Kdoctor 使用
一、Kdoctor 介绍

1、Kdoctor 诞生背景
为什么做这样一个工具?
其实说来惭愧,原因就一个:Kafka 实际生产排障经验不足。
前段时间碰到了很多 Kafka 的问题,而Kafka服务问题排查起来特别耗费时间,如果你无法快速的定位问题、发现问题,那么哪怕你分析问题的大模型再厉害,找不到问题那又谈何解决呢?
当你们后端大哥或者用户,告诉你们服务出了问题,一查日志看到一大堆Kafka问题,而后端服务日志指向性又不明显的时候,那么压力就全都给到你了,如何快速查询问题就变得重要起来,你总不能直接把运行日志全copy下来,直接甩给AI吧(虽然我偶尔这么干),但是实际起到的意义并不大。
所以,Kdoctor,就是一个单纯查问题的软件,你可能只知道一个 broker 的地址,就可以查看Kafka当前可能存在的所有问题。
在最开始的时候,我是想使用AI去解决问题的,但是无论使用mcp还是skills,都让我觉得有些差强人意,当然可能是我定义的Skills不咋地,才出现的这样的问题。SO,我换了个思路,我就先不用AI去解决问题,我先用 AI 帮我写一个去排查kafka问题的脚本工具,然后工具执行完一轮之后输出存在的问题,然后让AI直接对问题进行分析,这样效率就起来了,于是就开始干了(本工具未完成后续对AI的对接,自己写个skills让AI调用脚本就行了)。
(codex 干了两个账号的一周额度,撸了2w行代码,ChatGPT 深度研究8次,四天,搓出来了这个工具)
代码开源:https://github.com/isYaoNoistu/Kdoctor.git
详细使用说明: https://github.com/isYaoNoistu/Kdoctor/blob/main/USER_GUIDE.md
检查基线:https://github.com/isYaoNoistu/Kdoctor/blob/main/CHECK_BASELINE.md
2、设计理念
Kafka 的问题很容易"看起来像一个问题,实际上是另一层的问题"。
比如:
- 端口能通,但
advertised.listeners返回了错误地址 metadata能拿到,但 leader 落在了客户端不可达的 broker 上- 容器明明是
Up,但 controller listener 配错了 - 业务说"消息发不进去",最后根因其实在
ISR、内部主题、ACL,或者宿主机 / Docker / 日志层
如果每次都要手工拼:
nckafka-topics.shdocker psdocker inspectdocker logs
排障成本很高,而且不同人查同一个问题,路径也不一样。
所以这个工具的目标一直很克制:不是替代 Kafka 运维,而是帮一线值班人员更快走到"更像哪一层出问题"。
Kdoctor 从设计开始就没有往平台方向做。
它不是:
- Kafka 管理后台
- 监控告警平台
- 自动修复系统
- CMDB 或资产系统
它就是一个单二进制脚本工具。
你可以只给它一个地址:
bash
./kdoctor probe --bootstrap 192.168.1.1:9192也可以逐步补上下文:
bash
./kdoctor probe --config ./kdoctor.yaml
./kdoctor probe --config ./kdoctor.yaml --compose ./docker-compose.yml输入越完整,它给出的结论越接近真实部署上下文;输入很少时,它也能先跑出一版基础判断。
