0. 引言:此章并非GPU科普
这一章讲GPU发展、A100、SM、Warp、Tensor Core、FlashAttention、PageAttention等等,重点是理解为什么LLM训练和推理会天然走向GPU,以及为什么那么多优化都会回到访存、并行调度和IO上。 本章的展开也很科学,先讲GPU架构与执行模型,再讲内存模型和性能优化,最后讲FlashAttention与PageAttention具体工程案例。
很多"快"并不是因为算法更牛逼,而是算的时候等待数据更少、数据搬运更少,少浪费算力和内存。
1. GPU为什么会成为LLM的核心硬件
1.1 CPU和GPU 的差别
- CPU擅长的是复杂串行逻辑,目的是让单个任务尽快完成。
- GPU更多面积给ALU和大规模并行计算单元,只保留少量控制逻辑,目的是让单位时间内完成更多计算。
神经网络特别是Transformer的计算,本质上是大规模矩阵乘加,属于重复、批量、可并行的工作,因此GPU天然适合大模型。
1.2 A100层级结构
GPC(图形处理簇)→ TPC(纹理处理簇)→ SM(流式多处理器) → CUDA Core/Tensor Core
用工厂类比,GPC是车间,TPC是生产线,SM是干活的工作站,CUDA Core是普通算术工位,Tensor Core是专门负责矩阵块运算的设备。每个SM里有什么资源,Tensor Core能不能被喂饱,线程能不能把资源用满,这些是要考虑的问题。
1.3 Tensor Core
CUDA Core是标量计算单元,而Tensor Core把计算粒度抬升到矩阵块。
原文也在低精度(6.6.2)那一节指出,Tensor Core不是缩小版的FP32电路,而是重构版矩阵引擎,它之所以强,是因为它就是冲着矩阵乘法设计的。
2. GPU的执行模型
2.1 SM(流式多处理器)
SM为原子单元。SM是一个带有控制、调度和本地存储的小型计算中心。
它负责管理海量线程、发射指令、调配共享内存和寄存器,并驱动CUDA Core与Tensor Core持续。
与和CPU core的差异,在于SM可以用极轻量级的方式同时管理大量线程,并在等待内存时快速切换到别的warp,从而把延迟隐藏起来。
SM不像CPU为每个线程保存大量状态,而是轻量级切换,几乎没有开销。
2.2 Block、Warp、Thread
- Thread:最细粒度的执行单元,每个线程处理一份数据。
- Warp:32个线程组成的固定小组,是SM调度的最小单位。
- Block:程序员指定的线程组,会被整体映射到一个SM上执行,同一block内线程可共享shared memory,也能同步。
2.3 SIMT
GPU采用的是SIMT(单指令多线程)模型。它的优势在于:同一个warp里的线程执行同一条指令,只是处理不同数据,因此可以用很少的控制逻辑驱动大量并行计算。
但这也带来一个代价:warp 内一旦出现分支发散,执行就会被迫串行化。
原文关于这块的例子:如果一个warp里有些线程走if,另一些走else,GPU会采用掩码方式先执行一条路径,再执行另一条路径,两条路径的指令都要跑,但是每次只有部分线程有效。
这会直接拖低资源利用率,还可能破坏后续的合并访存。
3. GPU 的内存模型
3.1 内存离SM越近越快也越贵
GPU 的内存分层:
- 寄存器文件:线程私有,最快,完全自动。
- 共享内存/L1:SM内部,很快,block内线程可协作使用,完全手动。
- L2:整个芯片共享,自动缓存。
- HBM/全局内存:容量最大,最远,最慢,手动管理。
SM内部存储访问大约几十个周期,而访问L2或HBM是几百个周期,这个数量级差异会直接决定性能, 一旦计算频繁依赖HBM,SM就不是算不过来,而是在等数据。
3.2 Shared Memory
同一个block内的线程如果要反复访问某一小块数据,最理想的方式是先把这块数据搬到shared memory,再在SM内部反复使用。原文把它称为"线程协作的仓库",这是矩阵乘法分块等优化的核心支点。
GPU的解决方案是划分层级:
- L2缓存利用时间局部性,缓存重复访问的权重;
