深度神经网络中不同归一化函数、不同激活函数的区别与使用
- [1. 归一化](#1. 归一化)
-
- [1.1 引言](#1.1 引言)
- [1.2 归一化函数详解](#1.2 归一化函数详解)
-
- [1.2.1 Batch Normalization,简称 BN](#1.2.1 Batch Normalization,简称 BN)
- [1.2.2 Layer Normalization,简称 LN](#1.2.2 Layer Normalization,简称 LN)
- [1.2.3 Group Normalization,简称 GN](#1.2.3 Group Normalization,简称 GN)
- [1.2.4 Other](#1.2.4 Other)
- [2. 激活函数](#2. 激活函数)
-
- [2.1 引言](#2.1 引言)
- [2.2 激活函数详解](#2.2 激活函数详解)
-
- [2.2.1 Sigmoid](#2.2.1 Sigmoid)
- [2.2.2 Tanh](#2.2.2 Tanh)
- [2.2.3 ReLU](#2.2.3 ReLU)
- [2.2.4 Leaky ReLU](#2.2.4 Leaky ReLU)
- [2.2.5 GELU](#2.2.5 GELU)
- [2.2.6 SiLU / Swish](#2.2.6 SiLU / Swish)
- [2.2.7 Softmax](#2.2.7 Softmax)
- [2.2.7 应用](#2.2.7 应用)
1. 归一化
1.1 引言
- 为什么要归一化?
神经网络里,一个特征张量经过线性层、卷积层以后,数值分布可能会不断变化。比如某一层输出可能均值很大、方差很大,另一层输出又很小。这会导致:
- 梯度不稳定
- 学习率难设
- 深层网络难训练
- 不同样本之间分布差异过大
-
归一化总原则
归一化的核心目的,是把特征分布 控制在更稳定的范围内,让训练更容易、梯度更稳定、不同层之间更好配合。而不同归一化方法,统计均值 和方差的维度不同,这决定了它们适合不同类型的网络。
-
基本步骤
归一化层做的事情,本质上就是两步:
-
第一步,把特征标准化:
x ^ = x − μ σ 2 + ϵ \hat{x} = \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} x^=σ2+ϵ x−μ
x x x 是原始特征, μ μ μ 是均值, σ 2 \sigma^2 σ2是方差, ϵ \epsilon ϵ是很小的常数,防止分母为 0 -
第二步,把特征标准化:
y = γ x ^ + β y = \gamma \hat{x} + \beta y=γx^+β
γ \gamma γ是可学习的缩放参数, β \beta β是可学习的平移参数。这一步的作用是:如果只做标准化,表达能力可能被限制住。加上 γ \gamma γ, β \beta β 后,网络可以自己学"想要保持多大尺度、多大偏移",也就是说:归一化不是把特征固定死,而是先稳定下来,再允许网络自己调回来。
这里重点讲解BN和LN两个较为常用的归一化。
-
1.2 归一化函数详解
1.2.1 Batch Normalization,简称 BN
BN 最早是为卷积网络大规模训练设计的。它的核心思想是:对一个 batch 内、同一个通道的所有元素,一起计算均值和方差。 如果输入是卷积特征: x ∈ R B × C × H × W x \in \mathbb{R}^{B \times C \times H \times W} x∈RB×C×H×W,那么对某个通道 c,BN 会在: B × H × W B \times H \times W B×H×W 这些位置上统计均值和方差。也就是说,它假设:同一通道在不同样本、不同空间位置上的统计特性是可以一起估计的。
