MySQL中的索引是否越多越好
不是,索引是把双刃剑。读的时候能加速查询,写的时候要付出代价。索引太多,时间和空间成本都会上去。
从时间来看
每次insert,update,delete都要同步更新索引。例如删除一条name为123的记录。主键索引要改,name字段如果有二级索引也需要改,有几个索引就需要改几棵B+树。B+树还可能出发页分裂,页合并,写放大等问题。一张 高并发 的订单如果创建了10条索引,写入性能直接打骨折。
查询优化器也会增加负担。MySQL执行SQL语句前需要分析走那个索引成本最低,索引越多选择越多,优化器的耗时就更长。
从空间来看
每个二级索引都是一颗B+树,每个数据页16KB。假设一张表1000万行数据,一个二级索引差不多占到了几GB。索引一多,磁盘占用和内存开销都会飙升,Buffer Poll里能缓存的热数据也变少了。
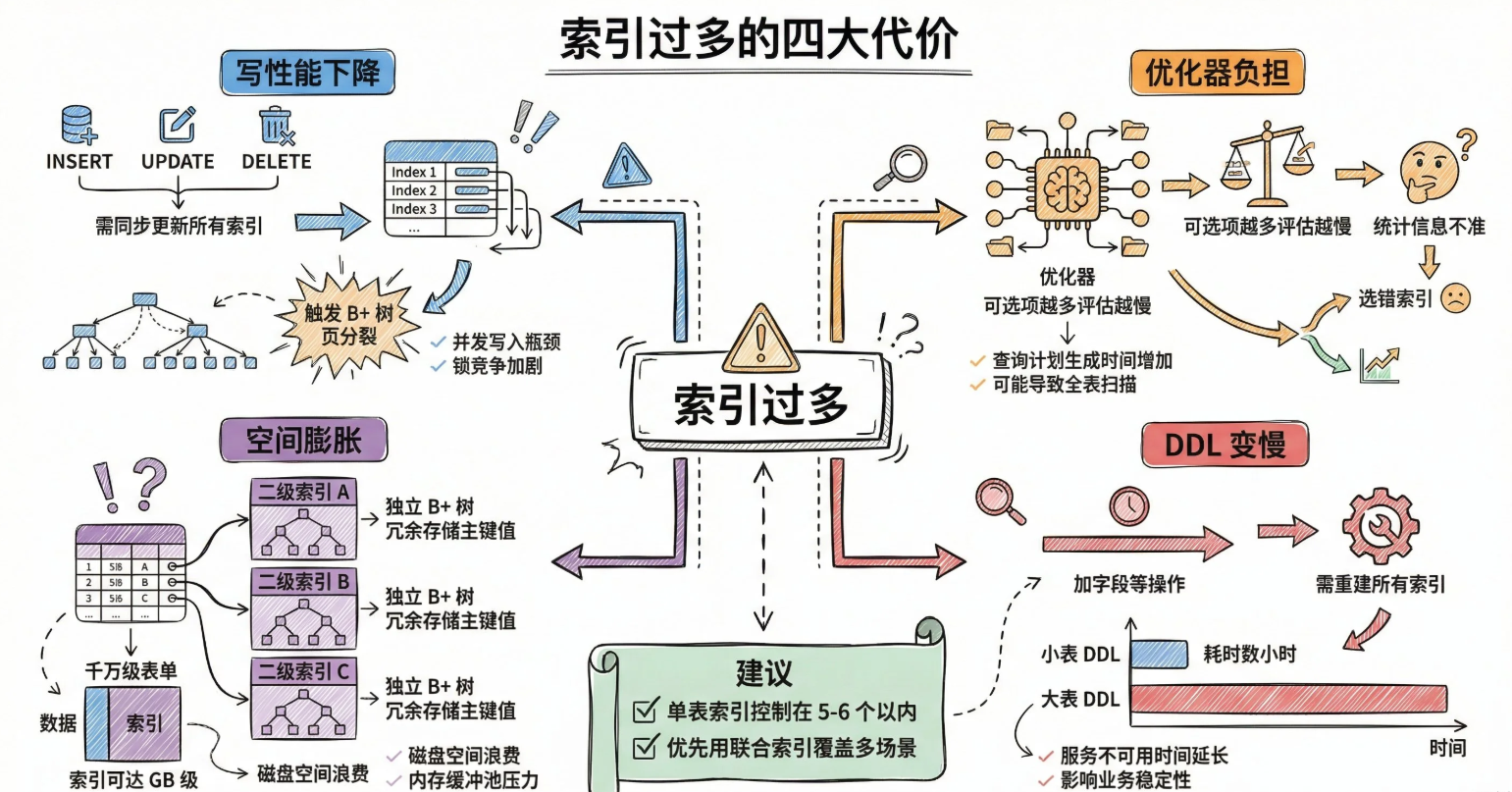
总结
具体由四点原因构成
- 写性能急剧下降
- 优化器选择困难
- 空间占用膨胀
- DDL操作变慢
