你肯定有过这种体验:跟 AI 聊得正欢,关掉窗口再打开,它反问你一句"有什么可以帮您?"
------刚才说的事它忘得一干二净。
这不怪 AI。绝大多数大模型对话接口都是无状态的,每一次请求对它来说都是全新开始。想让它记住之前聊过什么,你就得把整段对话历史原封不动地重新发一遍。聊个三五轮还好,聊到二十轮以后,光是上下文就要吃掉好几千 Token。
这篇文章,我们就自己动手给 AI 加一个"硬盘"------把聊天记录存到本地 JSON 文件里,每次只挑最相关的几条喂给模型。实现这一套的东西,技术圈叫 RAG(检索增强生成)。向量生成的部分,我们可以调用 AIO 开放平台(api.aiearth.dev)的云端接口,不用自己下载模型文件,门槛较低。"
接下来,我会一段一段拆代码,顺便把每处用到的 Python 知识和背后的 AGI 概念标出来解释。
整体思路:这个助手的运行原理是什么?
让我们先整理一下思路,将整个助手分成四个模块,各司其职:
-
记忆存储:负责把对话写成 JSON 存到本地硬盘。
-
向量化:把文字变成一串数字(向量),方便数学比较。
-
检索:拿你当前的问题向量,去跟记忆库里每条向量的相似度,挑出最像的三条。
-
对话生成:把这三条记忆加入提示词中,输入给大模型,再把新的对话存回记忆库。
可以总结为这样的流程:
你问问题 → 转成向量 → 跟记忆库比相似度 → 挑出最相关的 → 拼进 Prompt → 大模型回答 → 存下这条对话。
获取并接入API
01
这里以AIO通用智能服务平台为例。访问AIO通用智能服务平台注册账号
02
点击左上方控制台,进入数据看板
03
点击左侧令牌管理
04
点击添加令牌
05
在这里,只需要选择令牌分组即可,可选择

(额度可以在令牌管理界面编辑)
06
完成上述操作后,即可在令牌管理界面查看API了
配置基本python库
有了令牌,或者说密钥之后,就可以进行代码配置。

这里用了 python-dotenv 这个库,它会自动读取项目根目录下的 .env 文件。你只需要在里面写一行 `AIO_API_KEY=你的令牌`,代码里用 `os.getenv` 就能安全拿到,避免把密钥明文写在代码造成泄露。
- 涉及的 Python 知识点:`os` 模块读环境变量、`import` 管理依赖、安全编码习惯。
把记忆存进json文件里
我们助手的记忆库就是一个 memory.json 文件。每条记忆长这样:
json
{
"version": 1,
"records": [
{
"id": "20250411143022",
"role": "user",
"content": "我喜欢吃川菜",
"embedding": 0.012, -0.034, ...,
"timestamp": "2025-04-11T14:30:22.123456"
}
]
}
在每条记录里:
`id` 是时间戳生成的唯一标识。
`role` 记录是谁说的(`user` 或 `assistant`)。
`content` 是原话。
`embedding` 是这句话的向量表示,后面检索主要依靠和这些向量进行比对,相似度越高越容易采用。
`timestamp` 存下说话的时间,方便以后按时间清理。
读写文件的两个函数很简洁:

如果文件不存在,`load_memories` 会返回一个空列表,让程序继续跑下去而不是直接报错。
Python 知识点:`json` 模块读写、`with open` 上下文管理、`try...except` 异常处理、字典的 `get` 方法。
让文字变成数字:
调用AIO的Embedding接口
接下来是关键一步:把一句我们口中的命令变成一串机器能算的数字。我们直接调用 AIO 平台的现成接口。

请求头中用 Bearer Token 带上密钥,`payload` 里指定模型名称和要转换的文本。`raise_for_status()` 会在网络出问题或 API 返回错误时直接抛异常,方便调试。最后从返回的 JSON 里把向量数组抠出来。
-
Python 知识点:`requests.post` 发请求、字典构造、JSON 解析。
-
AGI 概念:Embedding 向量化------把非结构化文本映射成高维空间里的一个点,语义越近的文本,点在空间里靠得越近。
把每轮对话都存下来
每次用户说话或者 AI 回答后,我们都调这个函数把内容存进记忆库:

先读出现有记忆,给新内容生成向量,拼出一条新的记录塞进列表,最后写回文件。
Python 知识点:`datetime.now` 获取时间、`strftime` 自定义格式、`append` 追加列表元素、字典嵌套结构。
AGI 概念:记忆存储的结构设计。
计算两个向量的相似度
我们要比较当前问题和每条记忆的接近程度,这里用的是余弦相似度。公式不复杂:分子是点积,分母是两个向量模长的乘积。

