目录
[一、多分类交叉熵函数 ------ nn.CrossEntropyLoss()](#一、多分类交叉熵函数 —— nn.CrossEntropyLoss())
[二、二分类交叉熵函数 ------ nn.BCELoss()](#二、二分类交叉熵函数 —— nn.BCELoss())
[1. MAE 损失函数](#1. MAE 损失函数)
[2. MSE损失函数](#2. MSE损失函数)
[3. Smooth L1 Loss (也称为 Huber Loss)](#3. Smooth L1 Loss (也称为 Huber Loss))
[4. 如何选择回归任务的损失函数](#4. 如何选择回归任务的损失函数)
[5. 代码](#5. 代码)
损失函数
是什么? 评估模型的预测值和真实值差距的函数,从而评估模型的好坏,损失值越小越好。
(损失函数、代价函数、目标函数、误差函数)同一个意思。
一、多分类交叉熵函数 ------ nn.CrossEntropyLoss()
自带了SoftMax,模型的输出输出层不需要再softmax

例如:
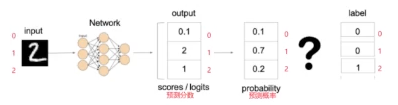
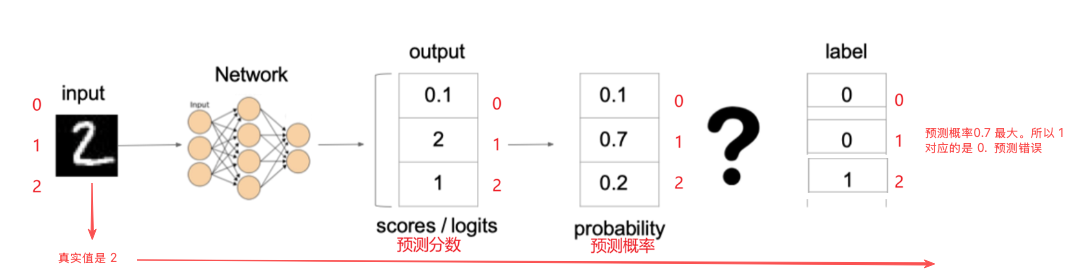
带入公式

正确类别的预测概率 曲线
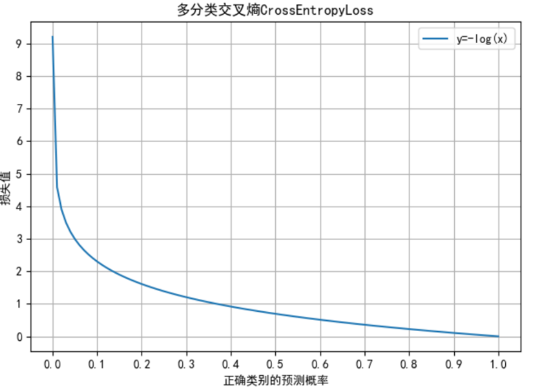
总结:
其中:y_logits是模型的原始输出/预测分数
softmax(y_logits)是模型输出的概率分布,也就是每个类别的预测概率,最大概率对应预测类别
注意:
多分类交叉熵CrossEntropLoss里面有softmax运算,所以模型的输出层不需要softmax。
但是如果要获取预测概率,则需要在模型输出的原始预测分数后面经过softmax
应用:
多分类问题,如:10个类别,预测图片属于哪一类
API:
nn.CrossEntropyLoss()
代码:
python
import torch
import torch.nn as nn
python
# 1.创建 样本的真实值,假设是一个三分类任务, 真实类别为[1,0,2,0]. 4个样本
y_true = torch.tensor([1,0,2,0], dtype=torch.long)
# 2.创建 模型的预测分数y_logits
y_logits = torch.tensor([
[0.1,2.0,1.0],
[0.2,0.5,0.3],
[0.3,0.2,0.5],
[0.5,0.2,0.3]
])
# 3.创建 多分类交叉熵损失函数对象
loss_fn = nn.CrossEntropyLoss()