- 共享内存利用空间局部性,手动加载分块(Tiling)数据;
- Warp利用常量内存的广播特性,1次读取服务32线程。
3.3 内存墙
近些年计算能力的增长速度远快于内存带宽的增长速度。也就是说,算力越来越不是稀缺资源,带宽才是。
未来算法设计必须以内存为中心,尽可能减少对低速全局内存的访问。
所以这一节就是:
很多GPU优化本质上是为了少搬运数据。
4. 常见优化手段
4.1 低精度
- 硬件电路更简单。位宽更低的乘法器更小,同样面积能塞下更多运算单元。
- 内存带宽节省。同样参数量、激活值、梯度,用 FP16/BF16 表示时,搬运的数据量直接下降。
- Tensor Core专门为低精度矩阵乘做了优化,加速原理如下:
脉动阵列(Systolic Array):数据在阵列中流动,类似DP里的状态转移,每个周期每个单元完成1次乘加,32×32阵列每周期完成1024次运算。
权重静止:矩阵权重预加载到阵列寄存器,减少数据搬运累。
加器优化:FP32累加器保证精度,输入输出用低精度。
4.2 算子融合(Operator Fusion)
如果一串连续操作只是围绕同一批数据展开,那么与其每一步都写回HBM,不如尽量在一个 CUDA kernel里做完。
从pytorch的角度:一串简单运算,底层可能会启动多个kernel,融合之后,中间结果可以尽量留在寄存器或片上存储里,不再频繁落回HBM。
算子融合是在用更长的单次计算,换取更少的中间结果搬运。
4.3 重计算(Recomputation)
在某些场景里,要用旧的数据,与其存起来不如重新算一遍划算。因为保存中间激活值不仅占显存,也意味着后面还要再把它们读回来。与其提前存,不如在反向传播真正需要的时候再现场算一遍,通过增加计算量来避免内存访问。
用多出来的计算,换更稀缺的显存带宽。
4.4 内存合并(Memory Coalescing)

合并访存(Memory Coalescing)背后对应的是DRAM的突发读取机制。
原文指出,显存读取时最昂贵的是把数据从远处搬到放大器这一步,一旦这一步完成,如果线程访问的是连续地址,后面的字节就能以突发段形式一起拿回来。于是同一个warp如果同时访问一行中的连续元素,硬件就能把很多小访问合并成更少的大事务。
4.5 分块(Tiling)
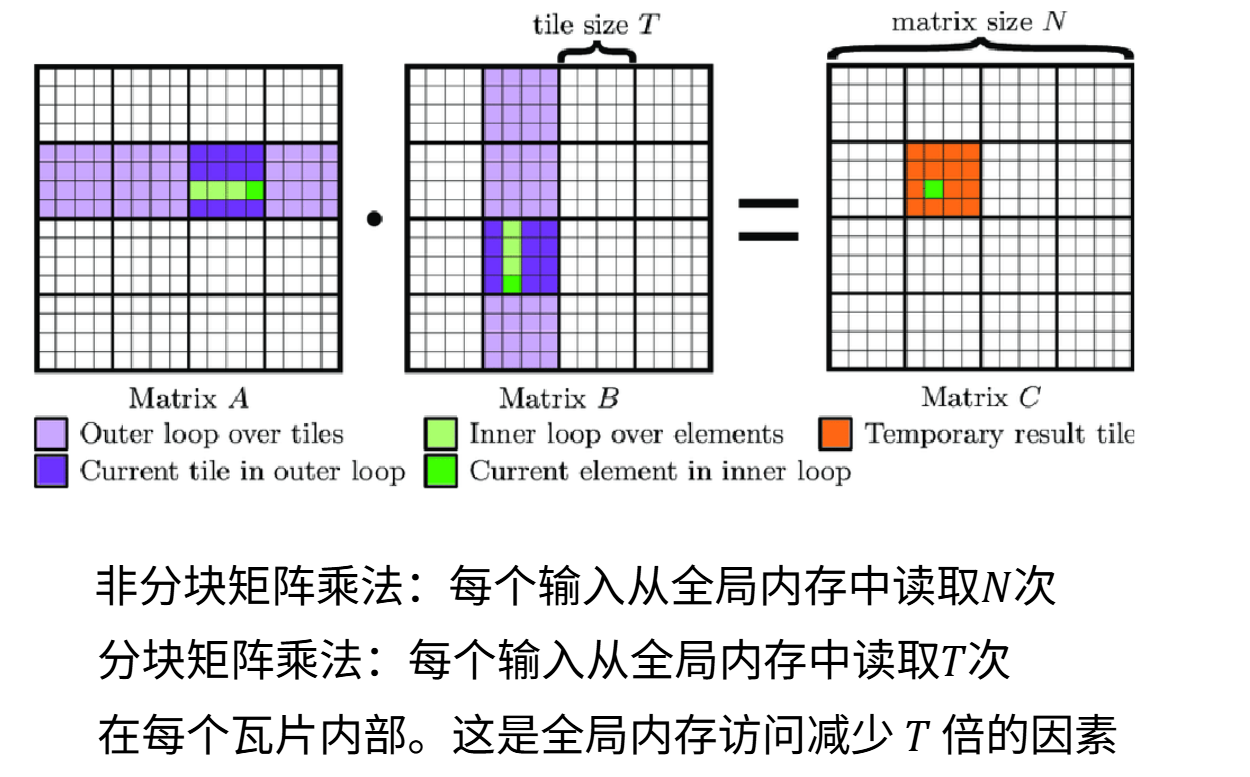
它的核心是把一次远距离、低速、昂贵的全局内存访问,变成一次搬入、多次本地复用。
不分块时,同一元素会被多个线程反复从全局内存读取;分块后,先把tile搬到shared memory,再在块内做大量计算,于是每个输入元素从全局内存的读取次数就会显著下降。
tiling的本质是提高数据复用率,让shared memory替HBM多干活。
5. Attention的两种优化
5.1 FlashAttention
FlashAttention在数学上与标准attention等价,属于精确重排,而非近似计算。它真正改变的是执行顺序。
普通attention的问题,不只是 O ( N 2 ) O(N^2) O(N2)的FLOPs,而是中间会出现巨大的 Q K T QK^T QKT结果,需要频繁在 HBM和片上存储之间来回搬运。
FlashAttention的核心就是通过tiling+online softmax+与 V V V的累积计算,让 Q K T QK^T QKT、softmax和与 V V V的累积尽量在SRAM中完成,避免显式构造完整attention matrix。这样attention计算就更接近 compute-bound,而不再被HBM带宽卡住。
5.1.1 V1、V2、V3
- V1解决IO瓶颈,tiling+online softmax。
- V2解决并行调度与GPU利用率问题,分块并行化处理Q,提高Tensor Core的整体占用率。
- V3 解决计算与访存重叠问题,异步WGMMA流水线,将一组 warp(32 个线程)组织为 warpgroup(4 个 warp,共 128 线程),并在硬件层面直接支持异步执行,让SM始终忙碌。
V1 的关键在于分块和 online softmax。它让 softmax 不再依赖"先拿到整行完整结果再统一归一化",而是通过维护当前最大值和归一化因子,在流式遍历中逐块完成全局归一化。
V2 的重点已经不只是"少搬数据",而是进一步提高并行度和 Tensor Core 利用率。
V3 则更进一步,针对 H100 的异步能力和 WGMMA 指令,把整个计算过程组织成生产者---消费者流水线:一边异步预取下一块数据,一边在 Tensor Core 上计算当前块,通过 double buffer 和显式同步把"搬运"和"计算"尽量重叠起来。
5.1.2 V3和FP8混合精度
混合精度策略:矩阵乘法 Q K T QK^T QKT用FP8,累加器保持FP16/BF16,softmax提升到 FP32,同时通过动态缩放因子控制溢出风险。NVIDIA的Transformer Engine文档也明确说明,在低精度训练和FP8 attention中,某些运算会固定保留在更高精度,softmax等数值敏感部分通常维持FP32。
V3不是单纯的算法技巧,是"算法---硬件协同设计"。
5.2 PageAttention
PageAttention针对的不是单次attention的数学过程,而是推理时KV Cache的组织方式。
传统方案通常给每个请求预留一段逻辑连续、物理也连续的缓存空间,并按最大长度静态分配。这么做问题很严重:长度短的请求会产生大量内部碎片,请求生命周期不一致又会形成很多零散空闲块,进一步带来外部碎片。
PageAttention的思路像操作系统分页:把KV Cache切成固定大小的page,通过block table做映射,让逻辑连续的序列不再要求物理上也连续。这样显存管理就从"按请求静态圈地"变成了"按token动态分配",显著减少浪费。
原文例子:page size为16时,300 token的请求只需19个page,浪费从原来按最大长度预留时的1700+ token,降到个位数。
5.3 FlashAttention与PageAttention对比
| 维度 | FlashAttention | PageAttention |
|---|---|---|
| 核心目标 | 算得更快(降低访存延迟与带宽压力) | 存得更高效(提升显存利用率与并发吞吐能力) |
| 优化层级 | 算子级(微观优化) | 系统级(宏观设计) |
| 核心技术 | Tiling与Oline Softmax | 分页机制(Paging)与逻辑页表映射 |
| 作用对象 | Attention Kernel本身 | 整个生成生命周期中的KV Cache |
| 时间尺度 | 聚焦于单次Forward的IO复杂度 | 聚焦于整个生成生命周期的内存管理 |
| 适用场景 | 训练+推理 | 推理 |
| 架构依赖 | 不依赖Decoder-only架构 | 强依赖Decoder-only架构 |
实际中两者常协同使用,但存在底层访存冲突。PageAttention的非连续物理布局会破坏FlashAttention的连续内存访问(Memory Coalescing)假设。
需将FlashAttention的计算单元(Tile Size)与PageAttention的页大小(Block Size)对齐,以维持共享内存的利用率和访存效率。
6. 理解与反思
- GPU 为什么适合大模型?
因为它不是在追求单个任务的低延迟,而是在追求矩阵乘法这种规则计算的高吞吐。 - 为什么后来越来越多优化都长得像"访存优化"?
因为现代GPU的核心矛盾已经不是算力不够,而是内存带宽和数据搬运越来越跟不上。 - 低精度、融合、重计算、合并访存、tiling这些技巧本质上在干什么?
减少低速内存访问,提高数据复用,让SM少等数据。 - FlashAttention和PageAttention区别
一个是在解决attention怎么算得更快,另一个是在解决KV Cache怎么存得更省。
以后看到新的优化,应该先看在替谁减少IO,替谁提升吞吐,让哪一级内存和哪一类计算单元不闲着。