在机器学习的学习过程中,样本、特征、标签、模型、训练、预测、评估等概念往往同时出现。若分别孤立地理解,容易显得零散;若把这些概念放在一个完整任务中加以观察,则更容易把握它们之间的联系。
因此,有必要先掌握一个最小机器学习工作流。所谓"最小",是指它不追求复杂的数据处理,也不追求完整的模型比较,而是尽量用较少的步骤,把一个机器学习任务真正跑通。只要这个基本闭环建立起来,后续再学习更复杂的模型、更系统的数据处理方法和更严格的评估流程,就会更顺畅。
本文通过一个简单的房价预测示例,说明如何使用 Scikit-learn 完成一个最基本的机器学习过程。
一、最小机器学习工作流简介
所谓最小机器学习工作流,可以概括为以下几个基本环节:
• 明确问题所属的任务类型
• 读取并整理数据
• 选择模型
• 训练模型
• 进行预测
• 分析结果并完成可视化表达
这个流程虽然简洁,却已经包含了机器学习建模的基本思想。它说明:机器学习并不是直接写出一个公式就结束了,而是围绕数据、模型与任务展开的一组连续操作。
用流程图表示如下:
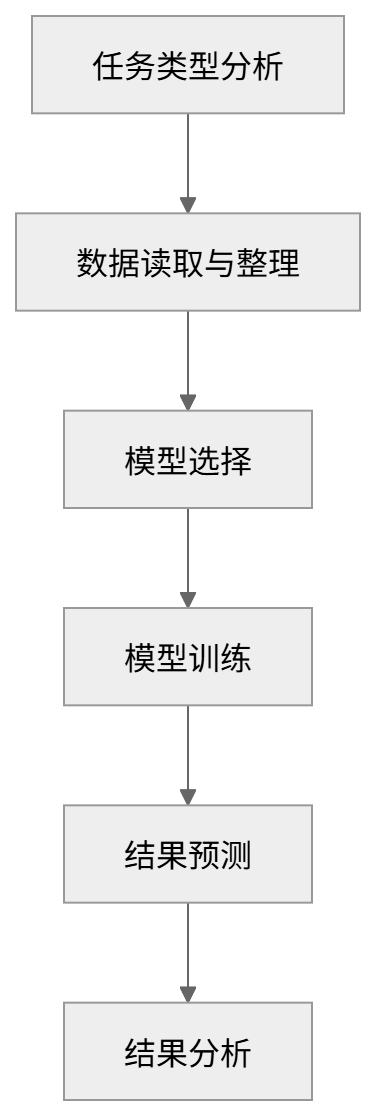
图 1:最小机器学习工作流程图
从教学角度看,这个流程的价值,不在于步骤本身是否复杂,而在于它把机器学习中的几个基本概念组织成了一条清晰主线。
二、问题类型分析与模型假设
假设现在有一个简单问题:根据房屋面积估算房价。
例如,已经调查得到一批房屋数据,每条记录包含两个字段:
• area:房屋面积
• price:房屋价格
现在,希望根据已有样本建立一个模型,并利用它预测新房屋的价格。
1、问题类型的判定
在这个问题中,输入是房屋面积,输出是房价。房价是连续数值,而不是离散类别,因此它不是分类任务,而是回归任务。
2、模型假设的建立
从直观上看,在其他条件变化不大的情况下,面积越大,房价通常越高。因此,可以先假设房价与面积之间大致存在一种线性关系,用一条直线去近似这种变化趋势。
线性回归的基本形式可以写为:
其中:
• x 表示输入变量,此处对应房屋面积
• f(x) 表示模型对房价的预测值
• w 表示斜率,反映面积每增加 1 个单位时,预测房价的大致变化量
• b 表示截距,表示当 x=0 时模型给出的理论预测值
这里的"线性"并不意味着现实中的所有房价都严格落在同一条直线上,而是说用一条直线去近似总体趋势。
3、机器学习方法的必要性
如果只有两个点,当然可以唯一确定一条直线;但实际数据通常不止两个点,而且还会受到噪声影响。不同样本之间往往并不会严格满足同一个简单方程。此时,就需要借助机器学习方法,从一组带有偏差的数据中找出较合适的规律。
因此,这个问题适合作为 Scikit-learn 工作流示例:任务明确、数据简单、流程完整。
三、数据准备、表示与可视化
机器学习模型不能直接理解"房子""面积""价格"这些现实世界概念,它只能处理整理后的数值数据。因此,在建模之前,必须先把数据组织成适合模型使用的形式,并对数据分布进行基本观察。
1、数据的表格化表示
假设数据已经保存在一个 CSV 文件中,例如 house_price.csv。其中包含两列:
• area:房屋面积
• price:房屋价格
从数据组织角度看,每一行是一套房屋样本,每一列是一个字段。
2、特征矩阵与目标变量
在 Scikit-learn 中,输入通常写作 X,输出通常写作 y。
对于本例来说:
• X 表示房屋面积构成的特征矩阵
• y 表示房屋价格构成的目标变量
它们可表示为:
在程序实现中,它们常见的形状为:
• X = (n_samples, n_features)
• y = (n_samples,)
由于这里只有一个特征,即房屋面积,因此 X 只有一列,但它仍然应保持二维结构;而 y 则通常是一维数组。
3、数据读取与整理
下面先借助 Pandas 读入数据:
python
import pandas as pd
df = pd.read_csv("house_price.csv")print(df.head())接着,从中取出模型需要的两个部分:
ini
X = df[["area"]].valuesy = df["price"].values这里需要注意:
• df\["area"] 使用双中括号,因此得到的是二维结构
• df"price" 使用单中括号,因此得到的是一维结构
到这里,数据已经被整理成了 Scikit-learn 最常见的输入输出形式。
4、数据分布的可视化观察
在模型训练之前,先对数据进行可视化观察,是十分必要的一步。图形能够帮助判断:
• 数据整体呈现何种趋势
• 样本点是否大致沿某一方向变化
• 是否存在明显异常点
• 线性模型是否具有尝试价值
对于本例,可以绘制散点图,以房屋面积为横轴、房屋价格为纵轴,观察它们之间的关系。
python
import pandas as pdimport matplotlib.pyplot as plt
df = pd.read_csv("house_price.csv")
plt.figure(figsize=(8, 5))plt.scatter(df["area"], df["price"])plt.xlabel("Area")plt.ylabel("Price")plt.title("House Price vs Area")plt.grid(True)plt.show()输出示意:
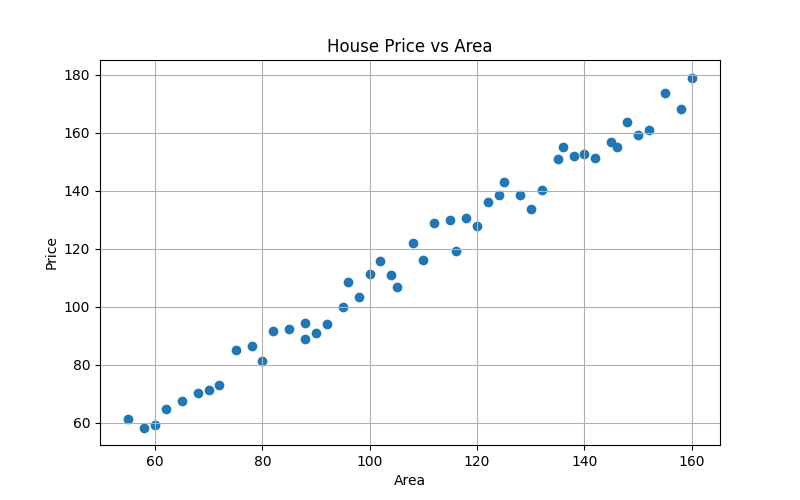
图 2:数据分布的可视化输出
若散点图显示:随着面积增大,价格整体也随之升高,并且样本点大致分布在一条上升趋势附近,那么就说明"面积"和"价格"之间确实存在较明显的正相关趋势。虽然这些点通常不会严格落在同一条直线上,但已经可以初步判断:使用线性回归来近似这种关系是合理的。
四、模型选择与训练过程
数据准备完成后,下一步是选择模型,并通过训练使模型从数据中学习规律。
1、模型类的导入
既然本例是回归任务,并且先假设面积与房价之间大致存在线性关系,那么可以选择 Scikit-learn 中的线性回归模型 LinearRegression。
导入方式如下:
javascript
from sklearn.linear_model import LinearRegression这里导入的是模型类,而不是已经训练好的模型。
2、模型对象的创建
然后创建模型对象:
ini
model = LinearRegression()这一过程称为实例化。它的含义是:根据某个模型类创建一个具体对象。
需要强调的是,实例化模型并不等于模型已经开始学习数据。此时只是创建了一个可供训练的对象,真正的学习过程要在后面的 fit() 中完成。
3、模型训练
模型创建好之后,就可以开始训练。训练过程通过 fit() 方法完成:
css
