上线并开源
2026年4月24日, 深度求索(DeepSeek) , DeepSeek V4 预览版正式上线并开源。
这款承载着技术突破与产业期待的万亿参数大模型,以极致效率、超长上下文、原生多模态、颠覆性定价四大核心优势。当前大小两个版本:
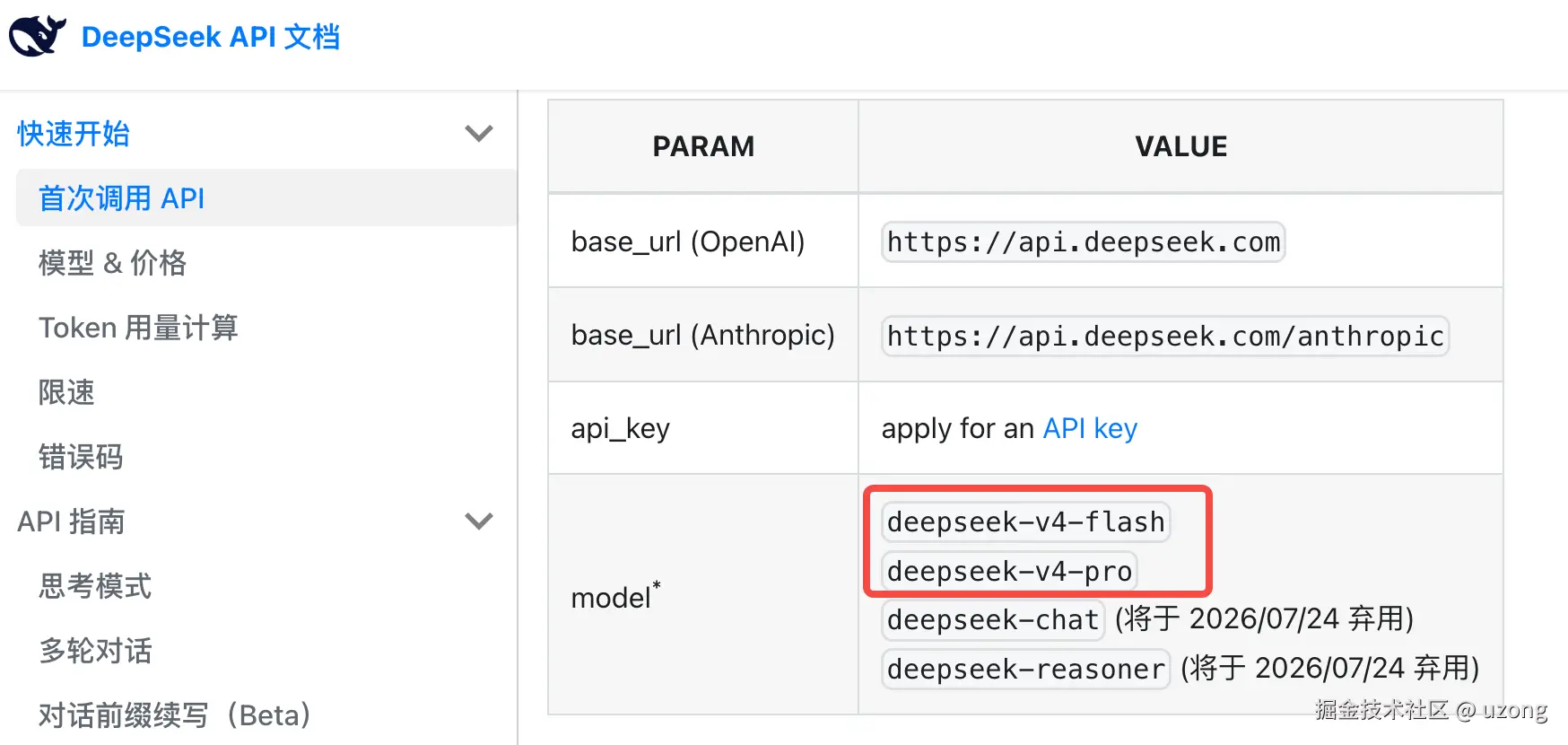
- DeepSeek-V4-Pro 拥有 1.6T 参数(49B 激活参数)
- DeepSeek-V4-Flash 拥有 284B 参数(13B 激活参数)
两者均支持百万级 token 的上下文长度。

API 服务已同步更新,通过修改 model_name 为 deepseek-v4-pro 或 deepseek-v4-flash 即可调用
性能比肩
DeepSeek-V4-Pro:性能比肩顶级闭源模型。
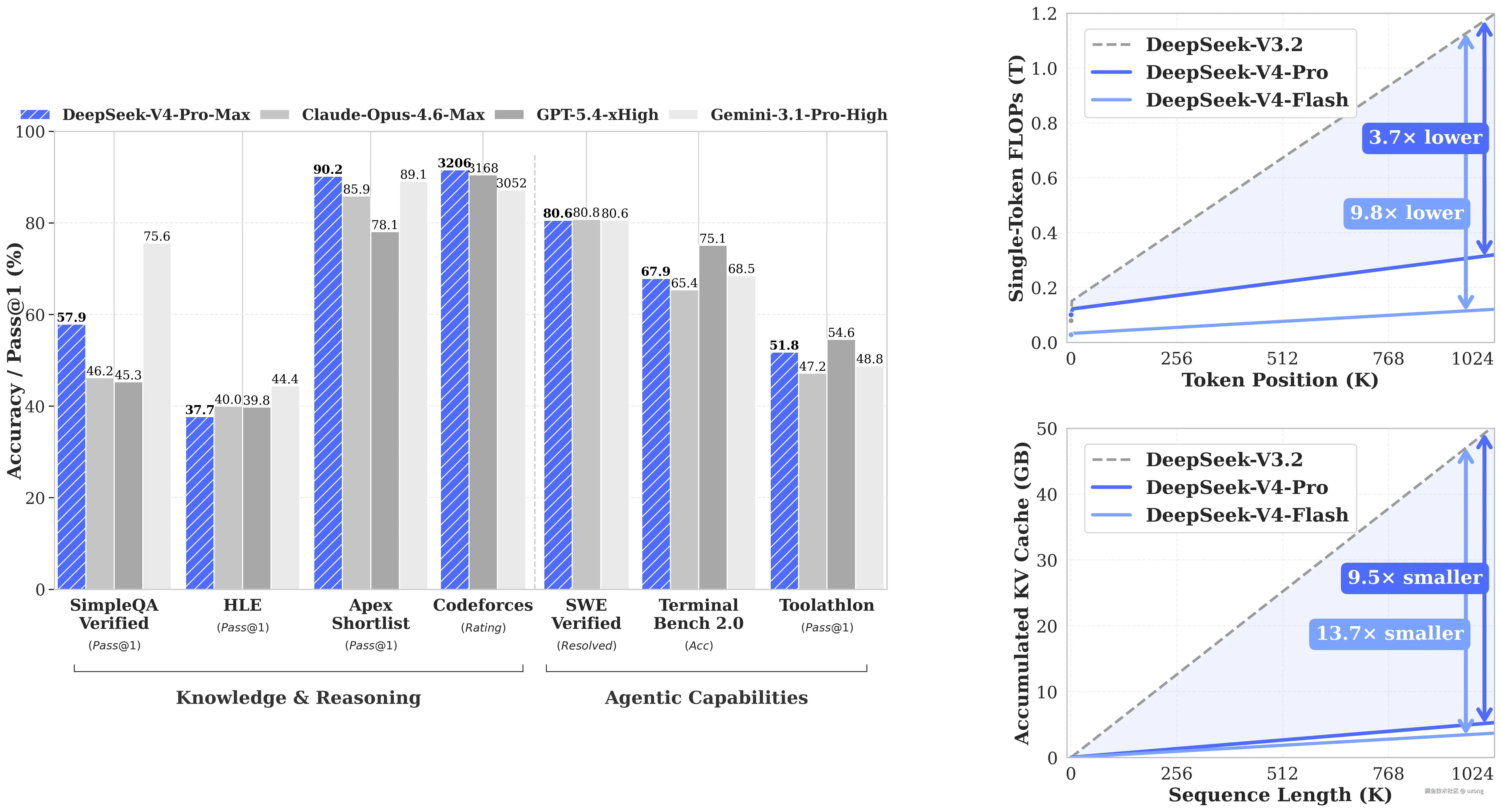
DeepSeek-V4-Pro 在三大核心能力上表现突出:
- Agent 能力大幅提升:达到开源模型最佳水平,公司内部使用体验优于 Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式(与思考模式仍有差距)。
- 世界知识丰富:大幅领先其他开源模型,仅略逊于顶尖闭源模型 Gemini-Pro-3.1。
- 推理性能顶级:在数学、STEM、竞赛代码等任务上,超越所有已评测的开源模型,性能比肩世界顶尖闭源模型。
