昨天比较热门的两个发布是:Kimi2.6 和 Qwen3.6 Max。
今天,先来看一下 Kimi2.6!

我可以先出一个论断:K 在实战场景肯定比 Q 强!
这两个模型的上一个版本我都测过了, Kimi2.6 的话其实就是之前的 Kimi Beta,只是当时没有任何描述信息。
现在正式发布了,我们就来全面的了解一下。
我大致搜索了一下,结果是这样的:
对于这些描述,我不做任何评论。
我们还是来看一下官方的文档和数据吧。
Kimi2.6 官方技术文档的第一句话是:
Kimi K2.6 是 Kimi 最新最智能的模型,Kimi K2.6 的通用 Agent、代码、视觉理解等综合能力得到全面提升。
同时它们也发布了一篇博客。我们不用看第三方的瞎扯,只要看这两个地方就可以了。
技术文档,写得比较笼统,所以主要是看这篇博客。

月之暗面,这个首图设计的还是酷炫的!
博客简介
博客的第一句话是:
我们将开源最新一代模型 Kimi K2.6 ,该模型具备顶尖编码能力、长时序执行能力以及智能体集群能力。
然后接下来是一张基准图:
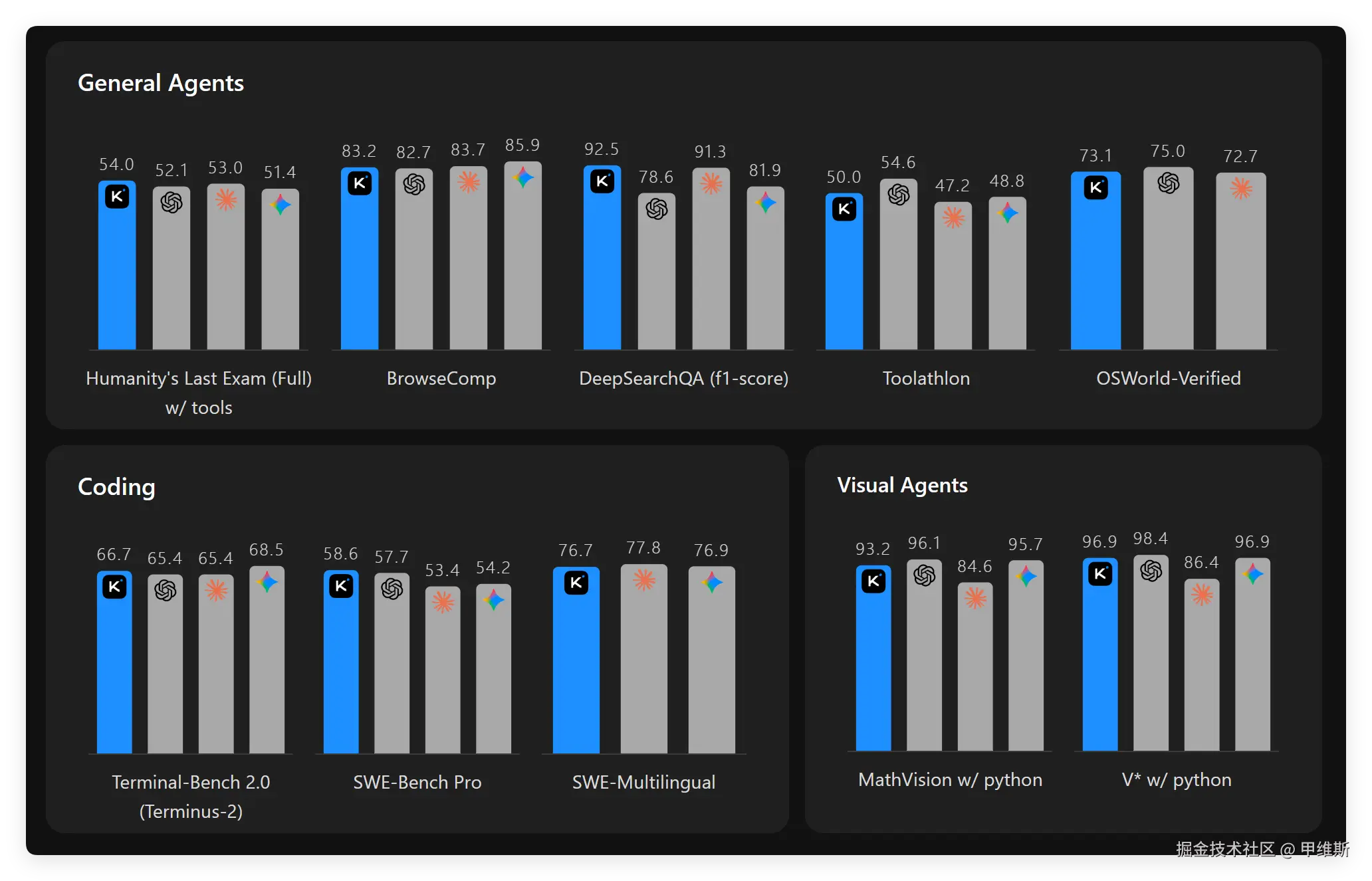
从图中的分类可以看出,这次更新也是聚焦在智能体和编码两个领域。
这次基准的主要对比对象是:
- GPT5.4 Xhigh
- Claude Opus 4.6 Max
- Gemini 3.1 Pro High
看看后缀,都是最强的存在了!