那么,为什么 BN 在 CNN 里有效呢?因为卷积网络的通道通常有明确语义,比如:某些通道响应边缘;某些通道响应纹理;某些通道响应局部形状。这些通道的统计分布在 batch 内通常有一定一致性。BN 把它们统一到更稳定的尺度上,可以让后续卷积层更容易学习。此外,BN 还有一个非常重要的副作用,即它引入了轻微的随机性,因为每个 mini-batch 的统计量都不一样。这相当于一种隐式正则化,能在一定程度上提升泛化。
适合什么网络
- BN 最适合:CNN、图像分类网络、大 batch 训练、检测和分割中 batch 不太小的情况
- 典型网络:AlexNet、VGG 的改进版本、ResNet、DenseNet、YOLO 系列中很多版本
为什么适合这些网络
因为 CNN 的特征是空间特征图,BN 在空间维和 batch 维上统计,和卷积的"同通道共享语义"非常匹配。如果 batch 足够大,均值方差估计就稳定,效果通常很好。
BN 的优点
-
训练更稳定
-
收敛更快
-
可以使用更大学习率
-
在 CNN 中非常成熟
-
具有一定正则化作用
BN的缺点
依赖 batch 统计。所以当 batch 很小时,会出问题:均值方差不稳定、训练和测试差异变大、性能波动明显。这在下面场景尤其明显:跟踪、视频任务、分割任务、大模型单卡训练、ROI 特征处理、batch=1 或 batch 很小。
BN怎么用
二维卷积特征一般用:
nn.BatchNorm2d(num_features)
标准搭配通常是:
Conv -> BN -> ReLU
1.2.2 Layer Normalization,简称 LN
LN 的核心思想是:对每个样本自己的特征维度做归一化,而不是跨 batch。如果输入是 Transformer token, x ∈ R B × N × C x \in \mathbb{R}^{B \times N \times C} x∈RB×N×C,那么 LN 通常对最后一维 C 做归一化。也就是说,对每个 token,单独计算它在通道维上的均值和方差。
那么,为什么 LN 在 Transformer 里有效呢?Transformer 的基本单位是 token,不像 CNN 那样天然有"同通道跨空间共享统计"的假设。Transformer 更关注的是每个 token 的特征表示、token 与 token 的关系、attention 的数值稳定性。而LN 的特点是不依赖 batch、每个 token 独立处理、非常适合注意力结构。所以 LN 解决的是在 token 表示空间里,让每个 token 的数值分布更平稳。
适合什么网络
- LN 最适合:Transformer、NLP 模型、Vision Transformer、多模态 Transformer、时序token 交互模块
- 典型网络:BERT、GPT、ViT、Swin Transformer、大部分 tracking transformer
为什么适合这些网络
因为 Transformer 的输入通常是: B , N , C B,N,C B,N,C。这里最自然的归一化方式就是对每个 token 的通道维做处理,而不是拿 batch 里的其他样本一起统计。LN 不依赖 batch,所以小 batch 也稳定、多卡/单卡一致性更好、序列建模更自然。
LN 的优点
-
不依赖 batch size
-
训练稳定
-
特别适合注意力模型
-
