论文阅读 | Morrigan: A Composite Instruction TLB Prefetcher
论文信息
- 标题:Morrigan: A Composite Instruction TLB Prefetcher
- 作者:Georgios Vavouliotis, Lluc Alvarez, Boris Grot, Daniel A. Jiménez, Marc Casas
- 机构:Barcelona Supercomputing Center / UPC / University of Edinburgh / Texas A&M University
- 发表:MICRO 2021(第 54 届 IEEE/ACM 微体系结构国际会议)
- 论文页码:1138--1153
1. 背景与动机
从"数据 TLB"到"指令 TLB"
长期以来,TLB(Translation Lookaside Buffer)相关的研究几乎都聚焦于数据访问:桌面和 HPC 应用的 STLB(Second-Level TLB)未命中绝大多数来自数据,指令的代码足迹历来较小,很难成为性能瓶颈。
但时代变了。现代数据中心和服务器应用 具有海量的指令代码足迹------深层软件栈、微服务架构、庞大的二进制文件------它们让指令 TLB 的压力急剧上升。来自 Google 和 Facebook 的工业研究已经陆续指出:指令 STLB 未命中(iSTLB miss)正在成为服务器应用的关键瓶颈。Google 的工作负载中,前端停顿占流水线槽位的 15-30%,而 Facebook 的工作负载前端停顿主要由 iSTLB miss 引起。同时,指令足迹以每年 20-30% 的速度增长,远超指令 Cache 和 TLB 容量的增长速度。
iSTLB 为何比 dSTLB 更致命?
在共享的 STLB 中,指令和数据 PTE 相互争抢空间,但两者产生的后果截然不同:
- dSTLB miss:数据访问可以被乱序执行部分掩盖------独立的指令可以继续推进,MLP(Memory-Level Parallelism)和 ILP 能够吸收大部分延迟。
- iSTLB miss :指令取指位于流水线的关键路径 上,一旦发生 miss,处理器将陷入无法掩盖的停顿。
因此,即使 iSTLB miss 的比例不算压倒性(作者的测量显示 QMM 工作负载中 iSTLB miss 占总 STLB miss 的 41.6%),其性能影响却远超 dSTLB miss。测量显示,QMM 工作负载花费了 6.6%-11.7% 的执行周期处理 iSTLB 访问,远超 Intel VTune 定义的 5% 瓶颈阈值。
现有方案为何不够?
作者系统性地检查了三类现有方案,结论都是"不够用":
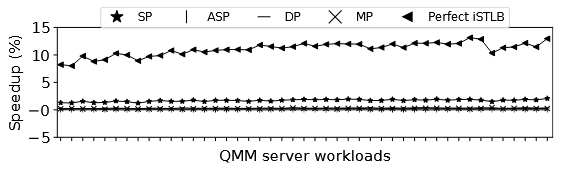
① 现有 dSTLB 预取器无效 :将 SP、ASP、DP、MP 等数据 TLB 预取器直接搬到 iSTLB miss 流上,性能提升非常有限------最好的 SP 也只有 1.6% 的加速,而 Perfect iSTLB 的上限是 11.1%。原因是这些预取器使用的特征(PC、距离等)与 iSTLB miss 相关性差,预测表冲突率高达 93-96%。
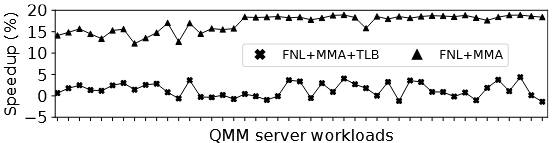
② 指令 Cache 预取器也不行 :IPC-1 的 FNL+MMA 在考虑地址翻译代价后,性能增益骤降。I-Cache 预取器针对的是短距离预取(目标块通常在 L2/LLC),而 iSTLB miss 需要的是长延迟的页表遍历,时效性(timeliness)完全对不上。
