文章目录
- [1. C/C++内存布局的验证](#1. C/C++内存布局的验证)
- [2. 虚拟地址的引入](#2. 虚拟地址的引入)
- [3. 进程地址空间的引入](#3. 进程地址空间的引入)
- [4. 解决历史遗留问题](#4. 解决历史遗留问题)
- [5. 什么是进程地址空间,如何理解?](#5. 什么是进程地址空间,如何理解?)
- [6. 如何理解空间中的区域划分?](#6. 如何理解空间中的区域划分?)
- [7. 看看源码](#7. 看看源码)
- [8. 补充](#8. 补充)
- [9. 为什么要有进程地址空间?](#9. 为什么要有进程地址空间?)
-
- [9.1 安全](#9.1 安全)
- [9.2 按需分配与惰性加载](#9.2 按需分配与惰性加载)
- [9.3 有序](#9.3 有序)
- [9.4 解耦](#9.4 解耦)
- [10. 进程地址空间的组织方式](#10. 进程地址空间的组织方式)
- [11. 虚拟内存块的管理](#11. 虚拟内存块的管理)
1. C/C++内存布局的验证
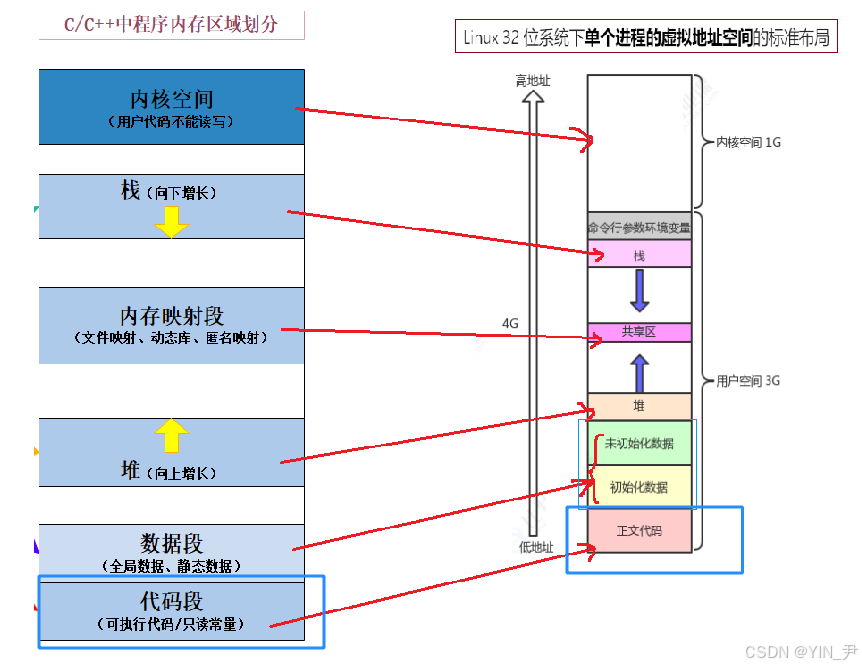
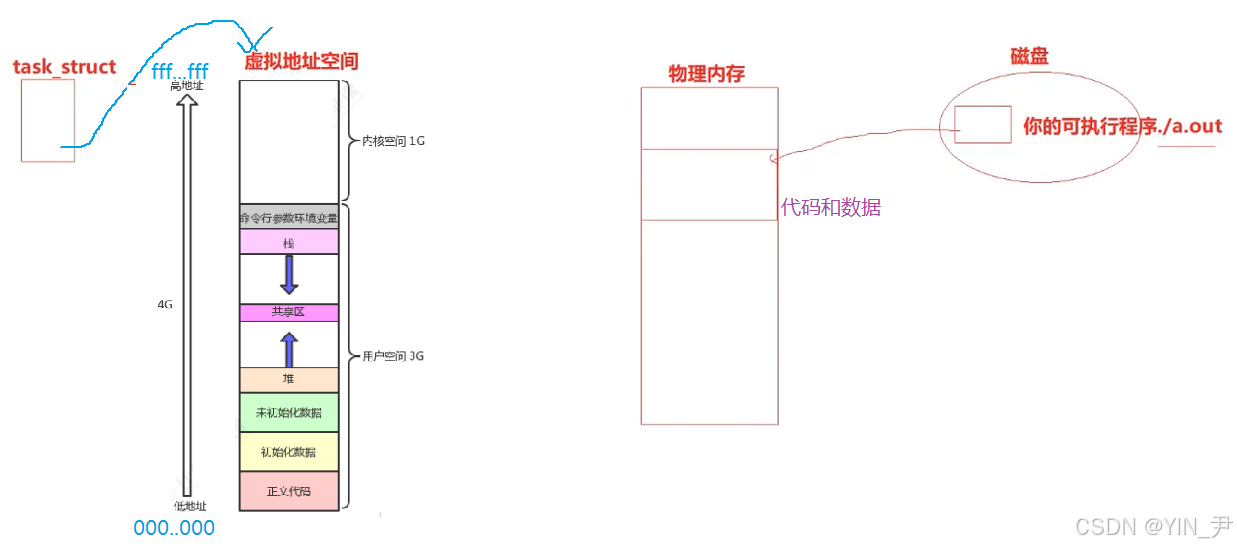
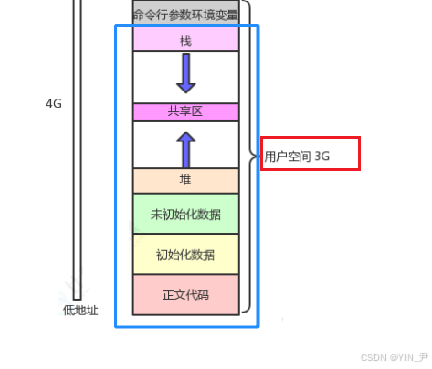
之前C/C++的文章中,我们讲解内存管理的时候,我们了解过这样一张图:
之前我们简单了解了这个内存区域的划分,了解了每个区域大致存放的是哪些内容。
不过如果我们去看一本C语言或C++的书籍,大概率书上并不会有这张图。
是因为这个东西其实不算语言的内容,而是操作系统的内容,之前我们把它叫做内存区域的划分,但其实它叫做进程地址空间/虚拟地址空间(不是真正的物理内存)。
这篇文章,我们来使用这张图(右边)
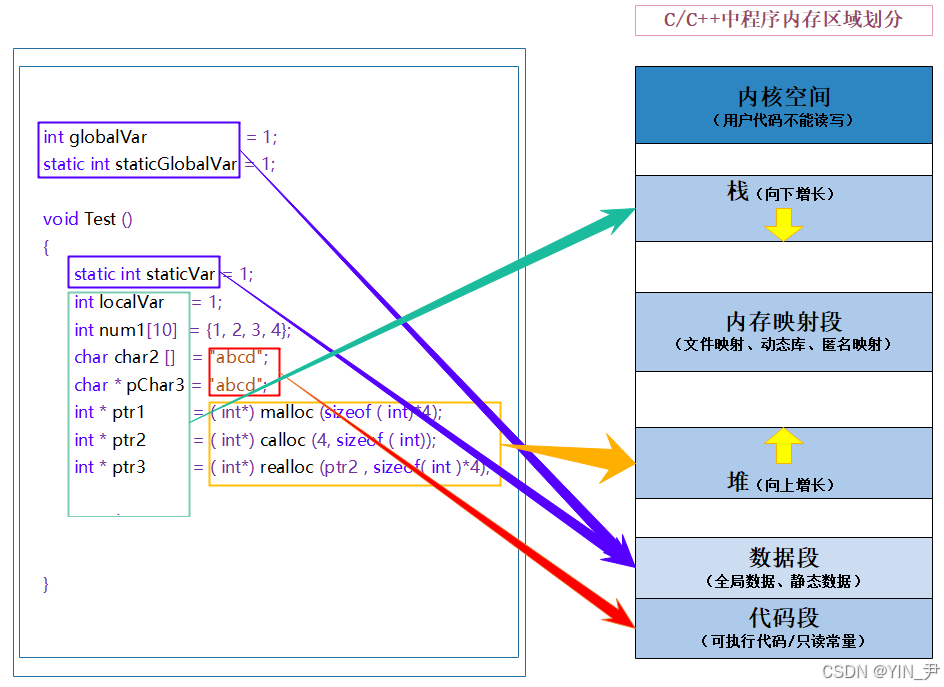
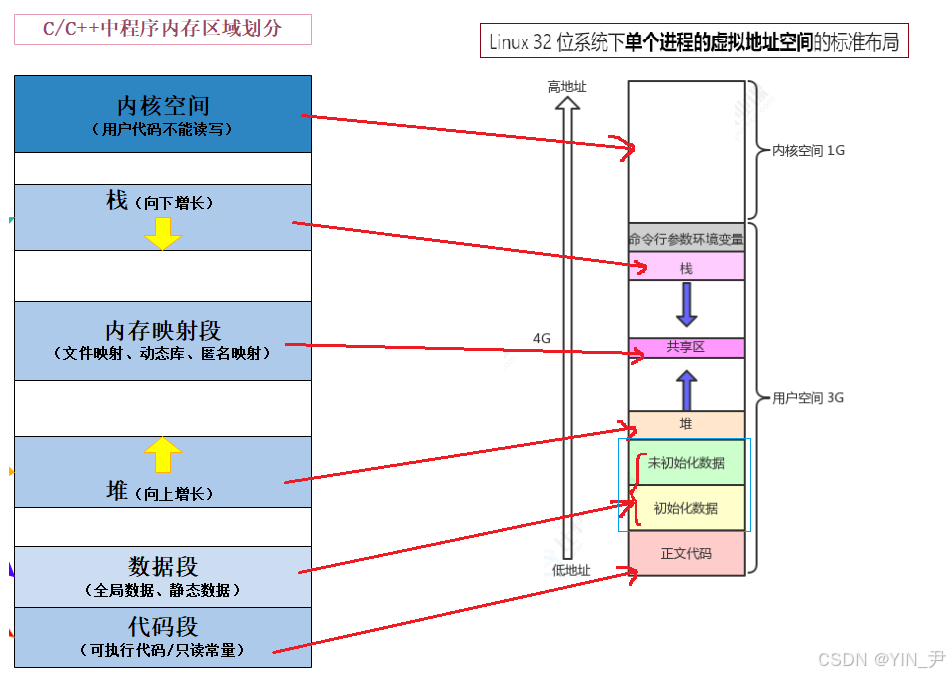
这篇文章我们来开始真正地学习进程地址空间。
首先,通过一段代码,我们来验证一下这个内存区域的分布:
cpp
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
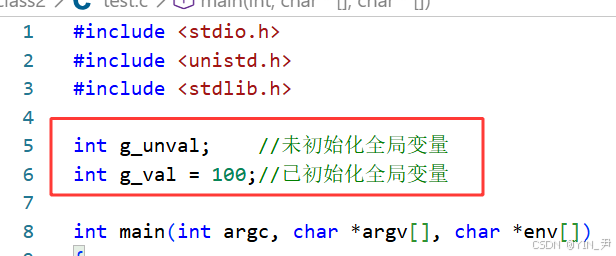
int g_unval;
int g_val = 100;
int main(int argc, char *argv[], char *env[])
{
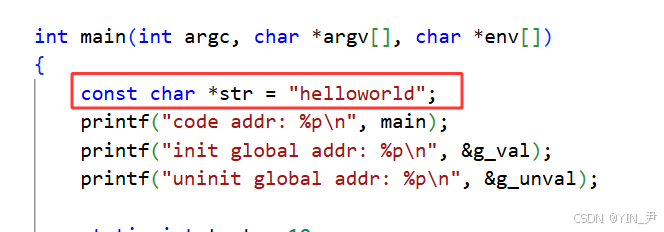