另外:DeepSeek-V4-Flash 推理能力接近 V4-Pro 水平,同时提供更快捷、经济的 API 服务。其不足在于世界知识储备稍弱,Agent 能力在简单任务上与 V4-Pro 旗鼓相当,但在高难度任务上仍有明显差距。适合对成本与速度敏感、任务复杂度不高的场景使用
DeepSeek V4 的核心 spec
DeepSeek V4 在其前身(如 V3 和 R1)的成功基础上,通过结合巨大的可扩展性和极低的运营成本效率而构建。
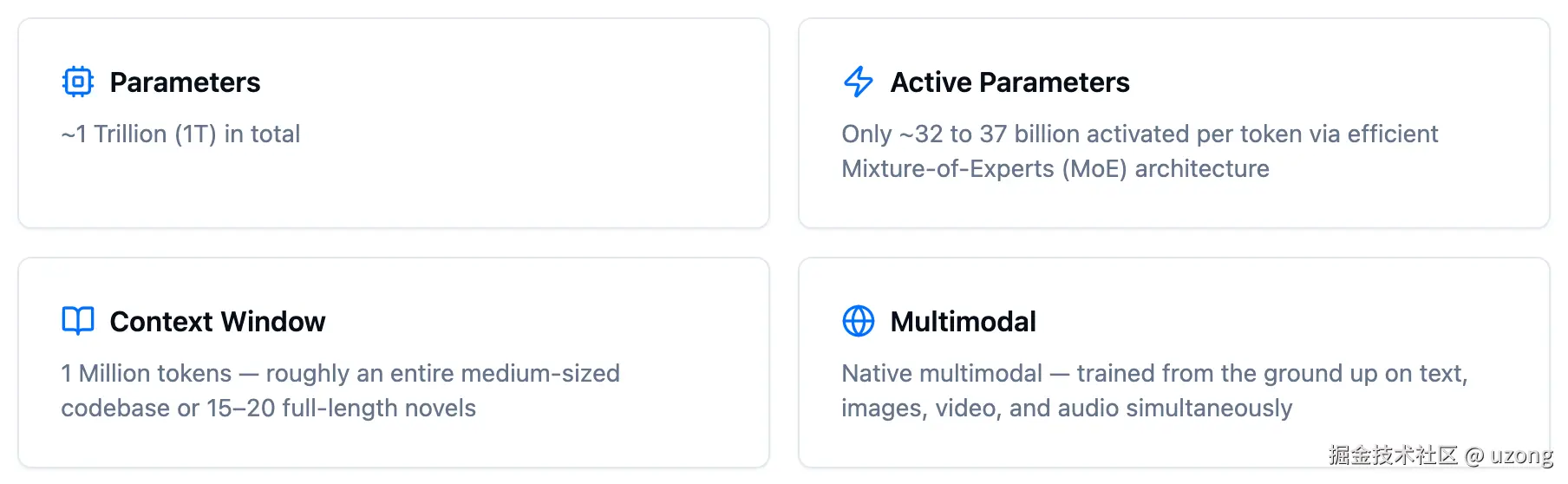
- 1 万亿总参数
- 激活参数 :单 Token 仅激活320-370 亿参数,避免冗余计算,推理成本与前代 V3 持平;
- 上下文窗口 :100 万 Token超长上下文,可承载 15-20 本完整小说、中型代码库全量内容,远超 GPT-5.4(256K)、Claude 4.5(200K);
- 原生多模态:从训练底层支持文本、图像、视频、音频多模态融合,告别后期拼接式适配;
- 本地部署:经 INT8/INT4 量化后,可在双路 RTX 4090 或单路 RTX 5090 消费级显卡本地运行,打破高端模型算力壁垒。
三大架构创新
真正让 DeepSeek V4 脱颖而出的,不是参数堆砌,而是三大颠覆性架构突破,解决长上下文、训练稳定性、计算效率三大行业难题:
- Engram 条件记忆架构 首创静态知识与动态推理分离 机制,在 100 万 Token 上下文的 "大海捞针" 测试中,准确率从传统 84.2% 提升至97% ,精准检索长文本核心信息,彻底解决大模型 "记不住、找不准" 痛点。