3、Kdoctor 能查什么
从能力边界上看,Kdoctor 不是只做端口探测,也不是只做静态配置审计,而是把几条最常见的 Kafka 排障链路串了起来:
(1)网络与入口问题
bootstrap本身是不是可达metadata返回的 broker 地址是不是可达- 返回地址是不是和当前执行视角匹配
listeners / advertised.listeners有没有明显配置错误
(2)Kafka 控制面与 Topic / ISR
- broker 是否全部注册
- controller / quorum 配置是否一致
- leader 是否存在
- ISR 是否健康
- 内部主题是否合理
- topic 规划是否明显失衡
(3)真实客户端链路
它会真正去跑:
- metadata
- produce
- consume
- commit
- end-to-end probe
这也是它和很多"只读配置、只看 metadata"工具最大的不同。
(4)Docker、宿主机和日志补证据
如果当前执行节点还能看到 Docker、宿主机和日志,它还会补:
- 容器运行态、OOM、重启、挂载
- 宿主机磁盘、端口、fd、内存
- 日志样本质量、错误指纹、聚合上下文
二、使用案例
下面这部分不是设计描述,而是一次真实环境中的使用记录。 这些命令和结果都来自实际跑出来的数据。
1、测试环境说明
本次测试环境是一套 3 broker + KRaft + docker-compose 的内网部署,关键节点如下:
- broker:
192.168.119.7:9192 / 9194 / 9196 - controller:
192.168.119.7:9193 / 9195 / 9197 - 部署方式:
docker-compose - 配置文件:
kdoctor.yaml
这也意味着,这次案例既能覆盖最小输入模式,也能覆盖 config + compose 的增强模式。
2、只有一个地址时
最小输入命令:
bash
./kdoctor probe --bootstrap 192.168.119.7:9192实际输出:
text
模式:链路探针
配置模板:master-internal-kraft-prod
总体状态:跳过
检查时间:2026-04-20 17:08:41+08:00
耗时:2555ms
Broker 存活:3/3
检查统计:严重 0 / 失败 0 / 告警 0 / 错误 0 / 通过 49 / 跳过 14
概览:本次共执行 63 项检查,最高状态为 跳过,未识别出足够明确的单一主因,请结合重点问题继续排查。
证据覆盖:
- 网络=已获取证据
- Compose=未纳入本次运行
- Kafka=已获取证据
- 消费组=未纳入本次运行
- Docker=已获取证据
- 宿主机=已获取证据
- 日志=已获取证据
- 探针=已执行
重点问题:
- 当前没有需要立即处理的 FAIL/WARN/ERROR 明细这一步说明了三件事:
- 最小输入模式本身是可用的,不需要先准备一堆资料。
- 当前内网
bootstrap、metadata 和 probe 主链路都是通的。 - 这套环境没有在第一轮巡检里暴露出硬故障。
不过它也有边界:
- 还没有拿到
compose里的静态配置 - 也就还看不到
listeners、authorizer、挂载规划这类更深一层的问题
所以,这一步适合做"第一刀",但还不适合做"最后结论"。
3、使用配置文件
在最小输入的基础上,继续补 kdoctor.yaml:
