深层神经网络
在掌握了单层神经网络(线性回归、逻辑回归、Softmax 回归)之后,我们正式跨入"深度"学习的领域。从单层到多层是神经网络发展史上的质变,增加的"隐藏层"彻底将神经网络的性能提升到了另一个高度。
一. 异或门问题
1. 单层网络的致命局限
在机器学习的底层表示中,这里的
x0列全为 1,通常是为偏置项(Bias)预留的"占位符"(即偏置乘以 1 仍然等于偏置本身)。与门数据(andgate): 与门是一组只有两个特征(x1, x2)的分类数据,当两个特征下的取值都为1时,分类标签为1,其他时候分类标签为0。
x0 x1 x2 y_and 1 0 0 0 1 1 0 0 1 0 1 0 1 1 1 1
或门数据(orgate):或门是一组只有两个特征(x1, x2)的分类数据,只要两个特征中至少有一个为 1(或者都为 1),分类标签就为 1;只有当两个特征都为 0 时,分类标签才为 0。
x0 x1 x2 y_or 1 0 0 0 1 1 0 1 1 0 1 1 1 1 1 1
非与门/与非门数据(nandgate):非与门(通常在工程中被称为"与非门")本质上是与门(AND)的完全反向操作。当且仅当两个特征都为 1 时,分类标签才为 0;在其他所有情况下,分类标签都为 1。
x0 x1 x2 y_nand 1 0 0 1 1 1 0 1 1 0 1 1 1 1 1 0
异或门数据(xorgate):异或门是一组只有两个特征(x1, x2)的分类数据,当且仅当两个特征下的取值不相同时(即一个为 1,一个为 0),分类标签为 1;当两个特征取值相同时(同为 0 或同为 1),分类标签为 0。
x0 x1 x2 y_xor 1 0 0 0 1 1 0 1 1 0 1 1 1 1 1 0
在机器学习的底层逻辑中,存在着一个极其重要的物理特性分水岭:线性可分性。
-
与门 (AND)、或门 (OR) 和 非与门 (NAND) :它们的数据是线性可分 的。这意味着,只要你设置好合适的权重 w w w 和偏置 b b b,就能在二维平面上画出一条直线,完美地把它们对应的标签 0 和 1 劈开。因此,最基础的单层感知机(即单层
