并不是所有机器学习任务都能事先拿到"标准答案"。在很多真实场景中,我们虽然收集到了大量数据,却不知道这些数据各自对应什么类别,也没有人为标注好的结果可供训练。此时,机器无法像监督学习那样直接从"输入---答案"对中学习,而只能从数据本身出发,去发现其中隐藏的结构、分布特点或相似关系。
例如,我们拿到一批用户的消费记录,但并不知道这些用户应被分成哪些类型;或者拿到一批商品数据,却不知道哪些商品彼此更相近;又或者面对高维数据,希望先把它压缩到更容易观察和分析的形式。这类问题都不再是"根据已知答案学习映射",而更接近"从数据内部寻找规律"。
这种学习方式,就是无监督学习(Unsupervised Learning)。
无监督学习是机器学习中的另一类重要方法。它不依赖人工给出的标签,而是通过数据之间的相似性、差异性或结构特征,帮助我们完成分组、降维、模式发现等任务。因此,学习无监督学习,本质上是在理解:当没有标准答案时,机器还能如何从数据中提取信息。
一、先从一个任务开始:当数据有很多,却没有答案时怎么办
假设现在有一批用户的购物数据,每位用户都有如下信息:
• 每月消费总额
• 每月下单次数
• 平均客单价
这些数据已经收集好了,但问题在于:我们并不知道这些用户事先应被划分成哪些类别。也就是说,没有人告诉我们:
• 谁属于高价值用户
• 谁属于价格敏感用户
• 谁属于偶尔购买用户
这时,如果仍然想从这些用户中找出某种规律,就不能再直接使用监督学习的"带答案训练"方式了。因为这里没有标签,也就没有 y 可以提供给模型。
例如,可以先把一组简化后的用户数据写出来:
cs
import numpy as np
X = np.array([ [5000, 20, 250], [5200, 22, 236], [800, 5, 160], [900, 4, 225], [3000, 10, 300], [3200, 11, 291]])这里:
• 每一行表示一个用户样本
• 每一列表示一个特征
• 没有额外给出"这个用户属于哪一类"的标准答案
此时,机器要做的不是学习"输入到答案"的映射,而是观察这些用户之间是否存在某种自然分组。例如:
• 前两个用户消费高、下单频繁,彼此较相近;
• 中间两个用户消费低、下单少,也可能更接近;
• 后两个用户介于二者之间,可能构成另一类。
这正是无监督学习最典型的思路:数据没有标签,但数据内部可能存在结构。
二、什么是无监督学习
无监督学习有时容易被误解为"没有目标地乱学"。这种理解并不准确。
无监督学习并不是没有任务,而是没有像监督学习那样现成的标签可供学习。模型面对的,通常只有输入数据本身,也就是一组样本特征 X,而没有对应的目标 y。
监督学习通常使用成对的数据:
其中 X 是输入特征,y 是标签。
而无监督学习通常只有 X。
也就是说,模型只能从输入数据本身出发,去分析其内部结构。
因此,无监督学习的重点不是"预测正确答案",而是完成一些不同类型的任务,例如:
• 找出数据中的自然分组
• 发现变量之间的隐藏结构
• 把高维数据压缩到低维空间
• 识别异常点或特殊模式
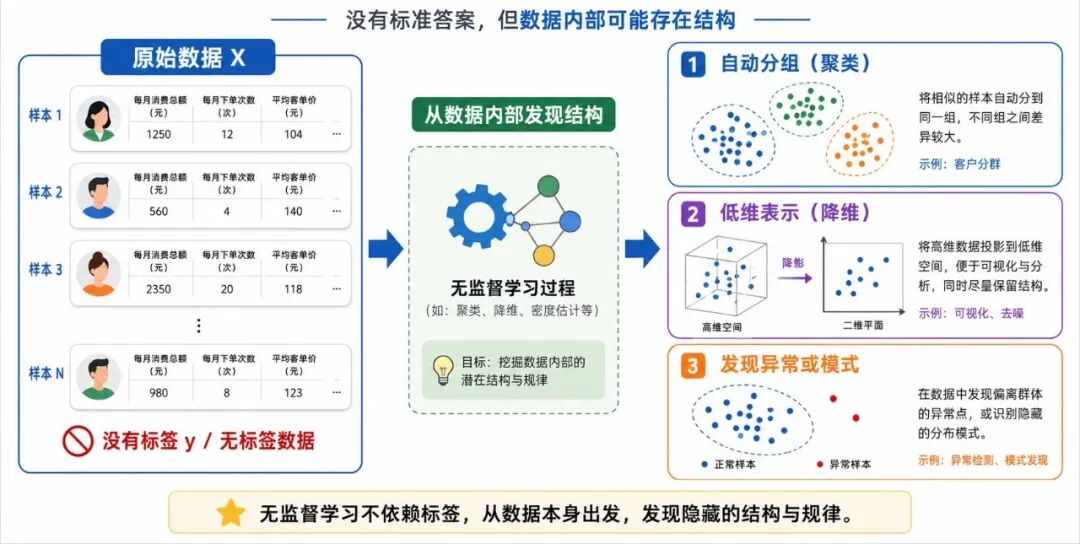
图 1:无监督学习的基本思想
从本质上说,无监督学习是在回答这样的问题:
• 这些数据彼此之间谁更像谁?
