前言
上一期介绍了RAG系统中的关键ETL(提取、转换、加载)流程中的提取,重点讲解SpringAI框架中的文档读取器实现。ETL过程包括从各类数据源提取内容、进行文本清洗和标准化处理,最后加载到向量数据库。文章详细演示了SpringAI提供的多种DocumentReader实现,包括处理JSON、纯文本、HTML、Markdown、PDF以及各类办公文档的读取器,并展示了MySQL数据库读取器的使用示例。这些工具为构建RAG系统提供了高效的数据预处理能力,确保原始数据能有效转化为适合AI模型检索结构化格式
本文主要说到ETL中的T(转换), L(加载) 和 重排序(Re-Ranking )
一.Transformers(文档转换器)
在大模型应用(如 RAG、知识库问答)中,原始文档通常太长、格式混乱或缺乏结构化元数据,无法直接输入给 LLM 使用。为此,Spring AI 提供了一组 文档转换器 (Document Transformers)。它们就像一个"智能流水线",把原始文档一步步加工成适合向量化、检索和生成的高质量片段。
主要包含以下 4 个组件:
-
TextSplitter (文本切分器):把长文切成小块。
-
ContentFormatTransformer (内容格式转换器):统一清洗文本。
-
KeywordMetadataEnricher (关键词提取器):借助 AI 模型自动提取关键词,类似给文档"贴标签"。
-
SummaryMetadataEnricher (摘要生成器):借助 AI 模型生成文档摘要。
总结:这些工具共同作用,提升后续 AI 处理的准确性与效率。
1.TokenTextSplitter(文本切分器)
1.1关于 TokenTextSplitter
TokenTextSplitter 是 TextSplitter 的一个实现,它基于 OpenAI 推荐的 CL100K_BASE 的分词编码方案,用于将长文本按 token数量 切分为多个较小的 Document 实例。
💡 **注意:**一个 token 不等于一个汉字!中文通常每 1~2 个汉字占 1 个 token,具体取决于词汇和语境。
可以把 TokenTextSplitter 理解为一个"智能断句"的分块专家。
1.2代码应用
@SpringBootTest
public class TransformersTest {
@Test
void testSplitter(@Value("classpath:/file/rule.txt") Resource resource) {
TextReader textReader = new TextReader(resource);
List<Document> documents = textReader.get();
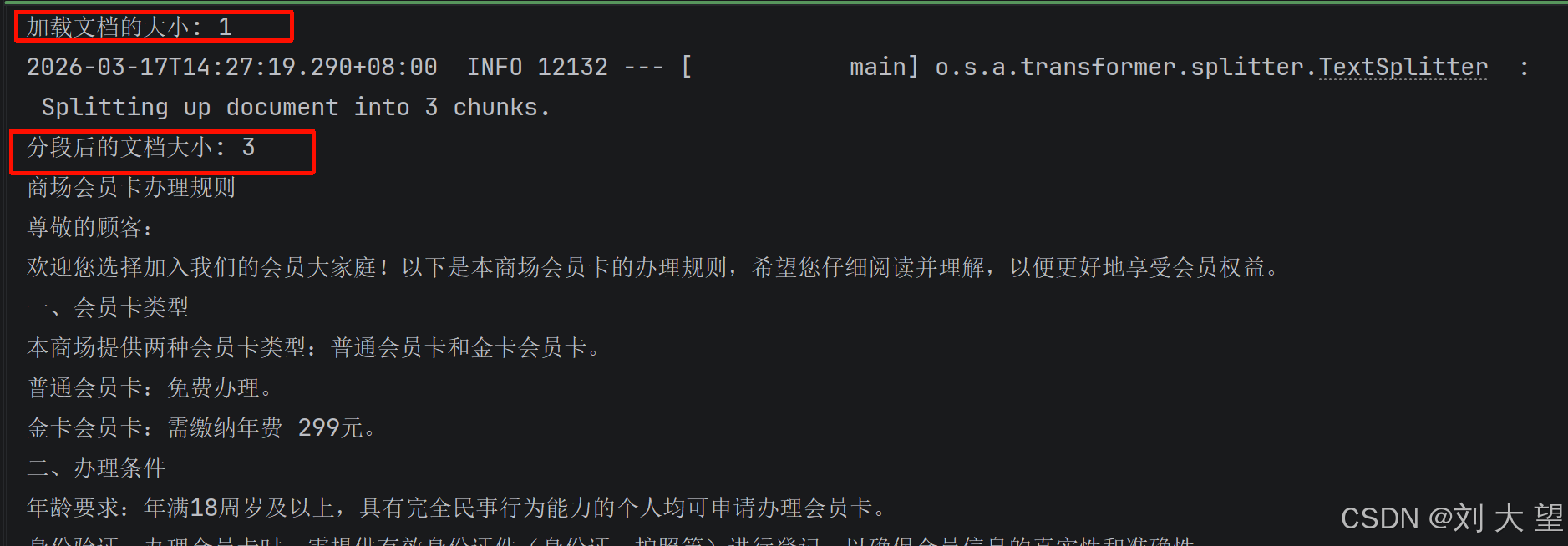
System.out.println("加载文档的大小: " + documents.size());
TokenTextSplitter tokenTextSplitter = new TokenTextSplitter();
List<Document> documentsSplit = tokenTextSplitter.apply(documents);
System.out.println("分段后的文档大小: " + documentsSplit.size());
documentsSplit.forEach(document -> {
System.out.println(document.getText());
System.out.println(document.getMetadata());
}
);
}
}1.3结果
 1.4TokenTextSplitter的全参构造函数
1.4TokenTextSplitter的全参构造函数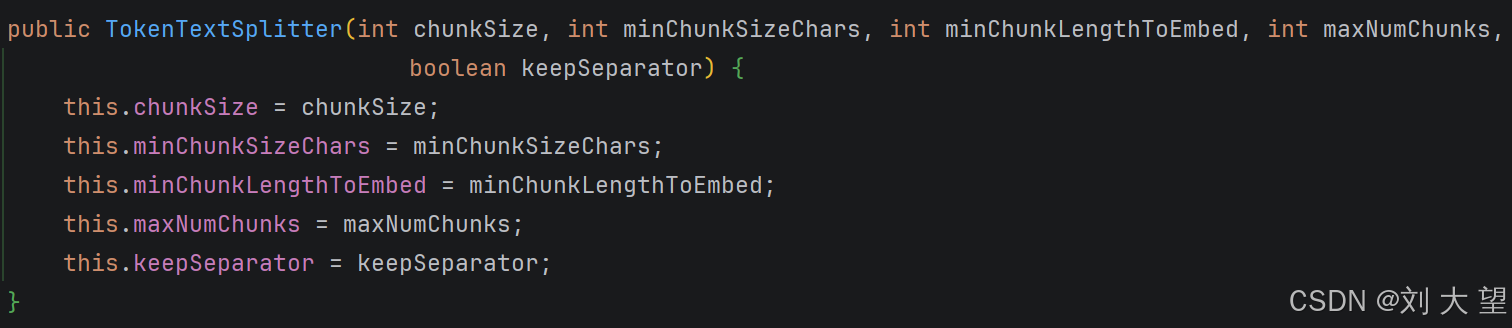
1.5参数说明
| 参数 | 默认值 | 含义 |
|---|---|---|
| defaultChunkSize | 800 | 每块目标 token 数 (尽量不超过) |
| minChunkSizeChars | 350 | 每块最少字符数 (防过短) |
| minChunkLengthToEmbed | 5 | 小于该长度的块会被丢弃 |
| maxNumChunks | 10,000 | 单文档最多切多少块 (防爆炸) |
| keepSeparator | TRUE | 是否保留分隔符 (如换行符\r\n) |
1.6 加入全参后的代码
@Test
void testSplitter(@Value("classpath:/file/rule.txt") Resource resource) {
TextReader textReader = new TextReader(resource);
List<Document> documents = textReader.get();
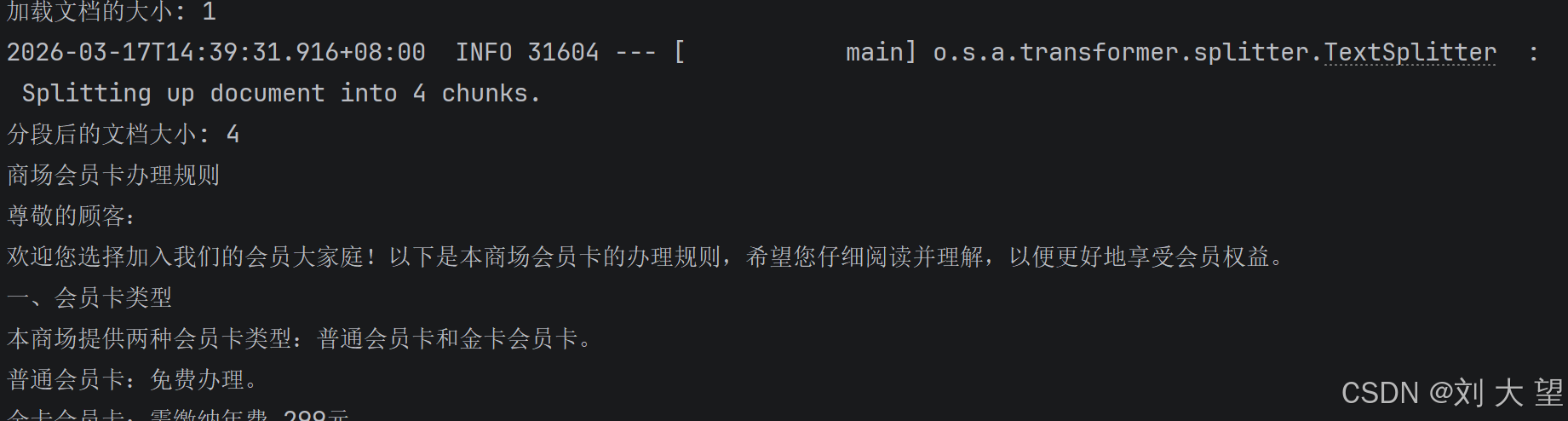
System.out.println("加载文档的大小: " + documents.size());
// TokenTextSplitter tokenTextSplitter = new TokenTextSplitter();
TokenTextSplitter tokenTextSplitter = new TokenTextSplitter(500, 300, 5, 5000, true);//全参构造