③ 大页方案不是万全之策:为代码使用大页存在诸多问题------性能病态、内存碎片化要求、破坏 ASLR 安全保护、iTLB multihit 漏洞等。Microsoft Azure 和 AWS 因此都强制将可执行页映射为 4KB 页。
这些观察共同指出了一个空白:需要一个专门针对 iSTLB miss 设计的硬件预取器。Morrigan(爱尔兰神话中司掌命运的女神)由此而生。
2. 核心洞察:三个关键发现
在提出设计之前,作者对 45 个 Qualcomm 工业服务器工作负载进行了详尽的 iSTLB 行为分析,得出三个关键 Finding:

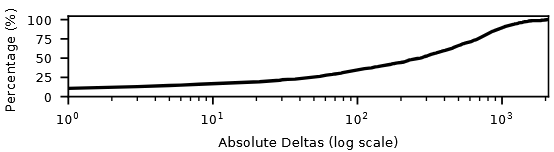
Finding 1:空间局部性有限,集中在小范围 delta
对连续两次 iSTLB miss 之间的页面距离(delta)分布分析显示:小 delta(1-10)占总数的 19%,但整体分布很宽泛,说明 iSTLB miss 具有有限的空间局部性,且主要集中在触发 miss 附近的小区域。
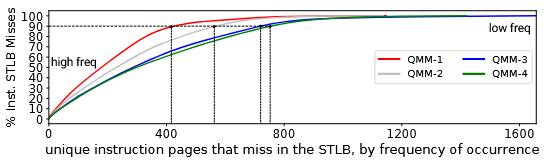
Finding 2:iSTLB miss 分布高度倾斜
少数页面贡献了绝大多数 miss 。具体而言,400-800 个指令页面造成了 90% 的 iSTLB miss (跨所有 QMM 工作负载)。这意味着一个容量适中的预取器就有希望覆盖大部分 miss,前提是它能准确识别并保留这些高频 miss 页面。
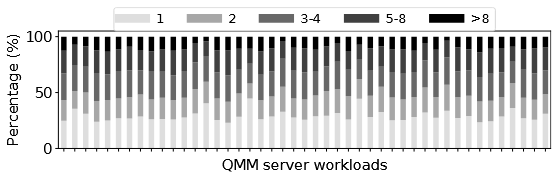
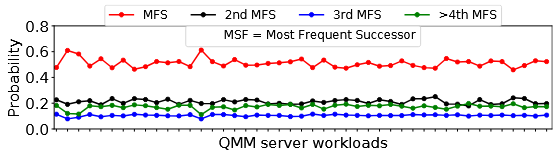
Finding 3:后继页面数少且概率集中
定义"后继页"(successor page)为 iSTLB miss 流中紧跟某页之后出现的页。分析显示:
- 相当一部分指令页面只有 1 个或 2 个后继;
- 对于 miss 最频繁的前 50 个指令页面,最频繁后继(MFS)出现概率为 51%,第二频繁后继为 21%,第三频繁为 11%;
- 这意味着:对高频 miss 页面,用少量"概率最高的后继"就能捕获绝大多数后续 miss。
Finding 4(针对 MP 的额外分析):LRU 是罪魁祸首
作者进一步对朴素 Markov 预取器 MP 做压力测试,发现:
- 128 项预测表 + LRU 替换:只有 0.2% 加速;
- 无限大预测表 + 2 后继:7.9% 加速;
- 无限大预测表 + 任意后继:10.3% 加速(接近理想的 11.1%)。
结论:MP 的潜力被两个因素压制------预测表容量和 LRU 策略 。LRU 会轻易驱逐那些 miss 频繁但短期内未被访问的"关键"页面,而这些页面恰好是我们最需要保留的。访问频率(frequency)比最近访问时间(recency)更能反映 iSTLB miss 的价值。
3. Morrigan 总体设计
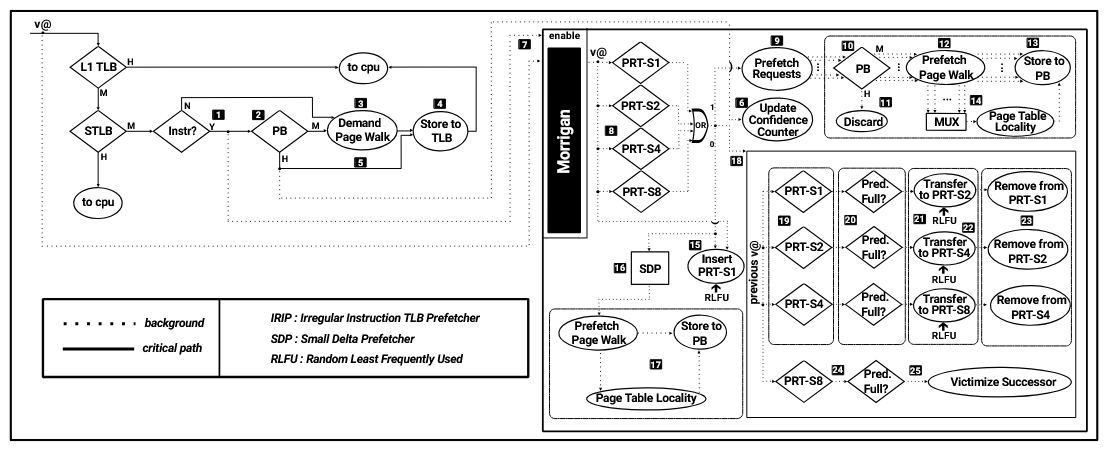
基于上述发现,Morrigan 被设计为一个复合(composite)预取器,由两个互补模块组成:
| 模块 | 角色 | 触发条件 |
|---|---|---|
| IRIP(Irregular Instruction TLB Prefetcher) | 不规则模式捕获,Markov 链预取 | 预测表命中时 |
| SDP(Small Delta Prefetcher) | 兜底,顺序 + 页表局部性预取 | IRIP 未命中时 |
两个模块都利用了页表局部性(同一 Cache Line 中连续的 8 个 PTE 被一并加载)来实现"零额外成本"的扩展预取,这与作者在 ISCA 2021 的 SBFP 工作思路一脉相承。
