任务:对微博评论信息的情感分析,建立模型,自动识别评论信息的情绪状态。
数据集:simplifyweibo_4_moods.csv
其中label分别为: 0: '喜悦' 1: '愤怒' 2: '厌恶' 3: '低落'
这里加载的是腾讯词向量库: embedding_Tencent.npz(4760 * 200)
对此项目的分析:
1、目标:将评论内容转换为词向量,这里考虑分字,而不是分词,因为数据集共有12w+条数据,分词的话可能会翻倍,按照分字的话最多1w,新华字典中汉字最多9000个。
2、每个词/字转换为词向量长度(维度)200,采用的是腾讯词向量库。
3、每一次传入的词/字的个数是否就是评论的长度? 应该是固定长度,每次传入数据与图像相似。 这里选择长度为70。则传入的数据为70*200,如果想要模型精确度更高,则选择评论长度最长的。
4、一条评论如果超过70个词/字怎么处理? 直接删除后面的内容
5、一条评论如果没有70个词/字怎么处理? 缺少的内容,统一使用一个数字(非词/字的数字)替代。
6、如果语料库中的词/字太多是否可以压缩? 可以,某些词/字出现的频率比较低,可能训练不出特征。因此可以选择频率比较高的词来训练。这里选择4760个。
7、被压缩的词/字如何处理? 可以统一使用一个数字(非词/字的数字)替代。
接下来开始项目:
一、词表onehot建立
由于选择了腾讯词向量库,这里限制了词表长度为4760(0--4759),4760作为<UNK>,4761作为<PAD>,对于整理好的字典数据,这里通过pickle库来保存数据。;
python
from tqdm import tqdm #python第3方,显示进度条
import pickle as pkl #标准库,打包python数据
MAX_VOCAB_SIZE = 4760 # 词表长度限制
UNK,PAD = '<UNK>','<PAD>' #未知字,pOdding符号 今天天气真好,我明要去打球->今天天气真好,我<UINK>要去打球PAD><PAD><PAD>3
def build_vocab(file_path,max_size,min_freq):
'''
功能:基于文本内容建立词表vocab,vocab中包含语料库中的字
参数file_path:需要读取的语料库的路径
max_size: 获取词频最高的前max_size个词
min_freq: 剔除字频低于min_freq个的词
'''
'''
def tokenizer(x):
ls = []
for y in x
ls.append()
'''
tokenizer = lambda x:[y for y in x]
vocab_dict = {} #用于保存词的字典,统计每个字出现的次数,语料库中的字1w个,
with open(file_path,'r',encoding='UTF-8') as f:
i = 0
for line in tqdm(f): #用来显示循环的进度条
if i ==0: ##跳过文件种第1行表头内容
i+=1
continue
lin = line[2:].strip() ##获取评论内容,剔除标签。不用split分割,因为评论内容中可能会存在逗号。
if not lin: #如果lin中没有内容则continue
continue
for word in tokenizer(lin): #对每行评论进行分字,并统计每个字出现的次数
vocab_dict[word] = vocab_dict.get(word,0)+1 #get:查看字典vocab_dic是否存在word键,存在返回字典中键对应的值
vocab_list = sorted([_ for _ in vocab_dict.items() if _[1] > min_freq],key=lambda x: x[1],reverse=True)[:max_size]
vocab_dic = {word_count[0]:idx for idx,word_count in enumerate(vocab_list)}
vocab_dic.update({UNK:len(vocab_list),PAD:len(vocab_dic)+1})
print(vocab_dic)
pkl.dump(vocab_dic,open('simplifyweibo_4_mods.pkl','wb')) #现在我完成:统计了所有的文字,并将每一个独一无二的文字