直接对标国际最强模型的最强版本,勇气可嘉!
从数据来看,有来有回。
当然,我一直强调,基准看看就好。很多时候测的不是实力而是"节操"!
这次 Kimi2.6 更新最重要的两个关键词就是 Coding + Agent。
Coding是重中之重。
博客中花了两个大章节来介绍 Coding。
第一个章节叫"Long-Horizon Coding"
第二个章节叫"Coding-Driven Design"
看一篇文章,只要看最重要和第二重要的内容就可以了。
所以我们只要关注这两个就可以了,这就是 Kimi2.6 的最大卖点。
长程编程能力
"long-horizon" 主要是「多步骤、跨阶段、需前瞻规划」的含义。
具体的介绍如下:
Kimi K2.6 在长周期编程任务中展现出显著进阶,具备跨编程语言(如 Rust、Go、Python)与跨任务类型(如前端开发、运维工程、性能优化)的可靠泛化能力。在内部基准测试平台 Kimi Code Bench(涵盖多样复杂端到端任务)上,Kimi K2.6 相较 Kimi K2.5 实现大幅性能提升。
Kimi Code Bench 是他们的内部基准。

文章中举了两个很有实战意义的例子。
案例一:Qwen3.5-0.8B Mac 端推理优化
Kimi K2.6 成功在 Mac 本地下载并部署 Qwen3.5-0.8B 模型,并采用极为小众的 Zig 语言实现与优化模型推理流程,展现出出色的分布外泛化能力。
案例二:exchange-core 金融匹配引擎重构
Kimi K2.6 自主重构了拥有 8 年历史的开源金融撮合引擎 exchange-core。在 13 小时连续执行过程中,模型迭代应用 12 种优化策略,发起 1,000+ 次工具调用,精准修改超 4,000 行代码。
其实这两个例子都是在证明一件事情:能自主完成更加复杂的任务!
代码驱动设计
这个概念的意思是,以代码为核心载体或生成逻辑,反向指导/实现系统架构、交互或产品设计。
具体描述如下:
依托卓越的代码生成能力,Kimi K2.6 能够将简单的提示词一键转化为完整的前端界面,自动生成结构严谨的布局,并融入精心考究的设计细节
具体能做什么呢?
可以给你一个很好看的首页!