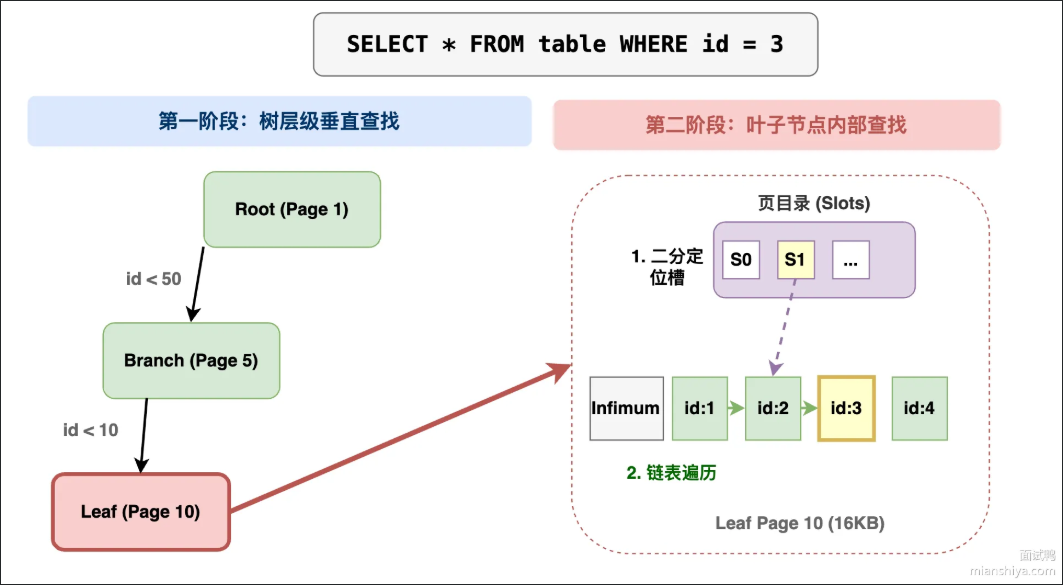
MySQL中B+树查询数据的全过程
B+树查询数据可以分为两个阶段:1.树的垂直查找2.页内查找
第一阶段(树的垂直查找):从根节点开始,把查询的键值与节点中存储的键值进行比较,用二分法来确定具体位置,顺着指针来达到子节点,一直重复直到到达叶子节点。一颗三层B+树查询一次数据最多需要三次I/O
第二阶段(页内查询):叶子节点是一个16KB的数据页,InnoDB用页目录 来加速查找,页目录将数据分成若干组。先用二分法在页目录中定位到记录所在的组,再沿着组内的单向链表遍历,找到目标记录。
过程浏览:根节点->中间节点->叶子节点->页目录二分->组内链表遍历
为什么MySQL用B+树来作为索引结构
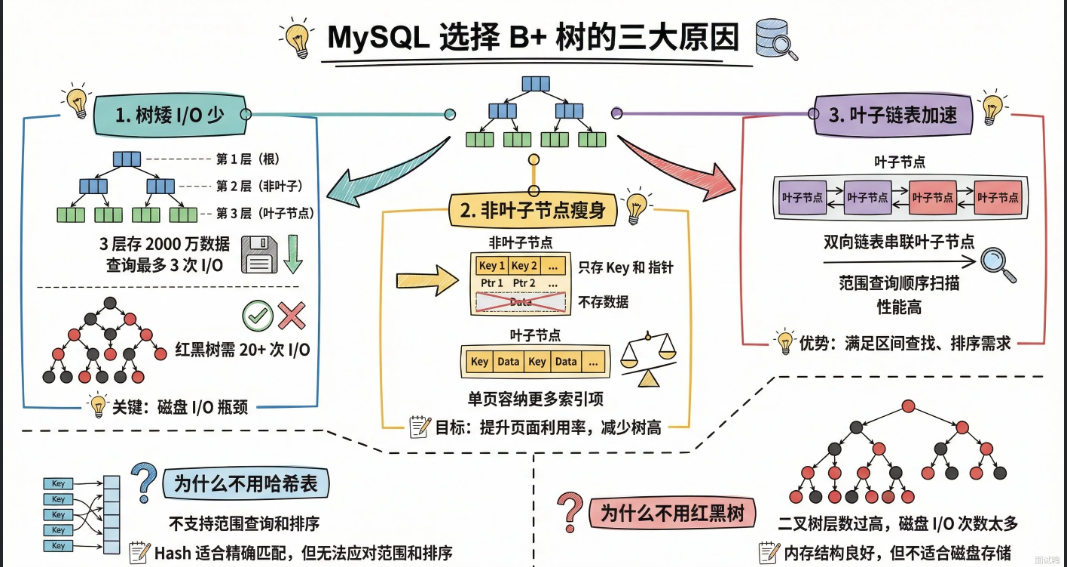
本质原因:磁盘I/O次数少
分三点来答:
- 树矮:B+树是多叉树,一个节点能存几百上千个key。三层B+树就可以存储两千多万条数据,查询一次最多3次磁盘I/O。作为二叉树的红黑树,存储同样多的数据需要20多层。
