27 届运维实习笔记|第三、四周:从流程熟练到故障排查,企业运维实战深化
前两周完成了从入职适配到基本工具使用,再到中间件熟悉延伸至工单处理、Jenkins 上线初体验,第三、四周进入高频实操、流程固化、原理理解、故障分析 的新阶段。这两周的日子,实操性得到大幅提升,使我在Linux系统的日常运维、定时项目发布、shell脚本优化、突发故障问题定位中持续深入,对Linux、Shell、SQL、Jenkins、Nginx、4A 合规、高可用架构的理解有了更加完整的体系认识,实现了从 "跟着做" 走向学着 "懂逻辑、会排查、能总结"的进阶探索。
一、日常运维:工单处理标准化,技能熟练度稳步提升
这两周我持续负责售后工单分析、权益平台排错、投诉平台查询 的日常处理,工作内容更复杂、场景更真实,也逐步形成了适合自己的标准化处理流程:
- 首先是通过 4A 平台,配置好网关,路由等设置登录内网·、进行权限核验,领取待处理工单;
- 梳理问题的描述,具体的业务模块归属,例如抓住用户号码、故障时间范围等关键信息作为排查关键线索;
- 编写 / 调用 Shell 脚本,连接数据库执行 SQL 查询,尽量使用
grep、sed、awk对日志进行过滤、清洗、提取所需的关键信息,避免表中干扰信息过多影响判断,同时提高分析效率; - 核对订单状态、业务记录、调取查询接口,核对返回结果是否符合工单述求,最终以快速完成问题定位、快速响应、解决问题并结果反馈,形成工单闭环。
同时,在实操中我进一步巩固了一些运维人员的基础但高频使用的技能:
1.熟练使用chmod调整脚本权限,避免执行报错,用explain分析 SQL 执行效率,优化查询速度
2.把重复查询逻辑封装成函数,提升脚本复用性,使得对多表关联、条件筛选、子查询等复杂 SQL 更加熟练
3.日志排查更精准,调用查询接口之后,能快速定位报错、超时、异常返回
这些日常工作让我深刻体会到:运维没有 "小操作",每一条命令、每一次查询都必须严谨、可追溯、而且要符合合规要求,便于集团审计。
二、项目上线全流程巩固:Jenkins + Nginx + 高可用落地
这两周我多次参与项目上线,对CI/CD 自动化发布体系 和高可用架构 的理解更加清晰,透彻,从 刚开始的"看流程" 变成 "跟流程、懂流程",逐渐在日常项目上线中将理解运用到实际之中,增强运维部署经验;
1. 完整上线流程回顾
- 资源管控后台录入信息,核对服务器、权限、上线时间
- 邮件申请上线,完成审批流程
- 开发提交代码到 Git,Jenkins 自动拉取
- 构建、编译、打包,生成可部署制品
- 通过 Ansible 批量分发到多台服务器
- 执行 Shell 脚本完成备份、替换、启动、检查
- Nginx 主备切换、流量调度、负载均衡
- 上线后巡检:服务状态、端口、进程、日志、数据库连接
- 确认业务正常,上线完成
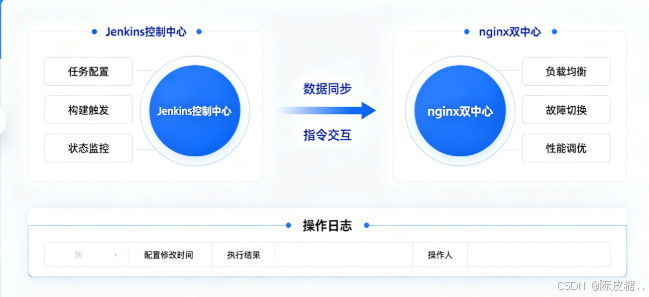
2. Nginx 与高可用核心收获
- 理解 Nginx 作为流量入口、反向代理、负载均衡的作用
- 掌握
nginx -s reload平滑重载,实现配置更新不中断业务 - 理解主备容灾、双中心部署的意义:保证业务不间断
- 看懂流量调度逻辑,明白上线为什么要 "切主备"
- 学会上线后检查服务是否正常接入流量
这部分让我真正理解:企业运维的核心不是 "能上线",而是 "稳上线、无损上线、可回滚上线"。
三、脚本优化与合规意识:运维效率与安全双重提升
在这小半个月时间里,我继续对常用 Shell 脚本进行优化,让工单处理、查询、巡检更高效、更规范:
- 把 8 大高频数据库查询场景封装成传参式脚本,使得查询之中可以达到一键切换库、一键查询,更加灵活,提高查询效率;
- 使用
grep匹配关键字,sed清洗冗余数据,输出整洁结果,所有高危操作全部放入脚本,禁止手动敲命令; - 执行日志自动记录,满足集团审计与可追溯要求,更加合规和安全;
优化后明显感受到:
- 工单处理速度更快,shell脚本的复用率也使得人为失误更少;
- 操作更规范、更安全符合企业合规、审计、留痕的硬性要求;
四、记录遇到的故障分析
内网登陆的云平台在连接4A功能平台之后,出现平台功能异常,清缓存即恢复(实战复盘)
本周遇到一个非常典型、企业高频出现的问题,刚开始我以为是dns异常解析导致功能异常,但后续的梳理之中,通过团队求助,资料查询等方式弄明白了原因,彻底搞懂前端与登录态原理:
故障现象:
4A 平台页面可以正常打开,但某个功能按钮失效、点击无反应、接口报错;
但是在只执行:清除浏览器缓存 → 关闭浏览器 → 重新登录之后,功能立刻恢复正常。
根本原因分析(与 DNS 无关):
-
本地 JS/CSS 缓存版本或不匹配,平台更新后,浏览器仍使用旧脚本,与后端接口不兼容
-
Cookie/Token 登录态过期 / 损坏,身份凭证失效,导致鉴权失败、功能无权限
-
localStorage 脏数据,权限、菜单、用户状态异常,页面渲染出错
-
页面加载不完整
网络波动导致状态异常,普通刷新无法修复
为什么清缓存重启就好?
-
清除缓存:删除旧资源、失效 Cookie、脏数据
-
重启浏览器:彻底重置页面状态
-
重新登录:获取全新 Token,加载最新前端文件
→ 该过程相当于 "重新初始化",故障直接消失
关键结论
- DNS 只负责域名解析,异常会直接打不开页面
- 能打开页面但功能异常 → 一定是前端 / 登录态问题
- 清浏览器缓存不清除 DNS 记录 → 彻底排除 DNS
这次故障复盘让我第一次完整完成:现象→原因→原理→结论的运维分析链路。
五、深化理解的技术栈(第三、四周巩固系列)
结合前两周学习,我对业务上的整套企业运维技术栈的认知更加连贯:
- Git:作为代码版本管理,发布的源头,保证可回溯
- Jenkins:持续集成,自动化构建、打包、调度
- Ansible:批量部署,多服务器统一操作、文件分发
- Shell:运维核心工具,实现操作标准化、自动化
- Nginx:流量网关、负载均衡、高可用、无损上线
- 4A 平台:统一认证、权限管控、操作审计、合规底线
- MySQL/DB2:数据查询、工单定位、业务核对
- Linux:基础环境,日志、进程、端口、文件管理
这套体系的目标:
更快发布、更少故障、更稳运行、更强合规、更易排查,适合CI/CD流水线控制机制,高效适配企业的业务开发,上线,维护需求。
六、这期间的总结与感悟
这两周是我从 "会操作" 迈向 "懂原理" 的重要阶段。
从高频工单处理、脚本优化、上线流程巩固,到真实故障分析,我逐步建立起完整的企业运维思维:
- 运维要严谨:每一步都关系业务稳定
- 运维要高效:能用脚本绝不重复手动操作
- 运维要合规:所有操作必须可审计、可追溯
- 运维要懂架构:高可用、流量调度、容灾是业务生命线
目前我已能独立完成:
售后工单处理、SQL 查询优化、Shell 脚本编写、Jenkins 上线流程、Nginx 基础理解、日志排查、简单故障分析。
后续我将继续深耕:
Shell 脚本进阶、中间件运维、监控体系、自动化巡检、高可用架构深化,不断向标准化、自动化、专业化运维方向提升。