model.fit(X, y)这一语句的作用是:把特征矩阵 X 和目标变量 y 交给模型,让模型根据这些样本学习房屋面积与房价之间的关系。
对于线性回归来说,训练的结果就是估计出较合适的 w 和 b。也就是说,模型会根据数据找到一条较能反映总体趋势的直线。
4、训练结果的属性
从程序角度看,训练后的结果通常会保存在模型对象的属性中。例如,在 LinearRegression 中,可以通过以下属性查看:
• model.coef_
• model.intercept_
其中:
• coef_ 表示回归系数
• intercept_ 表示截距
这些属性名后面的下划线 _,表示它们通常是在训练完成后才真正得到的结果。
五、预测结果与模型可视化分析
训练完成后,模型已经学到了面积与房价之间的关系。此时,可以调用模型的 predict() 方法进行预测,并将模型拟合结果可视化出来,从而更直观地分析其效果。
1、新样本预测
例如,想预测一套 75 平方米房屋的价格,可以写为:
python
pred = model.predict([[75]])print(f"预测 75 平方米房屋价格:{pred[0]:.2f} 万元")这里的 \[75] 仍然写成二维形式,是因为模型要求输入保持"样本 × 特征"的结构。虽然这里只预测一个样本、一个特征,但形式上仍应是二维数组。
2、模型参数的输出
除了直接给出预测结果,线性回归模型还允许查看其学习到的参数。例如:
python
print(f"每平米房价的提升幅度:{model.coef_[0]:.2f} 万元/平方米")print(f"基础房价(截距):{model.intercept_:.2f} 万元")这些参数有助于更直观地理解模型在数据中捕捉到了什么关系。
3、拟合结果的图形表示
仅有散点图还不够。训练完成后,还可以把模型拟合得到的直线画出来,与原始数据点一起观察。这样就能更直观地看到模型是否较好地刻画了整体趋势。
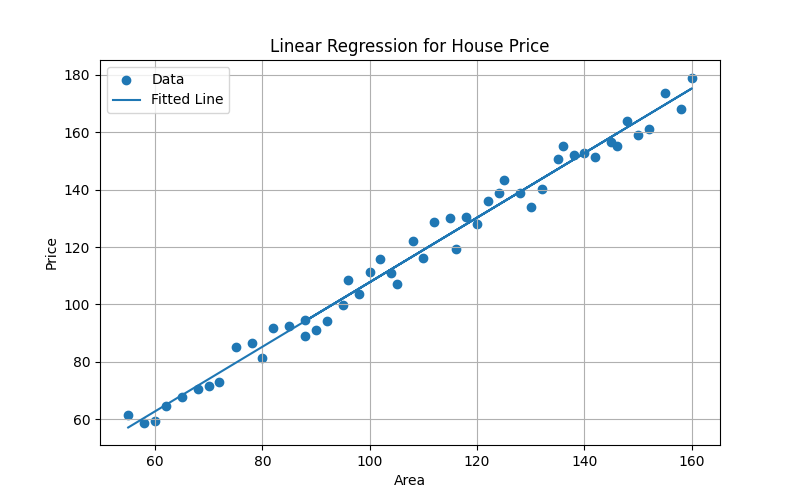
图 3:房屋价格的线性回归示意图
图中的散点表示真实样本,直线表示模型根据这些样本学习到的线性关系。若这条直线总体上穿过散点分布的中间区域,说明模型较好地抓住了整体趋势;若散点明显偏离直线,则说明仅使用简单线性模型可能还不够。
4、模型分析的意义
在本例中,拟合直线的主要作用,是帮助观察模型是否合理地描述了"面积越大,价格越高"的总体规律。这样一来,数据可视化与模型可视化就构成了一个完整分析过程:
• 数据散点图用于观察原始样本分布
• 拟合直线图用于观察模型是否抓住总体趋势
六、完整代码示例
下面把上述过程整理为一段完整代码,其中包括数据读取、散点图可视化、模型训练、价格预测以及拟合结果绘制。
python
import pandas as pdimport matplotlib.pyplot as pltfrom sklearn.linear_model import LinearRegression