- 流形约束超连接(mHC) 用数学框架约束信号放大倍数,将训练梯度波动控制在 2 倍以内(传统无约束模型高达 3000 倍),仅增加 6.7% 计算开销,就能稳定训练万亿参数模型,解决大规模模型训练崩溃难题。
- DeepSeek 稀疏注意力(DSA)+ 闪电索引器 替换传统密集注意力,通过闪电索引器快速定位上下文关键片段,仅聚焦有效 Token 计算,降低 50% 长上下文计算开销,让百万 Token 推理速度媲美短文本处理。
性能对标和定价
内部基准测试显示,DeepSeek V4 在推理、代码能力上直接对标 GPT-5.4、Claude Opus 4.5,部分指标实现反超,且成本优势颠覆性:
| 测试维度 | DeepSeek V4 | GPT-5.4 | Claude Opus 4.5 |
|---|---|---|---|
| SWE-bench 代码验证 | >80% | ~80% | 80.9% |
| HumanEval 代码生成 | ~90% | ~92% | ~92% |
| 输入 Token(缓存未命中) | 0.14−0.30 / 百万 | 1.75−15 / 百万 | $5 / 百万 |
| 输出 Token | 0.28−0.50 / 百万 | 5−60 / 百万 | $25 / 百万 |
数据显示,DeepSeek V4 API 定价比西方竞品便宜 10-50 倍 ,缓存命中时输入成本低至0.03 美元 / 百万 Token,让企业与个人开发者用极低成本享受顶级 AI 能力。
适配国产芯片