包括视觉精美的首屏区域(hero sections)、交互式组件以及丰富的动画效果(如滚动触发动效)。
凭借对图像与视频生成工具的娴熟调用,Kimi K2.6 能够输出视觉风格高度统一的素材,助力打造更高质量、更具视觉焦点的首屏设计。
除了做静态首页之外,动态的也可以了。
Kimi K2.6 的能力边界已从静态前端开发延伸至轻量级全栈工作流。
完整覆盖身份认证、用户交互到数据库操作等核心链路,可高效支持交易日志记录、会话管理等典型轻量级应用场景。
为了更好地测试这些能力,它们构建了内部基准测试集 Kimi Design Bench:
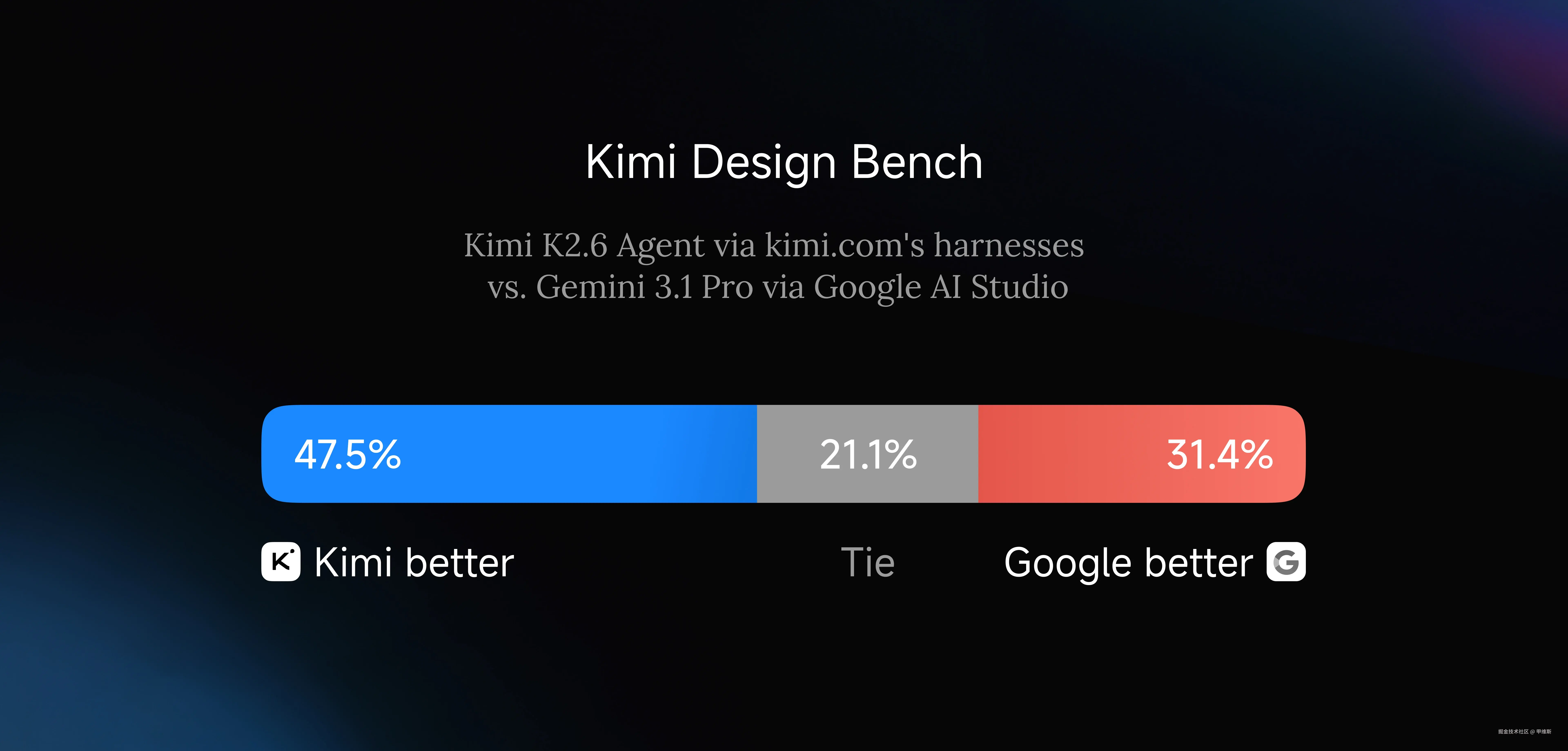
然后专门把 Google AI Studio 拉过来做了对比对象。
总共对比了四个大类:视觉输入任务、落地页构建、全栈应用开发与通用创意编程。
据官方介绍,Kimi K2.6 在上述各类别中均表现优异,展现出强劲的综合竞争力。
AI Studio 这个用过的知道,制作一个简单的页面,效果非常好!
如果上一个章节是在讲逻辑,这个章节主要是界面设计。
有逻辑有设计,就是一个完整的应用了。
所以 Kimi 2.6 主要是想干嘛,就应该很清晰了吧!
所以,这两点是它这次更新最重要的两个点,除了上面两个点,还有第三点是 Agent。
Agent 是大模型的必备能力,必须要的东西,就不展开讲了!
Kimi2.6 其实就是之前的 Kimi2.6 beta!
我在这篇《Kimi Beta内测模型实测,提升明显!》的文章中做了非常全面的测试。
包括业务逻辑理解能力和 UI 能力都做了测试。
在复杂业务处理方面基本上接近 GLM5-Turbo,在多模态识别、UI 复刻、UI 设计、UI 审美方面是比 GLM5V 强不少的!
基本上能论证上面 Blog 中的两个点了。
另外,你们如果用过 Kimi 的编程套餐就会发现,它的套餐也非常不经用。
为什么呢?因为稍微好一点的模型,都金贵。
要么贵,要么配额少,要么要抢(排除腾讯、阿里、百度的 Coding Plan),要么用不上~~!
至于对标 Opus 这种,我们看看就好了! 因为 Opus 既贵又少又难买!
参考链接: