文章目录
- [核心概念区分:正则化 和 优化算法](#核心概念区分:正则化 和 优化算法)
- 第一部分:正则化家族(控制模型复杂度)
- 第二部分:优化算法家族(寻找损失最低点)
- Dropout和批量归一化
- 最终归纳
深度学习优化中两个根本不同的概念: 正则化 和 优化算法 。
核心概念区分:正则化 和 优化算法
-
常见的优化算法:
- SGD (随机梯度下降)
- SGD with Momentum
- RMSprop
- Adam
- AdamW
- Adagrad
- Adadelta
- Nesterov Accelerated Gradient
-
正则化方式:
- L1正则化
- L2正则化(权重衰减)
- Dropout
- Batch Normalization
- Layer Normalization
- Weight Clipping
-
学习率调度器:
- StepLR
- CosineAnnealingLR
- ReduceLROnPlateau
首先,我们必须明确一个根本区别:
-
正则化(如L1、L2、权重衰减) :其首要目标是改变模型本身 ,通过限制模型的复杂度(具体表现为参数的大小),来提高 其在未见数据(测试集)上的泛化能力 ,防止过拟合。
- 它影响的是"最终学到的模型是什么样子"。
-
优化算法(如SGD, Momentum, AdaGrad, Adam) :其首要目标是高效、稳定地找到损失函数的一个(局部)最小值。
- 它关注的是"如何更快、更好地走到山谷底部"。它不改变优化目标(损失函数)的本质。
在计算梯度时,它们在参数更新公式这一步骤上的表面相似性 ,但背后的目的、时机和数学含义完全不同。
第一部分:正则化家族(控制模型复杂度)
它们的共同点是在参数更新时,引入一个与参数值本身成正比的"衰减力"或"惩罚力" ,把参数值"拉向"零。
1. L2正则化(岭回归)
- 做法:在原始的损失函数 L(θ) 后面直接加一项:L_reg(θ) = L(θ) + (λ/2) * ||θ||²。这里 λ 是正则化强度,||θ||² 是所有参数平方和(L2范数)。
- 对梯度的影响 :计算新损失函数 L_reg 的梯度时,会多出一项 λ * θ。所以参数更新公式变为:
θ = θ - η * (∇L(θ) + λ * θ)
整理一下:θ = (1 - ηλ) * θ - η * ∇L(θ) - 效果:在每次更新时,先将参数缩小一点(乘以 1-ηλ),再沿着负梯度方向走。这强制让参数保持较小的绝对值,使模型更平滑,抗噪声能力更强。
2. 权重衰减
- 做法:不修改损失函数。直接在标准的参数更新步骤里,在梯度更新之后,额外对参数进行缩放。
θ = θ - η * ∇L(θ) - ηλ * θ
整理一下:θ = (1 - ηλ) * θ - η * ∇L(θ) - 与L2正则化的关系:对于标准的随机梯度下降(SGD),权重衰减在数学上完全等价于L2正则化(您可以看到上面两个公式最终一样)。所以文档说它"更直接",因为它跳过了修改损失函数这一步,直接在更新规则里实现了"衰减"。
- 注意:对于像Adam这样的自适应优化器,权重衰减和L2正则化不再严格等价,但目的相同------抑制参数增长。
3. L1正则化(套索回归)
- 做法:在损失函数后加一项:L_reg(θ) = L(θ) + λ * |θ|。这里 |θ| 是参数绝对值之和(L1范数)。
