本文严格基于 MIT/Adobe 的《One-step Diffusion with Distribution Matching Distillation》原论文,专门补全所有你在看论文时会卡住的基础数学细节:从最基础的概率密度、梯度、期望,到分数函数的线性等价性、KL 散度的梯度推导,再到雅可比矩阵的作用。所有推导不跳步,所有符号都有明确解释,帮你彻底打通 DMD 的数学逻辑。
很多人看 DMD 论文的时候,都有这样的感受:看懂了 "双损失 + 双扩散模型" 的框架,也看懂了实验结果有多震撼,但一到 3.2 节的数学推导部分就直接懵了。满屏的∇、E、s (x_t)、D_KL,每个符号好像都认识,但组合在一起就不知道是什么意思,更不知道为什么这么推导。
这篇博客就是为了解决这个问题。我会从最基础的数学定义开始,一步步拆解 DMD 的核心数学原理,所有内容都严格对应原论文的公式和符号,不引入任何外部无关理论。看完这篇,你不仅能看懂原论文的所有推导,还能真正理解 DMD 为什么能做到 "一步生成媲美 50 步 Stable Diffusion"。
论文原文:https://arxiv.org/abs/2311.18828
如果想要了解论文中的大致实现框架的可以移步至:

篇幅较长,欢迎大家点赞收藏,我也会持续更新更多AIGC相关文章。
一、前置基础:原论文所有核心符号定义
先把论文里所有会用到的核心符号一次性讲清楚,这是看懂所有推导的前提。
表格
| 符号 | 严格定义 | 直观意义 |
|---|---|---|
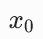 |
原始干净图像 | 真实世界中的照片,或者原始扩散模型生成的干净图像 |
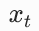 |
带噪声的图像, 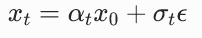 |
给干净图像加入 t 步高斯噪声后得到的图像 |
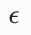 |
高斯噪声,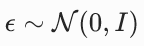 |
前向扩散过程中加入的纯噪声 |
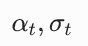 |
预定义的噪声调度参数,满足 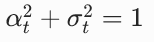 |
控制不同时间步加入的噪声强度,t 越大,σ_t 越大,噪声越强 |
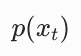 |
带噪声图像 x_t 的概率密度函数 | 随机采样一张带噪声图像,它正好是 x_t 附近的可能性大小 |
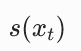 |
分数函数,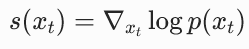 |
对数概率密度的梯度,指向概率密度增加最快的方向 |
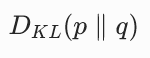 |
KL 散度,衡量用分布 q 近似分布 p 时损失的信息量 | 两个分布之间的 "距离",值越大,两个分布差异越大 |
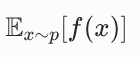 |
期望,函数 f (x) 在分布 p 下的加权平均值 | 从分布 p 中采样大量样本,计算 f (x) 的平均值 |
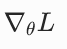 |
损失函数 L 对参数 θ 的梯度 | 参数 θ 的更新方向,沿着负梯度方向更新会让损失减小 |
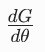 |
生成器 G 的雅可比矩阵 | 生成器输出对其参数的偏导数,连接图像空间和参数空间 |
二、核心概念 1:分数函数到底是什么?为什么扩散模型就是分数模型?
这是整个 DMD 最基础也是最容易被误解的概念。很多人说 "DDPM 是预测噪声的,不是分数模型",这是不完全正确的。预测噪声和预测分数是严格线性等价的,扩散模型的本质就是分数模型。
1. 先搞懂最基础的:概率密度与梯度
什么是概率密度?
对于连续随机变量(比如图像的像素值),单点的概率是 0,我们只能说 "某个区间内的概率是多少"。概率密度就是这个区间概率的 "变化率":
区间概率 ≈ 概率密度 × 区间长度
在高维图像空间中,p(x) 越大,说明 x 这个位置的图像越 "常见",越接近真实世界的图像。
什么是梯度?为什么它是 "增加最快的方向"?
对于一个多元函数 f(x1,x2,...,xn),它的梯度是一个向量,由函数对每个变量的偏导数组成: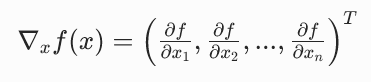
梯度有一个非常重要的几何性质:
梯度的方向是函数在该点增长最快的方向,梯度的模长是增长的速率。
你可以把函数想象成一座山,梯度就是你脚下最陡的上坡方向。沿着梯度方向走一小步,你会上升最多;沿着负梯度方向走一小步,你会下降最多。
分数函数的定义
分数函数就是对数概率密度函数的梯度 (对应原论文 3.2 节):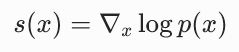
它的物理意义非常明确:
从点 x 出发,沿着分数函数的方向走一小步,这个点的概率密度会增加最快。
换句话说,分数函数永远指向离它最近的 "高概率区域",也就是更真实、更常见的图像区域。
2. 关键证明:扩散模型预测的噪声,就是分数函数的线性变换
这是扩散模型的核心数学结论,不是近似,是严格的代数恒等式。
前向扩散过程中,带噪声图像服从高斯分布:
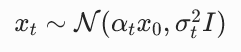
我们可以直接写出这个高斯分布的概率密度:
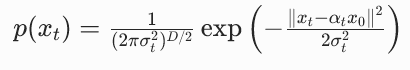
两边取对数:
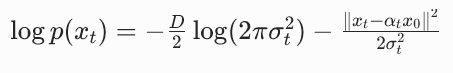
对 x_t 求梯度(注意常数项的导数为 0):
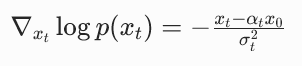
而根据前向扩散的定义,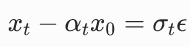 ,代入上式:
,代入上式: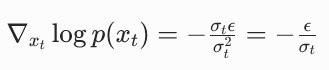
也就是: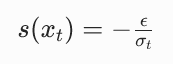
结论:扩散模型预测的噪声 ε,和分数函数 s (x_t) 是严格的线性关系。只要你有一个能预测噪声的扩散模型,你就能直接计算出任意点的分数函数。
这就是为什么 DMD 可以直接用预训练的 Stable Diffusion 作为真实分数模型 ------ 它本质上就是一个训练好的分数函数估计器。
三、核心概念 2:KL 散度的本质与梯度推导
DMD 的目标是让生成器的输出分布和原始扩散模型的输出分布尽可能相似,而衡量两个分布相似度最常用的指标就是 KL 散度。
1. 期望是什么?深度学习中怎么求期望?
期望就是加权平均值,权重是随机变量取各个值的概率。
- 离散变量:
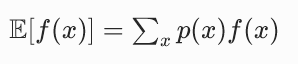
- 连续变量:
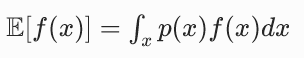
在深度学习中,我们不可能对所有可能的 x 求积分,所以用蒙特卡洛近似:
从分布 p 中采样 N 个样本,计算这些样本的平均值,就近似等于期望。
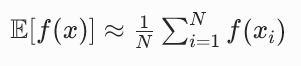
在训练中,我们通常用一个 batch 的样本(比如 32、64)来近似期望,样本越多,近似越准确。
2. KL 散度的定义与关键性质
KL 散度(Kullback-Leibler Divergence)衡量的是用一个分布 q 近似另一个分布 p 时,所损失的信息量 (对应原论文公式 (1)):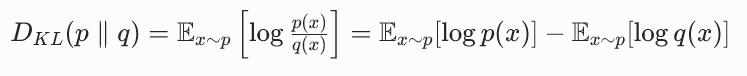
KL 散度有两个非常重要的性质:
- 非负性 :
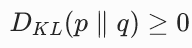 ,当且仅当 p 和 q 完全相同时,等于 0。这是我们可以用它作为损失函数的基础。
,当且仅当 p 和 q 完全相同时,等于 0。这是我们可以用它作为损失函数的基础。 - 不对称性 :
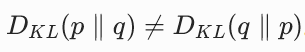 。这一点非常重要,直接决定了 DMD 的训练目标。
。这一点非常重要,直接决定了 DMD 的训练目标。
为什么 DMD 用 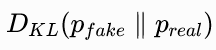 而不是反过来?
而不是反过来?
