排序算法二:归并排序、快速排序、希尔排序
一、归并排序(Merge Sort)
1.1 历史背景
归并排序于 1945年 由 约翰·冯·诺伊曼(John von Neumann) 首次提出。
1.2 核心思想
归并排序采用经典的分治策略(Divide and Conquer),将大问题分解为小问题分别解决,然后合并结果:
执行流程:
① 分割阶段:不断地将当前序列平均分割成2个子序列,直到不能再分割(序列中只剩1个元素)
② 合并阶段:不断地将2个子序列合并成一个有序序列,直到最终只剩下1个有序序列1.3 图示说明
以数组 [3, 5, 1, 2, 4, 6, 9, 8, 7, 10, 11] 为例:
| 步骤 | 数组状态 |
|---|---|
| 原始数组 | 3 5 1 2 4 6 9 8 7 10 11 |
| 一次分割合并后 | 2 1 3 5 4 6 7 8 9 10 11 |
| 最终有序 | 1 2 3 4 5 6 7 8 9 10 11 |
分割过程示意:
[3,5,1,2,4,6,9,8,7,10,11]
/ \
[3,5,1,2,4] [6,9,8,7,10,11]
/ \ / \
[3,5] [1,2,4] [6,9,8] [7,10,11]
/ \ / \ / \ / \
[3] [5] [1] [2,4] [6] [9,8] [7] [10,11]
/ \ / \ / \
[2] [4] [9] [8] [10] [11]1.4 代码实现
java
public class MergeSort {
private int[] leftArray; // 辅助数组,用于备份左半部分
public void sort(int[] array) {
// 初始化辅助数组,大小为原数组的一半即可
leftArray = new int[array.length >> 1];
sort(array, 0, array.length);
}
/**
* 对 [begin, end) 范围的数据进行归并排序
*/
private void sort(int[] array, int begin, int end) {
// 元素数量 < 2,已经有序,直接返回
if (end - begin < 2) return;
// 计算中间位置
int mid = (begin + end) >> 1;
// 递归排序左半部分 [begin, mid)
sort(array, begin, mid);
// 递归排序右半部分 [mid, end)
sort(array, mid, end);
// 合并两个有序子序列
merge(array, begin, mid, end);
}
/**
* 将 [begin, mid) 和 [mid, end) 范围的序列合并成一个有序序列
*/
private void merge(int[] array, int begin, int mid, int end) {
int lb = 0, le = mid - begin; // 左边数组的边界 [0, le)
int rb = mid, re = end; // 右边数组的边界 [rb, re)
int ab = begin; // 合并后填充的位置
// 1. 备份左边数组到 leftArray
for (int i = lb; i < le; i++) {
leftArray[i] = array[begin + i];