nn.Linear)能够完美解决这三个逻辑门。 -
异或门 (XOR) :它的数据是线性不可分 的。作为四大基础逻辑门中唯一的例外,无论你怎么调整单层神经网络的权重 w w w 和偏置 b b b,你都绝对不可能在二维平面上画出"一条直线"将它的四个点正确分类。
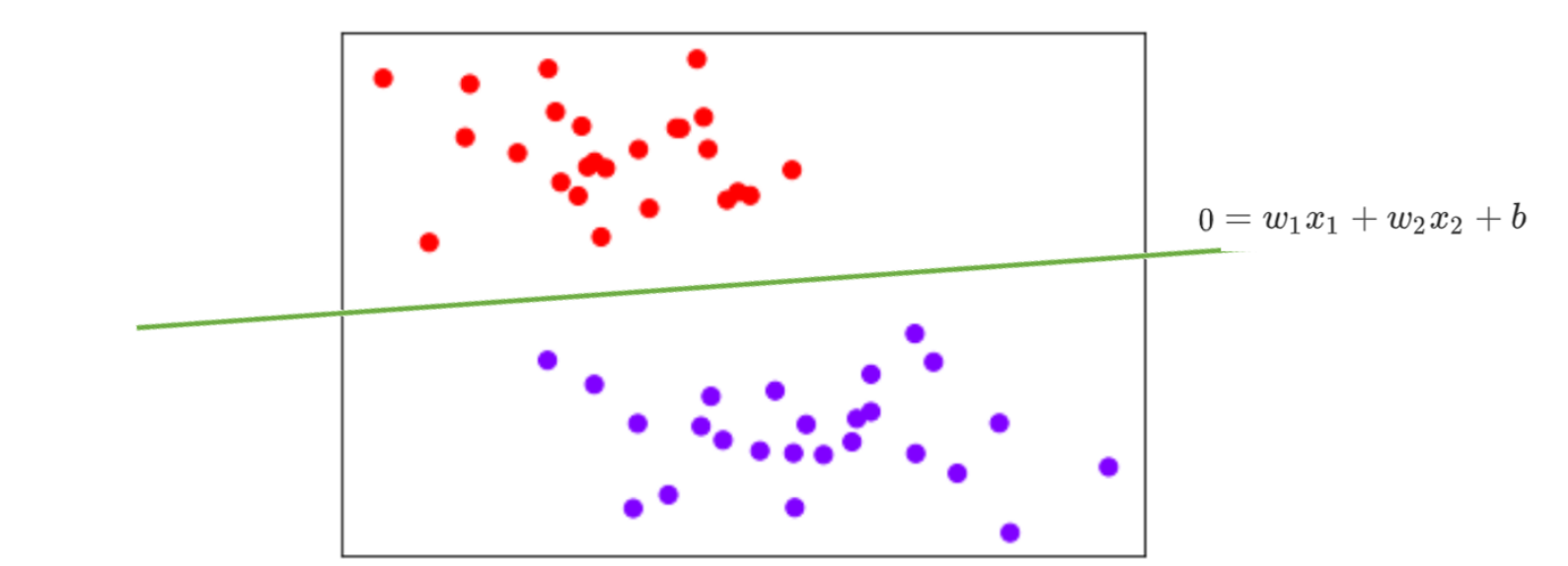
结论:单层神经网络无法解决非线性可分问题。这也是导致第一次人工智能寒冬的根本原因。
2. 非线性可分解法:引入隐藏层
(1).隐藏层
从结构上来看,多层神经网络比单层神经网络多出了"中间层"。中间层常常被称为隐藏层(hidden layer),理论上来说可以有无限层,所以在图像表示中经常被省略。
为了解决非线性问题,我们需要在输入层和输出层之间加入隐藏层 (Hidden Layer)。
物理意义:隐藏层对原始特征空间进行了扭曲和升维转换。它将原本在低维空间线性不可分的数据,映射到一个新的高维空间中,使其在新空间里变得线性可分。
(2).编号规范
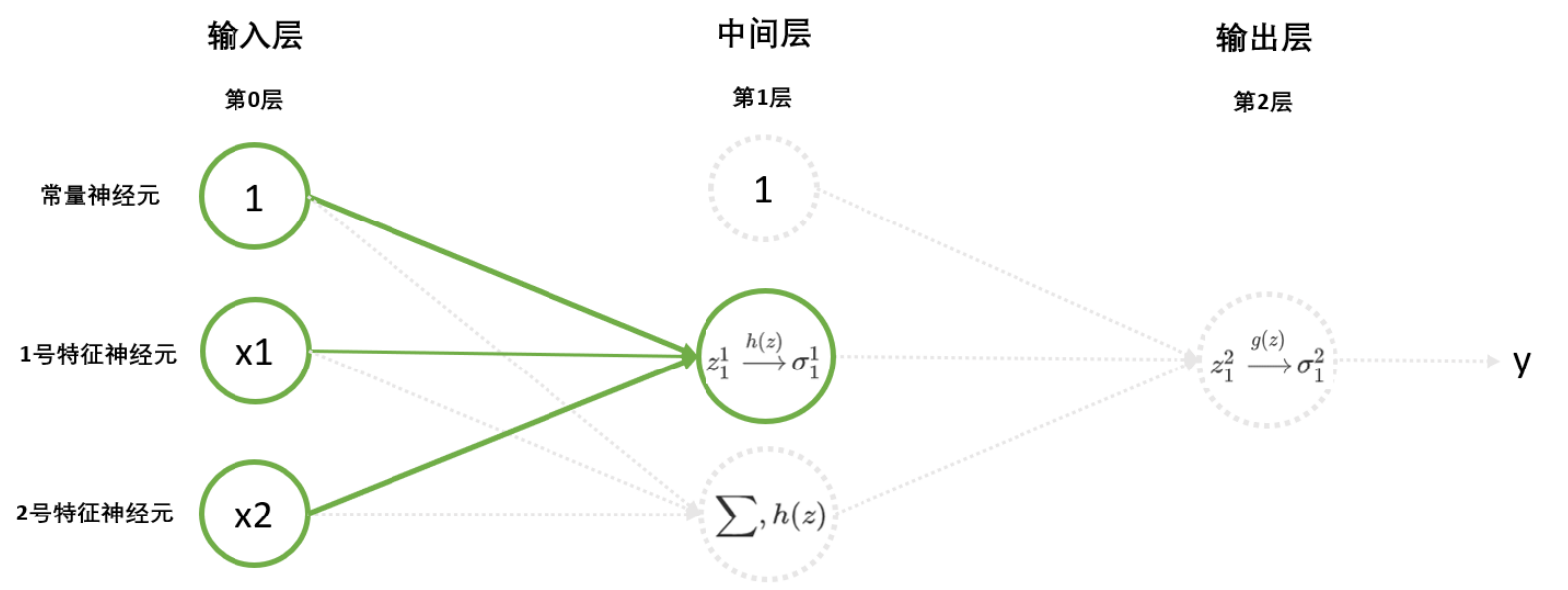
- 层从左向右:上层到下层
- 神经元分为两类:
- 常量的:常量神经元(每层只有一个不管几号)
- 带有特征的:特征神经元xx号
- z z z是加和的结果, σ \sigma σ是加和之后激活函数的结果
- z z z和 σ \sigma σ是在神经元上面的, w w w和 b b b是在神经元的连线之间的。
- H z Hz Hz:激活函数在中间层叫 H z Hz Hz
- G z Gz Gz:激活函数在输出层 G z Gz Gz
除了神经元和网络层,权重、偏差WWW、神经元上的取值也存在编号。这些编号规律分别如下:
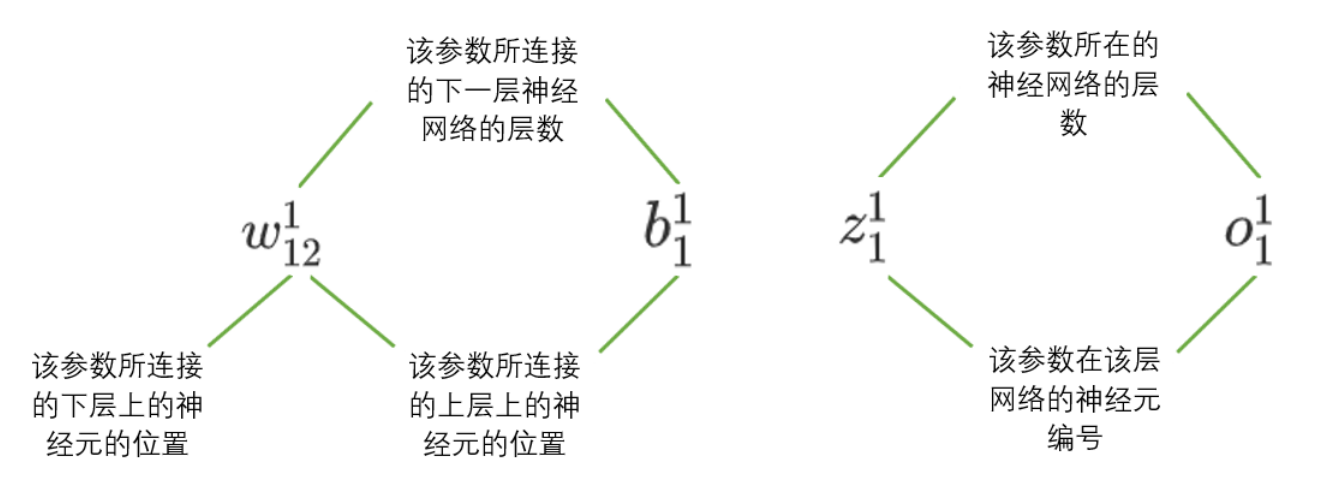
这些编号实在很复杂,因此在本系列中,我将编号改写为如下情况:
