1. 与大模型的交互
那么问题来了:传统程序该如何与大模型交互呢?
答案是:调用接口。
大模型在部署时通常都会对外暴露基于 HTTP 协议的 API 接口,我们可以用任何自己喜欢的方式调用该接口,实现与大模型的交互:
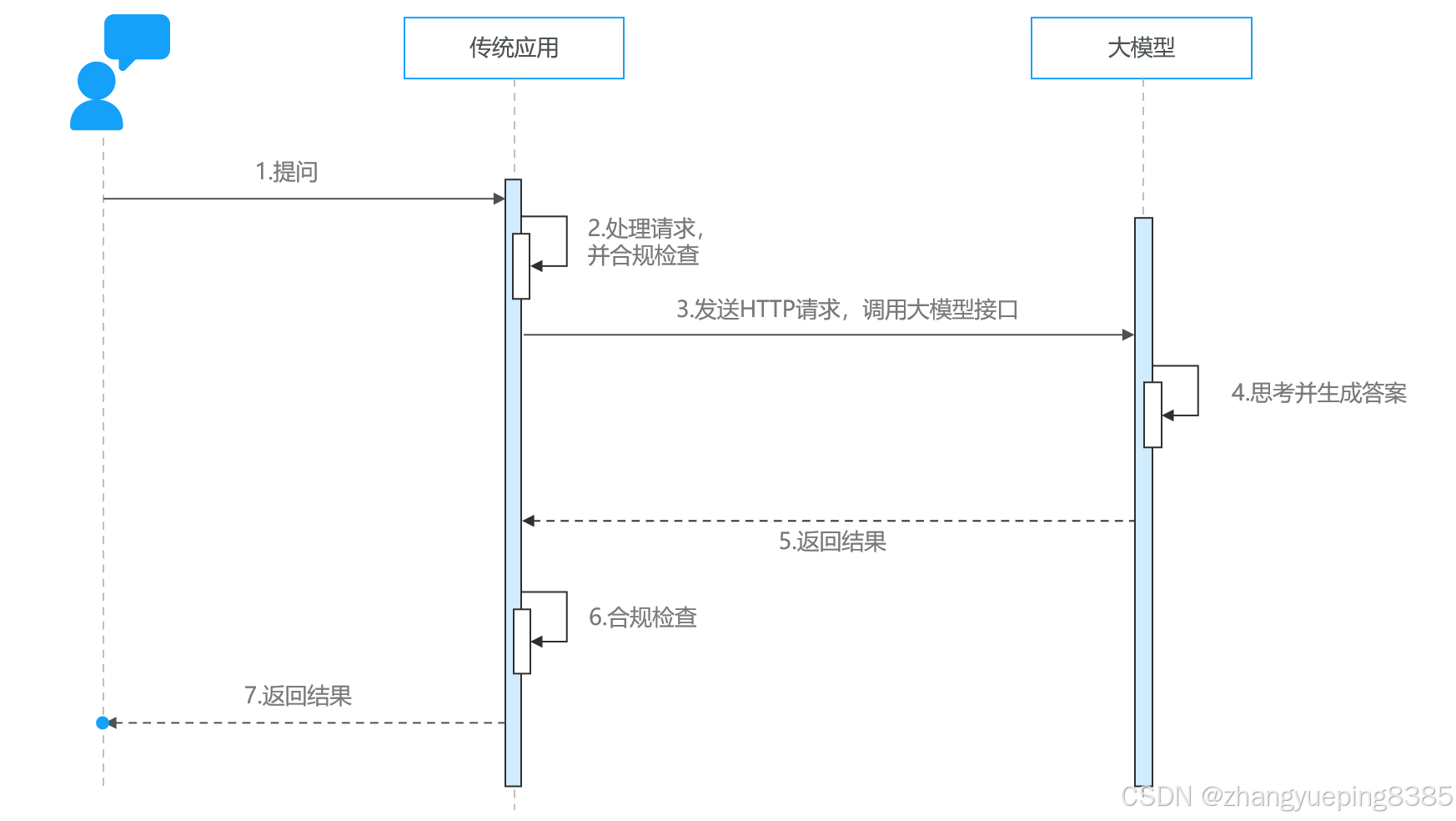
当然,首先我们需要有一个可以调用的大模型服务。
2. 大模型服务
前面说过:大模型应用开发并不是在浏览器中跟AI聊天。而是通过访问模型对外暴露的 API 接口,实现与大模型的交互。
因此,企业开发大模型应用,首先需要有一个可访问的大模型,通常有两种选择:
- 使用开放大模型
- 部署私有大模型
使用开放大模型API的优缺点如下:
优点:
- 没有部署和维护成本,按调用收费
缺点:
- 依赖平台方,稳定性差
- 长期使用成本较高
- 数据存储在第三方,有隐私和安全问题
部署私有模型:
优点:
- 数据完全自主掌控,安全性高
- 不依赖外部环境
- 虽然短期投入大,但长期来看成本会更低
缺点:
- 初期部署成本高
- 维护困难
接下来,我们给大家演示下两种部署方式:
- 公共大模型
- 私有大模型(在本机演示,将来在服务器也是类似的)
通常发布大模型的官方、大多数的云平台都会提供开放的、公共的大模型服务。大模型官方前面讲过,我们不再赘述,这里我们看一些国内提供大模型服务的云平台:
|--------------|----------|---------------------------------------------------------------------------------------------------------------------------------------------------|
| 云平台 | 公司 | 地址 |
| DeepSeek | DeepSeek | https://www.deepseek.com |
| 阿里百炼 | 阿里巴巴 | https://bailian.console.aliyun.com |
| 腾讯TI平台 | 腾讯 | https://cloud.tencent.com/product/ti |
| 千帆平台 | 百度 | https://console.bce.baidu.com/qianfan/overview |
| SiliconCloud | 硅基流动 | https://siliconflow.cn/zh-cn/siliconcloud |
| 火山方舟-火山引擎 | 字节跳动 | https://www.volcengine.com/product/ark |
这些开放平台并不是免费,而是按照调用时消耗的token来付费,每百万token通常在几毛~几元钱,而且平台通常都会赠送新用户百万token的免费使用权。(token可以简单理解成你与大模型交互时发送和响应的文字,通常一个汉字2个token左右)
接下来,我们分别讲解DeepSeek和阿里巴巴的百炼平台。
2.1 DeepSeek 模型服务
2.1.1 注册
首次访问,必须注册:

5.1.2 充值
