K8S高可用集群安装(基于Kubeadm+Docker)
一、环境说明
基础配置
- OS:Ubuntu Server 24.04 LTS
- CRI:Docker 28.2.2(Cgroup Driver: systemd)
- Kubernetes:1.35.0
- 节点资源:master节点4G、node节点2G、高可用/负载均衡节点1G
节点规划
| IP | 主机名 | 角色 |
|---|---|---|
| 10.0.0.112 | master1.wang.org | K8s集群主节点1(Master+etcd) |
| 10.0.0.113 | master2.wang.org | K8s集群主节点2(Master+etcd) |
| 10.0.0.114 | master3.wang.org | K8s集群主节点3(Master+etcd) |
| 10.0.0.115 | node1.wang.org | K8s集群工作节点1 |
| 10.0.0.116 | node2.wang.org | K8s集群工作节点2 |
| 10.0.0.117 | node3.wang.org | K8s集群工作节点3 |
| 10.0.0.118 | ha1.wang.org | K8s主节点访问入口1(高可用+负载均衡) |
| 10.0.0.119 | ha2.wang.org | K8s主节点访问入口2(高可用+负载均衡) |
| 10.0.0.100 | kubeapi.wang.org | VIP(在ha1/ha2实现) |
二、前置准备(所有节点执行)
1. SSH Key验证(可选,master1执行)
bash
# 生成密钥
ssh-keygen
# 分发密钥到所有节点(示例,需替换目标IP)
ssh-copy-id root@10.0.0.113
ssh-copy-id root@10.0.0.114
# 批量分发可循环处理
for i in {113..119};do ssh-copy-id root@10.0.0.$i;done补充说明:配置SSH免密登录可简化后续跨节点操作(如文件同步、命令执行),若节点IP范围变更,需对应调整循环中的IP段。
2. 安装rsyslog日志服务
bash
apt update
apt install -y rsyslog
systemctl enable --now rsyslog
systemctl status rsyslog补充说明:rsyslog用于集中管理节点日志,便于集群故障排查,安装后需确认服务状态为active。
3. 主机名与域名解析
bash
# 添加主机解析
cat >> /etc/hosts <<EOF
10.0.0.100 kubeapi.wang.org kubeapi
10.0.0.112 master1.wang.org master1
10.0.0.113 master2.wang.org master2
10.0.0.114 master3.wang.org master3
10.0.0.115 node1.wang.org node1
10.0.0.116 node2.wang.org node2
10.0.0.117 node3.wang.org node3
10.0.0.118 ha1.wang.org ha1
10.0.0.119 ha2.wang.org ha2
EOF
# 批量同步到其他节点(master1执行)
for i in {113..119};do scp /etc/hosts root@10.0.0.$i:/etc/; done补充说明 :主机名与IP映射需确保所有节点一致,否则会导致集群组件通信失败;同步后可登录其他节点执行cat /etc/hosts验证。
4. 时间同步
bash
# 设置时区
timedatectl set-timezone Asia/Shanghai
# 安装chrony
apt update && apt install chrony -y
# 修改配置文件,添加阿里云时间源
vim /etc/chrony/chrony.conf
# 新增:pool ntp.aliyun.com iburst maxsources 2
#加下面一行,添加aliyun时间同步服务器
pool ntp.aliyun.com iburst maxsources 2
pool ntp.ubuntu.com iburst maxsources 4
pool 0.ubuntu.pool.ntp.org iburst maxsources 1
pool 1.ubuntu.pool.ntp.org iburst maxsources 1
pool 2.ubuntu.pool.ntp.org iburst maxsources 2
# 重启服务
systemctl enable --now chrony
# 验证同步状态
chronyc sources补充说明 :K8s集群对时间同步要求严格(误差需控制在秒级),优先使用国内时间源可提升同步稳定性;chronyc sources输出中*代表已同步到对应时间源。
5. 关闭防火墙
bash
ufw disable
ufw status # 验证状态为"不活动"补充说明:Ubuntu默认使用ufw防火墙,关闭后需确认状态为"inactive";若使用其他防火墙(如iptables),需额外清理规则并停止服务。
6. 禁用Swap
在集群的 Master 和各 node 执行
bash
swapoff -a
