在 LangChain 这个全能型框架里,我们可以通过各种 Skills 来扩展能力,比如 DeepAgents 这类组件,能帮我们做很多复杂的事情。
说到知识库,通常分为两类:
- 非结构化数据:像 PDF、Word、HTML 这些文档类内容;
- 结构化数据:比如 MySQL 这类关系型数据库。
而企业的主数据,本质上就是高度结构化的 SQL 数据。数据越规范、质量越高,我们能从中挖掘出的价值就越大。像 ChatBI 这种场景,不仅能做数据看板,还能基于 XGBoost 等模型做更深度的数据洞察。
现在主流的 AI 应用,大多是你在网页上跟它聊天,比如问"现在黄金行情怎么样?",AI 会先去网上搜一圈,再整理分析,最后以对话的形式把结果抛给你。但这种方式有个问题------不够准,每次聊出来的结论可能都不太一样,稳定性比较差。
但结构化数据就不一样了,质量相对可控。你把数据治理好了,复用率会特别高,价值也很明显。因为最终 AI 回答的质量,很大程度上取决于你底层数据的质量。
所以,如果你想做一个高质量的 Agent,Text-to-SQL 是个非常值得考虑的方向。让 AI 去查询数据库、把数据捞出来,这个过程我们可以选择不同的大模型来支撑,有开源的,也有闭源的。
- 如果是个人开发者,直接选闭源的商业模型就行,不用自己搭服务器、配 GPU,性能还是顶配;
- 如果是企业,建议优先考虑开源方案,毕竟数据安全这根弦得绷紧。
那具体怎么让大模型拿到数据呢?核心思路是通过 Function Call,让模型主动去调用工具完成任务。
搭建 SQL Copilot(也就是 SQL 查询助手),目前常见的有三种路子:
- 直接用 LangChain 里的 SQL Agent(SQLDatabase):开箱即用,省事;
- 自己手写(LLM + Prompt):更灵活,不依赖第三方,想怎么改就怎么改;
- 用 Vanna 这类开源工具:里面已经集成好了很多功能,拿来就能用。
SQL 是一门面向集合的查询语言,它的优势在于一条语法就能批量捞数据,通过集合操作一次性把你要的东西都抓出来。
回想一下以前的工作模式:都是研发人员给业务同学写 SQL。业务方提个工单,说想查个数据,把需求列一列,然后就开始排期。研发拿到工单,经常发现需求写得比较模糊,得猜业务到底想看哪个字段、有什么筛选条件。一来二去,双方得反复沟通,研发还得帮业务分析需求,耗时又耗力。
现在 AI 越来越成熟了,研发同学也想把自己从这种重复劳动里解放出来,去做更有价值的事。一些基础的执行工作,完全可以交给 AI 来替代。业务人员直接用自然语言跟 LLM 描述需求,AI 自动生成 SQL。如果要看不同维度的数据,就跟 AI 多聊几句,让它帮你做转换。而研发人员则可以站在更高的视角,去做数据洞察、算法优化、特征分析这些更有深度的事情。
Text-to-SQL(文本转 SQL)
简单来说,就是把用户用自然语言描述的问题,自动转换成结构化的 SQL 查询语句,让用户能更直观地和数据库打交道。
这项技术大概经历了三个阶段的演变:
第一阶段:早期规则模板
靠人工写好的规则模板,去匹配自然语言和 SQL 之间的对应关系。比如把常用的 SQL 场景整理出来,业务人员可以参考、甚至照着模板填空拼接。但这种方式只能解决一小部分固定场景,灵活度完全不够。
第二阶段:机器学习
开始用 Seq2Seq 这类模型去学习自然语言到 SQL 的映射关系。但那时候准确率上不去,很难真正落地。
第三阶段:大模型时代(也就是我们现在所处的阶段)
借助 LLM 强大的语言理解和代码生成能力,通过提示工程、微调等手段,Text-to-SQL 的性能被提升到了一个新高度。
基于 LLM 的 Text-to-SQL 系统,通常会经历以下几个步骤:
- 自然语言理解:分析用户输入的问题,理解他的真实意图和语义;
- 模式链接:把问题里的实体(比如表名、字段名)跟数据库的实际 Schema 对应起来;
- SQL 生成:基于理解到的语义和 Schema 信息,生成对应的 SQL 语句;
- SQL 执行:在数据库里跑这条 SQL,把结果返回给用户。
LLM模型选择
闭源模型
-
GPT-5.4 / GPT-5: OpenAI 2026年3月发布的最新旗舰,272K-1M上下文,Text2SQL复杂Schema理解显著优于前代,Pro版本支持深度推理。
-
Claude 4.7 Opus / Sonnet: Anthropic 2026年2月发布,Text2SQL准确率分别达100%和98%,支持1M上下文和自适应推理深度,Sonnet为性价比最优选。