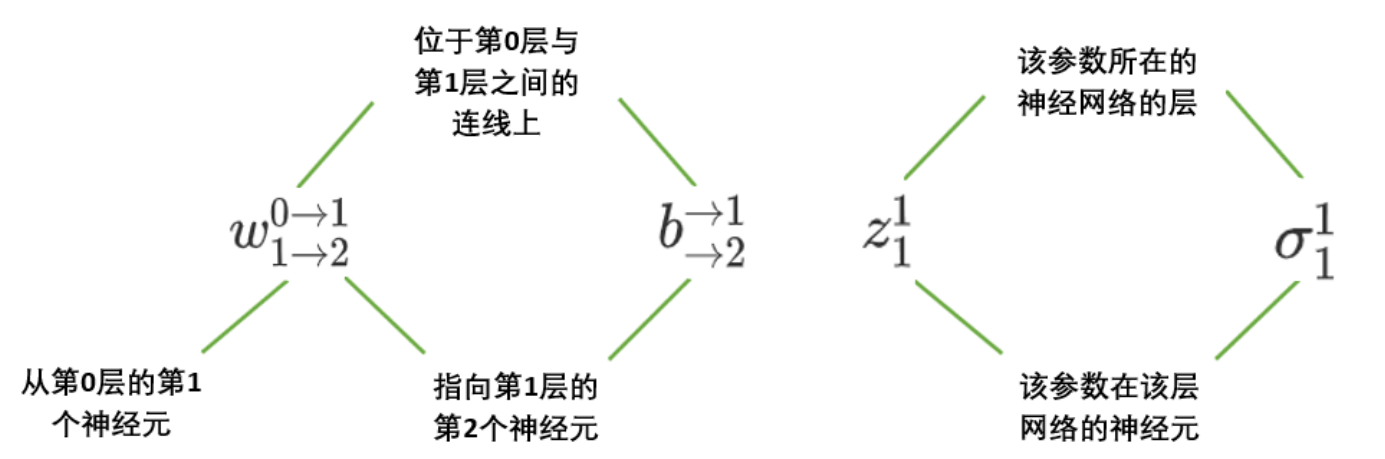
上标表示层的编号,下标表示层上的神经元的编号。
有了这些编号说明,我们就可以用数学公式来表示从输入层传入到第一层隐藏层的信号了。以上面说明的XOR异或门为例,对于仅有两个特征的单一样本而言,在第一层的第一特征神经元中获得加和结果的式子可以表示为:
z 1 1 = b → 1 → 1 + x 1 w 1 → 1 0 → 1 + x 2 w 2 → 1 0 → 1 z_1^1 = b_{\rightarrow 1}^{\rightarrow 1} + x_1 w_{1 \rightarrow 1}^{0 \rightarrow 1} + x_2 w_{2 \rightarrow 1}^{0 \rightarrow 1} z11=b→1→1+x1w1→10→1+x2w2→10→1
而隐藏层中被 h ( z ) h(z) h(z)处理的公式可以写作
σ 1 1 = h ( z 1 1 ) = h ( b → 1 → 1 + x 1 w 1 → 1 0 → 1 + x 2 w 2 → 1 0 → 1 ) \begin{aligned} \sigma_1^1 &= h(z_1^1) \\ &= h(b_{\rightarrow 1}^{\rightarrow 1} + x_1 w_{1 \rightarrow 1}^{0 \rightarrow 1} + x_2 w_{2 \rightarrow 1}^{0 \rightarrow 1}) \end{aligned} σ11=h(z11)=h(b→1→1+x1w1→10→1+x2w2→10→1)
根据我们之前写的NAND函数,这里的 h ( z ) h(z) h(z)为阶跃函数。
现在,我们用矩阵来表示数据从输入层传入到第一层,并在第一层的神经元中被处理成 σ \sigma σ的情况:
注:多层神经网络是 W W W@ X X X,且 X X X的每一个样本在 X X X矩阵的一列而不是单层神经网络的一行。(非常重要!)