DeepSeek V4 的另一重大意义,是全面适配国产 AI 算力,打破英伟达 GPU 垄断:
- 训练初期依托英伟达 H800,推理阶段深度优化华为昇腾 950PR、寒武纪 MLU芯片;
- 昇腾 950PR 计算性能达英伟达 H20(对华合规芯片)的2.87 倍,实现算力自主可控;
- 从 CUDA 框架全面转向华为 CANN,完成全栈国产适配,成为全球首个不依赖西方算力的前沿大模型,标志中国 AI 算力从 "可用" 迈向 "好用"。
发布与开源
历经多次延期后,DeepSeek V4 终于迎来落地:
- 2026 年 3 月 9 日,V4 Lite(200 亿参数) 悄然上线,验证核心架构稳定性;
- 2026 年 4 月 24 日,V4 预览版正式上线,同步开源权重,采用宽松 Apache 2.0 协议,支持商用、二次开发无门槛;
- 官方推出V4-Pro(旗舰性能) 与V4-Flash(高效经济) 双版本,覆盖复杂 Agent 场景与轻量化需求,100 万上下文成为全服务标配。
普惠 AI 时代来临。
行业影响
DeepSeek V4 不仅仅是一个渐进式更新,而是一次架构上的突破。通过结合原生多模态、一百万个 token 的上下文窗口和颠覆性的定价,DeepSeek 正在迫使企业公司和独立开发者重新思考他们的 AI 基础设施。
从参数突破到架构革新,从算力自主到普惠开源,DeepSeek V4 不仅是一款大模型,更是中国 AI 走向世界前沿的宣言。随着 4 月正式发布与开源,它将彻底激活长文本、多模态、低成本推理的海量应用场景,推动 AI 从 "少数人专属" 走向 "全民普惠"。