🔥个人主页: Milestone-里程碑
❄️个人专栏: <<力扣hot100>> <<C++>><<Linux>>
🌟心向往之行必能至
目录
[1. 创建视图:CREATE VIEW](#1. 创建视图:CREATE VIEW)
[2. 视图与基表的双向更新验证](#2. 视图与基表的双向更新验证)
[3. 删除视图:DROP VIEW](#3. 删除视图:DROP VIEW)
[五、实战 OJ:牛客网 - 针对 actor 表创建视图 actor_name_view](#五、实战 OJ:牛客网 - 针对 actor 表创建视图 actor_name_view)
[前置条件(actor 表结构)](#前置条件(actor 表结构))
[解题 SQL](#解题 SQL)
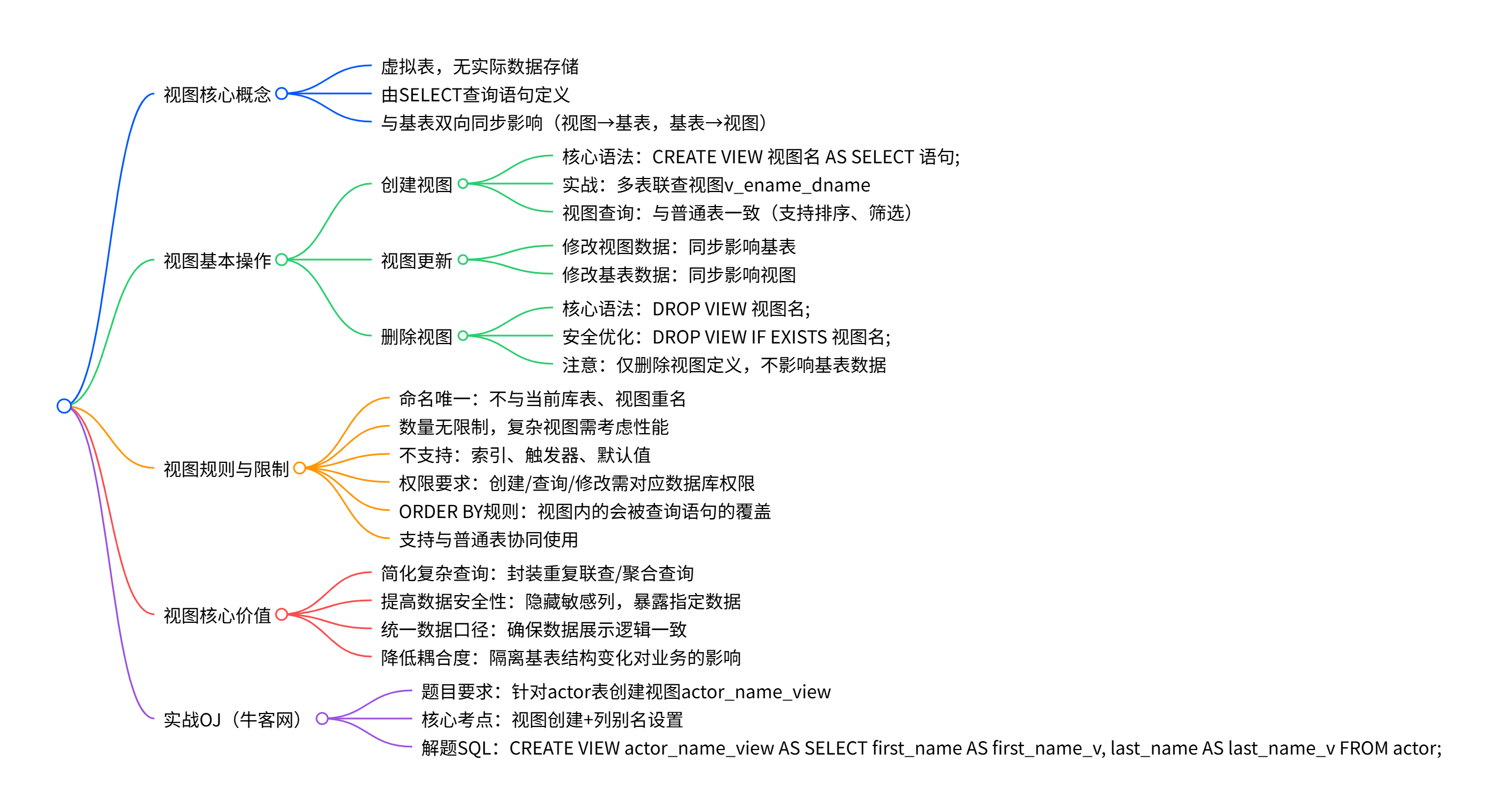
视图作为 MySQL 中重要的数据库对象,是很多开发者在数据查询、权限管控场景下的得力工具。很多初学者会疑惑 "视图和普通表有什么区别?""使用视图有哪些注意事项?",这篇文章就带大家从视图的核心概念出发,一步步掌握它的创建、使用、删除以及实战技巧,帮你彻底搞懂 MySQL 视图。
一、视图核心概念:什么是视图?