• 数据是否能自动形成若干簇?
• 数据中最主要的变化方向是什么?
• 有没有明显偏离整体分布的异常样本?
所以,无监督学习并不是"没有规则",而是规则不再来自人工标签,而是来自数据内部本身的组织方式。
三、无监督学习与监督学习有什么不同
无监督学习和监督学习都属于机器学习,但它们的出发点并不相同。
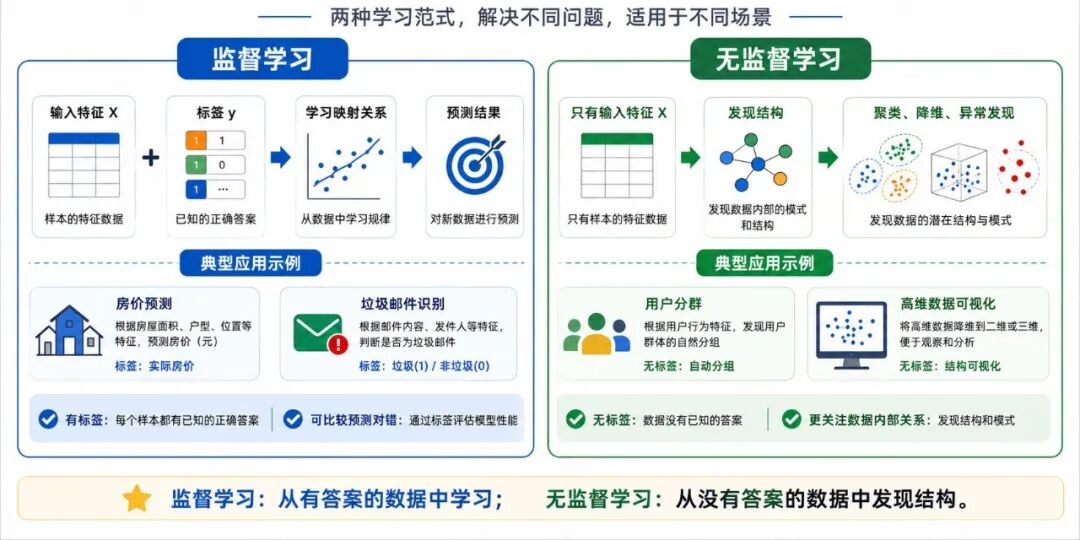
图 2:监督学习与无监督学习的区别
1、数据形式不同
监督学习通常使用带标签的数据:
• 输入特征 X
• 输出标签 y
而无监督学习通常只有输入特征 X,没有目标标签。
2、任务目标不同
监督学习的目标通常是:根据历史样本学会预测新样本的结果。
无监督学习的目标通常是:从数据内部自动发现结构、关系或模式。
3、结果形式不同
监督学习往往会输出一个明确预测结果,例如:
• 房价是多少
• 邮件是不是垃圾邮件
• 图像属于哪一类
而无监督学习的结果,很多时候不是"唯一正确答案",而是一种数据组织方式。例如:
• 把用户分成 3 类
• 把高维数据压缩到 2 个主方向
• 找出离群样本
4、评价方式也不同
监督学习因为有真实标签,所以比较容易评价预测是否正确。
但无监督学习由于没有现成标准答案,往往更难评价。很多时候,我们只能结合:
• 数据分布是否合理
• 结果是否有可解释性
• 是否符合业务经验
• 是否有助于后续分析
来判断无监督学习结果是否有价值。
可以用一个简洁方式概括:
• 监督学习:从"有答案的数据"中学习预测规则
• 无监督学习:从"没有答案的数据"中发现内部结构
延伸阅读:
四、无监督学习最常见的任务之一:聚类
