0. 前言:舆情分析的"进化史"
这篇文章和之前读的那几篇尤其是MulMoSenT,在舆情分析的'进化史'中处于一个互补且更进阶的位置,上一篇的MulMo是在教AI如何当好一个'孟加拉语专家',那么这篇就是在研究AI怎么成为一个'语言通'--利用语系的规律,把英语中学到的情感分析本事,'瞬移'到泰语、越南语等这些小语种上。
MSA 进化阶段速览
模型/方法 发表时间 核心武器 研究重点 CLIP 2021 双塔对齐 图文匹配基础,打通视觉与文本。 MISA 2020 特征解耦 解决声/影/文模态间的冗余与冲突。 Qwen-VL 2023 大模型大脑 通用认知、定位与细粒度描述。 MulMoSenT 2025 TICA 机制 精修派:在特定语料(孟加拉语)上靠注意力机制让文字救图片。 LFD-RT 2025 语系解耦 (LFD) 搬运派:利用语系亲缘关系进行无监督知识迁移。 和MulMoSenT有什么区别和联系:
- 相同点:两篇都在解决'低资源(小语种)'没数据没模型的问题
- 不同点:
- MulMoSenT:侧重于精修,在已有孟加拉语料上,用TICA这种更聪明的注意力机制,让文字救图片。
- LFD-RT:侧重于搬运,它觉得从小语种一张张标图太累了,它利用语系解,把英语里的情感知识过滤掉噪声,精准地传给和它相似的小语种。
1. Introduction:MSA 的分水岭
早期 MSA 研究以特征融合为主,经历了从特征级融合 (拼接、相加)到决策级融合(平均、投票)的转变。随后,研究重心分散到了多模态预训练、模态不变表示学习(如 MISA)、低资源跨语言迁移、缺失模态下的情感分析以及小样本学习等。
LFD-RT 的核心流程:
-
预训练阶段 :进行跨语言(CLA)与跨模态(CMA)对齐,通过语系解耦模块共享家族共性并剔除对齐噪声。
-
微调阶段 :提出反思策略(Rethinking),在无监督情况下通过"双重核查"机制适应下游任务。
这里可以回顾下早期的多模态特征融合,再普及下之后的研究方向分散情况:
特征融合:
- 特征级融合(2015-2018):分别提取文本图像特征,直接用拼接和元素相加方式粘在一起。这导致它们存在严重的模态鸿沟。
- 决策级融合:文字走文字的模型,图走图的模型。每个模型都给出一个预测结果(比如:文字模型说"积极"的概率是 0.8,图像模型说是 0.4),最后对这些分数(Scores)取平均、投票或加权求和。
研究方向:
- 多模态预训练:代表作为CLIP、BLIP、Qwen-VL(逐渐演进)。
- 模态不变表示学习:MISA(提取不同模态的模态不变特征和分离模态特定特征)
- 低资源于跨语言迁移:现在看的LFD-RT,把"模态不变学习"的思想升华了。它不仅要在"图"和"文"之间找共性,还要在"不同语系"之间找共性。
- 混合式融合:MMTC(虚假新闻检测模型)看图文,也看网友评论,属于 "内容+环境" 的综合体。这种流派不纠结于"怎么解耦",而纠结于"还能加什么数据来辅助判断"。
2. Related Work:近两年的顶尖突破
多模态情感分析:
- 处理缺失模态:Li等人引入了样本级对比学习和类别引导的原型提取技术,专门对付数据中可能缺失的视频或者音频情况。
- 深度语义融合:Zhu等人再24年提出基于文本的跨模态方法,将视频信息更紧密地融合进入文本语义中。