视图是一个虚拟表,它本身并不存储实际的数据,其内容完全由一条 SELECT 查询语句定义。
从外观上看,视图和真实的表毫无二致:它包含一系列带有名称的列和行数据,我们可以像操作普通表一样,对视图执行 SELECT 查询,甚至在满足条件时执行更新操作。
这里要重点记住视图和基表(视图对应的原始数据表)的双向影响关系:
- 对视图中的数据进行合法修改,会直接同步影响到对应的基表数据;
- 基表的数据发生变化(新增、修改、删除),也会实时反映在基于该基表创建的视图中。
这种双向绑定的特性,让视图在数据同步展示场景下极具价值。
二、视图基本使用:创建、查询、更新、删除
视图的核心操作围绕 "创建 - 使用 - 更新 - 删除" 展开,下面结合具体案例进行讲解,案例中使用经典的 EMP(员工表)和 DEPT(部门表)。
1. 创建视图:CREATE VIEW
创建视图的核心语法如下,语法要求简洁清晰,核心是后面的 SELECT 查询语句(可以是简单单表查询,也可以是多表联查、聚合查询等复杂查询)。
sql
-- 基本语法
CREATE VIEW 视图名 AS SELECT 语句;实战案例:创建一个视图 v_ename_dname,用于展示员工姓名和对应的部门名称,实现 EMP 表和 DEPT 表的联查。
sql
-- 创建多表联查视图
CREATE VIEW v_ename_dname AS
SELECT ename, dname
FROM EMP, DEPT
WHERE EMP.deptno=DEPT.deptno; -- 多表关联条件视图创建成功后,就可以像操作普通表一样,使用 SELECT 语句查询视图中的数据:
sql
-- 查询视图数据,支持排序、筛选等操作
SELECT * FROM v_ename_dname ORDER BY dname;查询结果如下(按部门名称排序),可以看到视图完美展示了我们需要的关联数据,无需每次都编写复杂的多表联查语句:
plaintext
+--------+------------+
| ename | dname |
+--------+------------+
| CLARK | ACCOUNTING |
| KING | ACCOUNTING |
| MILLER | ACCOUNTING |
| SMITH | RESEARCH |
| JONES | RESEARCH |
| SCOTT | RESEARCH |
| ADAMS | RESEARCH |
| FORD | RESEARCH |
| ALLEN | SALES |
| WARD | SALES |
| MARTIN | SALES |
| BLAKE | SALES |
| TURNER | SALES |
| JAMES | SALES |
+--------+------------+2. 视图与基表的双向更新验证
前面我们提到视图和基表是双向影响的,下面通过两个实战案例来验证这一点。
案例 1:修改视图数据,影响基表通过视图将员工 CLARK 的姓名修改为 TEST,然后查询基表 EMP,验证数据是否同步更新:
sql
-- 修改视图中的数据
UPDATE v_ename_dname SET ename='TEST' WHERE ename='CLARK';
-- 查询基表EMP,验证CLARK是否存在(无结果)
SELECT * FROM EMP WHERE ename='CLARK';
-- 查询基表EMP,验证TEST是否存在(有结果,数据已同步更新)
SELECT * FROM EMP WHERE ename='TEST';执行上述 SQL 后会发现,基表中的 CLARK 已经变成了 TEST,说明对视图的修改操作,直接同步到了基表中。
案例 2:修改基表数据,影响视图通过基表 EMP 将员工 JAMES 的部门编号修改为 10(原部门为 30),然后查询视图,验证数据是否同步更新:
sql
-- 修改基表EMP的数据
UPDATE EMP SET deptno=10 WHERE ename='JAMES';
-- 查询视图,验证JAMES对应的部门名称是否变化
SELECT * FROM v_ename_dname WHERE ename='JAMES';查询结果如下,可以看到 JAMES 对应的部门已经从 SALES 变成了 ACCOUNTING(部门 10 对应的部门名称),说明基表的修改也实时反映到了视图中:
plaintext
+-------+------------+
| ename | dname |
+-------+------------+
| JAMES | ACCOUNTING |
+-------+------------+3. 删除视图:DROP VIEW
当某个视图不再需要时,可以使用 DROP VIEW 语句将其删除,删除视图不会影响对应的基表数据(仅删除视图的定义,不删除原始数据),这一点非常重要。
sql
-- 基本语法
DROP VIEW 视图名;