Z 1 = W 1 ⋅ X + B 1 \mathbf{Z}^1 = \mathbf{W}^1 \cdot \mathbf{X} + \mathbf{B}^1 Z1=W1⋅X+B1
z 1 1 z 2 1 \] = \[ w 1 → 1 0 → 1 w 2 → 1 0 → 1 w 1 → 2 0 → 1 w 2 → 2 0 → 1 \] ∗ \[ x 1 x 2 \] + \[ b → 1 → 1 b → 2 → 1 \] \\begin{bmatrix} z_1\^1 \\\\ z_2\^1 \\end{bmatrix} = \\begin{bmatrix} w_{1 \\rightarrow 1}\^{0 \\rightarrow 1} \& w_{2 \\rightarrow 1}\^{0 \\rightarrow 1} \\\\ w_{1 \\rightarrow 2}\^{0 \\rightarrow 1} \& w_{2 \\rightarrow 2}\^{0 \\rightarrow 1} \\end{bmatrix} \* \\begin{bmatrix} x_1 \\\\ x_2 \\end{bmatrix} + \\begin{bmatrix} b_{\\rightarrow 1}\^{\\rightarrow 1} \\\\ b_{\\rightarrow 2}\^{\\rightarrow 1} \\end{bmatrix} \[z11z21\]=\[w1→10→1w1→20→1w2→10→1w2→20→1\]∗\[x1x2\]+\[b→1→1b→2→1
矩阵结构表示为: ( 2 , 1 ) = ( 2 , 2 ) ∗ ( 2 , 1 ) + ( 2 , 1 ) (2,1) = (2,2) * (2,1) + (2,1) (2,1)=(2,2)∗(2,1)+(2,1)
= x 1 w 1 → 1 0 → 1 + x 2 w 2 → 1 0 → 1 x 1 w 1 → 2 0 → 1 + x 2 w 2 → 2 0 → 1 + b → 1 → 1 b → 2 → 1 = \begin{bmatrix} x_1 w_{1 \rightarrow 1}^{0 \rightarrow 1} + x_2 w_{2 \rightarrow 1}^{0 \rightarrow 1} \\ x_1 w_{1 \rightarrow 2}^{0 \rightarrow 1} + x_2 w_{2 \rightarrow 2}^{0 \rightarrow 1} \end{bmatrix} + \begin{bmatrix} b_{\rightarrow 1}^{\rightarrow 1} \\ b_{\rightarrow 2}^{\rightarrow 1} \end{bmatrix} =x1w1→10→1+x2w2→10→1x1w1→20→1+x2w2→20→1+b→1→1b→2→1
= x 1 w 1 → 1 0 → 1 + x 2 w 2 → 1 0 → 1 + b → 1 → 1 x 1 w 1 → 2 0 → 1 + x 2 w 2 → 2 0 → 1 + b → 2 → 1 = \begin{bmatrix} x_1 w_{1 \rightarrow 1}^{0 \rightarrow 1} + x_2 w_{2 \rightarrow 1}^{0 \rightarrow 1} + b_{\rightarrow 1}^{\rightarrow 1} \\ x_1 w_{1 \rightarrow 2}^{0 \rightarrow 1} + x_2 w_{2 \rightarrow 2}^{0 \rightarrow 1} + b_{\rightarrow 2}^{\rightarrow 1} \end{bmatrix} =x1w1→10→1+x2w2→10→1+b→1→1x1w1→20→1+x2w2→20→1+b→2→1