- 非叶子节点值存key和键值,不存出数据。一个16KB的数据页能塞下更多索引,内存能存储更多索引,命中率高,磁盘访问少。
- 叶子节点用双向链表串起来,范围查询时,顺序I/O比随机I/O快很多。
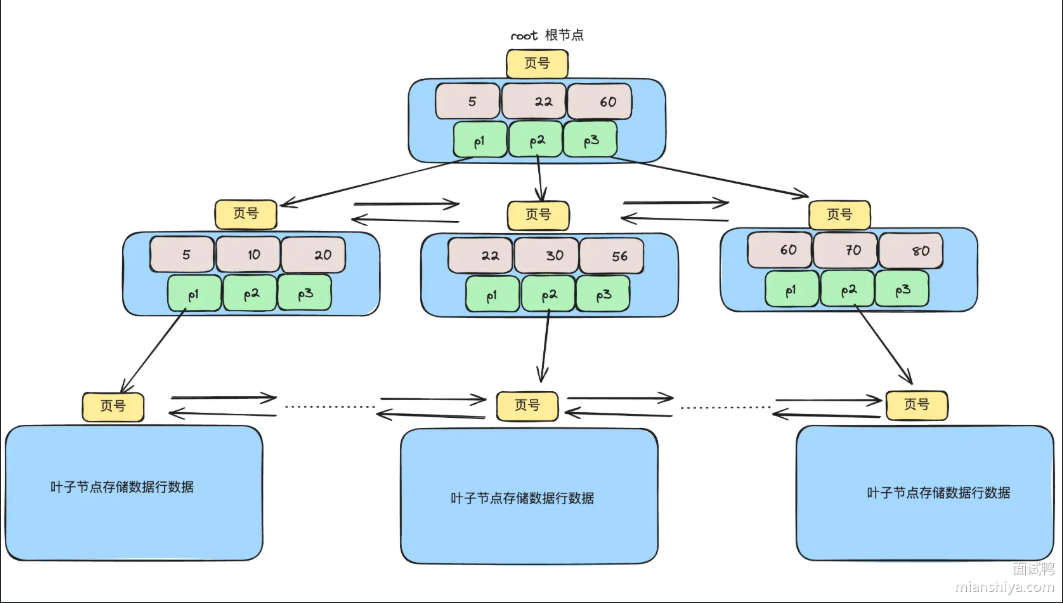
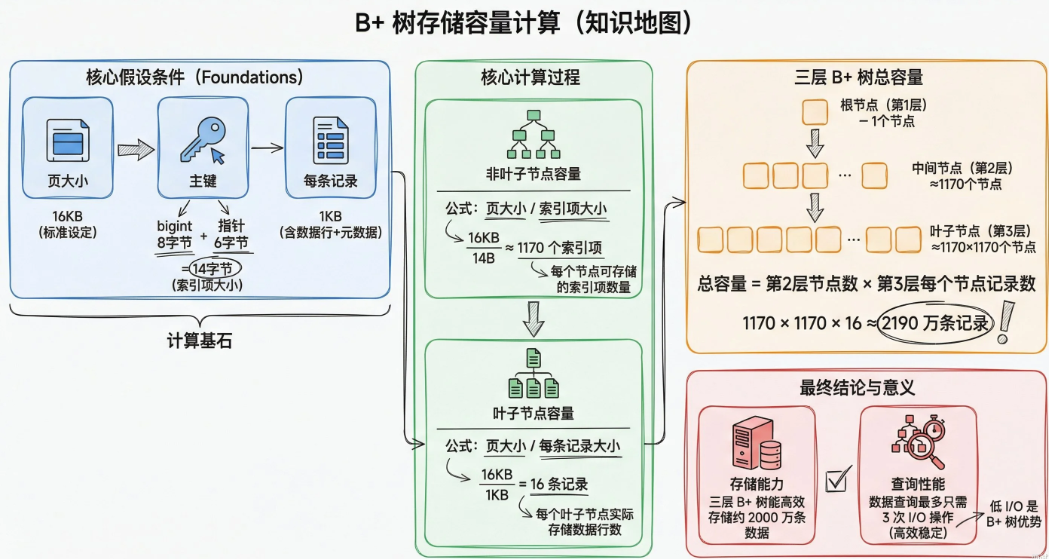
三层B+树能存多少数据具体时这么计算的
InnoDB默认页大小是16KB,非叶子节点存储的是主键和指针,叶子节点存的是完整数据行。
假设主键是bigint占8个字节,指针占6个字节,那么一个非叶子节点能存储的索引数量为:161024/14=1170个
假设每条记录占1KB,那么一个叶子节点能存的记录数为16/1=16条
总记录数:1170 1170*16=2190万条
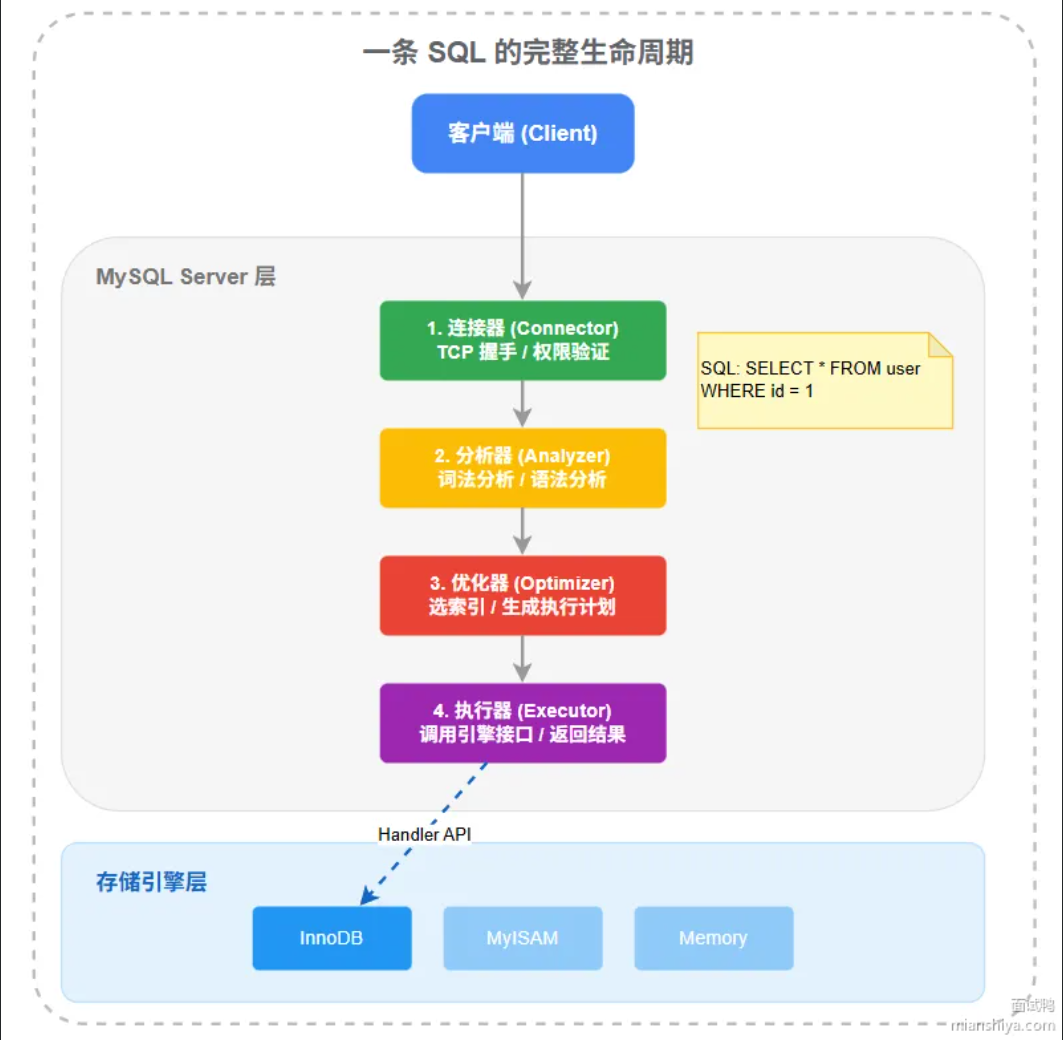
描述一下一条SQL语句在MySQL中的执行过程
