,model.train() 在训练过程中随机选择一部分网络连接进行训练,即"丢弃"一部分神经元的输出。这样做可以防止网络过拟合,因为每次训练时只有一部分神经元被激活,从而增加了模型的泛化能力。
model.eval(): 开启评估模式,在评估模式下,模型不会跟踪梯度,这有助于减少内存消耗并提高计算效率。此外,eval() 方法还会将模型中的某些层(如 BatchNorm 和 Dropout)设置为评估行为,这意味着它们的行为会根据固定的参数进行调整,而不是根据训练数据。
在评估模式(model.eval())下,BatchNorm 层会使用在训练过程中学习到的均值和方差,而不是使用当前批次的数据。
在评估模式下,Dropout 层会被禁用,所有的神经元都会保留其输出,确保评估时的确定性。
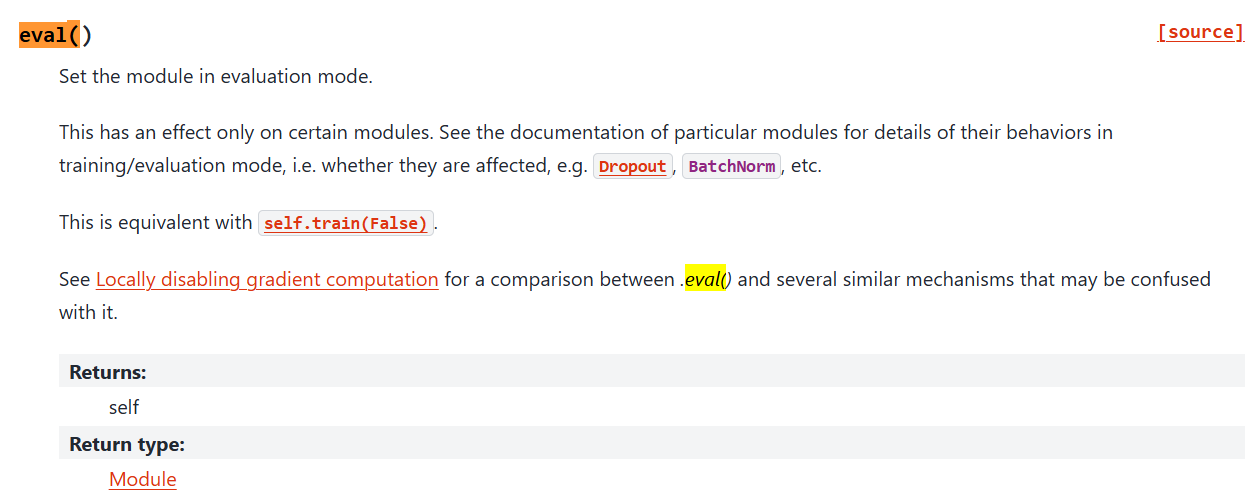
当网络中有这些Dropout、BatchNorm 层时,一定要调用 model.train()和model.eval(),当网络不含这些层时,不进行调用也可以
1.2 利用GPU训练
这里我电脑没有GPU但是有租云服务器,懒得再开一个实例用来跑基础代码,只跟着过一遍关键信息和代码。
1.2.1 使用GPU进行训练方式1 xx = xx.cuda()

训练数据和测试数据都要.cuda()
python
import torch.optim
import torchvision
from torch import nn
from torch.utils.tensorboard import SummaryWriter
# from model import *
from torch.utils.data import DataLoader
import time
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root='./dataset', train=True, download=True, transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.CIFAR10(root='./dataset', train=False, download=True, transform=torchvision.transforms.ToTensor())
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为{}".format(train_data_size))
print("测试数据集的长度为{}".format(test_data_size))
# 利用 DataLoader 加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class Reina(nn.Module):
def __init__(self):
super(Reina, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(32, 32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(32, 64, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10),
)
def forward(self, x):
x = self.model(x)
return x
reina = Reina()
if torch.cuda.is_available():
reina = reina.cuda()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
# 优化器
optimizer = torch.optim.SGD(reina.parameters(), lr=0.01)
# 设置训练网路的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加 tensorboard
writer = SummaryWriter("logs_train")
start_time = time.time()
for i in range(epoch):
print("-------第{}轮训练开始---------".format(i + 1))
# 训练步骤开始
reina.train()
for data in train_dataloader:
imgs,targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
output = reina(imgs)
loss = loss_fn(output, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
end_time = time.time()
print(end_time - start_time)
print("训练次数:{},Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar('train_loss', loss.item(), total_train_step)
# 测试步骤开始
reina.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs,targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
output = reina(imgs)
loss = loss_fn(output, targets)
total_test_loss += loss.item()
accuracy = (output.argmax(dim=1) == targets).sum()
total_accuracy += accuracy.item()
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/train_data_size))
writer.add_scalar('test_loss', total_test_loss, total_test_step)
writer.add_scalar('test_accuracy', total_accuracy/train_data_size, total_test_step)
total_test_step += 1
torch.save(reina.state_dict(), './reina_{}.pth'.format(i))
print("模型已保存")
writer.close()1.2.2 使用GPU进行训练方式2(更常用) xx = xx.to(device)

python
import torch.optim
import torchvision
from torch import nn
from torch.utils.tensorboard import SummaryWriter
# from model import *
from torch.utils.data import DataLoader
import time
# 定义训练的设备 两种写法均可
device = torch.device("cuda")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root='./dataset', train=True, download=True, transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.CIFAR10(root='./dataset', train=False, download=True, transform=torchvision.transforms.ToTensor())
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为{}".format(train_data_size))
print("测试数据集的长度为{}".format(test_data_size))
# 利用 DataLoader 加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class Reina(nn.Module):
def __init__(self):
super(Reina, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(32, 32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(32, 64, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10),
)
def forward(self, x):
x = self.model(x)
return x
reina = Reina()
reina = reina.to(device)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# 优化器
optimizer = torch.optim.SGD(reina.parameters(), lr=0.01)
# 设置训练网路的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加 tensorboard
writer = SummaryWriter("logs_train")
start_time = time.time()
for i in range(epoch):
print("-------第{}轮训练开始---------".format(i + 1))
# 训练步骤开始
reina.train()
for data in train_dataloader:
imgs,targets = data
imgs = imgs.to(device)
targets = targets.to(device)
output = reina(imgs)
loss = loss_fn(output, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
end_time = time.time()
print(end_time - start_time)
print("训练次数:{},Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar('train_loss', loss.item(), total_train_step)
# 测试步骤开始
reina.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs,targets = data
imgs = imgs.to(device)
targets = targets.to(device)
output = reina(imgs)
loss = loss_fn(output, targets)
total_test_loss += loss.item()
accuracy = (output.argmax(dim=1) == targets).sum()
total_accuracy += accuracy.item()
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/train_data_size))
writer.add_scalar('test_loss', total_test_loss, total_test_step)
writer.add_scalar('test_accuracy', total_accuracy/train_data_size, total_test_step)
total_test_step += 1
torch.save(reina.state_dict(), './reina_{}.pth'.format(i))
print("模型已保存")
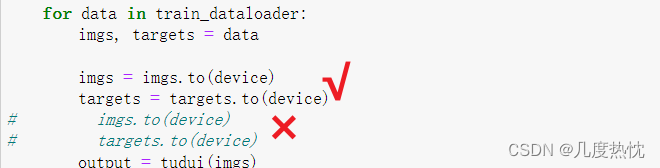
writer.close()**注意:**前面讲的两种在GPU训练方法,其实只有数据和标签(imgs和targets)需要进行 数据 = 数据.cuda() 或者 数据 = 数据.to(device)
模型和损失函数可以直接model.to() ,model.cuda() ,loss.to(),loss.cuda()而无需赋值

1.3 完整的模型验证套路
1.3.1 利用已经训练好的模型 提供输入进行验证
新建文件 verify.py,然后新建一个 imgs 文件,去浏览器照一张狗子照片保存进目录。

python
import torch
from PIL import Image
from torch import nn
from torchvision import transforms
image_path = "imgs/dog.jpg"
image = Image.open(image_path)
print(image)
image = image.convert('RGB') # 格式不同通道数可能会不同
transform = transforms.Compose([transforms.Resize((32,32)),transforms.ToTensor()])
image = transform(image)
print(image.shape)
class Reina(nn.Module):
def __init__(self):
super(Reina, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(32, 32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(32, 64, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10),
)
def forward(self, x):
x = self.model(x)
return x
model = Reina()
state_dict = torch.load("reina_0.pth", map_location=torch.device('cpu'))
model.load_state_dict(state_dict)
print(model)
image = torch.reshape(image,(1,3,32,32))
# model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))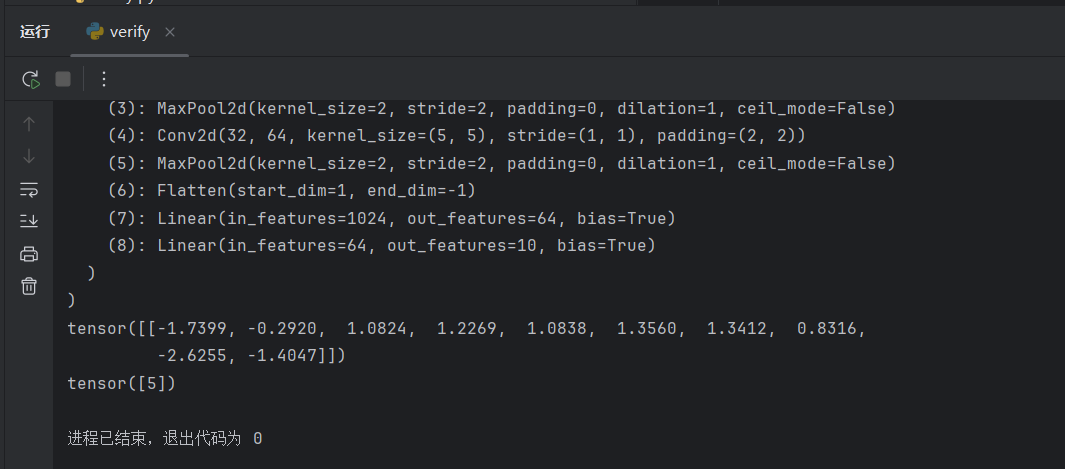
1.3.2 使用gpu训练保存的模型在cpu上使用
python
model = torch.load("XXXX.pth",map_location= torch.device("cpu"))**map_location=torch.device("cpu")**是在使用 PyTorch 的 torch.load 函数加载模型或张量时的一个参数,它用于指定加载数据的目标设备。当你使用这个参数时,你告诉 PyTorch 将加载的数据映射到 CPU 上,而不是默认的 CUDA 设备(如果你的系统上有 GPU)。
撒花!!!土堆跟完了!
然后要记得把学习代码上传仓库备份哟:ReinaKaka/Tudui_pyorch: Study Notes for XiaoTudui's PyTorch Deep Learning for Beginners
2.minimind
然后直接上项目,做攻略看好多人都用这个,先学一下丰富简历吧。
剩下的我再做做功课,今天就先到这里,over!