- 数据增强:Zhao等人在25年通过生成伪数据提升MSA性能
多语言情感分析:
- 增强生成方法:Kanayama 等人(2024)通过结合情感提取器和外部极性数据,增强了大模型在多语言环境下的生成能力。
- 翻译中转策略:Miah 等人 (2024) 则采用了较为传统但有效的路径,先将外语翻译成英语,再进行情感分析。
3. Methodology:LFD-RT 框架设计
3.1 预训练阶段:对齐与提纯
模型输入跨模态数据集 \\{T, I, y\\} 和平行语料库。
(1) 跨语言对齐 (CLA)
使用 mBERT 提取特征。注意: 作者采用了统一对比损失(Equation 2)。
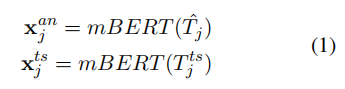
公式1就是它们利用mBERT提取锚点文本及其翻译的特征,第一个式子是先将锚点文本转化为一组高维度的数字(向量)。同样第二个转化的是目标文本。
现在既然两个文本都转化好了,就要开始进行对齐,但肯定会有损失,可是作者这里没有用普通的对比损失,而是统一对比损失(传统的就比如先对齐双语,再对齐文字和图像),直接让模型在同一个空间中同时对齐。
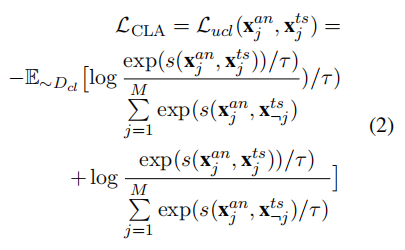
公式2定义的是跨语言对齐损失,就是通过对比学习来让模型在数学空间中把意思相同的不同语言文本"拉近"。公式中分子代表正确匹配的相似度,值越大越好,里面的s是相似度评分函数,计算的是余弦相似度,分母是锚点于批次中所有样本(也包括不相关的干扰项)的相似度总和。τ代表的是温度超参数,后面实验中它会默认设置为0.07,用来调节相似度得分的分布,让模型对细微的特征差异更加敏感。
深度纠错 :公式 2 实际上执行的是双向对齐。前项以图像为基准遍历文本负样本,后项以文本为基准遍历图像负样本。虽然余弦相似度数值相等,但分母的负样本集合不同,这决定了两个方向的 log 概率贡献完全不同。
(2) 跨模态对齐(CMA)
这一块用的也是同样的,唯一不同的是使用CLIP作为图像的编码输入,用的是跨模态数据集。
(3) 语系解耦模块 (LFD) ------ 核心创新
这是这篇论文的创新点,通过跨语言对齐后,对齐特征被输入至语系解耦模块,这模块设计在于如何设计能有效捕捉并保留语言普遍特征,同时最大限度减少语言特异性变异干扰的模型。举个例子,就比如英语和弗里西语它们在语法、词汇、后缀上非常像;而英语和汉语结构就完全不同,强行用英语逻辑去理解汉语或者汉语逻辑去理解英语,就会引入很多噪声。
-
交叉注意力:以锚点特征为 Q,语系特征为 K 和 V,提取"语系通用语义"。
-
掩码任务 (Mask1):强迫模型通过提纯后的特征 U_j 猜词,确保保留的是语义精髓。
-
KL 散度正则化:计算预测语系分布 P_j 与真实标签 Q_j 的距离,强行"压平"不属于当前语系的噪声信号。
3.2 微调阶段:无监督反思策略
这是模型在没有标签时的"自学"机制,通过两个并行的分类器(MLP_1, MLP_2)实现。
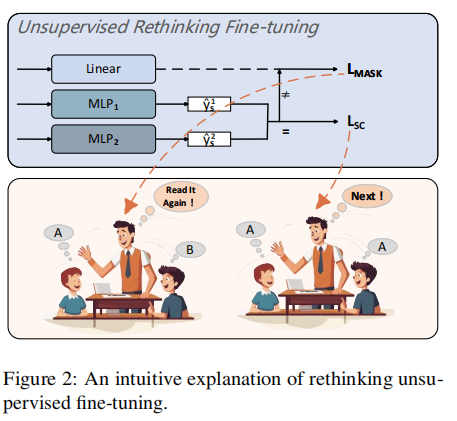
(1) Figure 2:反思机制直观解释
-
达成共识 (Agreement) :若 y_1 = y_2,生成伪标签,计算分类损失 L_{SC},强化记忆。