# 1. 读取数据df = pd.read_csv("house_price.csv")
# 2. 查看前几行print(df.head())
# 3. 绘制原始散点图plt.figure(figsize=(8, 5))plt.scatter(df["area"], df["price"], label="Data")plt.xlabel("Area")plt.ylabel("Price")plt.title("House Price vs Area")plt.grid(True)plt.legend()plt.show()
# 4. 构造特征矩阵 X 和目标变量 yX = df[["area"]].valuesy = df["price"].values
# 5. 创建模型model = LinearRegression()
# 6. 训练模型model.fit(X, y)
# 7. 预测 75 平方米房屋价格pred = model.predict([[75]])print(f"预测 75 平方米房屋价格:{pred[0]:.2f} 万元")
# 8. 输出模型参数print(f"每平米房价的提升幅度:{model.coef_[0]:.2f} 万元/平方米")print(f"基础房价(截距):{model.intercept_:.2f} 万元")
# 9. 计算训练样本上的预测值y_pred = model.predict(X)
# 10. 绘制拟合结果plt.figure(figsize=(8, 5))plt.scatter(df["area"], df["price"], label="Data")plt.plot(df["area"], y_pred, label="Fitted Line")plt.xlabel("Area")plt.ylabel("Price")plt.title("Linear Regression for House Price")plt.grid(True)plt.legend()plt.show()这段代码虽然不长,却已经完整体现了一个最小机器学习工作流:
1、从文件读入数据;
2、观察数据分布;
3、整理出 X 和 y;
4、创建模型;
5、训练模型;
6、进行预测;
7、查看参数;
8、可视化拟合结果。
这个过程表明,Scikit-learn 的使用并不是零散命令的拼接,而是围绕任务、数据与模型展开的有序过程。
七、工作流示例的基本结论
本例虽然简单,但它已经体现了机器学习建模中的几个关键环节。
1、任务类型的判断先于模型选择
在监督学习建模之前,先要判断问题属于分类还是回归。本例中,房价是连续数值,因此属于回归任务。
2、数据必须整理为标准形式
Scikit-learn 并不直接接收现实问题描述,而是接收整理好的数值数据。本例中,面积被整理为特征矩阵 X,价格被整理为目标变量 y。
3、模型训练是核心步骤
LinearRegression() 只是创建模型对象;fit(X, y) 才是真正的训练过程。
4、可视化有助于理解数据与模型
散点图帮助观察原始数据的整体趋势;拟合直线帮助判断模型是否较好地描述了这种趋势。因此,可视化不仅是结果展示手段,也是分析数据结构与模型行为的重要方法。
从任务分析到结果可视化,这一示例已经构成了一个完整而简洁的机器学习闭环。后续无论学习更复杂的模型,还是引入训练集与测试集、误差分析和模型比较,都可以在这一闭环基础上逐步展开。
📘 小结
一个最小机器学习工作流,包括任务分析、数据整理、数据可视化、模型训练、结果预测与拟合分析。通过这一过程,可以把 X、y、fit()、predict() 等核心概念连接起来,形成对 Scikit-learn 基本建模流程的整体认识。

"点赞有美意,赞赏是鼓励"