σ 1 1 σ 2 1 \] = \[ h ( x 1 w 1 → 1 0 → 1 + x 2 w 2 → 1 0 → 1 + b → 1 → 1 ) h ( x 1 w 1 → 2 0 → 1 + x 2 w 2 → 2 0 → 1 + b → 2 → 1 ) \] \\begin{bmatrix} \\sigma_1\^1 \\\\ \\sigma_2\^1 \\end{bmatrix} = \\begin{bmatrix} h(x_1 w_{1 \\rightarrow 1}\^{0 \\rightarrow 1} + x_2 w_{2 \\rightarrow 1}\^{0 \\rightarrow 1} + b_{\\rightarrow 1}\^{\\rightarrow 1}) \\\\ h(x_1 w_{1 \\rightarrow 2}\^{0 \\rightarrow 1} + x_2 w_{2 \\rightarrow 2}\^{0 \\rightarrow 1} + b_{\\rightarrow 2}\^{\\rightarrow 1}) \\end{bmatrix} \[σ11σ21\]=\[h(x1w1→10→1+x2w2→10→1+b→1→1)h(x1w1→20→1+x2w2→20→1+b→2→1)
相应的,从第一层(中间层)的神经元向下一层传递时,会得到结果 σ 1 1 \sigma_1^1 σ11 和 σ 2 1 \sigma_2^1 σ21。这些 σ \sigma σ 会作为输入结果继续传入第二层(输出层)。对于第二层的唯一输出神经元而言,我们可以得到:
z 1 2 = b → 1 → 2 + σ 1 1 w 1 → 1 1 → 2 + σ 2 1 w 2 → 1 1 → 2 z_1^2 = b_{\rightarrow 1}^{\rightarrow 2} + \sigma_1^1 w_{1 \rightarrow 1}^{1 \rightarrow 2} + \sigma_2^1 w_{2 \rightarrow 1}^{1 \rightarrow 2} z12=b→1→2+σ11w1→11→2+σ21w2→11→2
σ 1 2 = g ( z 1 2 ) \sigma_1^2 = g(z_1^2) σ12=g(z12)
σ 1 2 = g ( b → 1 → 2 + σ 1 1 w 1 → 1 1 → 2 + σ 2 1 w 2 → 1 1 → 2 ) \sigma_1^2 = g(b_{\rightarrow 1}^{\rightarrow 2} + \sigma_1^1 w_{1 \rightarrow 1}^{1 \rightarrow 2} + \sigma_2^1 w_{2 \rightarrow 1}^{1 \rightarrow 2}) σ12=g(b→1→2+σ11w1→11→2+σ21w2→11→2)
由于第二层就已经是输出层了,因此第二层使用的激活函数标记为 g ( z ) g(z) g(z)(如果是阶跃函数则是直接得到预测结果 y)。在这里,第二层的表达和第一层几乎一模一样。
