文章目录
- 前言
- 一、背景
- 二、在自然语言里,Token是什么?
- 三、为什么自然语言要这样切?
- 四、在基因组学里,Token可以是什么?
- 五、在蛋白质组学里,Token可以是什么?
- 六、在图片处理中,Token又是什么?
- 七、在语音处理中,Token可以是什么?
前言
Token
Token是模型处理信息的基本单位,相当于"信息颗粒"。它不固定等于字或词,而是根据不同场景有所变化:自然语言中可以是字、词片段或标点;基因组学中表现为碱基或k-mer;蛋白质组学中是氨基酸或功能区域;图像处理中是图像小块;语音处理中则是时间帧或音素。简单说,Token就是现实信息进入模型前被切分的小块。。
一、背景
刚接触大模型时,很多人都会反复看到一个词:Token。比如:
-
这个模型支持128KToken
-
这段内容会消耗多少Token
-
输入太长,超过Token限制了
很多人第一反应是:Token不就是字吗?或者不就是词吗?其实都不完全对。更通俗一点说,Token就是模型处理信息时,先切出来的一个个小单位 。具体的小单位是什么方式,与切词方法有关,后续我们会说到这个问题。
模型不会像人一样直接看懂一整段话、一整张图或者一整条序列,它通常要先把输入拆成一块一块,再去处理。这些被拆出来的一块一块,就是Token。
你可以把Token理解成:模型读东西时的基本颗粒。注意,是基本颗粒,不是固定等于一个字,也不是固定等于一个词。
二、在自然语言里,Token是什么?
这是大家最常见的场景。比如这句话:
text
今天天气很好。在我们人眼里,这是一句完整的话。但在模型那里,它不会直接把整句话当一个整体处理,而是会先切开。可能会切成:
text
今天
天气
很好
。也可能切成:
text
今
天
天气
很
好
。不同模型,切法可能不一样。所以你会发现:
Token不等于字。因为今天可能是1个Token,也可能是2个。很好也可能被当成一个整体。再看英文:
text
Large Language Model is useful.有的模型可能切成:
text
Large
Language
Model
is
useful
.也有的模型可能切成:
text
Large Language Model
is
use
ful
.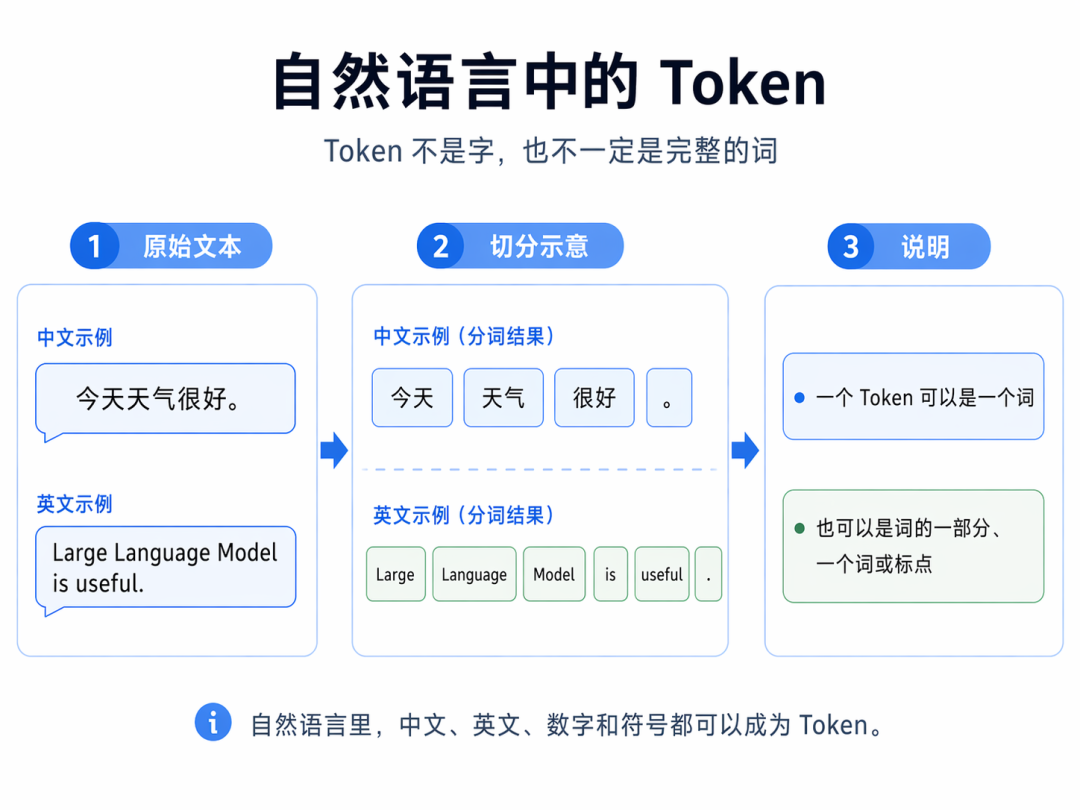
所以,Token也不等于单词。因为一个英文单词,有时是1个Token,有时会被拆成几段。
三、为什么自然语言要这样切?
因为模型本质上是在做计算。它不能直接看懂句子,而是要先把文本拆成适合计算的单位,再把这些单位转成数字、向量,最后送进模型。所以在自然语言里,Token可以是:
-
一个字
-
一个词的一部分
-
一个完整的词
-
一个短语
-
一个标点符号
-
一个数字
-
一个特殊符号
比如:
text
2026年,AI很火!可能会切成:
text
2026
年
,
AI
很
火
!你会发现,连标点符号都可能单独算Token。在不同研究领域中,Token的定义和形式往往并不相同。比如在基因组学中,Token可以是碱基或k-mer;在蛋白组学中,Token可以是氨基酸或序列片段;在图像任务中,Token则常常对应一块图像区域。
四、在基因组学里,Token可以是什么?
基因组学里,最基本的序列通常是DNA序列,比如:
text
ATCGGCTA如果把这个序列交给模型处理,也需要先切分成Token。
- 最简单的切法:单个碱基做Token。
比如:
text
A
T
C
G
G
C
T
A这时候,每个碱基都是一个Token。这是最直观的做法,因为DNA的基本字母本来就只有4个,字母N通常不参与模型训练:
text
A
T
C
G- 另一种切法:k-mer做Token。
比如把连续3个碱基当成一个单位,也就是常说的3-mer。对于:
text
ATCGGCTA可以切成:
text
ATC
TCG
CGG
GGC
GCT
CTA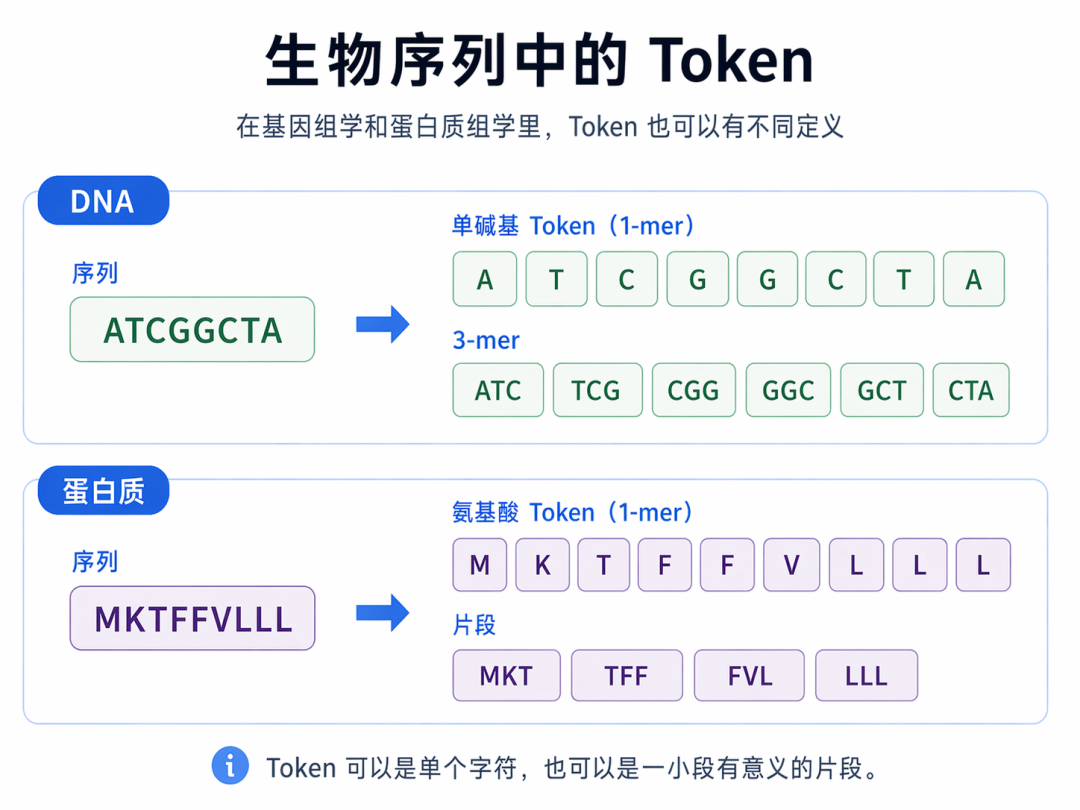
这时候,一个Token就不再是单个字母,而是一小段局部模式。这样做的好处是,模型不只看到单个碱基,还能更容易捕捉局部序列特征。在更复杂的建模里,Token甚至可以不是简单的字母串,而是:
-
启动子区域
-
外显子
-
内含子
-
某类 motif
-
某段调控元件
也就是说,在基因组学里,Token可以有不同层级:
-
最细:单个碱基
-
中间:k-mer
-
更高层:有生物学意义的功能片段
五、在蛋白质组学里,Token可以是什么?
蛋白质序列和自然语言也有点像。因为蛋白质本质上也是一串序列,只不过"字母"不是汉字或英文,而是氨基酸。比如一段蛋白序列:
text
MKTFFVLLL这里每个字母都代表一个氨基酸。最常见的切法:单个氨基酸做Token
比如:
text
M
K
T
F
F
V
L
L
L这时候,一个氨基酸就是一个Token。也可以用片段做Token,比如把连续几个氨基酸组成一个片段:
text
MKT
TFF
FVL
LLL或者用滑动窗口形成更细的片段。还可以用结构或功能单元做Token,如果模型更复杂,Token也可能不是简单序列,而是更高层的蛋白质单元,例如:
-
某个motif
-
某个二级结构片段
-
某个功能域片段
所以在蛋白质组学里,Token也不一定固定。它可以是:
-
单个氨基酸
-
若干氨基酸片段
-
结构单元
-
功能区域
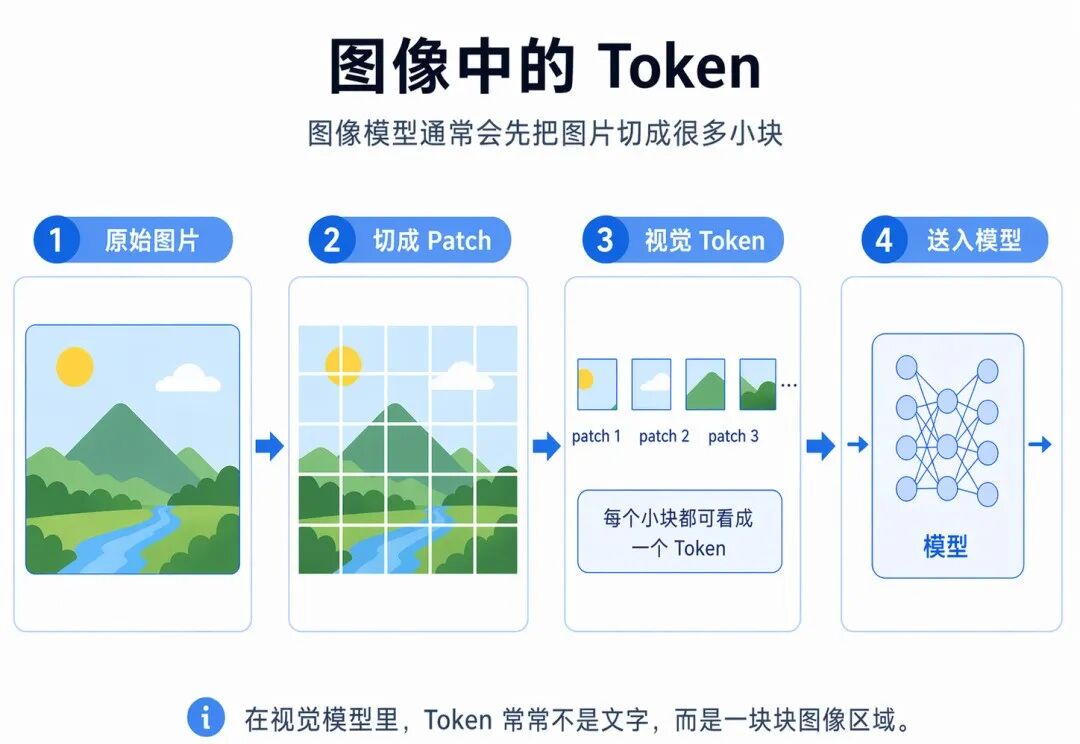
六、在图片处理中,Token又是什么?
很多人一听Token,会以为这只是文字里的概念。其实图像模型里也有Token。因为模型处理图片时,也不会像人一样直接看整张图 。它通常也会先拆。最常见的做法:把图片切成小块,比如一张图片大小是224×224。模型可以把它切成很多个16×16的小方块。这样整张图就变成一堆小块:
-
第1块
-
第2块
-
第3块
-
......
每一个小块,就可以看成一个Token。这就是视觉Transformer里很常见的思路。举个例子:你有一张猫的图片。在人眼里,这是一只猫。但模型不会先有猫这个概念,它会先看到:
-
左上角一块颜色纹理
-
中间一块耳朵区域
-
下方一块身体区域
-
背景的一块地板区域