DeepSeek官方对外提供的大模型API服务是需要收费的,因此我们必须注册账号,充值少量金额(1元也行)。
注册成功后即可进入平台管理页面,点击充值选项,进入充值页面:
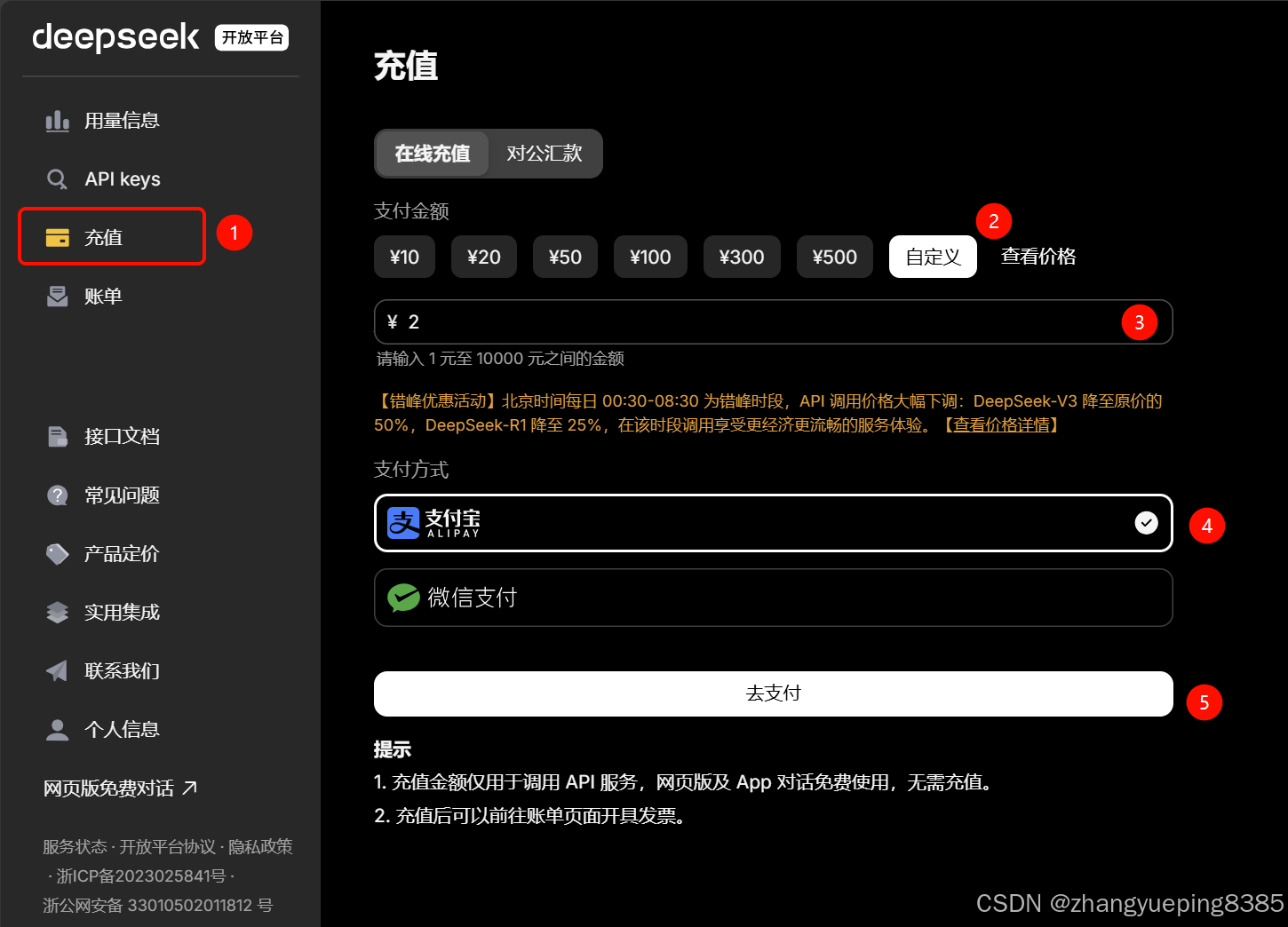
选择合适的价格充值后,即可使用DeepSeek的官方API服务。
2.1.3 创建 API_KEY
由于是收费服务,为了防止别人盗用你的账号,DeepSeek的所有API都有权限校验功能。我们需要创建一个鉴权用的API_KEY可以。
点击API Keys 选项卡,进入对应页面。第一次进入应该没有API key,可以点击创建API key:
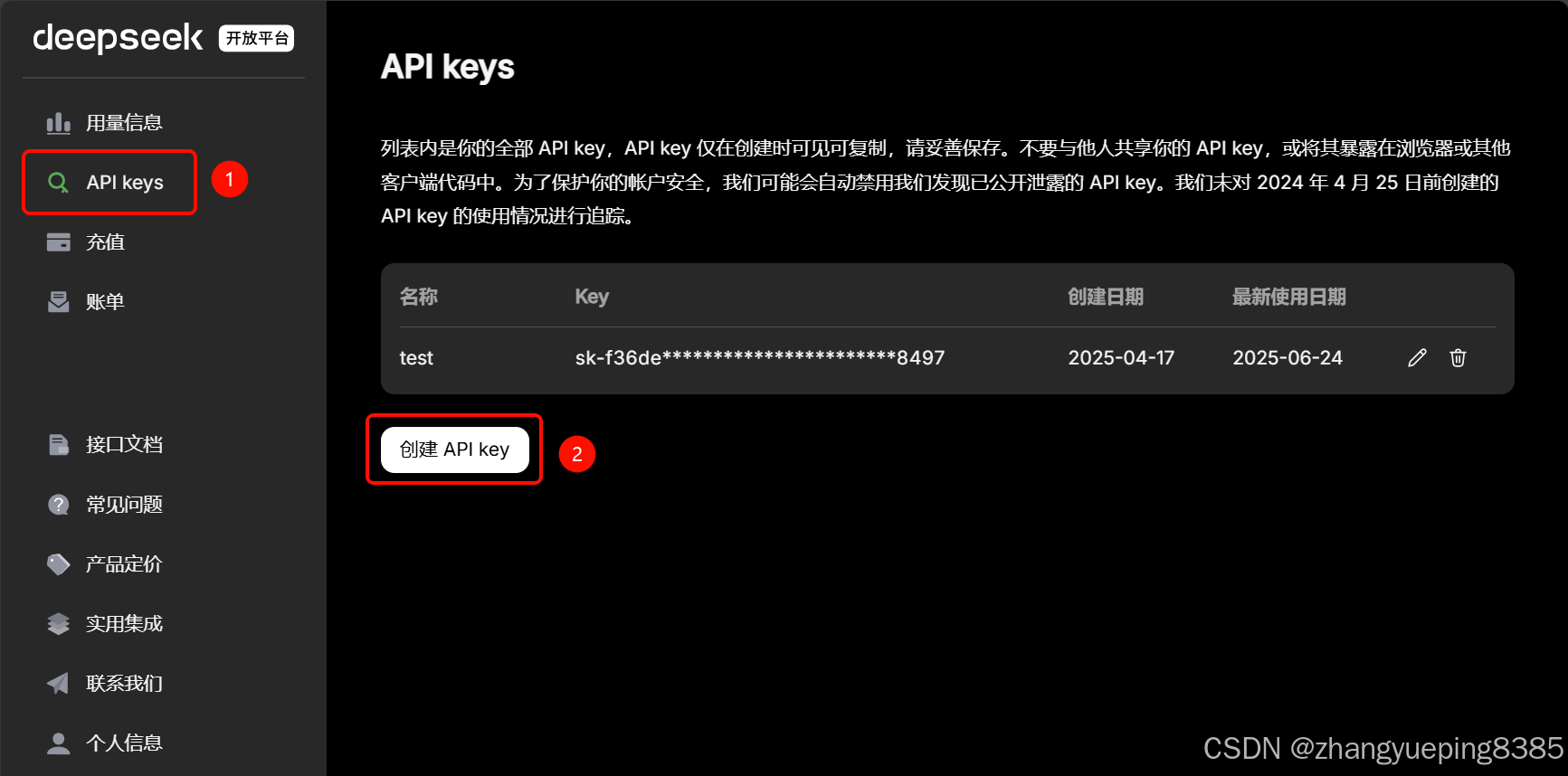
|-----------------------------------------------------------|
| 注意 :API key只有在创建时可以查看,以后都无法查看了。所以需要在创建时妥善保管自己的API key |
OK,准备工作完成。
2.1.4 API 文档
访问公共大模型都是通过API的形式,不同模型的API标准略有差异,但基本都兼容OpenAI规范。
可以看到,在文档中有这样一段调用对话的API示例:
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Bash curl https://api.deepseek.com/chat/completions \ -H "Content-Type: application/json" \ -H "Authorization: Bearer <DeepSeek API Key>" \ -d '{ "model": "deepseek-chat", "messages": {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Hello!"} , "stream": false }' |
这段信息就描述了调用DeepSeek大模型的API要求:
- 请求头:
- Content-Type: application/json,请求参数的格式,必须是application/json
- Authorization: Bearer <DeepSeek API Key>,上一节创建的API_KEY
- 请求体:json格式,稍后解释
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| JSON { "model": "deepseek-chat", "messages": {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Hello!"} , "stream": false } |
- 请求方式:虽然没说,但是由于带请求体,所以这里用POST方式
2.1.5 测试
我们可以使用任意的Http客户端来测试API:

注意:需要在请求头中添加刚刚我们注册时准备的API_KEY: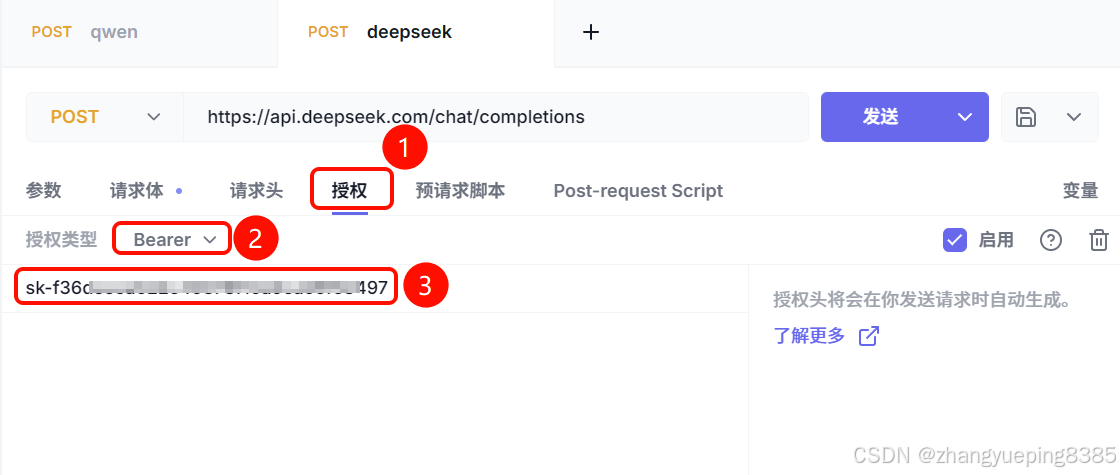
2.2 阿里巴巴百炼模型服务