MySQL的架构分为两层:Service层负责连接管理,SQL解析,查询优化这些逻辑处理。存储引擎负责数据的实际存取。
集体流程分为5步:
- 客户端先于MySQL建立连接,连接器负责验证账号密码和权限,确认你能对哪些库表做什么操作。
- 老版本会先查询缓存,在8.0版本之后删除了,因为每当表一更新,缓存就会不失效,缓存命中率太低
- 分析器对SQL语句做词法和语法分析。先将字符串拆成一个个Token,识别SELECT,表明,列名,WHERE这些元素;再按语法规则判断SQL语句写的对不对,最终生成一颗语法树。
- 优化器拿到语法树后,决定用哪个索引,多表JOIN时先查哪张表,子查询要不要改成JOIN,最终生成一个执行计划。
- 执行计 划按照执行计划,调用存储引擎的接口一行行读数据,做条件过滤,最终将结果表返回给客户端。
分析器和优化器有什么区别
分析器直观SQL写的对不对,不管这么执行。他把字符串拆成Token,检查语法,生成一颗描述SQL结构的语法树。优化器拿到这颗树后,要决定怎么执行:用哪个索引,表连接顺序,子查询要不要改写。同一条SQL语法树是固定的,但执行计划可能有很多种,优化器负责选成本最低的