在无监督学习中,最常见的一类任务就是聚类(Clustering)。
聚类的基本思想并不复杂:如果一些样本彼此很相似,而与另一些样本差异较大,那么就可以尝试把它们自动分到不同组中。
例如,在用户购物数据中:
• 高频高消费用户可能被分成一组
• 低频低消费用户可能被分成另一组
• 中间类型用户可能形成第三组
这里并没有人事先规定"哪位用户属于哪组",而是算法根据样本之间的距离或相似性自行完成划分。
从直观上看,聚类是在做一件事:让相近的样本尽量聚在一起,让相差较大的样本尽量分开。
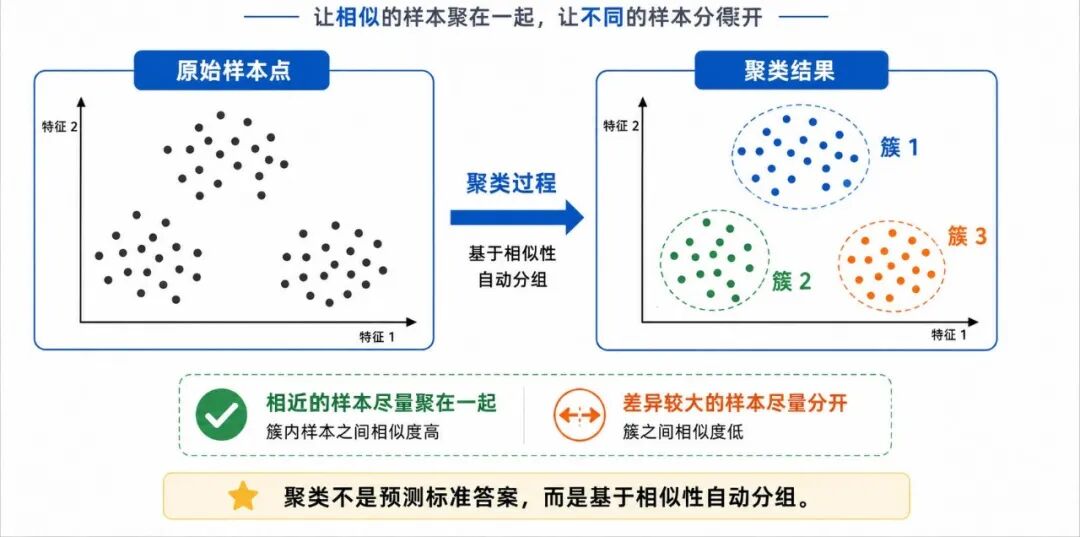
图 3:聚类的基本直觉
例如,假设二维平面上有一些点:
• 距离较近的点可能形成同一簇
• 相距较远的点可能属于不同簇
这就是聚类的基本直觉。
在常见聚类方法中,K 均值聚类(K-Means)是最基础也最常见的一种。它的思路是:
• 先假设要分成 K 个簇
• 不断调整各簇中心位置
• 让每个样本归到距离最近的中心
• 最终形成若干较稳定的分组
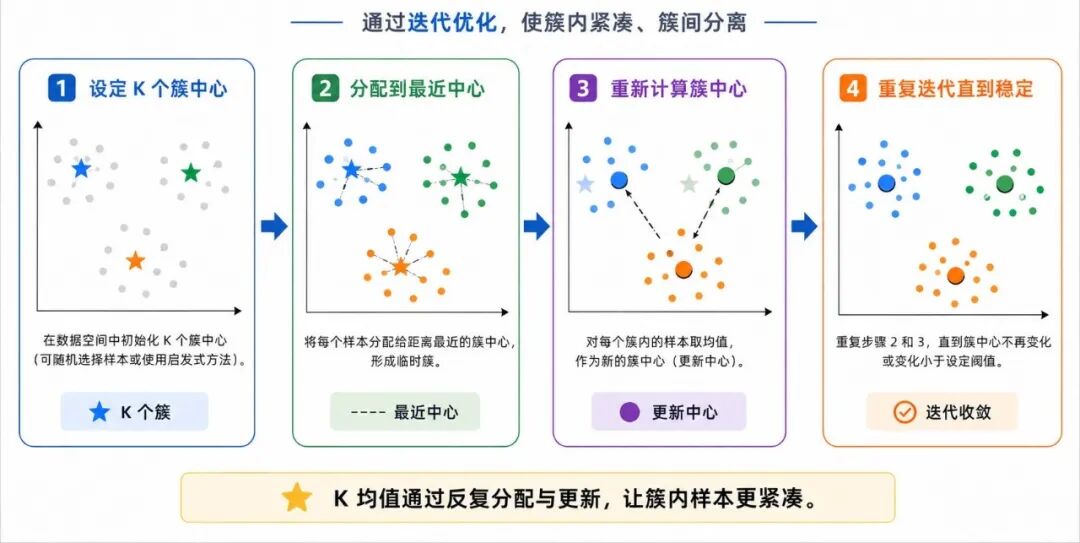
图 4:K 均值聚类的基本过程
这里要注意,聚类得到的"类"并不一定等于现实世界中天然存在的绝对类别,它更像是一种基于数据相似性的划分结果。
延伸阅读:
五、无监督学习的另一类重要任务:降维
除了聚类,无监督学习中另一类非常重要的任务是降维(Dimensionality Reduction)。
所谓降维,就是在尽量保留数据主要信息的前提下,把原本维度较高的数据压缩到更低维的表示形式。
例如,一份数据原本有很多个特征:
• 身高