sed -i '/swap/s/^/#/' /etc/fstab # 永久禁用补充说明 :K8s要求禁用Swap(避免资源调度异常),swapoff -a为临时禁用,修改/etc/fstab可永久生效;执行后可通过swapon --show验证无Swap分区启用。
7. 内核优化
集群的 Master 和各 node 执行
bash
#内核优化,集群的 Master 和各 node 执行,开机加载内核模块
cat <<EOF | tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
#立即加载内核模块
modprobe overlay
modprobe br_netfilter
# 验证模块加载
lsmod | grep -E 'overlay|br_netfilter'
# 设置sysctl参数,参数在重新启动后保持不变
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
#应用 sysctl 参数生效而不重新启动
sysctl --system 补充说明 :overlay用于容器存储层,br_netfilter用于桥接网络的iptables规则生效;sysctl --system会重载所有sysctl配置文件,无需重启节点。
三、高可用配置(ha1/ha2节点)
1. Keepalived(VIP管理)
在两台主机ha1和ha2 按下面步骤部署和配置 keepalived
安装
bash
# 改名
hostnamectl hostname ha1 # ha1执行
hostnamectl hostname ha2 # ha2执行
# 安装keepalived
apt update && apt -y install keepalived
cp /etc/keepalived/keepalived.conf.sample /etc/keepalived/keepalived.conf配置ha1
bash
vim /etc/keepalived/keepalived.conf
global_defs {
router_id ha1.wang.org #指定router_id,#在ha2上为ha2.wang.org
}
#检测haproxy服务是否存活
vrrp_script check_haproxy {
script "killall -0 haproxy"
interval 1
weight -30
fall 3
rise 2
timeout 2
}
vrrp_instance VI_1 {
state MASTER #在ha2上为BACKUP
interface ens33
garp_master_delay 10
smtp_alert
virtual_router_id 51 #指定虚拟路由器ID,ha1和ha2此值必须相同
priority 100 #在ha2上为80
advert_int 1
authentication {
auth_type PASS
auth_pass 123456 #指定验证密码,ha1和ha2此值必须相同
}
virtual_ipaddress {
10.0.0.100/24 dev ens33 label ens33:1 #指定VIP,ha1和ha2此值必须相同
}
track_script {
check_haproxy
}
}配置ha2
bash
vim /etc/keepalived/keepalived.conf
global_defs {
router_id ha2.wang.org #指定router_id,#在ha2上为ha2.wang.org
}
vrrp_instance VI_1 {
state BACKUP #在ha2上为BACKUP
interface ens33
garp_master_delay 10
smtp_alert
virtual_router_id 51 #指定虚拟路由器ID,ha1和ha2此值必须相同
priority 80 #在ha2上为80
advert_int 1
authentication {
auth_type PASS
auth_pass 123456 #指定验证密码,ha1和ha2此值必须相同
}
virtual_ipaddress {
10.0.0.100/24 dev ens33 label ens33:1 #指定VIP,ha1和ha2此值必须相同
}
}启动验证
bash
systemctl restart keepalived
hostname -I # 验证VIP(10.0.0.100)是否存在补充说明:
interface ens33需替换为节点实际网卡名称(可通过ip addr查看);vrrp_script check_haproxy用于监控haproxy状态,若haproxy故障,keepalived会降低节点优先级,触发VIP切换;- 验证时,ha1正常情况下应持有VIP,停止ha1的keepalived服务后,VIP应自动漂移到ha2。
2. Haproxy(负载均衡)
通过 Harproxy 实现 kubernetes Api-server的四层反向代理和负载均衡功能
在ha1和ha2都执行下面操作
配置系统参数
bash
#允许监听不存在的 IP
cat >> /etc/sysctl.conf <<EOF
net.ipv4.ip_nonlocal_bind = 1
EOF
sysctl -p安装配置
bash
apt -y install haproxy
vim /etc/haproxy/haproxy.cfg
...