}
// 2. 合并过程:比较左右两边,将较小的放入原数组
while (lb < le) { // 左边未结束
if (rb < re && array[rb] < leftArray[lb]) {
// 右边元素更小,拷贝右边
array[ab++] = array[rb++];
} else {
// 左边元素更小或相等,拷贝左边(相等时先拷贝左边保证稳定性)
array[ab++] = leftArray[lb++];
}
}
// 左边先结束,则数组已经排序完毕
// 右边先结束,剩余左边元素已经在原位置,无需处理
}
}1.5 合并过程详解
需要 merge 的两组序列存在于同一个数组中,并且是挨在一起的 [begin, mid) 和 [mid, end):
| 情况 | 处理方式 |
|---|---|
| 左边先结束 | 数组已经排序完毕,因为两边数组都是有序的 |
| 右边先结束 | 只需把左边数组剩余元素移到右边即可(已在原位置,无需操作) |
合并示意:
原数组: [2, 4, 6 | 1, 3, 5] (mid=3)
↑左边有序 ↑右边有序
备份左边: leftArray = [2, 4, 6]
合并过程:
比较 leftArray[0]=2 和 array[3]=1 → 1更小 → array[0]=1
比较 leftArray[0]=2 和 array[4]=3 → 2更小 → array[1]=2
比较 leftArray[1]=4 和 array[4]=3 → 3更小 → array[2]=3
比较 leftArray[1]=4 和 array[5]=5 → 4更小 → array[3]=4
比较 leftArray[2]=6 和 array[5]=5 → 5更小 → array[4]=5
左边剩余 [6] → array[5]=6
结果: [1, 2, 3, 4, 5, 6]1.6 复杂度分析
| 指标 | 复杂度 | 说明 |
|---|---|---|
| 最好时间复杂度 | O(n log n) | 总是平均分割 |
| 最坏时间复杂度 | O(n log n) | 总是平均分割 |
| 平均时间复杂度 | O(n log n) | 总是平均分割 |
| 空间复杂度 | O(n) | n/2 用于临时存放左侧数组,log n 是因为递归调用 |
| 稳定性 | ✅ 稳定排序 | 相等元素保持原有顺序 |
二、快速排序(Quick Sort)
2.1 历史背景
快速排序于 1960年 由 查尔斯·安东尼·理查德·霍尔(Charles Antony Richard Hoare,缩写为 C. A. R. Hoare) 提出,昵称为 东尼·霍尔(Tony Hoare) 。

2.2 核心思想
快速排序的本质是 逐渐将每一个元素都转换成轴点元素(pivot) :
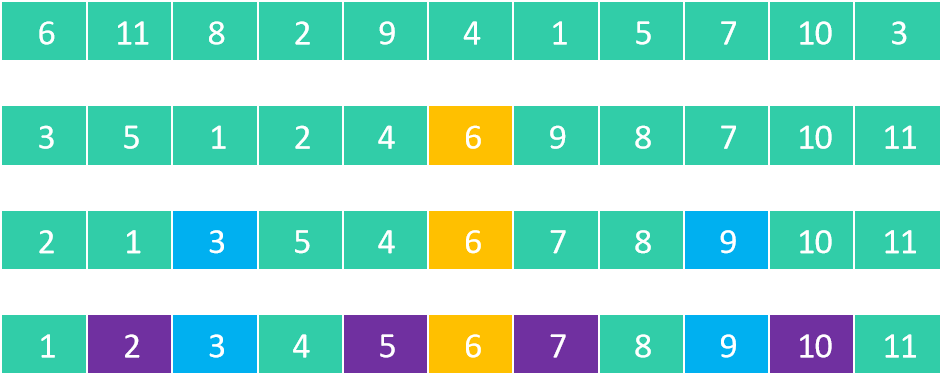
执行流程:
① 从序列中选择一个轴点元素(pivot),假设每次选择 0 位置的元素
② 利用 pivot 将序列分割成 2 个子序列:
- 将小于 pivot 的元素放在 pivot 前面(左侧)
- 将大于 pivot 的元素放在 pivot 后面(右侧)
- 等于 pivot 的元素放哪边都可以
③ 对子序列重复执行 ① ② 操作,直到不能再分割(子序列中只剩下1个元素)2.3 轴点构造过程(重点)