print(f"vocab size:{len(vocab_dic)}") #将评论的内容,根据你现在词表vocab_dic,转换为词向量
return vocab_dic
if __name__=='__main__':
vocab = build_vocab('simplifyweibo_4_moods.csv',MAX_VOCAB_SIZE,3) #如果某个字在整个语料库中一共就出现3次
print('vocab')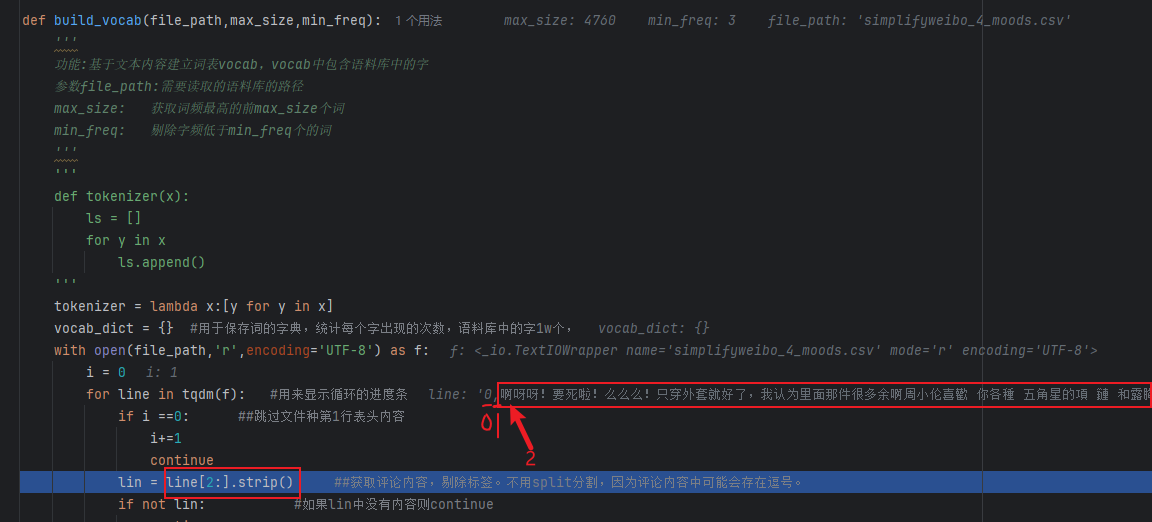
二、评论转换为独热编码+切分数据集+数据打包
首先需要对每条评论数据进行处理,长度超过70的只选取前70个字,未超过70的,补充<PAD>至70,其次通过上一步生成的simplifyweibo_4_mods.pkl文件,查询每个字的独热编码,将每条评论转化为独热编码,直至所有数据。
接下来打包数据(类似Dataloader),当对这个类DatasetIterater实例化的对象进行遍历时,这个类中要有def iter(self),def next(self)这两个方法才可以遍历。
python
from tqdm import tqdm
import pickle as pkl#
import random
import torch
UNK, PAD = '<UNK>', '<PAD>' # 未知字, padding符号
def load_dataset(path, pad_size=70):
contents = []#用来存储转换为数值标号的句子
vocab = pkl.load(open('simplifyweibo_4_mods.pkl', 'rb')) #读取vocab文件
tokenizer = lambda x: [y for y in x]#大模型的课程。
with open(path, 'r', encoding='UTF-8') as f:
i = 0
for line in tqdm(f):
if i ==0:
i += 1
continue
if not line: #是不是空行
continue
label = int(line[0])
content = line[2:].strip('\n')
words_line = []
token = tokenizer(content) # 将每一行的内容进行分字
seq_len = len(token) #获取一行实际内容的长度
if pad_size:#判断每条评论是否超过70个字
if len(token) < pad_size: # 如果一行的字少于70,则补充<PAD>
token.extend([PAD] * (pad_size - len(token)))
else: # 如果一行的字大于70,则只取前70个字
token = token[:pad_size] #如果一条评论种的字大于或等于70个字,索引的切分
seq_len = pad_size #当前评论的长度
# word to id
for word in token:
words_line.append(vocab.get(word, vocab.get(UNK)))#把每一条评论转换为独热编码
contents.append((words_line, int(label), seq_len))
random.shuffle(contents)#打乱顺序
train_data = contents[ : int(len(contents)*0.8)]#前80%的评论数据作为训练集
dev_data = contents[int(len(contents)*0.8) : int(len(contents)*0.9)]#把80%~90%的评论数据作为验证数据
test_data = contents[int(len(contents)* 0.9):]#90%~最后的数据作为测试数据集
return vocab, train_data, dev_data, test_data
class DatasetIterater(object):
'''将数据batches切分为batch_size的包。'''
def __init__(self, batches, batch_size, device):