-
Gemini 3.1 Pro / Flash: Google 2026年2月与2025年12月更新,保持1M上下文优势,支持原生图像生成与多模态输入,Flash-Lite版价格低至$0.10/M Tok。
-
Qwen 3.6 Plus: 阿里2026年4月最新发布,100万token上下文,采用混合架构,Agent编程与前端开发能力显著优于3.5系列,Terminal-Bench 2.0基准超越Claude Opus 4.5,目前OpenRouter免费预览,后续定价预计为Claude的1/17,Text2SQL长Schema处理首选。
开源模型
-
DeepSeek-V4 Pro / Flash: 2026年4月24日发布,1.6T/284B总参数,49B/13B激活(MoE架构),V3.2支持1000K上下文与Tool Use,三档推理模式可切换:快速响应/逻辑分析/全力推理,原生多模态(文本/图像/视频/音频),深度适配华为昇腾芯片,国产算力友好,成本约为GPT-4的1/70,Text2SQL工具调用能力显著增强。
-
Qwen3 / Qwen3-Coder-Next: 阿里2025年4月及2026年2月开源,235B-A22B(22B激活)与80B-Coder(仅3B激活)均采用MoE架构,支持256K-1M上下文,Apache 2.0协议,Coder-Next在SWE-bench达70.6%且仅需46GB显存即可本地部署,Text2SQL代码生成效率优于Llama 4。
搭建SQL Copilot(SQL助手)
LangChain 里的 SQL Chain:开箱即用,但也有天花板
LangChain 这个框架很贴心,它内置了一套 SQL Chain,把 Prompt(提示词)、Retriever(检索)、Tools(工具)、Agent(智能体)这些模块都串在了一起。用户只需要用自然语言提问,它就能自动帮你执行 SQL 查询。
它的优点很明显:
高度封装,用起来特别省事。你只需要配好数据库连接,它就能自动去拉取数据库的元数据(metadata),表结构、字段类型这些信息它自己就能拿到,不用你手动往里塞。
但短板也很真实:
执行起来不够灵活。比如遇到复杂查询,它要反复判断"到底该用哪张表",这个决策链路一多,就容易翻车。复杂查询的通过率其实并不高,稍微绕一点的业务逻辑,它可能就搞不定了。
从知识库到 SQL Agent:LangChain 的两种打开方式
以前我们用 LangChain,更多是搭知识库------把文档做切片、灌进向量数据库,做召回和问答,让 AI 能基于本地文档来回答问题。或者就是搭 Agent 工作流,把各种工具串成一个自动化流程。
但其实 LangChain 里面还内嵌了一个 SQL Chain(也就是 SQL Agent),专门对 SQL 查询做了封装。你可以直接跟它用自然语言提问,它内置了一些现成的工具,能直接跟你的数据库做连接,自动读取元数据,省去了很多手动配置的麻烦。
向量数据库在这里能发挥什么作用?
在 Text-to-SQL 的场景里,向量数据库并不是摆设,它有几个很实用的价值:
- 给 Prompt 补充更多上下文:检索出来的相关信息可以作为 context 喂给 LLM,帮它做更准确的决策。
- 用相似度阈值过滤噪音:通过设置 similarity threshold,把那些跟用户 query 关系不大的 example 筛掉,避免垃圾信息干扰模型判断。
- 优化 few-shot examples 的多样性:让 Prompt 里展示的案例尽可能覆盖更多场景,而不是总给那几个相似的例子,提升泛化能力。
Prompt 怎么写?这几个细节很关键
Prompt 的写法直接决定了 Text-to-SQL 的效果,有几个点特别值得注意:
- 明确标注语言类型 :在 Prompt 里写清楚
-- language: SQL,让模型知道你要输出的是 SQL。 - 把 SQL 建表语句放进去 :大语言模型是通过建表语句来理解表结构的,所以
CREATE TABLE这些 DDL 语句一定要塞到 Prompt 里,这是它"看懂"你数据库的关键。 - SQL 代码块用标识语言包裹 :生成的 SQL 语句要用 ```````sql```` 这样的代码块标识包起来,放在 Prompt 的最后,让模型输出格式更规范,也方便后续解析。
Prompt中的首尾很重要!