errorfile 503 /etc/haproxy/errors/503.http
errorfile 504 /etc/haproxy/errors/504.http
# 在文件末尾添加:
listen stats
mode http
bind 0.0.0.0:8888
stats enable
log global
stats uri /status
stats auth admin:123456
listen kubernetes-api-6443
bind 10.0.0.100:6443
mode tcp
server master1 10.0.0.112:6443 check inter 3s fall 3 rise 3
# 集群初始化后启用master2/3
# server master2 10.0.0.113:6443 check inter 3s fall 3 rise 3
# server master3 10.0.0.114:6443 check inter 3s fall 3 rise 3
# 重启服务
systemctl restart haproxy
systemctl is-active haproxy # 验证状态为active验证
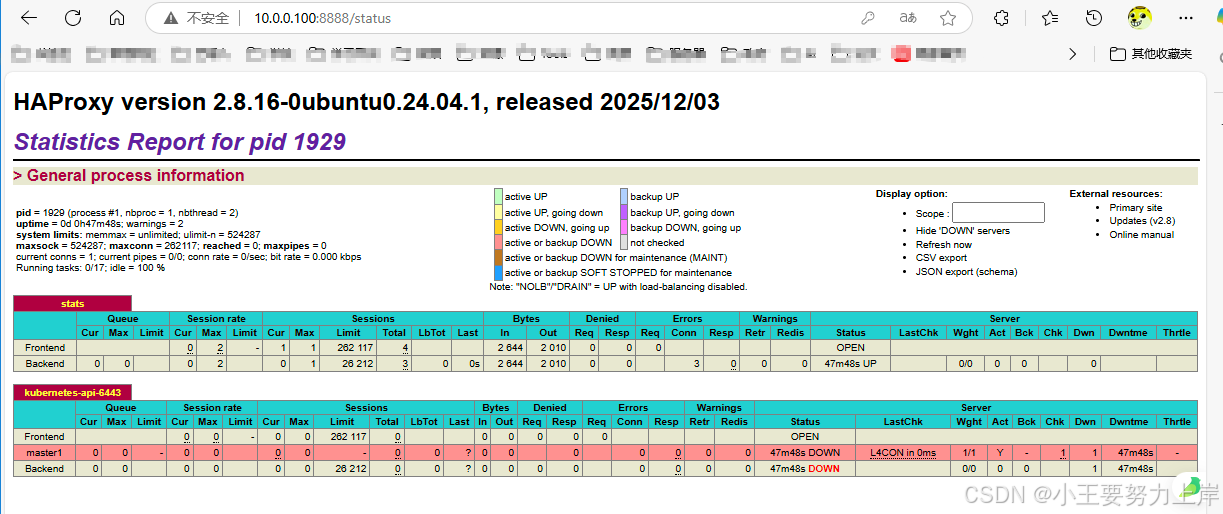
浏览器访问 http://10.0.0.100:8888/status(账号admin/123456)
补充说明:
mode tcp表示四层负载均衡(适配K8s Api-server的TCP协议);check inter 3s fall 3 rise 3表示每3秒检查后端节点状态,连续3次失败标记为不可用,连续3次成功标记为可用;- 集群初始化完成后,需取消master2/3的注释,实现多master节点的负载均衡;
- 验证页面可查看后端节点的健康状态,确保master1的6443端口可正常访问。
四、容器运行时配置(所有master/node节点)
1. 安装Docker
bash
apt update && apt -y install docker.io
docker version
#因为国内无法访问docker官方镜像,需要配置docker访问docker官方镜像
cat > /etc/docker/daemon.json <<EOF
{
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://docker.1panel.live",
"https://docker.1ms.run",
"https://docker.xuanyuan.me"
],
"insecure-registries": ["harbor.wang.org"]
}
EOF
systemctl restart docker补充说明:
registry-mirrors配置国内Docker镜像源,提升镜像拉取速度;insecure-registries用于配置私有镜像仓库(如Harbor),若无需私有仓库可删除该行;- 配置完成后可通过
docker info查看镜像源是否生效。
2. 安装cri-dockerd(适配K8S 1.24+)
在所有主机上下载Linux通用二进制文件并创建service和socket文件
bash
VERSION=0.4.2
# 下载二进制包
wget https://github.com/Mirantis/cri-dockerd/releases/download/v${VERSION}/cri-dockerd-${VERSION}.amd64.tgz
#-t 查看里面内容,-x解压缩
tar -xvf cri-dockerd-${VERSION}.amd64.tgz
mv cri-dockerd/cri-dockerd /usr/bin/
# 下载service/socket文件
wget -O /etc/systemd/system/cri-docker.service https://raw.githubusercontent.com/Mirantis/cri-dockerd/refs/heads/master/packaging/systemd/cri-docker.service
wget -O /etc/systemd/system/cri-docker.socket https://raw.githubusercontent.com/Mirantis/cri-dockerd/refs/heads/master/packaging/systemd/cri-docker.socket
#/lib/systemd/system/和/etc/systemd/system/ 都是存放服务配置文件的,可以指定wget下载位置
# 启动服务
systemctl daemon-reload && systemctl enable --now cri-docker.service && systemctl enable --now cri-docker.socket补充说明:
- K8s 1.24+移除了对Docker的直接支持,需通过cri-dockerd实现Docker与K8s的适配;
- 若wget下载失败,可手动下载二进制包和配置文件后上传至节点;
- 启动后通过
systemctl status cri-docker.service确认服务状态为active。
3. 配置cri-dockerd国内镜像(v1.24以后版本)
众所周知的原因,从国内 cri-dockerd 服务无法下载 k8s.gcr.io上面相关镜像,导致无法启动,所以需要修改 cri-dockerd 使用国内镜像源
bash
vim /lib/systemd/system/cri-docker.service
# 修改ExecStart行:
#最新版Kubernetes v1.35.0和v1.34.1
ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd:// --pod-infra-container-image registry.aliyuncs.com/google_containers/pause:3.10.1
# 批量同步到其他节点(master1执行)
for i in {113..117};do