不用 `numpy`,纯 Python 实现。`zip` 把两个向量的对应位置打包,生成器表达式直接喂给 `sum`,既简洁又省内存。
Python 知识点:`zip` 并行迭代、生成器表达式
AGI 概念:余弦相似度------衡量两个向量方向的一致性,值越接近 1 说明语义越像。
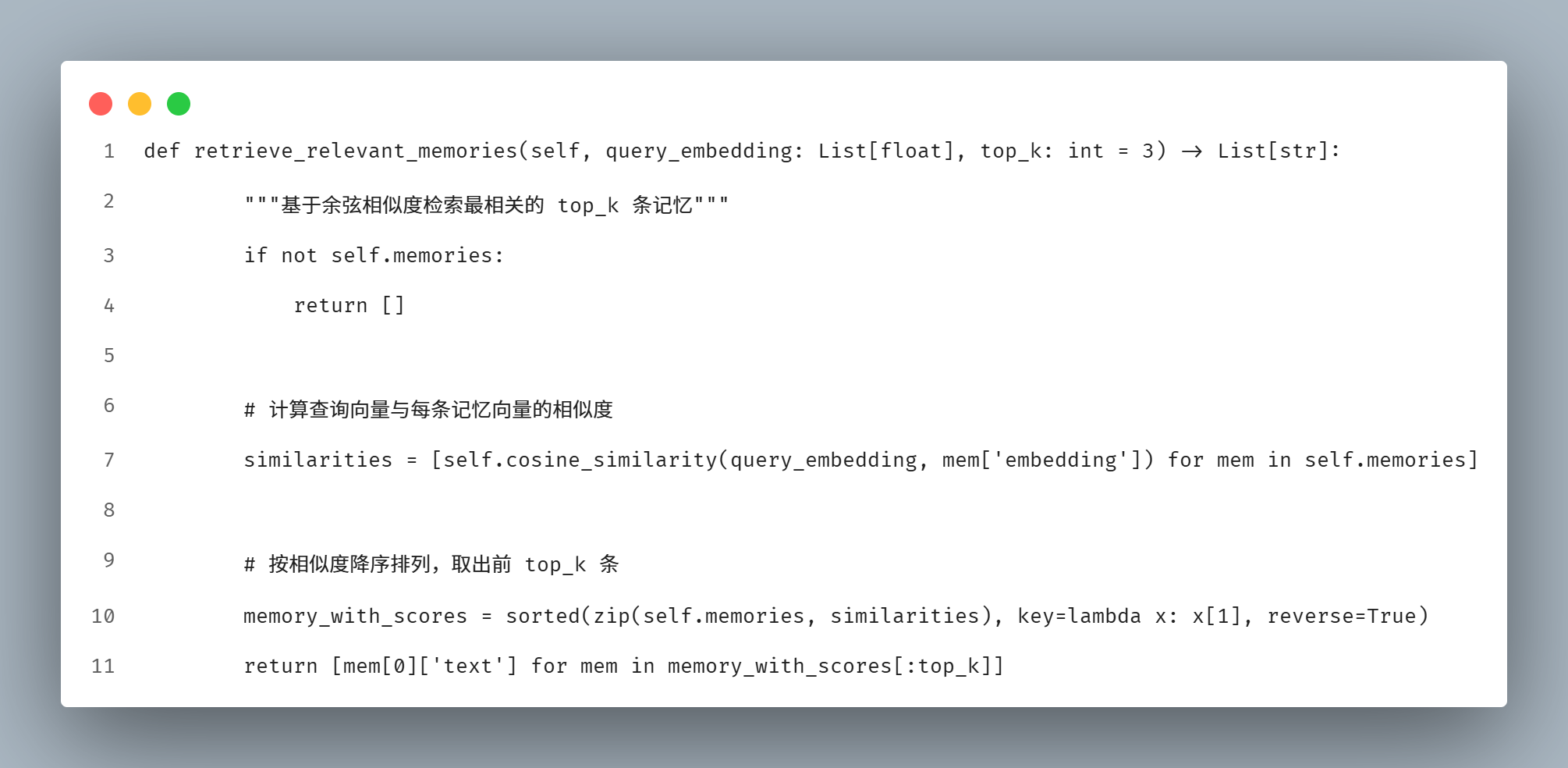
从记忆库中翻出最相关的几条
有了相似度计算,检索就水到渠成了:
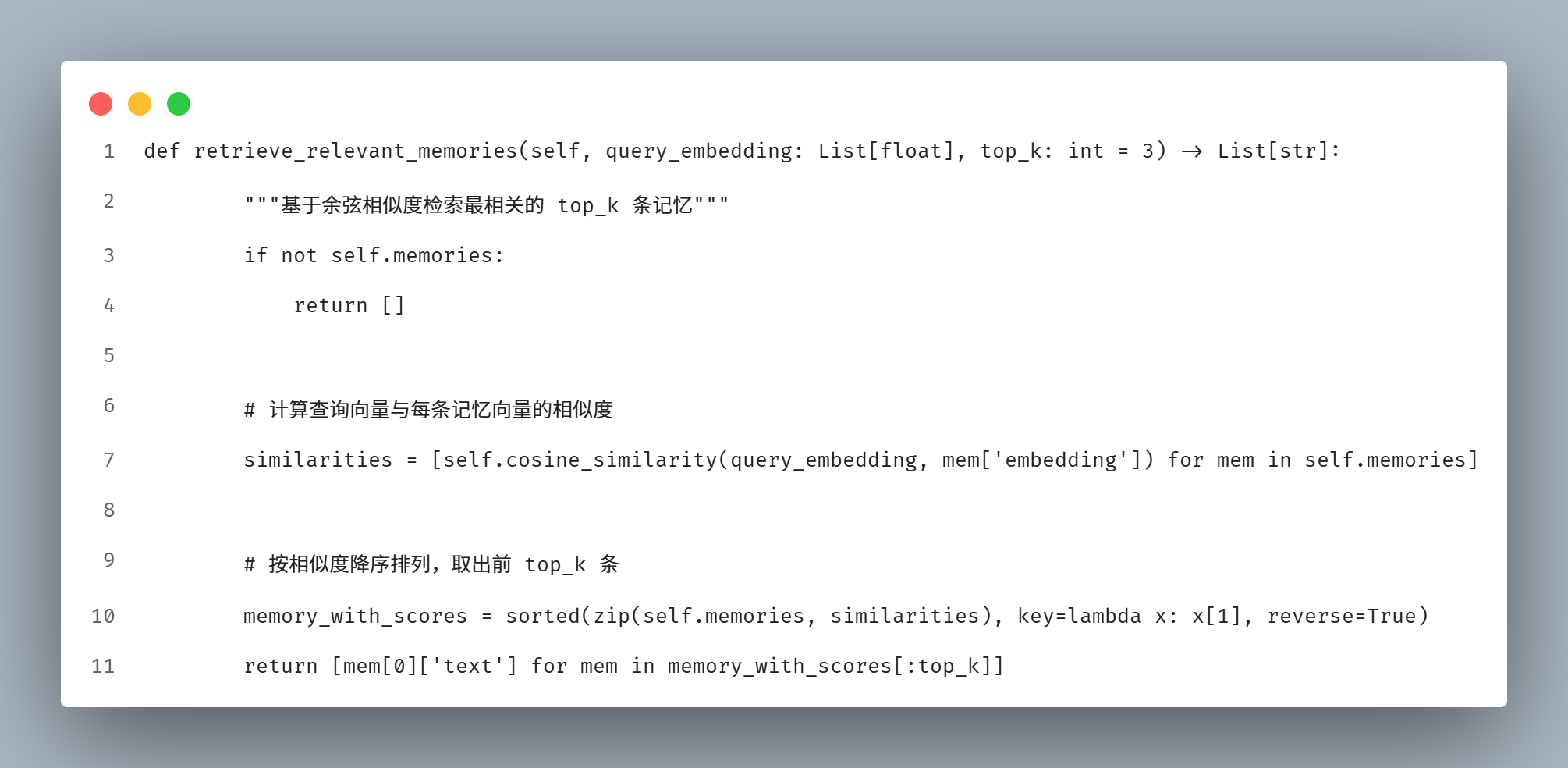
过程很直观:
加载记忆 → 给当前问题生成向量 → 挨个算相似度 → 按得分从高到低排 → 取前几条。
Python 知识点:列表推导式、`lambda` 匿名函数当排序依据、元组解包、列表切片。
AGI 概念:RAG 的检索环节------基于向量相似度做语义召回,而不是机械匹配关键词。
将检索结果返回大模型
现在,我们有了之前对话的"记忆碎片"。把前面捡出来的记忆拼进提示词,交给 AIO 的对话接口生成回答:
注意最后要把用户问题和 AI 的回答都存进记忆库,这样下一次才能检索到这一轮的内容。

Python 知识点:列表推导式格式化文本、`join` 拼接多行、f-string 多行模板、函数组合调用。
AGI 概念:RAG 的增强与生成环节------检索到的内容增强上下文,让大模型基于更丰富的背景信息作答。
搭建命令行对话入口
最后写个简单的循环,让你能在终端里直接跟助手聊天:

至此,我们完成了一个有记忆的AI对话chatbot,在之后的长对话中和它的对话会更加连贯、靠谱。

欢迎加入我们!