python
prompt = f"""-- language: SQL
### Question: {query}
### Input: {create_sql}
### Response:
Here is the SQL query I have generated to
answer the question `{query}`:
```sql
"""Prompt + SQL + 向量数据库 + LLM:
- 向量数据库可以提供领域知识,当用户检索某个问题的时候 => 从向量数据库中找到相关的内容,放到prompt中 => 提升 SQL查询的相关性RAG技术。
- 在prompt中增加few-shot examples
- 专门定制检索工具,从向量数据库中 检索到与用户query相近的知识
- 除了对用户query,补充领域知识外,针对专门名词(用户可以拼写错误的),也可以进行纠正。
- 如果想让LLM使用tool(可以按照某个顺序,执行完这个再执行下一个),比较有效的方式是写在prompt中,而不是在tool description中进行定义
- 通过SQLDatabase可以访问到数据库的Schema
python
# 构建数据库连接字符串
db_uri = f"mysql+pymysql://{db_user}:{db_password}@{db_host}/{db_name}"
# 连接数据库
logger.info("正在连接数据库...")
db = SQLDatabase.from_uri(db_uri)
logger.info("数据库连接成功!")- query_database 作为SQL Agent,可以执行用户的各种SQL需求(通过自然语言 => 编写SQL => 查询结果返回)
python
# 示例查询
example_question = "找出所有理赔金额大于10000元的理赔记录,并列出相关客户的姓名和联系电话"
print(f"查询问题: {example_question}")
print("\n查询结果:")
try:
result = query_database(example_question)
print(result)
except Exception as e:
print(f"查询失败: {e}")如果数据库中没有找到对应的表,会报OutputParseException错误。