对小 batch 非常友好
-
train/test 行为一致性更强
LN的缺点
-
对 CNN 空间特征不如 BN 自然
-
在纯卷积网络里通常不如 BN 高效
-
不显式利用空间维统计
LN怎么用
nn.LayerNorm(normalized_shape)
在 Transformer 里常见结构是:
python
x = x + Attention(LN(x))
x = x + MLP(LN(x))1.2.3 Group Normalization,简称 GN
GN 的想法是把通道分成 G 组,每组做归一化。如果输入是 x ∈ R B × C × H × W x \in \mathbb{R}^{B \times C \times H \times W} x∈RB×C×H×W,GN 会把 C 个通道分成 G 组,每组包含 C/G 个通道,然后在每组内部对 ( C / G ) × H × W (C/G) \times H \times W (C/G)×H×W做均值和方差统计。
μ = 1 C / G ⋅ H ⋅ W ∑ x \mu = \frac{1}{C/G \cdot H \cdot W} \sum x μ=C/G⋅H⋅W1∑x
GN 介于 BN 和 LN 之间,它不像 BN 那样依赖 batch,又不像 LN 那样把所有通道全部混在一起归一化,保留了"局部通道组"的统计结构。因此 GN 的逻辑是在不依赖 batch 的前提下,尽量保留 CNN 的通道分组和空间结构。
适合什么网络
- LN 最适合:小 batch CNN、检测、分割、跟踪、ROI feature 编码、视频模型中的卷积分支;
- 典型场景:Mask R-CNN 小 batch 训练、tracking 中的 memory encoder、ROI encoder、单卡训练的卷积模块
为什么适合这些网络
-
不依赖 batch
-
保留空间信息
-
比 LN 更适合 CNN
GN 的优点
-
不依赖 batch
-
小 batch 稳定
-
仍然适合 CNN 特征图
-
对检测、分割、跟踪很友好
GN的缺点
-
在大 batch 场景下通常不如 BN 快
-
对组数有一点超参数敏感
-
工程上不如 BN 那么"默认"
GN怎么用
nn.GroupNorm(num_groups, num_channels)
常见结构:
Conv -> GN -> GELU/ReLU
1.2.4 Other
-
Instance Normalization(IN) :每个样本、每个通道单独归一化: μ = 1 H W ∑ x \mu = \frac{1}{HW} \sum x μ=HW1∑x。 适合风格迁移的网络,可有效去除风格(光照/颜色)。应用场景:style transfer和GAN等。具有强去风格能力,同时也会有丢语义信息的缺点。
-
SyncBatchNorm(SyncBN):SyncBN 本质还是 BN,但它会在多张 GPU 之间同步 batch 统计量。也就是说,多卡训练时,均值和方差不是每张卡自己算,而是所有卡一起算。它是为了解决,单卡 batch 小但多卡总 batch 不小。适合多卡 CNN 训练、检测/分割、大模型多机多卡训练。其兼顾 BN 效果和多卡小 batch 问题,训练更稳定。
2. 激活函数
2.1 引言
假设有两层线性变换:
y = W 2 ( W 1 x + b 1 ) + b 2 y = W_2(W_1x + b_1) + b_2 y=W2(W1x+b1)+b2
展开后还是:
y = W x + b y = Wx + b y=Wx+b
也就是说,不加激活函数,多层网络等价于一层。所以激活函数的根本作用是:
- 引入非线性
- 提升表达能力
- 让网络能拟合复杂模式
- 影响梯度传播和训练稳定性
激活函数除了非线性之外,还决定了很多训练行为:
- 会不会梯度消失
- 会不会梯度为 0
- 是否平滑
- 是否保留负值信息
- 是否适合深层网络
- 是否适合 Transformer / CNN / 轻量模型
2.2 激活函数详解
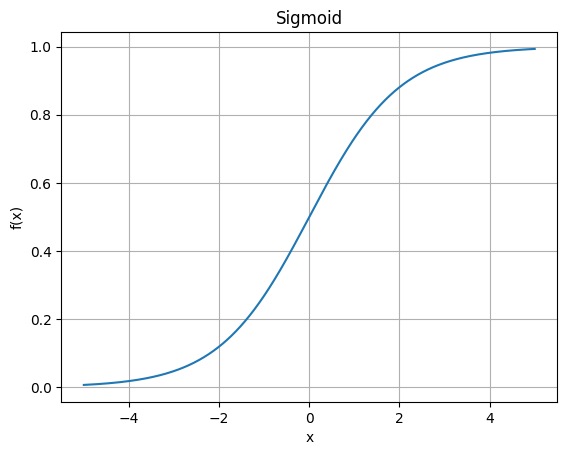
2.2.1 Sigmoid
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
输出范围: ( 0 , 1 ) (0,1) (0,1)。Sigmoid 会把任意实数压缩到 0 到 1 之间。所以它的一个天然含义是把输出解释为概率。例如:输出接近 1:更像正类;输出接近 0:更像负类。
曲线特性:单调递增、平滑、中间区域梯度较大、两端饱和。当 x 很大或很小时:输出接近 1 或 0,梯度非常小。这就导致经典问题:梯度消失
优点
-
输出有明确概率意义
-
曲线平滑
-
常用于二分类输出层
-
常用于门控结构(gate)
缺点
-
容易饱和,梯度消失
-
输出不是零中心
-
深层网络中训练困难
-
作为隐藏层激活通常不如 ReLU 类
适合场景
Sigmoid 现在不太适合隐藏层,但非常适合:
-
二分类输出层
-
attention gate
-
memory update gate
-
confidence score
-
mixture 权重
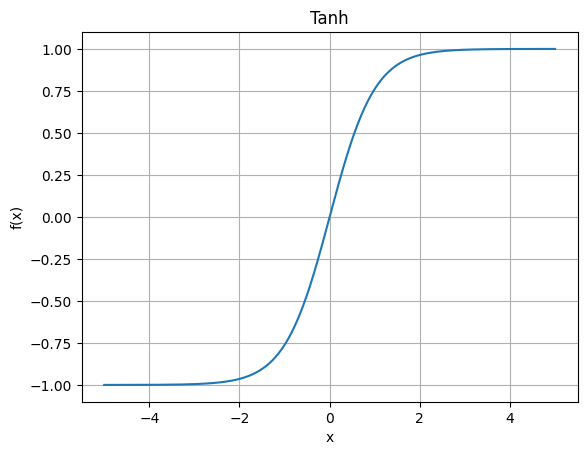
2.2.2 Tanh
tanh ( x ) = e x − e − x e x + e − x \tanh(x) = \frac{e^{x} - e^{-x}}{e^{x} + e^{-x}} tanh(x)=ex+e−xex−e−x
输出范围: ( − 1 , 1 ) (-1,1) (−1,1)。Tanh 和 Sigmoid 很像,但它是零中心的。这比 Sigmoid 好一些,因为输出既有正值也有负值,更利于优化。
曲线特性 :平滑、单调递增、零中心、两侧仍然会饱和。所以它虽然比 Sigmoid 好,但依然存在梯度消失。
优点
-
零中心
-
平滑
-
在早期 RNN/LSTM 中很常见
缺点
-
仍然有饱和问题
-
深层网络不如 ReLU 类好训
适合场景
-
一些门控循环单元
-
特殊输出限制在 -1,1
-
早期序列模型
-
在现代 CNN/Transformer 中已经不常作为主激活。
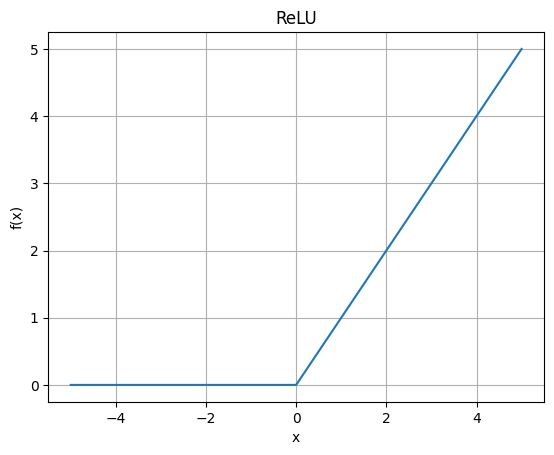
2.2.3 ReLU
ReLU ( x ) = max ( 0 , x ) \text{ReLU}(x) = \max(0, x) ReLU(x)=max(0,x)
ReLU 的逻辑非常简单,即正值直接通过,负值全部置 0。这使它相比 Sigmoid/Tanh 更不容易出现大面积梯度消失。
曲线特性 :分段线性、不平滑、负半轴梯度为 0、正半轴梯度恒为 1。
优点
简单高效、训练快、缓解梯度消失、计算便宜,在CNN 里非常经典
缺点
神经元死亡,即:如果某些单元长期落在负半轴,它们输出恒为 0,梯度也恒为 0,就"死掉"了。
适合场景
-
CNN
-
大多数常规视觉网络
-
轻量模型
-
对速度敏感的场景
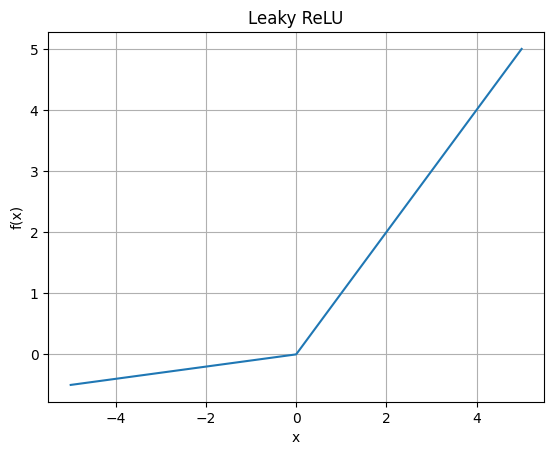
2.2.4 Leaky ReLU