List<Document> documentsSplit = tokenTextSplitter.apply(documents);
System.out.println("分段后的文档大小: " + documentsSplit.size());
documentsSplit.forEach(document -> {
System.out.println(document.getText());
System.out.println(document.getMetadata());
}
);
}1.7加入参数后的运行结果
1.8处理流程
-
使用
CL100K_BASE编码将文本编码,得到 token 列表。 -
根据
defaultChunkSize的设置,获取前 N 个 token (N=defaultChunkSize),对这个块进行处理:-
a. 将数据库解码回文本,并找到最后一个句号/问号/感叹号/换行符。(注:图中文案"数据库"疑似"数据块"的笔误)
-
b. 若位置合适,则在该点截断 (是否大于
minChunkSizeChars)。 -
c. 清理格式 (去空格、换行替换等),检查长度是否够用。
-
d. 加入结果列表,从原 token 列表中移除已处理部分。
-
-
继续循环处理剩余未处理的令牌,直到处理完所有令牌或达到
maxNumChunks。
💡 通俗比喻:
想象你要把一本小说发到朋友圈,但每条只能发 200 字。 我们不会从"他说"中间剪开,而是会找到句号、问号等地方断开。
TokenTextSplitter就是像一个**"懂语法的裁缝"**,它先按 AI 能理解的单位 (token) 数好长度,然后尽量在句号、问号这些自然停顿的地方下剪刀,剪出一段段既不过长又能独立成意的小段落,最后还把边角料检查一遍,确保没有漏掉重要内容。
2.ContentFormatTransformer(内容格式转化器)
ContentFormatTransformer 是 Spring AI 框架中用于统一管理和调整文档内容格式的处理器。
💡 通俗比喻: 它就像一个 "文档化妆师",不改变文档原本的内容,而是决定在什么时候,哪些信息要展示,哪些信息要隐藏,并且统一排版格式。
它常用于处理从文件中读取的文档,确保它们以整洁、安全的方式被 AI 看到和使用。
简单说,就是让杂乱的文档变得整齐划一,该露的露,该藏的藏。常用于 RAG 系统中对加载的文档进行标准化预处理,从而提升后续检索与生成的质量和可控性。
这里不做过多介绍
3.KeywordMetadataEnricher(关键词提取器)
3.1关于KeywordMetadataEnricher
eywordMetadataEnricher 是一个基于大模型的元数据增强器,利用 ChatModel 分析文档内容,生成关键词列表,并作为字符串添加至文档元数据中。
默认使用的元数据键是 "excerpt_keywords"。
可以把 KeywordMetadataEnricher 看做一个 "自动打标签的机器人"。
比如:你有一批文章要归档,人工标注主题太慢了。
这个组件就像请了个实习生,快速扫一眼就说:"这篇讲的是 人工智能、机器学习、深度神经网络。"
然后把这些词贴在文件夹上,方便以后搜索查找。
3.2代码演示
@Test
void testEnricher(@Autowired ChatModel chatModel, @Value("classpath:/file/rule.txt") Resource resource) {
//加载文档
TextReader textReader = new TextReader(resource);
List<Document> documents = textReader.get();
System.out.println("加载文档的大小: " + documents.size());
//文档分块
TokenTextSplitter tokenTextSplitter = new TokenTextSplitter(500, 300, 5, 5000, true);//全参构造
List<Document> documentsSplit = tokenTextSplitter.apply(documents);
System.out.println("分段后的文档大小: " + documentsSplit.size());
//关键词生成
KeywordMetadataEnricher keywordMetadataEnricher = KeywordMetadataEnricher.builder(chatModel)
.keywordCount(2).build(); //每个文档提取关键词的数量
List<Document> enricher = keywordMetadataEnricher.apply(documentsSplit);
System.out.println("关键词生成后的文档大小: " + enricher.size());
enricher.forEach(document -> {
System.out.println(document.getText());
System.out.println(document.getMetadata());
}
);
}3.3结果

两个关键词
3.4构造函数参数解析
KeywordMetadataEnricher 提供了两种构造函数选项。
- KeywordMetadataEnricher(ChatModel chatModel, int keywordCount):指定关键词数量(使用默认提示词模版)