这些图像块经过编码后,就变成视觉Token。所以在图片处理中,Token常常是:
-
一小块图像patch
-
或者某种压缩后的视觉特征块
七、在语音处理中,Token可以是什么?
语音也是一样。比如一句话的语音波形,对人来说是连续的声音;但模型一般不会直接整段吞下去。它可能先切成:
-
很短的时间帧
-
声学特征片段
-
音素
-
子词单元
举个简单例子:一句你好,在人耳里就是两个字。但对语音模型来说,可能先变成一串短时间片段的声学特征,再进一步映射成语音Token。所以在语音场景下,Token可以是:
-
时间帧
-
音素
-
离散语音单元
-
压缩后的声学编码片段
模型需要把复杂输入,变成一串可以计算的基本单位。Token就是这个桥梁。你可以把它理解成:现实世界的信息,进入模型之前,先被切成一个个可处理的小块。这些小块就是Token。把模型想成一个流水线工厂。
-
一整篇文章进来,太大了,不方便加工
-
一整张图片进来,也太大了,不方便加工
-
一整条基因序列进来,同样太长了
所以工厂第一步不是直接生产,而是先分拣、切块 。切成适合机器处理的一小块一小块之后,再进入后面的加工流程。这些小块,就是Token。Token这个词听起来很技术,但本质并不复杂。你只要记住下面这几句就够了:
1. Token是模型处理信息时的基本单位。
2. 它不等于字,也不等于词,而是模型自己的切分颗粒。
3. 不同场景下,Token可以完全不同。
比如:
-
在自然语言里,Token可以是字、词的一部分、词、标点
-
在基因组学里,Token可以是碱基、k-mer、功能片段
-
在蛋白质组学里,Token可以是氨基酸、序列片段、结构单元
-
在图片处理中,Token可以是一块块图像patch
-
在语音处理中,Token可以是时间帧、音素或语音单元
本文的引用仅限自我学习如有侵权,请联系作者删除。
参考知识
什么是Token?一篇讲清楚