如果有多张表,会分别执行,然后判断哪个数据表可以得到结果。
每次查询都会把数据库内所有的表以及表字段都会查询一次,效率比较慢,而且耗时长。
相似的数据表会导致LangChain多次尝试生成SQL,
而且用户Prompt太宽泛,生成的结果可能并不是用户想要的。
我们可以通过给Agent配备专有知识库,在Prompt中动态完善和query相关的context
数据权限控制:
- prompt:定义用户角色,不要让它看XXX表数据,比如收入字段;
- 过滤器函数,通过规则来定义,在sql数据库内打tag标签(规则)。角色都对应一个tag标签,数据库表有tag,数据字段也可以有tag==> 精准匹配。
案例:SQL查询
数据库表:
使用Trae Idea进行 vibe coding:
prompt:
使用gpt-3.5-turbo进行数据表的查询
LangChain 1.x:SQL Agent 在 langchain_community,对话模型在 langchain_openai
本地数据库信息:
db_user = "root"
db_password = "666666"
db_host = "127.0.0.1:3306"
db_name = "study"
通过LLM => 撰写SQL
需要设置 llm(用于 SQL 校验等工具)
SQL 智能体:给它目标,它自己会进行规划,最终把结果给你
tool-calling 适配 DevAGI 接口(需模型支持函数调用)
参考 @example03.py 调用模型
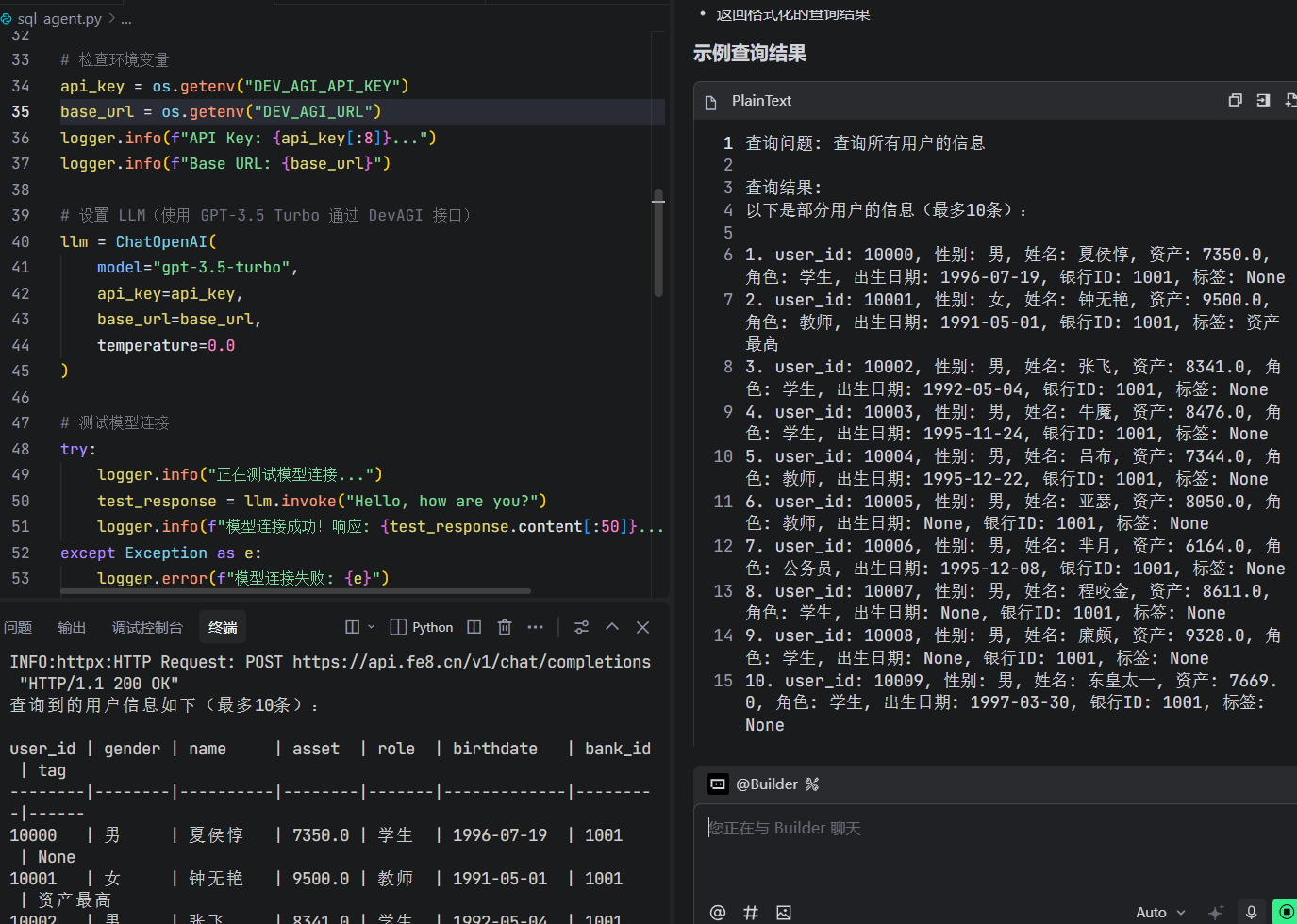
描述数据表
结果如下:
Vanna框架
Vanna 是开源的 RAG框架,专注于将自然语言转换为 SQL 查询(Text-to-SQL),并支持与数据库的交互,Github可以下载源代码:Vanna源码。
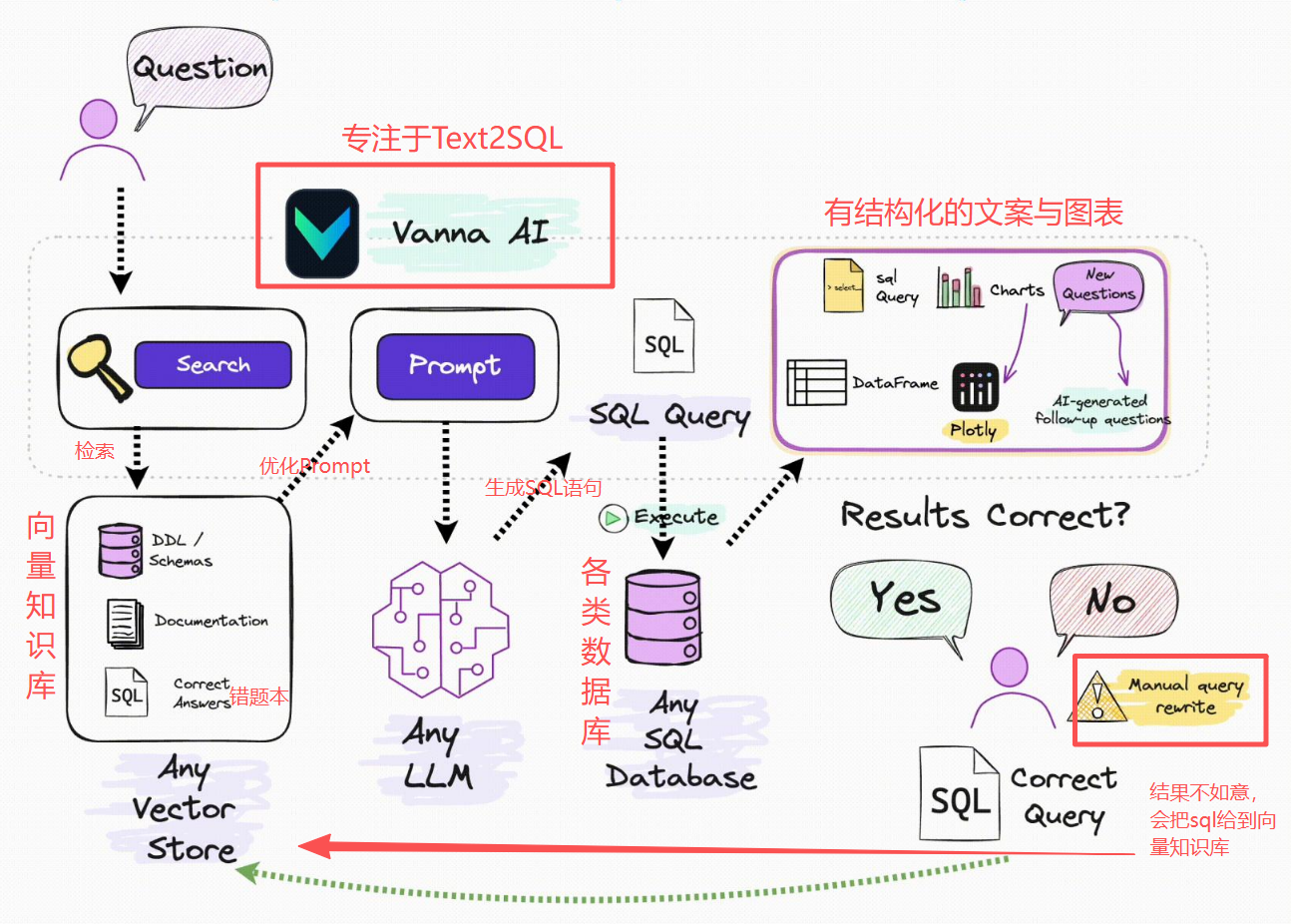
Vanna特点:
- 开源与可定制化: Vanna 提供完整的 Python 库,支持本地化部署,允许用户自定义大语言模型(LLM)、向量数据库(VectorDB)和关系型数据库(如 MySQL、PostgreSQL 等)。
- RAG 增强的准确性: 通过检索增强生成技术,结合数据库的元数据(如 DDL 语句、表注释、示例 SQL 等)训练模型,显著提升复杂查询的准确率。