scp /lib/systemd/system/cri-docker.service 10.0.0.$i:/lib/systemd/system/cri-docker.service;
ssh 10.0.0.$i "systemctl daemon-reload && systemctl restart cri-docker.service";
done补充说明:
pause镜像为K8s基础镜像,用于Pod的网络命名空间共享;- 需确保镜像版本与K8s版本兼容(v1.35.0适配pause:3.10.1);
- 同步后需在各节点重启cri-docker服务,避免配置不生效。
五、K8S组件安装(所有master/node节点)
1. 安装kubeadm/kubelet/kubectl
通过国内镜像站点阿里云安装的参考链接:
https://developer.aliyun.com/mirror/kubernetes
bash
# 添加阿里云源
apt-get update && apt-get install -y apt-transport-https
export K8S_VERSION=v1.35
curl -fsSL https://mirrors.aliyun.com/kubernetes-new/core/stable/${K8S_VERSION}/deb/Release.key | gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
echo "deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://mirrors.aliyun.com/kubernetes-new/core/stable/${K8S_VERSION}//deb/ /" | tee /etc/apt/sources.list.d/kubernetes.list
#查看版本信息
apt-cache madison kubeadm
#查看kubeadm,kubectl,kubelet最新版本
apt list kubeadm kubectl kubelet
#安装指定版本的k8s相关包
#在所有master和node节点安装 kubeadm,kubelet和kubectl,但是默认为最新版本,所以此处要指定版本
#注意:因为有依赖关系,安装kubeadm时会自动安装kubelet和kubectl,但是为最新版本,所以此处要指定版本
#1.30版本后没有相互的依赖需要指定三个安装包
apt -y install kubeadm kubelet kubectl
# 锁定版本防止自动升级
apt-mark hold kubelet kubeadm kubectl docker.io
#需要升级时,可以解锁
apt-mark unhold kubelet kubeadm kubectl docker.io
bash
#服务kubelet因缺少配置文件默认无法启动,需要初始化
[root@master1 ~ ]# systemctl status kubelet
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; preset:>
Drop-In: /usr/lib/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: activating (auto-restart) (Result: exit-code) since Sun 2026-04-1>
Docs: https://kubernetes.io/docs/
Process: 5336 ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET>
Main PID: 5336 (code=exited, status=1/FAILURE)
CPU: 64ms
4月 19 23:48:30 master1 systemd[1]: kubelet.service: Main process exited, code>
4月 19 23:48:30 master1 systemd[1]: kubelet.service: Failed with result 'exit->
lines 1-12/12 (END)
[root@master1 ~ ]# tail /var/log/syslog
2026-04-19T23:49:11.758654+08:00 master1 (kubelet)[5368]: kubelet.service: Referenced but unset environment variable evaluates to an empty string: KUBELET_KUBEADM_ARGS
2026-04-19T23:49:11.840537+08:00 master1 kubelet[5368]: E0419 23:49:11.840343 5368 run.go:72] "command failed" err="failed to load kubelet config file, path: /var/lib/kubelet/config.yaml, error: failed to load Kubelet config file /var/lib/kubelet/config.yaml, error failed to read kubelet config file \"/var/lib/kubelet/config.yaml\", error: open /var/lib/kubelet/config.yaml: no such file or directory"
2026-04-19T23:49:11.843745+08:00 master1 systemd[1]: kubelet.service: Main process exited, code=exited, status=1/FAILURE
2026-04-19T23:49:11.843906+08:00 master1 systemd[1]: kubelet.service: Failed with result 'exit-code'.