Morrigan 是完全 legacy-preserving 的------不修改虚拟内存子系统、不修改 OS、不修改页表结构,纯粹是一个微架构增强。
4. IRIP 模块:可变长度 Markov 链预取
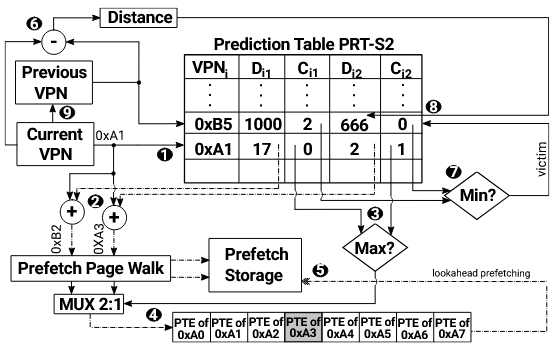
四表集成设计
IRIP 的核心创新是四个预测表的集成(PRT-S1、PRT-S2、PRT-S4、PRT-S8),每个表对应不同数量的预测槽:
| 预测表 | 每项预测槽数 | 针对的指令页面类型 |
|---|---|---|
| PRT-S1 | 1 | 只有 1 个后继的页面 |
| PRT-S2 | 2 | 有 2 个后继的页面 |
| PRT-S4 | 4 | 有 3-4 个后继的页面 |
| PRT-S8 | 8 | 有 5-8 个后继的页面 |
这种设计直接对应 Finding 3:不同页面的后继数量差异显著,固定槽数(如传统 MP 的 2 个槽)要么浪费存储、要么丢失预测。IRIP 通过动态迁移机制,让每个页面根据其实际后继数"落户"到最合适的表中。
存储优化:用 distance 替代完整 VPN
朴素设计会在每个预测槽中存储完整的虚拟页号(VPN,36 bits),代价昂贵。IRIP 改为存储距离(distance)------当前 miss 页和前一个 miss 页之间的有符号差。使用时将 distance 与当前 miss 页相加即可恢复预测地址。每个 distance 只需 15 bits,显著降低存储开销。
每个预测表项包含:
- 16 bits 部分 tag(用于索引)
s个预测槽,每槽 15 bits distances个 2-bit 置信度计数器
工作流程(以 PRT-S2 为例)
假设当前虚拟页 0xA1 发生 iSTLB miss:
- 查表:在 PRT-S2 中查找 0xA1;
- 生成预取:若命中,取出所有预测 distance(如 17 和 2),分别与 0xA1 相加,生成对 0xB2 和 0xA3 的预取请求;
- 选出最高置信度:假设 distance=2 置信度最高;
- 页表局部性扩展 :在 0xA3 的预取 page walk 完成时,顺便将同一 Cache Line 中的邻居 PTE(0xA0-0xA7 中的另外 7 个)也放入 PB------仅对置信度最高的那个预取执行此操作,避免污染;
- 更新表项:计算当前 miss 页(0xA1)与前一 miss 页(0xB5)的 distance,插入到前一 miss 页对应的表项中;
- 替换决策:若 PRT-S2 的某项预测槽已满,按置信度最低的槽替换(仅 PRT-S8 这样做,其他表是向上迁移)。
关键点:跨表迁移
这是 IRIP 与传统 MP 的本质区别。当 PRT-S1 中某项的槽已满(意味着该页发现了第 2 个后继),整个表项不会被原地替换 ,而是被迁移到 PRT-S2。同理 S2→S4,S4→S8。这种设计实现了:
- 存储按需分配:简单页面只占 S1 的小空间,复杂页面才升级到 S8;
- 无信息丢失:迁移过程保留所有已学习的预测槽。
只有在 PRT-S8 中,当 8 个槽全满且新 distance 要插入时,才会真正替换(选置信度最低的)。
RLFU:新的替换策略
既然 Finding 4 指出"frequency 比 recency 重要",IRIP 的替换策略也围绕频率展开。但纯 LFU 有一个致命缺陷:新插入的表项频率为 0,随时可能被驱逐,这在相位变化(phase change)时尤其糟糕------新相位的页面刚装进去就被老相位的高频页面挤走。
作者提出 RLFU(Random-Least-Frequently-Used):
- 维护一个频率栈,类似 LFU;
- 但在选择替换候选时加入随机性------给那些"刚插入但还未累积足够频率"的表项一次"第二次机会";