const char *str = "helloworld";
printf("code addr: %p\n", main);
printf("init global addr: %p\n", &g_val);
printf("uninit global addr: %p\n", &g_unval);
static int test = 10;
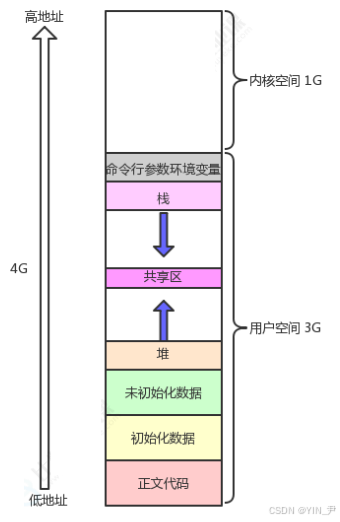
char *heap_mem = (char *)malloc(10);
char *heap_mem1 = (char *)malloc(10);
char *heap_mem2 = (char *)malloc(10);
char *heap_mem3 = (char *)malloc(10);
printf("heap addr: %p\n", heap_mem);
printf("heap addr: %p\n", heap_mem1);
printf("heap addr: %p\n", heap_mem2);
printf("heap addr: %p\n", heap_mem3);
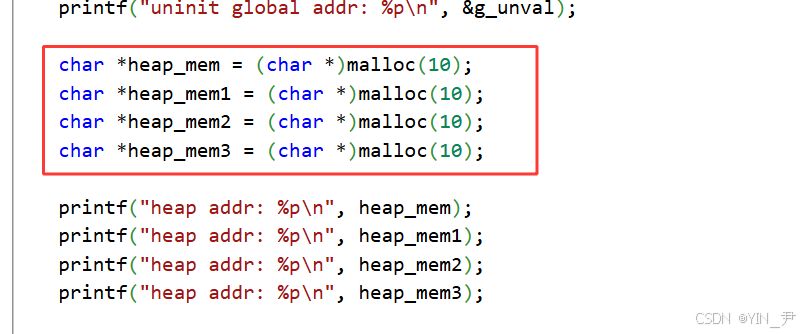
printf("test static addr: %p\n", &test);
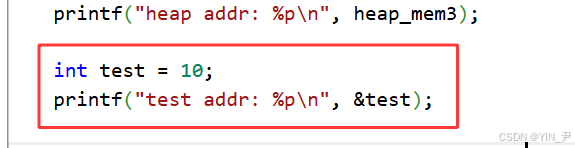
printf("stack addr: %p\n", &heap_mem);
printf("stack addr: %p\n", &heap_mem1);
printf("stack addr: %p\n", &heap_mem2);
printf("stack addr: %p\n", &heap_mem3);
printf("read only string addr: %p\n", str);
for (int i = 0; i < argc; i++)
{
printf("argv[%d]: %p\n", i, argv[i]);
}
for (int i = 0; env[i]; i++)
{
printf("env[%d]: %p\n", i, env[i]);
}
return 0;
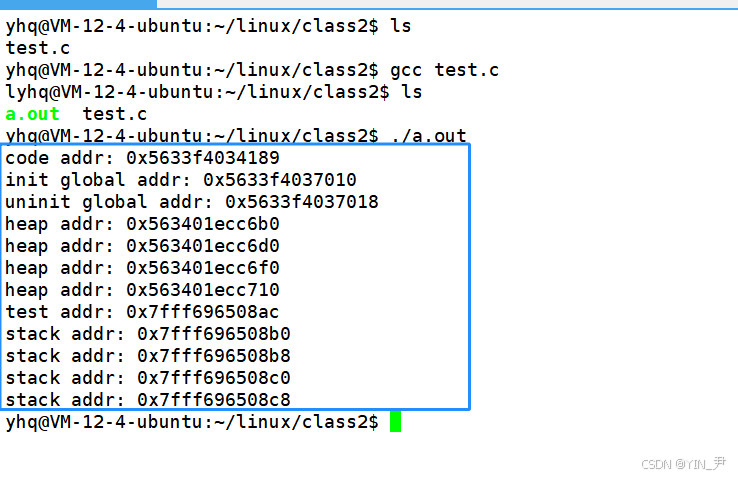
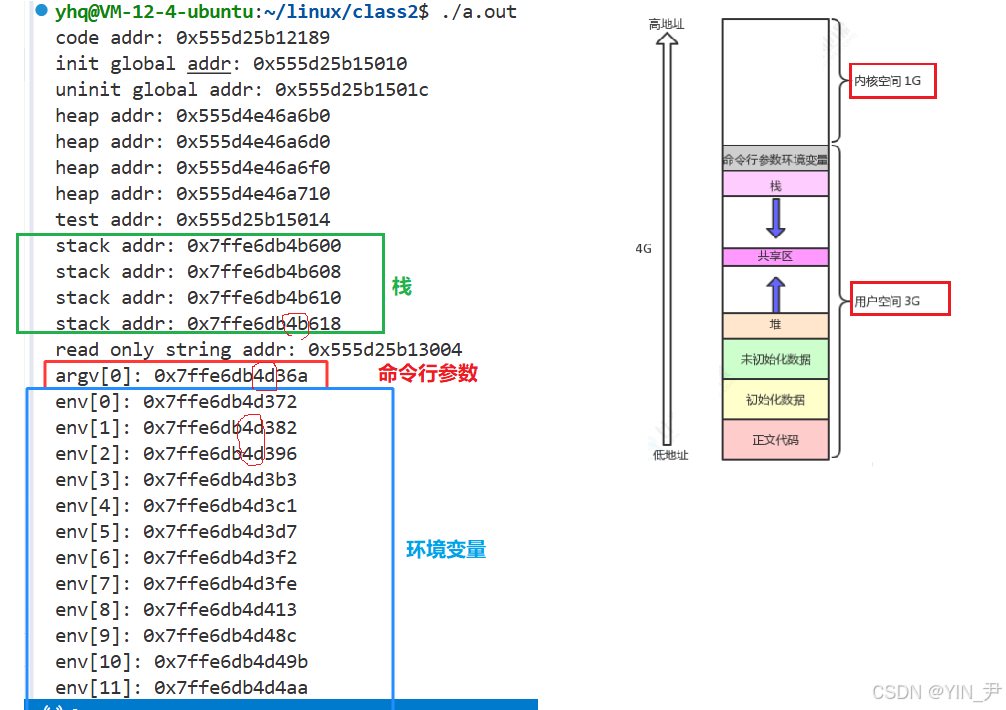
}上面的图中,下面低地址,上面高地址,我们这段代码打印一些不同类型变量或者空间的地址,看大小关系是否符合上面的分布!
