本篇导读
上一篇我们实现了一个能编码 / 解码训练文本的分词器,但它有个致命缺陷------遇到训练集里没出现过的词就会直接报错。这就像一个只认得 1,159 个字的人,第 1,160 个字对他来说就是一片空白。
现实世界中新词层出不穷:
- 人名、地名、品牌名
- 新造词、俚语、网络热词
- 专业术语、外语词汇
- 拼写变体、打字错误
本篇将介绍两种彻底解决未知词问题的思路:
- 方案一:特殊 Token --- 用占位符
<|unk|>标记所有未知词(简单但粗糙) - 方案二:BPE 字节对编码 --- 把未知词拆分成已知子词(GPT 系列使用的方案)
同时还会引入另一个重要的特殊 Token <|endoftext|>,用于标记文档边界。
1、特殊 Token --- 用占位符处理未知词
思路:给分词器一个"兜底"选项
既然未知词是避免不了的,那就干脆给它一个统一的占位符。我们在词汇表里增加两个特殊 Token:
| 特殊 Token | 用途 |
|---|---|
| `< | unk |
| `< | endoftext |
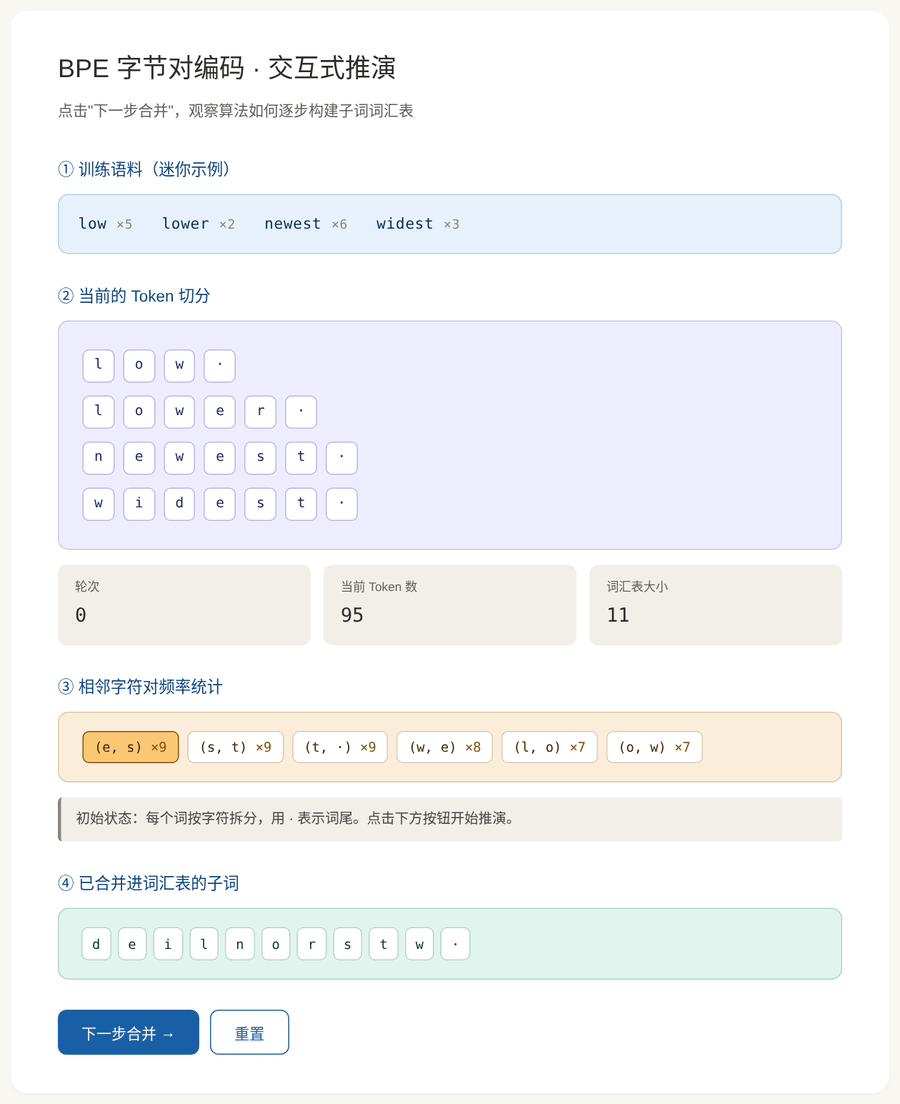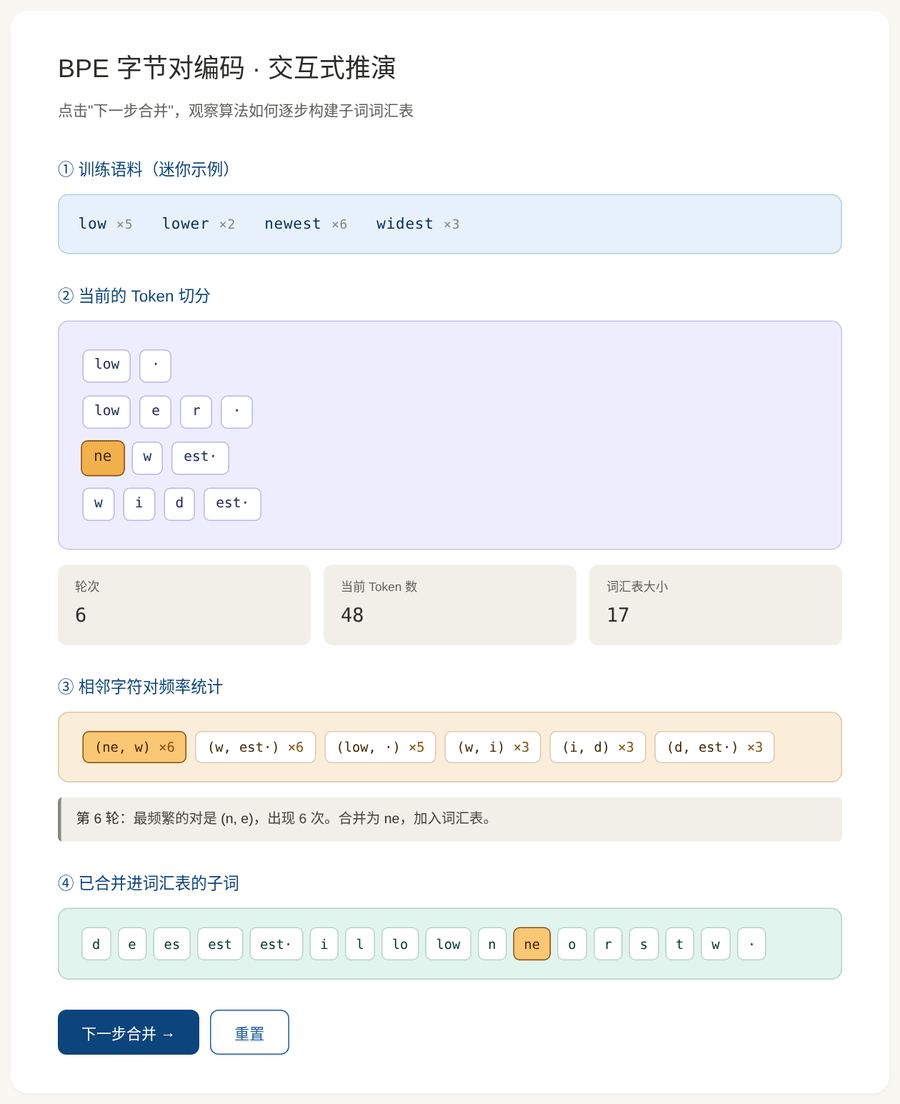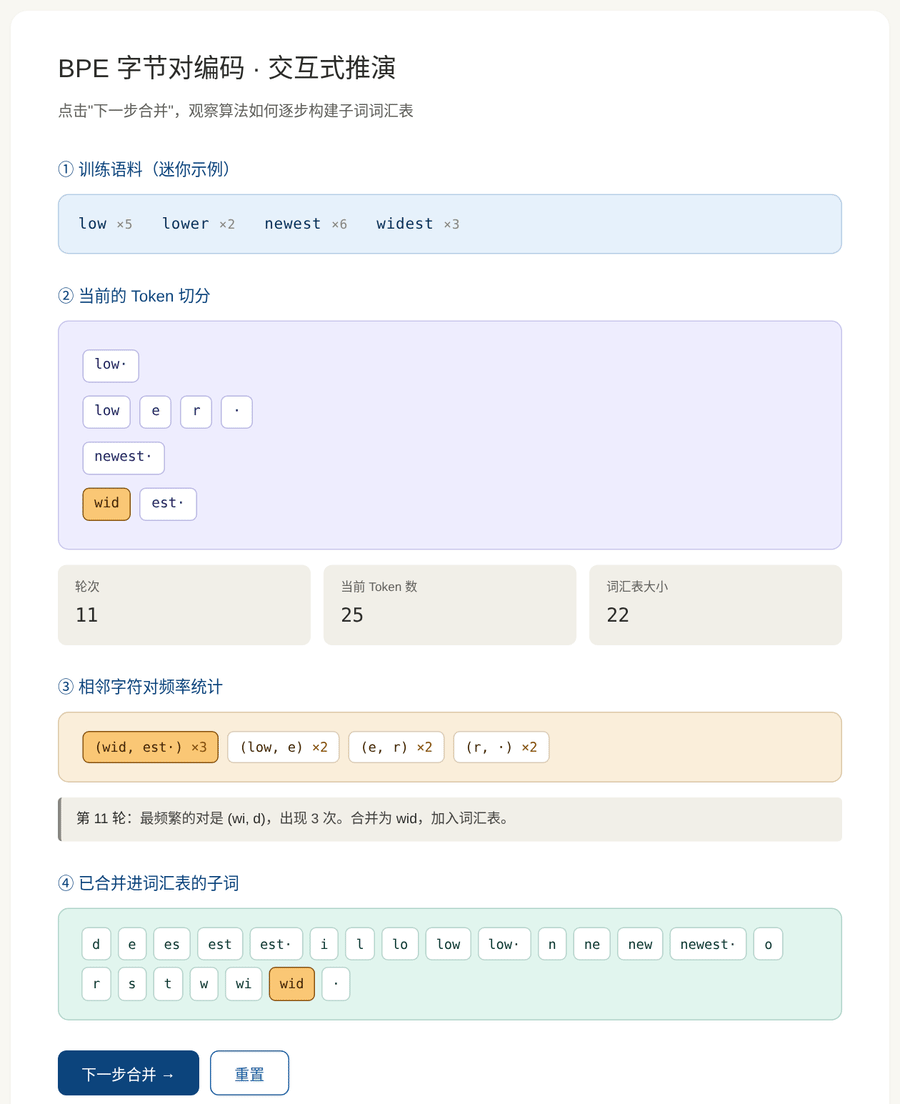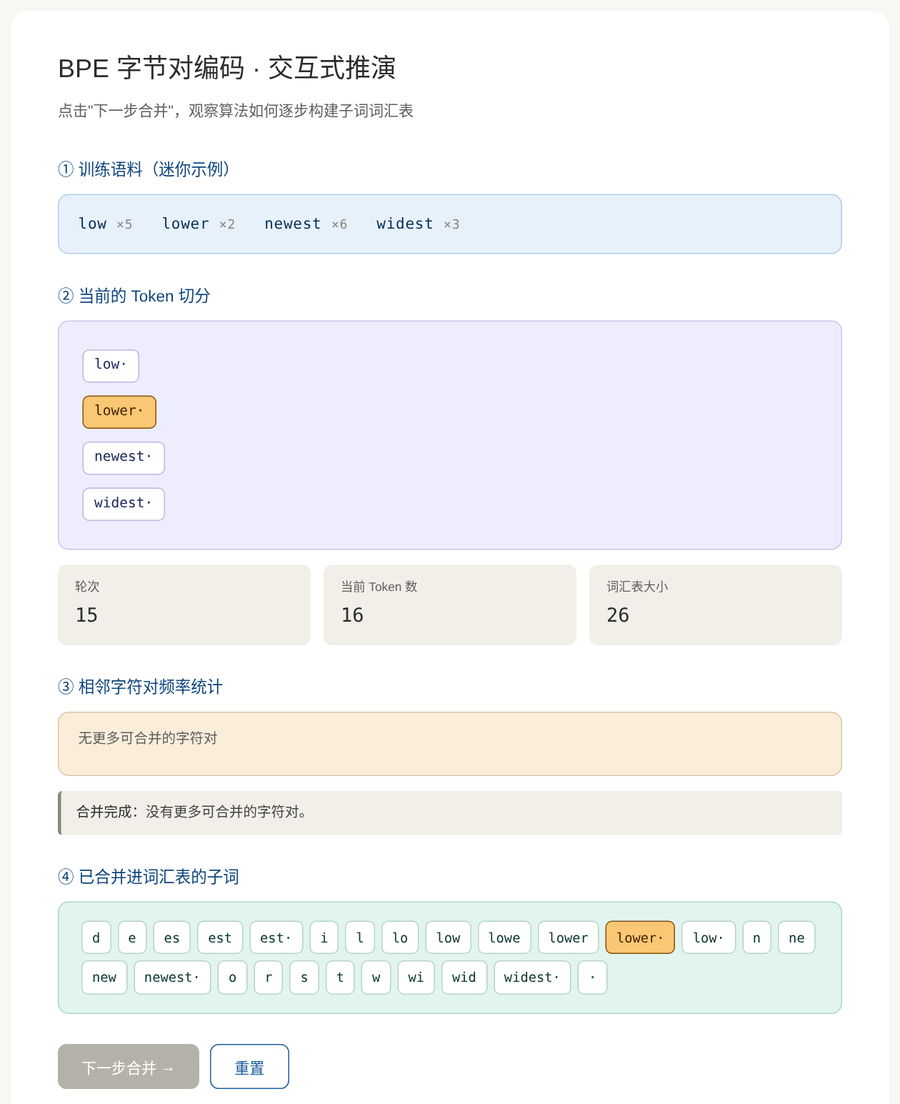
图 1:特殊 Token 方案和 BPE 子词方案的对比。前者简单但丢失信息,后者能完美还原任何词。
为什么需要 <|endoftext|>?
训练 LLM 时,我们通常会把大量独立文档拼接成一个长序列来喂给模型。但这里有个问题:如果不加分隔,模型会误以为第二篇文档是第一篇的延续,从而学到错误的上下文关联。
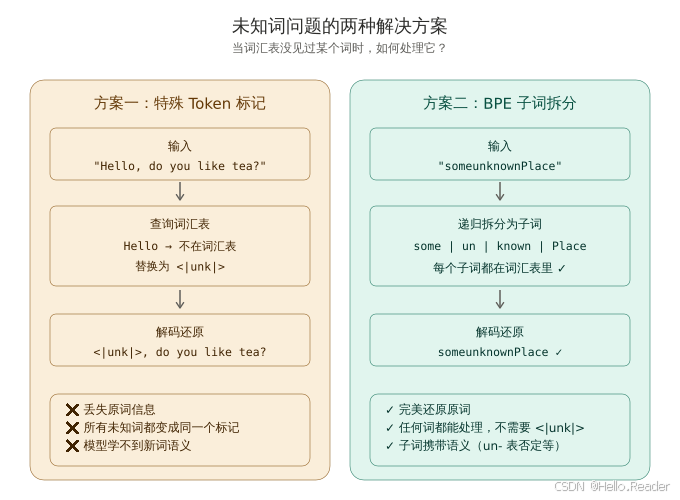
图 2:训练时,用 <|endoftext|> 拼接两个不相关的文档。这个特殊 Token 明确告诉模型:边界在这里,前后内容没有关联。
代码实现:扩展词汇表
在上一篇的 preprocessed 列表基础上,我们加入两个特殊 Token:
python
all_tokens = sorted(list(set(preprocessed)))
all_tokens.extend(["<|endoftext|>", "<|unk|>"])