2026-04-19T23:49:21.999456+08:00 master1 systemd[1]: kubelet.service: Scheduled restart job, restart counter is at 6.
2026-04-19T23:49:22.005473+08:00 master1 systemd[1]: Started kubelet.service - kubelet: The Kubernetes Node Agent.
2026-04-19T23:49:22.006205+08:00 master1 (kubelet)[5376]: kubelet.service: Referenced but unset environment variable evaluates to an empty string: KUBELET_KUBEADM_ARGS
2026-04-19T23:49:22.071439+08:00 master1 kubelet[5376]: E0419 23:49:22.071242 5376 run.go:72] "command failed" err="failed to load kubelet config file, path: /var/lib/kubelet/config.yaml, error: failed to load Kubelet config file /var/lib/kubelet/config.yaml, error failed to read kubelet config file \"/var/lib/kubelet/config.yaml\", error: open /var/lib/kubelet/config.yaml: no such file or directory"
2026-04-19T23:49:22.075990+08:00 master1 systemd[1]: kubelet.service: Main process exited, code=exited, status=1/FAILURE
2026-04-19T23:49:22.076141+08:00 master1 systemd[1]: kubelet.service: Failed with result 'exit-code'.
#kubelet 启动失败,因为找不到 /var/lib/kubelet/config.yaml 这个配置文件
#你这台机器 还没有执行 kubeadm init(搭建 master) 或者 kubeadm join(加入集群)
#kubelet 只有在 初始化集群 / 加入集群后 才会生成这个配置文件!补充说明:
- 安装时若需指定具体版本(如1.35.0),可将
apt -y install kubeadm kubelet kubectl改为apt -y install kubeadm=1.35.0-00 kubelet=1.35.0-00 kubectl=1.35.0-00; apt-mark hold可防止系统更新时自动升级K8s组件,避免版本不一致导致集群故障;- kubelet启动失败为正常现象,完成
kubeadm init/join后会自动生成配置文件并正常启动。
2. 命令补全(可选)
bash
# 1. 安装补全依赖
apt update
apt install -y bash-completion
# 2. 配置 kubectl 补全
kubectl completion bash | tee /etc/bash_completion.d/kubectl
# 3. 配置 kubeadm 补全
kubeadm completion bash | tee /etc/bash_completion.d/kubeadm
# 4. 立即生效
source /usr/share/bash-completion/bash_completion
source ~/.bashrc
#永久生效(下次登录依然能用)
echo "source /etc/bash_completion.d/kubectl" >> ~/.bashrc
echo "source /etc/bash_completion.d/kubeadm" >> ~/.bashrc
#测试
kubeadm <按两下 Tab>
kubectl <按两下 Tab>补充说明:命令补全可提升操作效率,仅需在需要频繁执行kubectl/kubeadm命令的节点配置(如master1)。
六、集群初始化与节点加入
1. 初始化master1节点
在第一个 master 节点准备安装 kubernetes 所需的相关镜像 (可选)
在三台 master 中任意一台 master 主机执行kubeadm命令进行集群初始化,而且集群初始化只需要初始化一次
bash
K8S_RELEASE_VERSION=1.35.0
kubeadm init \
--kubernetes-version=v${K8S_RELEASE_VERSION} \
--control-plane-endpoint kubeapi.wang.org \
--pod-network-cidr=10.244.0.0/16 \
--service-cidr=10.96.0.0/12 \
--token-ttl=0 \
--image-repository=registry.aliyuncs.com/google_containers \
--upload-certs \
--cri-socket=unix:///run/cri-dockerd.sock
# 初始化失败可重置
# kubeadm reset -f --cri-socket=unix:///run/cri-dockerd.sock
bash
#参数注解
kubeadm init \
# 1. 指定要安装的 Kubernetes 版本号(从环境变量 K8S_RELEASE_VERSION 读取)
--kubernetes-version=v${K8S_RELEASE_VERSION} \
# 2. 高可用 VIP/域名(多 master 必须用,单 master 也建议写)
--control-plane-endpoint kubeapi.wang.org \