f ( x ) = { x , x > 0 α x , x ≤ 0 f(x) = \begin{cases} x, & x > 0 \\ \alpha x, & x \le 0 \end{cases} f(x)={x,αx,x>0x≤0
其中 α 很小,比如 0.01。
Leaky ReLU 是 ReLU 的改进版。它不是把负值直接切成 0,而是保留一条很小的斜率。
这样做的可以避免 ReLU 在负半轴完全没有梯度。
曲线特性 :
优点
缓解 dying ReLU、比 ReLU 更稳一点、实现简单
缺点
改进有限、通常不如 GELU/SiLU 流行
适合场景
希望比 ReLU 稳一些、简单 CNN、GAN 中也常见
2.2.5 GELU
GELU 可以写成近似形式:
GELU ( x ) = x Φ ( x ) \text{GELU}(x) = x\Phi(x) GELU(x)=xΦ(x)
其中 Φ ( x ) \Phi(x) Φ(x) 是标准正态分布的累积分布函数。常见近似写法:
GELU ( x ) ≈ 0.5 x ( 1 + tanh ( 2 π ( x + 0.044715 x 3 ) ) ) \text{GELU}(x) \approx 0.5x \left( 1 + \tanh\left( \sqrt{\frac{2}{\pi}} \left( x + 0.044715x^3 \right) \right) \right) GELU(x)≈0.5x(1+tanh(π2 (x+0.044715x3)))
GELU 的思想不是"硬阈值"地把负值截断,而是根据输入值大小,平滑地决定保留多少信息。和 ReLU 相比:
ReLU:负值全砍。
GELU:小负值可能还保留一点,小正值也不是完全通过,而是平滑过渡
所以 GELU 更像一种"软门控"。
曲线特性 :
平滑、非单纯分段线性、对小值更温和、对 Transformer 很友好
优点
平滑、表达细腻、训练稳定、Transformer 中表现很好、适合高维特征建模
缺点
比 ReLU 计算更贵、在极轻量模型中未必划算。
适合场景
-
Transformer
-
ViT
-
BERT/GPT
-
高维 token 建模
-
多模态交互模块
2.2.6 SiLU / Swish
SiLU ( x ) = x ⋅ σ ( x ) \text{SiLU}(x) = x \cdot \sigma(x) SiLU(x)=x⋅σ(x)
它本质是用 sigmoid 作为门控,对输入进行平滑调制。和 GELU 类似,都属于"平滑型激活"。
曲线特性 :
优点
平滑、通常比 ReLU 表现更好、在检测和轻量网络中很流行
缺点
比 ReLU 稍贵、在 Transformer 里通常不如 GELU 标准。
适合场景
现代 CNN、检测网络、轻量模型、YOLO 系列
2.2.7 Softmax
softmax ( x i ) = e x i ∑ j e x j \text{softmax}(x_i) = \frac{e^{x_i}}{\sum_j e^{x_j}} softmax(xi)=∑jexjexi
严格说它softmax不是"隐藏层激活函数",更像输出归一化函数。输出是一组概率,总和为 1。主要用在多分类输出层、注意力权重、mixture-of-experts 路由。
2.2.7 应用
做 CNN网络,优先级通常是:
简单稳定:ReLU
更现代:SiLU
小幅改进:LeakyReLU / PReLU
做 Transformer网络,优先级通常是:
标准:GELU
某些高效变体:SiLU 也可以试,但主流仍是 GELU
做 gate / score / probability,优先级通常是:
Sigmoid(二分类、门控)
Softmax(多分类、注意力分配)