以数组 [6, 11, 8, 2, 9, 4, 1, 5, 7, 10, 3] 为例,选择 6 作为轴点:
初始: [6, 11, 8, 2, 9, 4, 1, 5, 7, 10, 3]
↑pivot=6
begin=0, end=10
目标: 将数组分为 <6 和 >6 两部分,6放在正确位置
过程示意(双指针法):
begin从左找>6的,end从右找<6的,交换
[6, 11, 8, 2, 9, 4, 1, 5, 7, 10, 3]
↑begin(11>6) ↑end(3<6)
交换11和3:
[6, 3, 8, 2, 9, 4, 1, 5, 7, 10, 11]
↑begin(8>6) ↑end(7>6,继续左移)
↑begin(8>6) ↑end(5<6)
交换8和5:
[6, 3, 5, 2, 9, 4, 1, 8, 7, 10, 11]
↑begin(2<6,右移)↑end(1<6,继续左移)
↑begin(9>6) ↑end(4<6)
交换9和4:
[6, 3, 5, 2, 4, 9, 1, 8, 7, 10, 11]
↑begin(9>6)↑end(1<6)
交换9和1:
[6, 3, 5, 2, 4, 1, 9, 8, 7, 10, 11]
↑begin ↑end (begin>end,停止)
将pivot与end位置交换:
[1, 3, 5, 2, 4, 6, 9, 8, 7, 10, 11]
↑pivot最终位置
结果: 左边[1,3,5,2,4]都<6, 右边[9,8,7,10,11]都>62.4 代码实现
java
public class QuickSort {
public void sort(int[] array) {
sort(array, 0, array.length);
}
/**
* 对 [begin, end) 范围的元素进行快速排序
*/
private void sort(int[] array, int begin, int end) {
if (end - begin < 2) return; // 元素数量 < 2,已有序
// 确定轴点位置
int mid = pivotIndex(array, begin, end);
// 对子序列进行递归排序
sort(array, begin, mid); // 排序左边 [begin, mid)
sort(array, mid + 1, end); // 排序右边 [mid+1, end)
}
/**
* 构造 [begin, end) 范围的轴点元素
* @return 轴点元素的最终位置
*/
private int pivotIndex(int[] array, int begin, int end) {
// 选择第一个元素作为轴点(可优化为随机选择)
int pivot = array[begin];
end--; // end指向最后一个元素
while (begin < end) {
// end从右向左找 < pivot 的元素
while (begin < end) {
if (array[end] > pivot) { // 右边元素 > pivot,正确位置
end--;
} else { // 右边元素 <= pivot,放到左边
array[begin++] = array[end];
break;
}
}
// begin从左向右找 > pivot 的元素
while (begin < end) {