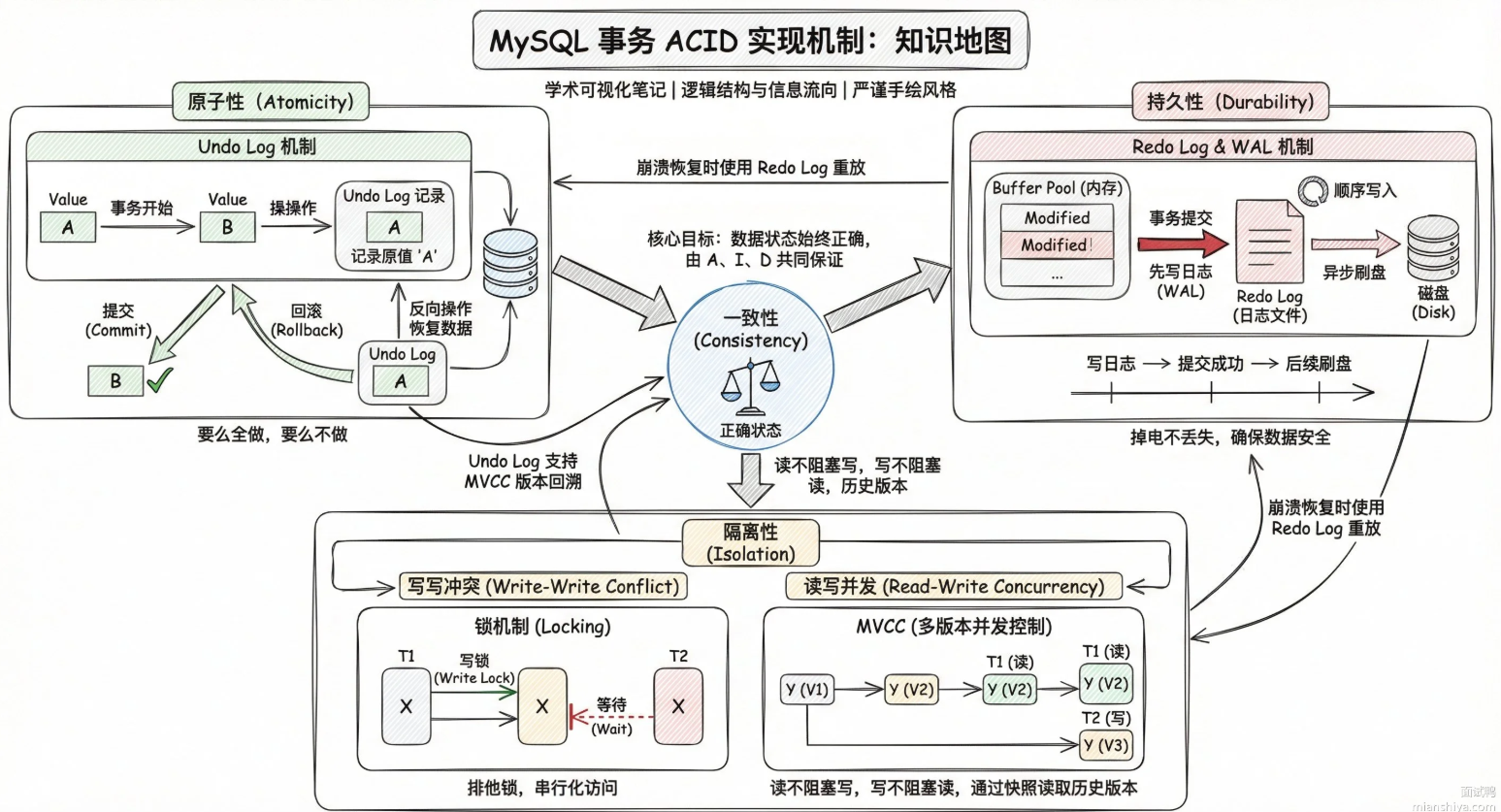
MySQL是如何实现事务的
实现事务主要靠四个核心组件:redo log undo log MVCC 锁 分别对应了事务ACID特性的不同方面。
Redo Log 保证持久性:事务提交时,修改先写到redo log再写磁盘数据页。就算写数据页时宕机了,重启后通过redo log就能恢复数据。这就是WAL机制。
Undo Log 保证原子性:每次修改数据前,先把原值存到undo log里。事务回滚时,按undo log反向操作把数据恢复回去。要么全做完,要么全撤销,不会出现改了一半的中间状态。
锁机制 (行锁,间隙锁)保证隔离性:两个事务同时改同一行,必须一个等另一个释放锁。InnoDB的锁粒度精确到行级,还有间隙锁防止幻读。
MVCC保证隔离性的读写并发:读操作不加锁,用过undo log里的版本连找到自己应该看到的数据版本。写的时候别人照样能读,读的时候别人也能写。大大提升并发性能。