相信各种编号在这里已经让人感觉到有些头疼了,虽然公式本身并不复杂,但涉及到神经网络不同的层以及每层上的神经元之间的数据流动,公式的编号会让人有所混淆。如果神经网络的层数继续增加,或每一层上神经元数量继续增加,神经网络的嵌套和计算就会变得更加复杂。
在实际中,我们的真实数据可能有超过数百甚至数千个特征,所以真实神经网络的复杂度是非常高,计算非常缓慢的。所以,当神经网络长成如下所示的模样,我们就无法立刻理解中间过程了。我们不知道究竟有多少个系数,如何相互作用产生了我们的预测结果,因此神经网络的过程常被称为一个"黑箱"。

(3).异或门代码
示例:异或门 (XOR)解法
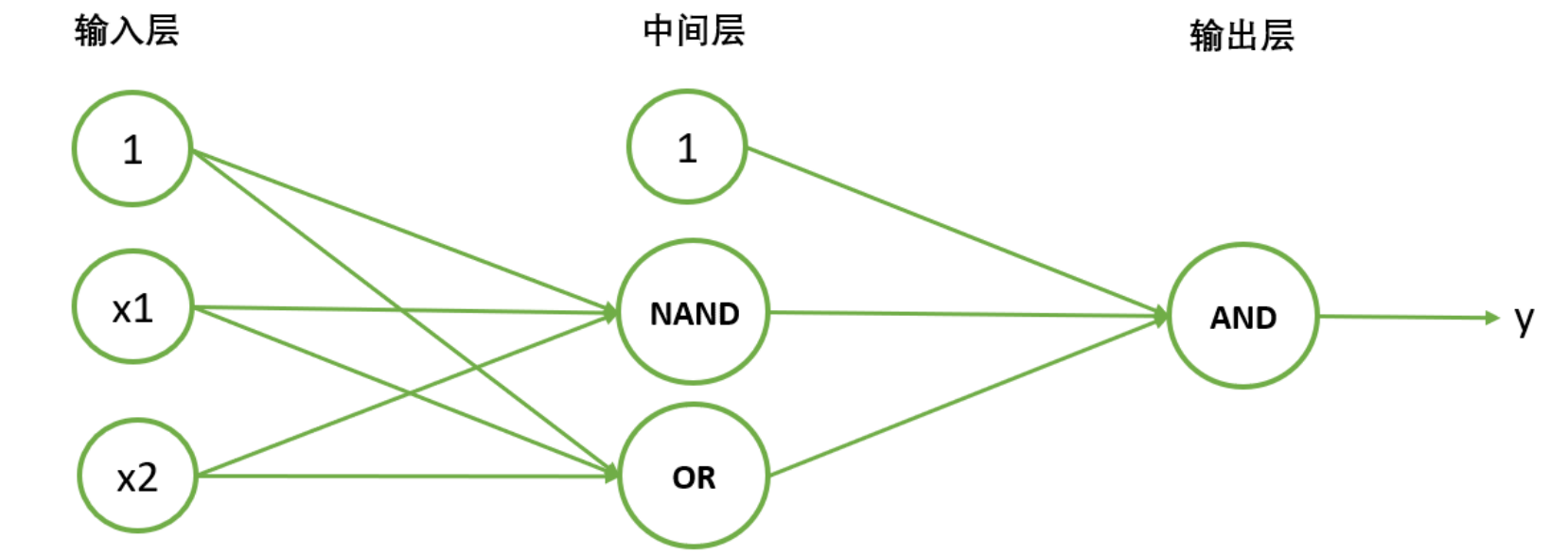
python
import torch
def NAND(X):
w = torch.tensor([0.23,-0.15,-0.15])
zhat = X@w
yhat = torch.tensor([int(x) for x in zhat>0],dtype=torch.float32)
return yhat
def OR(X):
w = torch.tensor([-0.08, 0.15,0.15])
zhat = X@w
yhat = torch.tensor([int(x) for x in zhat>0],dtype=torch.float32)
return yhat
def AND(X):
w = torch.tensor([-0.2,0.15, 0.15])
zhat = X@w
yhat = torch.tensor([int(x) for x in zhat>0],dtype=torch.float32)
return yhat
def XOR(X):
#输入值:
input_1 = X
#中间层:
sigma_nand = NAND(input_1)
sigma_or = OR(input_1)
x0 = torch.tensor([[1],[1],[1],[1]],dtype=torch.float32)
#输出层:
input_2 = torch.cat((x0,sigma_nand.view(4,1),sigma_or.view(4,1)),dim=1)
y_and = AND(input_2)
return y_and
X = torch.tensor([[1.,0,0],[1,1,0],[1,0,1],[1,1,1]])
print(XOR(X))
# tensor([0., 1., 1., 0.])二. 激活函数(Activation Function)
Hz:激活函数在中间层叫Hz
Gz:激活函数在输出层Gz
1. 仿射变换
重大警告:如果不加激活函数,盲目堆叠多少个隐藏层都等于单层网络!
数学证明:
假设我们有一个两层网络,都不加激活函数。
-
第一层(隐藏层): H = X W 1 H = XW_1 H=XW1
-
第二层(输出层): Z = H W 2 Z = HW_2 Z=HW2
-
代入展开: Z = ( X W 1 ) W 2 = X ( W 1 W 2 ) Z = (XW_1)W_2 = X(W_1W_2) Z=(XW1)W2=X(W1W2)
由于矩阵乘法结合律, W 1 W 2 W_1W_2 W1W2 可以等效为一个全新的权重矩阵 W n e w W_{new} Wnew。
最终 Z = X W n e w Z = XW_{new} Z=XWnew,它本质上依然是一个单层线性网络,毫无非线性表达能力!