- KeywordMetadataEnricher(ChatModel chatModel, PromptTemplate keywordsTemplate):自定义提示词模版
3.5提示词模板代码
@Test
void testEnricher(@Autowired ChatModel chatModel, @Value("classpath:/file/rule.txt") Resource resource) {
//加载文档
TextReader textReader = new TextReader(resource);
List<Document> documents = textReader.get();
System.out.println("加载文档的大小: " + documents.size());
//文档分块
TokenTextSplitter tokenTextSplitter = new TokenTextSplitter(500, 300, 5, 5000, true);//全参构造
List<Document> documentsSplit = tokenTextSplitter.apply(documents);
System.out.println("分段后的文档大小: " + documentsSplit.size());
//关键词生成
// KeywordMetadataEnricher keywordMetadataEnricher = KeywordMetadataEnricher.builder(chatModel)
// .keywordCount(2).build();
KeywordMetadataEnricher keywordMetadataEnricher = KeywordMetadataEnricher.builder(chatModel)
.keywordsTemplate(new PromptTemplate("根据给定的文本:{context_str},生成关键字,只允许以下关键字" +
" [会员宗旨,会员类型,会员注册,积分制度,会员权益,会员行为,会员服务,公告,隐私保护] " +
"只返回关键字,其他信息不返回")).build();
List<Document> enricher = keywordMetadataEnricher.apply(documentsSplit);
System.out.println("关键词生成后的文档大小: " + enricher.size());
enricher.forEach(document -> {
System.out.println(document.getText());
System.out.println(document.getMetadata());
}
);
}3.6结果


3.7注意事项
- KeywordMetadataEnricher 需要一个功能良好的 ChatModel 来生成关键字(API 调用可能会产生费用)
- 关键字个数必须大于等于 1
- enricher 会向每个处理过的文档添加 "excerpt_keywords" 元数据字段
- 生成的关键字以逗号分隔的字符串返回,如:"会员权益,会员行为,会员服务,公告"
- 在 Builder 模式 中,如果设置了 keywordsTemplate 参数,keywordCount 参数将被忽略
4.SummaryMetadataEnricher(摘要生成器)
4.1关于SummaryMetadataEnricher
SummaryMetadataEnricher 利用 ChatModel 为每个文档生成摘要信息,并将其作为元数据的一部分添加到文档中。也可以根据需要,指定为当前文档或相邻文档(上一个和下一个)生成摘要,添加到元数据中。
可以把 SummaryMetadataEnricher 看做一个 "会写读书笔记的助手"。
4.2快速使用-代码
SummaryMetadataEnricher 支持三种摘要类型(通过 SummaryType 枚举指定)
- CURRENT:当前文档摘要
- PREVIOUS:前一个文档摘要
- NEXT:下一个文档摘要
比如你在读一系列连载文章,每看完一篇,都有个小助手帮你写一句总结:"上一篇讲了 AI 发展史,这一篇重点介绍大模型训练方法,下一篇会讨论部署挑战。"
这让你更容易理解前后逻辑关系。
@Test
void testSummary(@Autowired ChatModel chatModel, @Value("classpath:/file/rule.txt") Resource resource) {
//加载文档
TextReader textReader = new TextReader(resource);
List<Document> documents = textReader.get();
//文档分块
TokenTextSplitter tokenTextSplitter = new TokenTextSplitter(500, 300, 5, 5000, true);//全参构造
List<Document> documentsSplit = tokenTextSplitter.apply(documents);
SummaryMetadataEnricher summaryMetadataEnricher = new SummaryMetadataEnricher(chatModel,
List.of(SummaryType.PREVIOUS, SummaryType.CURRENT, SummaryType.NEXT));