我们来分析一下:
首先
首先定义两个全局变量,一个初始化,一个未初始化
然后,在main函数中
首先,定义一个字符指针,指向了一个常量字符串,所以str存的就是该常量字符串的起始地址(首字符地址)
再看下面三个打印:
首先打印main函数的地址(对于函数来说,函数名和&函数名表示的意义是完全一样的,都表示函数的地址),main函数是一段可执行代码,所以放在正文代码区域(代码段),在图中地址最小。
接着打印了两个全局变量的地址,全局变量之前我们讲它和static修饰的静态变量都是放在静态区,在C/C++内存布局中就是数据段,对应进程地址空间中就是已初始化数据区+未初始化数据区。
g_unval未初始化,所以应该放在未初始化数据区
g_val初始化,所以放在已初始化数据区
再往下看
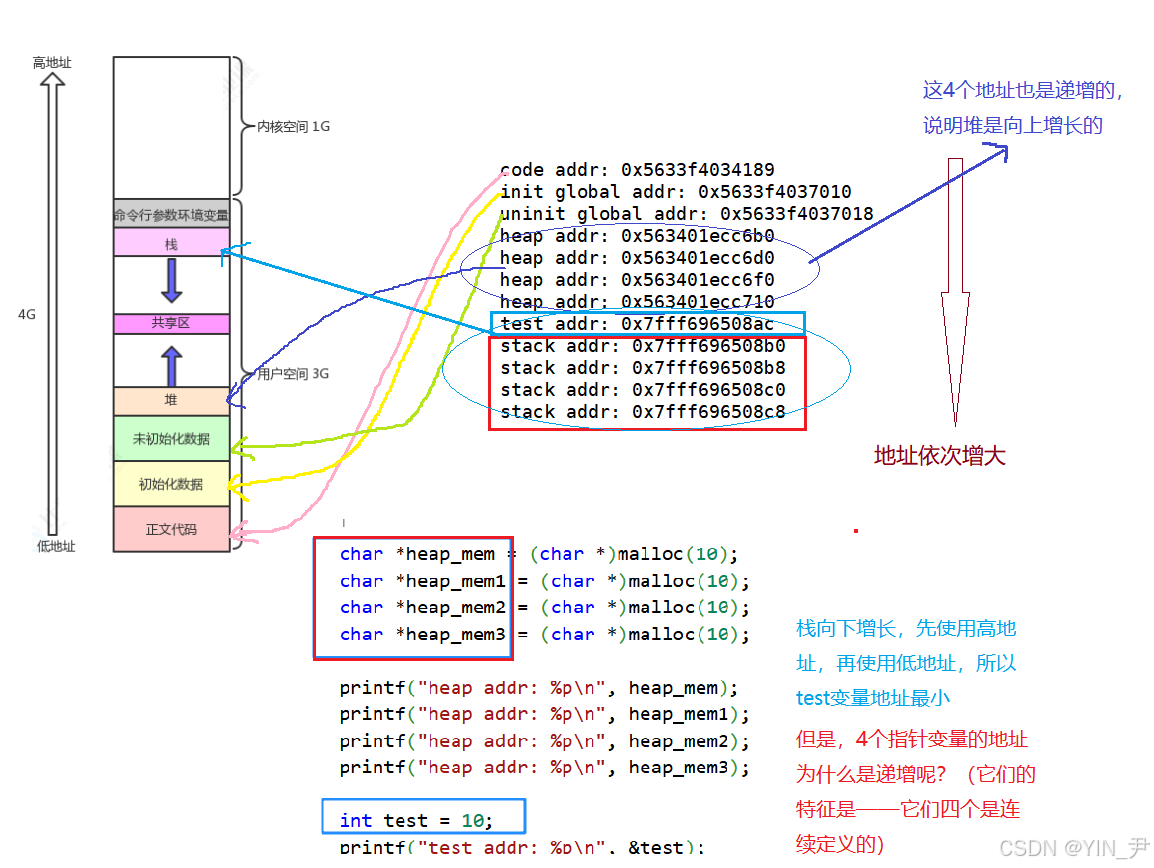
调用4次malloc在堆上开辟四块空间,malloc返回开辟内存块的起始地址,所以这里四个指针变量存储4块堆上空间的地址。(堆是向上增长的,即先使用低地址,再使用高地址,后面我们看这四个地址的大小关系)
再往下
我们打印了一个局部变量的地址,局部变量是在栈上的。
再往下
打印了四个指针变量的地址,这四个也是局部变量,所以也在栈上
目前先看这些,我们来在Linux机器上运行这段代码看一下:
我们来看一下这些地址
首先整体上各区域的地址是递增的,这都符合我们的预期,不过我当时看到这个结果,我疑惑的是,这四个指针变量的地址,test定义在它们四个后面,所以地址比他们低,没毛病。
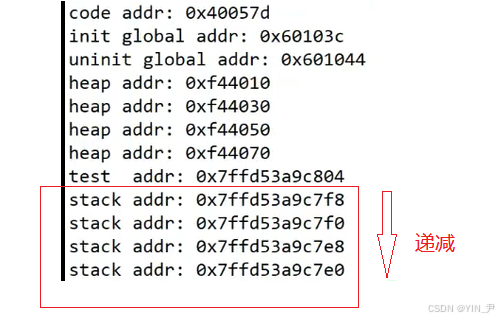
但是这四个指针为什么后定义的地址更高呢?而且我让其他人也在Linux云服务器(我们的版本不同)上执行了这段代码,他的结果这四个指针变量的地址是依次递减的。
问了一些大模型,大都是如是说的:
连续定义 时,编译器通常会给它们分配连续且顺序固定(可能正序也可能逆序)的栈偏移。你看到的"后定义地址高",说明你的编译器是按定义顺序从低地址向高地址分配(即第一个变量在最低地址,最后一个在最高地址)。这与栈增长方向并不矛盾,因为函数栈帧内偏移是编译器静态决定的,与栈动态增长方向(rsp 移动方向)无关。
编译器对局部变量在栈帧内的偏移量分配顺序,并没有统一标准。你和另一个人运行"相同代码"却得到相反的地址顺序,根源在于编译器实现细节不同(包括编译器类型、版本、甚至默认的栈帧布局策略)。
当然无需深究这种细节,整体上这个地址的变化是符合我们对进程地址空间布局的理解的。(而且如果你在Windows下执行这段代码,可能结果又会有所差异)
堆是向上增长的,栈上向下增长的,堆,栈相向而生。
那我们继续:
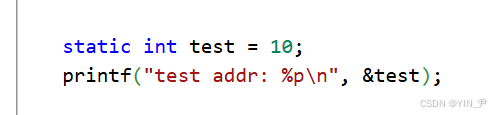
现在把test变量加上static关键字修饰:局部变量被static修饰后,将存储在静态区,出作用域后将不会被销毁,而是保留在静态区,生命周期改变(本质上改变了存储类型),这时它的生命周期就是程序的生命周期
我们来看下此时它的地址
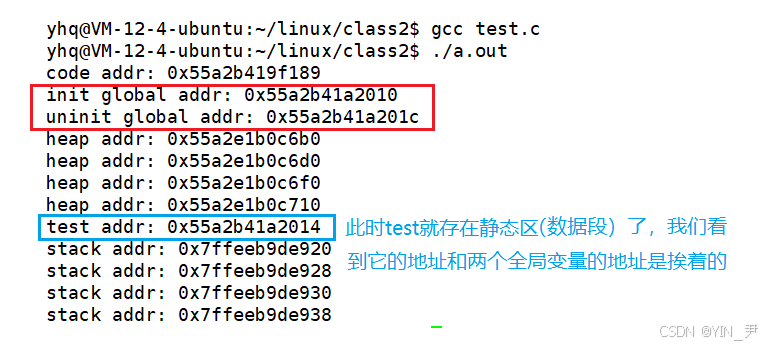
再往下:
我们来打印一下str,str是一个字符指针,指向一个常量字符串,所以str存的就是这个常量字符串的首地址。
看一下结果
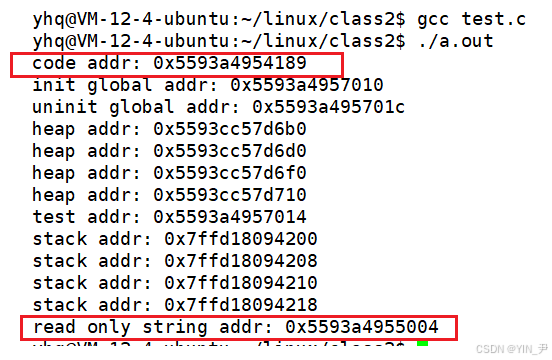
我们能看出来它和main函数的地址是挨着的,这也和我们之前的理解一致,常量字符串是存在代码段(正文代码)区域的
因为常量字符串和可执行代码一样是只读的,不能修改,这也是我们在前面加上const修饰的原因。
2. 虚拟地址的引入
之前在进程创建那篇文章,我们还遗留了一个问题:
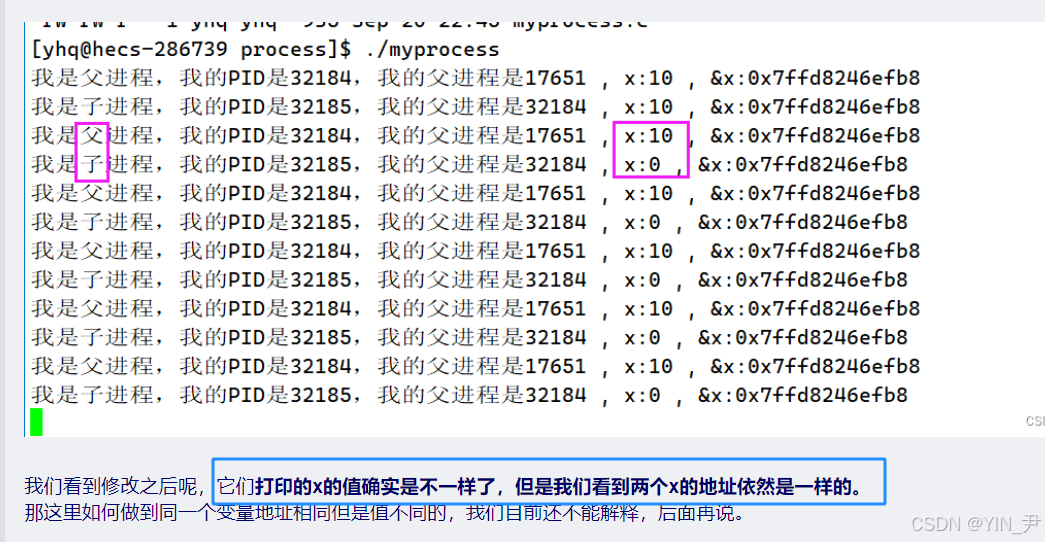
我们再来写一写当时的代码,回顾一下这个场景:
新建一个源文件,写这样一段代码
代码相信大家都可以看懂,我们来运行一下
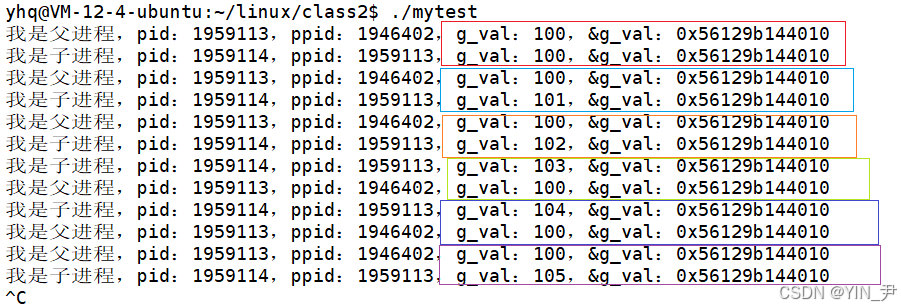
父子进程代码共享,数据写时拷贝。所以父子进程都可以打印全局变量g_val。
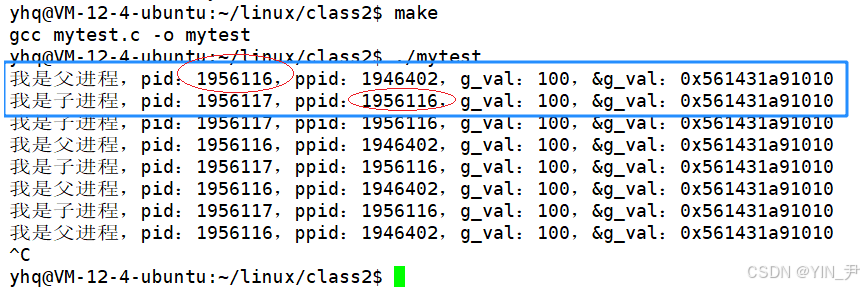
然后我们把代码做一下修改:
子进程不仅打印这个全局变量,还对他进行修改
结果是这样的,同一个全局变量,子进程在自己的执行流中修改它,并不会影响父进程,因为进程之间具有独立性,子进程修改这个数据的时候会发生写时拷贝 。
这都是我们之前讲过的内容了

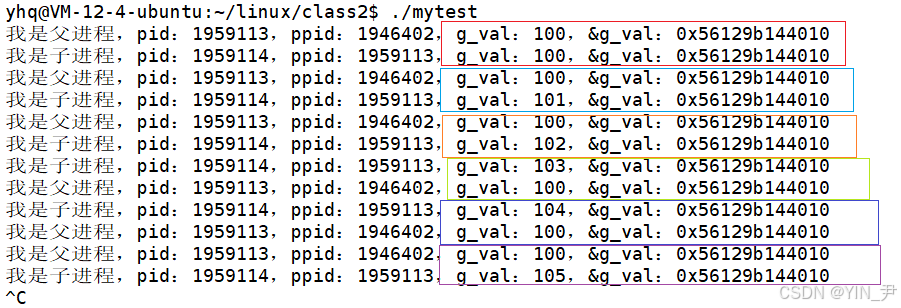
今天我们要重点关注的问题就是:子进程修改后,父子进程的执行流都打印g_val这个变量,我们看到它们的值是不一样的,但是,它们的地址居然是一样的?
同一个变量地址相同但是值不同的?
这是不符合逻辑的。
那么原因在于这里我们看到的地址并不是真正的物理地址,而是虚拟地址!
我们之前学C/C++,看过的各种变量的地址,通过调式窗口观察的各种内存地址,都是虚拟地址!!!
那,为什么呢?
为什么会有虚拟地址呢?这个虚拟地址是哪里的地址呢?
那下面就引出我们今天的主角------进程地址空间/虚拟地址空间
3. 进程地址空间的引入
我们来介绍一下什么是进程地址空间:
我们之前讲,一个程序被执行变成进程,除了要把代码和数据加载到内存中,操作系统还会在内核中给进程创建对应的进程控制块------task_struct
那么在task_struct中,会有一个指针,指向该进程的进程地址空间(每个进程都有自己独立的虚拟地址空间)。
空间的地址从全0到全f,所以我们上面看到的变量地址就是这里面的地址,就叫做虚拟地址!
这张图是以32位机器为标准画的,所以地址范围就是32位0~32为1
那他跟物理内存有什么关系嘛?
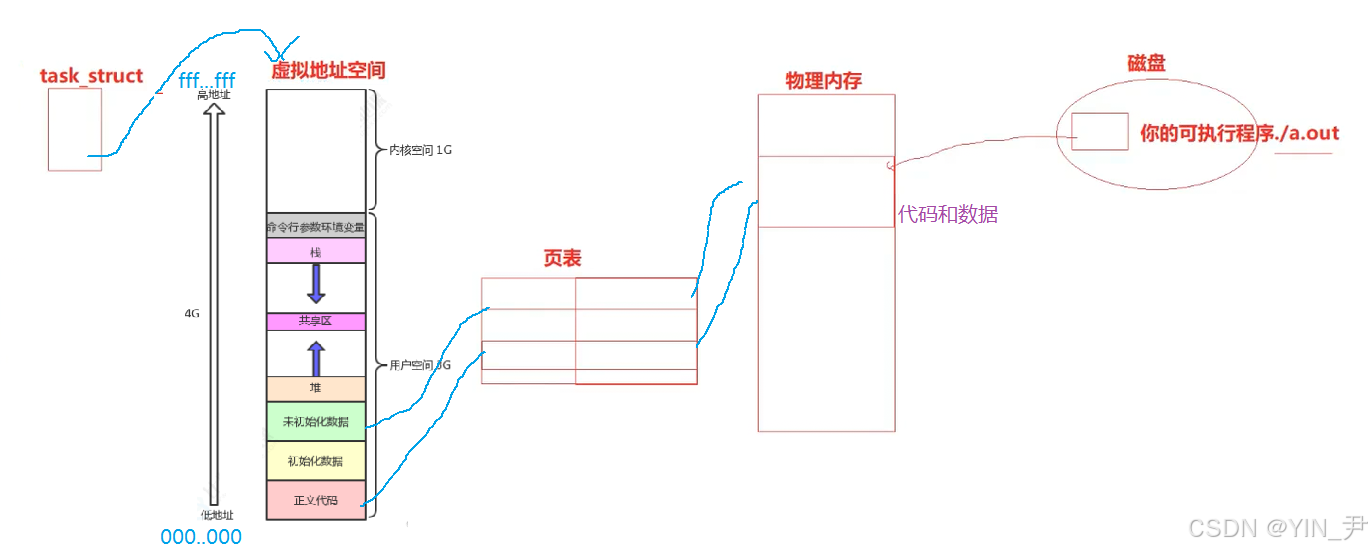
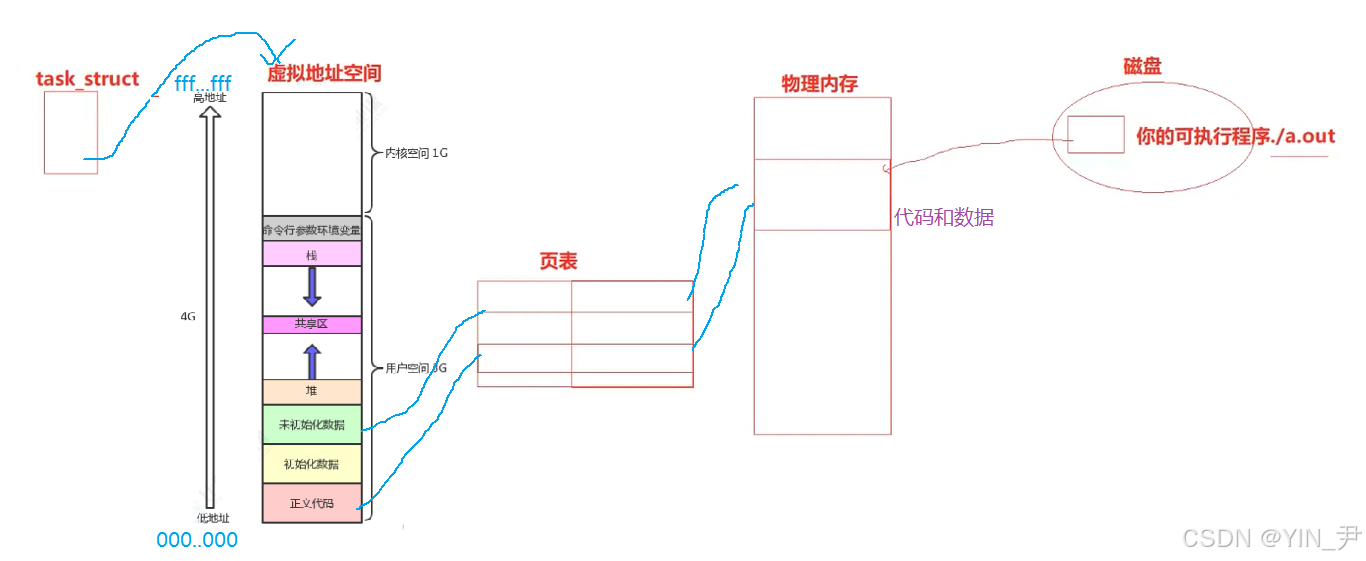
🆗,进程地址空间中的地址,是可以映射到对应的物理内存的。
因为我们进程的代码和数据,在执行的时候肯定是加载到物理内存的,只不过站在进程的角度,我们看到的是虚拟地址,但是它会被映射到对应的物理内存。
那谁来进行这个映射,谁来完成虚拟地址到物理地址的转换呢?------页表
我们在使用时,访问的都是虚拟地址,但是页表会在底层班我们完成虚拟地址到物理地址的转换,进而访问真正的物理内存。
4. 解决历史遗留问题
有了上面的铺垫,我们就可以来解决一下我们之前遗留的这个问题了:
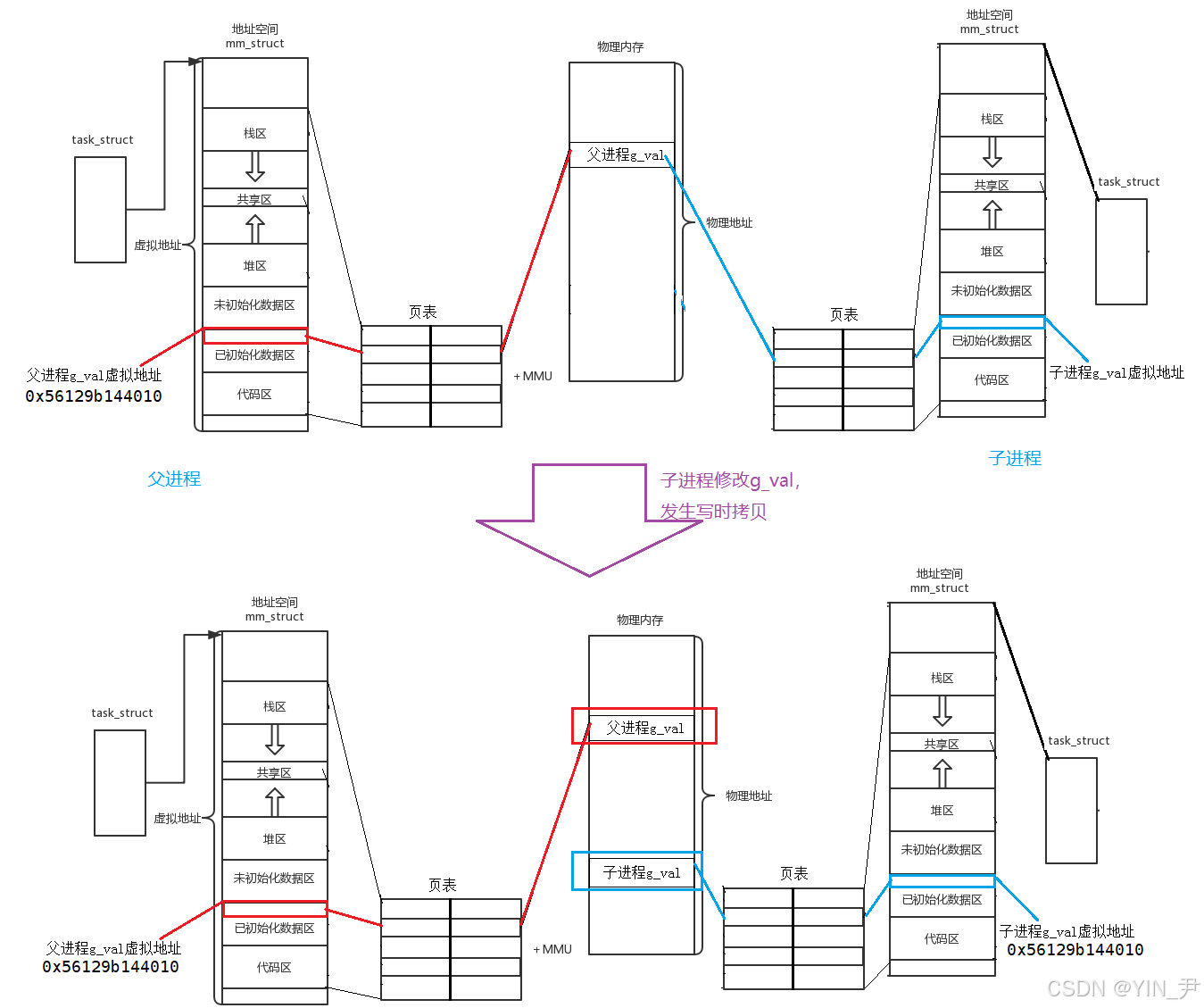
子进程修改g_val后,父子进程打印g_val,变量地址相同,但是值不同,怎么回事呢?