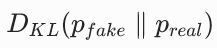 :对 pfake 求期望,我们可以很容易地从生成器采样得到假样本。
:对 pfake 求期望,我们可以很容易地从生成器采样得到假样本。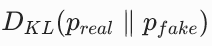 :对 preal 求期望,需要从真实数据采样。
:对 preal 求期望,需要从真实数据采样。
虽然两者都可以,但 ProlificDreamer 提出的变分分数蒸馏(VSD)框架用的是前者,DMD 直接继承了这个框架。
3. 核心推导:KL 散度对生成器参数的梯度
这是 DMD 最核心的数学推导,对应原论文公式 (2)。我会一步一步推导,不跳任何步骤。
我们的目标是最小化 KL 散度: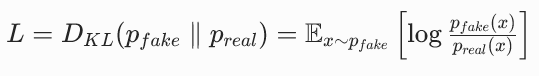
生成器 Gθ 将随机噪声 z 映射为图像 x:x=Gθ(z),其中 z∼N(0,I)。所以我们可以把期望改写为对 z 的期望: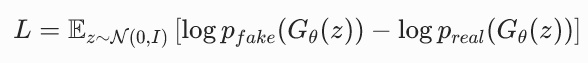
现在我们对生成器的参数 θ 求梯度: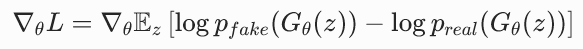
梯度和期望可以交换顺序(期望是线性运算):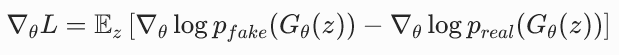
现在我们需要用链式法则来计算复合函数的梯度。对于复合函数 f(g(x)),它的导数是 f′(g(x))⋅g′(x)。
在这里,logp(x) 是关于 x 的函数,而 x 又是关于 θ 的函数 x=Gθ(z),所以: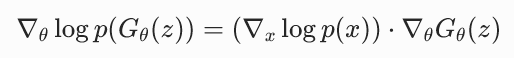
而 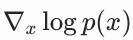 就是分数函数 s (x),∇θGθ(z) 就是生成器的雅可比矩阵
就是分数函数 s (x),∇θGθ(z) 就是生成器的雅可比矩阵 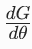 。代入上式:
。代入上式: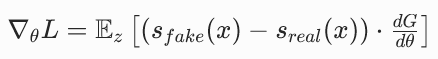
这就是原论文公式 (2) 的完整推导!
核心结论:KL 散度对生成器参数的梯度,等于假分数与真实分数的差值,乘以生成器的雅可比矩阵。
四、核心概念 3:雅可比矩阵的作用 ------ 连接图像空间与参数空间
很多人看到这里都会问:为什么要乘以雅可比矩阵?它到底是什么?
1. 雅可比矩阵的定义
雅可比矩阵是一个向量值函数对其输入的所有偏导数组成的矩阵。
如果有一个函数 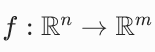 ,输入是 n 维向量,输出是 m 维向量,那么它的雅可比矩阵 J 是一个 m×n 的矩阵:
,输入是 n 维向量,输出是 m 维向量,那么它的雅可比矩阵 J 是一个 m×n 的矩阵:
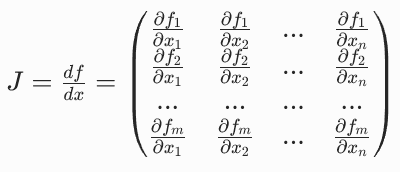
2. 雅可比矩阵的几何意义
雅可比矩阵描述了函数在某一点的局部线性变换。它告诉我们,当输入发生一个微小变化时,输出会发生多大的变化。
3. 在 DMD 中,雅可比矩阵的不可替代作用
现在我们来回答最关键的问题:为什么要乘以雅可比矩阵?