List<Document> enricher = summaryMetadataEnricher.apply(documentsSplit);
enricher.forEach(document -> {
System.out.println(document.getText());
System.out.println(document.getMetadata());
}
);
}4.3代码结果
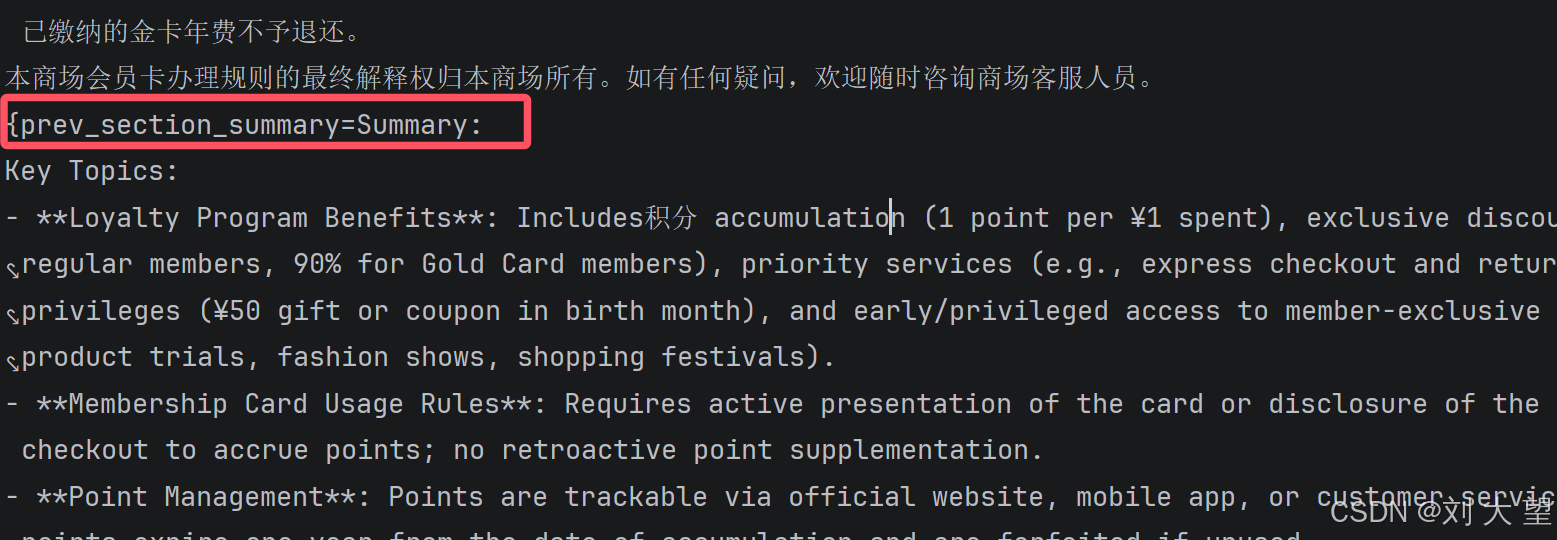
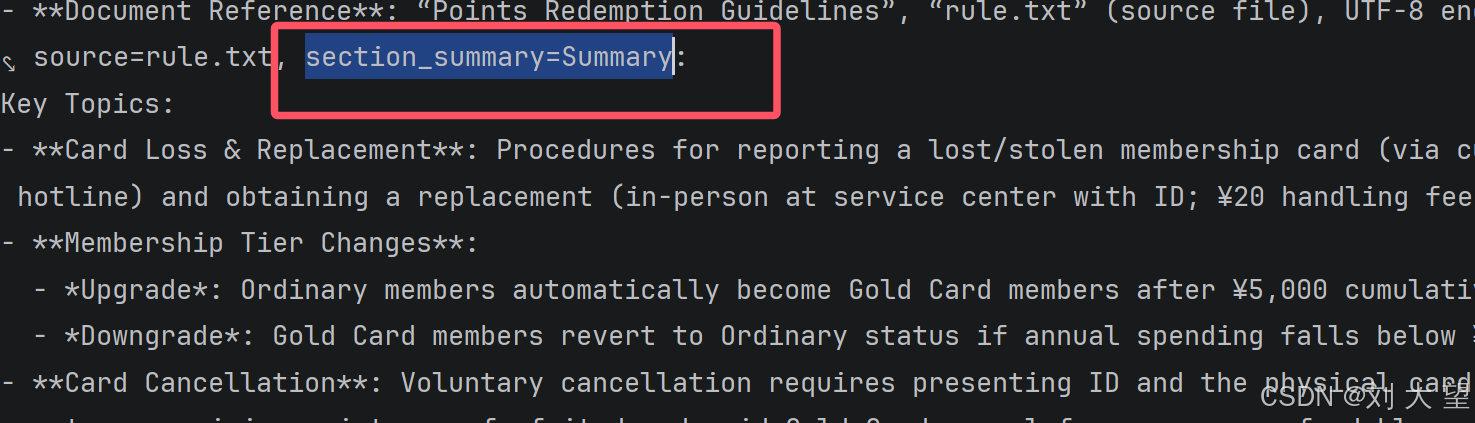
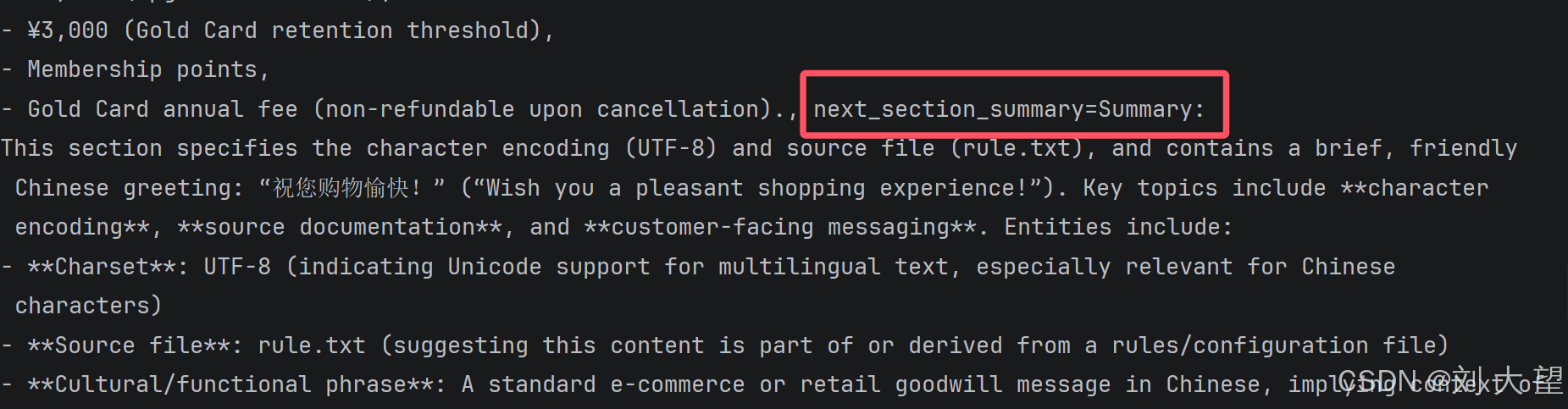
上面图中对应的前一个文档信息 当前文档信息 后一个文档信息 第一个文档没有前一个文档信息 最后一个文档没有下一个文档的信息 还有一个问题 : 文档生成的摘要太多了 可以传入自定义模板
4.4构造函数介绍
SummaryMetadataEnricher 提供了 2 个构造函数
SummaryMetadataEnricher(ChatModel chatModel, List<SummaryType> summaryTypes)SummaryMetadataEnricher(ChatModel chatModel, List<SummaryType> summaryTypes, String summaryTemplate, MetadataMode metadataMode)
| 参数 | 类型 | 作用 |
|---|---|---|
| chatModel | ChatModel |
生成摘要的 LLM 客户端实现 (如 OpenAI、Ollama 等) |
| summaryTypes | List<SummaryType> |
指定需生成的摘要类型(PREVIOUS, CURRENT, NEXT) |
| summaryTemplate | String(可选) |
用于生成摘要的自定义模板(可选) |
| metadataMode | MetadataMode(可选) |
指定在生成摘要时如何处理文档元数据 |
默认的提示词模板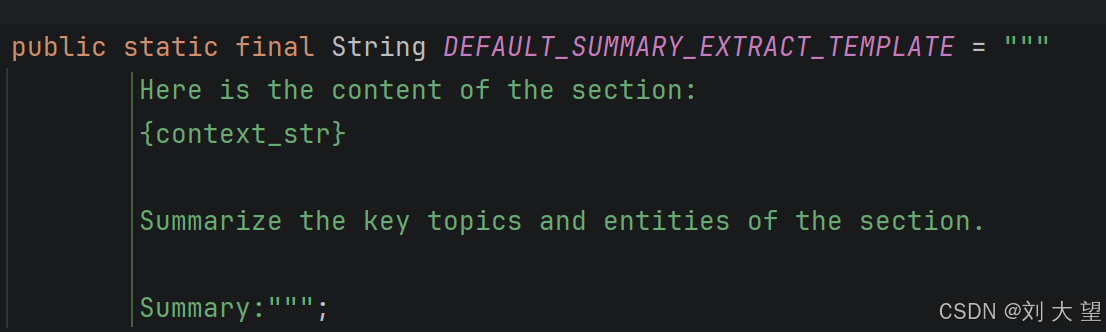
4.5传入自定义的提示词模板代码
@Test
void testSummary(@Autowired ChatModel chatModel, @Value("classpath:/file/rule.txt") Resource resource) {
//加载文档
TextReader textReader = new TextReader(resource);
List<Document> documents = textReader.get();
//文档分块
TokenTextSplitter tokenTextSplitter = new TokenTextSplitter(500, 300, 5, 5000, true);//全参构造
List<Document> documentsSplit = tokenTextSplitter.apply(documents);
String summaryTemplate = """
根据给定的文本:
{context_str}
生成摘要信息,限制在50字以内。只返回摘要信息,其他信息不返回
""";
SummaryMetadataEnricher summaryMetadataEnricher = new SummaryMetadataEnricher(chatModel,
List.of(SummaryType.PREVIOUS, SummaryType.CURRENT, SummaryType.NEXT),
summaryTemplate, MetadataMode.NONE);
List<Document> enricher = summaryMetadataEnricher.apply(documentsSplit);
enricher.forEach(document -> {
System.out.println(document.getText());
System.out.println(document.getMetadata());
}
);
}4.6结果

给文档生成摘要的同时也可以加上前面的关键词生成 也可以对文档不拆分 但是必须得加载文档
4.7工作流程
- 输入接收 :接收一个有序的 List<Document>,顺序决定相邻关系。
- 遍历处理:对每个文档,根据文档内容和摘要模版生成摘要信息。
- 摘要生成 :根据配置的 summaryTypes,分别构建针对当前、前一个、后一个文档的摘要,并添加到对应文档的元数据中。
- 边界处理 :首文档无 "prev_section_summary" ,末文档无 "next_section_summary"。
- 返回值:返回经过元数据增强的新文档列表。
5.总结
四大组件总览表
| 组件 | 主要功能 | 是否需要 LLM | 典型用途 |
|---|---|---|---|
TokenTextSplitter |
切分长文本 | × | 向量化前预处理 |
ContentFormatTransformer |
统一文档格式 | × | 格式标准化 |
KeywordMetadataEnricher |
提取关键词并写入元数据 | √ | 打标签、增强检索 |
SummaryMetadataEnricher |
生成摘要 (当前 / 前后) | √ | 上下文理解、RAG |