self.batch_size = batch_size
self.batches = batches
self.n_batches = len(batches) // batch_size # 数据划分batch的数量
self.residue = False # 记录划分后的数据是否存在剩余的数据
if len(batches) % self.n_batches != 0: # 表示有余数
self.residue = True
self.index = 0
self.device = device
def _to_tensor(self, datas): # 自己定义的一个函数,并不是内置的函数功能
x = torch.LongTensor([_[0] for _ in datas]).to(self.device) # 评论内容
y = torch.LongTensor([_[1] for _ in datas]).to(self.device) # 评论情感
# pad前的长度(超过pad_size的设为pad_size)
seq_len = torch.LongTensor([_[2] for _ in datas]).to(self.device)
return (x, seq_len, y) # (([23,34,...,13],70),2)
# __getitem__:是通过索引的方式获取数据对象中的内容。__next__ p[3] 是使用 for i in train_iter: for i in p:
def __next__(self): # 用于定义迭代器对象的下一个元素。当一个对象实现了__next__方法时,它可以被用于创建迭代器对象。
if self.residue and self.index == self.n_batches: # 当读取到数据的最后一个batch:
batches = self.batches[self.index * self.batch_size: len(self.batches)]
self.index += 1
batches = self._to_tensor(batches) # 转换数据类型tensor
return batches
elif self.index > self.n_batches: # 当读取完最后一个batch时:
self.index = 0
raise StopIteration # 为了防止迭代永远进行,我们可以使用StopIteration(停止迭代)语句
else: # 当没有读取到最后一个batch时:
batches = self.batches[self.index * self.batch_size: (self.index + 1) * self.batch_size] # 提取当前bat
self.index += 1
batches = self._to_tensor(batches)
return batches
def __iter__(self):
return self
def __len__(self):
if self.residue:
return self.n_batches + 1
else:
return self.n_batches # dataload
if __name__=='__main__': #数据的预处理:1、将所有的评论都转换为独热编码,2、提取出 训练集、验证集、测试集。
vocab, train_data, dev_data,test_data = load_dataset('simplifyweibo_4_moods.csv')
print(train_data, dev_data,test_data )
print('结束')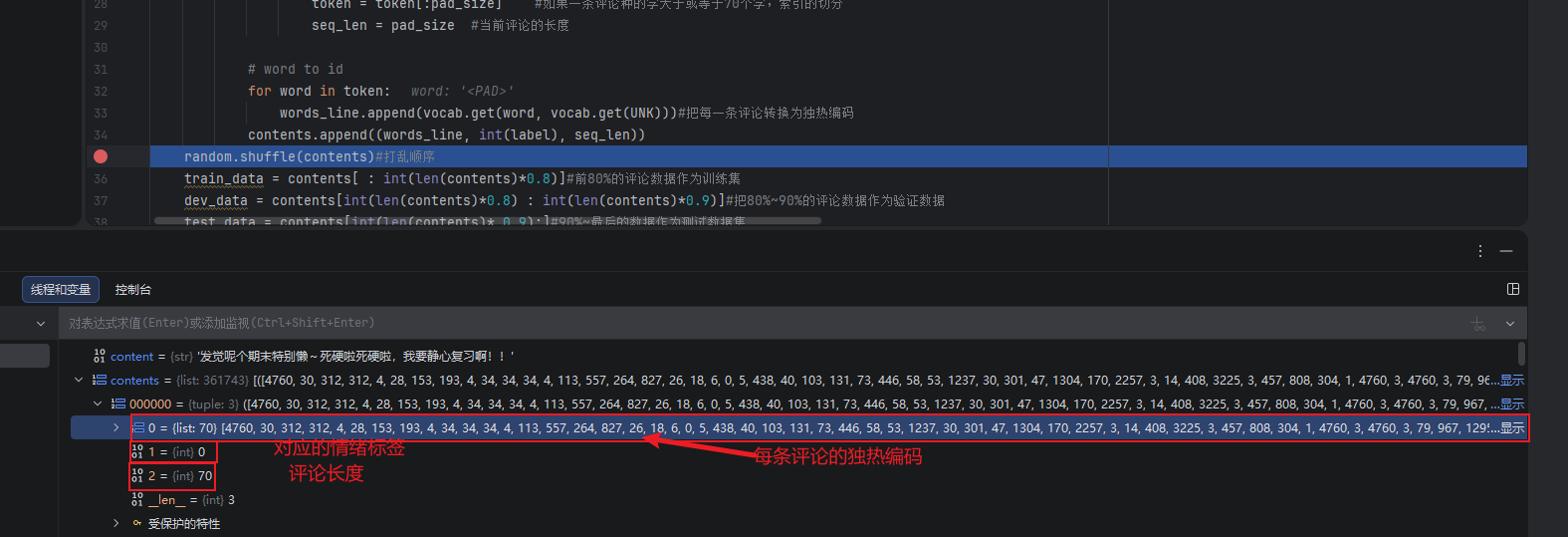
三、LSTM网络模型的构建

python
import torch.nn as nn
class Model(nn.Module): # 名字随意定义
'''
nn.LSTM 参数拆解
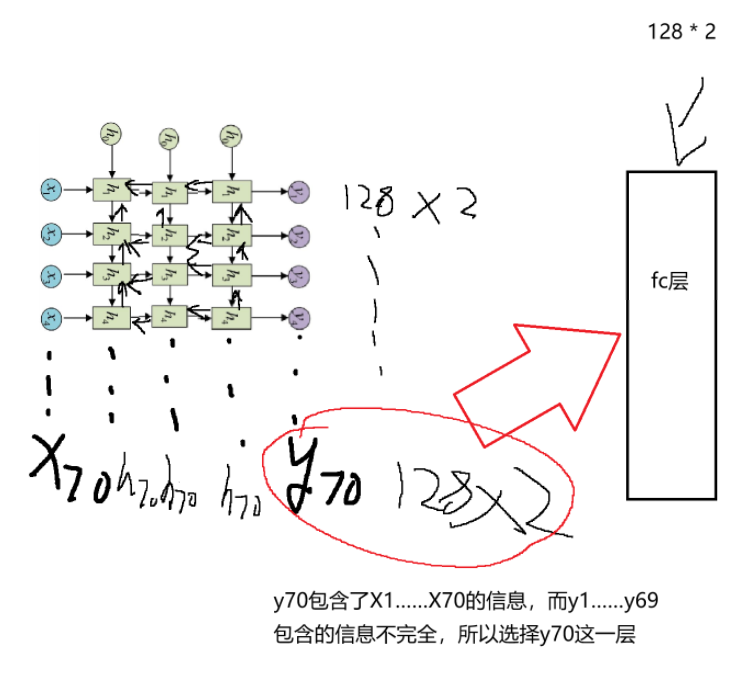
embed:输入特征维度(词向量维度,你这里是 200)
128:每一层 LSTM 的隐藏单元数(隐状态维度)