- 我们通过
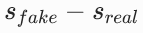 得到的是图像空间的梯度:它告诉我们 "为了让这张图像更真实,应该怎么调整它的像素值"。
得到的是图像空间的梯度:它告诉我们 "为了让这张图像更真实,应该怎么调整它的像素值"。 - 但我们不能直接调整图像的像素值,我们需要调整的是生成器的参数。
- 雅可比矩阵的作用就是把图像空间的梯度转换为参数空间的梯度。
直观比喻:
- 图像空间的梯度就像一个 "力",作用在图像上,想把图像往更真实的方向推。
- 生成器就像一个 "机器",它的参数是机器的旋钮。
- 雅可比矩阵就像一个 "传动装置",把作用在图像上的力,转换为转动旋钮的力。
- 这样我们转动旋钮(更新参数),就能让机器输出更真实的图像。
没有雅可比矩阵,我们就只能知道 "图像应该怎么改",但不知道 "生成器的参数应该怎么改"。
五、DMD 完整数学逻辑链:从目标到梯度更新
现在我们把所有内容串起来,形成一个完整的逻辑闭环,你就会发现 DMD 的数学原理其实非常清晰:
- 我们的最终目标:让一步生成器的输出分布 pfake 和原始多步扩散模型的输出分布 preal 尽可能相似。
- 选择衡量指标 :用 KL 散度
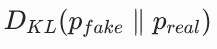 来衡量两个分布的差异,它的值越小,两个分布越相似。
来衡量两个分布的差异,它的值越小,两个分布越相似。 - 优化方法:用梯度下降法最小化 KL 散度,所以需要求 KL 散度对生成器参数 θ 的梯度。
- 数学推导 :通过链式法则,我们推导出 KL 散度的梯度等于两个分数的差值乘以生成器的雅可比矩阵:
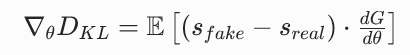
- 分数的获取 :
- 真实分数 sreal:由固定的预训练扩散模型提供,它指向真实数据的高概率区域。
- 假分数 sfake:由动态更新的扩散模型提供,它指向生成器当前输出的高概率区域。
- 梯度的物理意义 :
- −sreal:把图像往真实数据的方向推,提升生成质量。
- sfake:把图像往远离假数据集中区域的方向推,防止模式崩溃。
- 两者的差值就是 "既真实又多样" 的最优更新方向。
- 实际实现:通过一个巧妙的 MSE 损失(原论文算法 2),将分数差转换为可以反向传播的梯度,更新生成器的参数。
六、关键问题解答:原论文没说清楚的那些事
1. 为什么必须给假图像注入随机噪声?
原论文 3.2 节提到了这个问题,但没有详细解释。根本原因是:
原始的真实分布 preal 和假分布 pfake 可能完全没有重叠。
对于假分布中的样本 x,真实分布的概率密度 preal(x)≈0,导致真实分数 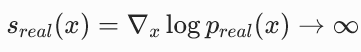 ,梯度爆炸,训练完全无法进行。
,梯度爆炸,训练完全无法进行。
注入随机噪声后,两个扩散后的分布是完全重叠的,在整个空间中都有非零的概率密度,两个分数都是有限且良定义的,训练可以稳定进行。
2. 为什么用 KL 散度而不是 JS 散度或 Wasserstein 距离?
主要有两个原因:
- 梯度可计算性:只有 KL 散度的梯度可以完美地用分数函数表示,这是其他散度做不到的。
- 与 VSD 的一致性:DMD 直接继承了 ProlificDreamer 提出的变分分数蒸馏(VSD)框架,而 VSD 的核心就是最小化 KL 散度。
3. 为什么两个分数相减就能防止模式崩溃?
如果我们只使用真实分数 sreal,那么所有的假样本都会向最近的真实模式收敛,出现严重的模式崩溃(对应原论文图 3a)。

加入假分数 sfake 后,它会把过于集中的样本 "推开",防止它们都挤在一个点上。这样生成器就会覆盖所有的真实模式,而不是只覆盖少数几个。
七、总结
DMD 的成功不是偶然的,它建立在坚实的数学基础之上。它没有沿着传统扩散蒸馏 "让学生模仿老师单步输出" 的老路,而是另辟蹊径,从分布匹配的角度出发,利用扩散模型本质上是分数函数估计器的特性,推导出了一个简单而有效的训练目标。
这篇博客补全了原论文中的基础数学细节,从最基础的概率密度、梯度、期望,到分数函数的线性等价性、KL 散度的梯度推导,再到雅可比矩阵的作用。希望看完这篇,你能彻底搞懂 DMD 的核心数学原理,而不仅仅是记住它的框架。