# 4.计算损失
# y_logits: 2D(batch_size, 3), y_true: 1D(batch_size)
# 为什么是 3 ----> 三分类
loss = loss_fn(y_logits,y_true)
print(f"多分类交叉熵损失函数: {loss}")二、二分类交叉熵函数 ------ nn.BCELoss()
二分类中使用

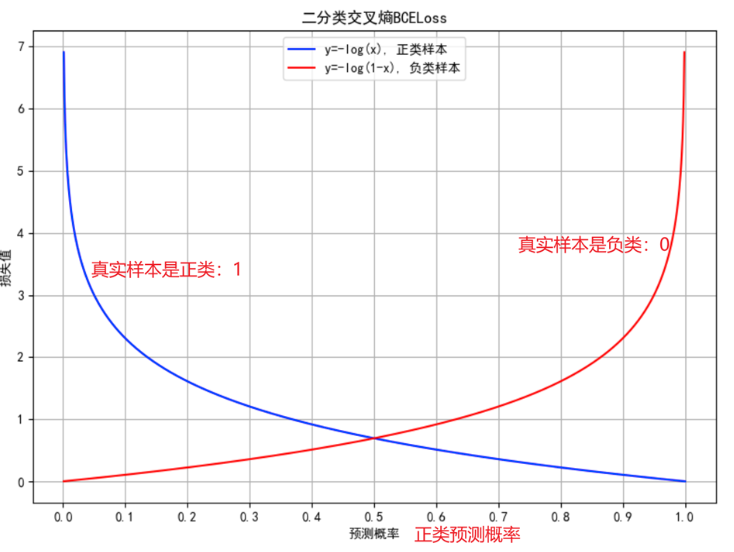
总结:
二分类交叉熵损失
公式:BCELoss = -y*log(y_hat)-(1-y)*log(1-y_hat)
其中:y_hat是模型的预测值,也就是经过sigmoid之后的预测概率,对应正类
y 是真实值,0或1,
负类:标签编码0,one-hot编码1,0,正类:标签编码1,one-hot0,1
注意:
二分类交叉熵损失BCELoss里面没有sigmoid,所以模型输出层最后需要添加sigmoid
API:
nn.BCELoss()
代码:
python
# 1.创建 样本的真实值,假设是一个二分类任务, 真实类别为[0,1,0,1]
y_true = torch.tensor([0,1,0,1], dtype=torch.float)
# 2. 创建 预测分数, 1D (batch_size,)
y_logits = torch.tensor([10, -10, -50, 2.5], dtype=torch.float)
"""
# 预测类别 [1,0,0,1]
# 经过sigmoid,转换为概率,这里才是模型输出的预测值
"""
y_preds = torch.sigmoid(y_logits)
# 3. 创建 二分类交叉熵损失函数
loss_fn = nn.BCELoss()
# 4. 计算损失
# y_pred: 1D (4,). y_true:1D(4,)
loss = loss_fn(y_preds,y_true)
print(f"二分类交叉熵损失:: {loss}")二分类任务可以用 多分类交叉熵损失。
三、回归任务
1. MAE 损失函数
公式:
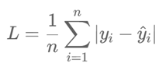
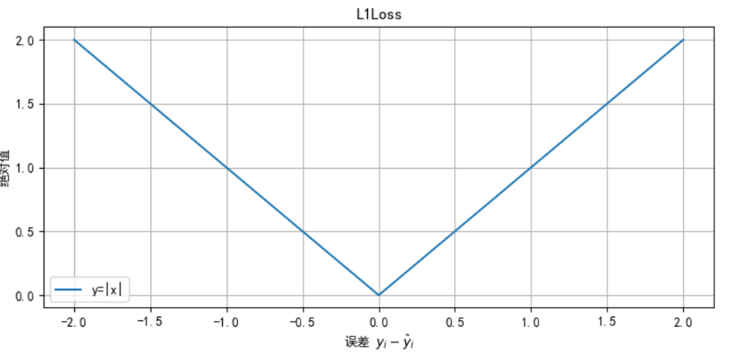
特点:
① 损失 - 误差呈线性关系
② MAE损失函数本身不具有稀梳性,不会让权重衰减为0
③ 最大问题是梯度在零点不平滑,会跳过极小值
④ 适用于回归问题中存在异常值或噪声数据时,可以减少对离群点的敏感性
2. MSE损失函数