3:LSTM 的堆叠层数(3 层深层 LSTM)
bidirectional=True:双向 LSTM,最终隐状态维度会翻倍(128×2)
batch_first=True:输入张量形状为 (batch_size, seq_len, embed_dim),而非默认的 (seq_len, batch_size, embed_dim)
dropout=0.3:层间 Dropout,仅在多层 LSTM 的非最后一层生效
nn.Linear(128 * 2, num_classes) 为什么乘 2因为开启了双向 LSTM,前向和后向的隐状态会拼接在一起,所以输入全连接层的维度是 128×2,对应 4 分类任务的输出维度 num_classes=4
'''
def __init__(self, embedding_pretrained, n_vocab, embed, num_classes):
super(Model, self).__init__()
if embedding_pretrained is not None: # 4761 pad 告诉模型padding_idx是4761,如果没有预训练的词向量模型,那么就
self.embedding = nn.Embedding.from_pretrained(embedding_pretrained, padding_idx = n_vocab-1, freeze=False)
# freeze:指定是否冻结embeding层的权重。True则embedding层的权重在训练过程中
else:
self.embedding = nn.Embedding(n_vocab, embed, padding_idx = n_vocab - 1) # 如果新训练embedding使用本行
# padding_idx默认为None,如果指定,则padding_idx对应的参数PAD不会对梯度产生影响,因此在padding_idx处词嵌入向量在训
self.lstm = nn.LSTM(embed, 128, 3, bidirectional=True, batch_first=True, dropout=0.3)
# 128为每一层中每个隐状态中的U、W、V的神经元个数,resnet()
# 3为隐藏层 层的个数,batch_first=True表示输入和输出张量将以(batch, seq, feature) 而不是(seq, batch, feature)
# bidirectional = True:指定LSTM是双向的。网络会同时从前向后和从后向前处理输入序列,两个方向的输出结合起来。通常可以
# dropout = 0.3:这指定了在LSTM层中使用的dropout比例。Dropout是一种正则化技术,用于防止网络在训练过程中过拟合。在每个LSTM的输出上,都有
self.fc = nn.Linear(128 * 2, num_classes)
def forward(self,x):
x,_ = x #就是只提取评论的独热编码
out = self.embedding(x)
out,_ = self.lstm(out)
out = self.fc(out[:,-1,:])
return out四、训练+测试+验证
python
import torch
import torch.nn.functional as F
import numpy as np
from sklearn import metrics
def evaluate(class_list, model, data_iter, test=False):
# 验证集的处理
# class_list: ['喜悦', '愤怒', '厌恶', '低落']
model.eval() # 进入测试模型,将model的w设置为只读模式,w中的值都没被修改的权限,保护模型不被修改。
loss_total = 0
predict_all = np.array([], dtype=int)
labels_all = np.array([], dtype=int)
with torch.no_grad(): # 一个上下文管理器,关闭梯度计算。当你确认不会调用Tensor.backward()的时候。这可以减少计算所用内存消耗。
for texts, labels in data_iter:
outputs = model(texts) # 它就是输出。
loss = F.cross_entropy(outputs, labels)
loss_total += loss
labels = labels.data.cpu().numpy()
# torch.max(outputs.data, 1)[1].cpu().numpy() 代表的就是输出的结果
predic = torch.max(outputs.data, 1)[1].cpu().numpy()
labels_all = np.append(labels_all, labels)
predict_all = np.append(predict_all, predic)
acc = metrics.accuracy_score(labels_all, predict_all)
if test:
report = metrics.classification_report(labels_all, predict_all, target_names=class_list, digits=4)
return acc, loss_total / len(data_iter), report
return acc, loss_total / len(data_iter)
def train(model, train_iter, dev_iter, test_iter, class_list):
# 进入训练模式,启用 dropout、batch_norm 等训练特定层
model.train()
# 初始化优化器(Adam 优化器,学习率 1e-3)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
total_batch = 0 # 记录累计进行的 batch 数量
dev_best_loss = float('inf') # 初始化验证集最佳损失为无穷大
last_improve = 0 # 记录上次验证集 loss 下降的 batch 数
flag = False # 标记是否长时间未优化
epochs = 20 # 训练轮数
for epoch in range(epochs):
# 打印当前训练轮次
print('Epoch [{}/{}]'.format(epoch + 1, epochs))
# 遍历训练数据迭代器
for i, (trains,labels) in enumerate(train_iter):
# 经过DatasetIterater中的_to_tensor返回的数据格式为:(x,seq_len),y
# 模型前向传播,获取输出
outputs = model(trains)
# 计算交叉熵损失
loss = F.cross_entropy(outputs, labels)
# 梯度清零(避免梯度累积)
model.zero_grad()
# 反向传播,计算梯度
loss.backward()
# 更新模型参数
optimizer.step()
if total_batch % 100 == 0: # 每多少轮输出在训练集和验证集上的效果
predic = torch.max(outputs.data, 1)[1].cpu()
train_acc = metrics.accuracy_score(labels.data.cpu(), predic)
dev_acc, dev_loss = evaluate(class_list, model, dev_iter) # 将验证数据集传入模型
if dev_loss < dev_best_loss:
dev_best_loss = dev_loss
# 保存最优模型
torch.save(model.state_dict(), 'TextRNN.ckpt')
last_improve = total_batch # 保存最优模型的batch值
msg = 'Iter: {0:>6}, Train Loss: {1:>5.2}, Train Acc: {2:>6.2%}, Val Loss: {3:>5.2}, Val Acc: {4:>6.2%}'
print(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc))
model.train()
total_batch += 1