# 3. Pod 网络地址段(Flannel 网络插件必须用 10.244.0.0/16)
--pod-network-cidr=10.244.0.0/16 \
# 4. Service 网络地址段(K8s 默认就是这个,不用改)
--service-cidr=10.96.0.0/12 \
# 5. 节点加入集群的 token 永不过期(方便以后随时加节点)
--token-ttl=0 \
# 6. 镜像仓库改成阿里云(解决国内拉不到 K8s 官方镜像的问题)
--image-repository=registry.aliyuncs.com/google_containers \
# 7. 多 master 高可用集群必须加:自动上传证书到集群
--upload-certs \
# 8. 指定容器运行时为 cri-dockerd(如果你用的是 docker,必须加这个)
--cri-socket=unix:///run/cri-dockerd.sock初始化完成后输出的信息记得保存一下,里面的信息后面会用到。
bash
#初始化完成后输出的信息
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes running the following command on each as root:
kubeadm join kubeapi.wang.org:6443 --token vc2eeq.5nlx8gmrizyg1od5 --discovery-token-ca-cert-hash sha256:808fd66ad363c9a9cd585f342e12edcaf41d7034fcb07dda057e66a089f7b496 --control-plane --certificate-key 36bfe129dfef20da54f6d291223172165e21f5089d304d13ca1c32750ecd4e3d
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join kubeapi.wang.org:6443 --token vc2eeq.5nlx8gmrizyg1od5 \
--discovery-token-ca-cert-hash sha256:808fd66ad363c9a9cd585f342e12edcaf41d7034fcb07dda057e66a089f7b496需要保存的信息:
bash
#master节点使用
kubeadm join kubeapi.wang.org:6443 --token vc2eeq.5nlx8gmrizyg1od5 --discovery-token-ca-cert-hash sha256:808fd66ad363c9a9cd585f342e12edcaf41d7034fcb07dda057e66a089f7b496 --control-plane --certificate-key 36bfe129dfef20da54f6d291223172165e21f5089d304d13ca1c32750ecd4e3d
#worker节点使用
kubeadm join kubeapi.wang.org:6443 --token vc2eeq.5nlx8gmrizyg1od5 --discovery-token-ca-cert-hash sha256:808fd66ad363c9a9cd585f342e12edcaf41d7034fcb07dda057e66a089f7b496补充说明:
--control-plane-endpoint指定VIP/域名,确保多master节点的统一访问入口;--upload-certs会自动上传证书到集群,有效期2小时,若超时需重新执行kubeadm init phase upload-certs --upload-certs;- 初始化过程中若镜像拉取失败,可手动下载镜像后再执行初始化(参考后续master2/3的镜像同步方法);
- 保存的join命令中,token和cert-hash为实际环境值,需替换为自身集群输出的内容。
2. 配置kubectl授权(master1)
bash
# 创建.kube目录,用于存放kubectl配置文件
mkdir -p $HOME/.kube
# 将集群管理员配置文件复制到当前用户kubectl默认加载路径
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
# 修改配置文件所属用户和组为当前用户,避免权限不足
chown $(id -u):$(id -g) $HOME/.kube/config补充说明:
- 若使用root用户操作,可直接执行
export KUBECONFIG=/etc/kubernetes/admin.conf临时生效; - 配置完成后可执行
kubectl get nodes验证是否能正常访问集群(此时仅master1节点,状态为NotReady)。
3. 加入其他master节点(master2/3)
步骤1:同步镜像(解决网络拉取失败)
bash
# master1打包镜像
docker save -o k8s-images.tar $(docker images --format "{{.Repository}}:{{.Tag}}")
# 分发到master2/3
for i in {113..114};do scp ./k8s-images.tar root@10.0.0.$i:/root;done
# master2/3导入镜像
docker load -i k8s-images.tar
#用tag将registry.aliyuncs.com/google_containers/pause:3.10.1 改为registry.k8s.io/pause:3.10.1,让其认为这是k8s官方下载的镜像
docker tag registry.aliyuncs.com/google_containers/pause:3.10.1 registry.k8s.io/pause:3.10.1补充说明:
- 镜像打包/导入可避免master2/3因网络问题拉取镜像失败;
- 若镜像文件过大,可使用
scp -C开启压缩传输,提升速度; docker tag用于修正镜像仓库前缀,确保K8s组件能识别镜像。