yaml
version: 2
default_profile: master-internal-kraft-prod
profiles:
master-internal-kraft-prod:
bootstrap_external:
- "192.168.119.7:9192"
- "192.168.119.7:9192"
- "192.168.119.7:9192"
bootstrap_internal:
- "192.168.119.7:9192"
- "192.168.119.7:9194"
- "192.168.119.7:9196"
controller_endpoints:
- "192.168.119.7:9193"
- "192.168.119.7:9195"
- "192.168.119.7:9197"
broker_count: 3
expected_min_isr: 2
expected_replication_factor: 3
execution_view: "internal"
security_mode: "plaintext"
producer:
acks: "all"
enable_idempotence: true
retries: 3
max_in_flight: 5
delivery_timeout_ms: 120000
request_timeout_ms: 30000
linger_ms: 0
expected_durability: "strong"
consumer:
max_poll_interval_ms: 300000
session_timeout_ms: 45000
heartbeat_interval_ms: 15000
auto_offset_reset: "latest"
isolation_level: "read_uncommitted"
logs:
enabled: true
tail_lines: 800
lookback_minutes: 60
min_lines_per_source: 5
probe:
enabled: true
topic: "_kdoctor_probe"
timeout: "15s"
message_bytes: 1024然后执行:
bash
./kdoctor probe --config ./kdoctor.yaml实际输出:
text
模式:链路探针
配置模板:master-internal-kraft-prod
总体状态:跳过
检查时间:2026-04-20 17:09:32+08:00
耗时:2532ms
Broker 存活:3/3
检查统计:严重 0 / 失败 0 / 告警 0 / 错误 0 / 通过 50 / 跳过 13
概览:本次共执行 63 项检查,最高状态为 跳过,未识别出足够明确的单一主因,请结合重点问题继续排查。
证据覆盖:
- 网络=已获取证据
- Compose=未纳入本次运行
- Kafka=已获取证据
- 消费组=未纳入本次运行
- Docker=已获取证据
- 宿主机=已获取证据
- 日志=已获取证据
- 探针=已执行
重点问题:
- 当前没有需要立即处理的 FAIL/WARN/ERROR 明细这一轮和"只给一个地址"相比,状态没有变化,但意义不一样了:
Kdoctor已经不只是按默认逻辑判断,而是开始按这套环境自己的 broker 数、ISR、RF、producer/consumer 基线来判断。- 这意味着后续如果真出问题,工具给出的结果会更贴近这套环境的实际标准,而不是泛化标准。
