TL;DR
- 场景:决策树模型对训练集分类能力强,但对未知测试集泛化能力差,容易过拟合
- 结论:预剪枝通过限制树的生长降低过拟合风险,但可能欠拟合;后剪枝全局优化效果更好但计算成本更高;ID3/C4.5/CART 三者核心差异在于分裂标准与剪枝策略
- 产出:掌握预剪枝/后剪枝原理,理解 ID3/C4.5/CART 算法差异,获得 Scala/Spark 决策树实战代码
版本矩阵
| 功能 | 状态 | 说明 |
|---|---|---|
| 预剪枝 | ✅ 已验证 | 通过限制树深度、节点样本数等规则提前停止生长 |
| 后剪枝 | ✅ 已验证 | 全局优化,删除子树后按多数原则确定叶节点类别 |
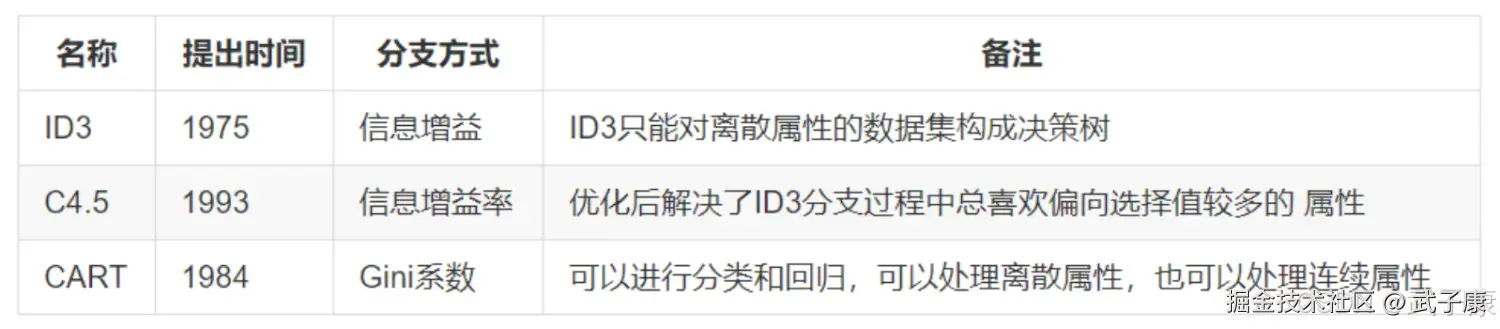
| ID3 算法 | ✅ 已验证 | 信息增益分裂标准,仅支持离散属性 |
| C4.5 算法 | ✅ 已验证 | 信息增益率,支持连续属性离散化与后剪枝 |
| CART 算法 | ✅ 已验证 | 基尼系数,二叉树结构,代价复杂度剪枝 |
| Spark MLlib 实战 | ✅ 已验证 | Scala 代码示例见文章末尾 |
预剪枝和后剪枝
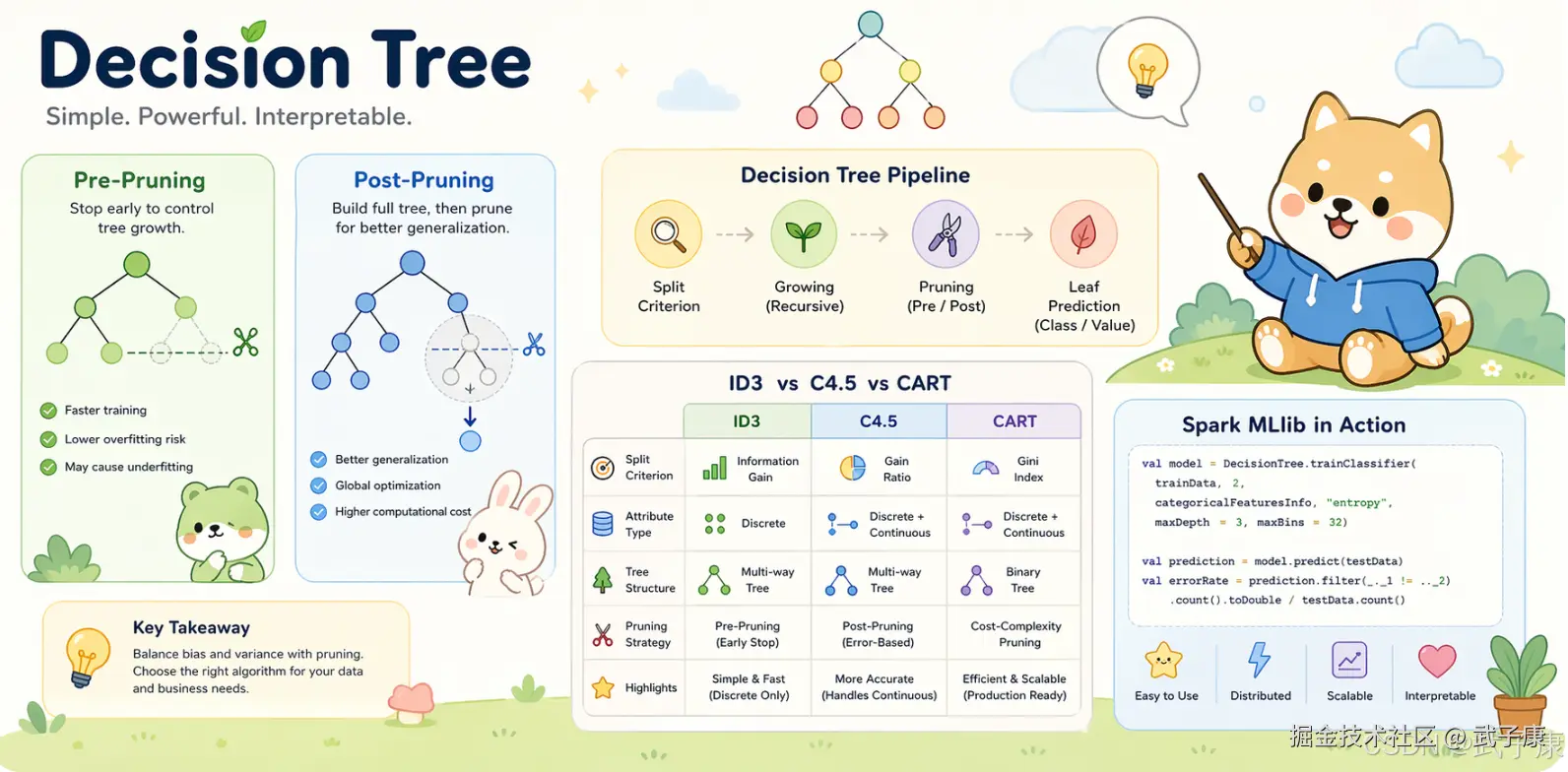
决策树对训练集有很好的分类能力,但是对于未知的测试集未必能有很好的分类能力,导致模型的泛化能力差,可能发生过拟合的情况,为了防止过拟合的情况出现,可以对决策树进行剪枝,剪枝分为预剪枝和后剪枝。
预剪枝
预剪枝就是在构建决策树的时候提前停止,比如指定树的深度最大为3,那么训练出来的决策树的高度就是3,预剪枝主要是建立某些规则限制决策树的生长,降低了过拟合的风险,降低了建树的时间,但是有可能带来欠拟合的问题。
后剪枝
后剪枝是一种全局的优化方法,在决策树构建好之后,然后才开始进行剪枝。后剪枝的过程就是删除一些子树,这个叶子节点的标识类别通过大多数原则来确定,即属于这个叶子节点下大多数样本所属的类别就是该叶子节点的标识。 选择减掉哪些子树时,可以计算没有减掉子树之前的误差和减掉子树之后的误差,如果相差不大,可以将子树减掉。 一般使用后剪枝得到的结果比较好。
算法总结
- 分裂标准(Split Criterion):选择划分属性与划分点
- 树生成(Growing):递归地对子集继续分裂
- 剪枝(Pruning):降低过拟合:预剪枝 / 事后剪枝
- 叶节点预测:分类树:投票 / 概率;回归树:均值 / 中位数
ID3、C4.5、CART 的区别主要体现在 分裂标准、支持的属性类型、树结构与剪枝方法。
ID3