vocab = {token: integer for integer, token in enumerate(all_tokens)}
print(len(vocab.items())) # 1161(原来 1159 + 新增 2 个)查看词汇表的最后 5 个条目:
python
for i, item in enumerate(list(vocab.items())[-5:]):
print(item)输出:
('younger', 1156)
('your', 1157)
('yourself', 1158)
('<|endoftext|>', 1159)
('<|unk|>', 1160)两个新 Token 已经成功加入。
升级版分词器:SimpleTokenizerV2
改造 encode 方法------遇到词汇表里没有的词,就替换为 <|unk|>:
python
class SimpleTokenizerV2:
def __init__(self, vocab):
self.str_to_int = vocab
self.int_to_str = {i: s for s, i in vocab.items()}
def encode(self, text):
preprocessed = re.split(r'([,.?_!"()\']|--|\s)', text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
# 关键改动:未知词替换为 <|unk|>
preprocessed = [item if item in self.str_to_int else "<|unk|>"
for item in preprocessed]
ids = [self.str_to_int[s] for s in preprocessed]
return ids
def decode(self, ids):
text = " ".join([self.int_to_str[i] for i in ids])
text = re.sub(r'\s+([,.?!"()\'])', r'\1', text)
return text实测
用两段独立的文本拼接起来,中间用 <|endoftext|> 分隔:
python
text1 = "Hello, do you like tea?"