我们以阿里云百炼平台为例。
2.2.1 注册账号
首先,我们需要注册一个阿里云账号:
|---------------------------------|
| 注意 :账号需要进行个人实名认证,否则后续会有警告~ |
然后访问百炼平台,开通服务:
https://bailian.console.aliyun.com/cn-beijing#/home
首次访问会弹出窗口,询问是否同意开通百炼服务:
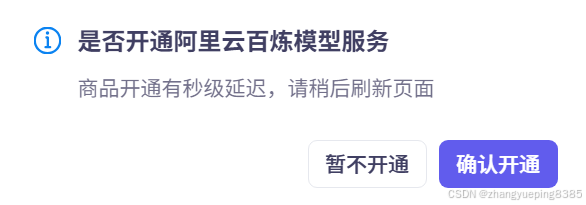
点击确认开通后,如果未进行实名认证,会提醒账户异常:
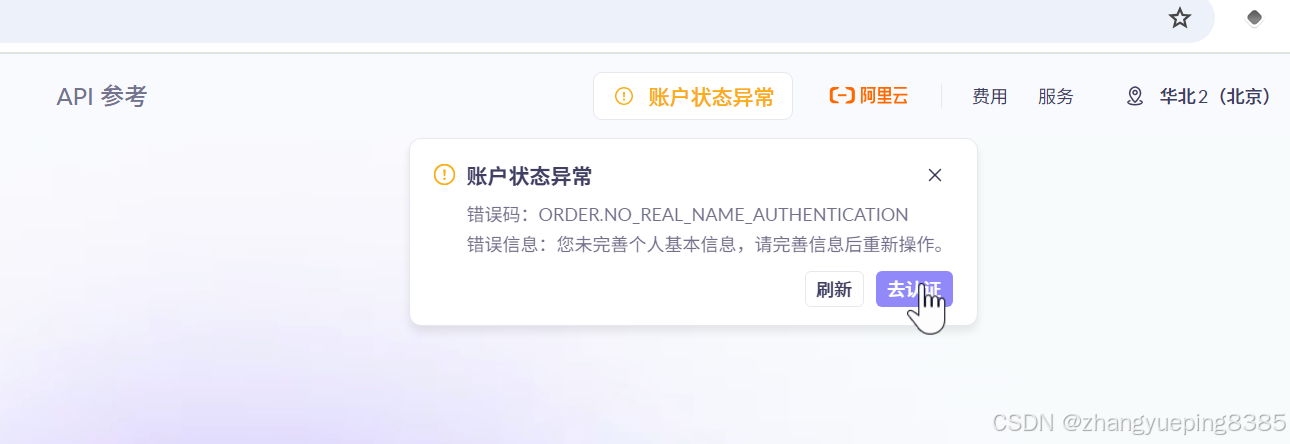
点击去认证,申请个人认证即可,此处略过。
首次开通应该会赠送百万token的使用权,包括DeepSeek-R1模型、qwen模型等等,有效期是3~9个月不等。大家可以在《模型控制台》-> 《模型用量》查看到你的免费额度使用情况:
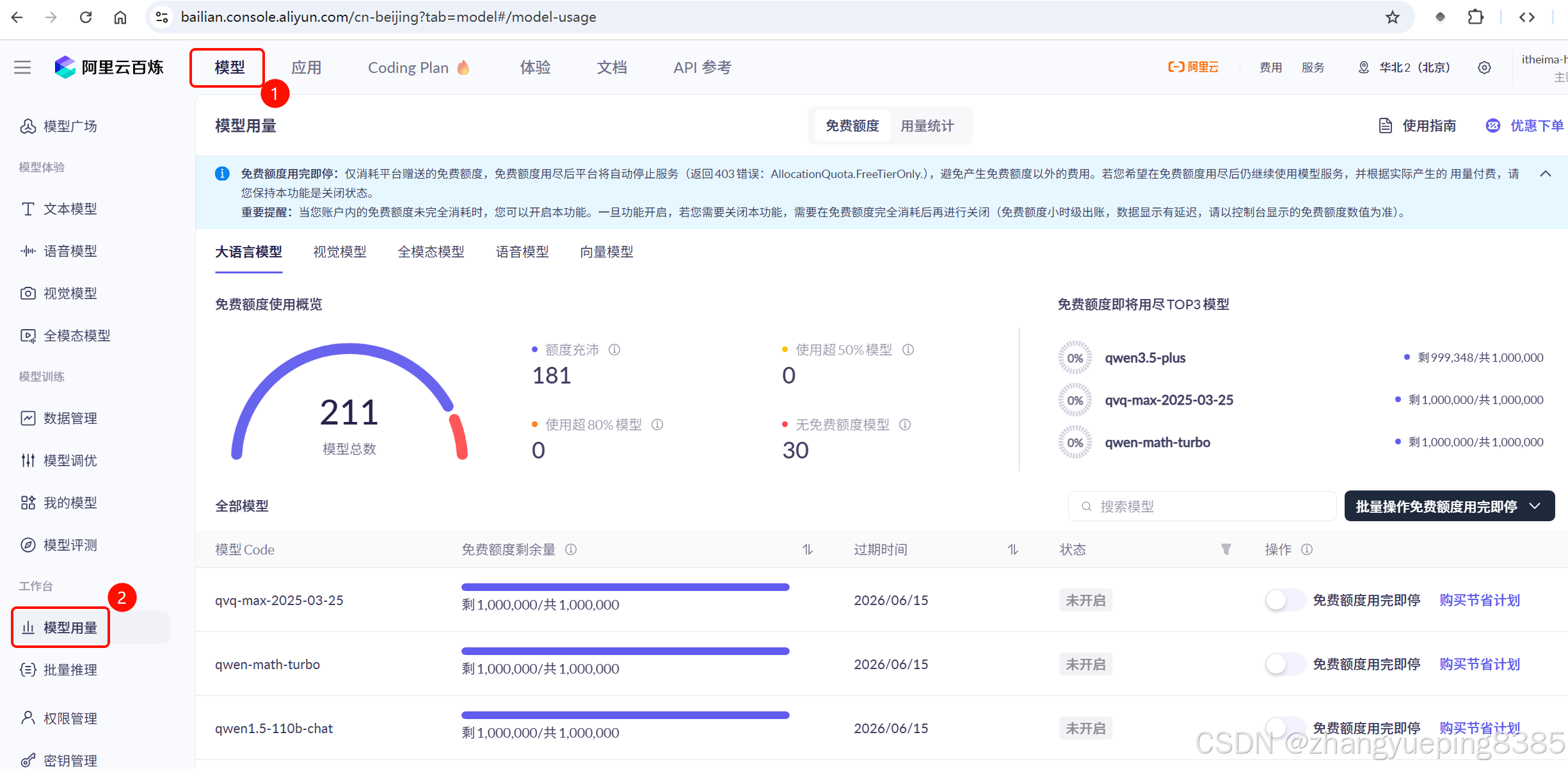
由于阿里爸爸免费赠送了额度,所以我们就跳过充值的过程了。😊
2.2.2 申请 API_KEY
注册账号以后还需要申请一个API_KEY才能访问百炼平台的大模型。
注册成功后进入阿里云百炼首页,点击模型:
在阿里云百炼平台的左侧菜单的最下方,有一个《密钥管理》选项:
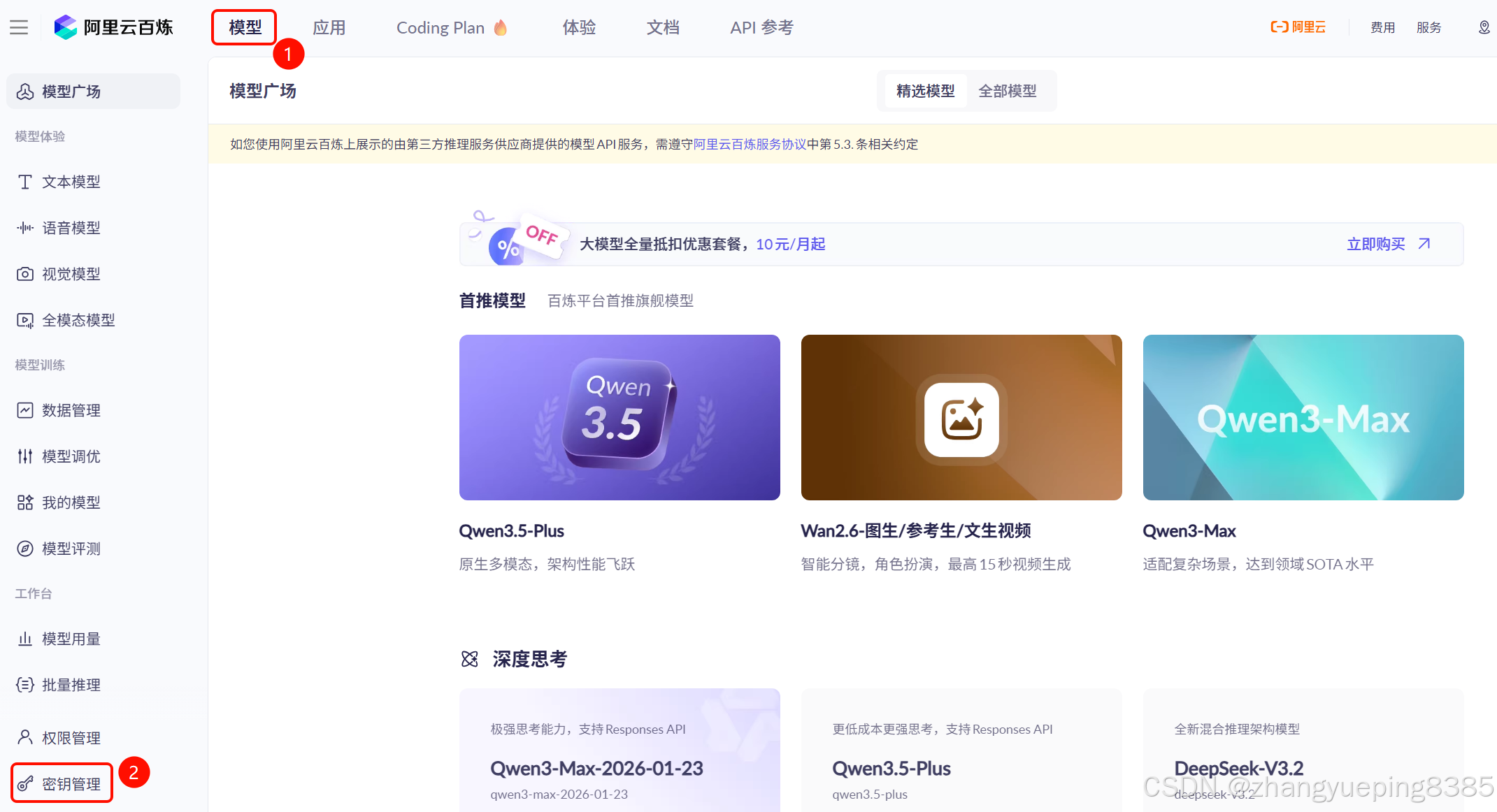
点击后,进入《密钥管理》页面,点击创建API-KEY:
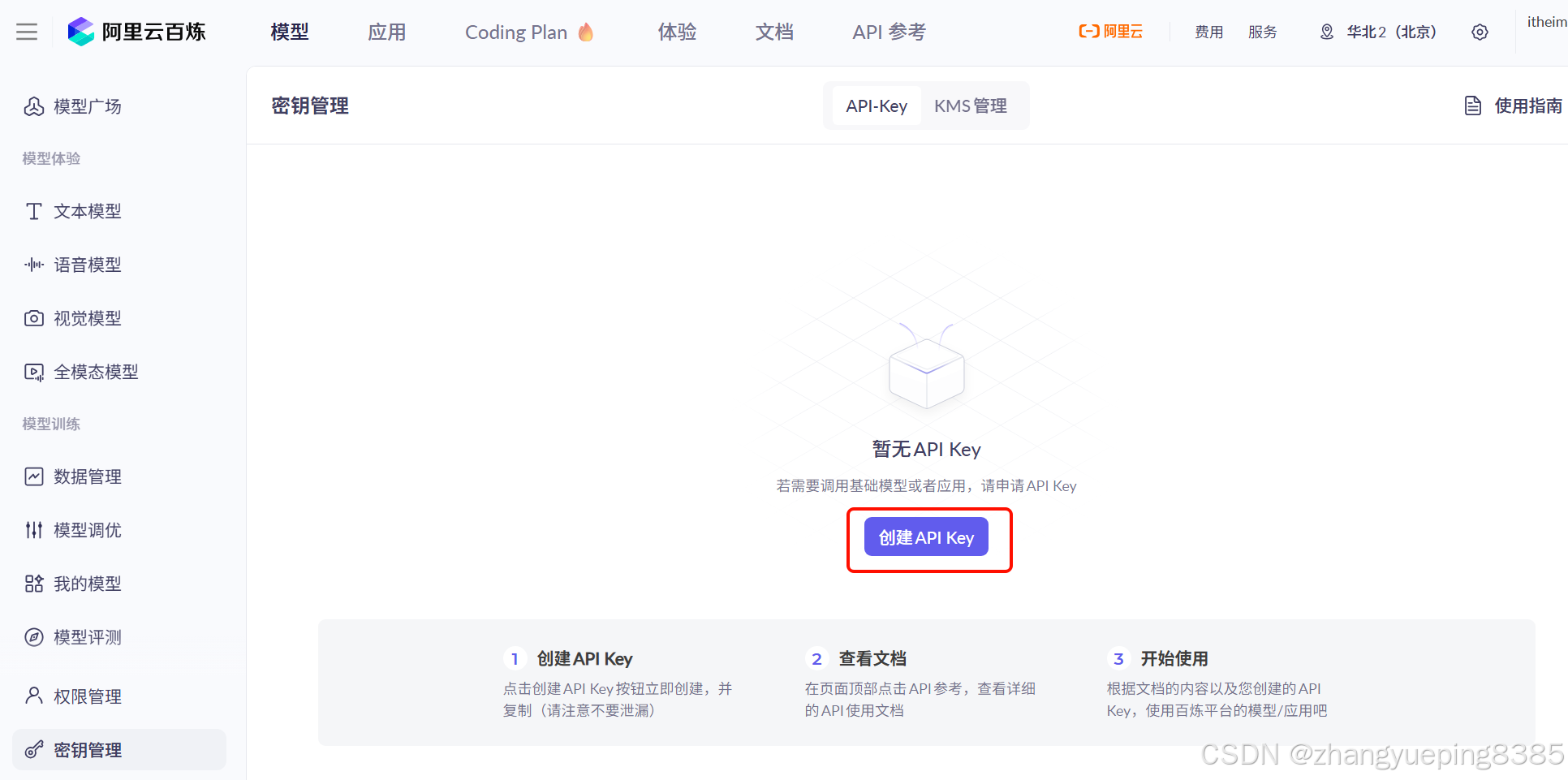
选择创建API-KEY后,会弹出表单,只有一个选项,勾选后点击确定即可:
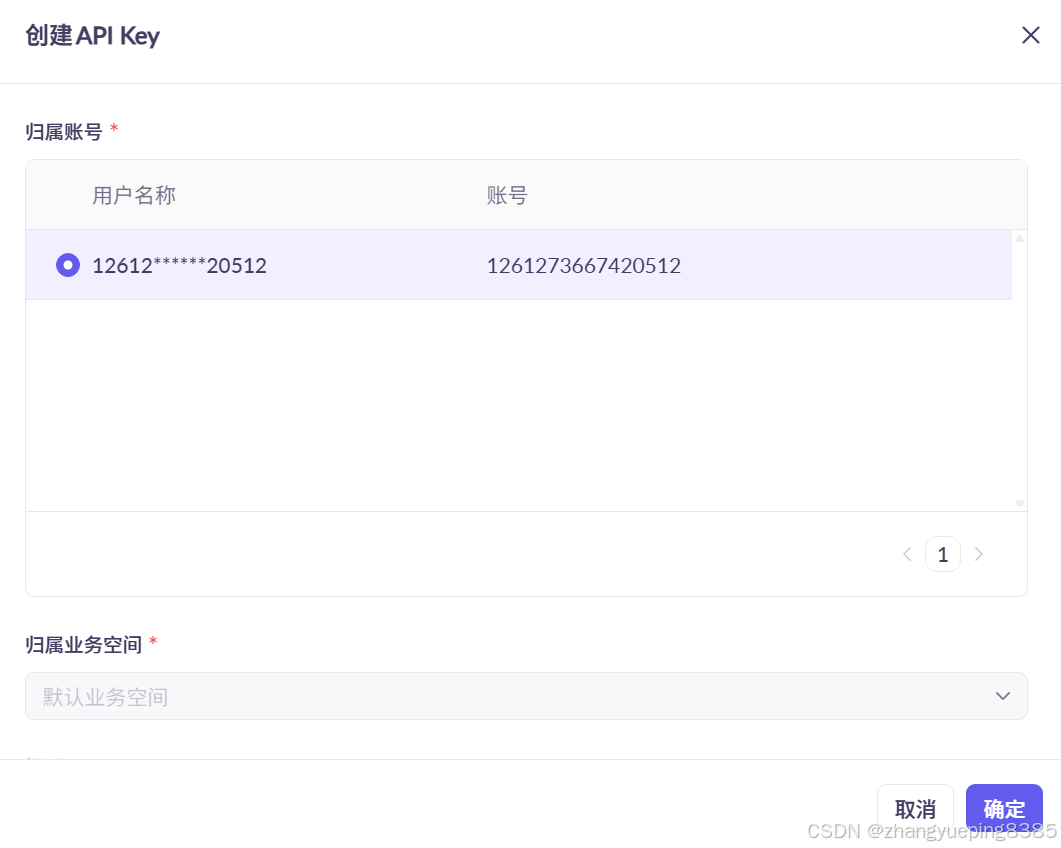
点击确定,即可生成一个新的API-KEY:

后续开发中就需要用到这个API-KEY了,一定要记牢。而且要保密,不能告诉别人。
2.2.3 体验模型
访问百炼平台,点击模型:
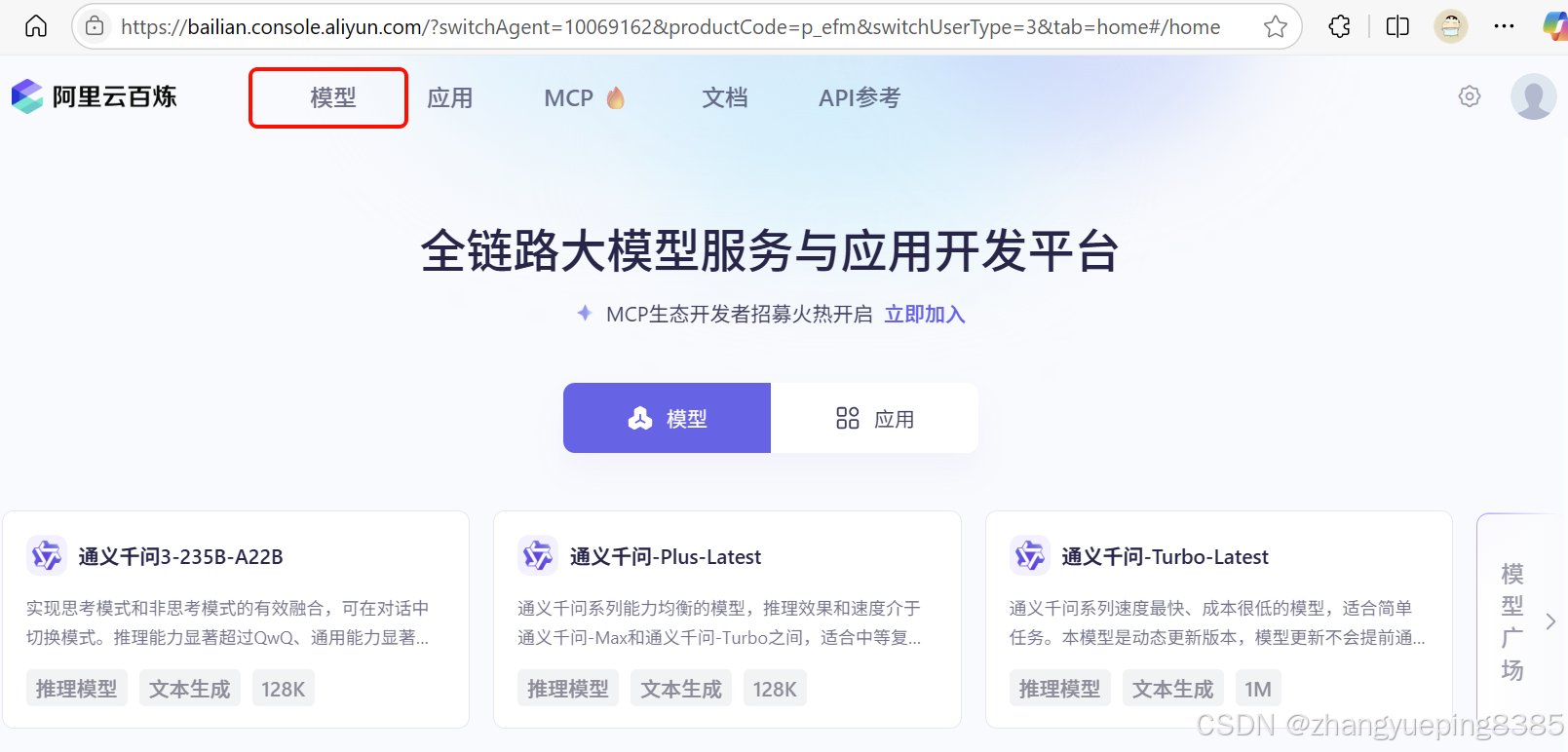
即可进入模型广场:
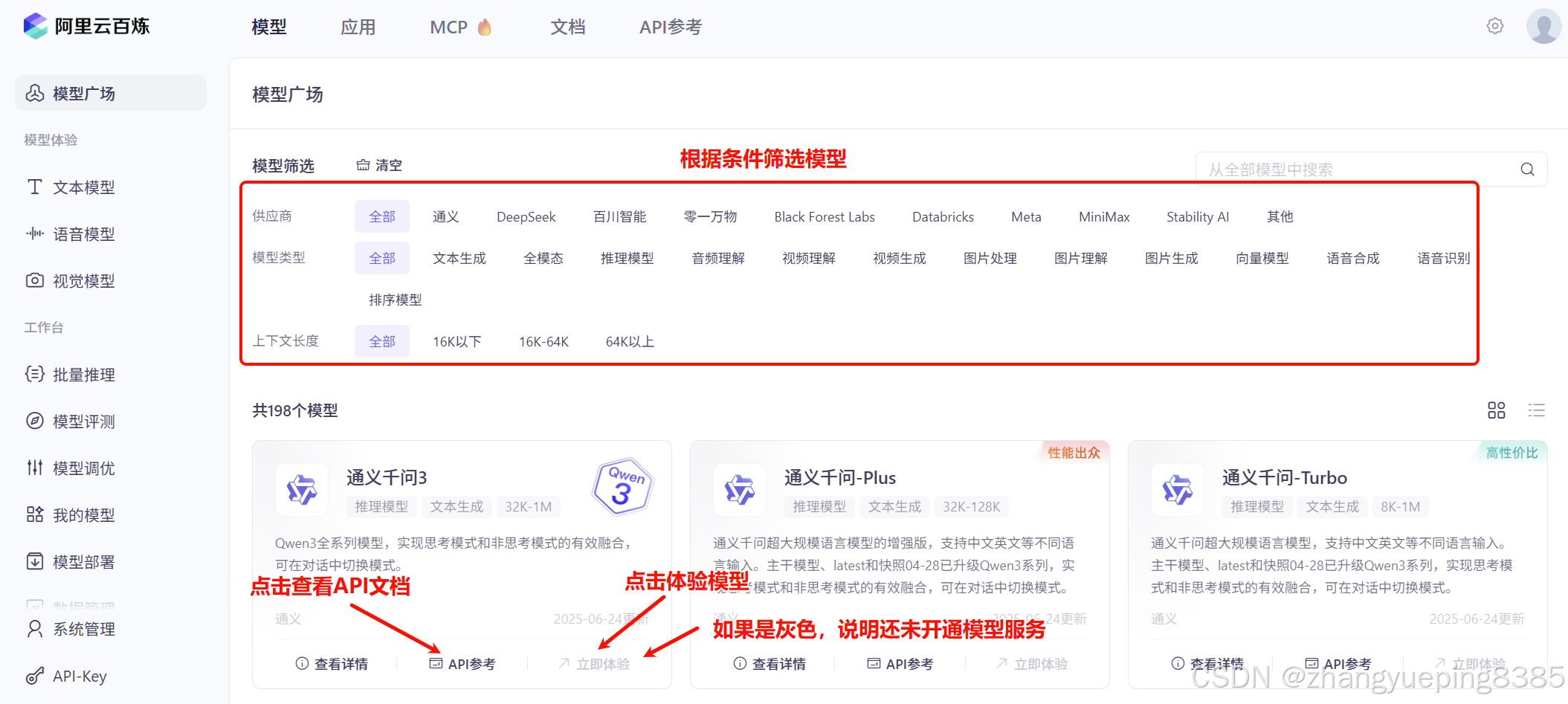
5.2.4 API 文档
点击API参考即可进入API文档页面:
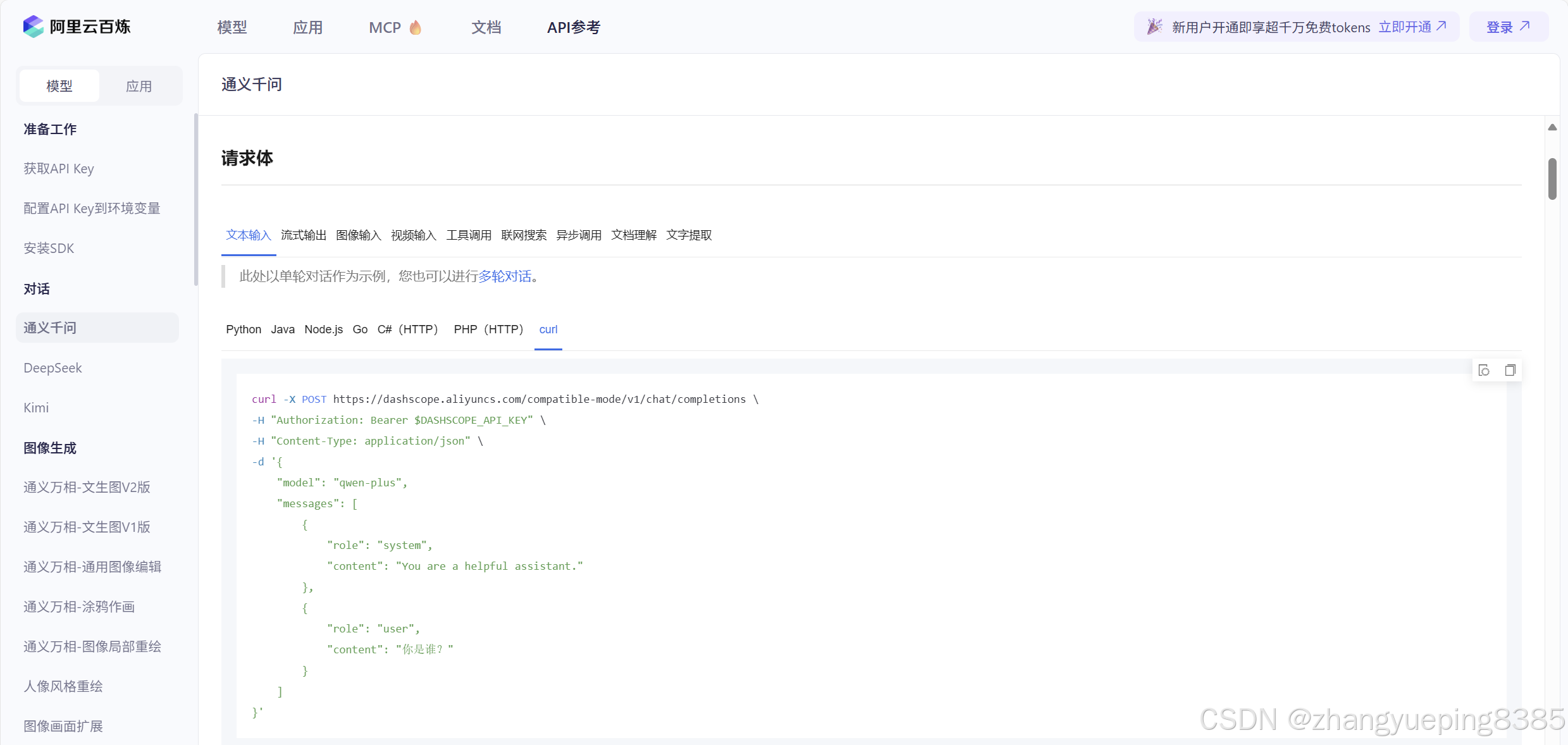
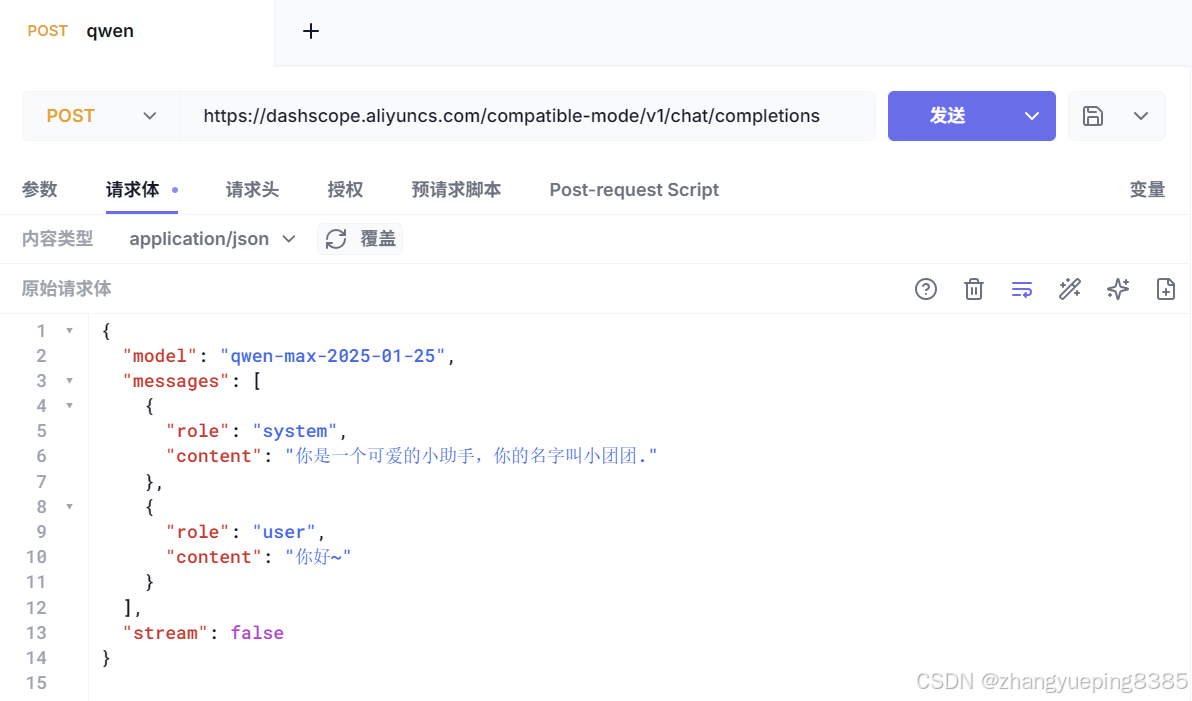
5.2.5 测试
我们使用Http客户端来调试(不要忘了设置 API_KEY):
2.3 本地部署
很多云平台都提供了一键部署大模型的功能,这里不再赘述。我们重点讲讲如何手动部署大模型。
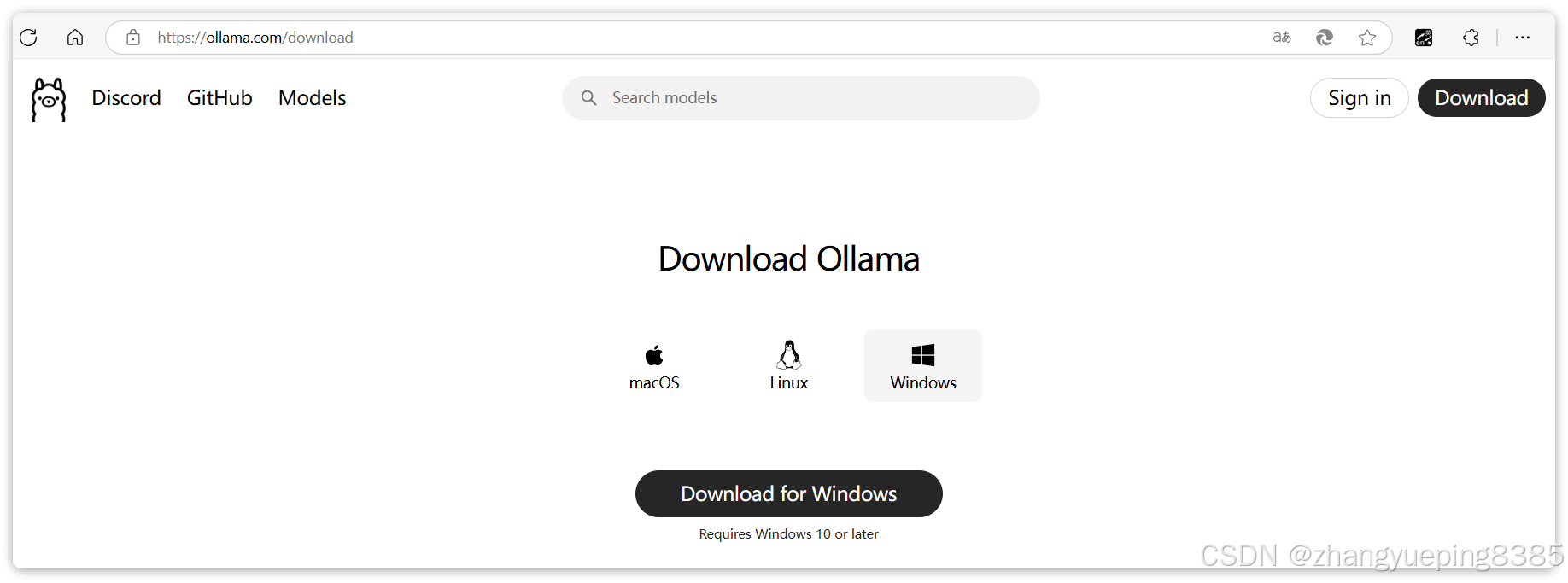
手动部署最简单的方式就是使用Ollama,这是一个帮助你部署和运行大模型的工具。官网如下:
2.3.1 下载安装 ollama
首先,我们需要下载一个Ollama的客户端,在官网提供了各种不同版本的Ollama,大家可以根据自己的需要下载。
下载后双击就会弹出安装界面:
|----------------------------------------------------------------------------------------------------|
| 注意: Ollama默认安装目录是C盘的用户目录,如果不希望安装在****C 盘 的话(其实C盘如果足够大放C盘也没事),就不能直接双击安装了。需要通过命令行安装。 |
命令行安装方式如下:
在OllamaSetup.exe所在目录打开cmd命令行,然后命令如下:
|-------------------------------------|
| Bash OllamaSetup.exe /DIR=你要安装的目录位置 |
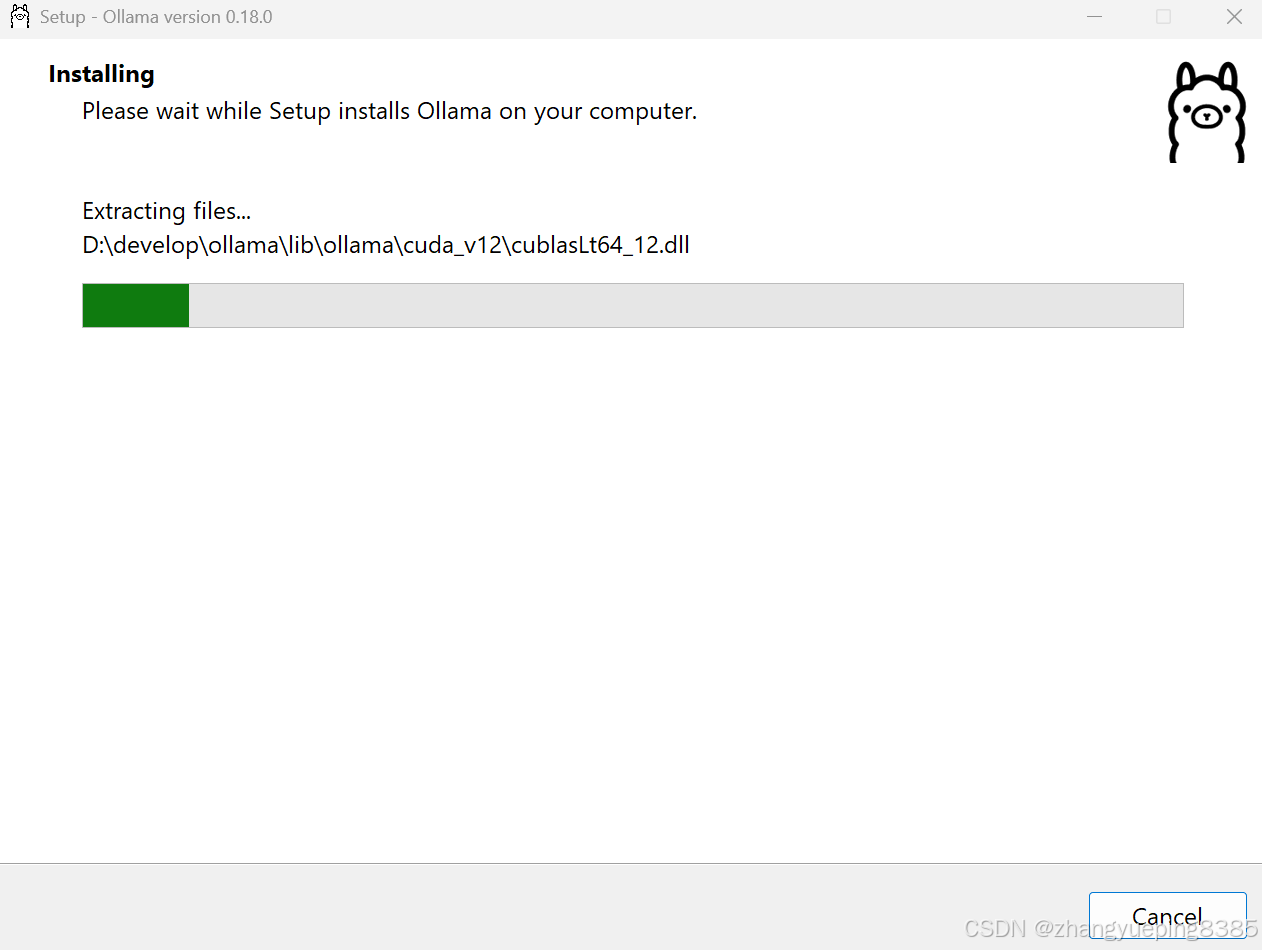
运行命令后,同样会弹出刚才的安装窗口,但是安装的位置已经是你设定的位置了。
点击Install即可安装,可以看到安装目录是自定义的D盘,而不是C盘:
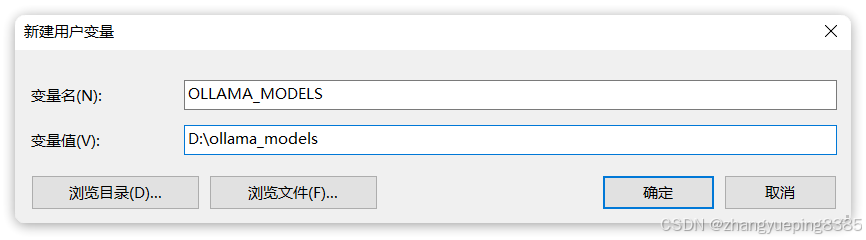
OK,安装完成后,还需要配置一个环境变量,更改Ollama下载和部署模型的位置。环境变量如下:
|-------------------------------|
| Bash OLLAMA_MODELS=你想要保存模型的目录 |
环境变量配置方式相信学过Java的都知道,这里不再赘述,配置完成如图:
2.3.2 搜索模型
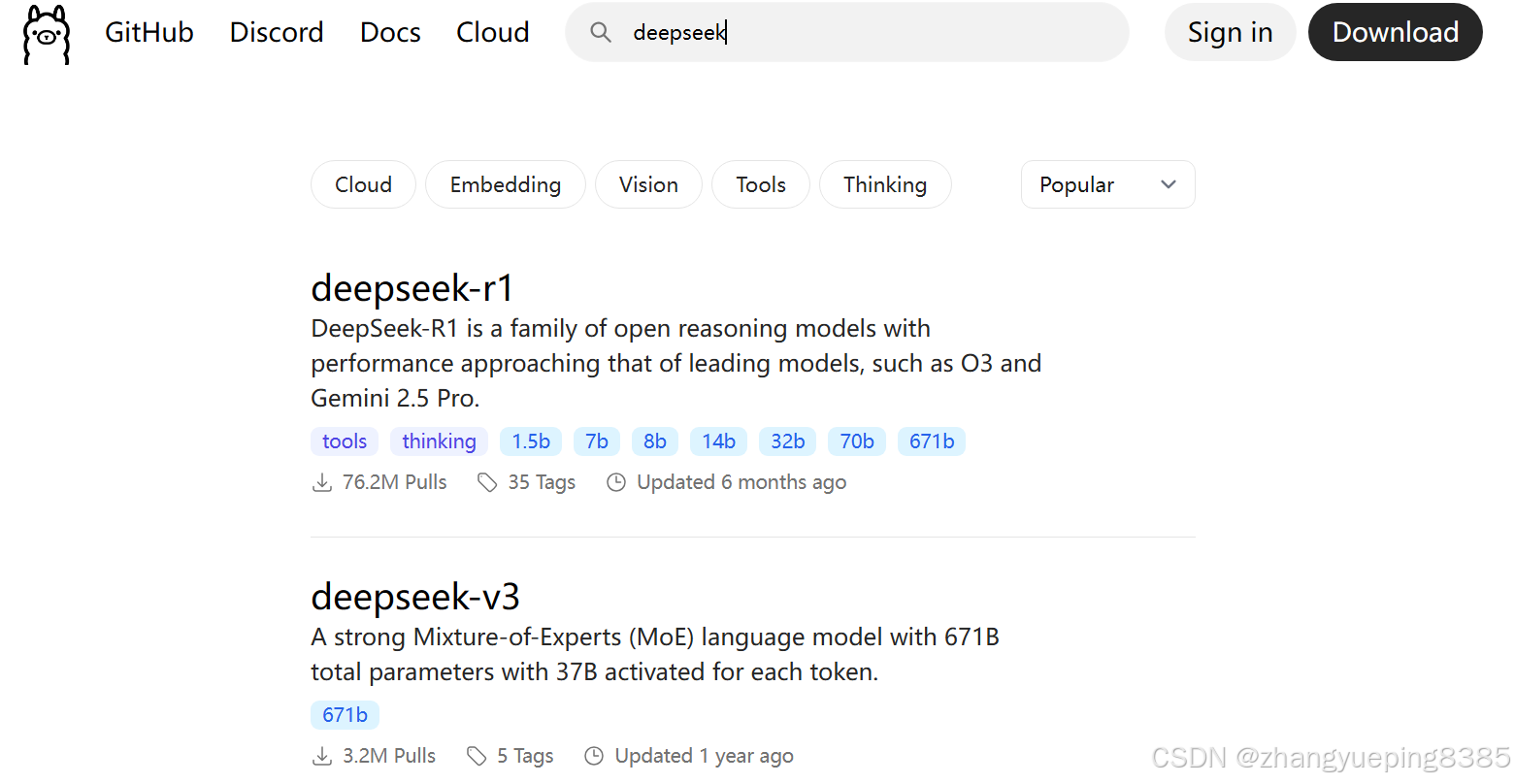
ollama是一个模型管理工具和平台,它提供了很多国内外常见的模型,我们可以在其官网上搜索自己需要的模型:
如图,搜索deepseek,可以看到排在第一的是deepseek-r1:
点击进入deepseek-r1页面,会发现deepseek-r1也有很多版本:
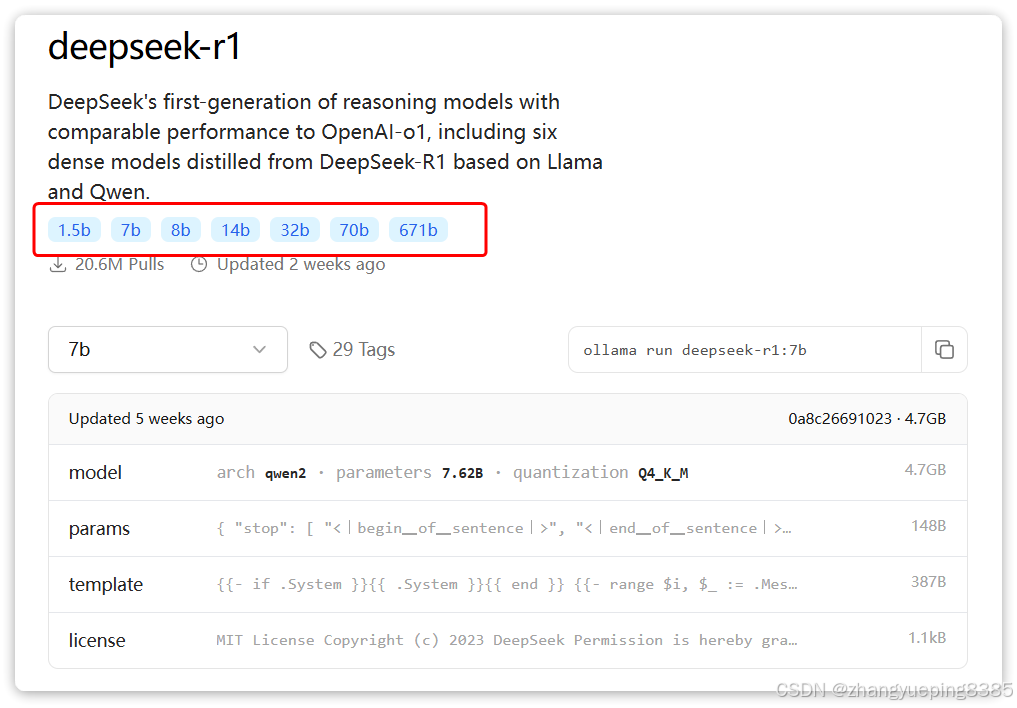
这些就是模型的参数大小,越大推理能力就越强,需要的算力也越高。671b版本就是最强的满血版deepseek-r1了。需要注意的是,Ollama提供的DeepSeek是量化压缩版本,对比官网的蒸馏版会更小,对显卡要求更低。对比如下:
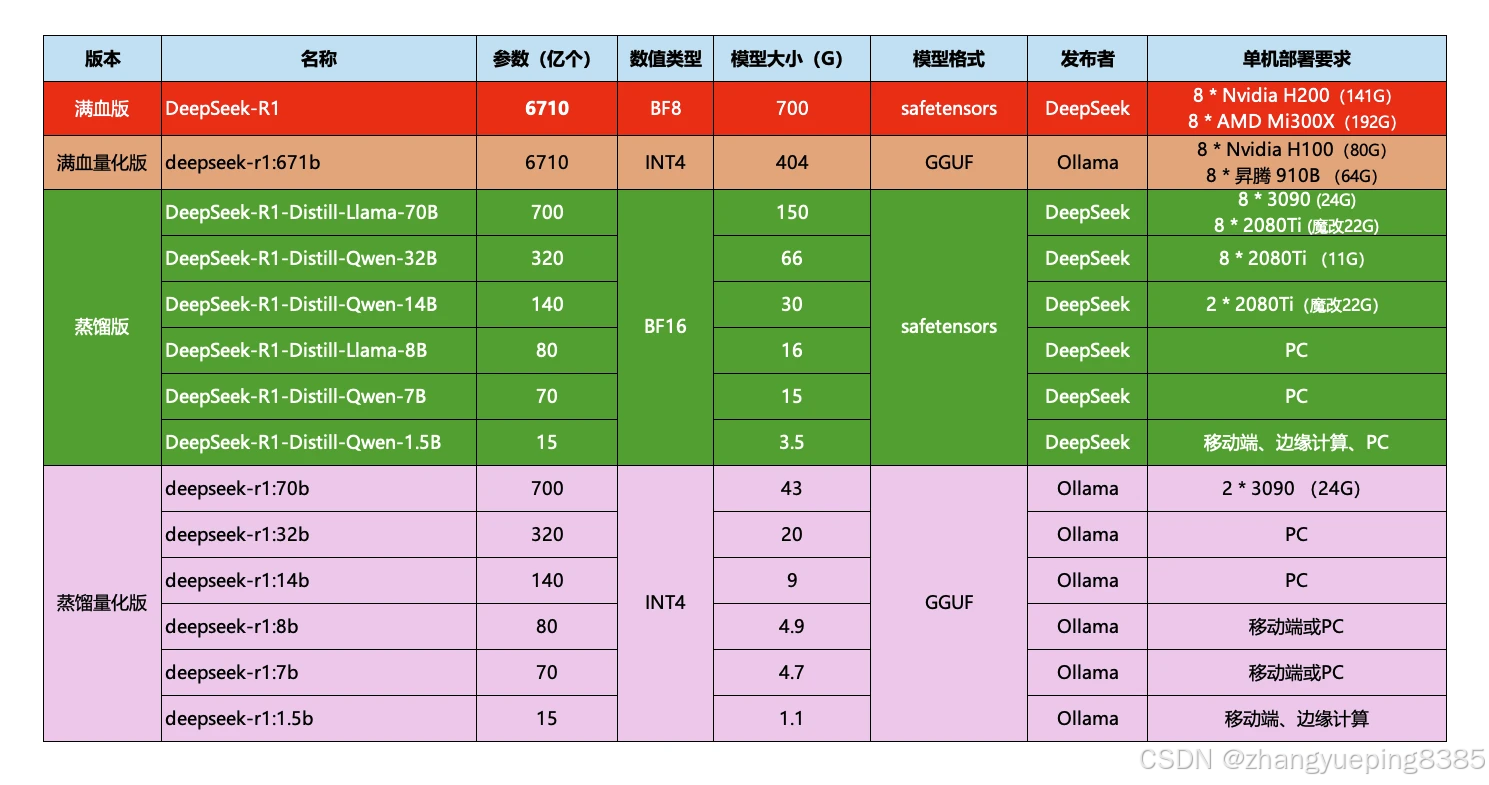
比如,我的电脑内存32G,显存是6G,我选择部署的是7b的模型,当然8b也是可以的,差别不大,都是可以流畅运行的。
2.3.3 运行模型
选择自己合适的模型后,ollama会给出运行模型的命令:
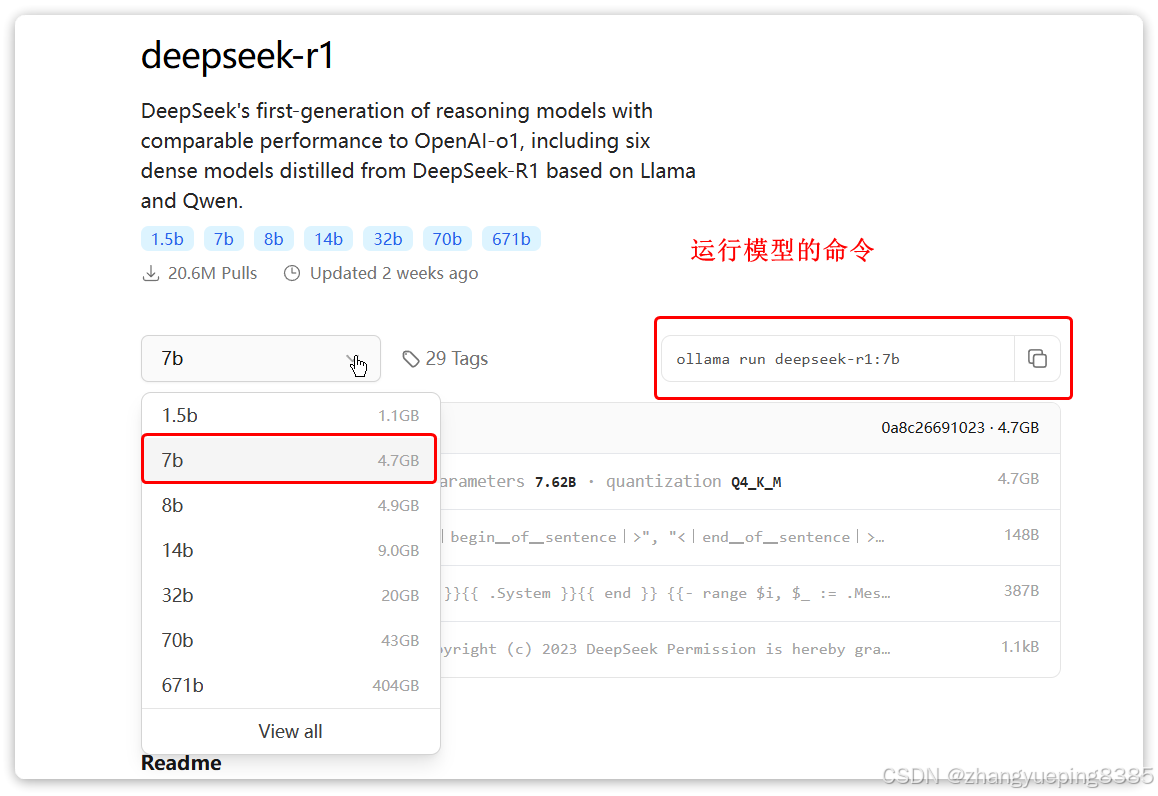
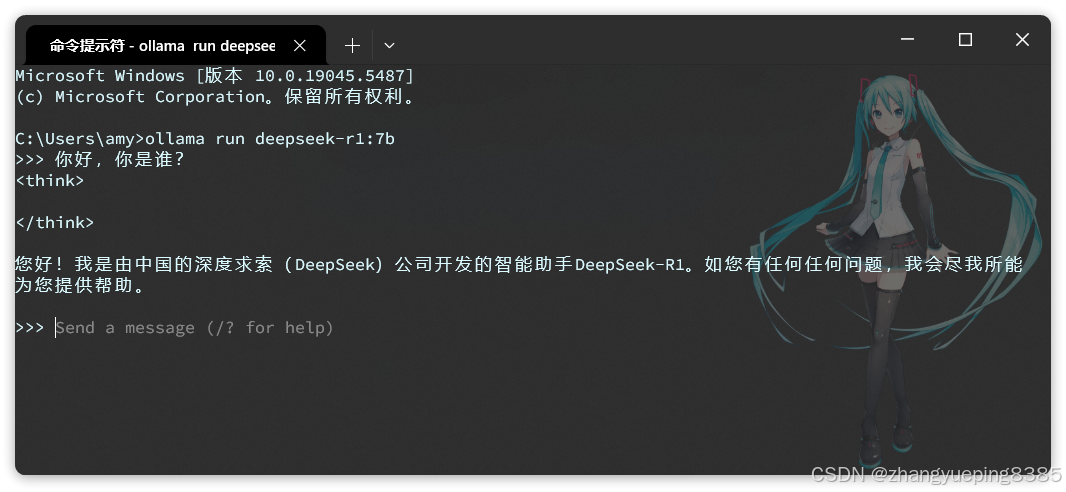
复制这个命令,然后打开一个cmd命令行,运行命令即可,然后你就可以跟本地模型聊天了:
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 注意: * 首次运行命令需要下载模型,根据模型大小不同下载时长在5分钟~1小时不等,请耐心等待下载完成。 * ollama控制台是一个封装好的AI对话产品,与ChatGPT类似,具备会话记忆功能。 * ollama也提供了供程序访问的HTTP接口,默认地址是http://127.0.0.1:11434/api/chat |
Ollama是一个模型管理工具,有点像Docker,而且命令也很像,比如:
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Bash ollama serve # Start ollama ollama create # Create a model from a Modelfile ollama show # Show information for a model ollama run # Run a model ollama stop # Stop a running model ollama pull # Pull a model from a registry ollama push # Push a model to a registry ollama list # List models ollama ps # List running models ollama cp # Copy a model ollama rm # Remove a model ollama help # Help about any command |
2.3.4 测试 API
Ollama在本地部署时,会自动提供模型对应的Http接口,访问地址是:http://localhost:11434/api/chat
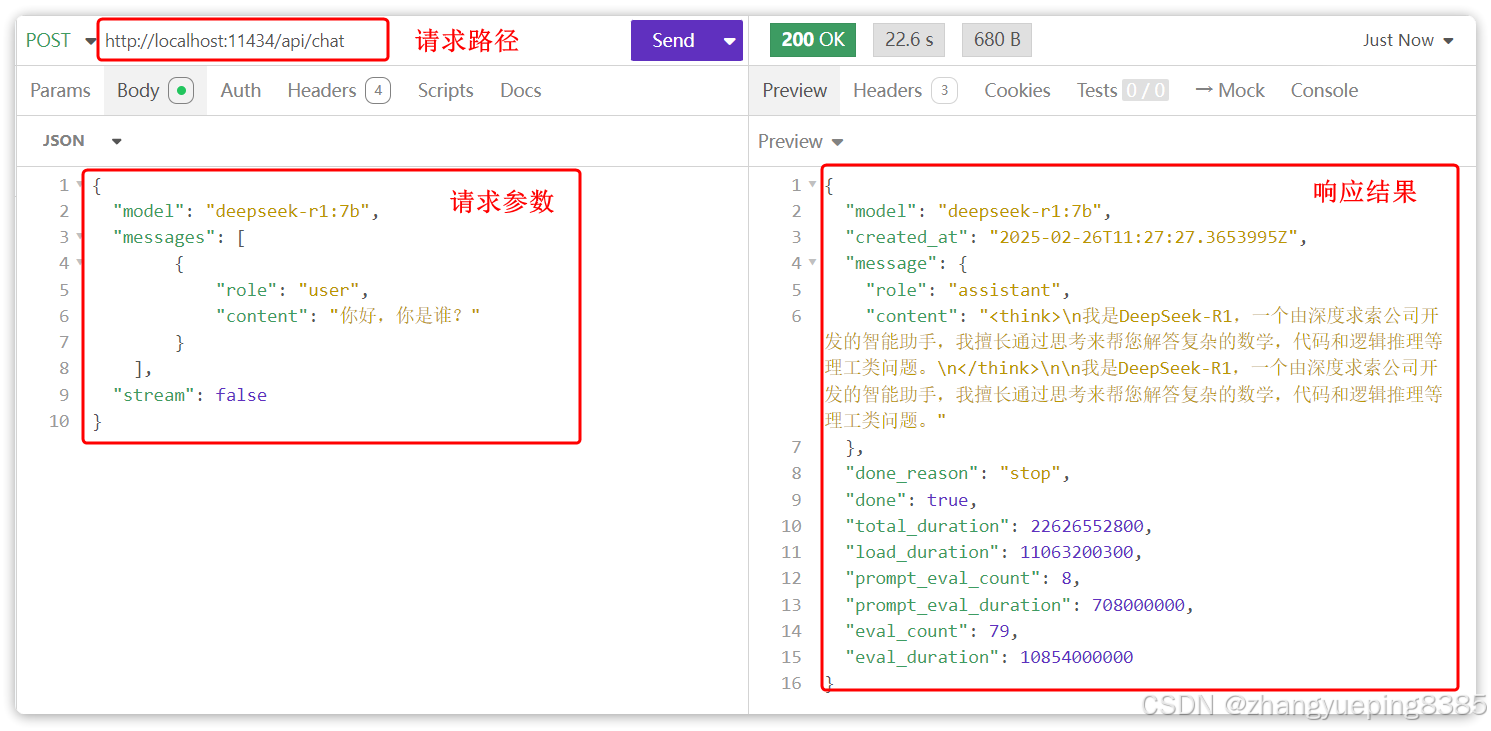
3. 大模型 API
前面说过,大模型开发并不是在浏览器中跟AI聊天。而是通过访问模型对外暴露的 API 接口,实现与大模型的交互。
所以要学习大模型应用开发,就必须掌握模型的API接口规范。
目前大多数大模型都遵循OpenAI的接口规范,是基于Http协议的接口。因此请求路径、参数、返回值信息都是类似的,可能会有一些小的差别。具体需要查看大模型的官方API文档。
3.1 大模型接口规范
我们以DeepSeek官方给出的文档为例:
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Bash curl -X POST https://api.deepseek.com/chat/completions \ -H "Content-Type: application/json" \ -H "Authorization: Bearer <DeepSeek API Key>" \ -d '{ "model": "deepseek-chat", "messages": { "role": "system", "content": "You are a helpful assistant." }, { "role": "user", "content": "Hello!" } , "stream": false }' |
3.1.1 接口说明
- 请求方式:通常是POST,因为要传递JSON风格的参数
- 请求 URL:与平台有关
- DeepSeek官方平台:https://api.deepseek.com/chat/completions
- 本地ollama部署的模型:http://localhost:11434
- 请求头:开放平台都需要提供API_KEY来校验权限,本地ollama则不需要
- Content-Type: application/json,请求参数的格式,必须是application/json,稍后解释
- Authorization: Bearer <DeepSeek API Key>,上一节创建的API_KEY
- 请求参数:JSON格式:
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| JSON { "model": "deepseek-chat", "messages": {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Hello!"} , "stream": false } |
- model:模型名称,DeepSeek支持deepseek-reasoner和deepseek-chat两者模型
- messages:发送给大模型的消息,\[\]是数组的意思,里面可以有多条消息。消息结构:
- content:是消息的内容
- role:消息的角色,有system、user、assisant三种角色
- system:是给大模型设定一个角色,比如你让她扮演你的奶奶,让她哄你睡觉
- user:就是用户提问的问题
- assisant:是大模型的回答
- stream:true,代表响应结果流式返回;false,代表响应结果一次性返回,但需要等待
注意,这里请求参数中的messages是一个消息数组,而且其中的消息要包含两个属性:
- role:消息对应的角色
- content:消息内容
其中System和User消息的内容,也被称为提示词 (Prompt ),也就是用户发送给大模型的指令。
- System提示词,是系统指令,给大模型设定一个角色,比如你让她扮演你的奶奶,让她哄你睡觉
- User提示词,是用户指令,也就是用户向大模型的提问或命令
3.1.2 提示词角色
通常消息的角色有三种:
|---------------|--------------------------------------|----------------------------------|
| 角色 | 描述 | 示例 |
| system | 优先于user指令之前的指令,也就是给大模型设定角色和任务背景的系统指令 | 你是一个乐于助人的编程助手,你以小团团的风格来回答用户的问题。 |
| user | 终端用户输入的指令(类似于你在ChatGPT聊天框输入的内容) | 写一首关于Java编程的诗 |
| assistant | 由大模型生成的消息,可能是上一轮对话生成的结果 | 注意,用户可能与模型产生多轮对话,每轮对话模型都会生成不同结果。 |
其中System类型的消息非常重要!影响了后续AI会话的行为模式。
比如,我们会发现,当我们询问这些AI对话产品"你是谁"这个问题的时候,每一个AI的回答都不一样,这是怎么回事呢?
这其实是因为AI对话产品并不是直接把用户的提问发送给LLM,通常都会在user提问的前面通过System消息给模型设定好背景:
所以,当你问问题时,AI就会遵循System的设定来回答了。因此,不同的大模型由于System设定不同,回答的答案也不一样
示例:
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Bash ## Role System: 你是一家名为《黑马程序员》的职业教育培训公司的智能客服,你的名字叫小黑。请以友好、热情的方式回答用户问题。 ## Example User : 你好 Assisant: 你好,我是小黑,很高兴认识你!😊 你是想了解我们的课程信息,还是有其他关于职业培训的问题需要咨询呢?无论什么问题,我都会尽力帮你解答哦! |
3.2 会话记忆问题
这里还有一个问题:
|----------------------------------|
| 我们为什么要把历史消息都放入Messages中,形成一个数组呢? |
大模型的API接口是"无状态"的,服务端不会记录用户请求的上下文。因此我们调用API接口与大模型对话时,每一次对话信息都不会保留,多次对话之间都是独立的,没有关联的。
因此大模型并不知道之前的聊天历史,也就是说大模型是没有记忆的。
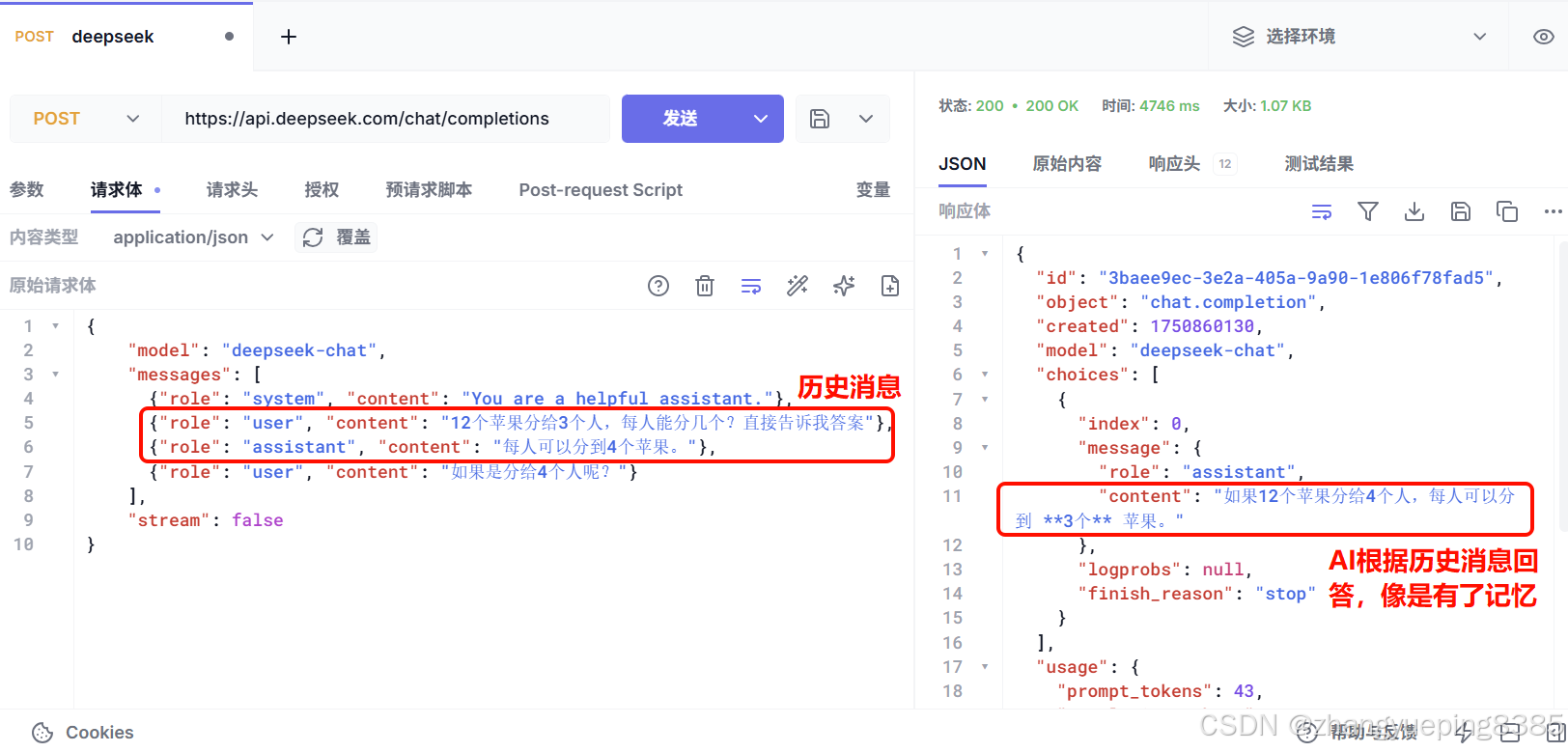
测试,我询问AI一个问题:12个苹果分给3个人,每人能分几个?
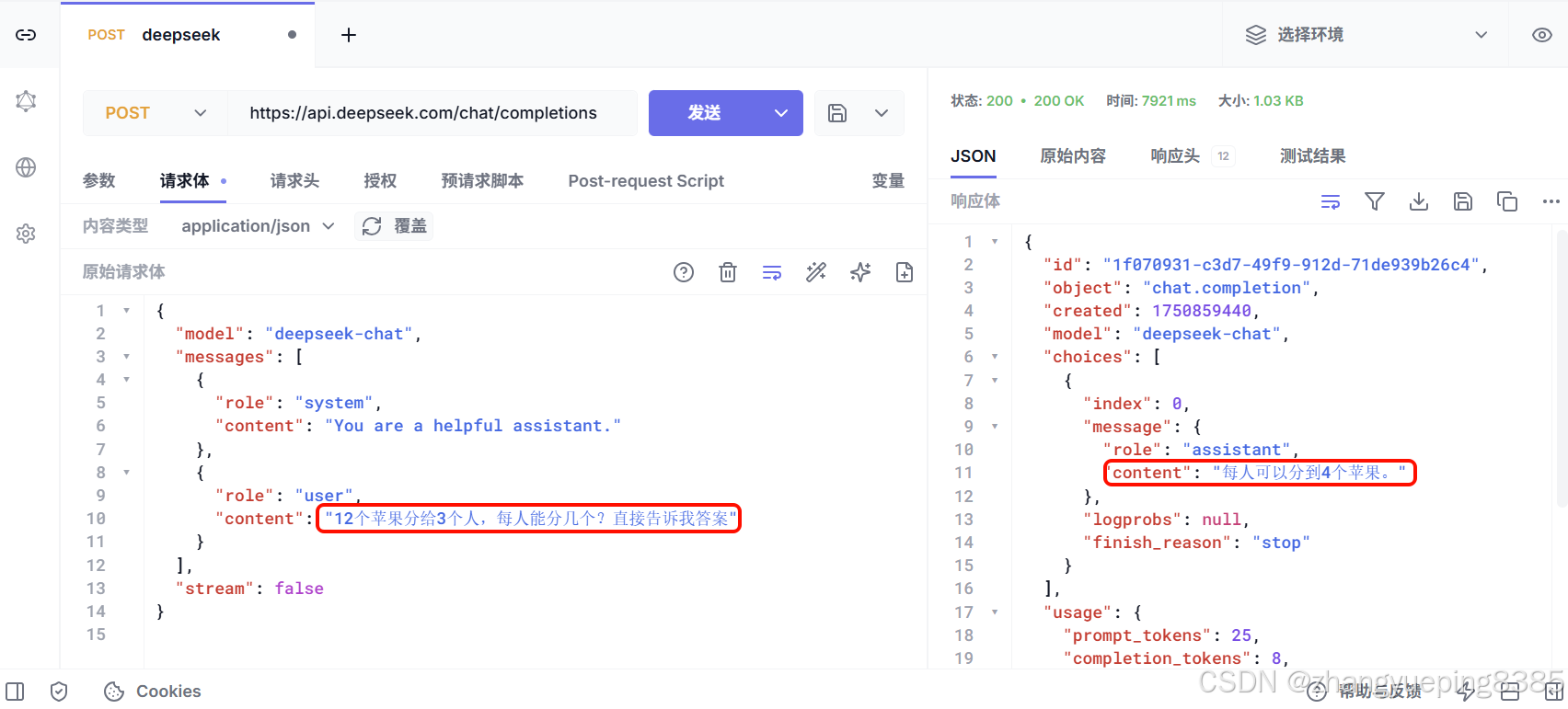
AI的答案是:每人可以分到4个苹果。
我们接着问:如果是分给4个人呢?,由于AI没有记忆,它不知道我是接着上一题问的,因此不知道要分的是12个苹果,答案就有问题:
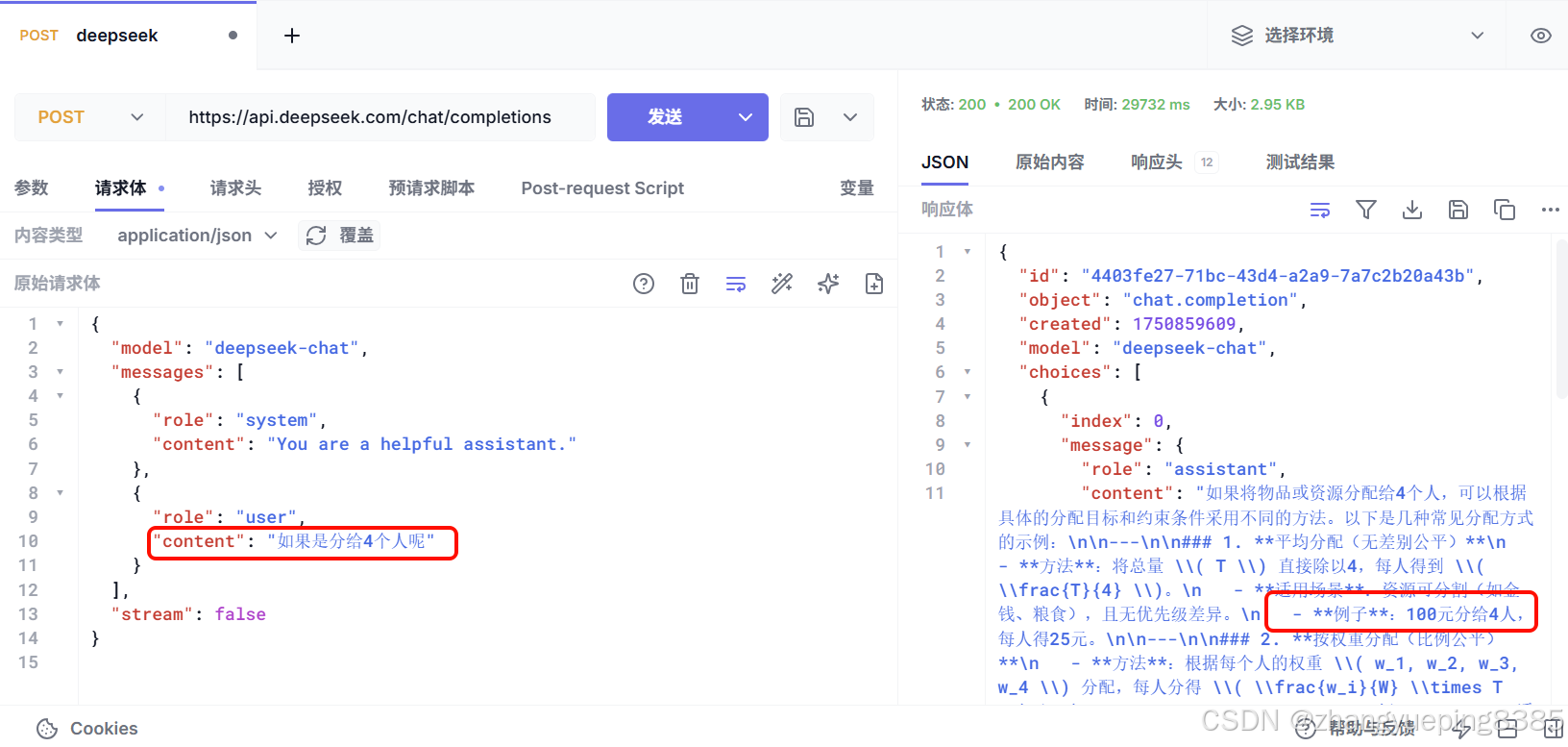
可以看到,AI完全不知道我们聊天的背景是上一次的分12个苹果。
那么,如何才能让AI具备记忆呢?
要想让大模型有记忆,必须在每次请求时,将之前所有对话的历史拼接好,传递给对话 API 接口。
要想让AI具备记忆,就必须把对话历史都添加到请求体中的messages数组中,像这样:
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| JSON { "model": "deepseek-chat", "messages": {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "12个苹果分给3个人,每人能分几个?直接告诉我答案"}, {"role": "assistant", "content": "每人可以分到4个苹果。"}, {"role": "user", "content": "如果是分给4个人呢?"} , "stream": false } |
测试结果:
好了,现在我们能用图形界面的Http客户端发送http请求,调用大模型了。
但是这样还不够,如果要开发AI应用,肯定是要通过编程的方式发送Http请求,调用大模型。
3.3 开发环境准备
现在,我们已经掌握了大模型提供的API接口规范了,不过,最终我们还是要用编程的方式来访问大模型。
所以,接下来就让我们准备好开发的 环境吧。
3.3.1 安装 UV
Python的环境管理方案有很多种,例如:
- pip
- uv
- conda
- ...
在后面的课程中我们会选择uv作为项目管理工具,其官网如下:
** **该类型的内容暂不支持下载** **
还有个第三方写的中文文档:
** **该类型的内容暂不支持下载** **
它有非常多的优点:

最简单的安装方案就是使用pip:
|---------------------|
| Bash pip install uv |
3.3.2 添加镜像源
默认情况下,uv下载依赖是到国外站点:https://test.pypi.org/simple,速度很慢。推荐大家将下载的镜像源改为国内站点。
uv支持项目级配置和系统级配置两种方案,项目级优先级高,但是需要每个项目都配置,比较麻烦。推荐采用系统级配置。
系统配置方式如下:
- Windows系统,在CMD运行如下命令:
|-----------------------------------------------------------------------|
| Bash setx UV_DEFAULT_INDEX "https://pypi.tuna.tsinghua.edu.cn/simple" |
- MacOS或Linux系统:
|-------------------------------------------------------------------------------------------------------------------|
| Bash echo 'export UV_DEFAULT_INDEX=https://pypi.tuna.tsinghua.edu.cn/simple' >> ~/.zshrc && source ~/.zshrc |
常见的国内镜像站点有:
阿里云
|----------------------------------------------------|
| Plain Text https://mirrors.aliyun.com/pypi/simple/ |
腾讯云
|-----------------------------------------------------------|
| Plain Text https://mirrors.cloud.tencent.com/pypi/simple/ |
火山引擎
|----------------------------------------------------|
| Plain Text https://mirrors.volces.com/pypi/simple/ |
华为云
|--------------------------------------------------------------------|
| Plain Text https://mirrors.huaweicloud.com/repository/pypi/simple/ |
清华大学
|------------------------------------------------------|
| Plain Text https://pypi.tuna.tsinghua.edu.cn/simple/ |
中国科学技术大学
|-----------------------------------------------------|
| Plain Text https://pypi.mirrors.ustc.edu.cn/simple/ |
3.3.3 创建项目
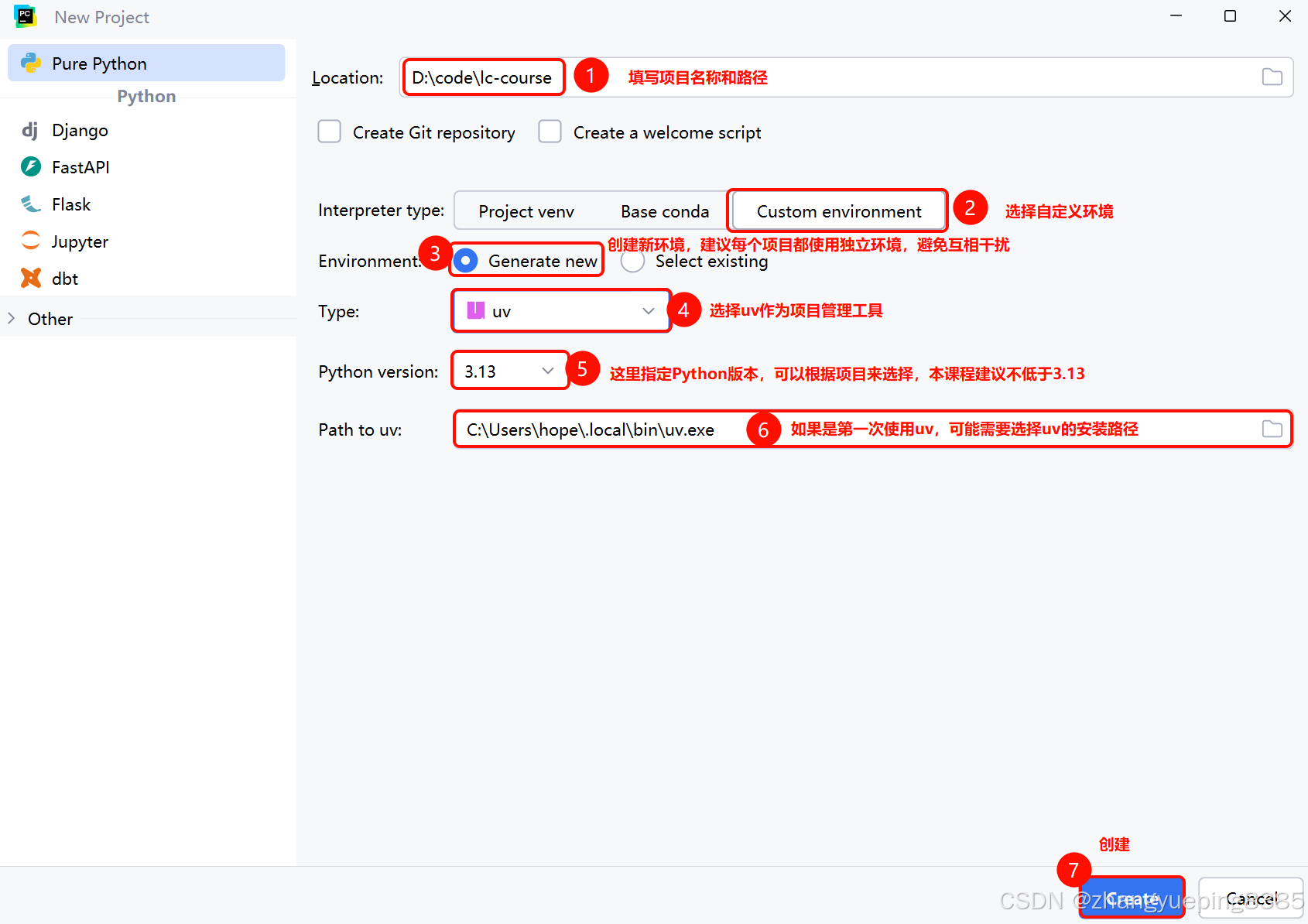
接下来我们就创建一个项目,我们会使用PyCharm作为开发工具,以uv作为项目管理工具。
第一步,打开PyCharm,创建Project:
为了方便大家学习,我们会使用jupyter,所以需要在项目中引入notebook依赖。
在PyCharm中,左侧有一个Terminal按钮,点击即可打开终端:
如图:
在终端中输入命令:
|----------------------|
| Bash uv add notebook |
3.3.4 测试
为了测试环境,我们创建一个notebook试试:
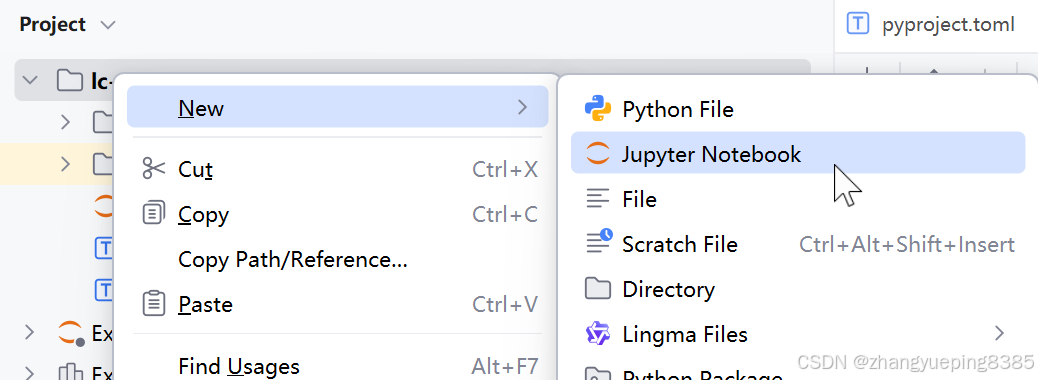
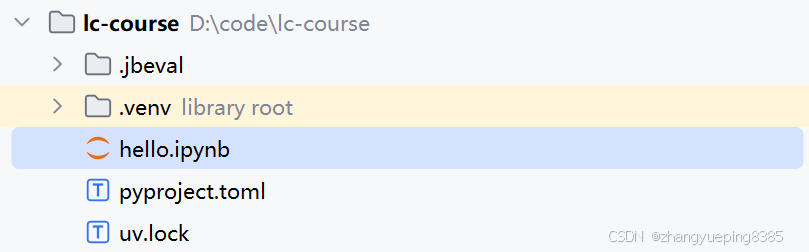
起名为hello:

如图:
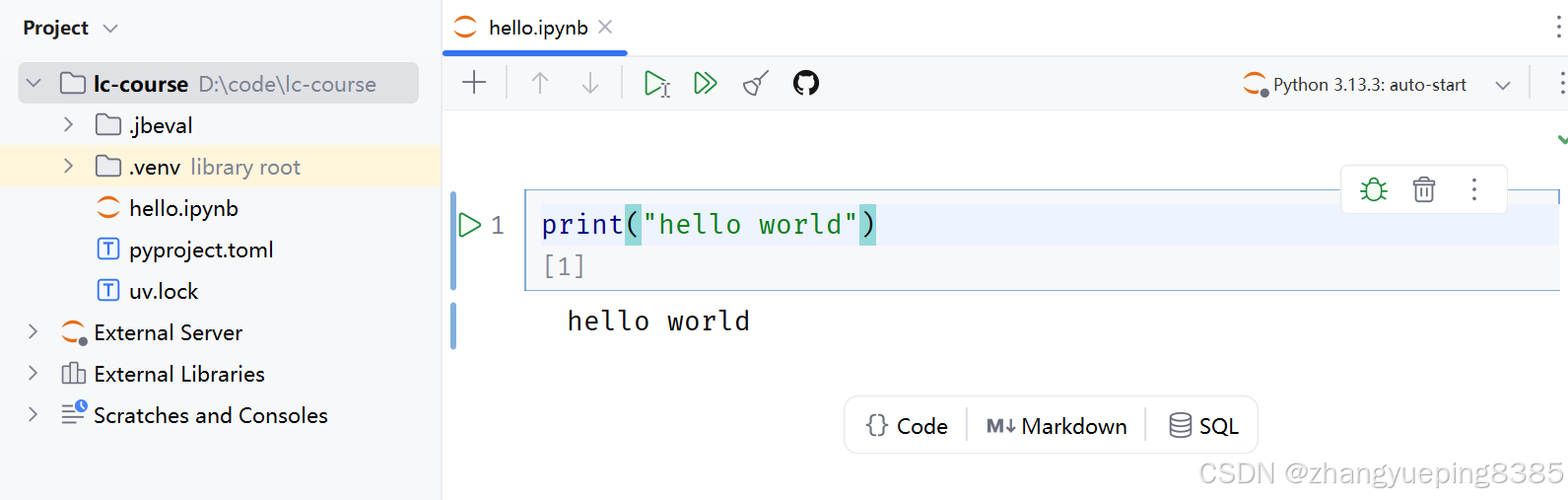
然后在代码框中编写打印HelloWorld的代码,快捷键SHIFT + ENTER即可运行::
3.4 OpenAI
OpenAI作为全球最早,也是最火的大模型公司之一,占据了先发优势。因此其制定的API规范几乎成为了大模型API的默认规范,几乎所有的大模型API都兼容OpenAI的规范。
在任何模型的官方文档中都能看到基于OpenAI提供的SDK的代码示例,例如DeepSeek:
本节我们来学习如何使用OpenAI提供的SDK工具来访问大模型。
3.4.1 基本使用
首先,我们需要安装OpenAI的SDK,以python为例:
- 使用pip安装:
|-------------------------|
| Bash pip install openai |
- 使用uv安装:
|--------------------|
| Bash uv add openai |
接下来,就可以使用SDK调用任何兼容OpenAI规范的模型了,只要将base_url和api_key设定为对应的模型提供者的url和api_key即可:
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python from openai import OpenAI client = OpenAI( api_key="sfxxxxx", base_url="https://api.deepseek.com" ) print("🚀 正在调用大模型...") response = client.chat.completions.create( model="deepseek-chat", messages= {"role": "system", "content": "你是一名友好的AI助教。"}, {"role": "user", "content": "你好,你是谁?"} , stream=False ) print(response) |
3.4.2 环境变量
将api_key直接写在代码中非常危险,所以通常我们都将其写入环境变量,程序运行时加载。
第一步,配置环境变量。
在项目根目录创建一个.env文件:
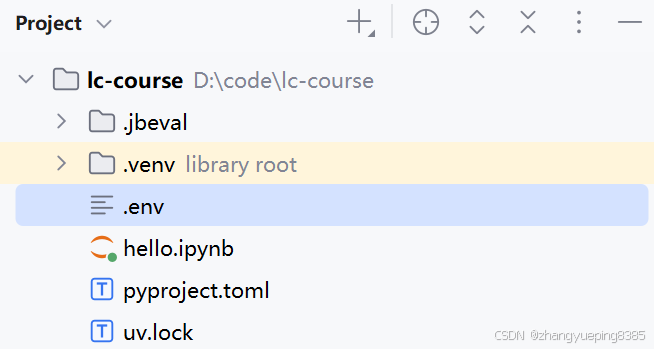
在其中配置自己的API_KEY,我们以Deepseek为例:
|-------------------------------------------------------------------------------------------------|
| Properties # deepseek DEEPSEEK_API_KEY=sk-1234567890 *#*阿里云 DASHSCOPE_API_KEY=sk-1234567890 |
第二步,安装 python-dotenv。
在项目中,我们通过python-dotenv库来读取环境变量,所以要先安装依赖。
|---------------------------|
| Bash uv add python-dotenv |
安装成功后,会在pyproject.toml中看到新添加的依赖:
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Java project name = "lc-course" version = "0.1.0" description = "Add your description here" requires-python = ">=3.13" dependencies = "notebook\>=7.5.5", "openai\>=2.28.0", "python-dotenv\>=1.2.2", |
第三步,读取环境变量。
最后,我们就可以在代码中读取环境变量了:
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Python from openai import OpenAI from dotenv import load_dotenv import os *#*加载环境变量 load_dotenv() client = OpenAI( api_key=os.getenv("DEEPSEEK_API_KEY"), base_url="https://api.deepseek.com" ) print("🚀 正在调用大模型...") response = client.chat.completions.create( model="deepseek-chat", messages= {"role": "system", "content": "你是一名友好的AI助教。"}, {"role": "user", "content": "你好,你是谁?"} , stream=False ) print(response) |