-
产生分歧 (Disagreement) :若 y_1 \\neq y_2,触发 Rethinking 。系统将文本
[MASK]掉,强迫模型结合图片重新进行"看图填空",计算掩码损失 L_{mask2}。
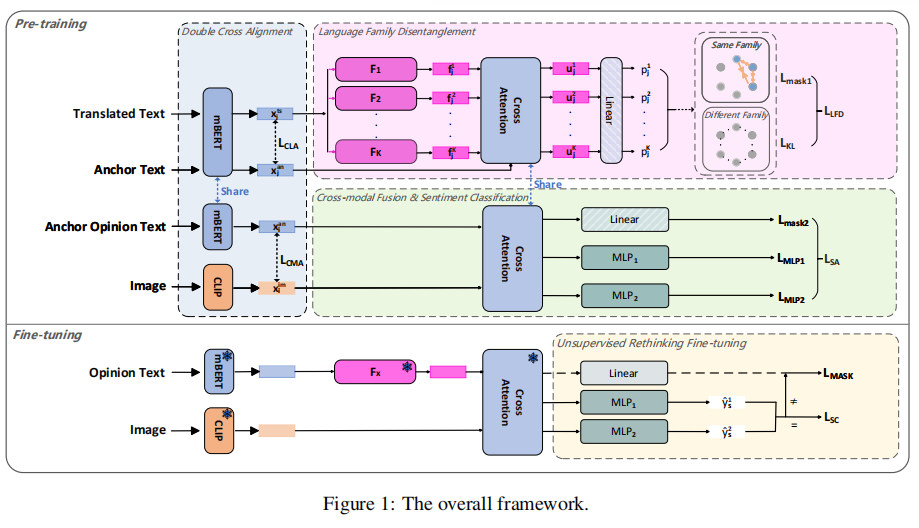
一个论文如果图画得好是几乎可以帮助理解整篇文章的,下面说一下Figure1的架构图:
注:模型设置了共13个预设的语系特征向量。
上面最左边的是对齐后的文本和图像向量被作为输入该模块。-------
- LFD模块(紫色部分的内容)
LFD 模块的设计初衷是:利用语言学上的"亲缘关系",将跨语言对齐后的特征拆解为语言通用特征(Universals)和语系特有噪声(Specifics)。
1. 核心机制:基于跨语系权重的"寻根"查询
模型并不孤立看待输入,而是将其放入全球 13 个预设语系的坐标系中进行定位:
查询 (Query):输入文本(如泰语)对齐后的锚点特征 Q。
键值 (Key & Value):13 个预设语系特征向量 K, V。
逻辑 :通过 Cross-Attention(交叉注意力),模型用泰语特征去"询问"这 13 个语系专家。
- 核心原理 :如果英语(源语)和泰语(目标语)在某个语系专家下的匹配度很高,说明这部分重合特征就是跨语言通用的核心语义。
2. 特征加工:从"提纯"到"定性"
提纯特征 (U_j) :通过对注意力结果进行加权求和,得到 U_j(提纯通用特征)。它代表了被剥离了语系杂质后的"纯粹语义"。
概率分布 (P_j) :将 U_j 送入线性层(Linear),映射到最终预测空间,得到文本属于 13 个不同语系的概率分布 P_j。这相当于给这段文本开了一张"家族身份证明"。
3. 两重约束:确保特征的"强"与"纯"
为了保证解耦后的特征既不丢失关键信息,又不掺杂其他语系的噪声,作者设置了双重损失函数:
约束一:掩码预测任务 (\\mathcal{L}_{mask1})
做法:挖掉输入文本中的词,强迫模型只用提纯后的 U_j 去"猜"被遮盖的词。
目的 :验证强度。如果模型能猜对,证明 U_j 虽然精简,但保留了最核心的语义支柱。同时,这也强迫同语系的样本在特征空间中靠得更近。
约束二:KL 散度正则化 (\\mathcal{L}_{KL})
做法:计算模型预测的语系分布 P_j 与真实语系标签之间的 KL 散度。
目的 :强制纯化。如果预测空间中混入了大量无关语系的特征(比如分析泰语时带入了过多的德语特征),KL 散度会迅速增大。
结果:通过反向传播,模型被迫"稀释"并剔除非目标语系的干扰信息,从而实现完美的特征解耦。
- CmF & SC模块(浅绿色部分)
依然是再次使用的交叉注意力识别图像和文本中的关联信息,之后送入三个并行的分支,线性层用的依然是掩码预测机制,跟上面用的方法是一样的,下面的两个MLP 用于做情感分类任务,根据融合特征判断该图文对表达的情感极性,最后,这些损失被整合为**\\mathcal{L}_{SA}**,用于指导模型在微调阶段。
下面的模块是微调模块,前面基本上跟预训练是一样的,但是后面多了个无监督反思微调,也就是不依赖真实标签,但是它依然保留了预训练时候的掩码任务,防止模型为了刻意迎合特定任务而忘掉通用信息,无监督只是用在了两个感知机的输出上,将y1和y2作的自监督,两者不一样就会产生语义一致性损失,强迫模型缩小两者差距。