if total_batch - last_improve > 10000:
# 验证集loss超过10000 batch没下降,结束训练
print("No optimization for a long time, auto-stopping...")
flag = True
# 若触发早停,跳出外层训练循环
if flag:
break
test(model, test_iter, class_list)
import time
def test(model, test_iter, class_list):
# model.load_state_dict(torch.load('TextRNN.ckpt'))
model.eval() # 进入测试模式,w只有读的权限
start_time = time.time() # 当前的时间
test_acc, test_loss, test_report = evaluate(class_list, model, test_iter, test=True)
msg = 'Test Loss: {0:>5.2}, Test Acc: {1:>6.2%}'
print(msg.format(test_loss, test_acc))
print(test_report)五、主程序
python
import torch
import numpy as np
import load_dataset, TextRNN
from train_eval_test import train
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
np.random.seed(1) # np.random.seed:用于设置随机数生成器的种子。
torch.manual_seed(1) # torch.manual_seed是用于设置PyTorch中随机数生成器的种子的函数。它将为当前进程设置一个随机种子。
torch.cuda.manual_seed_all(1) # 是用于设置所有CUDA设备的随机种子的函数。它将为每个CUDA设备设置相同的随机种子,以确保在不同的运行中获
torch.backends.cudnn.deterministic = True
# torch.backends.cudnn.deterministic:用于控制使用cudnn库时的算法是否确定。如果将这个标志设置为True,每次返回的卷积算法将是确定的,
# 如果配合上设置Torch的随机种子为固定值的话,可以保证每次运行网络的时候输入是固定的。
vocab, train_data, dev_data, test_data = load_dataset.load_dataset('simplifyweibo_4_moods.csv')
train_iter = load_dataset.DatasetIterater(train_data, 128, device) # 128条数据打包。
dev_iter = load_dataset.DatasetIterater(dev_data, 128, device)
test_iter = load_dataset.DatasetIterater(test_data, 128, device)
embedding_pretrained = torch.tensor(np.load('embedding_Tencent.npz')["embeddings"].astype('float32'))
# embedding_pretrained = None # 不使用外部训练的词向量。
embed = embedding_pretrained.size(1) if embedding_pretrained is not None else 200 # 词向量200
class_list = ['喜悦', '愤怒', '厌恶', '低落']
num_classes = len(class_list)
model = TextRNN.Model(embedding_pretrained, len(vocab), embed, num_classes).to(device)
train(model, train_iter, dev_iter, test_iter, class_list)