if (array[begin] < pivot) { // 左边元素 < pivot,正确位置
begin++;
} else { // 左边元素 >= pivot,放到右边
array[end--] = array[begin];
break;
}
}
}
// 将轴点元素放入最终位置
array[begin] = pivot;
return begin;
}
}2.5 与轴点相等元素的处理
问题场景: 如果序列中所有元素都与轴点元素相等(如 [6a, 6b, 6c, 6d, 6e])
| 比较方式 | 效果 | 结果 |
|---|---|---|
cmp < 0(严格小于) |
相等元素分到左边 | ✅ 轴点左右均匀分割,最优 O(n log n) |
cmp <= 0(小于等于) |
相等元素全分左边 | ❌ 轴点右边为空,最坏 O(n²) |
结论: cmp 位置的判断应使用 严格小于 <,才能保证相等元素均匀分布。
2.6 复杂度分析
| 情况 | 时间复杂度 | 说明 |
|---|---|---|
| 最好情况 | O(n log n) | 轴点左右元素数量均匀分布 |
| 平均情况 | O(n log n) | 随机数据下期望表现 |
| 最坏情况 | O(n²) | 轴点左右极度不均匀(如有序数组选第一个为轴点) |
优化策略: 为降低最坏情况出现概率,一般采取 随机选择轴点元素。
| 指标 | 结果 |
|---|---|
| 最好/平均时间复杂度 | O(n log n) |
| 最坏时间复杂度 | O(n²) |
| 空间复杂度 | O(log n)(递归调用栈) |
| 稳定性 | ❌ 不稳定排序 |
最坏情况示例(有序数组选第一个为轴点):
[7, 1, 2, 3, 4, 5, 6] → pivot=7, 右边为空
[6, 1, 2, 3, 4, 5, 7] → pivot=6, 右边为空
[5, 1, 2, 3, 4, 6, 7] → pivot=5, 右边为空
...
每次只减少1个元素,退化为 O(n²)三、希尔排序(Shell Sort)
3.1 历史背景
希尔排序于 1959年 由 唐纳德·希尔(Donald Shell) 提出。
3.2 核心思想
希尔排序把序列看作是一个矩阵,分成 n 列,逐列进行排序:
核心概念:
- 步长(gap):矩阵的列数,从某个整数逐渐减为1
- 当步长为1时,整个序列将完全有序
- 因此希尔排序也被称为 "递减增量排序"(Diminishing Increment Sort)矩阵索引计算:
假设元素在第
col列、第row行,步长(总列数)是step那么这个元素在数组中的索引是:
col + row * step
例如:步长为5时,元素 9 在第2列、第0行,索引 = 2 + 0 * 5 = 2
3.3 实例演示
以 [16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1](16个元素)为例:

步长序列:{1, 2, 4, 8}(希尔本人给出的 n/2^k)
第一步:分成8列排序(步长=8)
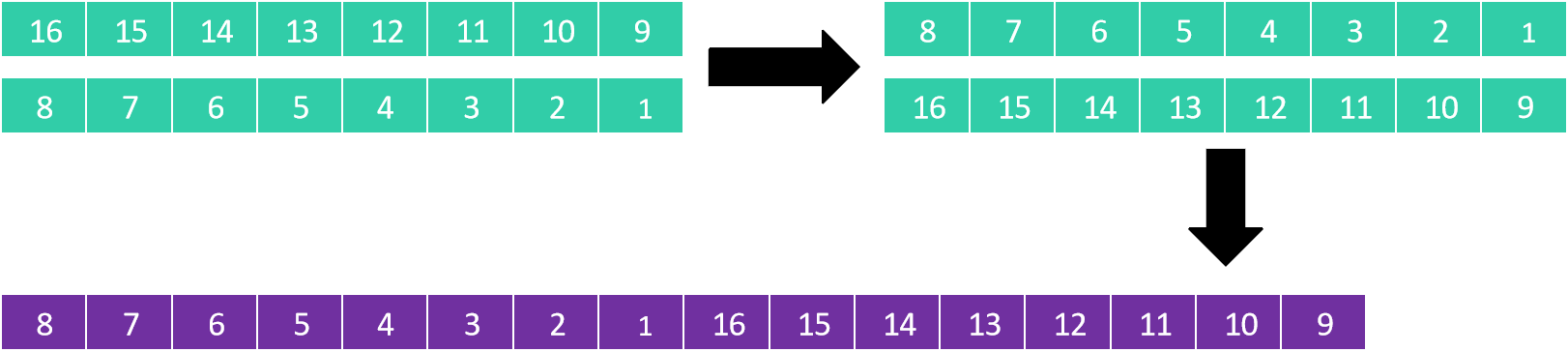
原始序列看作8列2行的矩阵:
16 15 14 13 12 11 10 9
8 7 6 5 4 3 2 1
每列排序后(每列内部有序):
8 7 6 5 4 3 2 1
16 15 14 13 12 11 10 9