- 多场景支持: 适用于企业数据分析、智能客服、电商搜索、金融报告生成等场景,非技术人员可通过自然语言直接查询数据库。
- 灵活的基础设施: 支持多种 LLM(如 OpenAI、本地部署的 Ollama)、向量数据库(如 ChromaDB),并可扩展至非默认支持的数据库。
Vanna支持的基础设施:
- LLM: OpenAI、Azure OpenAI、Anthropic、Google Gemini、Ollama、Mistral、DeepSeek、ZhipuAI、千问 / 通义、Bedrock 等
- 向量库: ChromaDB、FAISS、Qdrant、Milvus、Weaviate、Pinecone、PgVector、OpenSearch、Marqo 等
- 数据库: MySQL、PostgreSQL、SQLite、Snowflake、BigQuery、ClickHouse、Oracle、DuckDB、MSSQL、Presto、Hive 等
Vanna使用步骤:
- vanna安装: pip install vanna,可选扩展如 vannachromadb,ollama,mysql 支持本地化部署。
- 连接数据库: 自定义 run_sql 方法(如 MySQL 需通过 mysql.connector 返回 Pandas DataFrame)。
- 训练模型: 通过 DDL、文档或 SQL 示例训练,例如:vn.train(ddl="CREATE TABLE users (id INT PRIMARY KEY, name VARCHAR(100))")
- 提问与查询: 调用 vn.ask("查询销售额最高的产品"),生成并执行 SQL。
Vanna工作原理:
用户问题 → 向量检索(DDL/Doc/SQL) → 组装 Prompt → LLM 生成 SQL → 执行 SQL → 返回 DataFrame + Plotly 图表
1)训练阶段
把数据库的元数据写入向量库,作为后续检索的知识库:
- DDL:建表语句,告诉模型表结构与字段含义。
- Documentation:业务文档、字段口径、术语解释。
- Question-SQL pairs:高质量的 问题-SQL 示例(few-shot 样本)。
2)推理阶段