存在的缺点: ● ID3 算法在选择根节点和各内部节点中的分支属性时,采用信息增益作为评价标准。信息增益的缺点是倾向于选择取值较多的属性,在有些情况下这类属性可能不会提供太多有价值的信息 ● ID3 算法只能对描述属性为离散型属性的数据集构造决策树
核心思想
信息增益 (Information Gain):选择能最大化熵下降(信息增益)的属性来分裂,仅支持 离散属性;连续属性需先离散化。 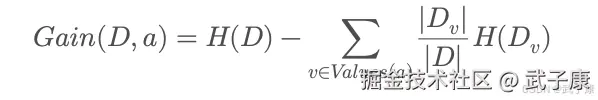
算法流程
- 计算当前数据集 D 的熵 H(D)
- 对每个属性 a 计算 Gain(D,a)
- 选 Gain 最大者分裂,对子集递归生成子树
- 当属性耗尽或样本纯度足够时停止
C4.5
那为什么 C4.5 好呢? ● 用信息增益率来选择属性 ● 可以处理连续数值型属性 ● 采用了一种后剪枝的方法 ● 对于缺失值的处理
优点: ● 产生的分类规则易于理解,准确率较高
缺点: ● 在构造数的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效 ● 只适合与能够驻留在内存的数据集,当训练集大得无法再内存中时则程序无法运行
CART
CART算法相比C4.5算法的分类方法,采用了简化的二叉树模型,同时特征选择采用了近似的基尼系数来简化计算。
流程要点
- 对每个特征枚举所有切分点 → 计算基尼下降量 / 均方误差下降量
- 选最大下降量的「特征 + 切分点」做二分
- 直到叶节点样本少于阈值或纯度满足停止准则
- 代价复杂度剪枝得到最终子树
决策树案例
scala
package icu.wzk.logic
import org.apache.spark.mllib.tree.DecisionTree
import org.apache.spark.mllib.util.MLUtils
import org.apache.spark.{SparkConf, SparkContext}
object LogicTest2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("dt")
val sc = new SparkContext(conf)
sc.setLogLevel("warn")
//读取数据集
val labeledPointData = MLUtils.loadLibSVMFile(sc, "./data/dt.data")
val trainTestData = labeledPointData.randomSplit(Array(0.8, 0.2), seed = 1)