-- 实战案例:删除前面创建的视图v_ename_dname
DROP VIEW v_ename_dname;注意:如果视图不存在,执行 DROP VIEW 会报错,MySQL 中可以添加
IF EXISTS关键字避免报错:DROP VIEW IF EXISTS 视图名;
三、视图的规则和限制
视图虽然使用灵活便捷,但并非没有约束,在使用视图的过程中,需要遵守以下核心规则和限制,避免踩坑。
- 命名唯一性约束:视图的名称必须唯一,不能与当前数据库中的其他表、其他视图重名,遵循与表名相同的命名规范。
- 创建数量无限制,但需考虑性能:理论上,MySQL 对创建视图的数量没有硬性限制,但如果视图基于复杂的多表联查、聚合查询(GROUP BY、SUM 等)创建,查询视图时的性能会大打折扣(因为视图每次被查询时,都会重新执行底层的 SELECT 语句),因此不建议将过于复杂的查询创建为视图。
- 不支持索引、触发器和默认值:视图是虚拟表,无法为视图添加索引(包括主键索引、普通索引),也不能为视图的列设置默认值,同时也无法创建与视图关联的触发器。如果需要优化查询性能,应优化视图底层的基表(如给基表添加索引)。
- 权限管控要求:创建视图需要具备足够的数据库权限(CREATE VIEW 权限),查询、修改视图也需要对应的 SELECT、UPDATE 等权限,这一特性也让视图可以用于提高数据安全性。
- ORDER BY 的覆盖规则:视图的定义中可以包含 ORDER BY 语句,但如果在查询视图时,SELECT 语句中也包含了 ORDER BY,那么视图中的 ORDER BY 会被覆盖,最终以查询视图时的 ORDER BY 为准。
- 可与普通表协同使用:视图可以和普通表一起参与查询,比如在多表联查中,视图可以作为其中一个 "表" 与其他普通表、其他视图进行关联查询。
四、视图的核心价值:为什么要使用视图?
了解了视图的使用方法和规则后,我们来总结一下视图的核心价值,明白它在实际开发中的应用场景:
- 简化复杂查询:这是视图最核心的价值,对于经常使用的复杂查询(多表联查、聚合查询等),可以将其封装为视图,后续使用时只需查询视图即可,无需重复编写复杂的 SQL 语句,提高开发效率。
- 提高数据安全性:可以通过视图向用户暴露指定的列和数据,隐藏基表中的敏感数据(如员工的薪资、身份证号等)。例如,只给普通用户开放 "员工姓名 + 部门名称" 的视图,不开放完整的 EMP 表,从而保护敏感数据。
- 统一数据展示口径:视图可以将分散在多个表中的数据整合为统一的展示口径,确保所有用户查询到的数据格式、逻辑一致,避免因个人编写 SQL 的差异导致数据结果不一致。
- 降低数据耦合度:业务系统中,如果前端或其他服务依赖某一固定格式的数据,可以通过视图封装数据结构,后续如果基表的结构发生变化(如字段更名、表结构调整),只需修改视图的定义,无需修改前端或服务的查询逻辑,降低耦合度。
五、实战 OJ:牛客网 - 针对 actor 表创建视图 actor_name_view
最后,我们通过一个经典的牛客网 OJ 题目,来巩固视图的创建技巧,检验学习成果。
题目要求
针对 actor 表创建视图 actor_name_view,视图中只包含 actor 表的 first_name 和 last_name 两列,并且列名分别为 first_name_v 和 last_name_v。
前置条件(actor 表结构)
| 列名 | 类型 | 说明 |
|---|---|---|
| actor_id | int(11) | 演员 ID |
| first_name | varchar(45) | 名 |
| last_name | varchar(45) | 姓 |
| last_update | datetime | 最后更新时间 |
解题 SQL
sql
-- 创建视图,指定列的别名(满足题目要求的列名)
CREATE VIEW actor_name_view AS
SELECT first_name AS first_name_v, last_name AS last_name_v
FROM actor;解题思路
- 遵循 CREATE VIEW 的基本语法,视图名指定为 actor_name_view;
- SELECT 语句中选择题目要求的 first_name 和 last_name 两列;
- 使用 AS 关键字为列设置别名,满足题目要求的 first_name_v 和 last_name_v;
- 底层查询表为 actor 表,无需复杂关联,直接单表查询即可。
六、总结
- 视图是虚拟表,由 SELECT 语句定义,与基表双向同步影响,修改一方会同步到另一方;
- 核心操作语法:
CREATE VIEW 视图名 AS SELECT 语句;(创建)、DROP VIEW 视图名;(删除),视图查询与普通表一致; - 视图有明确的使用限制,不支持索引、触发器,复杂视图需考虑性能问题;
- 视图的核心价值是简化查询、提高数据安全性、统一数据口径,在实际开发中应用广泛。