- 对梯度的影响:其梯度多出一项 λ * sign(θ)(sign是符号函数,θ>0时为1,θ<0时为-1)。更新公式类似:
θ = θ - η * ∇L(θ) - ηλ * sign(θ) - 效果:它不仅让参数变小,更关键的是,它倾向于产生稀疏解(即让很多不重要的参数直接变成0),起到了特征选择的作用。
小结:正则化的核心是 - ηλ * θ 或 - ηλ * sign(θ) 这项,它像一个始终指向零点的"拉力"。
第二部分:优化算法家族(寻找损失最低点)
它们的共同点是只关心如何利用梯度 ∇L(θ) 信息来更新参数,目标是更快、更稳地收敛。它们不会主动引入对参数值 θ 本身的惩罚。
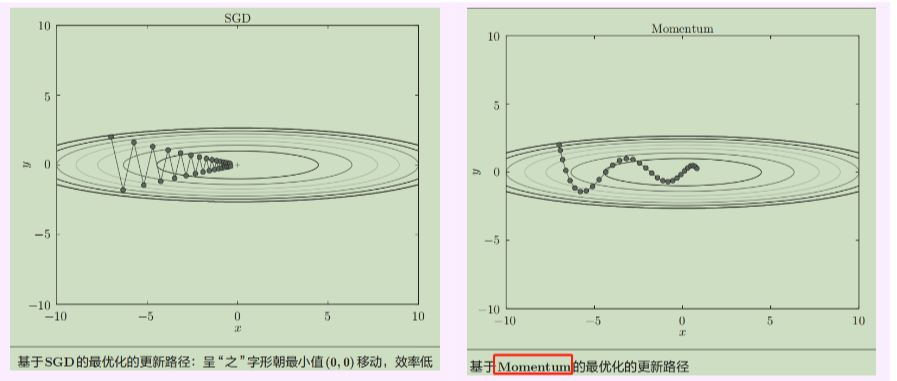
1. 随机梯度下降(SGD)
- 做法 :最基础的方法。参数沿着当前批数据计算出的负梯度方向更新。
θ = θ - η * ∇L(θ)
η 是学习率,是一个超参数,需要手动设定,且在训练中通常固定或按计划衰减。 - 问题:学习率选择困难;容易在沟壑方向震荡;收敛慢。
2. Momentum(动量)
- 目的:解决SGD在山谷中震荡、下降慢的问题。引入"惯性"思想。
- 做法 :不仅看当前梯度,还累积过去梯度的指数移动平均作为"速度" v 。
v = β * v + (1 - β) * ∇L(θ) (有的版本直接用 v = β * v + ∇L(θ))
θ = θ - η * v - 效果:在持续的方向上加速,在震荡的方向上抵消,从而更快、更稳地穿过平坦区域和沟壑。
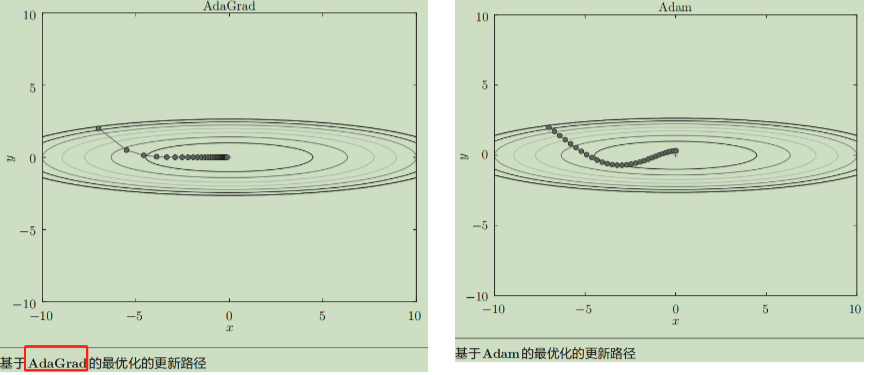
3. AdaGrad(自适应梯度)
目的 :为每个参数自适应地调整学习率。适合处理稀疏数据或特征尺度差异大的情况。
做法 :累积每个参数历史梯度的平方和 s 。用这个平方和来缩放每个参数的学习率。
s = s + ∇L(θ)²
θ = θ - η * ∇L(θ) / √(s + ε) (ε 防止除零)
效果:对于频繁更新(梯度大)的参数,s 变大,学习率自动减小;对于不频繁更新(梯度小)的参数,s 小,学习率相对较大。问题:s 会一直单调增长,导致后期学习率过小,提前停止学习。
4. Adam(Adaptive Moment Estimation)
-
目的:结合 Momentum(一阶矩) 和 AdaGrad(二阶矩) 的优点,成为目前最流行的默认优化器。
-
做法:
- 计算梯度的一阶矩(动量均值) m 和二阶矩(梯度平方的均值) v ,都使用指数移动平均。
m = β1 * m + (1 - β1) * ∇L(θ)
v = β2 * v + (1 - β2) * ∇L(θ)² - 对 m 和 v 进行偏差校正(因为初始为0)。
- 参数更新:θ = θ - η * m_hat / (√(v_hat) + ε)
- 计算梯度的一阶矩(动量均值) m 和二阶矩(梯度平方的均值) v ,都使用指数移动平均。
-
效果:像Momentum一样保持前进动力,同时又像AdaGrad那样为每个参数自适应调整步长,且避免了学习率过早衰减。
小结 :优化算法的核心是围绕梯度 ∇L(θ) 做文章,通过计算其动量、缩放其幅度等方式,设计更聪明的"下山策略"。它们不关心参数 θ 本身的大小。