后面的Figure2是直观地展示了这一"自省"过程,根据两个分类器(MLP_1 和 MLP_2)的判断结果,流程会走向截然不同的两条路径:
路径 A:达成共识(Agreement)------ 乘胜追击
触发条件:两个分类器对同一个图文对给出了相同的判断(例如都认为是"积极")。
操作逻辑:
伪标签诞生 :系统认为该预测结果具有极高的可信度,于是将其提取并设为伪标签(Pseudo-label)。
计算 L_{SC}:将伪标签带入交叉熵公式,计算分类损失 L_{SC}。
目的:通过反向传播,进一步巩固模型在这些"送分题"上的信心,确化模型对明确情感特征的捕捉能力。
路径 B:产生分歧(Disagreement)------ 闭门思过(Rethinking)
触发条件:两个分类器的答案不一致(一个说 A,一个说 B)。这通常意味着文字存在歧义,或者跨语言噪声干扰了判断。
操作逻辑:
强制反思 :系统拒绝生成伪标签,转而触发 Rethinking 机制。
掩码重构:回到最初的文本输入,随机"涂黑"部分单词(Mask)。
跨模态填空 :带着残缺的文本和原始图片,再次流经 LFD 模块与跨模态融合层。此时的任务不再是分类,而是猜词。
计算 L_{mask2}:对比预测词与原词,计算第二层掩码损失 L_{mask2}。
目的:通过"看图填空"这种更高难度的任务,强迫模型在文本失效时,深度挖掘图片与上下文的深层语义关联,从而消除分歧。
总结起来就是,我输入一段小语种图文对和标签,它会把这段特征送给13个语系专家分析,每个语系都会从自己的角度进行解读,看这段输入在多大程度上符合13个语系特征,但不会将权重低的概率直接扔掉,而是通过掩码和正则化的反向传播不断优化,稀释掉不属于标签描述语系的杂志信息。
4. Experiments & Result Analysis
4.1 数据集与实验细节
-
数据源:英文 Meld(老友记)、中文 CH-SIMS。通过翻译扩展至 28 种语言。
-
预训练语料:WikiMatrix(15 万文本对)。
-
配置:RTX 3090,训练 20 小时。
4.2 战报分析
-
主赛场 (Table 4 & 6) :LFD-RT 整体表现优于 GPT-4o 和 M2SA。尤其在 CH-SIMS 数据集上,模型在象形文字圈(中日韩)展现了极强的适配性。
-
跨语言实战 (Table 5):证明了语系亲缘关系的重要性(英语到法语的迁移优于到西班牙语)。
-
局限性:在"恶心"和"恐惧"等小样本情感上,受限于预训练数据量,表现略逊于 GPT-4o。
5. 总结:三个 Mask 的进阶之路
LFD-RT 框架巧妙地设置了三道关卡:
-
Mask (CLA):解决识字问题(字面翻译)。
-
Mask1 (LFD):解决噪声问题(语系共性提纯)。
-
Mask2 (Rethinking):解决分歧问题(图文深度对齐)。
Equation (16) 作为微调阶段的总指挥公式:
L_{total} = L_{SC} + \\lambda_5 L_{mask2}
它完美平衡了"巩固已有共识"与"通过重新思考攻克分歧"的逻辑。