text2 = "In the sunlit terraces of the palace."
text = " <|endoftext|> ".join((text1, text2))
print(text)
# 'Hello, do you like tea? <|endoftext|> In the sunlit terraces of the palace.'编码:
python
tokenizer = SimpleTokenizerV2(vocab)
print(tokenizer.encode(text))
# [1160, 5, 362, 1155, 642, 1000, 10, 1159, 57, 1013, 981, 1009, 738, 1013, 1160, 7]注意观察:
1160出现了两次------分别对应 "Hello" 和 "palace"(训练集里没有的词)1159出现一次------对应<|endoftext|>分隔符
解码回去:
python
print(tokenizer.decode(tokenizer.encode(text)))
# '<|unk|>, do you like tea? <|endoftext|> In the sunlit terraces of the <|unk|>.'问题出现了 :原文是 Hello 和 palace,解码后都变成了 <|unk|>。原始信息彻底丢失了。
这就是特殊 Token 方案的致命缺陷:所有未知词都被压缩成同一个占位符,模型无法区分 "Hello" 和 "palace",更学不到它们的语义。
其他常见的特殊 Token
不同的 LLM 使用不同的特殊 Token 体系:
| Token | 含义 |
|---|---|
[BOS] |
序列开始(beginning of sequence) |
[EOS] |
序列结束(end of sequence),类似 `< |
[PAD] |
填充 Token,用于把不同长度的输入对齐到同一长度 |
GPT 系列的做法 :只使用 <|endoftext|> 一个 Token,同时充当序列边界和填充标记。至于未知词,GPT 根本不用 <|unk|>------它采用了下面要讲的 BPE 方案。
2、BPE 字节对编码 --- 从根本上消除未知词
核心思想
BPE(Byte Pair Encoding)的思路非常巧妙:
与其给未知词打标签,不如把它拆成已知的零件。
就像乐高积木------你可能没见过"宇宙飞船"这个完整模型,但只要你认得单个砖块,就能拼出任何东西。
对于 "someunknownPlace" 这样的陌生词,BPE 会拆分成:
some | un | known | Place每个子词都在词汇表里,所以能被正确编码,也能被完美还原。
BPE 的构建算法
BPE 词汇表是通过一个迭代合并算法自动构建的。过程如下:
初始化:把每个词按字符拆开,词汇表就是所有单字符。
迭代步骤:
- 统计所有相邻字符对的出现频率
- 找到频率最高的那一对
- 把它们合并成一个新的子词,加入词汇表
- 回到步骤 1,直到达到预设的词汇表大小
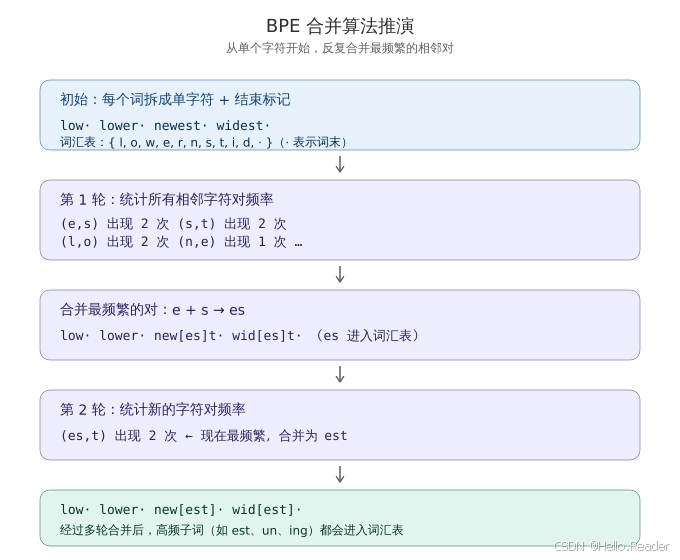
图 3:BPE 合并过程的完整推演。从单字符开始,每轮合并最频繁的相邻对,直到构建出子词词汇表。
频率统计的公式
对于语料 C = { w 1 , w 2 , . . . , w n } C = \{w_1, w_2, ..., w_n\} C={w1,w2,...,wn},其中每个词 w i w_i wi 有出现次数 c i c_i ci,则字符对 ( a , b ) (a, b) (a,b) 的频率为:
freq ( a , b ) = ∑ i = 1 n c i ⋅ 1 ( a , b ) ∈ pairs ( w i ) \text{freq}(a, b) = \sum_{i=1}^{n} c_i \cdot \mathbb{1}(a, b) \\in \\text{pairs}(w_i) freq(a,b)=i=1∑nci⋅1(a,b)∈pairs(wi)
其中 1 ⋅ \mathbb{1}\\cdot 1⋅ 是指示函数(括号里条件成立为 1,否则为 0), pairs ( w i ) \text{pairs}(w_i) pairs(wi) 是词 w i w_i wi 中所有相邻字符对的集合。
具体推演一轮合并
假设语料里有四个词及其出现次数:
low ×5 lower ×2
newest ×6 widest ×3初始拆分 (每个词拆成字符 + 结束标记 ·):
l o w · (重复 5 次)
l o w e r · (重复 2 次)
n e w e s t · (重复 6 次)
w i d e s t · (重复 3 次)统计关键字符对的频率:
| 字符对 | 频率计算 | 频率 |
|---|---|---|
| (e, s) | 出现在 newest 和 widest 里 → 6 + 3 |
9 |
| (s, t) | 同样在 newest 和 widest 里 → 6 + 3 |
9 |
| (l, o) | 在 low 和 lower 里 → 5 + 2 |
7 |
| (o, w) | 在 low 和 lower 里 → 5 + 2 |
7 |
| (w, e) | 只在 newest 里 → 6 |
6 |
| (n, e) | 只在 newest 里 → 6 |
6 |
最频繁的是 (e, s),频率 9。合并!
合并后:
l o w ·
l o w e r ·
n e w [es] t ·
w i d [es] t ·词汇表新增子词 es。
下一轮 :现在 (es, t) 的频率变成 9(在 newest 和 widest 里),成为最频繁------合并为 est。再下一轮 (l, o) 会被合并为 lo......
经过几千到几万轮迭代后,就得到了一个完整的 BPE 词汇表。
🎮 动手体验:交互式 BPE 推演
为了让这个过程更直观,我做了一个交互式动画。你可以点击"下一步合并"按钮,一步步观察:
- 当前的 Token 切分状态
- 所有相邻字符对的频率
- 最频繁的那一对(高亮)被合并
- 词汇表逐步扩大
打开后你会看到四个区域:
- 训练语料:一个迷你的示例语料(四个词及其频率)
- 当前 Token 切分:每个词被切成哪些 Token
- 字符对频率:实时统计,频率最高的那个会被高亮
- 词汇表:已经进入词汇表的子词,新加入的会被高亮
每按一次"下一步合并",你就完整地走过一轮算法。建议至少点 10 次感受一下。
用 tiktoken 库实战
实际使用中,我们不用自己实现 BPE------OpenAI 开源了 tiktoken 库(底层用 Rust 写的,非常高效)。安装:
bash
pip install tiktoken加载 GPT-2 使用的 BPE 分词器:
python
import tiktoken
tokenizer = tiktoken.get_encoding("gpt2")测试一段混合了未知词和特殊 Token 的文本:
python
text = "Hello, do you like tea? <|endoftext|> In the sunlit terraces of someunknownPlace."