问题向量化后从向量库召回 Top-K 相似的 DDL / Doc / SQL 例子, 拼成一份 system prompt + few-shot 示例 => 交给 LLM 生成 SQL,再 run_sql 执行。
Top-K越大,召回信息越多,Top-K越小,召回信息越精准。
比如,Top-K=10,如果没在召回的Top10里面,就不会有数据,要把这个超参数Top-K改大点,才会有参数。
核心API
ask函数
ask函数是一站式入口!
作用:用户通过自然语言提问时调用此函数,它是查询的核心入口,会依次调用generate_sql、run_sql、generate_plotly_code、get_plotly_figure四个函数来完成整个查询及可视化的过程。
工作流程:
-
首先将用户的问题转换成向量表示,然后在向量数据库中检索与问题语义最相似的DDL语句、文档和SQL查询。
-
将检索到的信息和用户的问题一起提供给LLM,生成对应的SQL查询。
-
执行生成的SQL查询,并将查询结果以表格和Plotly图表的形式返回给用户。
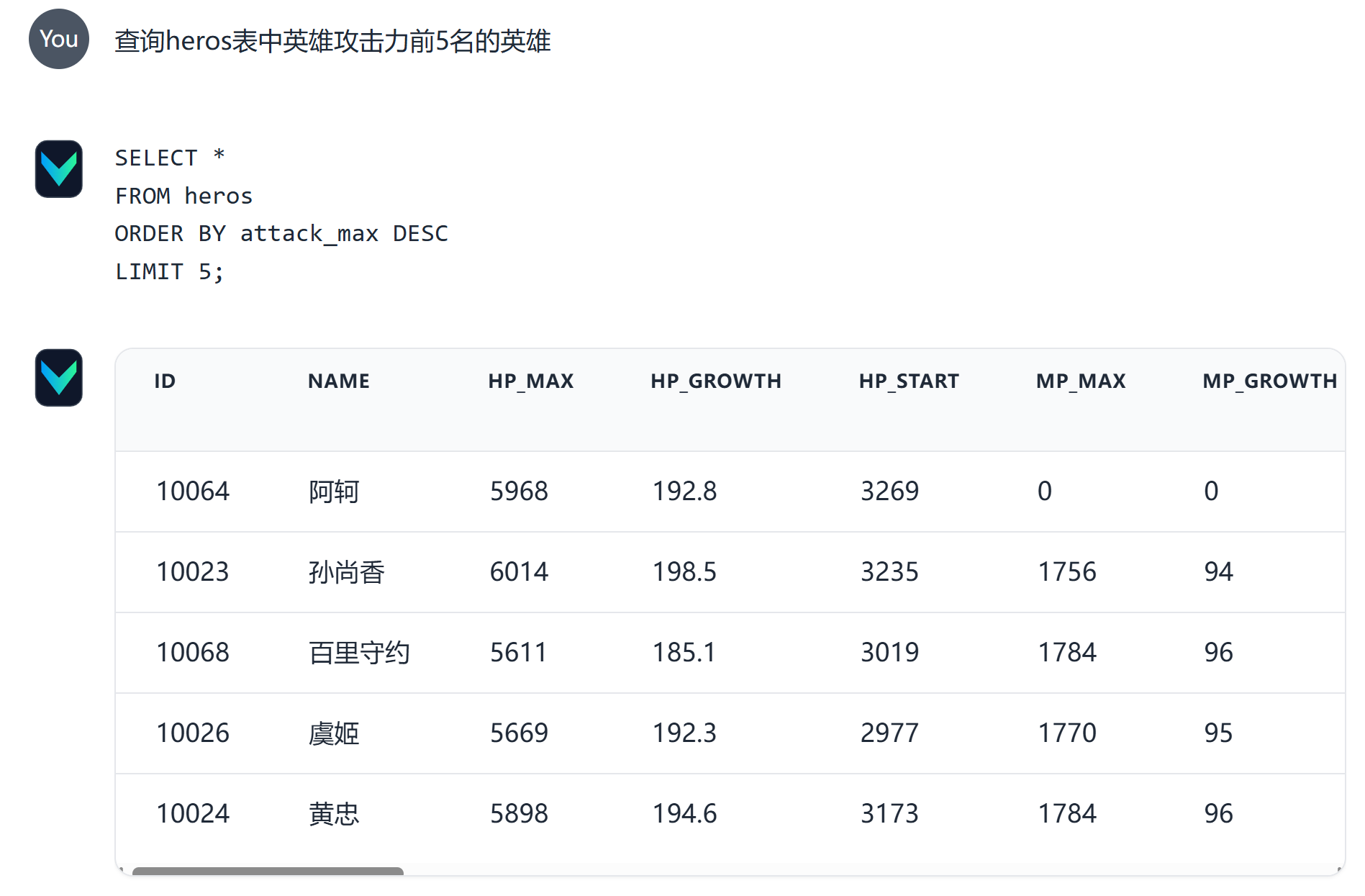
比如:vn.ask("查询heros表中 英雄攻击力前5名的英雄")
generate_sql函数
作用:不执行,只返回 SQL 字符串
工作流程:
- 调用get_similar_question_sql函数,在向量数据库中检索与问题相似的sql/question对。
- 调用get_related_ddl函数,在向量数据库中检索与问题相似的建表语句ddl。
- 调用get_related_documentation函数,在向量数据库中检索与问题相似的文档。
- 调用get_sql_prompt函数,结合上述检索到的信息生成prompt,然后将prompt提供给LLM,生成SQL语句。
比如:sql=vn.generate_sql("查询heros表中 英雄攻击力前5名的英雄")
run_sql函数
作用: 执行generate_sql函数生成的SQL语句,并返回查询结果。
工作流程: 将生成的SQL语句发送到连接的数据库中执行,获取并返回查询结果。
比如:
sql=vn.generate_sql("查询heros表中 英雄攻击力前5名的英雄")
vn.run_sql(sql)
train函数
作用: 训练(写入向量库)
三种训练姿势:
-
vn.train(ddl="CREATE TABLE users (id INT, name VARCHAR(100))")