- 此外,Morrigan 会周期性重置频率栈,主动适应相位变化。
实验证明,RLFU 在小存储预算下显著优于 LRU、Random、LFU。例如在 3.76KB 预算下,RLFU 的 miss 覆盖率比 LFU 高 4.9%。
置信度更新
- 命中时:某预取产生 PB 命中(消除一次 demand page walk),对应预测槽的置信度 +1;
- 替换决策:PRT-S8 用置信度选受害者;页表局部性扩展选择置信度最高的预取目标。
5. SDP 模块:小 delta 兜底预取
当 IRIP 所有预测表都 miss 时(意味着当前页从未被学习过),Morrigan 没有可靠的 Markov 预测,但仍不能白白放弃预取机会。SDP(Small Delta Prefetcher) 此时登场。
SDP 的逻辑非常简单:
- 对当前 miss 页 X,预取 X+1;
- 在 X+1 的预取 page walk 完成时,利用页表局部性,将同一 Cache Line 中的其他 7 个邻居 PTE 也放入 PB。
这种设计直接对应 Finding 1 ------ iSTLB miss 的小 delta(1-10)相对频繁。SDP 用极低的成本(一次 page walk + 免费获得 7 个邻居)覆盖了这部分模式。
关键是:SDP 只在 IRIP 彻底无预测时启用,不与 IRIP 并行工作,避免浪费带宽和污染 PB。
6. Morrigan 完整操作流程
总览整个系统:
- iSTLB miss 发生 → 查 PB;
- PB 命中:从 PB 取 PTE 装入 STLB,避免 demand page walk;如果这个预取来自 IRIP,顺便给对应预测槽加置信度;
- PB 未命中:触发 demand page walk 取回 PTE;
- 并行启动 Morrigan :
- 并行查询所有四个 IRIP 预测表(由于设计保证无重复项,最多一个命中);
- 若 IRIP 命中 → 对每个有效预测槽发起预取,查 PB 去重后触发 prefetch page walk,结果存入 PB;对置信度最高者额外利用页表局部性取邻居 PTE;
- 若 IRIP 全部 miss → 将当前 miss 页插入 PRT-S1(满时用 RLFU 选受害者),并启用 SDP 产生兜底预取;
- 更新学习状态:无论 hit 还是 miss,计算当前页与前一 miss 页的 distance,插入前一页对应的表项中;若该表项槽已满,按照表位置选择迁移或替换策略。
这个设计最精妙之处在于:无论任何情况,每次 iSTLB miss 都能产生预取,而不是像 MP 那样只在预测表命中时工作。
7. 实验评估
实验设置
| 组件 | 配置 |
|---|---|
| 处理器 | 4-wide OoO,ChampSim 最新版本,扩展为真实 x86 page walker |
| L1 I-TLB | 128 项,8 路,1 cycle |
| L1 D-TLB | 64 项,4 路,1 cycle |
| L2 TLB | 1536 项,6 路,8 cycle |
| PSC | 3 级 split PSC |
| PB | 64 项,全相联 |
| 工作负载 | 45 个 Qualcomm 工业服务器工作负载(iSTLB MPKI ≥ 0.5) |
| 预热/测量 | 50M warmup + 100M 统计指令 |
工作负载筛选:SPEC 2006/2017 的 iSTLB MPKI 都低于 0.5,不构成瓶颈,未纳入评估(只在 §3 用于说明背景)。
主要性能结果
在 3.76KB 存储预算下,各方案的几何平均加速比如下:
| 方案 | 加速比 | 备注 |
|---|---|---|