TokenTextSplitter是裁缝,精准剪出合身布料;ContentFormatTransformer是保洁,清除表面灰尘;KeywordMetadataEnricher是标签员,贴上关键词便签;SummaryMetadataEnricher是讲解员,写出前后关联的导览笔记。
四者协同工作,最终将杂乱无章的原始文档打造成 AI 可读、可检、可理解的高质量知识资产。
二.Writers
刚说完Transformers(ETL中的T)接下来介绍最后一个L(加载) 这个加载不是文档的加载而是数据的写入
1.FileDocumentWriter
1.1关于FileDocumentWriter
FileDocumentWriter 是一个实现了 DocumentWriter 接口的类,用于将一组 Document 对象的内容写入到指定的文本文件中。适用于调试、日志记录或生成人类可读的文档输出。
1.2代码演示
@Test
void testFileWritter(@Value("classpath:/file/rule.txt") Resource resource){
//读取文档
TextReader reader = new TextReader(resource);
List<Document> documents = reader.get();
//文档分割
TokenTextSplitter splitter = new TokenTextSplitter();
List<Document> splitterDoc = splitter.apply(documents);
//文档写入
FileDocumentWriter writer = new FileDocumentWriter("output.txt");
writer.accept(splitterDoc);
System.out.println("文档写入完成");
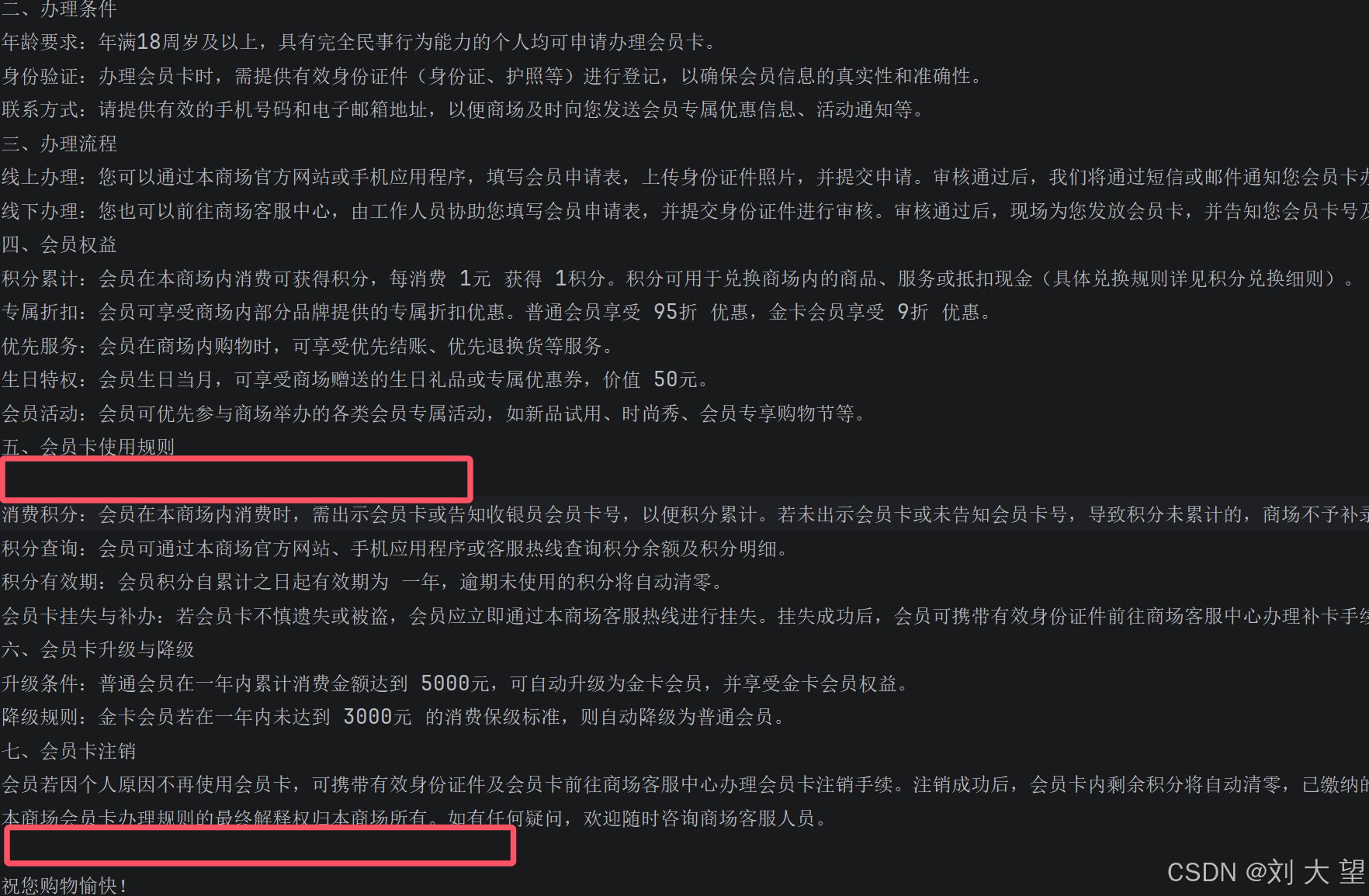
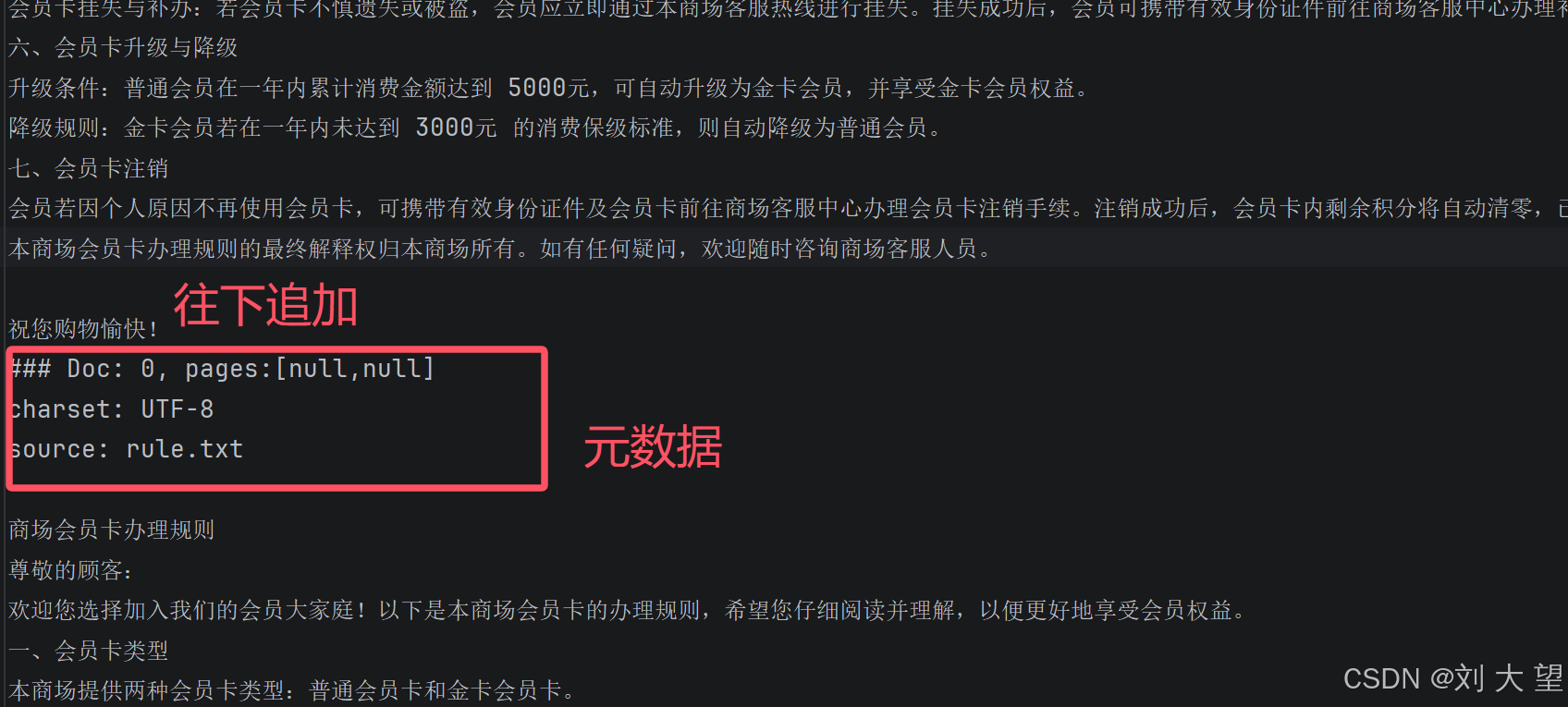
}1.3结果
图中红框标出的地方是每个文档分割的地方
1.4构造函数
FileDocumentWriter 提供了三个构造函数,便于灵活配置:
FileDocumentWriter(String fileName):写入指定文件,不带标记、无元数据、覆盖写入FileDocumentWriter(String fileName, boolean withDocumentMarkers):指定是否在输出中包含文档标记FileDocumentWriter(String fileName, boolean withDocumentMarkers, MetadataMode metadataMode, boolean append):完整配置
- withDocumentMarkers:是否写入文档分隔标记
- metadataMode:控制写入哪些内容(正文、元数据等)
- append :是否追加到文件末尾(
true)还是覆盖(false)
1.5全参构造函数代码
@Test
void testFileWritter(@Value("classpath:/file/rule.txt") Resource resource){
//读取文档
TextReader reader = new TextReader(resource);
List<Document> documents = reader.get();
//文档分割
TokenTextSplitter splitter = new TokenTextSplitter();
List<Document> splitterDoc = splitter.apply(documents);
//文档写入
FileDocumentWriter writer = new FileDocumentWriter("output.txt",
true, MetadataMode.ALL, true);
writer.accept(splitterDoc);
System.out.println("文档写入完成");
}1.6结果
2.SimpleVectorStore
2.1关于SimpleVectorStore
除了 FileDocumentWriter 之外,Spring AI 还提供了与各种向量存储(vector stores)集成,上面讲的 SimpleVectorStore 就是其中一种。
详细参考:https://docs.spring.io/spring-ai/reference/api/vectordbs.html
当使用向量数据库存储 document 时,可以省略向量化这一步,向量数据库会在底层自动完成向量化。
下面挑几种向量数据库进行讲解,先来回顾下 SimpleVectorStore。
SimpleVectorStore
SimpleVectorStore 是 Spring AI 内置的一个 "内存版" 向量数据库,无需外部依赖,开箱即用,适合本地测试和快速原型开发。
SimpleVectorStore 实现了 VectorStore,VectorStore 继承了 DocumentWriter(文档写入的接口,后续会讲),所以具备文档写入的能力。
2.2代码
//存入向量数据库
@Test
void testSimpleVectorWritter(@Value("classpath:/file/rule.txt") Resource resource){
//读取文档