• 体重
• 年龄
• 收入
• 教育年限
• 消费频率
• 活跃天数
• 浏览时长
如果直接分析,可能既不直观,也不便于可视化。这时就可以通过降维,把这些特征压缩成两个或三个主要方向,从而更容易观察数据整体结构。
降维的常见作用包括:
• 便于可视化高维数据
• 去除部分冗余信息
• 降低计算复杂度
• 为后续建模提供更紧凑的表示
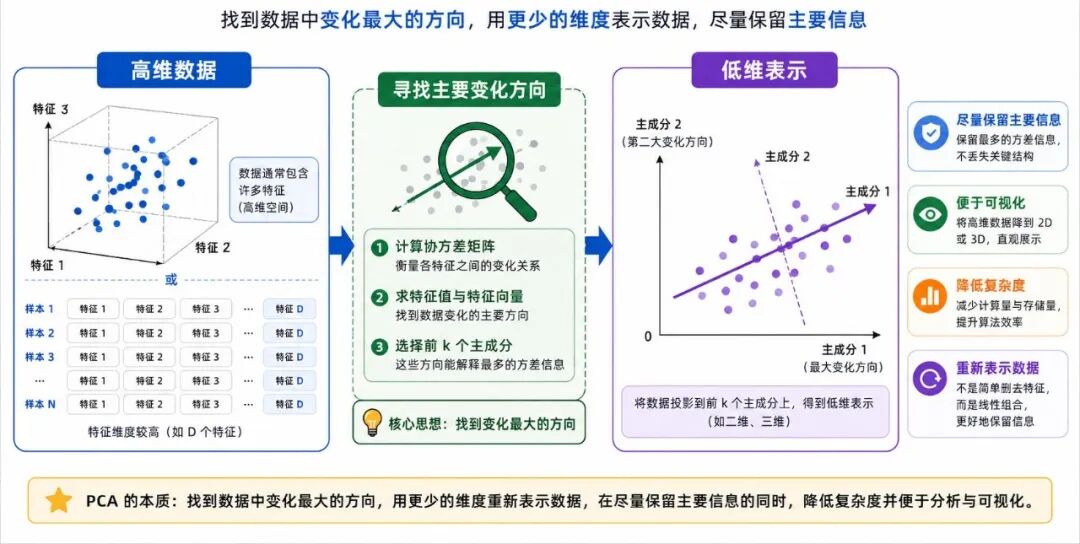
图 5:降维与 PCA 的基本思想
最常见的降维方法之一是主成分分析(PCA,Principal Component Analysis)。它的核心思想可以粗略理解为:
• 在原始高维空间中寻找数据变化最明显的方向
• 用这些主要方向重新表示数据
• 用更少维度保留数据中的主要信息
这里要注意,降维并不是随意删掉几个特征,而是通过某种变换,把原数据重新映射到更有代表性的低维空间中。
因此,聚类更强调"分组",降维更强调"压缩表示"。二者都属于无监督学习,但解决的问题并不相同。
延伸阅读:
六、无监督学习在实际中有什么用
由于无监督学习不依赖标签,因此它在很多真实场景中都非常有用,尤其是在"数据多但标注难"的情况下。
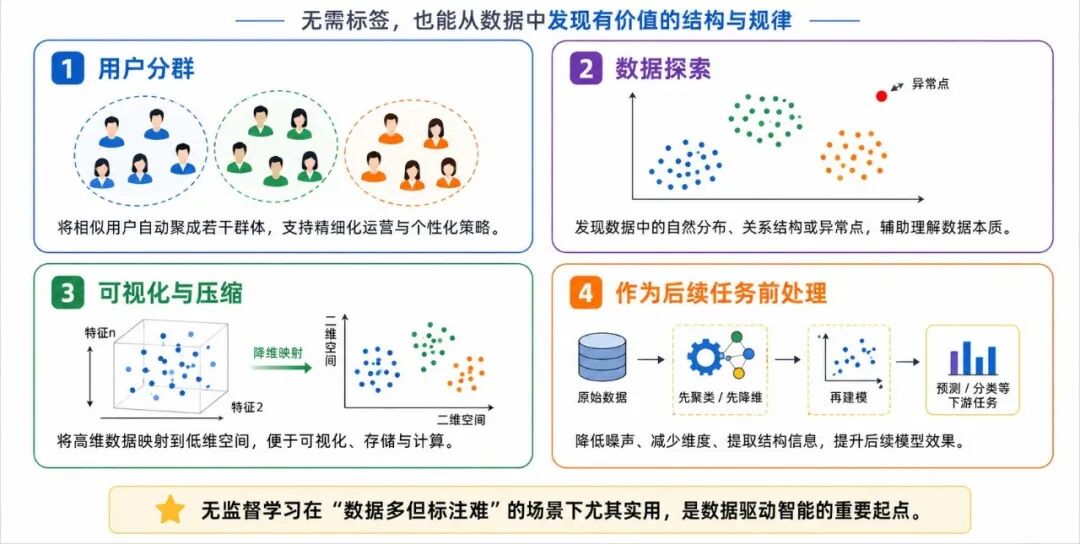
图 6:无监督学习的常见应用场景
1、用户分群
在电商、内容平台或服务系统中,可以根据用户行为自动做分群。例如:
• 高活跃用户
• 高消费低频用户
• 低活跃流失风险用户
这样可以帮助运营人员更有针对性地制定策略。
2、数据探索
在正式建模之前,往往需要先理解数据本身。无监督学习可以帮助我们发现:
• 是否存在自然分组
• 数据是否分布集中
• 是否有异常点
• 哪些方向上变化最明显
这对于后续分析非常重要。
3、可视化与压缩
当数据维度较高时,直接观察几乎不可能。降维方法可以帮助我们把高维数据投影到二维或三维空间,便于画图和理解整体结构。
4、作为后续任务的前处理
无监督学习本身有时并不是最终目的,而是为后续监督学习、推荐系统、异常检测等任务提供支持。例如:
• 先聚类,再对不同群体分别建模
• 先降维,再训练分类器
• 先分析结构,再设计标签体系
因此,无监督学习常常不是"最终结论机器",而是"帮助理解数据、组织数据、准备数据"的重要工具。
延伸阅读:
《Scikit-learn:从数据到结构------无监督学习的最小闭环》
七、无监督学习为什么更难一些
从表面看,无监督学习似乎比监督学习更自由,因为不需要准备标签。但也正因为没有标签,它在很多方面反而更难。
1、没有现成标准答案
监督学习中,预测对不对通常可以直接和真实标签比较。但无监督学习没有标准答案,因此结果是否合理,往往更难判断。
2、结果可能不唯一
同一批数据,在不同算法、不同参数设定下,可能产生不同的分组或不同的低维表示。这并不一定意味着某一种绝对错误,而是说明数据解释本身可能具有多种角度。
3、对数据表示更敏感
无监督学习通常更依赖"样本之间是否相似"这一点,因此特征选择、特征缩放和数据预处理往往会显著影响结果。
4、更依赖解释与分析能力
无监督学习得出的结果,通常需要结合具体问题背景去解释。例如:
• 这 3 个簇分别代表什么类型用户?
• 这个主成分反映的是价格因素还是活跃度因素?
• 某个异常点是真异常还是采集错误?