换句话说,这一步的价值不在于"多出了一条告警",而在于判断开始有了环境语境。
4、再叠加 compose
当 Kafka 是 docker-compose 部署时,这一步通常最关键:
bash
./kdoctor probe --config ./kdoctor.yaml --compose ./docker-compose.yml实际输出:
text
模式:链路探针
配置模板:master-internal-kraft-prod
总体状态:告警
检查时间:2026-04-20 17:10:39+08:00
耗时:2612ms
Broker 存活:3/3
检查统计:严重 0 / 失败 0 / 告警 1 / 错误 0 / 通过 76 / 跳过 8
概览:本次共执行 85 项检查,最高状态为 告警。已识别 1 个优先级较高的主因,请优先按建议动作顺序处理。
证据覆盖:
- 网络=已获取证据
- Compose=已获取证据
- Kafka=已获取证据
- 消费组=未纳入本次运行
- Docker=已获取证据
- 宿主机=已获取证据
- 日志=已获取证据
- 探针=已执行
主因判断:
- 高优先级主因:安全协议、SASL/TLS 或授权配置与当前执行视角不一致,这类问题常表现为端口可达但 metadata、认证或 ACL 行为异常。
建议动作:
- 如果集群需要 ACL,请启用 StandardAuthorizer
- 确认当前环境是否允许无 ACL 运行
- 把授权策略纳入后续 V2 安全域基线
重点问题:
- [告警] SEC-005 安全:当前未配置 Authorizer,ACL 拒绝类问题将无法被治理
核心证据:
- 服务=kafka1 未配置 authorizer.class.name
- 服务=kafka2 未配置 authorizer.class.name
- 服务=kafka3 未配置 authorizer.class.name
下一步:
- 如果集群需要 ACL,请启用 StandardAuthorizer
- 确认当前环境是否允许无 ACL 运行
- 把授权策略纳入后续 V2 安全域基线这是整篇案例里最有代表性的一次运行。
原因很简单:
- 前两步只能说明"这套集群当前能用"
- 补上
compose之后,工具才真正看到了部署方式背后的结构信息
最终发现的不是运行故障,而是一个治理层面的缺口:
- 当前未配置
Authorizer - 如果未来需要做 ACL,这里会成为一个明确短板
也就是说,这次结果不是"Kafka 出了问题",而是:
- 主链路正常
- 集群可用
- 但安全治理还没有补齐
这类结果在生产现场其实很常见,也很有价值,因为它能把"故障"和"治理问题"区分开。
5、常用模式的实际差异
同一套环境里,quick / probe / lint / incident 的表现并不一样。
下面是实际跑出来的结果。
5.1 quick
bash
./kdoctor quick --bootstrap 192.168.119.7:9192实际输出:
text
模式:快速巡检
配置模板:master-internal-kraft-prod
总体状态:跳过
检查时间:2026-04-20 17:12:32+08:00
耗时:809ms
Broker 存活:3/3
检查统计:严重 0 / 失败 0 / 告警 0 / 错误 0 / 通过 44 / 跳过 19
证据覆盖:
- 网络=已获取证据
- Compose=未纳入本次运行
