论文标题 :Improving Language Understanding by Generative Pre-Training
论文作者 :Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever (OpenAI)
发布时间 :2018年
核心贡献 :提出了"半监督学习"框架,即在大规模无标注文本上进行生成式预训练(Generative Pre-Training) ,然后在特定下游任务上进行有监督微调(Supervised Fine-Tuning)。这奠定了后续 GPT 系列(甚至整个当代大语言模型)的范式基础。
1. 论文提出背景
在此之前,NLP 领域的深度学习模型主要依赖于大量有标注的特定领域数据集,这带来两个问题:
- 有标签数据获取成本高:自然语言处理(NLP)领域对大规模监督数据的严重依赖,特定任务的高质量人工标注数据稀缺且昂贵。
- 无标签语料库丰富:未标记的大规模文本语料库非常丰富。如果模型能够直接从原始文本中有效地学习其语言信息,将成为一种极具价值的替代方案。
虽然有大量的无标注文本存在,但如何从中提取有用的词汇与句法层面的表示进行迁移学习,一直是个难题。GPT-1 的提出就是为了解决如下三个问题:
- 优化目标不明确:在从无标签文本中学习有用的信息时,过去并不清楚哪种优化目标(如语言建模、机器翻译或语篇连贯性)最能有效地学习出易于迁移的文本表示。
- 特征迁移机制缺乏共识且过于复杂:以往在将预训练学到的表示迁移到目标任务时,通常需要对模型架构进行针对特定任务的大幅修改,或者使用错综复杂的学习方案。论文致力于解决这一痛点,希望在微调阶段通过特定任务的输入转换(task-aware input transformations),在几乎不改变预训练模型架构的前提下实现高效迁移 。
- 模型难以捕捉长距离依赖:之前的研究虽然也使用了语言建模目标进行预训练,但它们主要依赖 LSTM 模型,这导致模型的预测和理解能力被限制在较短的上下文范围内。本论文旨在通过引入 Transformer 架构和使用包含长段连续文本的数据集,来突破这一限制,从而有效地捕捉和处理长距离的语言结构信息。
2. 训练流程(两段式)
训练过程包含两个阶段。
阶段一:无监督预训练 (Unsupervised Pre-Training)
在这个阶段,模型在一个庞大的无标注语料库(BooksCorpus,约7000本未出版书籍,超10亿词)上进行训练。
- 训练目标:标准的语言模型目标,最大化给定前文条件下下一个词出现的概率。
- 公式 : L1(U)=∑ilogP(ui∣ui−k,...,ui−1;Θ)L_1(\mathcal{U}) = \sum_i \log P(u_i | u_{i-k}, \dots, u_{i-1}; \Theta)L1(U)=∑ilogP(ui∣ui−k,...,ui−1;Θ)(其中 kkk 为上下文窗口大小,设为 512)。
阶段二:有监督微调 (Supervised Fine-Tuning, SFT)
预训练好语言模型之后,将其用于有标注数据集(如文本分类、蕴含推理、问答等)进行特定任务的训练。
- 训练目标:最大化带有标签数据的条件概率。
