
👨💻 关于作者:会编程的土豆
"不是因为看见希望才坚持,而是坚持了才看见希望。"
你好,我是会编程的土豆,一名热爱后端技术的Java学习者。
📚 正在更新中的专栏:
-
《数据结构与算法》😊😊😊
-
《leetcode hot 100》🥰🥰🥰🤩🤩🤩
-
《数据库mysql》
💕作者简介:后端学习者
1.
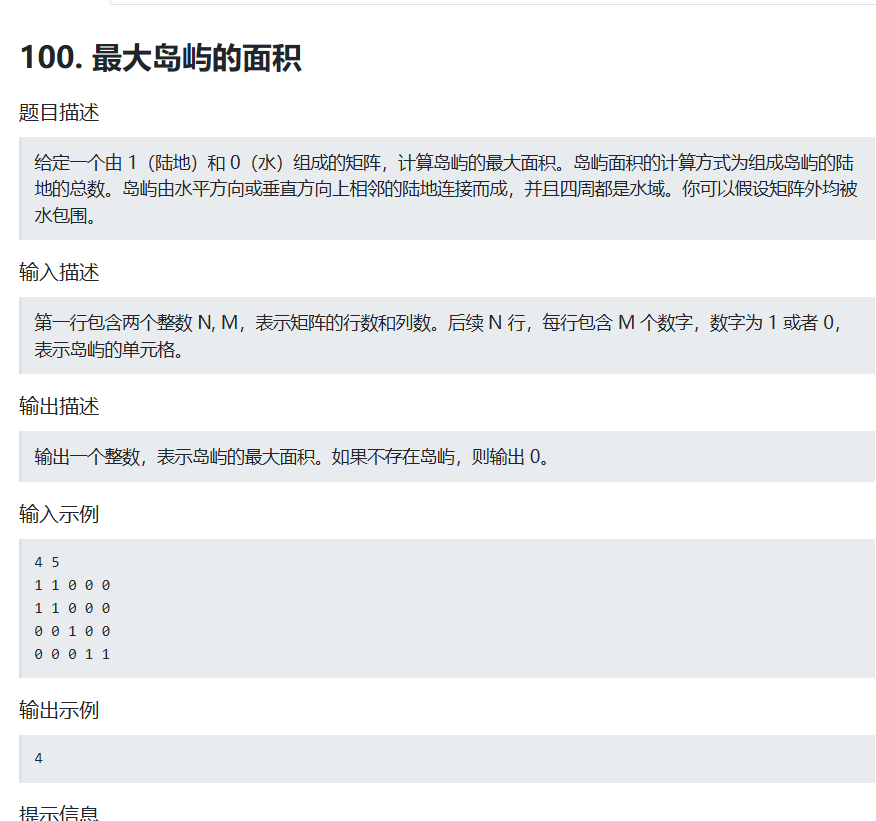
cpp
#include<iostream>
#include<vector>
#include<algorithm>
#include<queue>
using namespace std;
vector<vector<int>>edge;
long long maxn = 0;
long long cur;
int dx[4] = { 1,-1,0,0 };
int dy[4] = { 0,0,1,-1 };
int N, M;
void dfs(int x, int y)
{
for (int i = 0; i < 4; i++)
{
int nx = x + dx[i];
int ny = y + dy[i];
if (nx >= 1 && nx <= N && ny >= 1 && ny <= M && edge[nx][ny] == 1)
{
cur++;
maxn = max(maxn, cur);
edge[nx][ny] = 0;
dfs(nx, ny);
}
}
}
int main()
{
cin >> N >> M;
edge.resize(N + 1, vector<int>(M + 1, 0));
for (int i = 1; i <= N; i++)
{
for (int j = 1; j <= M; j++)
{
cin >> edge[i][j];
}
}
for (int i = 1; i <= N; i++)
{
for (int j = 1; j <= M; j++)
{
if (edge[i][j] == 1)
{
edge[i][j] = 0;
cur = 1;
maxn = max(maxn, cur);
dfs(i, j);
}
}
}
cout << maxn << endl;
return 0;
}从"数岛屿"到"最大岛屿面积":DFS 进阶一篇讲透(附代码细节分析)
很多同学做到"岛屿数量"就停了,但其实更经典的一道题是:
在一个二维网格中,求最大连通块的面积
你这段代码已经写到了这个进阶版本,这篇文章我们就把它彻底讲清楚。
一、问题本质
给你一个 N × M 的网格:
-
1表示陆地 -
0表示水
要求:
找出最大的"岛屿面积"(连续的1的数量)举个例子
1 1 0
1 0 0
0 1 1这里:
-
左上角岛:面积 = 3
-
右下角岛:面积 = 2
答案:
3二、核心思路(非常重要)
相比"数岛屿",这里只多了一步:
每找到一个岛 → 统计它的大小 → 更新最大值三、变量含义解释
你的代码中有两个关键变量:
long long maxn = 0; // 最大岛屿面积
long long cur; // 当前岛屿面积四、DFS 核心逻辑
来看你的 DFS:
void dfs(int x, int y)
{
for (int i = 0; i < 4; i++)
{
int nx = x + dx[i];
int ny = y + dy[i];
if (nx >= 1 && nx <= N && ny >= 1 && ny <= M && edge[nx][ny] == 1)
{
cur++;
maxn = max(maxn, cur);
edge[nx][ny] = 0;
dfs(nx, ny);
}
}
}五、DFS 在干什么?