TextReader reader = new TextReader(resource);
List<Document> documents = reader.get();
//文档分割
TokenTextSplitter splitter = new TokenTextSplitter();
List<Document> splitterDoc = splitter.apply(documents);
//文档写入向量数据库
vectorStore.accept(splitterDoc);
System.out.println("文档写入完成");
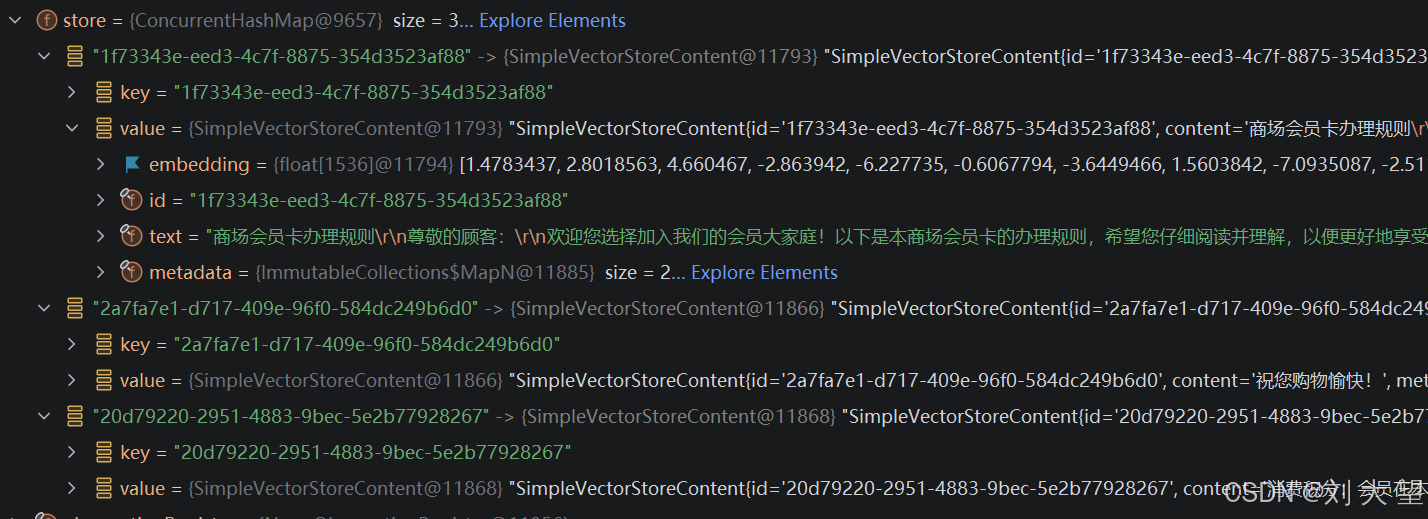
}2.3结果
因为SimpleVectorStore是内存存储的 所以要debug观察
3.Redis Vector Store
3.1关于Redis Vector Store
我们还可以使用 Redis 来存储向量。Redis 是一个开源(BSD 许可)内存数据结构存储,用作数据库、缓存、消息代理和流引擎。Redis 提供数据结构,例如字符串、哈希、列表、集合、带有范围查询的排序集、位图、超日志、地理空间索引和流。大多数开发人员都熟悉 Redis,并且多年来已被众多大型企业采用。
Redis Search 扩展了 Redis OSS 的核心特性,通过加载 RedisSearch,可以将 Redis 用作向量数据库,支持向量存储和相似性搜索。
3.2环境准备
使用 Redis 来存储向量,需要准备相关环境:
- 一个 Redis 实例(必需)
- Redis 客户端(非必需)
- Embedding 模型接入(必需)
我选择使用 Docker 来启动 Redis 实例(根据自己情况进行选择即可)
docker run -d --name redis-stack -p 6579:6379 -p 8001:8001 redis/redis-stack:latest第一个端口是redis服务的端口 第二个是redis可视化界面端口
远程服务器要注意开放端口供本地访问
Redis 客户端
- Redis DeskTop Manager
- Another Redis Desktop Manager
- Navicat
Embedding 模型接入
需要一个实现了 EmbeddingModel 接口的服务来生成向量,比如:DashScopeEmbeddingModel、OpenAiEmbeddingModel 都可以。
3.3引入依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-redis</artifactId>
</dependency>3.4添加配置
spring:
ai:
dashscope:
api-key: ${DASH_SCOPE_API_KEY} #阿里百炼平台申请的key
embedding:
options:
model: text-embedding-v1 #配置向量模型
vectorstore:
redis:
initialize-schema: true # 是否自动创建索引结构
index-name: spring-ai-index # 向量索引名称
prefix: "embedding:" # Redis Key 前缀
data:
redis:
url: redis://你的服务地址:65793.5代码
@Autowired
private RedisVectorStore redisVectorStore;
@Test
void testRedisVectorStore(@Value("classpath:/file/rule.txt") Resource resource) {
//读取文档
TextReader reader = new TextReader(resource);
List<Document> documents = reader.get();
//文档分割
TokenTextSplitter splitter = new TokenTextSplitter();
List<Document> splitterDoc = splitter.apply(documents);
//加载文档到redis向量存储
redisVectorStore.add(splitterDoc);
System.out.println("向量存储加载文档完成");
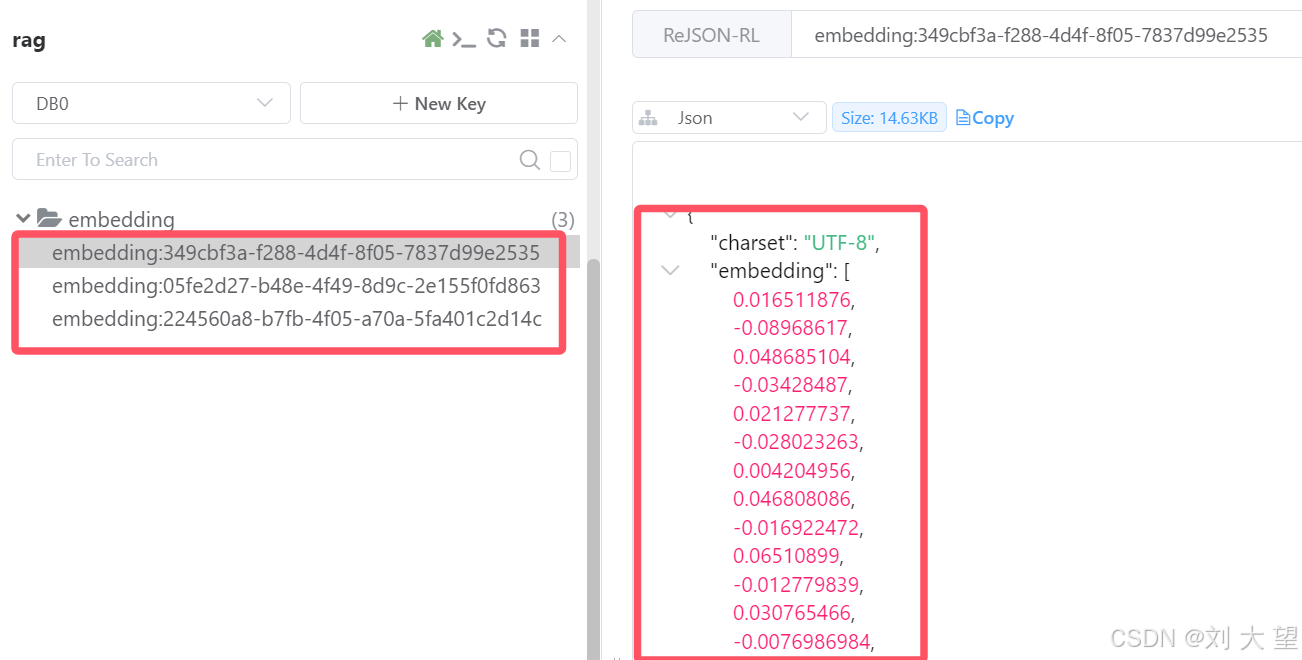
}3.6观察存储结果
3.7相似性检索
注意: 文档只需加载一次
@Test
void testRedisVectorStore(@Value("classpath:/file/rule.txt") Resource resource) {
// //读取文档
// TextReader reader = new TextReader(resource);
// List<Document> documents = reader.get();
//
// //文档分割
// TokenTextSplitter splitter = new TokenTextSplitter();
// List<Document> splitterDoc = splitter.apply(documents);
//
// //加载文档到redis向量存储
// redisVectorStore.add(splitterDoc);
// System.out.println("向量存储加载文档完成");
//相似性检索