- 创新点:在微调时,保留了预训练语言模型的目标作为辅助损失(Auxiliary Loss),这有助于提高泛化能力并加速收敛速度。
- 公式 : L3(C)=L2(C)+λL1(C)L_3(\mathcal{C}) = L_2(\mathcal{C}) + \lambda L_1(\mathcal{C})L3(C)=L2(C)+λL1(C) (L2L_2L2 是任务导向的交叉熵损失,L1L_1L1 是语言模型的辅助损失)。
3. 模型架构:Transformer Decoder
GPT-1 并没有使用后来 BERT 使用的 Transformer Encoder(双向),而是沿用了标准的 Transformer Decoder(单向/多头自注意力) 结构。
- 层数:12层 Transformer Decoder
- 隐藏层维度:768
- 注意力头数:12
- 参数量:约 1.17 亿 (117M)
之所以使用 Decoder(带 Masked Self-Attention),是因为其训练目标是自回归语言建模(预测下一个词),模型不能"看到"未来的词。
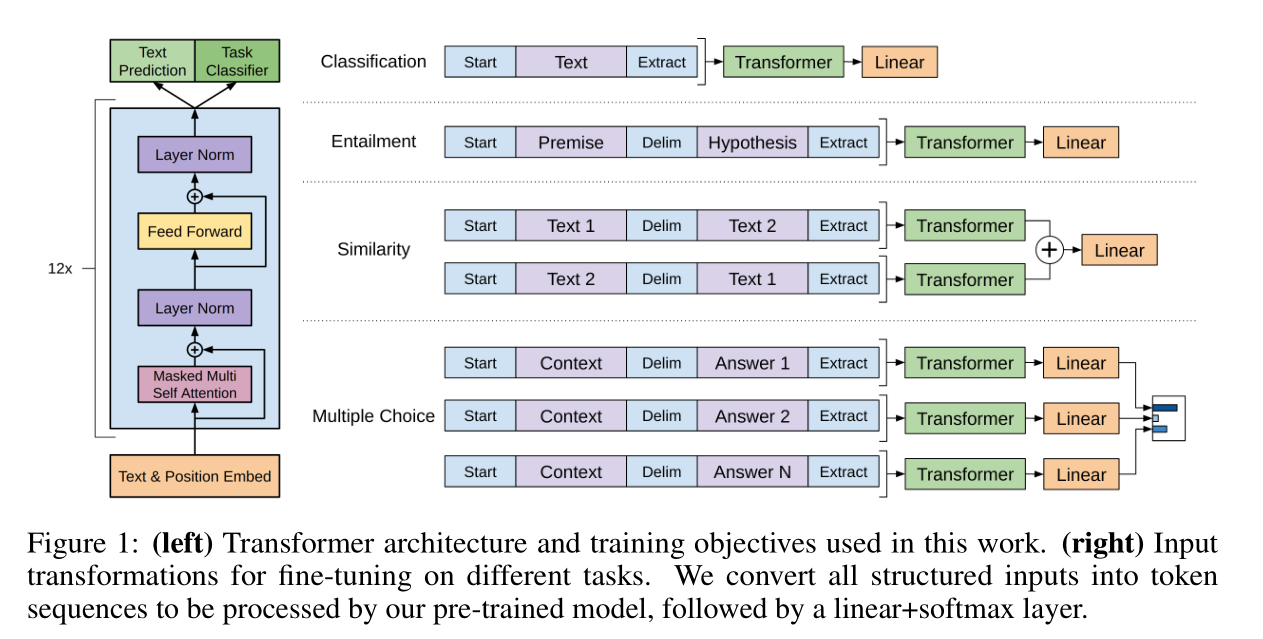
4. 任务特定的输入表示 (Task-specific Input Transformations)
由于下游任务的输入形式各不相同(如文本分类是一段文本,蕴含推理是前提+假设两段文本,问答是多项选择),GPT-1 创新性地采用了一种 "遍历式"处理法 (Traversal-style approach),将不同任务的输入转化为模型能接受的统一线性序列:
- 加入特殊词元:如
[START](序列开始),[DELIM](分隔符),[EXTRACT](提取/结尾符)。 - 直接改变输入文本的结构传入预训练模型,极大减少了为不同任务修改模型结构的需要。
5. 实验结果与影响
- 性能飞跃:在当时测试的12个NLP数据集中,GPT-1 在9个任务上取得了 SOTA(State-of-the-Art)性能。
- 消融实验结论 :
- 预训练的重要性:没有预训练的模型在所有任务上的表现均大幅下降(平均下降 14.8%)。
- 辅助目标的价值:辅助语言模型目标对大型数据集更有利 。
- 架构优势:在相同框架下,使用 Transformer 比使用 LSTM 的平均得分高出 5.6 分 。
- 零样本学习 (Zero-shot) 的涌现:论文通过实验发现,随着预训练步骤的增加,模型在缺乏微调(Zero-shot)的条件下的下游任务性能也在稳步提高,这说明预训练不仅让模型学到了语法,也学到了解决许多NLP任务所需要的内在逻辑。
- 深远影响 :确立了 Pre-training + Fine-tuning (预训练+微调) 范式的正统地位,为后续的 GPT-2、GPT-3 乃至现在的各类大语言模型铺平了道路。
6. 优缺点总结
- 优点:通用性强,泛化能力优秀;训练框架简单统一;极大地降低了对大规模高质量特定任务标注数据的依赖。
- 局限性:由于是单向语言模型(仅用左侧上下文预测右侧),在一些需要双向深度语境信息的任务(如阅读理解中的填空)上表现不如稍后推出的双向模型 BERT。但长远来看,单向自回归架构在生成式任务上取得了压倒性优势。