我们来讲解一下其中的原理:
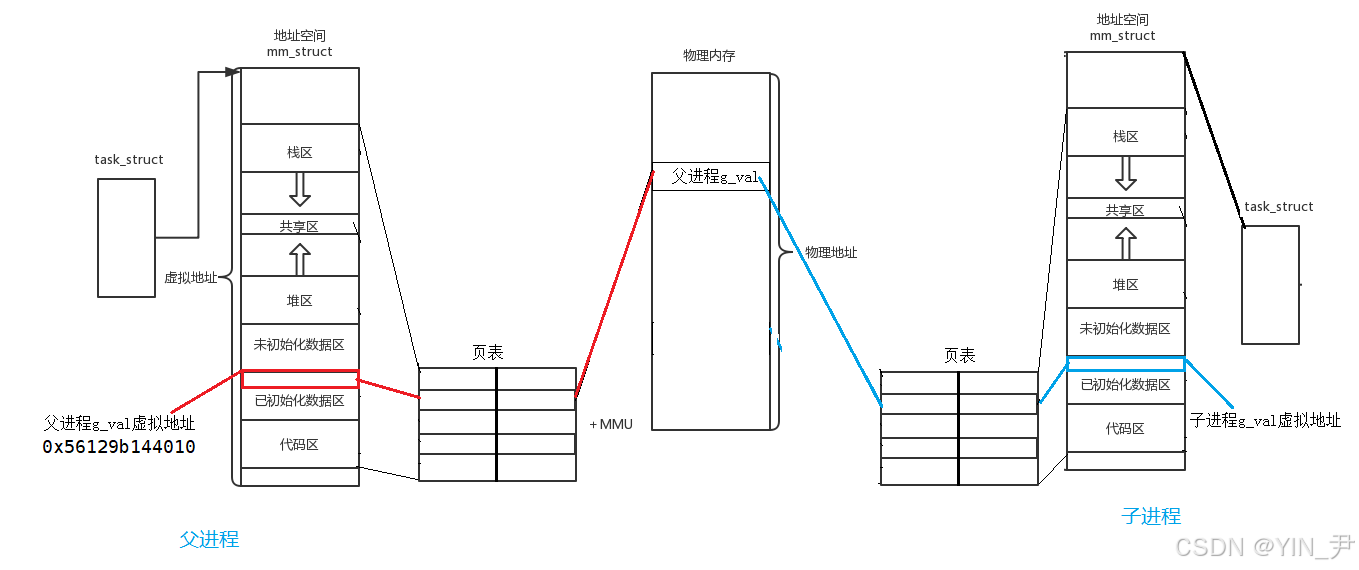
先看这张图
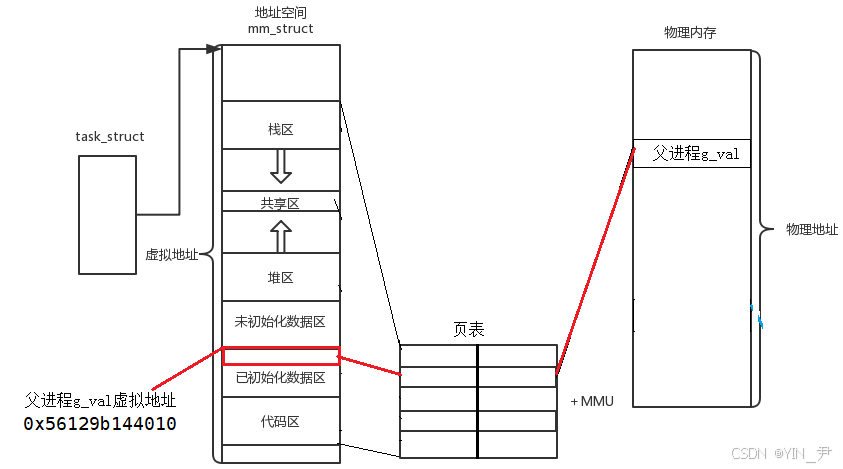
g_val是父进程定义的一个全局变量
对他进行了初始化,所以它是在进程地址空间的已初始化数据区的。
我们说了进程地址空间这地址是虚拟地址,我们去访问这个变量的时候,操作系统会在底层通过页表把虚拟地址转换为物理地址,然后就可以访问到真实物理内存中的这个变量。
然后呢,我们调用fork创建了一个子进程
那进程=程序加载到内存中的指令和数据+内核中与之关联的进程控制块(task_struct),前面我们讲过子进程会以父进程的task_struct作为模板,只修改诸如pid,ppid这些属性,大部分直接拷贝父进程task_struct中的属性值。
然后代码共享,数据写时拷贝。
每个进程都有自己的页表,fork时,操作系统会为子进程创建一个新的页表,并把父进程页表的内容(即页表项,PTE)逐项复制到子进程的页表中(即子进程的页表也是以父进程的页表为模板创建的 )。
子进程没有修改g_val之前,父子进程就共享这个数据,所以父子进程中g_val的虚拟地址相同,并且页表映射的物理地址也相同
这就是一开始我们看到的父子进程打印g_val,值相同,虚拟地址也相同。
后来
子进程修改了g_val
这时为了保证进程间的独立性 ,子进程修改了,但是我父进程没有修改,你不能影响我啊,所以,这时就会发生写时拷贝 !
那这个写时拷贝在物理内存中如何实现呢?
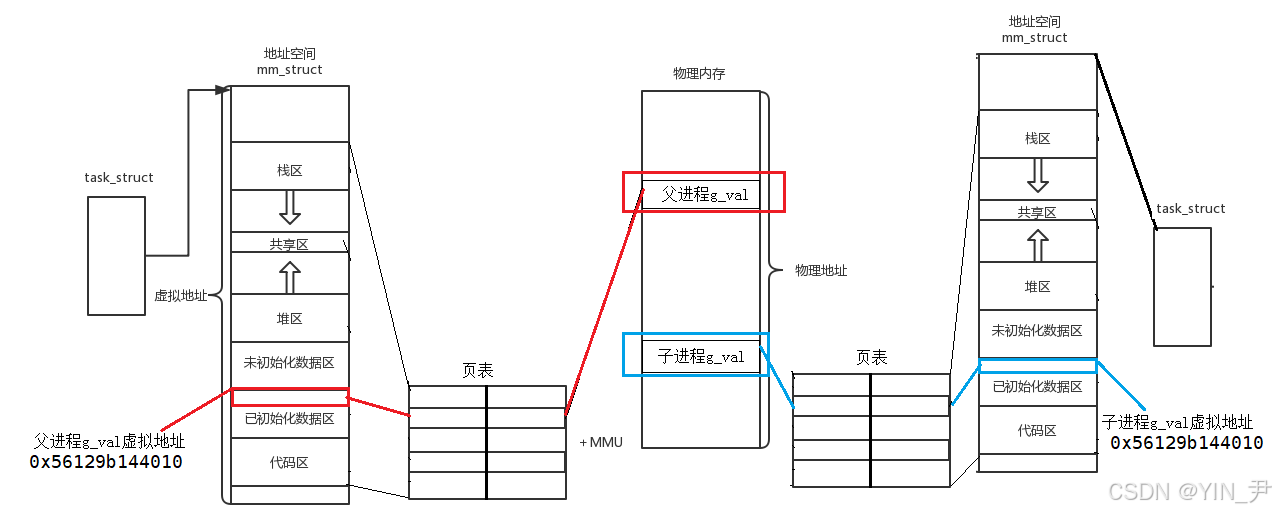
当发生写入时,进行写时拷贝:内核会分配新物理页、拷贝数据,然后修改发生写入的那个进程的页表项,使其指向新的物理页。而另一个进程的页表项仍然指向原来的物理页。
所以,子进程修改了g_val,操作系统就会在物理内存中新开辟一块空间,拷贝g_val过去,这个新的g_val作为子进程独立的g_val,你要修改,改你自己的,父进程不受影响。
但此时子进程的g_val对应的物理地址就变化了,所以子进程的对应页表项也会被修改,把g_val的虚拟地址映射到一个新的物理地址(虚拟地址无需改动)。
最终就变成了这样
当然这些工作由操作系统自动完成,对我们用户完全透明。
所以,就出现了上面我们看到的现象------父子进程都打印g_val,虚拟地址相同,但是打印的值不同,因为虽然虚拟地址相同,但是两者映射的物理地址是不同的,在物理内存中,其实是两个变量 (保证了进程的独立性)。
5. 什么是进程地址空间,如何理解?