-
vn.train(documentation="users 表存储 C 端注册用户,name 为脱敏昵称")
-
vn.train(question="用户总数?", sql="SELECT COUNT(*) FROM users")
训练数据管理
td = vn.get_training_data() # 列出全部训练数据
vn.remove_training_data(id="xxx") # 按 id 删除某条
其他函数
| 函数 | 作用 |
|---|---|
| connect_to_mysql / postgres / sqlite ... | 连接对应数据库,自动注入 run_sql |
| generate_followup_questions(q, sql, df) | 根据当前结果,建议下一步追问 |
| generate_summary(q, df) | 用自然语言总结查询结果 |
| generate_plotly_code / get_plotly_figure | 自动生成 Plotly 图表代码并渲染 |
| generate_question(sql) | 反向:根据 SQL 生成问题(用来扩样本) |
案例:Vanna Web
使用Trae Idea进行 vibe coding:
prompt:新建一个.py的文件
自定义 Vanna:
向量库用 ChromaDB,LLM 用 DevAGI 接口(这里走通义千问,qwen-plus)
参考 @example03.py ,创建LLM客户端
初始化 Vanna 实例:
n_results_ddl = 30 ,确保所有相关表的 DDL 都能召回到 prompt 里
连接到 MySQL:db_user = "student123"
db_password = "student321"
db_host = "rm-uf6z891lon6dxuqblqo.mysql.rds.aliyuncs.com:3306"
db_name = "information_schema"
通过 vn.run_sql 获取 information_schema数据库的所有表名
训练每个表的 schema,表名加反引号,避免遇到 SQL 关键字(如 using)时报语法错
训练完成要打print
启动 Vanna Web 界面