SearchRequest searchRequest = SearchRequest.builder()
.query("大语言模型") //查询的文本
.topK(5) //匹配文档的前N个
.similarityThreshold(0.6) //相似度分数大于等于0.5
.build();
List<Document> searchResults = redisVectorStore.similaritySearch(searchRequest);
searchResults.forEach(System.out::println);
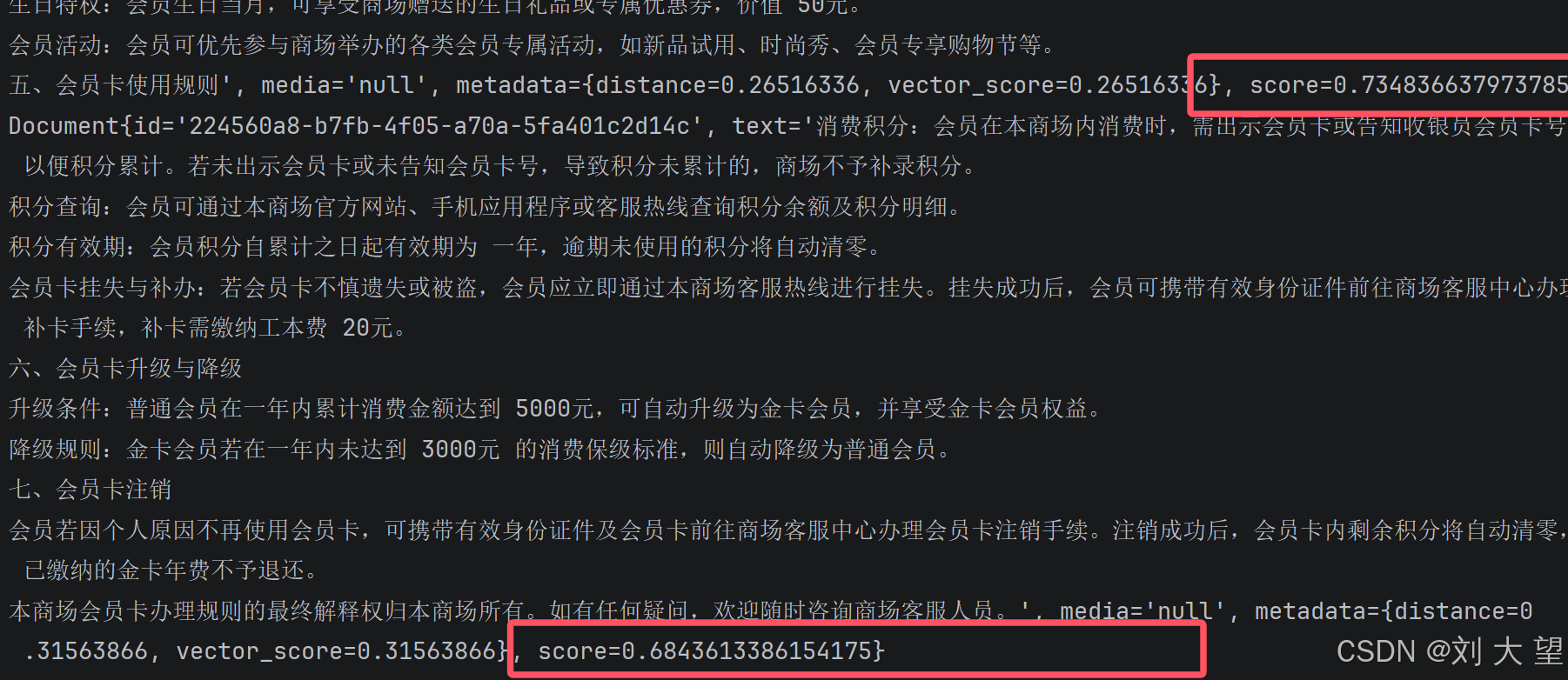
}3.8相似性检索结果
4.Pinecone Vector Store
4.1关于Pinecone Vector Store
Pinecone 是为机器学习应用量身打造的生产级向量数据库服务,适用于高维向量数据的高效存储、索引与查询。它屏蔽了基础设施管理,提供无缝扩展、实时数据写入和强大安全保障,让开发者和数据科学家能够以极低运维成本,快速构建高效的相似度搜索、推荐系统和 AI 应用。
Pinecone 是一个全托管的向量数据库平台,负责所有后端维护、扩展、更新和监控,让用户专注于应用开发,无需担心数据库管理。
Pinecone 官方地址:https://www.pinecone.io/(需科学上网)
4.2环境准备
完成注册(选择个人免费)
注册成功会⽣成⼀个默认的APIKey注意保存好你的key (也可以新建)
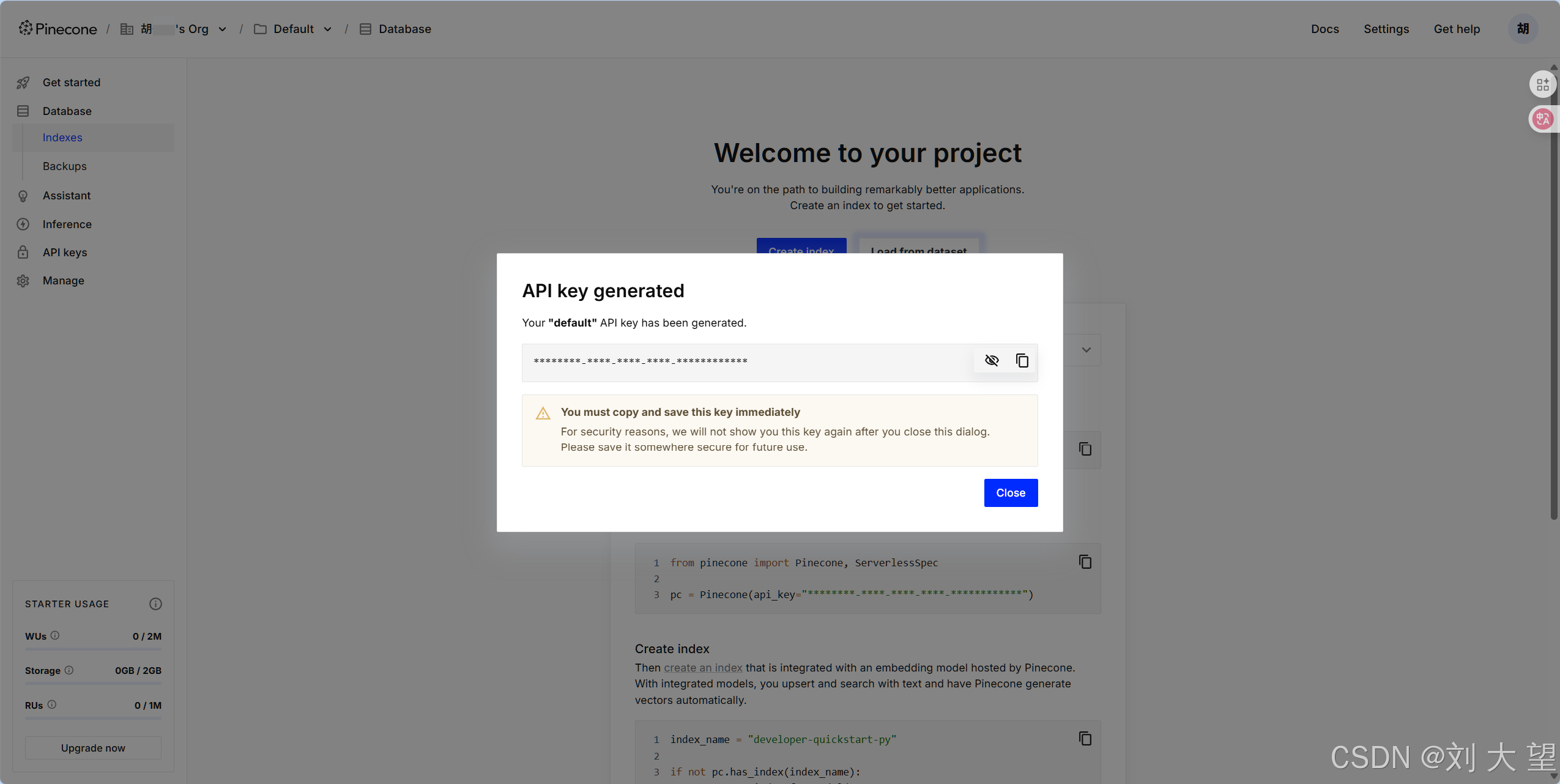
设置 PINECONE_API_KEY ,将Key添加进环境变量
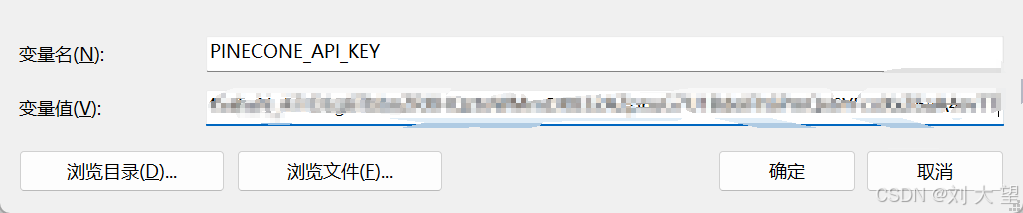
创建索引,索引名字和项⽬中配置保持⼀致
输入索引名字 其他默认 (索引可以理解为一个数据库)
4.3引入依赖
注释掉redis的依赖 否则bean会冲突
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-pinecone</artifactId>
</dependency>4.4添加配置
注意模型配置生成的维度 要和PINECONE数据库的维度一样
spring:
ai:
dashscope:
api-key: ${DASH_SCOPE_API_KEY}
embedding:
options:
model: text-embedding-v4 #配置向量模型
vectorstore:
pinecone:
api-key: ${PINECONE_API_KEY}
index-name: pinecone-index #上面创建的索引名称4.5代码
@Autowired
private PineconeVectorStore pineconeVectorStore;
@Test
void testPineconeVectorStore(@Value("classpath:/file/rule.txt") Resource resource) {
//读取文档
TextReader reader = new TextReader(resource);
List<Document> documents = reader.get();
//文档分割
TokenTextSplitter splitter = new TokenTextSplitter();
List<Document> splitterDoc = splitter.apply(documents);
//加载文档到redis向量存储
pineconeVectorStore.add(splitterDoc);
System.out.println("向量存储加载文档完成");
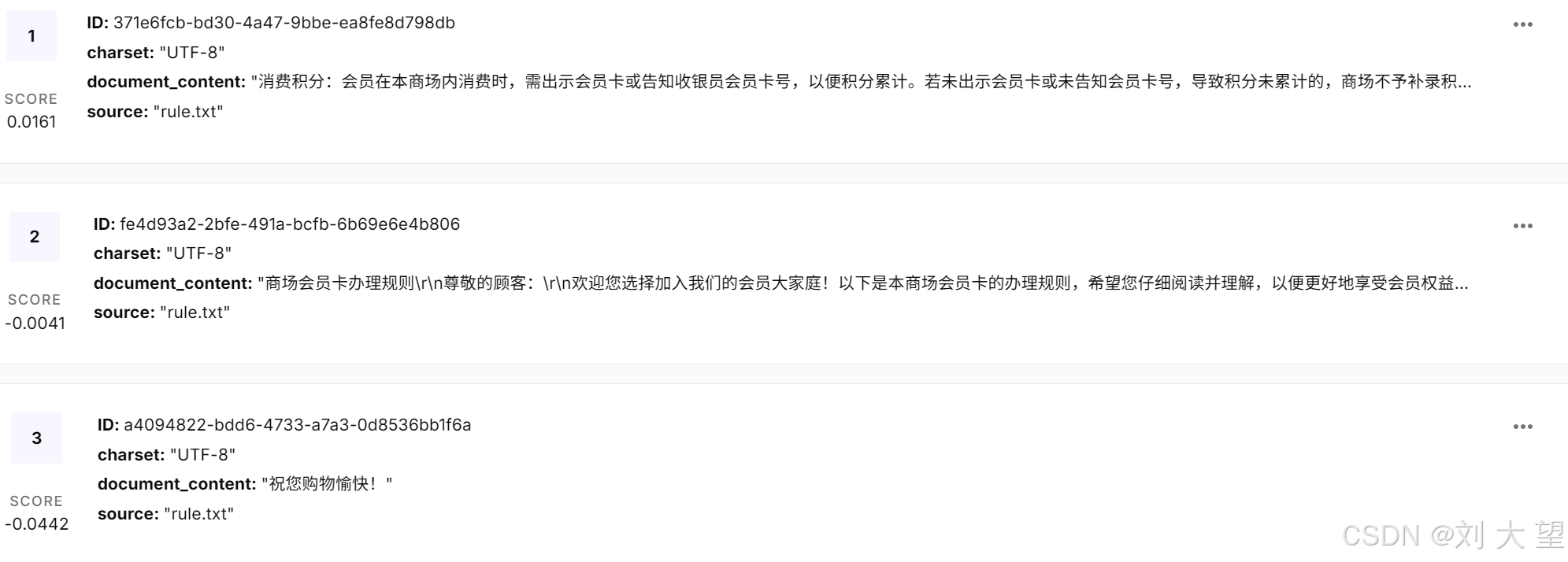
}4.6观察存储内容
4.7相似性检索
@Test
void testPineconeVectorStore(@Value("classpath:/file/rule.txt") Resource resource) {
// //读取文档
// TextReader reader = new TextReader(resource);
// List<Document> documents = reader.get();
//
// //文档分割
// TokenTextSplitter splitter = new TokenTextSplitter();
// List<Document> splitterDoc = splitter.apply(documents);
//
// //加载文档到redis向量存储
// pineconeVectorStore.add(splitterDoc);
// System.out.println("向量存储加载文档完成");
//相似性检索
SearchRequest searchRequest = SearchRequest.builder()
.query("会员") //查询的文本
.topK(2) //匹配文档的前N个
.build();
List<Document> searchResults = pineconeVectorStore.similaritySearch(searchRequest);
searchResults.forEach(System.out::println);
System.out.println("相似性检索完成");
}4.8检索结果
三.重排序(Re-Ranking)
1.问题切入