下面带大家来理解一下,到底什么是进程地址空间。
首先我们来讲一个故事:
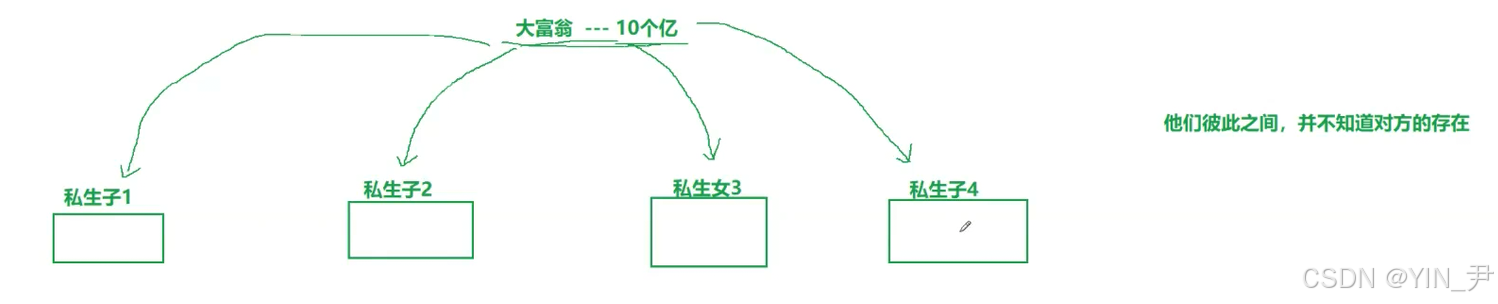
有一个富翁,假设他有10个亿。然后他有很多私生子/私生女。
这些私生子/私生女之间,他们彼此之间不知道其他人的存在。
大富翁对每一个私生子都说,等以后老了,我的这些钱都是你的。
所以每一个私生子都认为自己以后可以独占这十个亿,且都不知道其它私生子的存在
这时候,私生子4过来说,我要交学费,你给我100块钱,大富翁说可以,就给他了。
私生女3过来说我要买化妆品,需要200块钱,大富翁也给了。
然后私生子2过来说,我要做项目,给我10个亿!这时大富翁直接把私生子2骂了一顿,说还"我活得好好的呢,你就想把我10个亿全都要走!"
私生子2说好吧,其实200块钱就够了。
私生子1说我要1万块钱读研,大富翁也给了。
所以大富翁对于私生子呢,只要是正常的请求,都是有求必应;
然后所有的私生子,都认为自己可以拥有这10个亿,但是正常情况下他们也不会直接要10个亿。
所以,虽然大富翁给每个私生子说你以后可以拥有这十个亿,但是只要大富翁还在,就不会真的一次给他们10个亿 。
所以大富翁这样说,其实就是在画大饼!
那这里的大富翁就对应操作系统,私生子/女就对应一个个的进程,这里画的大饼就是进程地址空间!
每个进程都有一套独立的页表(Page Table)。对于进程而言,它看到的内存地址是连续的(全0-全f)、独占的(但实际进程运行时不可能一次申请特别大块的空间)。它不需要关心物理内存哪一块被占用了,他认为自己进程地址空间中的任何空间都可以使用,但实际通过页表映射,会帮它把虚拟地址映射到合适的物理地址。
每个进程都觉得自己独占了内存(这就是虚拟地址空间的魅力)
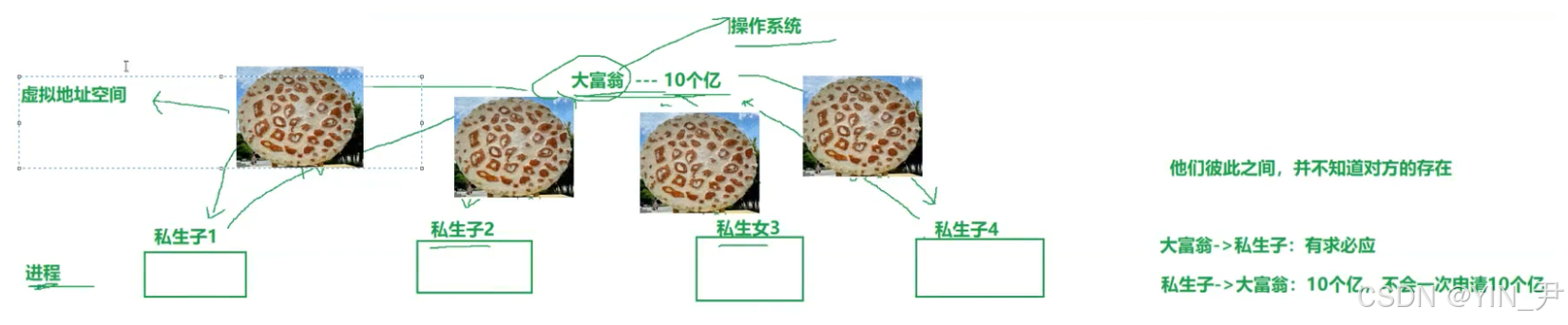

如何管理
那下一个问题:进程可能有很多,操作系统给每一个进程都画了一个大饼(进程地址空间),那操作系统要不要将这么多的大饼管理起来呢?
当然需要!
如何管理呢?
先描述,再组织!
先用一个结构体描述进程地址空间,然后再用一种数据结构把所有的结构体变量组织起来!
然后对进程地址空间的管理就变成了对特定数据结构的增删查改。
所以,进程地址空间在操作系统中,本质就是一个结构体!
结构体内部,就是划分了一个个的区域。
那如何理解这其中的区域划分呢?
6. 如何理解空间中的区域划分?
举个栗子:
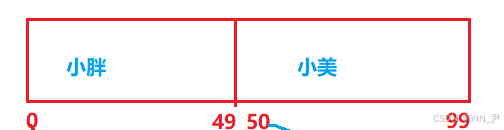
有一张桌子,长100厘米,现在想把它划分成两部分,55分
假设每一厘米都有一个下标,那就是0~99
那平均划分两半的话就0~49是一半,50~99是另一半即可
假设左边是小胖同学的位置,右边是小美同学的位置
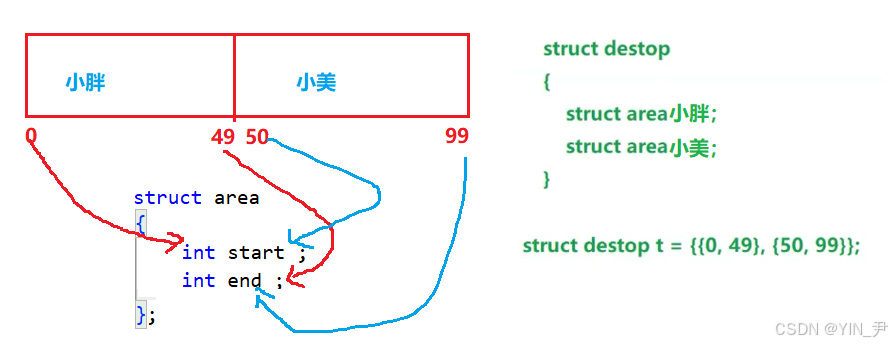
那在一个结构体中,如何描述这种区域划分呢?
很简单:
一块区域,只需要有两个变量标识它的起始和结束位置即可!这中间的空间,都是我拥有的
那我后续想扩大或缩小某个区域呢?
只需要改对应的start和end的值就行了。
7. 看看源码
那下面我们就来看看Linux中进程地址空间对应的结构体,看看它内部是如何做的?
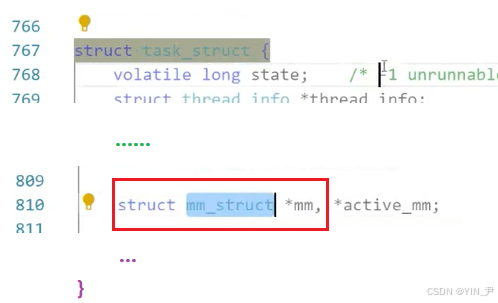
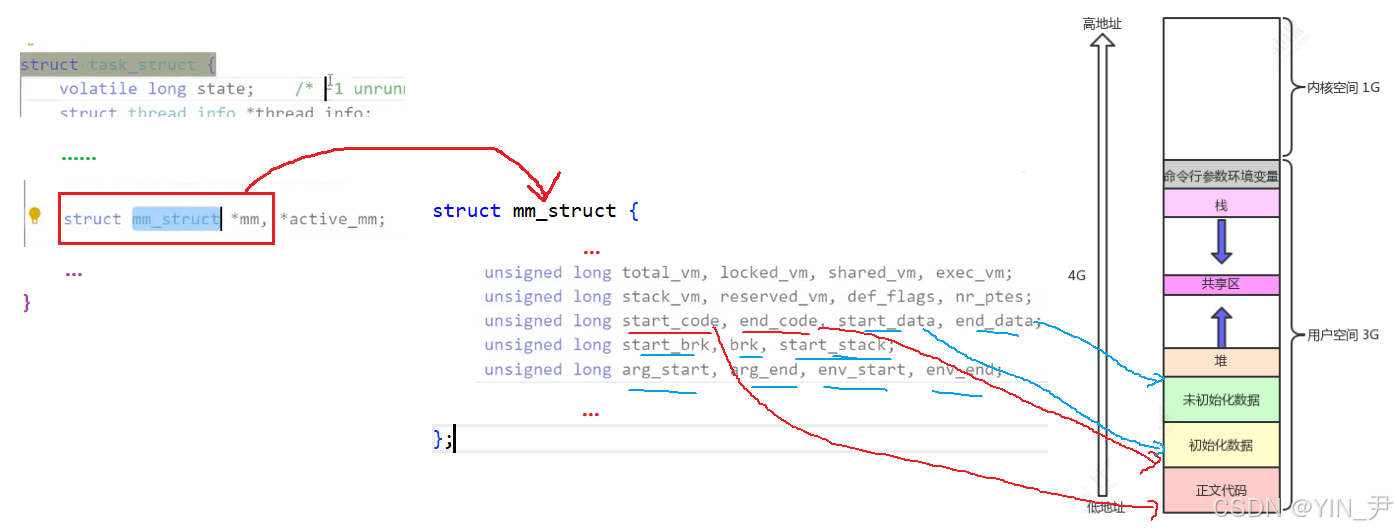
Linux中,描述进程地址空间的结构体叫做
mm_struct(进程内存描述符)
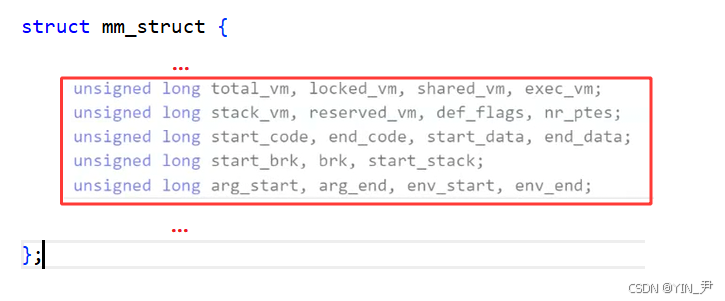
在每个进程的task_struct中,会有一个mm_struct类型的结构体指针------mm,指向当前进程的进程地址空间
然后我们来看mm_struct结构体
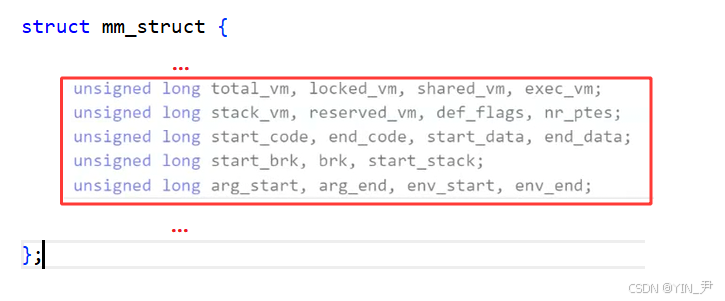
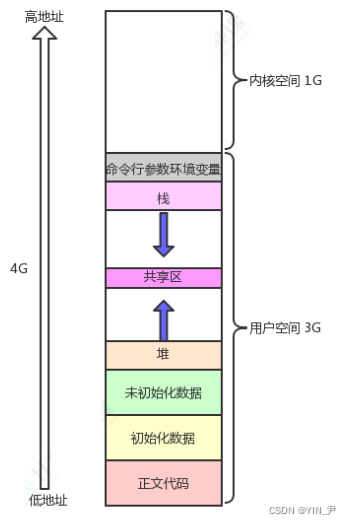
mm_struct里面的成员很多,我们现在也不需要全部看,但是,通过上面的铺垫,我们猜测mm_struct中一定会有很多类似上面start,end这样的字段来标识各个内存区域
从源码中,我们确实能找到
比如第三行的start_code,end_code就标识了代码段(正文代码区域)的起始和结束位置
内核空间:大富翁(操作系统)自己的「私人领地」,私生子无权访问。
mm_struct中还有一个指针pgd_t *pgd;指向当前进程的页表

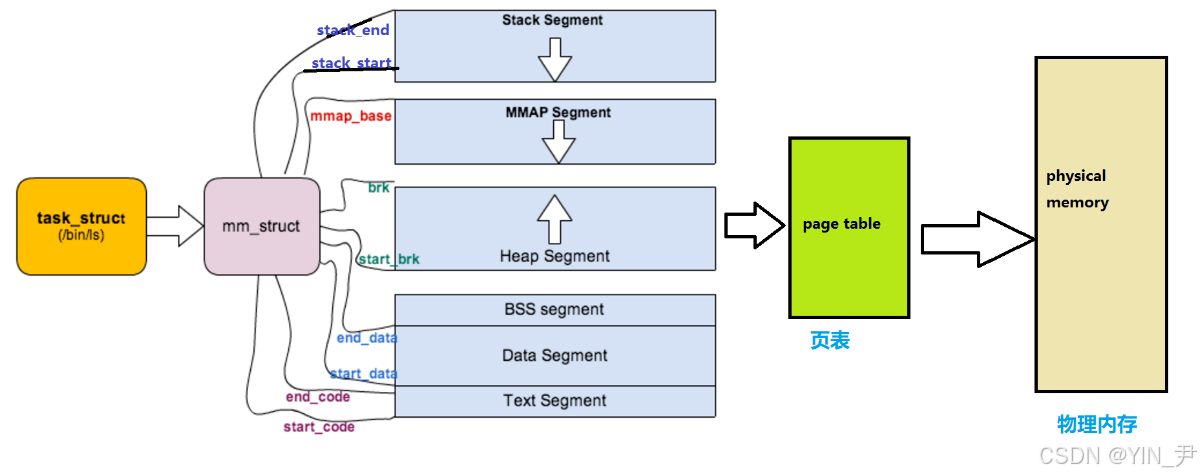
一图总结:
8. 补充
然后我们再来做一些补充:
第一点:
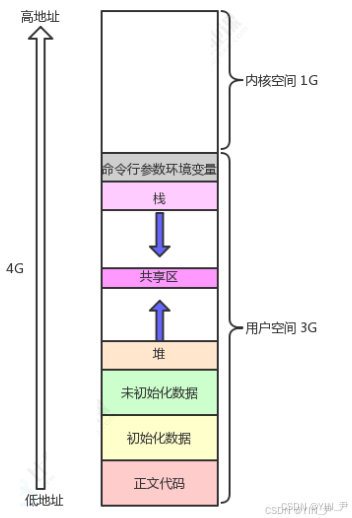
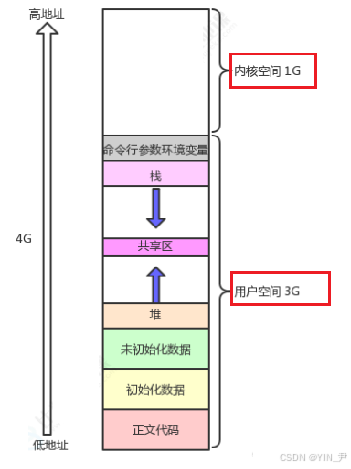
我们看到进程地址空间其实被分成两大部分:内核空间和用户空间。
而我们目前比较熟悉的其实是用户空间的这几个区域,内核空间我们先不关心。
那么什么是用户空间呢?所谓的用户空间,即我们用户可以通过地址直接访问的空间,而如果要访问内核空间,必须通过操作系统提供的系统调用来访问。
第二点:简单谈谈页表
通过上面的了解,我们现在至少知道页表主要是进行虚拟地址到物理地址的转换的。
然后在进程地址空间中,正文代码区域(代码段)通常是只读的,其它区域比如数据段又是可读可写的。
那如何做到这种权限的约束呢?
那在页表中,还会有一列用来记录权限信息,标识当前映射地址所属区域的读写权限。
回头来看我们之前的那段代码
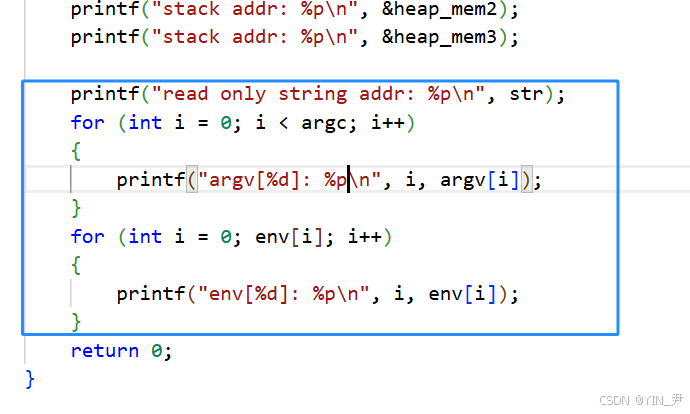
下面还有一小段,现在我们把注释放开。
运行一下,先来看这个常量字符串的地址
这个我们其实上面观察过了,常量字符串和代码是放在一起的,在正文代码区域(代码段),都是只读的,不能修改。
那如何实现不能修改呢?
如果我要访问代码段的地址,去修改这块地址的内容,那么在页表映射的时候,会检查对应的权限,发现你对这块空间只有读权限,现在你想写,那就直接拒绝。


第三点:命令行参数和环境变量区
在用户空间中
我们比较熟悉的是蓝色框中的这几个区域。
但是,我们看到,用户空间的最上面,还有一个区域------命令行参数和环境变量。
什么是命令行参数和环境变量我们之前的文章讲解过了。
所以,这块区域存的就是命令行参数和环境变量吗?
我们来验证一下,看一下刚才打印的地址(看图,命令行参数和环境变量的地址应该在栈区上面,比栈的地址高)
没有问题,就是在栈的上面。
即命令行参数和环境变量也是存在进程的地址空间中的,在栈的上面。
所以命令行参数和环境变量也属于进程数据的一部分,父子进程之间就遵循数据默认共享,修改写时拷贝。
这也解释了我们之前讲的------环境变量可以被子进程继承!
9. 为什么要有进程地址空间?
这个问题其实可以转化为:如果程序直接可以操作物理内存会造成什么问题?
在早期的计算机中,没有进程地址空间,即程序中访问的内存地址都是实际的物理内存地址。当计算机同时运⾏多个程序时,必须保证这些程序用到的内存总量要小于计算机实际物理内存的大小。
那当程序同时运⾏多个程序时,操作系统是如何为这些程序分配内存的呢?
例如某台计算机总的内存大小是128M,现在同时运行两个程序A和B,A需占⽤内存10M,B需占⽤内存110M。计算机在给程序分
配内存时会采取这样的⽅法:先将内存中的前10M分配给程序A,接着再从内存中剩余的118M中划分出110M分配给程序B。
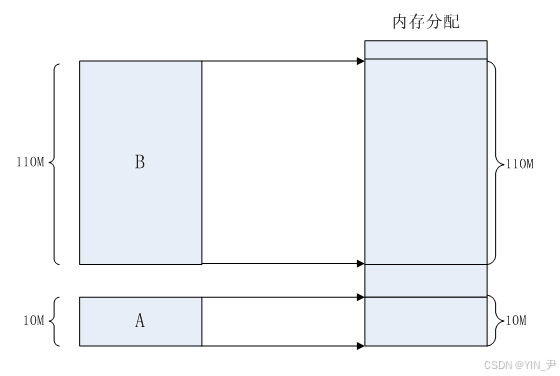
这种分配⽅法虽然可以保证程序A和程序B都能运⾏,但是这种简单的内存分配策略问题很多。
9.1 安全
想象一下:
如果没有进程地址空间,没有虚拟地址。我们在C/C++程序中使用一个指针,就可以随意地访问物理内存。
那就会导致缺乏隔离:一个进程可能错误的访问另一个进程的内存空间,一个程序的错误指针可能破坏其他程序甚至操作系统内核的数据 。
这就会造成进程之间的相互干扰,一个进程出问题可能会干扰其它进程,那这不就违背了进程之间的独立性嘛。
那反过来:
因为有了进程地址空间的存在,我们在程序中使用的都是虚拟地址,那访问内存的时候,就必须先进行虚拟地址到物理地址的转换(相当于在进程和物理内存之间添加了一层软件层)
在计算机科学中,存在一个经典的计算机科学谚语:
因为存在这样一层转换,那么就可以在虚拟地址转换为物理地址的时候,进行相关的安全性的审核。如果你进行了一个非法的访问,那操作系统就可以拦截你。
这防止了进程间的相互干扰,一个进程的崩溃或缓冲区溢出不会破坏其他进程甚至内核的数据,极大提升了系统的稳定性和安全性。
这就变相地保证了物理内存的安全,维护了进程之间的独立性!

给大家举个例子,这就好比:
你每年过年的时候,都能收到很多压岁钱。
之前一直都是你自己管这些钱,所以你想买啥就买啥,没人管你,各种垃圾食品疯狂地买,各种奶茶外卖狠狠地吃。
现在呢,你妈妈每次都会把你的压岁钱收走,管理起来。你妈妈跟你说的是:"我帮你管起来,但是这钱还是你的,你要买啥问我要就行了!"
你说你要买本书,买支笔。没问题,要花多少钱你妈就给你多少。
你说你想买十包辣条就着十瓶可乐吃,你妈骂了你一顿,说天天吃这种垃圾食品,有什么好处啊,不准买!
此时你妈妈(操作系统+虚拟地址空间+页表)就可以对你(进程)对这些钱(物理内存)的使用进行限制和审核,让你只把钱用在"合理"的地方。
9.2 按需分配与惰性加载
再来看这张图:
问大家一个问题:
双击执行一个可执行程序让他变成进程的时候,它所有的代码和数据是不是都全部一块加载到内存中?
通常不是这样的,而是采用按需分配与惰性加载的策略
按需分配:执行一个程序,先只加载目前需要的部分,给他分配物理空间(此时可能并不需要执行所有的代码和数据,其它不需要的就先不加载)
惰性加载:如果进程使用malloc申请了一块空间,先只给他分配虚拟内存空间,并不立刻分配物理页。只有当进程真正访问该地址时,出现缺页异常才触发物理页的分配并建立页表中的映射。
因为有地址空间的存在,所以我们在C、C++语⾔上new, malloc空间的时候,其实是在地址空间上申请的,物理内存可以甚⾄⼀个字节都不给你。当你真正进行对物理地址空间访问的时候,才执行内存的相关管理算法,帮你申请内存,构建页表映射关系(延迟分配),这是由操作系统自动完成,用户包括进程完全0感知!!
这就可以做到:
- 程序启动极快(只加载极少代码):比如你玩一个大型游戏,此时你在玩这个场景/地图,那就只需加载当前场景的代码和数据在内存中,其它没用到的就不加载
- 减少物理内存的浪费:只给实际使用的页分配物理页
- 支持运行比物理内存更大的程序(结合换入换出):你玩一个大型游戏,此时你在玩这个场景/地图,那就只需加载当前场景的代码和数据在内存中,其它没用到的就不加载(省出来的这部分空间还可以先被其它进程使用),等你玩其它场景的时候,把之前不需要的代码和数据换出去,把需要的加载进来(通过这一系列的手段,就可以使得从用户的感知上来看,内存好像比实际的要大多)
9.3 有序
什么意思呢?
操作系统中可能运行很多进程,物理内存经过长时间分配释放,会产生难以利用的"外碎片"(比如许多几KB的小空隙)。
所以,进程的代码和数据加载到物理内存中,可能是非常零散、非常分散的。
但是因为有进程地址空间的存在,站在进程的视角,他看到的就是虚拟地址空间,虚拟地址空间允许进程的连续虚拟地址映射到物理内存中不连续的、分散的页面 。即进程能够以一种比较规整有序的视角看待自己的代码和数据,无需关心它在物理内存中有多么混乱无序!
同时,这样可以充分利用内存碎片,提高了物理内存的利用率。
9.4 解耦
进程地址空间的存在使得进程管理和内存管理可以解耦合!
对进程而言:
每个进程都以为自己独占了从 0 到最大地址的连续内存,无需关心物理内存的碎片、容量上限、其他进程的占用。进程只需使用虚拟地址,程序编写和编译不需要知道最终的物理位置。
对操作系统而言:
物理内存可以按页自由分配给任意进程的任意虚拟页,物理页帧可以是非连续的。内存分配、回收、移动(如压缩碎片)变得非常灵活,不影响进程运行(只需更新页表)。
两者通过页表连接,但不耦合
10. 进程地址空间的组织方式
前面讲了:
描述
linux下进程的地址空间的结构体是mm_struct(内存描述符 )。每个进程只有⼀个mm_struct结构,在每个进程的task_struct结构中,有⼀个指向该进程mm_struct的结构体指针。
先描述,再组织。mm_struct结构体描述了进程地址空间,那具体是如何组织呢?
task_struct中有一个mm指针指向mm_struct,所以操作系统把所有进程的task_struct 组织起来,就变相的已经把进程地址空间mm_struct组织起来了。
11. 虚拟内存块的管理
但是,还有一些情况需要我们考虑:
在进程地址空间中:
一个内存区域(堆、栈、代码段...)对应一整块,但是在实际使用的过程中,比如堆空间,我们正常是一小块一小块的使用的,比如在一个程序中我malloc了多次,申请多块空间,每一块都有起始地址和空间大小,当然通过上面的理解我们知道,我们malloc得到的都是虚拟地址空间,当我们真正使用申请的空间时才会开辟物理内存块,然后建立页表映射。
所以,不仅进程地址空间要被管理起来,我们在进程地址空间中申请的一块块虚拟内存块也需要被管理起来!
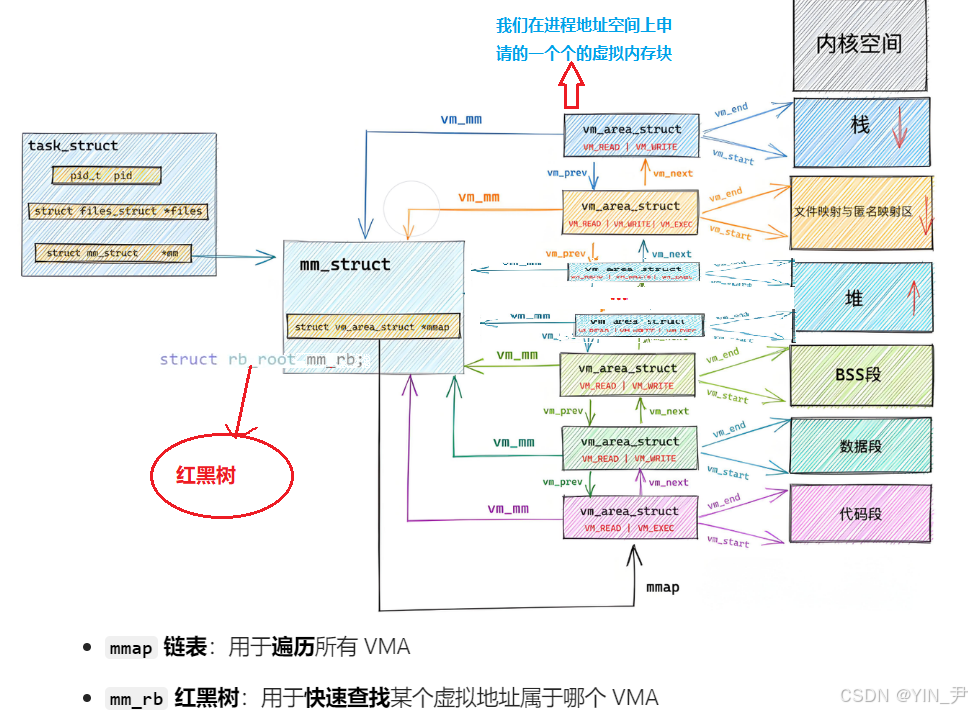
如何管理:先描述,再组织!
内核中使用
vm_area_struct这个结构体来描述我们在进程地址空间中申请的一块虚拟内存块(VMA)。
每一个vm_area_struct,就代表进程地址空间中「一块已经被申请、被使用、有明确用途」的虚拟内存区域
如何组织呢?
单链表+红黑树!
mmap链表:用于遍历所有 VMA
mm_rb红黑树:用于快速查找某个虚拟地址属于哪个 VMA(缺页异常时)
看看源码:
从
mm_struct结构体的定义中,除了上面我们了解过的:
还可以找到mmap和mm_rb
简单了解:红黑树的节点是struct rb_node。每个vm_area_struct结构体内部内嵌了一个struct rb_node成员(名为 vm_rb)。通过这个内嵌的rb_node,内核将所有的vm_area_struct组织成红黑树。

另外:
在
vm_area_struct中
也是有访问权限相关的字段的。
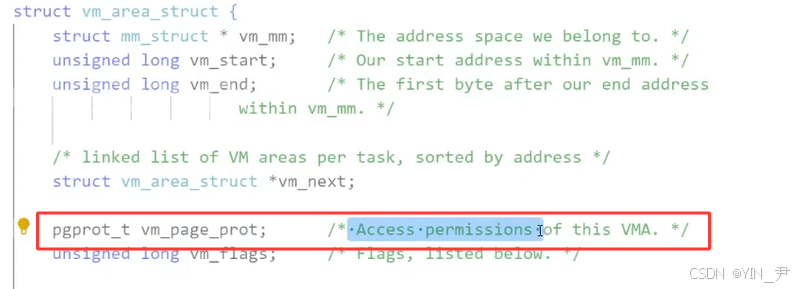
那前面我们说页表里面也有权限字段,那他俩是什么关系呢?(先简单了解)
两者的角色分工:
vm_area_struct(VMA):进程地址空间的逻辑描述。它记录了某一段虚拟地址区域应该具有的权限(如可读、可写、可执行) ,以及该区域是映射文件还是匿名内存。这是内核管理虚拟内存的"意图"。
页表项(PTE):硬件 MMU 直接使用的数据结构。它记录了虚拟页到物理页的映射,以及该页当前在硬件层面的访问权限 (通常是 VMA 权限的子集 ,比如因为写时复制暂时设为只读 (这句话我们后面会用到))。
非法访问最终是被 VMA 权限拦截的(通过内核判断后发送信号)。页表权限的作用是触发异常,让内核有机会介入决策;如果页表权限过于宽松(比如直接允许写一个本该只读的 VMA),那么硬件不会产生异常,非法访问就会成功------但这不会发生,因为内核在建立页表时总是根据 VMA 设置权限,且不会超过 VMA。
(图片截取自deepseek的回答)