一句话总结:
从一个点出发,把整个岛屿遍历一遍,同时统计大小执行流程
-
遇到一个新的 1(岛屿起点)
-
cur = 1(当前面积从1开始) -
DFS 扩展:
- 每找到一个 1 →
cur++
- 每找到一个 1 →
-
同时更新最大值
六、主函数逻辑
if (edge[i][j] == 1)
{
edge[i][j] = 0;
cur = 1;
maxn = max(maxn, cur);
dfs(i, j);
}逻辑解释
发现一个新岛:
→ 初始化面积 cur = 1
→ DFS 扩展整个岛
→ 更新最大值七、一个关键优化点(更推荐写法)
你现在的写法是:
cur++;
maxn = max(maxn, cur);其实可以更清晰一点:
推荐写法:DFS返回面积
int dfs(int x, int y)
{
int area = 1; // 当前节点算1
for (int i = 0; i < 4; i++)
{
int nx = x + dx[i];
int ny = y + dy[i];
if (nx >= 1 && nx <= N && ny >= 1 && ny <= M && edge[nx][ny] == 1)
{
edge[nx][ny] = 0;
area += dfs(nx, ny);
}
}
return area;
}主函数写法
if (edge[i][j] == 1)
{
edge[i][j] = 0;
int area = dfs(i, j);
maxn = max(maxn, area);
}为什么更好?
逻辑更清晰:一个函数只干一件事 → 返回面积
避免全局变量混乱
更符合面试写法八、时间复杂度
O(N × M)原因:
- 每个点最多访问一次
九、空间复杂度
最坏 O(N × M)原因:
- 递归栈可能很深(全是1的情况)
十、常见错误
1. 忘记标记访问
edge[nx][ny] = 0;否则会无限递归。
2. cur 没初始化
cur = 1;3. 起点没处理
edge[i][j] = 0;必须在 DFS 前做。
十一、DFS vs BFS 做这个题
| 方法 | 思路 | 推荐程度 |
|---|---|---|
| DFS | 递归扩展 | 简单直观 |
| BFS | 队列扩展 | 更稳定(防爆栈) |
十二、一句话总结
这道题的本质就是:用 DFS 找连通块,同时统计每个连通块的大小,取最大值
2.
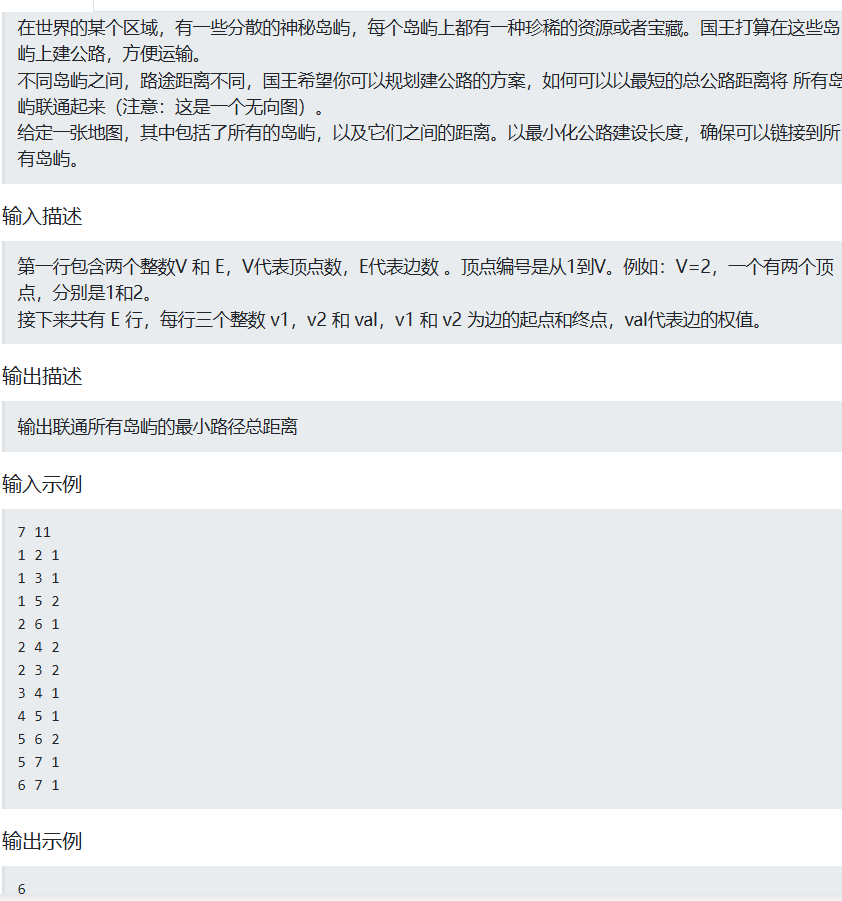
cpp
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
typedef struct node {
int u, v, w;
}node;
vector<node>edge;
vector<int>parent;
bool f(node a, node b)
{
return a.w < b.w;
}
int find(int x)
{
if (parent[x] != x)
{
parent[x] = find(parent[x]);
}
return parent[x];
}
int main()
{
int V, E;
cin >> V >> E;
parent.resize(V + 1);
for (int i = 1; i <= V; i++)
{
parent[i] = i;
}
for (int i = 0; i < E; i++)
{
int u, v, w;
cin >> u >> v >> w;
edge.push_back({ u,v,w });
}
sort(edge.begin(), edge.end(), f);
long long sum = 0;
long long use = 0;
for (int i = 0; i < edge.size(); i++)
{
int u = edge[i].u;
int v = edge[i].v;
int w = edge[i].w;
int rootu = find(u);
int rootv = find(v);
if (rootu != rootv)
{
parent[rootu] = rootv;
sum += w;
use++;
if (use == V-1) break;
}
}
cout << sum << endl;
return 0;
}Kruskal算法从入门到实战:最小生成树一篇彻底讲明白(附完整代码)
最小生成树(MST)是图论里非常核心的一块内容,而 Kruskal算法 是最经典、最适合入门的一种解法。
你这份代码已经是一个标准模板级写法了,这篇文章我帮你整理成一篇可以直接发 CSDN 的高质量版本,从思路到代码彻底讲清楚。
一、问题背景:什么是最小生成树
给你一个无向图:
-
有 V 个点
-
有 E 条边,每条边有权值
要求:
选出若干条边,使所有点连通,并且总权值最小核心特点
1. 必须连通所有点
2. 不能有环
3. 边数一定是 V - 1二、Kruskal算法核心思想
一句话理解:
从小到大选边,只要不形成环就加入为什么可行?
因为:
每次都选当前最小的边(贪心)
并用并查集保证不会成环三、代码结构解析
我们一步一步拆代码。
1. 边结构体
typedef struct node {
int u, v, w;
} node;表示一条边:
u → v,权值 w2. 排序(关键一步)
bool f(node a, node b)
{
return a.w < b.w;
}
sort(edge.begin(), edge.end(), f);作用:
按边权从小到大排序3. 并查集初始化
parent.resize(V + 1);
for (int i = 1; i <= V; i++)
{
parent[i] = i;
}含义:
每个点一开始是独立集合4. find函数(路径压缩)
int find(int x)
{
if (parent[x] != x)
{
parent[x] = find(parent[x]);
}
return parent[x];
}作用:
查找集合的根节点,并压缩路径四、Kruskal核心流程
for (int i = 0; i < edge.size(); i++)
{
int u = edge[i].u;
int v = edge[i].v;
int w = edge[i].w;
int rootu = find(u);
int rootv = find(v);
if (rootu != rootv)
{
parent[rootu] = rootv;
sum += w;
use++;
if (use == V - 1) break;
}
}逻辑解释
情况1:不在同一集合
可以连 → 不会成环操作:
合并集合 + 加入权值情况2:在同一集合
跳过 → 否则会形成环五、为什么一定是 V - 1 条边?
树的性质:n个点的最小连通结构一定有 n-1 条边所以:
if (use == V - 1) break;这是一个关键优化:
-
提前结束
-
避免不必要计算