因此,无监督学习不仅是算法问题,也包含较强的数据理解和结果解释问题。
八、Python 示例:用 K 均值聚类对用户进行简单分组
下面用一个基础示例,把无监督学习中的聚类流程串起来。
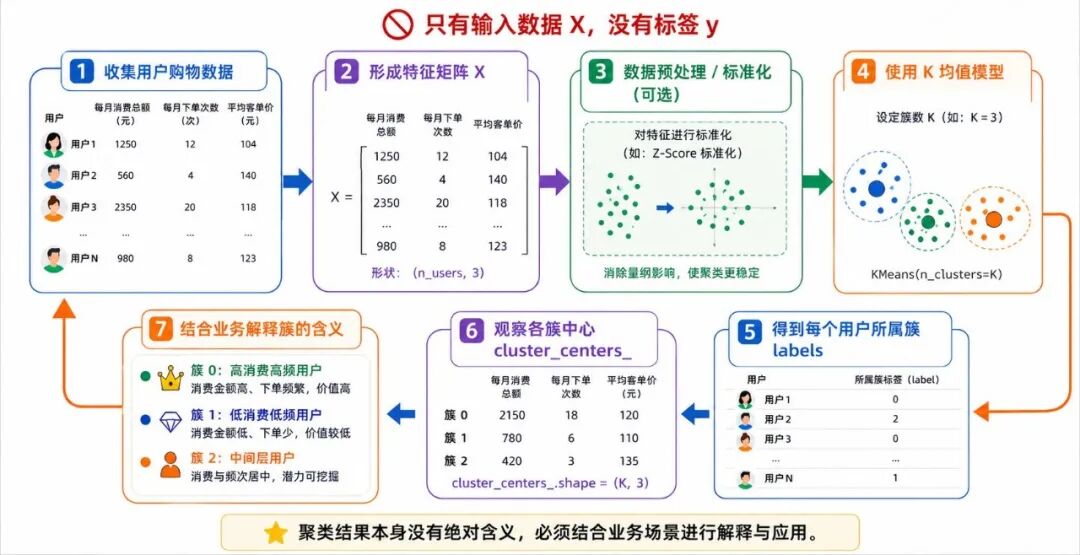
图 7:用户购物数据中的无监督学习闭环
任务是:根据用户的消费总额、下单次数和平均客单价,把用户自动分成 3 类。
cs
import numpy as np # 数值计算from sklearn.cluster import KMeans # KMeans聚类算法
# 每一行表示一个用户:[每月消费总额, 每月下单次数, 平均客单价]X = np.array([ [5000, 20, 250], [5200, 22, 236], [4800, 19, 253], [800, 5, 160], [900, 4, 225], [850, 5, 170], [3000, 10, 300], [3200, 11, 291], [2800, 9, 311]])
# 创建 KMeans 模型,设定分成 3 类model = KMeans(n_clusters=3, random_state=42, n_init=10)
# 训练聚类模型并得到每个样本所属类别(簇标签)labels = model.fit_predict(X)
print("每个用户所属的簇编号:")print(labels)
print("\n各簇中心:")print(model.cluster_centers_)这个示例中要注意几点:
• 这里只有输入数据 X,没有标签 y
• 模型不是去预测"正确答案",而是自动给出分组结果
• labels 表示每个用户被分到哪个簇
• cluster_centers_ 表示各簇的中心位置
从这个结果中,我们可以进一步观察:
• 哪一类用户消费更高
• 哪一类用户购买频率更低
• 哪一类用户处于中间层
虽然这些簇编号本身并没有天然语义,但结合具体业务背景,我们可以对它们进行解释,从而把纯数据结果转化为有意义的信息。
需要注意的是,KMeans 对特征尺度较敏感。真实项目中,如果不同特征的数值范围差异较大,通常应先进行标准化处理;这里为了突出无监督学习的基本流程,暂时省略预处理步骤。
九、无监督学习与人工智能学习路径的关系
在人工智能学习路径中,无监督学习通常出现在监督学习之后。这并不是因为它不重要,而是因为它在理解上往往更抽象。
监督学习通常更容易理解,因为:
• 有标签,目标明确
• 预测对错容易判断
• 训练流程更直观
而无监督学习更强调:
• 从数据本身理解结构
• 从相似性与差异性中发现模式
• 在没有答案的情况下组织信息
因此,学习无监督学习的意义,不只是多掌握几种算法,更重要的是帮助我们建立一种新的数据观:数据即使没有标签,也可能蕴含值得挖掘的结构。
这对于理解聚类、降维、异常检测、表示学习等内容都非常重要。
📘 小结
无监督学习是在没有标签的情况下,从数据内部发现结构、关系和模式的方法。它常见的任务包括聚类与降维,常用于用户分群、数据探索、可视化和前处理等场景。理解无监督学习,有助于建立从数据本身出发分析问题的能力。

"点赞有美意,赞赏是鼓励"