integers = tokenizer.encode(text, allowed_special={"<|endoftext|>"})
print(integers)
# [15496, 11, 466, 345, 588, 8887, 30, 220, 50256, 554, 262, 4252, 18250, 8812, 2114, 286, 617, 34680, 27271, 13]几个关键观察:
<|endoftext|>的 ID 是 50256------这是 GPT-2 词汇表的倒数第一个位置- 词汇表总大小是 50,257(ID 从 0 到 50256)
someunknownPlace这个完全虚构的词被正确编码了------没有报错
解码验证:
python
print(tokenizer.decode(integers))
# 'Hello, do you like tea? <|endoftext|> In the sunlit terraces of someunknownPlace.'完美还原!包括那个虚构的词。
为什么 GPT 选择 BPE?
对比两种方案:
| 维度 | 特殊 Token (<|unk|>) | BPE 子词拆分 |
|---|---|---|
| 未知词处理 | 压缩成一个统一标记 | 拆分成已知子词 |
| 信息保留 | ❌ 完全丢失原词 | ✓ 完美还原 |
| 语义学习 | ❌ 所有未知词看起来一样 | ✓ 子词携带语义(前缀/后缀/词根) |
| 词汇表大小 | 受训练数据限制 | 可灵活控制(GPT-2 是 50,257) |
| 跨语言支持 | 差 | 好(字符级兜底) |
GPT 选择 BPE 的根本原因:它在"词级精度"和"字符级覆盖"之间找到了最佳平衡点。
- 高频词(如
the、and)保持完整 - 低频复合词被拆成有意义的子词(
un+known+Place) - 极端罕见的字符串被拆到单字符级别
这样模型既不会被数不清的长尾词淹没,又能处理任何输入。
一个有趣的练习
试试用 BPE 编码一个完全随机的字符串:
python
tokens = tokenizer.encode("Akwirw ier")
print(tokens)
# [32, 74, 86, 343, 86, 220, 959]
# 查看每个 Token 对应什么
for t in tokens:
print(t, "→", tokenizer.decode([t]))
# 32 → A
# 74 → k
# 86 → w
# 343 → ir
# 86 → w
# 220 → (空格)
# 959 → ier
# 重新解码整体
print(tokenizer.decode(tokens))
# 'Akwirw ier'可以看到 BPE 把这个"外星词"拆成了 7 个子词(有的是单字符 A、k、w,有的是子词 ir、ier),然后完美还原。
本篇小结
| 概念 | 要点 |
|---|---|
| 未知词问题 | 固定词汇表总会遇到训练集外的新词,需要兜底机制 |
| 特殊 Token 方案 | 用 `< |
| `< | endoftext |
| BPE 核心思想 | 把未知词拆分成已知子词(乐高积木式) |
| BPE 构建算法 | 迭代合并最频繁的相邻字符对 |
| GPT-2 词汇表 | 50,257 个 Token,最后一个是 `< |
| BPE 的优势 | 完美还原 + 子词携带语义 + 跨语言友好 |
| tiktoken | OpenAI 开源的高效 BPE 实现 |
3、关键公式回顾
字符对频率:
freq ( a , b ) = ∑ i = 1 n c i ⋅ 1 ( a , b ) ∈ pairs ( w i ) \text{freq}(a, b) = \sum_{i=1}^{n} c_i \cdot \mathbb{1}(a, b) \\in \\text{pairs}(w_i) freq(a,b)=i=1∑nci⋅1(a,b)∈pairs(wi)
BPE 每一轮的更新规则:
vocab t + 1 = vocab t ∪ { arg max ( a , b ) freq ( a , b ) } \text{vocab}_{t+1} = \text{vocab}t \cup \{ \arg\max{(a,b)} \text{freq}(a, b) \} vocabt+1=vocabt∪{arg(a,b)maxfreq(a,b)}
即:每一轮把频率最高的那对字符合并,加入词汇表。
4、预习思考
- 如果一个词被 BPE 拆成了 5 个子词,那么这个词在嵌入层里会对应几个向量?这对模型有什么影响?
- BPE 的"频率阈值"决定了词汇表大小。如果阈值设得很低(允许更多合并),词汇表会变大还是变小?每个词的 Token 数会变多还是变少?
- 中文和英文的分词差异很大------中文的"字"本身就是最小单位。BPE 在中文上会怎么表现?