| No Prefetching | 基线 | --- |
| SP | 1.6% | 仅捕获顺序模式 |
| ASP | 0.4% | PC 索引冲突严重(96.3% 冲突率) |
| DP | 0.1% | distance 索引冲突严重(93.7%) |
| MP | 0.7% | LRU 策略导致性能低下 |
| Morrigan | 7.6% | --- |
| Perfect iSTLB | 11.1% | 理论上限 |
Morrigan 达到了 Perfect iSTLB 上限的约 68% ,相比所有现有 dSTLB 预取器有数量级的性能改进。在 PB 命中的来源分布中,IRIP 模块贡献 93%,SDP 贡献 7%------IRIP 是主力,SDP 是重要的兜底。
存储预算与覆盖率权衡
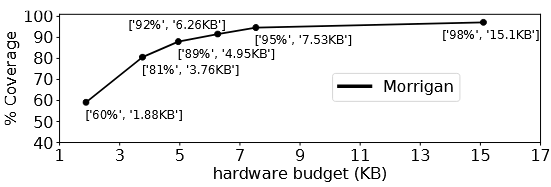
不同预算下的覆盖率:
| 预算 | 覆盖率 |
|---|---|
| 1.88KB | 60% |
| 3.76KB | 81% |
| 4.95KB | 89% |
| 7.53KB | 95% |
| 15.1KB | 98% |
5KB 以后收益迅速饱和,因此论文将 3.76KB 作为"甜点"配置(81% 覆盖率)。最终采用的物理配置为:PRT-S1/S2/S4 各 128 项 32 路,PRT-S8 为 64 项 16 路,PB 为 64 项。
替换策略对比
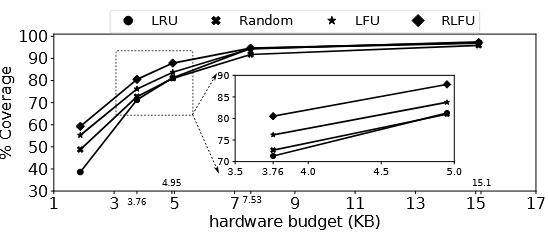
在 3.76KB 小预算下,四种替换策略的覆盖率排序为:
RLFU > LFU > Random > LRU
RLFU 比 LRU 高出约 12 个百分点覆盖率,证实了作者的核心假设:frequency 是 iSTLB 预取的关键特征。随着预算增大(>7KB),各策略差距迅速缩小------因为此时预测表容量已经能装下几乎所有高频 miss 页,替换策略变得不那么重要。
页表遍历访存开销

对内存访问引用的拆解显示:
- Morrigan 将 demand page walk 的访存减少 69%;
- 但引入 117% 额外的 prefetch page walk 访存;
- 其他 dSTLB 预取器的 demand 减少 ≤11%,prefetch 增加 ≤20%。
乍看之下 Morrigan 的"预取成本"很高,但关键在于:
- demand page walk 在关键路径上,引发流水线停顿;
- prefetch page walk 在后台执行,不阻塞流水线。
所以交换"关键路径访存"为"后台访存"是高性价比的。此外,Morrigan 的 prefetch page walk 访存中,20%/25%/45%/10% 分别由 L1/L2/LLC/DRAM 满足,大部分被 Cache 吸收。
IRIP 单表 vs 多表
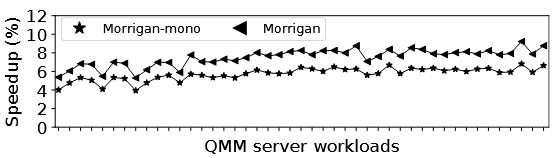
作者构造了 Morrigan-mono 作为对照------使用单个 203 项 8 槽的预测表,与 Morrigan 4 表版本等存储预算。结果:Morrigan 比 Morrigan-mono 平均快 1.9% 。原因是多表设计的实际追踪能力更强(128×3 + 64 = 448 项 vs 203 项),且按需分配槽数的方式存储利用率更高。要匹配 Morrigan 的性能,Morrigan-mono 需要 6.9KB 存储预算------约 1.83 倍。
与其他技术对比
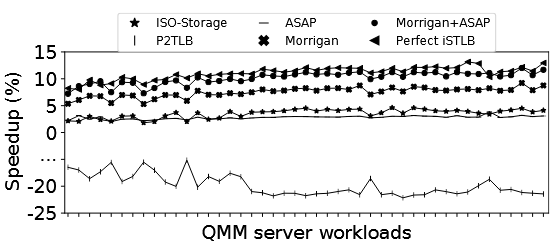
- ISO-Storage (把 Morrigan 的存储全加到 STLB 上):性能低于 Morrigan 4.1%,说明预取比单纯扩容更有效;