总结与对比表
| 特性 | 正则化 (L1, L2, 权重衰减) | 优化算法 (SGD, Momentum, AdaGrad, Adam) |
|---|---|---|
| 首要目标 | 提高泛化能力,防止过拟合。控制模型复杂度。 | 加速训练,促进收敛。高效找到损失函数最小值。 |
| 作用对象 | 模型参数 (θ) 本身。施加一个指向零的力。 | 梯度 (∇L)。调整梯度的大小和方向用于更新。 |
| 数学本质 | 在优化问题中增加一个约束项(先验)。 | 求解无约束优化问题的数值迭代方法。 |
| 关键项 | -ηλ * θ 或 -ηλ * sign(θ) (与参数值成正比) | 基于 ∇L(θ) 构造的 v, s, m 等项。 |
| 超参数 | 正则化强度 λ。 | 学习率 η,动量系数 β,一阶矩系数 β1,二阶矩系数 β2 等。 |
| 关系 | 可以与任何优化算法结合使用。例如,你可以使用 SGD with Weight Decay,或者 AdamW(Adam with decoupled weight decay,一种更现代的将权重衰减与Adam结合的方式)。 |
最终回答您的问题:
L1、L2、权重衰减的"加减参数"是为了惩罚大参数 ,简化模型,属于正则化 。
Momentum、AdaGrad、Adam、SGD的"加入权重"是为了更好地利用梯度信息来指导更新方向/步长 ,属于优化算法 。
它们是深度学习训练中相辅相成的两个独立工具:优化算法决定"怎么走",正则化决定"不想走到某些地方(参数过大)"。在实际中,我们总是同时使用它们。
Dropout和批量归一化
此外对 Dropout(丢弃法) 和 批量归一化(Batch Normalization, BN) 进行分类和解释。
- Dropout:属于正则化技术
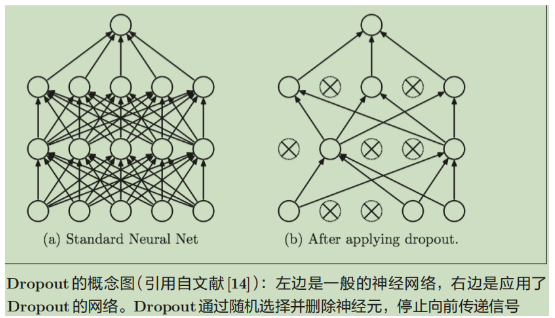
Dropout 是一种在训练阶段使用的、通过修改神经网络结构本身来防止过拟合的技术。
-
核心思想:在每次前向传播训练时,随机"丢弃"(即暂时屏蔽)网络中一部分神经元(如50%),让本次更新只在一个更瘦、随机的"子网络"上进行。
-
工作原理:
- 训练时:每个神经元以概率 p 被临时设置为零(不激活),其输出被缩放(通常乘以 1/(1-p) 以保持训练时输出的总期望值不变)。
- 预测时:使用完整的网络,所有神经元都激活,但权重需要乘以 1-p(如果训练时做了缩放,预测时则无需再调整)。
-
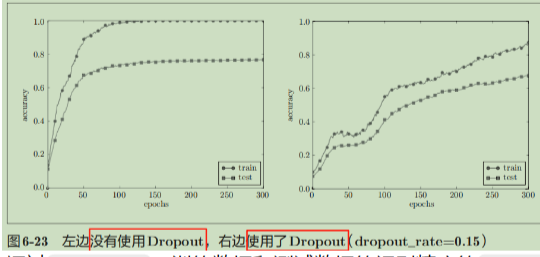
效果与目的:
- 打破协同适应:防止网络过度依赖某些特定的神经元或特征组合,迫使每个神经元都能独立地提供有用特征,从而增强模型的鲁棒性和泛化能力。
- 模型平均的近似:随机丢弃相当于训练了多个不同的子网络,预测时相当于这些子网络的"平均",这是一种高效的模型集成。
-
与权重衰减的区别:权重衰减直接惩罚参数值的大小,而 Dropout 是通过随机改变网络激活的路径来增加噪声,间接约束模型复杂度。它们从不同角度实现正则化。
- 批量归一化(Batch Normalization) :主要属于优化技术 ,但附带正则化效果
BN 是一种通过改变网络层输入的分布来加速训练、稳定学习过程 的技术。它的主要目标是优化,但其实现方式带来了轻微的正则化副作用。
• 核心思想 :对每一层的输入(即上一层的激活输出)进行归一化处理,使其均值为0、方差为1,然后再进行缩放和平移。
• 工作原理(训练时) :- 对于一个 mini-batch 的数据,计算该层输入的均值和方差。
- 用这个均值和方差对该批次的输入进行标准化。
- 引入两个可学习的参数(缩放因子 γ 和平移因子 β),对标准化后的值进行线性变换。这保证了网络的表达能力不会因归一化而下降。
- 主要效果与目的(作为优化技术) :
- 缓解内部协变量偏移:使每一层的输入分布更稳定,极大缓解了深度网络训练中的梯度消失/爆炸问题。
- 允许使用更高的学习率:训练过程更平稳,可以使用更大的学习率加速收敛。
- 降低对参数初始化的敏感度:网络对初始权重的选择不再那么脆弱。
- 附带的正则化效果 :
- 因为在训练时,每个批次的均值和方差都是基于该批次样本估计的,这给网络激活值引入了依赖于批次内其他样本的噪声。
- 这种噪声类似于 Dropout 和数据增强的效果,可以轻微提高模型的泛化能力。但在预测时,使用的是整个训练集上统计的固定均值和方差,所以这种正则化效果是有限的、非主要的。
总结对比
| 方法 | 主要类别 | 核心目标 | 作用阶段 | 如何工作 |
|---|---|---|---|---|
| Dropout | 正则化 | 防止过拟合,提高泛化能力 | 训练时随机丢弃神经元;预测时使用完整网络。 | 修改网络结构,增加噪声,打破神经元间的固定依赖。 |
| 批量归一化 | 优化技术(为主) | 加速训练,稳定收敛,允许高学习率 | 训练时用批次统计;预测时用全局固定统计。 | 标准化层输入,稳定分布。其引入的批次噪声带来次要的正则化效果。 |
- 其他常见的正则化与优化方法
其他方法
除了已讨论的,还有以下重要方法:
正则化方法(防止过拟合):
- 数据增强:对训练数据进行随机变换(如翻转、裁剪、旋转、颜色抖动等),人工扩大数据集,是最有效且直接的正则化手段。
- 早停:在训练过程中持续监控验证集性能,当性能不再提升时即停止训练,防止模型在训练集上过度优化。
- 标签平滑:在分类任务中,将硬标签(如 0, 0, 1)稍微软化(如 0.05, 0.05, 0.9),可以减少模型对正确标签的过度自信,提高泛化性。
优化技术(改善训练过程):
- 学习率调度:不是一种独立算法,而是策略。在训练中动态调整学习率(如步长衰减、余弦退火、热重启等),帮助模型更好地收敛。
- 梯度裁剪:当梯度超过某个阈值时,将其缩放回阈值内。常用于训练RNN等模型,防止梯度爆炸,稳定训练。
- 权重初始化:如 Xavier/Glorot 初始化、He 初始化等,正确的初始化能显著影响训练起点和收敛速度,是优化成功的前提。
最终归纳
在深度学习中,正则化技术(如权重衰减、Dropout、数据增强)和优化技术(如SGD/Adam、批量归一化、学习率调度)是相辅相成的两大工具箱。
- 你需要优化技术 来让模型高效、稳定地学习("快速下山")。
- 你需要正则化技术 来确保学到的模型不过于复杂和特异 ,能在新数据上表现良好("不去那些陡峭怪异的山谷")。
在实际应用中,通常会组合使用多种技术,例如:使用 AdamW(带解耦权重衰减的Adam)作为优化器,配合 批量归一化 来加速训练,同时在网络中加入 Dropout 层,并对输入图像进行 数据增强,最后用 早停 来决定训练轮数。