Mean Squared Loss / Quadratic Loss (MSE loss) 也被称为L2 loss,或欧氏距离。
++计算误差平方的平均值. =++ ++均差平方之和 / 样本总数++
公式:
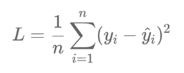
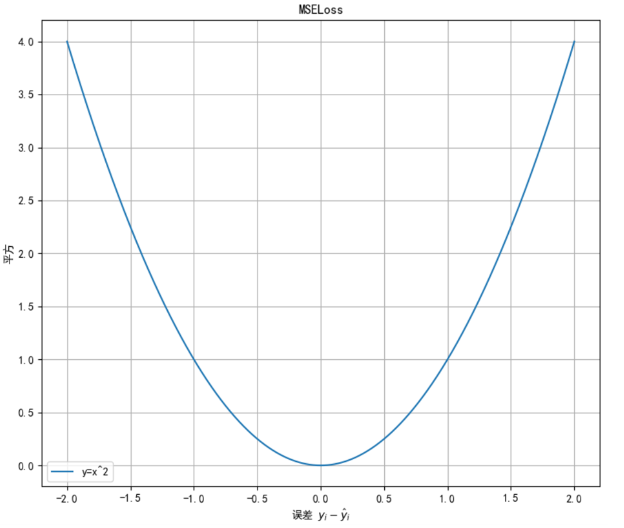
特点:
① 损失-误差呈二次曲线关系
② 处处可导、梯度平滑,是 ++最常用++的回归损失函数
③ 误差大时候,容易梯度过大, 无法有效训练模型
④ 适用于大多数标准回归问题,如房价、温度预测等
3. Smooth L1 Loss (也称为 Huber Loss)
简单来说:
就是 MAE 和 MSE的结合,尤其是在面对异常值时,它能平滑过渡,避免大误差的影响
公式:
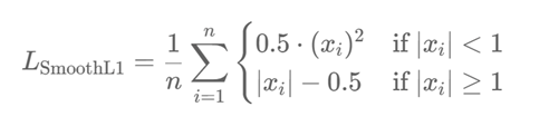
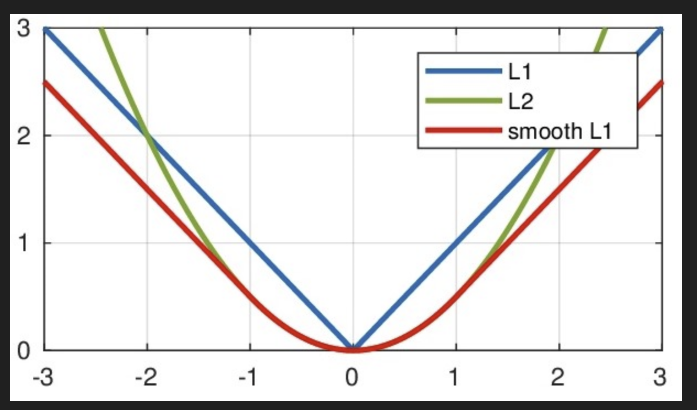
可以转换看做
< 1是 MSE. ≥ 1 是MAE
解决L1(MAE)在0点不平滑、以及L2(MSE)的梯度爆炸问题
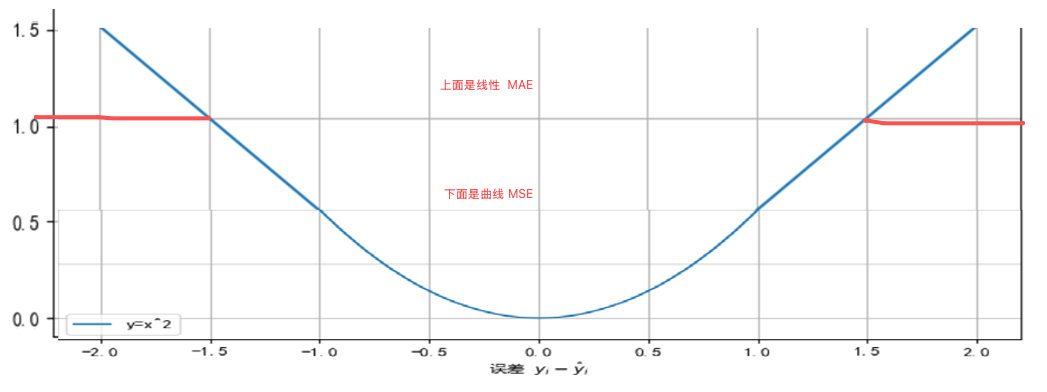
4. 如何选择回归任务的损失函数
MSE > Smooth L1 > MAE
API:
nn.L1Loss()
nn.MSELoss()
nn.SoothL1Loss()
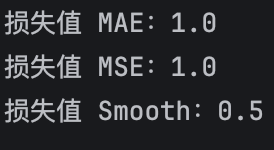
5. 代码
python
# 1.创建 样本的真实值
# 4个样本
y_true = torch.tensor([20.0,21.0,22.0,23.0],dtype=torch.float32)
# 2.创建 模型的预测值
y_pred = torch.tensor([21.0,22.0,23.0,24.0],dtype=torch.float32,requires_grad=True)
# 3.定义损失函数对象
loss_fn1 = nn.L1Loss()
loss_fn2 = nn.MSELoss()
loss_fn3 = nn.SmoothL1Loss()
# 4.计算损失值
loss1 = loss_fn1(y_pred,y_true)
loss2 = loss_fn2(y_pred,y_true)
loss3 = loss_fn3(y_pred,y_true)
# 5.打印损失值
print(f"损失值 MAE:{loss1}") # 1
print(f"损失值 MSE:{loss2}") # 2
print(f"损失值 Smooth:{loss3}") # 3