- Kafka=已获取证据
- 消费组=未纳入本次运行
- Docker=已获取证据
- 宿主机=已获取证据
- 日志=已获取证据
- 探针=未纳入本次运行结果说明:
quick的重点是低成本巡检- 它不会执行真实 probe
- 适合"先看一眼环境有没有明显异常"
5.2 probe
bash
./kdoctor probe --bootstrap 192.168.119.7:9192实际输出:
text
模式:链路探针
配置模板:master-internal-kraft-prod
总体状态:跳过
检查时间:2026-04-20 17:12:56+08:00
耗时:2488ms
Broker 存活:3/3
检查统计:严重 0 / 失败 0 / 告警 0 / 错误 0 / 通过 49 / 跳过 14
证据覆盖:
- 网络=已获取证据
- Compose=未纳入本次运行
- Kafka=已获取证据
- 消费组=未纳入本次运行
- Docker=已获取证据
- 宿主机=已获取证据
- 日志=已获取证据
- 探针=已执行结果说明:
probe比quick慢一些- 但它换来的是"真实客户端路径已经跑过"的把握
- 适合用来回答"服务现在到底通不通"
5.3 lint
bash
./kdoctor lint --config ./kdoctor.yaml --compose ./docker-compose.yml实际输出:
text
模式:配置审计
配置模板:master-internal-kraft-prod
总体状态:告警
检查时间:2026-04-20 17:13:28+08:00
耗时:875ms
Broker 存活:3/3
检查统计:严重 0 / 失败 0 / 告警 1 / 错误 0 / 通过 71 / 跳过 13
主因判断:
- 高优先级主因:安全协议、SASL/TLS 或授权配置与当前执行视角不一致
重点问题:
- [告警] SEC-005 安全:当前未配置 Authorizer结果说明:
lint更适合新环境验收、变更后核对、上线前静态巡检- 它不强调真实链路,而强调"配置结构有没有问题"
- 在这套环境里,它非常准确地把问题收敛到了
SEC-005
5.4 incident
bash
./kdoctor incident --config ./kdoctor.yaml --compose ./docker-compose.yml实际输出:
text
模式:战时排障
配置模板:master-internal-kraft-prod
总体状态:告警
检查时间:2026-04-20 17:14:04+08:00
耗时:2595ms
Broker 存活:3/3
检查统计:严重 0 / 失败 0 / 告警 1 / 错误 0 / 通过 76 / 跳过 8
概览:已锁定主因:高优先级主因:安全协议、SASL/TLS 或授权配置与当前执行视角不一致。;建议优先动作:如果集群需要 ACL,请启用 StandardAuthorizer结果说明:
incident和probe不是简单的"多跑几项"- 它更偏向战时使用,重点是直接给主因和动作
- 如果你在值班现场,通常会更愿意先看这个模式的输出
6、JSON 和 Markdown 输出
除了终端输出,实际使用里还会遇到两个很现实的需求:
- 给系统消费
- 给人留档
6.1 JSON 输出
实际效果如下:
bash