val trainData = trainTestData(0)
val testData = trainTestData(1)
//训练模型
val categoriFeatureMap = Map[Int, Int](0 -> 4, 1 -> 4, 2 -> 3, 3 -> 3)
val model = DecisionTree.trainClassifier(trainData, 2,
categoriFeatureMap, "entropy", 3, 32)
//预测
val testRes = testData.map(data => {
(model.predict(data.features), data.label)
})
testRes.take(10).foreach(println(_))
//评价
val errorRate = testRes.filter(x => x._1 != x._2).count().toDouble /
testData.count()
println("错误率:" + errorRate)//if-else展示
println(model.toDebugString)
sc.stop()
}
}错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 决策树过拟合,训练集准确率高但测试集准确率低 | 模型对训练数据学习过度,捕捉了噪声 | 对比训练集与测试集准确率差异 | 采用预剪枝(限制深度/最小样本数)或后剪枝(代价复杂度剪枝) |
| ID3 信息增益偏向取值多的属性 | 信息增益公式天然倾向多取值属性 | 观察分裂属性分布 | 改用 C4.5 信息增益率或 CART 基尼系数 |
| C4.5 训练速度慢,大数据集内存溢出 | 需多次顺序扫描和排序,连续属性离散化开销大 | 监控内存使用与执行时间 | 改用 CART(近似基尼系数更高效)或采样/并行方案 |
| 预剪枝后模型欠拟合 | 预剪枝阈值设置过小,过早停止生长 | 观察树深度与验证集表现 | 调大预剪枝阈值,或改用后剪枝策略 |
| Spark 决策树报错 Dimension mismatch | categoriFeatureMap 配置与数据集特征数不匹配 | 检查特征数量与 Map 配置 | 确认数据实际特征维度,更新 MapInt, Int 配置 |
| Spark MLlib 决策树训练 OOM | 数据集过大且特征数多,单节点内存不足 | 监控 Spark UI 内存使用 | 调小 maxMemoryInMB,或切换到分布式集群模式 |