步骤2:执行加入命令(替换实际token和cert-hash)
bash
kubeadm join 控制平面地址:6443 \
--token=xxx \ # 集群接入令牌(身份验证)
--discovery-token-ca-cert-hash=xxx # CA证书哈希,验证集群合法性(防冒充)
--control-plane \ # 指定以 Master(控制平面)身份加入
--certificate-key=xxx \ # 多Master证书同步密钥(必须)
--cri-socket=unix:///run/cri-dockerd.sock # 指定容器运行时
bash
#根据前面集群初始化时最后面信息,添加master2和master3节点
kubeadm join kubeapi.wang.org:6443 \
--token vc2eeq.5nlx8gmrizyg1od5 \
--discovery-token-ca-cert-hash sha256:808fd66ad363c9a9cd585f342e12edcaf41d7034fcb07dda057e66a089f7b496 \
--control-plane \
--certificate-key 36bfe129dfef20da54f6d291223172165e21f5089d304d13ca1c32750ecd4e3d \
--cri-socket=unix:///run/cri-dockerd.sock #注意:v1.24版本需要添加此项才能支持docker
# 配置kubectl授权(master2/3)(可选,配置了此节点具有控制权限)
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
#查看加入的master节点信息
[root@master1 ~ ]# kubectl get nodes补充说明:
- 加入命令中的
--control-plane表示以控制平面节点加入,--certificate-key为初始化时输出的证书密钥; - 加入完成后,master2/3的kubelet会自动启动并生成配置文件;
- 执行
kubectl get nodes可看到master2/3节点,状态为NotReady(需安装网络插件后变为Ready)。
4. 加入worker节点(node1/2/3)
这是工作节点,没有 --control-plane、--certificate-key,执行后节点会作为普通工作节点加入集群
bash
kubeadm join kubeapi.wang.org:6443 \
--token vc2eeq.5nlx8gmrizyg1od5 \
--discovery-token-ca-cert-hash sha256:808fd66ad363c9a9cd585f342e12edcaf41d7034fcb07dda057e66a089f7b496 \
--cri-socket=unix:///run/cri-dockerd.sock
#查看加入所有节点信息
[root@master1 ~ ]# kubectl get nodes补充说明:
- worker节点无需同步镜像(加入后会自动拉取所需镜像,若网络问题可参考master节点的镜像同步方法);
- 加入完成后,节点状态为NotReady,需安装网络插件后变为Ready;
- 若token过期,可在master1执行
kubeadm token create --print-join-command生成新的join命令。
七、网络插件安装(master1执行)
Kubernetes系统上Pod网络的实现依赖于第三方插件进行,这类插件有近数十种之多,较为著名的有 flannel、calico、canal和kube-router等,简单易用的实现是为CoreOS提供的flannel项目。下面的命令 用于在线部署flannel至Kubernetes系统之上
- 官方仓库地址:https://github.com/flannel-io/flannel/
- 关键前提:下载可能需要科学上网,若失败可使用代理链接
- 网段适配:需与K8s初始化时
--pod-network-cidr=10.244.0.0/16保持一致(默认无需修改)
1. 安装flannel
离线镜像压缩包:flannel.tar
离线配置文件: kube-flannel-v0.28.2.yml
查看节点信息为NotReady状态,原因为没有网络插件
bash
# 加载离线镜像(如有)
[root@master1 ~ ]# docker load -i flannel.tar下载Flannel配置文件(二选一,优先新版)
bash
#新版配置文件(推荐,适配K8s v1.17+)
# 直接下载(需科学上网)
[root@master1 ~]# wget https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml
# 下载失败时,使用代理链接(推荐)
[root@master1 ~]# wget https://mirror.ghproxy.com/https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml
# 旧版配置文件(备用,适配低版本K8s)
[root@master1 ~]# wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml修改配置文件(可选,按需操作)
若K8s初始化时自定义了 --pod-network-cidr(非10.244.0.0/16),需修改配置文件中的网段,否则无需修改:
bash
#离线把flannel的镜像导入的话,后续因为网络问题下载镜像出错的问题可以避免。
#使用下载好的配置文件,文件名为:kube-flannel-v0.28.2.yml(我使用的是这个,下同)
[root@master1 ~]# vim kube-flannel-v0.28.2.yml
#在线下载的话使用下面的命令
[root@master1 ~]# vim kube-flannel.yml
#找到以下内容,将Network值改为自己的pod网段(默认10.244.0.0/16可跳过):
net-conf.json: |
{