恢复为一维数组:
[8, 7, 6, 5, 4, 3, 2, 1, 16, 15, 14, 13, 12, 11, 10, 9]第二步:分成4列排序(步长=4)
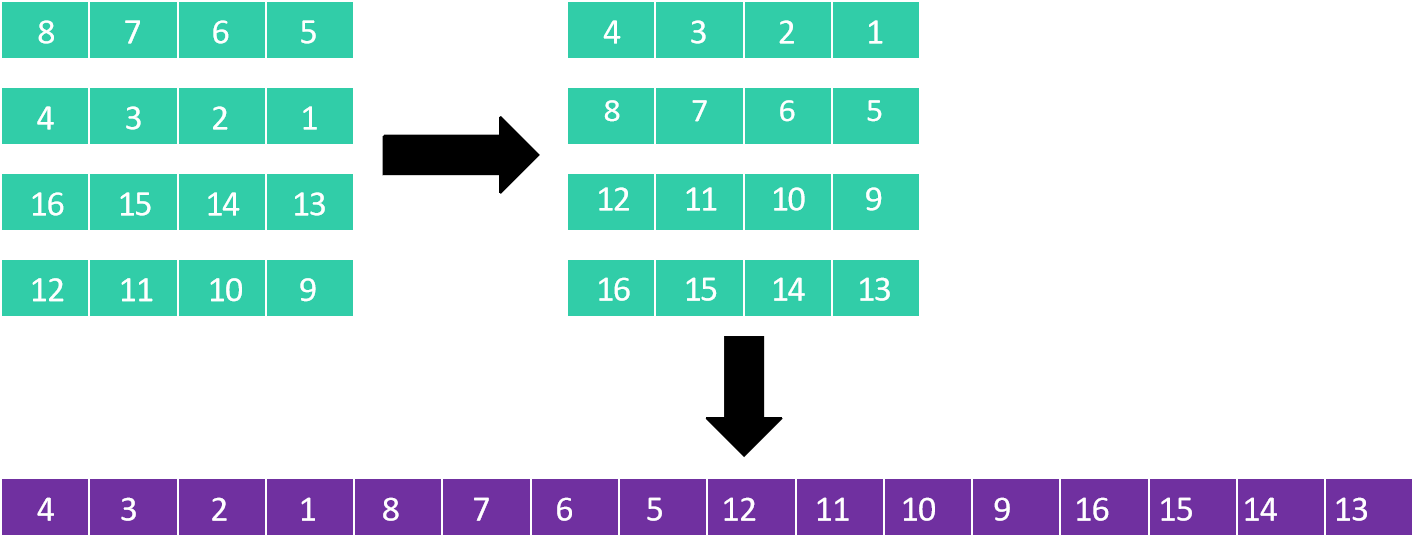
将上一步结果看作4列4行的矩阵:
8 7 6 5
4 3 2 1
16 15 14 13
12 11 10 9
每列排序后:
4 3 2 1
8 7 6 5
12 11 10 9
16 15 14 13
恢复为一维数组:
[4, 3, 2, 1, 8, 7, 6, 5, 12, 11, 10, 9, 16, 15, 14, 13]第三步:分成2列排序(步长=2)
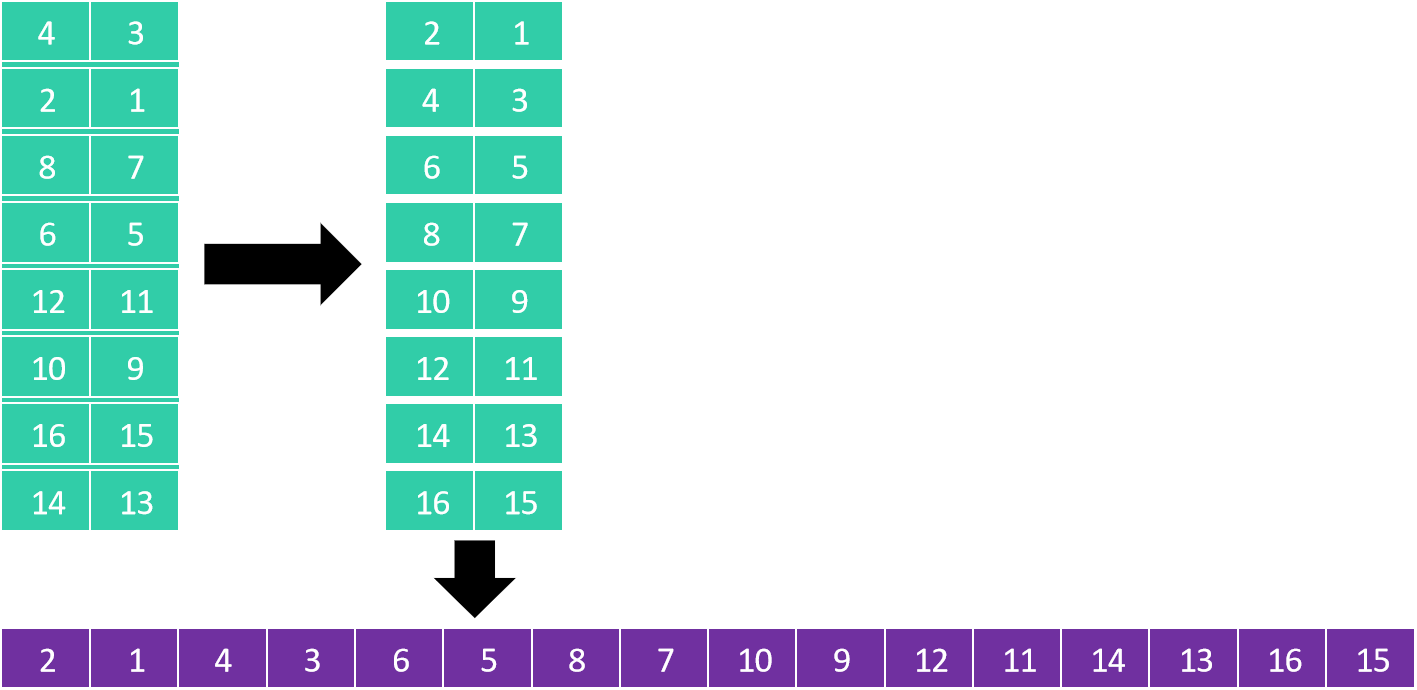
看作2列8行的矩阵:
4 3
2 1
8 7
6 5
12 11
10 9
16 15
14 13
每列排序后:
2 1
4 3
6 5
8 7
10 9
12 11
14 13
16 15
恢复为一维数组:
[2, 1, 4, 3, 6, 5, 8, 7, 10, 9, 12, 11, 14, 13, 16, 15]第四步:分成1列排序(步长=1)
此时数组已基本有序,逆序对极少:
[2, 1, 4, 3, 6, 5, 8, 7, 10, 9, 12, 11, 14, 13, 16, 15]
使用插入排序(此时效率极高):
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]3.4 关键观察
从8列 → 4列 → 2列 → 1列 的过程中:
- 逆序对的数量在逐渐减少
- 当步长为1时,数组已经"几乎有序"
- 此时插入排序的效率特别高(时间复杂度接近 O(n))结论: 希尔排序底层一般使用 插入排序 对每一列进行排序,因此很多资料认为希尔排序是 插入排序的改进版。
3.5 代码实现
java
public class ShellSort {
public void sort(int[] array) {
// 使用希尔步长序列: n/2, n/4, n/8, ..., 1
List<Integer> stepSequence = shellStepSequence(array.length);
// 按步长序列依次排序
for (Integer step : stepSequence) {
sort(array, step);
}
}
/**
* 希尔步长序列:n/2^k
*/
private List<Integer> shellStepSequence(int length) {
List<Integer> stepSequence = new ArrayList<>();
int step = length;
while ((step >>= 1) > 0) {
stepSequence.add(step);
}
return stepSequence;
}
/**
* 按指定步长进行列排序(本质是插入排序)
*/
private void sort(int[] array, int step) {
// 对每一列进行插入排序
// col: 列号,从0到step-1
for (int col = 0; col < step; col++) {
// 对第col列进行插入排序
// 第col列的元素索引: col, col+step, col+2*step, ...