- P2TLB (直接预取到 STLB 而非 PB):性能反而降低 18.9%,证实了"PB 缓冲"的必要性------不准确的预取直接污染 STLB 代价太大;
- ASAP(预取更深层页表,降低 page walk 延迟):比 Morrigan 低 4.8%,因为 QMM 的 PSC 命中率高,ASAP 的优化空间有限;
- Morrigan + ASAP :两者正交,组合达到 10.1% 加速,接近理想的 11.1% 上限。
与 I-Cache 预取器的协同
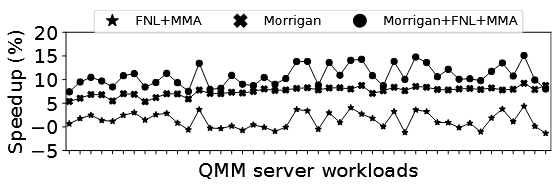
| 方案 | 加速比 |
|---|---|
| FNL+MMA(IPC-1 冠军) | 1.2% |
| Morrigan | 7.6% |
| Morrigan + FNL+MMA | 10.9% |
组合的收益超过各自的加法(1.2% + 7.6% = 8.8% < 10.9%),即1+1 > 2 。原因是 Morrigan 提高了 FNL+MMA 跨页边界预取的时效性------51.7% 的 FNL+MMA 跨页预取命中了 Morrigan 的 PB,避免了原本需要的 page walk 延迟。
SMT 共置场景
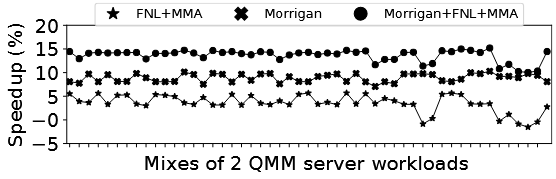
在双线程 SMT 核心上共置两个 QMM 工作负载(IRIP 表容量加倍至 7.5KB):
| 方案 | 加速比 |
|---|---|
| FNL+MMA | 3.4% |
| Morrigan | 8.9% |
| Morrigan + FNL+MMA | 13.7% |
SMT 共置下加速比普遍更高,因为 TLB 压力更大,预取空间更多。即使不加倍 IRIP 容量,Morrigan 仍能取得 6.4% 加速。
8. 关键创新点总结
Morrigan 的贡献可以归纳为三个层次:
① 首次系统性刻画 iSTLB miss
论文是第一个专门针对指令 TLB 预取的工作,明确揭示了 iSTLB miss 的三个核心特性(skewed distribution、少量后继、frequency 主导),并证伪了"dSTLB 预取器可直接迁移"的假设。
② 复合预取器设计哲学
Morrigan 的"IRIP + SDP" 两模块 + "四预测表集成" 的复合结构,体现了用结构多样性应对模式多样性的设计思路:
- 不同后继数的页面用不同表容纳;
- 不同置信度的预取享受不同的扩展策略(是否应用页表局部性);
- 不同执行阶段(有无可预测模式)由不同模块兜底。
③ RLFU:Frequency + Randomness 的折中
RLFU 是一个看似简单但效果显著的创新:用随机性为新插入条目提供缓冲,解决了纯 LFU 在相位变化时的病态。这个思想对其他需要频率驱动的硬件结构(分支预测、Cache 替换等)也有参考价值。
此外,Morrigan 还利用了页表局部性(与其 ISCA 2021 SBFP 工作呼应),实现了零额外成本的空间扩展预取。
9. 个人思考
值得借鉴的设计方法论
深度刻画驱动设计:Morrigan 的每一个设计决策都能追溯到某个 Finding------PRT-S1/S2/S4/S8 对应 Finding 3 的后继数分布,RLFU 对应 Finding 2+4 的 frequency 主导,SDP 对应 Finding 1 的小 delta 局部性。这种"先度量、后设计"的方法论是扎实工程的基础。
复合结构而非单点优化:与该团队的 ISCA 2021 ATP 工作一样,Morrigan 再次选择了"复合预取器 + 场景化模块"的路线。这种思路承认"单一机制无法覆盖所有场景"的现实,用工程上的组合性来获得鲁棒性。