在当前 Retrieval-Augmented Generation (RAG) 架构广泛应用的背景下,向量数据库已成为连接大模型与外部知识的核心桥梁。通过将文本转化为高维向量,并基于余弦相似度等度量方式进行相似搜索,我们可以快速从海量文档中 "找到看起来相关的片段",但是,在实际应用中,我们发现其排序结果并不总是最优。
也就是:最相似的向量 ≠ 最相关的答案
所以,重排序 (Re-Ranking) 正在成为高质量 RAG 系统不可或缺的一环。
比如:查询 "如何申请产假"文档 A: "员工请病假需提交医院证明."文档 B: "女职工享有 188 天带薪产假及哺乳时间."
从词向量角度看,"请假"、"申请"、"病假"、"产假" 可能处于相近空间区域,系统或许会误判文档 A 更相关;但从真实需求出发,文档 B 显然更具回答价值。
真正相关的文档被排在后面,会导致送入给 LLM 的上下文质量大打折扣,导致检索的结果不准确。
为解决这个问题,业界普遍采用重排序的模式来提升检索质量。
2.什么是重排序?
Re-Ranking (重排序) 是指在初步检索出一批候选文档后,使用一个更加精细、专精于相关性判断的模型,重新评估每个文档与查询之间的匹配程度,并按新得分重新排序。
这一过程类似于搜索引擎的工作机制:
- 先用倒排索引 + 向量检索快速召回几百个候选网页。
- 再用精排排序模型打分筛选,最终呈现前 10 条结果。
工作流程如下:
- 粗排阶段 (Retrieve):使用向量数据库进行快速 ANN 搜索,召回一批候选文档(如 top-50)
- 精排阶段 (Rerank):调用更精细的排序模型(如 Cross-Encoder 类重排序模型),计算每个文档与原始查询之间的细粒度语义匹配分数;
- 根据重排序后的得分重新排列文档顺序,选取 top-k 高质量上下文;
- 将优化后的上下文注入 Prompt,交由 LLM 生成最终回答。
比如:查询:"怎么请产假"召回可能返回关于 "病假"、"调休" 的文档(因词向量接近);经过 re-ranker 分析后,"产假规定"、"女职工权益保护" 类文档会被提至前列,确保 LLM 接收到最贴切的信息。
3.Spring AI中的实现方式
Spring AI 提供了开箱即用的支持组件:RetrievalRerankAdvisor,极大简化了集成流程。
为方便测试,向量数据库使用了 SimpleVectorStore
@SpringBootTest
public class RerankTest {
private SimpleVectorStore simpleVectorStore;
@Autowired
public RerankTest(EmbeddingModel embeddingModel) {
this.simpleVectorStore = SimpleVectorStore.builder(embeddingModel).build();
}
@BeforeEach
void testSimpleVectorStore(@Value("classpath:/file/rule.txt") Resource resource){
// 读取文件
TextReader reader = new TextReader(resource);
List<Document> documents = reader.get();
// 分割文档
TokenTextSplitter splitter = new TokenTextSplitter(200, 50, 5, 1000, true);
List<Document> apply = splitter.apply(documents);
// 添加向量存储
simpleVectorStore.add(apply);
System.out.println("向量存储写入完成");
}
@Test
void testRerank(@Autowired DashScopeRerankModel rerankModel,
@Autowired DashScopeChatModel chatModel){
ChatClient client = ChatClient.builder(chatModel).build();
//1. 定义一个advisor, 提供rerank模型
RetrievalRerankAdvisor rerankAdvisor = new RetrievalRerankAdvisor(simpleVectorStore,
rerankModel, SearchRequest.builder().topK(5).build());
//2. 把这个advisor 绑定给chatclient
String content = client.prompt()
.user("金卡会员打几折")
.advisors(rerankAdvisor)
.call()
.content();
System.out.println(content);
}4.通过Debug观察精排前后Document的顺序变化
精排之前

精排之后(重排序)

四.RAG的应用场景
RAG 不是取代 LLM,而是给它装上 "知识雷达"。当答案需要基于特定文档(如企业内部文档、非公开文档)时,RAG 会让 AI 准确率明显提升。下面是一些 RAG 的落地场景:
- 智能客服:实时关联企业产品文档、用户手册、历史工单等,让客服回答动态匹配最新产品信息
- 企业知识库:将公司 Wiki、SOP 文档、会议纪要等文档导入 RAG 知识库,员工快速检索获得精准答案
- 法律咨询服务:构建法律条文 + 历史判例知识库,让 AI 当 "临时律师"