for (int begin = col + step; begin < array.length; begin += step) {
int cur = begin;
int v = array[cur]; // 备份待插入元素
// 在已排序的列中寻找插入位置
while (cur > col && v < array[cur - step]) {
array[cur] = array[cur - step]; // 元素后移
cur -= step;
}
array[cur] = v; // 插入到正确位置
}
}
}
}3.6 步长序列优化
| 步长序列 | 提出者 | 最坏时间复杂度 |
|---|---|---|
| n/2^k(希尔原始) | Donald Shell | O(n²) |
| 1, 5, 19, 41, 109, ... | Robert Sedgewick (1986) | O(n^(4/3)) ⭐ 目前最优 |
Sedgewick步长序列公式:
9 * 4^i - 9 * 2^i + 1或4^i - 3 * 2^i + 1
3.7 复杂度分析
| 指标 | 结果 |
|---|---|
| 最好时间复杂度 | O(n) --- 步长序列只有1,且序列几乎有序 |
| 最坏时间复杂度 | O(n²) --- 使用希尔原始步长 |
| 最优步长时间复杂度 | O(n^(4/3)) --- 使用Sedgewick步长 |
| 空间复杂度 | O(1) --- 原地排序 |
| 稳定性 | ❌ 不稳定排序 |
四、三种排序算法对比总结
| 特性 | 归并排序 | 快速排序 | 希尔排序 |
|---|---|---|---|
| 提出时间 | 1945年 | 1960年 | 1959年 |
| 提出者 | 冯·诺伊曼 | C. A. R. Hoare | Donald Shell |
| 核心思想 | 分治:先分割再合并 | 分治:找轴点分割 | 分组插入:递减增量 |
| 最好时间 | O(n log n) | O(n log n) | O(n) |
| 平均时间 | O(n log n) | O(n log n) | O(n log n) ~ O(n^(4/3)) |
| 最坏时间 | O(n log n) | O(n²) | O(n²) |
| 空间复杂度 | O(n) | O(log n) | O(1) |
| 稳定性 | ✅ 稳定 | ❌ 不稳定 | ❌ 不稳定 |
| 适用场景 | 需要稳定排序、链表排序 | 通用场景,平均性能最好 | 空间受限、中小规模数据 |
五、关键知识点回顾
5.1 归并排序要点
- 稳定性保证 :合并时当
array[rb] >= leftArray[lb]时先拷贝左边,相等时保持原有顺序 - 空间优化:辅助数组只需原数组的一半大小,备份左边部分即可
- 递归终止条件 :
end - begin < 2时返回
5.2 快速排序要点
- 轴点选择:随机选择可避免最坏情况,常用"三数取中"法
- 相等元素处理 :比较必须用 严格小于
<,保证相等元素均匀分布 - 原地排序:通过双向扫描和覆盖实现,无需额外数组
5.3 希尔排序要点
- 步长序列是关键:好的步长序列能将最坏复杂度降到 O(n^(4/3))
- 底层是插入排序:利用插入排序在"几乎有序"时 O(n) 的特性
- 矩阵视角 :理解
索引 = col + row * step的计算方式