"拒绝的艺术" :P2TLB 实验(直接预取到 STLB 反而降速 18.9%)提醒我们,不加筛选的激进预取是危险的。PB 缓冲、置信度选择、只对最高置信度应用页表局部性------都是"拒绝不好预取"的机制。
局限性与可能的未来方向
① 大页场景的适配:论文专门解释了为什么不用大页(性能病态、ASLR 风险、iTLB multihit),但现实中大页仍是很多系统的默认选择。Morrigan 虽声称兼容多页尺寸,但未给出详细评估。大页下 iSTLB miss 的分布可能大不相同(少量巨页覆盖大范围代码),需要重新设计。
② 虚拟化场景:在嵌套虚拟化环境中,一次 TLB miss 可能触发 24 次内存引用(radix-4 guest-to-host 翻译)。Morrigan 的思路能否推广到 nested page walk 是一个自然的方向。
③ 与 Cache 预取器更紧密的整合 :论文已经证明 Morrigan 与 FNL+MMA 协同良好,但两者仍是独立工作的。如果能共享控制流信号(例如 I-Cache 预取器提供未来控制流预测,Morrigan 基于此做更精准的 iSTLB 预取),可能还有进一步收益。
④ 安全性考虑:IRIP 的预测表从 iSTLB miss 流中学习指令访问模式,本质上是记录了程序的控制流指纹。这是否可能被侧信道攻击利用(如通过监测 PB hit 模式推断其他进程的代码执行路径)是值得研究的问题。
⑤ RISC-V / ARM 架构的验证:论文声称适用于其他架构,但评估全部在 x86-64 上。RISC-V Sv39/Sv48 的页表结构相似但 MMU-Cache/PSC 设计不同,实际效果如何需要验证。
对 TLB 研究趋势的启示
这篇论文与同团队的 ATP (ISCA'21) 共同标志着 TLB 预取研究的一次范式转变:
- 从"单一机制"到"复合结构";
- 从"针对通用负载"到"针对服务器工作负载";
- 从"只关注数据翻译"到"指令翻译也要重视";
- 从"追求高覆盖"到"平衡覆盖与开销"。
后续工作如 Protean (MEMSYS'23) 等也延续了"高效指令预取"的思路。对做体系结构、虚拟内存、服务器系统优化的研究者,Morrigan 提供了方法论和具体工程细节双重层面的参考。
10. 总结
《Morrigan: A Composite Instruction TLB Prefetcher》是一篇问题定位准确、分析扎实、设计精巧的论文。它从一个被长期忽视的瓶颈(iSTLB miss)出发,系统性地验证了"现有方案不够用"的假设,并给出了一个工程化且性能突出的新设计。
Morrigan 的核心贡献不仅是 7.6% 的几何加速和 69% 的访存削减,更是一种针对服务器工作负载前端瓶颈的新视角。IRIP 的多表集成、RLFU 的频率+随机策略、SDP 的小 delta 兜底、以及对页表局部性的系统性利用------每一个组件都在回应具体的观察,整体又浑然一体。
对于研究地址翻译、TLB 管理、服务器系统优化的研究者和工程师,这篇论文值得仔细品读其方法论、具体设计和评估思路。
参考链接
Vavouliotis et al., "Exploiting Page Table Locality for Agile TLB Prefetching", ISCA 2021(同团队 SBFP+ATP 工作)
Kanev et al., "Profiling a Warehouse-scale Computer", ISCA 2015(Google 工作负载画像)
Nagendra et al., "AsmDB: Understanding and Mitigating Front-End Stalls in Warehouse-Scale Computers", IEEE Micro 2020