一致性不是单独实现的,它是由:原子性,隔离性,持久性共同作用的结果。数据从一个正确状态转移到另一个正确状态,中间不会出现不一致。
衍生
redo log的工作原理
innodb修改数据时不会直接写磁盘上的数据页,因为随机IO太多,性能扛不住。用的是WAL策略:先修改操作顺序到redo log,再找机会把数据页刷到磁盘。顺序写比随机写快几个数量级。
redo log采用循环写的方式,有两个指针:write pos表示当前写到哪了,checkpoint表设计已经刷盘的位置。两个指针之间就是待刷盘的脏数据。
sql
+---+---+---+---+
| 0 | 1 | 2 | 3 | redo log 文件组
+---+---+---+---+
^ ^
| |
checkpoint write_pos事务提交时,redo log必须落盘,这个行为由innodb_flush_log_at_trx_commit控制:
- 设成1:每次提交都刷盘,最安全但性能差
- 设成0:每秒刷一次,宕机可能丢失一秒数据
- 设成2:写到操作系统缓存,MySQL挂了数据还在,机器挂了才丢
undo log与版本链
每条数据都有两条隐藏字段:trx_id记录最后修改这条数据的事务ID,roll_pointer指向undo log里的上一个版本。多次修改就会形成一条版本链。
假设原始数据name='张三,事务100改成李四',事务200又改成'王五':
sql
当前数据页:name='王五', trx_id=200, roll_pointer →
undo log:name='李四', trx_id=100, roll_pointer →
undo log:name='张三', trx_id=0, roll_pointer=nullMVCC读数据时,根据事务的Read View沿着版本链往回找,找到第一个自己能看见的版本。可重复读隔离级别下,Read View在事务开始时生成一次,后面一直用这个。读已提交隔离级别下,每次查询都生成新的Read VIew。
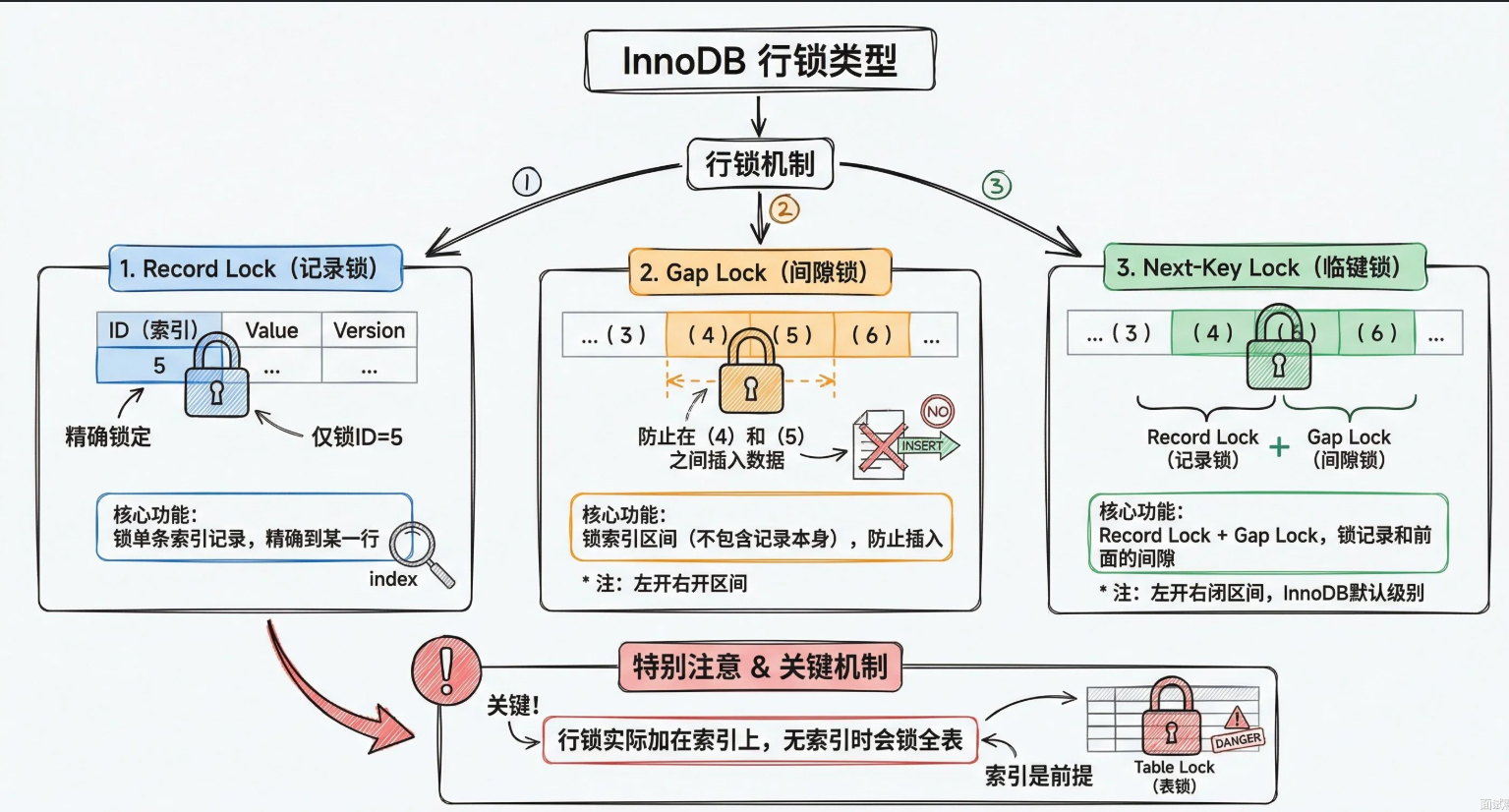
锁的实现细节
innodb的行锁是加在索引上的。如果MySQL没走索引,就会锁全表
InnoDB有三种行锁:
Record Lock:锁单条记录
GapLock:锁一个区间,不包含记录本身
Next-Key Lock:Record Lock +Gap Lock,锁记录和它前面的间隙
事务提交的两阶段提交
InnoDB和Service层有各自自己的日志,redo log和binlog。为保证这两个日志的一致性,用了两阶段提交:
- prepare阶段:redo log写盘,状态标记为prepare
- commit阶段:binlog写盘,然后redo log状态改为commit
如果prepare后binlog写入前宕机,重启恢复时发现redo log是prepare状态但没对应的binlog,事务回滚。
如果 binlog 写完但 commit 前宕机,重启恢复时发现 redo log 是 prepare 状态且有对应的 binlog,事务提交。
这套机制保证了主从复制的数据一致性,从库靠 binlog 同步数据,主库靠 redo log 恢复数据,两边必须对得上。