在层中流动的数据被做了仿射变换(affine transformation),仿射变换后依得到一个线性方程而这样的方程不能解决非线性问题。
2. 激活函数
为了打破纯线性的矩阵乘法,我们必须在每一层的输出后套上一个非线性函数,这就是激活函数(如 σ \sigma σ)。
神经网络中可用的激活函数多达数十种(激活函数介绍),但机器学习中常用的激活函数只有恒等函数(identity function),阶跃函数(sign),sigmoid函数,ReLU,tanh,softmax这六种,其中Softmax与恒等函数几乎不会出现在隐藏层上,Sign、Tanh几乎不会出现在输出层上,ReLU与Sigmoid则是两种层都会出现,并且应用广泛。
输出层的 g ( z ) g(z) g(z) 与隐藏层的 h ( z ) h(z) h(z) 之间的区别:
- **虽然都是激活函数,但隐藏层和输出层上的激活函数作用是完全不一样的。输出层的激活函数 g ( z ) g(z) g(z) 是为了让神经网络能够输出不同类型的标签而存在的。其中恒等函数用于回归,sigmoid函数用于二分类,softmax用于多分类。换句话说, g ( z ) g(z) g(z) 仅仅与输出结果的表现形式有关,与神经网络的效果无关,也因此它可以使用线性的恒等函数。**但隐藏层的激活函数就不同了,如我们之前尝试的XOR,隐藏层上的激活函数 h ( z ) h(z) h(z) 的选择会影响神经网络的效果,而线性的 h ( z ) h(z) h(z) 是会让神经网络的结构失效的。
- 在同一个神经网络中, g ( z ) g(z) g(z) 与 h ( z ) h(z) h(z) 可以是不同的,并且在大多数运行回归和多分类的神经网络时,他们的确是不同的。每层上的 h ( z ) h(z) h(z) 可以是不同的,但是同一层上的激活函数必须一致。
结论:
-
h ( z ) h(z) h(z)影响模型效果,而 g ( z ) g(z) g(z)只影响模型输出结果的形式
-
激活函数是神经网络的灵魂!它赋予了神经网络非线性表达能力,使其理论上能够拟合世界上任意复杂的函数(万能近似定理)。
三. 从0实现深度神经网络的正向传播
在PyTorch中,构建复杂的深层网络必须依靠面向对象编程,通过继承 torch.nn.Module 基类来实现。
1. nn.Module类的核心结构
构建网络类时,必须重写两个极其重要的方法:
-
__init__(self):初始化方法。用于定义网络中需要的所有层(如nn.Linear)。-
__init__(self)需要in_features和out_features两个参数-
in_features:输入该神经网络的特征数目(输入层上的神经元的数目)
-
out_features:神经网络的输出的数目(输出层上的神经元的数目)
-
-
__init__(self)需要调用父类初始化方法:super().__init__()在自定义网络的
__init__方法中,第一行必须要调用super().__init__()
-
-
forward(self, x):前向传播方法。定义数据 x x x 是如何一步步通过这些层的。
注:不需要自己去写__call__,只需要负责把网络前向传播的数学逻辑写进forward里。 在使用模型时,永远通过仿函数使用模型,打死都不要写 module.forward(X)!
nn.Module这个父类本身就已经自带了极其复杂的__call__方法!当你写
class Model(nn.Module):时,你的子类直接继承了父类的__call__。而父类的__call__在底层被设计成了会自动去寻找并运行你写的forward。
2. 从nn.Module 继承的属性和方法
nn.Module 类的底层定义代码有一千多行,它的 __init__ 内部包含了极其复杂的状态初始化逻辑。
(1). 从 nn.Module 继承的属性
只要继承了 nn.Module,子类对象就自动拥有了以下重要的状态属性:
net.training(模式状态): 返回一个布尔值,指示当前模型是否处于训练模式(默认True)。这对某些在训练和推断时行为不一致的层(如 Dropout 或 BatchNorm)极其重要。- 底层的状态字典 (隐藏属性):
self._parameters: 存放所有的可学习参数(如权重和偏置)。self._modules: 存放你定义的各个子网络层(如各个nn.Linear)。self._buffers: 存放不需要梯度更新的常量状态(如 BatchNorm 追踪的均值和方差)。- 各类
_hooks: 存放前向/反向传播时的钩子函数。
(2). 从 nn.Module 继承的方法
只要继承了 nn.Module,子类对象就直接拥有了以下强大的内置方法来管理和操作模型:
①. train & eval - 模式切换
作用:用于一键切换模型的工作状态。调用 train() 会将子类对象的 training 属性设为 True;调用 eval() 则设为 False。这对那些在训练和推断时计算逻辑不同的层(如 Dropout、BatchNorm)极其重要。
python
net.train(mode=True)
net.eval()参数:
- 模式 (mode): 仅
train()包含该参数。传入布尔值,默认True代表开启训练模式 (bool)。
返回值:
- 成功: 返回模型实例本身 (Module)。
避坑警告:在进行模型预测/测试/评估时,务必提前调用 net.eval()!