"Network": "10.244.0.0/16", # 与--pod-network-cidr保持一致
"Backend": {
"Type": "vxlan"
}
}部署Flannel(仅在第一个Master节点执行)
bash
# 应用配置
[root@master1 ~ ]# kubectl apply -f kube-flannel-v0.28.2.yml
### 正常部署输出(出现以下内容即为成功):
Warning: policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
podsecuritypolicy.policy/psp.flannel.unprivileged created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds created
#使用如下命令确认其输出结果中Pod的状态为"Running"
[root@master1 ~ ]# kubectl get pods -n kube-flannel
NAME READY STATUS RESTARTS AGE
kube-flannel-ds-494gx 1/1 Running 0 11m
kube-flannel-ds-5fb8g 1/1 Running 0 11m
kube-flannel-ds-6nnrr 1/1 Running 0 11m
kube-flannel-ds-s4zxf 1/1 Running 0 11m
kube-flannel-ds-xhgrm 1/1 Running 0 11m
kube-flannel-ds-xkkgd 1/1 Running 0 11m
# 验证节点状态
[root@master1 ~ ]# kubectl get nodes # 所有节点应为Ready补充说明:
- Flannel是轻量级网络插件,适合小规模集群;若需更高级的网络策略(如网络隔离),可选择Calico;
- 部署后需等待1-2分钟,让Flannel Pod在所有节点启动,节点状态会从NotReady变为Ready;
- 若Flannel Pod启动失败,可执行
kubectl logs -n kube-flannel <pod-name>查看日志,常见原因包括网段不匹配、镜像拉取失败; - 离线部署时,需先在所有节点加载flannel镜像,再执行
kubectl apply。
八、集群测试
1. 创建测试Deployment和Service
bash
# 创建deployment(2副本)
kubectl create deployment pod-test --image=registry.cn-beijing.aliyuncs.com/wangxiaochun/pod-test:v0.1 --replicas=2
# 扩容到3副本
kubectl scale deployment/pod-test --replicas=3
# 创建NodePort服务
kubectl create service nodeport pod-test --tcp=80:80
# 查看服务端口
kubectl get svc -l app=pod-test
# 外部访问:http://NodeIP:NodePort(如http://10.0.0.115:32246)补充说明:
pod-test镜像为测试用Web服务,可返回节点信息;NodePort服务会在所有节点开放一个随机端口(30000-32767),通过任意节点的该端口可访问Pod;- 验证步骤:
- 执行
kubectl get pods确认测试Pod为Running; - 执行
kubectl get svc pod-test获取NodePort端口; - 浏览器访问
http://NodeIP:NodePort,应能看到测试页面; - 执行
kubectl delete deployment pod-test && kubectl delete svc pod-test清理测试资源。
- 执行
九、常见问题处理
1. 清理错误环境
bash
kubeadm reset -f --cri-socket=unix:///var/run/cri-dockerd.sock
rm -rf /etc/kubernetes /var/lib/etcd /var/lib/kubelet $HOME/.kube
systemctl restart docker cri-docker补充说明:
- 重置集群会清除所有K8s配置和数据,需谨慎操作;
- 重置后若需重新初始化,需确保所有节点执行相同的重置步骤;
- 若重置后仍有残留问题,可重启节点后再重新操作。
2. kubelet启动失败
- 原因:未执行
kubeadm init/join,缺少/var/lib/kubelet/config.yaml - 解决:完成集群初始化/节点加入后自动生成配置文件
补充说明: - 若完成
kubeadm init/join后仍启动失败,可检查:- cri-dockerd服务是否正常(
systemctl status cri-docker.service); /etc/systemd/system/kubelet.service.d/10-kubeadm.conf配置是否正确;- 执行
journalctl -u kubelet -f查看kubelet日志,定位具体错误。
- cri-dockerd服务是否正常(
3. flannel网络异常
- 检查
pod-network-cidr与flannel配置是否一致 - 重新加载镜像:
docker load -i flannel.tar - 重建网络:
kubectl delete -f kube-flannel-v0.28.2.yml && kubectl apply -f kube-flannel-v0.28.2.yml
补充说明: - 若Pod之间无法通信,可检查:
- 节点间网络是否互通(ping测试);
- Flannel的VXLAN隧道是否正常(
ip link show flannel.1); - 节点的iptables规则是否被清空(可重启flannel Pod重新生成规则);
- 若flannel Pod卡在ContainerCreating状态,多为镜像拉取失败,需确保节点能访问镜像仓库或加载离线镜像。