./kdoctor probe --bootstrap 192.168.119.7:9192 --format json --output ./report.json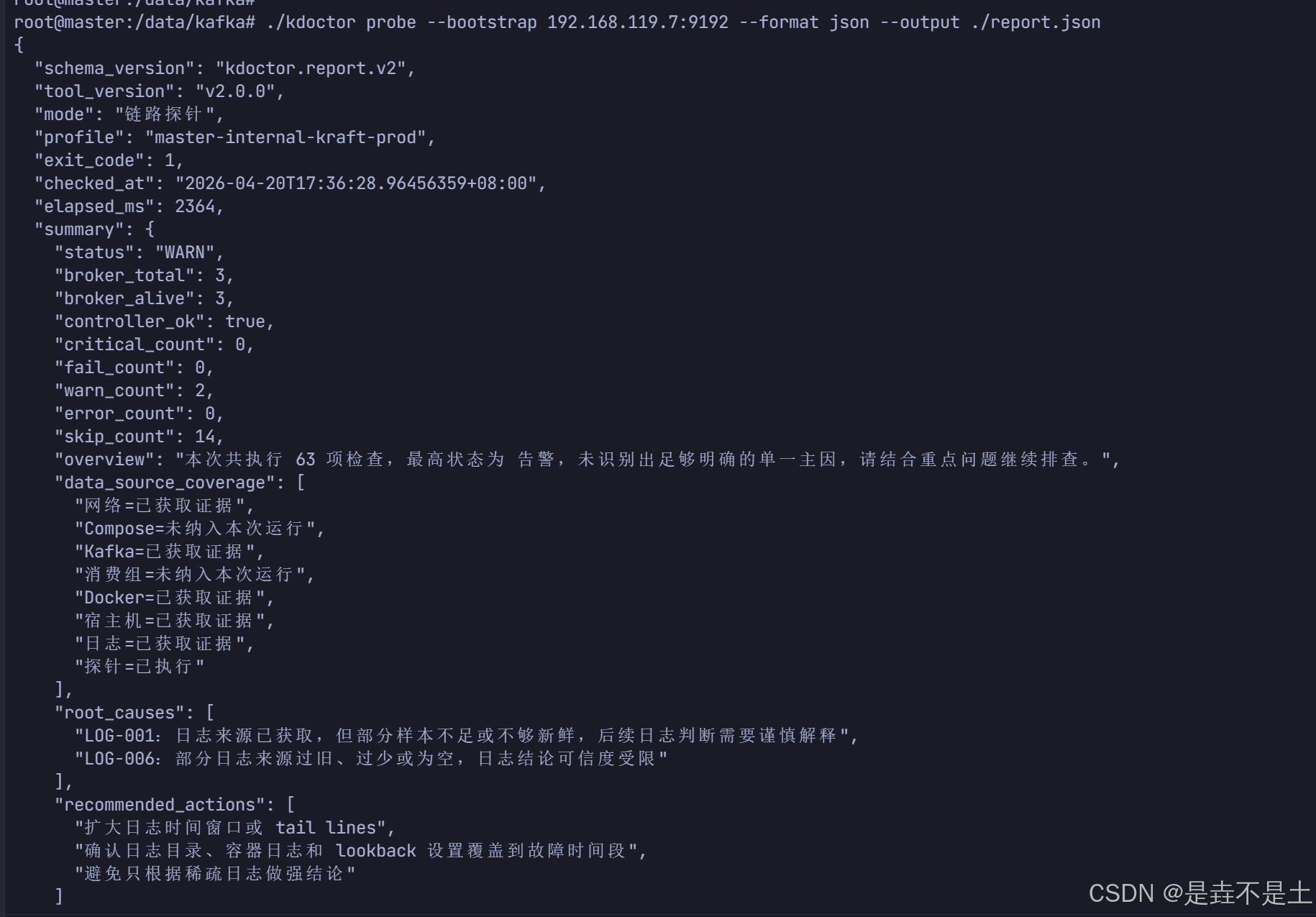
这一类输出更适合:
- 接自动化
- 写平台接口
- 做二次解析
6.2 Markdown 输出
实际效果如下:
bash
./kdoctor probe --bootstrap 192.168.119.7:9192 --format markdown --output ./report.md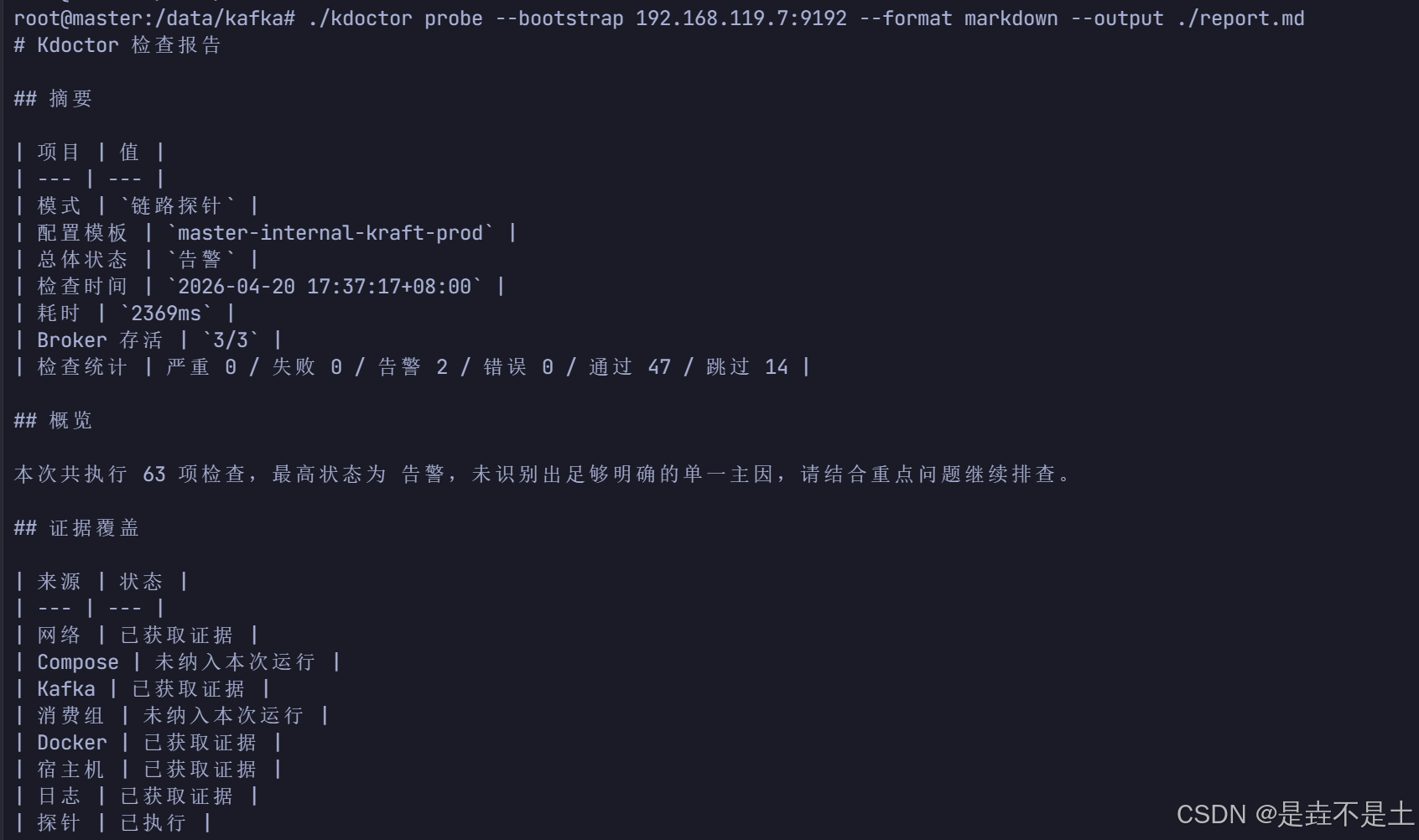
这一类输出更适合:
- 留档
- 工单
- 巡检记录
- 复盘材料
三、怎么理解这组真实结果
光看命令和输出还不够,真正有价值的是把这些结果串起来。
1、为什么前两次是"跳过",但并不是故障
第一次和第二次运行,虽然总体状态显示"跳过",但没有任何 FAIL/WARN/ERROR。
这里的"跳过"更准确的含义是:
- 不是环境异常
- 而是本次运行里还有部分检查没有纳入
比如:
compose侧配置检查还没进来- 消费组目标没配
- 某些增强型检查没有证据来源
所以,这里的"跳过"更像"上下文还不完整",不是"系统有问题"。
2、为什么叠加 compose 后,状态变成了"告警"
因为这时候工具终于拿到了:
listener.security.protocol.mapauthorizer.class.namecontroller.quorum.voters- 数据目录、挂载规划、节点角色信息
它不再只是回答"能不能连上 Kafka",而开始回答:
- 这套部署方式是不是完整
- 这套安全策略是不是成型
- 这套配置是不是可治理
于是,SEC-005 这种"运行没坏,但治理还不到位"的问题就被看见了。
3、这套环境的真实结论
从这组实际结果里,我认为最准确的结论是:
- Kafka 主链路可用
- broker、controller、topic、probe 基本都正常
- 当前没有硬故障
- 但安全治理层存在一个明确提示:未配置
Authorizer
这其实正好说明了 Kdoctor 的价值:
- 它不是只会报故障
- 它也能把"当前可用,但治理有缺口"的状态说清楚
而这恰恰是很多生产现场最需要的判断。
四、Kdoctor 适合怎么用
1、推荐使用顺序
如果是第一次接环境,我建议按这个顺序使用:
先跑最小输入:bootstrap-only
再补 kdoctor.yaml
再补 docker-compose.yml,当然如果不是拿compose部署的,后续会更新
最后再看日志、Docker、宿主机增强证据
这个顺序的好处是非常明显的:
- 先判断主链路能不能通
- 再判断环境基线合不合理
- 最后再判断部署和运行态有没有偏差
2、这类工具最适合的场景
我觉得它最适合这些场景:
- Kafka 刚出问题,先做第一轮收敛
- 新环境刚搭好,先做一轮巡检
- 变更刚结束,想快速核对部署配置
- 后端只告诉你"消息发不进去 / 消费不到",需要先判断更像哪一层
- 你不想一上来就手工敲一堆 Kafka 命令
五、最后
我一直不太想把 Kdoctor 写成"又一个功能列表很长的 Kafka 工具"。
真正让我在意的是:
- 它是不是能拿起来就用
- 输出是不是能帮助值班人快速排序
- 会不会制造太多误报
- 结论是不是尽量基于真实证据
从这组真实环境的使用结果看,它至少已经证明了一件事:它不一定替你解决所有问题,但它确实能明显缩短你走到正确方向的时间。
对一线排障来说,这已经非常值得了。