②. cuda & cpu - 设备转移
作用:能够将整个模型内部所有的参数张量(权重、偏置等)及缓冲区,一键无缝搬运到 GPU 或 CPU 的显存/内存中。
python
net.cuda(device=None)
net.cpu()参数:
- 设备索引 (device): 仅
cuda()包含该参数。可指定转移到具体的 GPU 编号(如cuda(1)),不填则默认转移到当前默认的 GPU 设备 (int / device / None)。
返回值:
- 成功: 返回模型实例本身 (Module)。
③. apply - 批量操作 (递归遍历)
作用:极其强大的方法! 它会递归地遍历模型 __init__ 中定义的所有子模块对象(即全部网络层),并对它们逐一执行传入的函数操作。最经典的应用场景就是批量初始化模型权重。
python
net.apply(fn)参数:
- 操作函数 (fn): 将被应用于每个子模块的自定义函数。该函数必须且只能接收一个参数(即子模块本身) (Callable)。
返回值:
- 成功: 返回模型实例本身 (Module)。
示例:
python
import torch.nn as nn
# 比如,令所有线性层的初始权重 w 都为 0
def initial_0(m):
# 工业界标准写法:使用 isinstance 判断类型
if isinstance(m, nn.Linear):
m.weight.data.fill_(0)
print(f"已初始化网络层: {m}")
# 将 initial_0 函数一键应用到全网络
net.apply(initial_0) ④. parameters - 参数迭代器
作用:返回一个特殊的生成器/迭代器,里面打包了整个网络中所有需要被优化的可学习参数张量(权重和偏置)。这个方法在训练循环中绝对不可或缺,我们必须将它提取出的参数统统喂给优化器(Optimizer)去进行梯度下降更新。
python
net.parameters(recurse=True)参数:
- 是否递归 (recurse): 如果为
True,则返回当前模块及所有子模块的参数;若设为False,则仅返回直接隶属于当前模块的顶层参数(默认True)(bool)。
返回值:
- 成功: 返回一个包含所有可学习参数的生成器 (IteratorParameter)。
示例:
python
# 我们可以通过循环的方式,查看网络里面究竟装着哪些参数张量
# 假设我们有一个极小的微型网络net里面有linear1和output两层:
# linear1 = nn.Linear(2, 3)
# output = nn.Linear(3, 1)
# 1. 打印具体的参数张量内容 (print(param))
for param in net.parameters():
print(param)
# ---- 输出演示 (为了排版清爽,假定权重已被初始化为 0 或随机小数) ----
# Parameter containing:
# tensor([[ 0.0000, 0.0000],
# [ 0.0000, 0.0000],
# [ 0.0000, 0.0000]], requires_grad=True) <-- linear1 的 weight矩阵 (3x2)
# Parameter containing:
# tensor([ 0.1234, -0.5678, 0.9101], requires_grad=True) <-- linear1 的 bias向量 (3)
# Parameter containing:
# tensor([[ 0.0000, 0.0000, 0.0000]], requires_grad=True) <-- output 的 weight矩阵 (1x3)
# Parameter containing:
# tensor([-0.3141], requires_grad=True) <-- output 的 bias向量 (1)
# 2. 工业界更常用的方式:只打印每一层参数张量的形状 (print(param.shape))
for param in net.parameters():
print(param.shape)
# ---- 输出演示 ----
# torch.Size([3, 2]) <-- linear1.weight
# torch.Size([3]) <-- linear1.bias
# torch.Size([1, 3]) <-- output.weight
# torch.Size([1]) <-- output.bias3. 代码示例
假设我们有500条数据,20个特征,标签为3分类。我们现在要实现一个三层神经网络,这个神经网络的架构如下:第一层有13个神经元,第二层有8个神经元,第三层是输出层。其中,第一层的激活函数是relu,第二层是sigmoid。
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self,in_features=10, out_features=2):
"""
in_features: 输入该神经网络的特征数目(输入层上的神经元的数目)
out_features:神经网络的输出的数目(输出层上的神经元的数目)
"""
# 1. 重点:必须继承父类的初始化方法!
super().__init__()
# 2. 定义网络的各个层 (此时并不执行计算,只是声明有这些组件)
self.linear1 = nn.Linear(in_features,13,bias=True)
self.linear2 = nn.Linear(13,8,bias=True)
self.output = nn.Linear(8,out_features,bias=True)
def forward(self,x): #神经网络的向前传播
# 3. 定义数据x的流向和激活过程
z1 = self.linear1(x)
sigma1 = torch.relu(z1)
z2 = self.linear2(sigma1)
sigma2 = torch.sigmoid(z2)
z3 = self.output(sigma2)
sigma3 = F.softmax(z3,dim=1)
return sigma3
# 4. 实例化模型并进行前向传播测试
# 确定数据
# 假设我们有500条数据,20个特征,标签为3分类。
X = torch.rand((500,20),dtype=torch.float32)
y = torch.randint(low = 0,high=3,size=(500,1),dtype=torch.float32)
input_ = X.shape[1] #输入层神经元个数,即特征数量
output_ = len(y.unique()) #对y中内容去重,得到标签一共有几类
torch.random.manual_seed(420)
net = Model(in_features=input_,out_features=output_)
print(net(X)) #内部自动调用了net.forward(X)
# tensor([[0.4158, 0.3465, 0.2377],
# [0.4201, 0.3423, 0.2376],
# [0.4158, 0.3467, 0.2375],
# ...,
# [0.4206, 0.3414, 0.2381],
# [0.4186, 0.3410, 0.2404],
# [0.4070, 0.3517, 0.2413]], grad_fn=<SoftmaxBackward0>)
print(net.linear1.weight.shape)
# torch.Size([13, 20])
# x(500,20)@linear1.weight.T(20,13) -> (500,13) 注:nn.Linear底层自动转置的是它自己的权重矩阵
print(net.linear2.weight.shape)
# torch.Size([8, 13])
# (500,13)@linear2.weight.T(13,8) -> (500,8)
print(net.output.weight.shape)
# torch.Size([3, 8])
# (500,8)@output.weight.T(8,3) -> (500,3)